技术架构解析:从“功能外挂”到“智能内核”——“AI原生”理念如何重构CRM系统
引言:由两个行业现象引发的技术思考
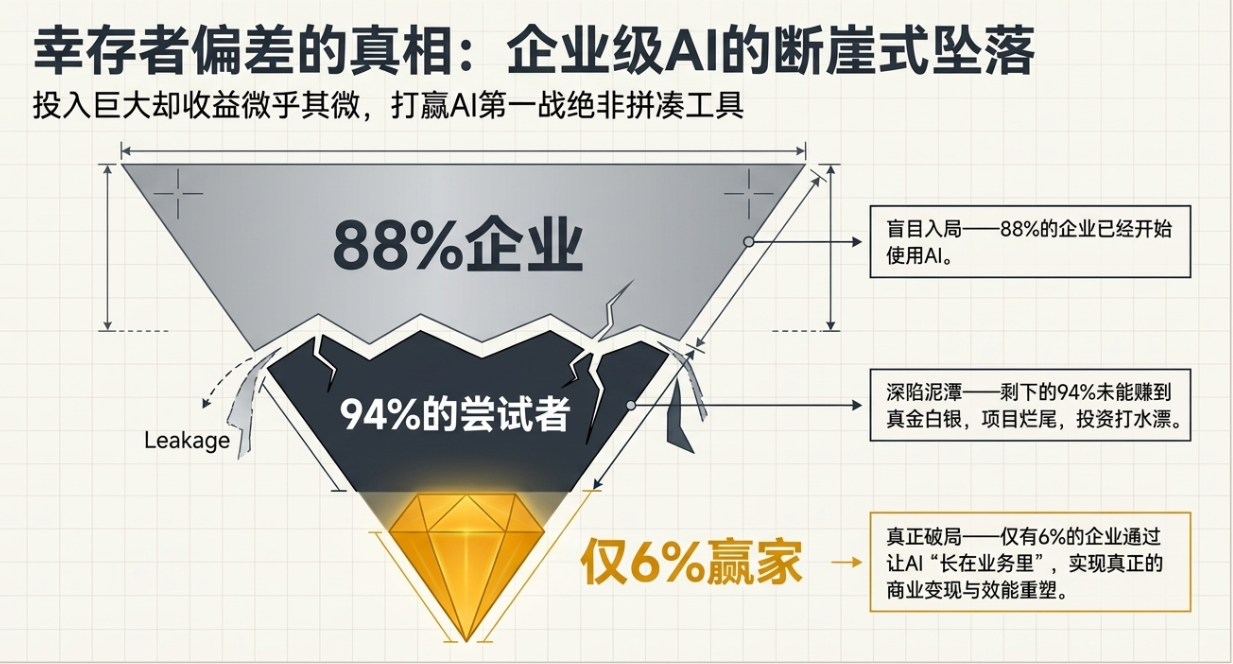
进入2026年,两个并行的行业观察值得技术从业者关注。一是AI生成内容(AIGC)在短剧等标准化生产领域已实现成熟的工程化替代,引发了关于自动化边界的社会讨论。二是一份来自快鹭科技的2026年行业调研数据显示,尽管AI技术应用广泛,但高达88%的企业级项目未能达成预期业务目标,存在显著的“价值实现鸿沟”。
后者在客户关系管理(CRM)系统的智能化升级中尤为突出。许多企业投入建设的AI CRM系统,在技术上完成了模型集成,但在业务上并未成为核心生产力工具。本文旨在从系统架构与工程实践的视角,分析这一普遍困境的技术根源,并探讨“AI原生”作为一种设计范式,其背后的技术逻辑与实现路径。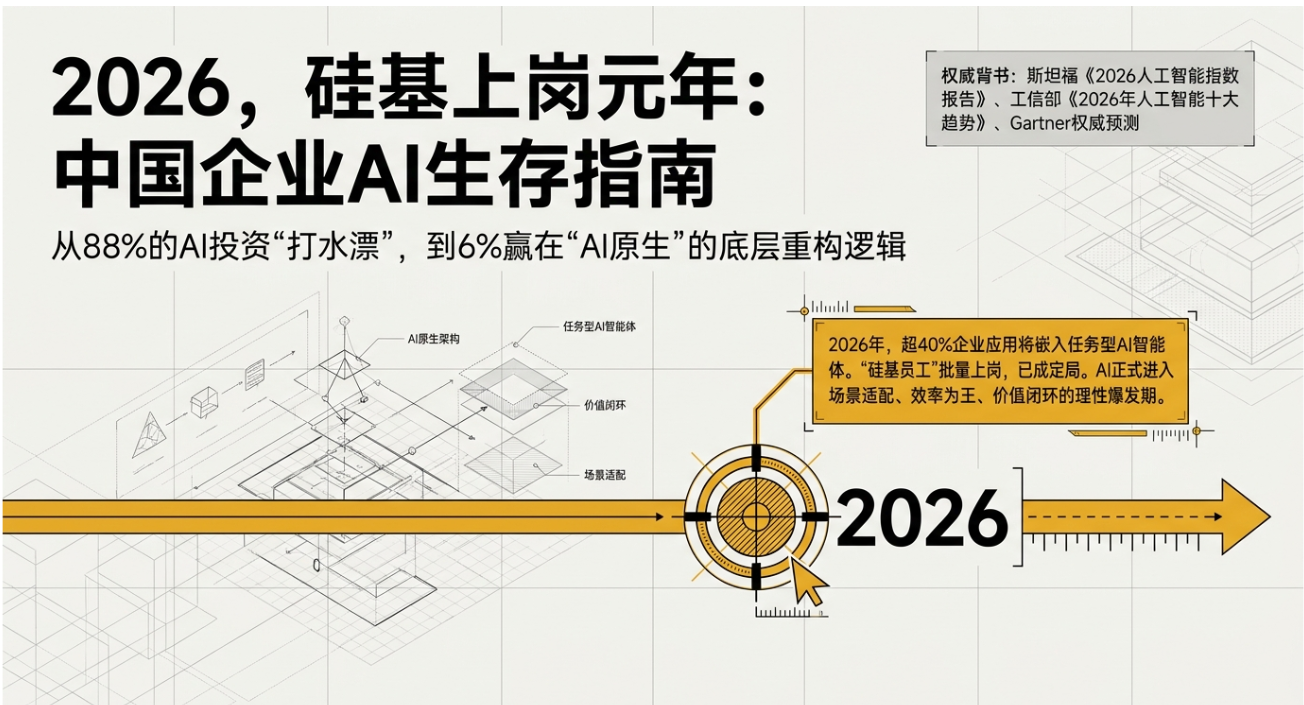
一、 现状诊断:传统“AI+CRM”集成模式的技术瓶颈
当前主流的CRM智能化路径,可称之为“AI+CRM”模式。其技术特征是在以流程管理和数据记录为核心的传统CRM单体或微服务架构上,通过API集成外部AI能力。这种模式在工程层面常遇到以下瓶颈:
1. 架构层面的“功能孤岛”问题
从架构上看,AI能力(如一个预测微服务、一个对话机器人)通常作为独立的服务模块,通过RESTful API或RPC与核心CRM业务模块通信。这种“中心化业务逻辑+外围智能服务”的架构,导致:
- 流程断裂:智能功能与核心业务流程(如从线索到回款的L2C流程)耦合度低,用户需主动跳出主工作流调用AI,体验割裂。
- 上下文丢失:AI服务在单次API调用中难以获取完整的、动态的业务会话上下文,影响判断准确性。
2. 数据层面的“管道与质量”挑战
AI模型的效果严重依赖数据质量和广度。在集成模式下:
- 数据管道复杂:为训练或推理一个销售预测模型,需要从CRM、ERP、客服系统等多个独立数据源进行ETL,实时性差、维护成本高。
- 特征工程受限:模型通常只能使用CRM系统内有限的结构化字段,无法有效利用客户邮件、会议录音、合同文档等非结构化数据中的丰富语义信息,导致特征维度不足,模型性能天花板低。
3. 模型层面的“领域适应性”不足
直接调用通用大语言模型(LLM)接口处理业务请求,是常见但低效的做法。其问题在于:
- 缺乏领域知识:模型不理解企业特定的产品参数、行业术语、内部审批规则,输出结果业务针对性弱。
- 结果不可控:生成式模型的随机性可能导致在合同关键条款审查、报价单生成等场景输出不一致的结果,不符合企业级应用对确定性和可审计性的要求。
4. 运维与安全层面的“合规性风险”
- 部署模式僵化:公有云模型服务存在数据合规风险,而私有化部署和精调大型模型对多数团队而言在资源、技术上挑战巨大。
- 监控调试困难:AI模块作为“黑盒”集成,一旦出现效果下滑或偏差,定位问题涉及从数据、特征到模型的多层排查,运维复杂度高。
二、 范式演进:“AI原生CRM”的架构理念与技术内核
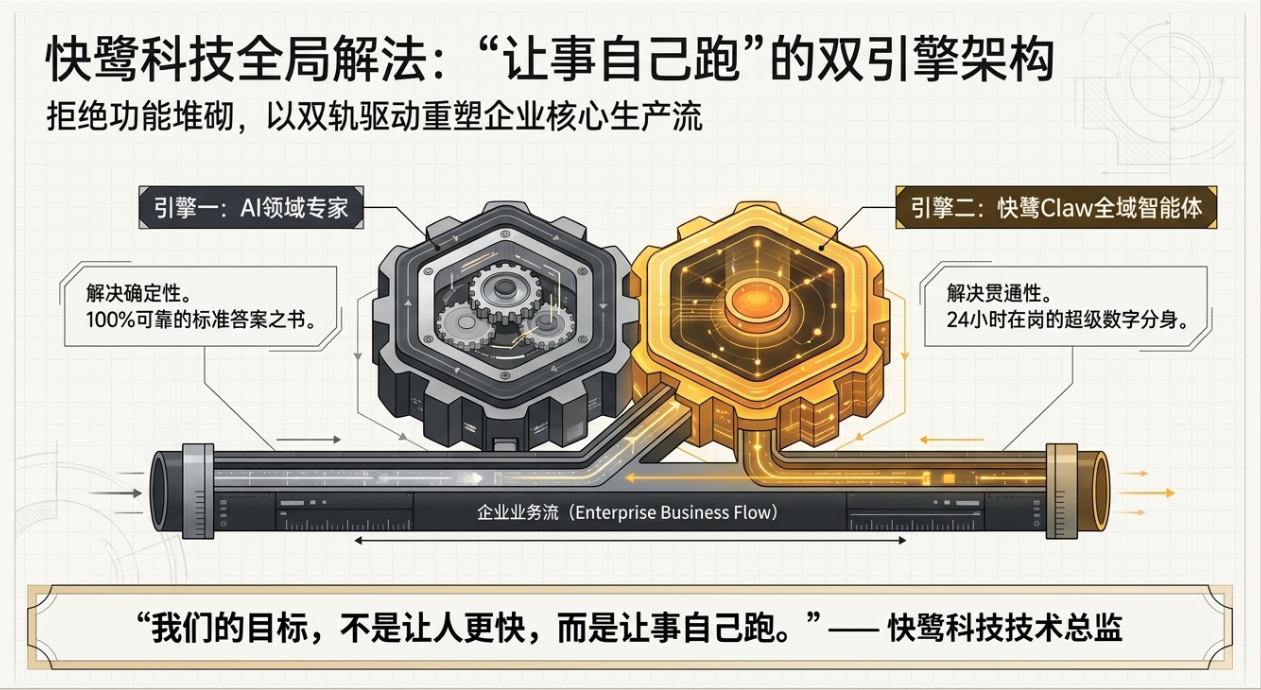
“AI原生”并非简单的功能增强,而是指在系统设计的初始阶段,就将AI作为核心业务逻辑的承载者和驱动者。其技术目标是从“记录流程”转向“自动化执行流程”。
我们可以将其核心架构理念归纳为:“以智能体(Agent)为执行单元,以工作流引擎为编排核心,以统一数据平台为支撑”。
- 传统“AI+CRM”架构:
[CRM Core] <-- API Call --> [AI Service],AI是服务于主流程的“外挂组件”。 - “AI原生CRM”架构:
[Orchestrator] --> [Agent A] --> [Agent B] --> [CRM Data Layer],AI智能体是执行业务逻辑的“原生细胞”,CRM数据层是状态持久化和知识存储的后端。
例如,在快鹭提出的框架中,“AI领域专家”可被视为一个技能确定、结果可追溯的专用智能体,而“全域智能体”则是一个具备任务规划与工具调用能力的元智能体。整个系统更像一个由多种智能体协同工作的操作系统。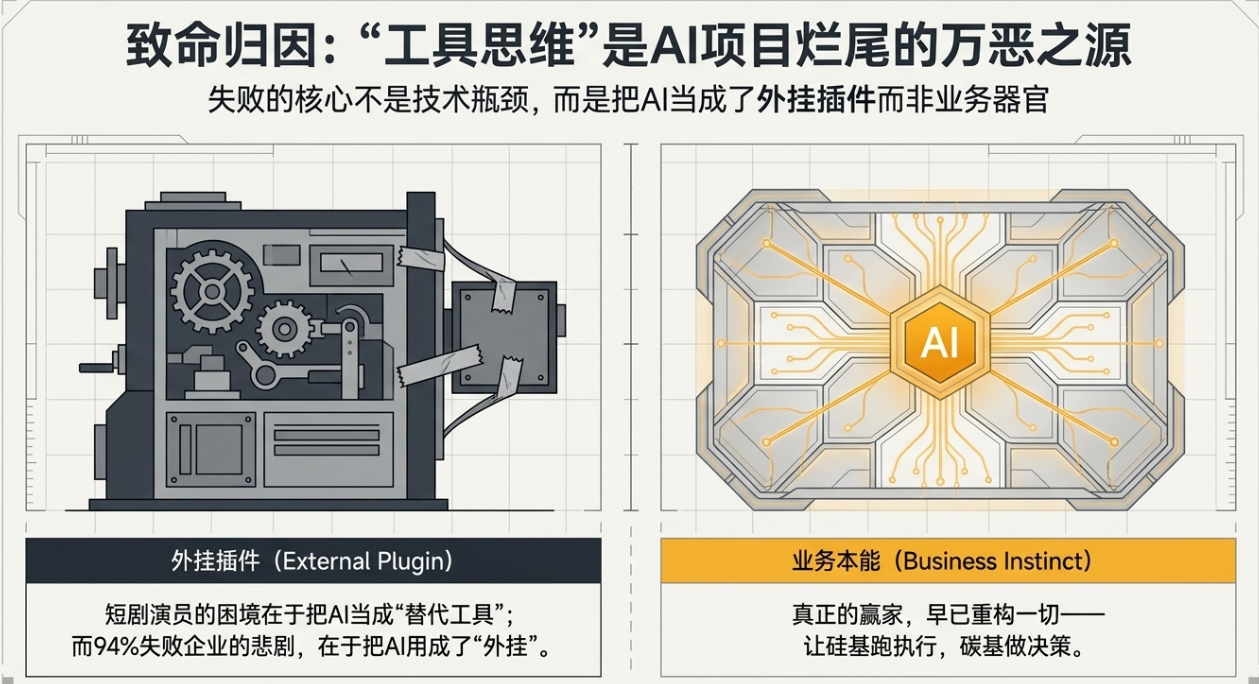
三、 关键技术实现路径探讨
构建此类系统,以下几个技术方向是关键:
1. 架构设计:面向智能体的松耦合架构
建议采用事件驱动的微服务架构,其中每个核心业务能力由一个或多个“智能体”微服务实现。例如:
Lead-Qualification-Agent:专司线索评分与分类,集成RAG(检索增强生成)从知识库获取产品匹配度信息。Contract-Review-Agent:专司合同比对,内置规则引擎与文档解析模型。- 一个中央的
Workflow-Orchestrator负责根据业务场景(如“新线索进入”)编排这些智能体的执行顺序与数据传递。
2. 数据底座:构建实时客户数据管道与向量知识库
- 统一数据管道:利用CDC(变更数据捕获)和流处理技术(如Apache Kafka + Flink),构建实时、统一的企业客户数据管道,为各智能体提供低延迟、一致的数据视图。
- 向量知识库:将产品文档、最佳实践、历史成单案例等非结构化知识进行嵌入(Embedding),存入向量数据库(如Milvus, Pinecone),为智能体提供基于语义检索的上下文增强能力。
3. 模型策略:混合模型与工程化治理
- 领域模型精调:在通用基座模型上,使用企业独有的对话、文档、代码数据进行有监督精调(SFT),得到领域适应模型,这是解决“懂业务”问题的关键。
- 小模型协同:对于价格预测、流失预警等任务,继续使用特征明确、可解释性强的传统机器学习模型(如LightGBM),与生成式模型形成互补。
- 模型治理:建立完整的MLOps流水线,涵盖从数据版本控制、模型训练、评估、注册到线上监控、A/B测试的全生命周期管理。
4. 安全与部署:全栈可控的私有化方案
企业级应用必须支持完全私有化部署,这意味着:
- 模型层面:提供可在企业内部环境部署的精调后模型,支持增量更新。
- 应用层面:提供容器化(Docker/K8s)的完整应用部署包。
- 数据层面:确保训练、推理全链路数据不出私有环境,并提供完善的访问审计日志。
四、 总结与展望
短剧行业的自动化替代,展示了AI在封闭、明确场景下的工程化成功。而企业CRM的智能化困境,则揭示了在开放、复杂业务系统中深度集成AI的艰巨性——这本质上是一个复杂的系统重构工程,而非单纯的技术集成。
“AI原生”路径的提出,其技术实质是承认AI(特别是大模型和智能体)已成为一种新型的计算范式,并以此范式为指导,重新设计应用架构、数据流和交互模式。它要求开发团队具备跨领域的技能,包括软件工程、数据工程、机器学习以及特定的业务知识。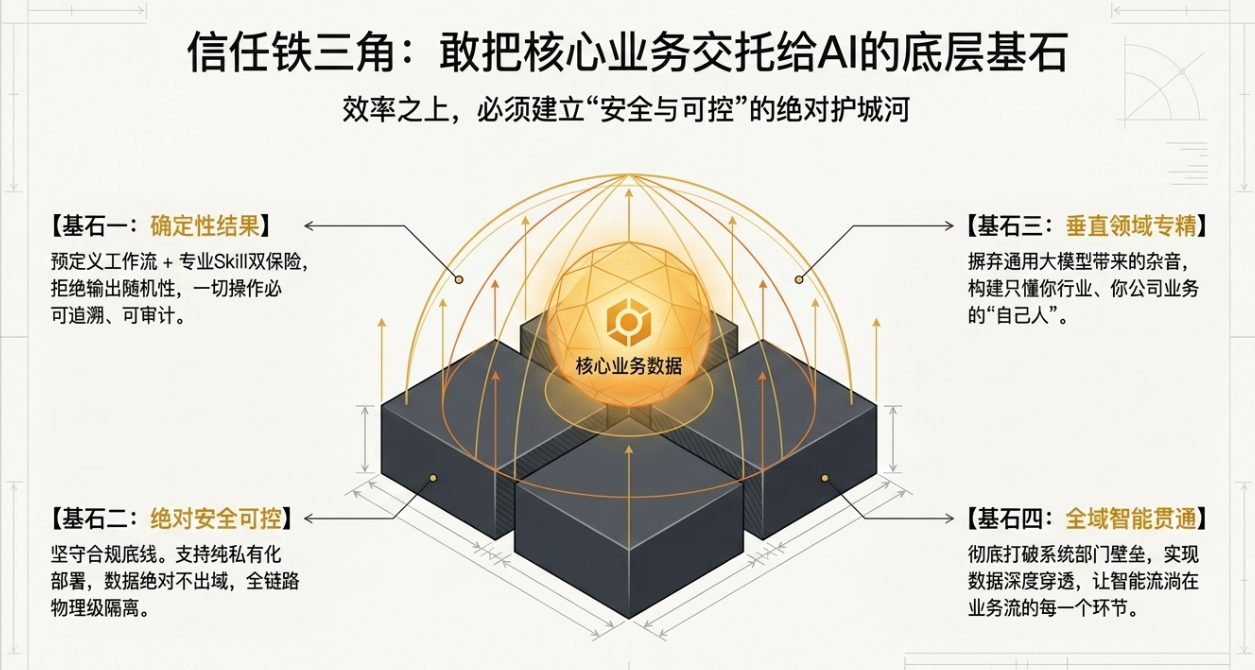
对于技术人员和架构师而言,在评估或设计2026年之后的智能业务系统时,关注点应从“是否集成了AI”转向“架构是否以智能体为中心、数据是否全域实时流通、模型是否领域深度适配、部署是否全栈安全可控”。这条路线上仍有大量工程挑战待解,如智能体的可靠编排、长周期任务的状态管理、复杂人机交互的设计等,但它代表了将AI价值从“局部增效”推向“全局重构”的必然技术方向。
讨论: 在您看来,实现“AI原生”业务系统的最大技术挑战是智能体的稳定性与可靠性,还是多源异构数据的实时融合与治理?或者是其他工程化难题?欢迎在评论区分享您的见解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)