实现AI帮你出题、判题、给解析和自动记录错题一条龙服务,遇见的6个血泪坑与修复方案
摘要: 在开发一个考前测验AI Tutor系统的过程中,我踩了6个典型的LLM+Agent工程坑:无效选项被误判、上下文折叠丢错题、LLM忘记调工具、第1道题兜底失效……本文记录了每个问题的根因分析、解决方案,以及那些"Prompt写满也没用,必须代码兜底"的血泪经验。
前言:完成AI帮你出题、判题、给解析和自动记录错题这一套流程,怎么这么难?
做在线教育产品时,我设计了一个"考前测验"场景:用户做题,AI即时判对错、记录错题、自动生成薄弱点报告。
听起来很简单对吧?但开发过程中,我就遇到了这些问题:
“我做的错题Agent为什么没有自动记入错题库?”
“Agent说我第3题错了,为什么错题本里没有?”
“我的回答超出选项范围Agent怎么没发现?”
经过排查和重构,我修复了6个高优先级问题。这篇文章把踩坑和填坑的过程完整记录下来,希望能帮助到做类似功能的朋友。
痛点一:用户输入 F/E/G,AI 默认当作 D 处理
问题现象
用户在选择题中输入了 f、e、g 等无效选项,AI Agent 并没有拒绝,而是直接当作 D 选项处理,甚至直接判对错。
根因分析
Prompt 层只写了"请核对答案",没有明确告诉 LLM:遇到非 A~D 的输入必须拒绝。
LLM 的"善意揣测"导致它倾向于把用户的输入解释成有效选项,而不是质疑用户。
解决方案:双层拦截
第一层:Prompt 规则强化
在 exam-quiz.md 中新增输入校验规则:
输入校验规则:
- 用户必须输入单个字母 A/B/C/D
- 遇到非 A~D 的输入,必须明确提醒"选项范围仅为 A、B、C、D"
- 禁止猜测用户意图或替用户选择
第二层:代码层硬拦截
在 LLM 调用前,检测用户消息是否为单个非 A~D 字母:
stripped_answer = latest_user_query.strip()
if len(stripped_answer) == 1 and stripped_answer.lower() not in ('a', 'b', 'c', 'd'):
if last_assistant_content and re.search(r'[A-D][.、.)\s]', last_assistant_content, re.IGNORECASE):
# 直接返回提醒,不消耗 LLM Token
return StreamingResponse(validation_warning_generator(), ...)
效果: 拦截后端直接返回 "选项范围仅为 A、B、C、D,请重新输入",完全不经过 LLM,零 Token 消耗。
痛点二:刷题多了上下文折叠,错题信息全丢了
问题现象
用户刷了 30 道题后,早期的错题信息在上下文折叠时丢失。最终生成的总结报告中,错题列表不完整,薄弱点分析也出现了偏差。
根因分析
通用消息折叠摘要只保留了"最近几轮"的内容,答题统计和错题清单没有结构化保留。
解决方案:测验专用折叠摘要
拆分检测逻辑,用不同阈值处理不同场景:
assistant_msgs = [m for m in request.messages if m.role == "assistant"]
quiz_pattern_count = 0
for am in assistant_msgs[-6:]:
if re.search(r'[A-D][.、.)\s]', am.content, re.IGNORECASE):
quiz_pattern_count += 1
is_quiz_mode = quiz_pattern_count >= 2 # 折叠摘要用(需强证据)
is_likely_quiz = quiz_pattern_count >= 1 # 错题兜底用(第1题就生效)
折叠摘要时使用定制指令:
collapse_instruction = (
"你正在总结一场**考前测验**的对话历史。请按以下结构生成摘要:\n"
"1. **答题统计**:总答题数、正确/错误数量、正确率。\n"
"2. **错题清单**:逐条列出每道错题(题目、用户答案、正确答案、知识点)。\n"
"3. **薄弱知识点**:归纳学生反复出错的知识点。\n"
"4. **关键诉求**:学生当前的核心需求。\n"
"请务必保留每一道错题的具体信息,不可省略或合并。"
)
痛点三:工具调用消息刷屏,干扰用户体验
问题现象
错题入库时,前端显示一连串 "🛠️ 正在调用工具..."、"✅ 工具调用完成" 等系统消息,用户体验很差。
根因分析
tool_start 和 tool_end 的 SSE 事件被前端直接渲染成文本。
解决方案
直接移除 chatStore.ts 中对 tool_start 和 tool_end 事件的可见文本渲染。LLM 本身会在工具执行后给出自然语言确认(如"这道错题已帮你记录"),不需要额外的系统状态行。
痛点四:LLM 判错后"忘记"保存错题
问题现象
用户:“老师,我这道题选错了”
AI:“是的,你选错了,正确答案是 B”
(然后就没有然后了,错题没有入库)
根因分析
即使 Prompt 里写了"必须调用 save_mistake_records",LLM 也经常"忘记"。这不是 LLM 故意不听话,而是判错流程和保存流程分离后,执行链路断裂了。
解决方案:Prompt 强化 + 后端兜底双保险
Prompt 层:强制编号步骤
回答结构(每一步都必须执行):
1. 核对答案并告知对错
2. 立即调用 save_mistake_records 记录错题
⚠️ 步骤 2 不可跳过,必须在回复用户前完成
后端层:兜底机制(核心修复)
即使 LLM 完全忘记调工具,后端也能自动补救:
# 检测 LLM 回复中的错题语义(15+种模式)
wrong_answer_patterns = [
r'不[太对]?对', r'[有错]误', r'不正确', r'有误',
r'再想想', r'再考虑', r'误区', r'不是正确答案',
...
]
indicates_wrong = any(re.search(p, full_assistant_response) for p in wrong_answer_patterns)
# 检测本轮是否已调用 tool
has_mistake_tool = any("save_mistake_records" in str(r) for r in tool_records_to_save)
if indicates_wrong and not has_mistake_tool:
# 触发兜底:轻量 LLM 提取错题 → 直接写库
mistake_data = json.loads(extract_result)
await save_mistake_records(subject=..., questions=[mistake_data], context=...)
full_assistant_response += '\n\n(错题已自动记入错题本)'
痛点五:第 1 道错题永远不触发兜底
问题现象
用户只做了 1 道题就答错了,兜底机制没有生效,错题依然没有入库。
根因分析
测验模式检测阈值 quiz_pattern_count >= 2,第 1 道题答错时只有 1 条 assistant 消息含 ABCD,不满足条件。
解决方案:拆分阈值
is_quiz_mode = quiz_pattern_count >= 2 # 折叠摘要用(需强证据)
is_likely_quiz = quiz_pattern_count >= 1 # 错题兜底用(第1题就生效)
低成本解法,在灵敏度和误判之间取得平衡。
痛点六:兜底成功入库后,AI 不知道
问题现象
后端兜底成功写入数据库了,但用户追问"我刚才那道错题你记了吗",AI 说"没有啊,我帮你记一下"——然后又重复入库。
根因分析
兜底消息只通过 SSE 发给了前端,没有追加到 full_assistant_response,所以没有存入数据库对话历史,LLM 下一轮看不到。
解决方案
# 关键修复:同时追加到 full_assistant_response
full_assistant_response += '\n\n(错题已自动记入错题本)'
yield f"data: {json.dumps({'content': fallback_note})}\n\n"
只有同时写入 full_assistant_response,这条消息才会进入对话历史,LLM 才能在后续交互中感知到。
经验总结:5条血泪换来的设计原则
1. 不要信任 LLM 的指令遵循能力
Prompt 里写"必须"、"强制"只能提高概率,不能保证 100%。关键操作必须有代码层兜底。
设计原则:
Prompt 指令(第一道防线,概率性)
↓ 失败时
代码层兜底(第二道防线,确定性)
2. SSE 流中 yield ≠ 写入对话历史
循环外 yield 的内容虽然前端能看到,但不会自动进入数据库对话历史。如果要让 LLM 在下一轮感知到某条消息,必须同时追加到 full_assistant_response。
3. 阈值设置需要考虑冷启动
>= 2 对"确认测验状态"合理,但对"第 1 题就触发"不够。拆分阈值是一个低成本解法。
4. LLM 有"学习"效应,但别被它骗了
用户反馈"第 2 题起 AI 就主动调工具了"——这不是 LLM 理解了规则,而是第 1 次手动提醒后,对话历史里有了 tool-call 先例,LLM 在做模式匹配。
不能在测试时误以为 Prompt 生效了,必须覆盖冷启动场景。
5. 沉默的兜底比没有兜底好,但透明的兜底更好
让兜底消息对 LLM 可见(写入对话历史),比只写日志强 100 倍。
效果图展示
进入考前测验模式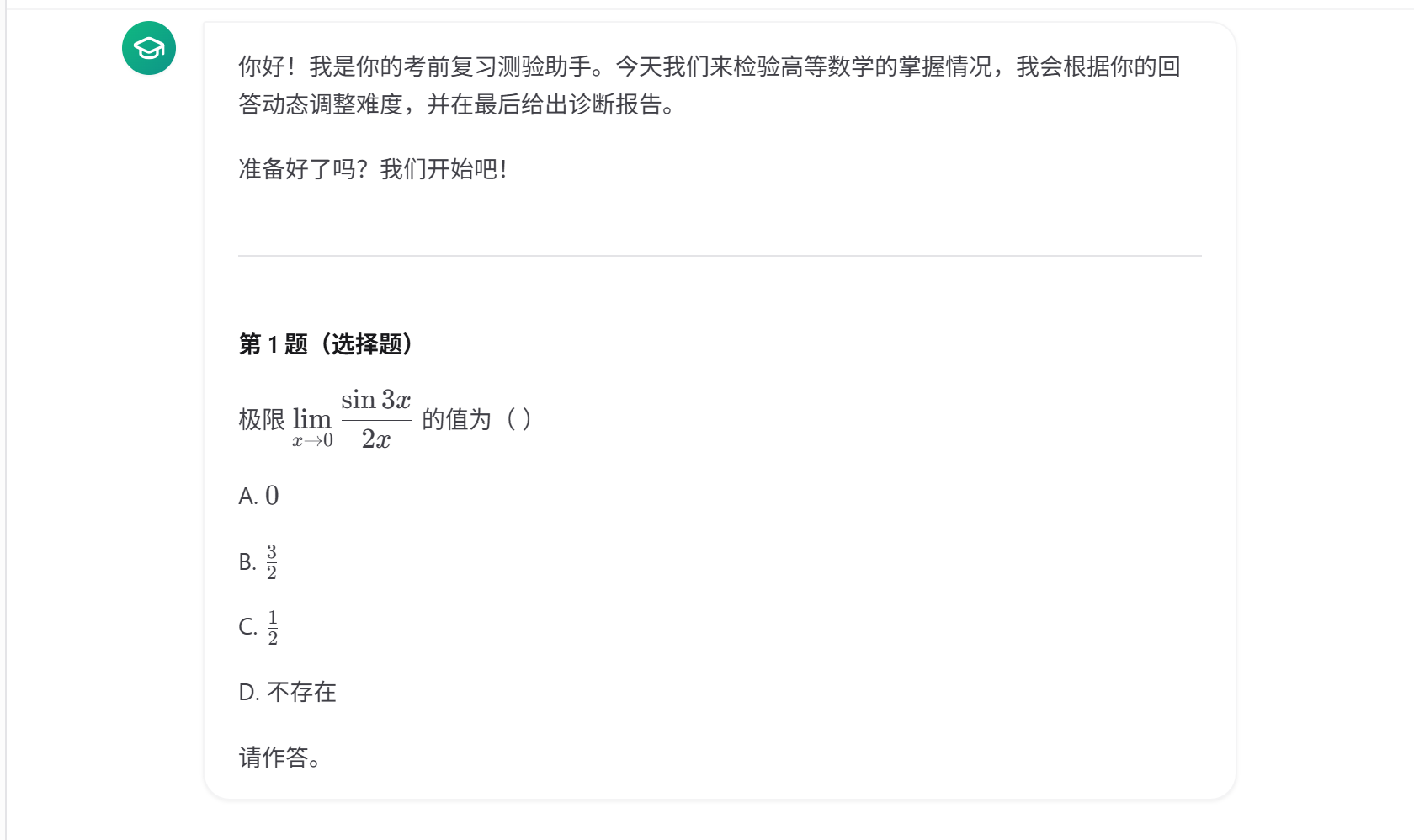
学生回答错误
错误的题自动记入,可在错题本中查看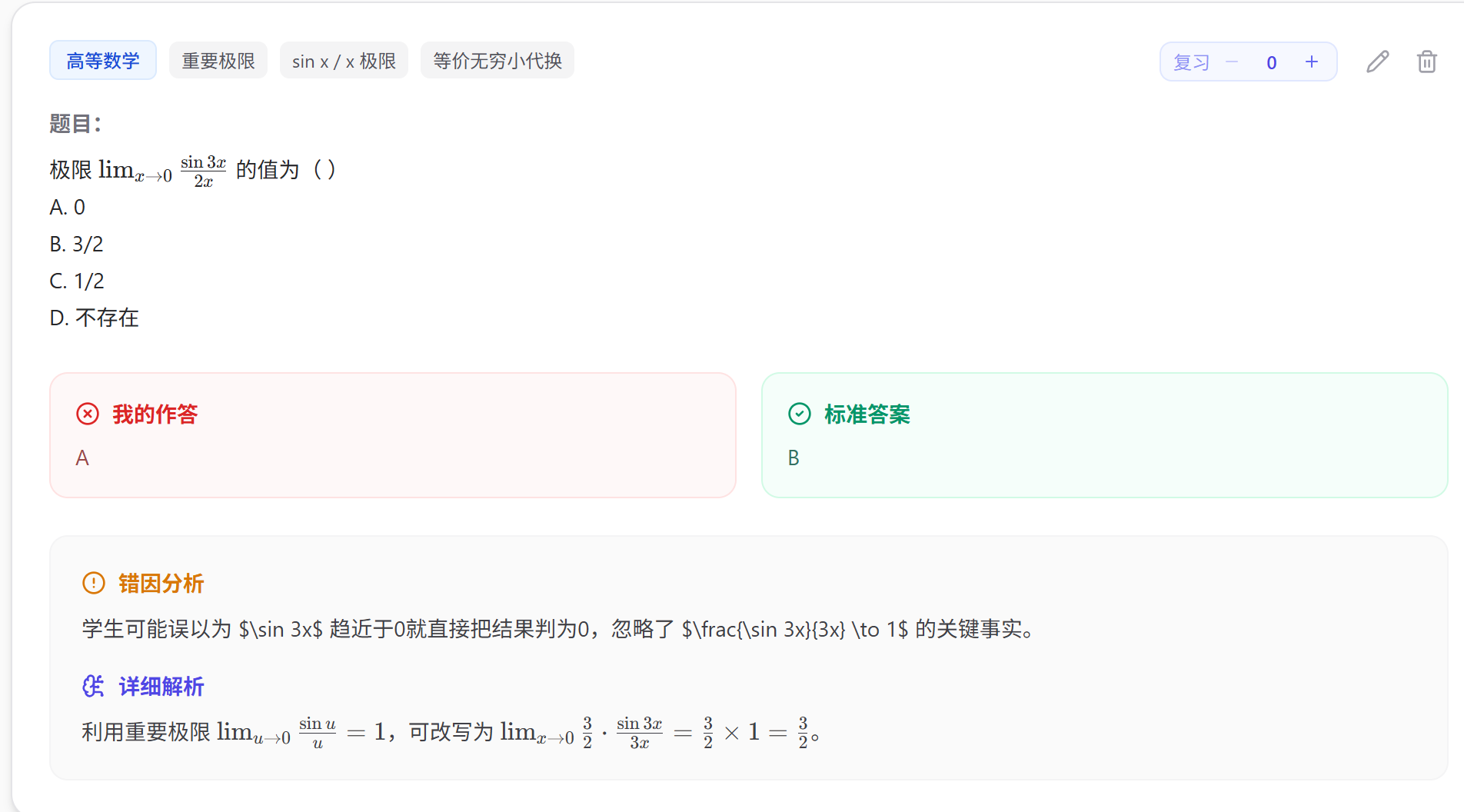
结束测验,给学生测验报告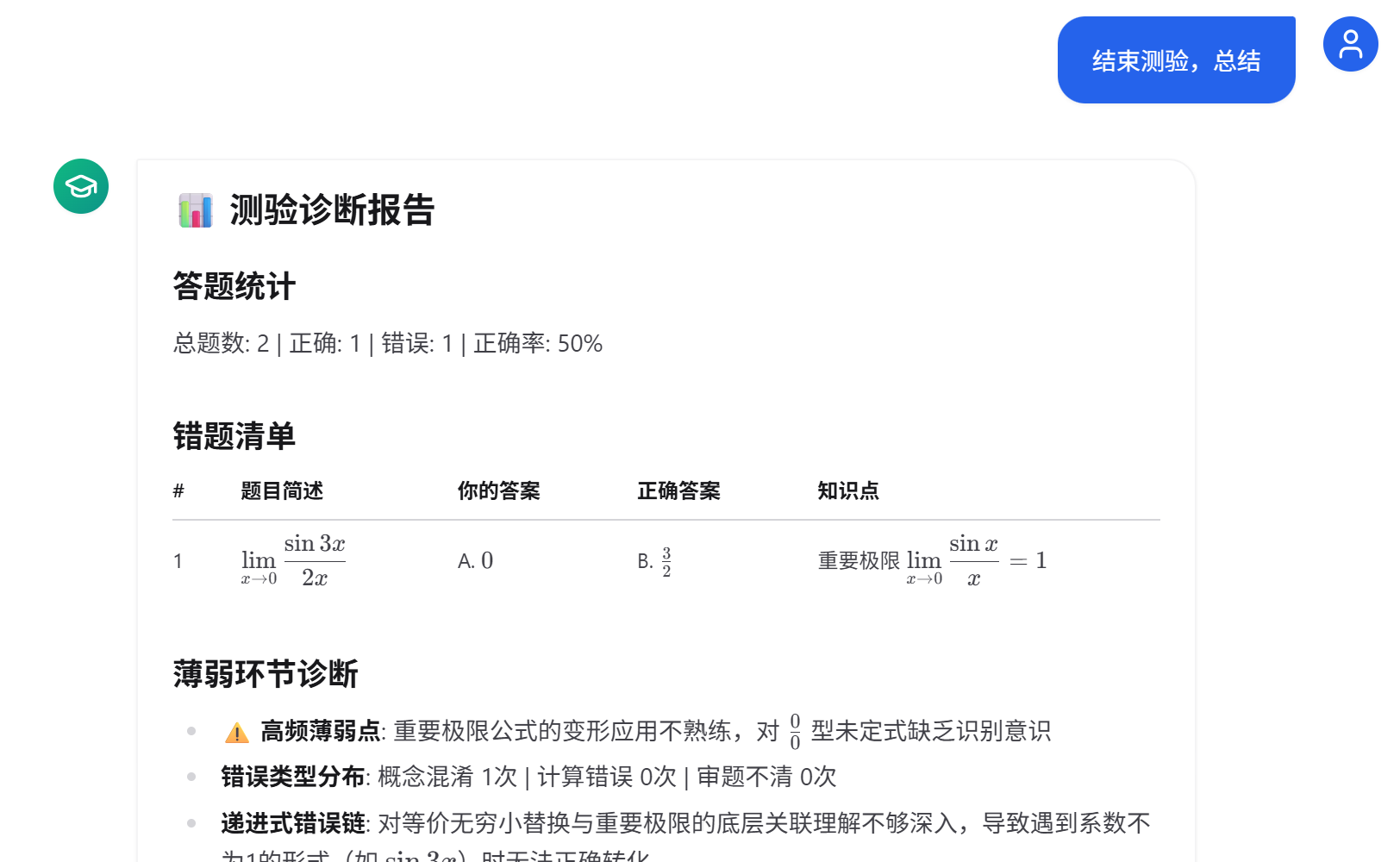
完整实现AI出题、判题、给解析、自动记录错题和总结测验报告一条龙服务。
结语
做 AI Tutor 系统,最难的不是"让 AI 回答正确",而是"让 AI 可靠地完成所有关联操作"。
LLM 的不确定性决定了:任何关键操作都不能依赖单一 Prompt 层,必须有代码层兜底。这是从"能用"到"可靠"的关键一步。
希望这篇文章对你有帮助。如果你在做类似的教育 AI 产品,欢迎交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)