基于 YOLOv10 实现工业缺陷检测:从环境配置到模型部署全解析
随着计算机视觉技术的飞速发展,目标检测算法在工业质检领域的应用愈发广泛。YOLO(You Only Look Once)系列算法凭借其高效的端到端检测能力,成为实时目标检测的主流选择。YOLOv10 作为该系列的最新版本,在检测精度、速度和模型轻量化方面均有显著提升,尤其适合工业场景下的缺陷检测需求。本文将以工业零件缺陷检测为例,从数据集配置、模型训练、推理部署三个维度,详细讲解如何基于 YOLOv10 实现完整的目标检测流程,帮助开发者快速上手并落地 YOLOv10 项目。
一、YOLOv10 核心优势与适用场景
1.1 YOLOv10 的技术升级
YOLOv10 在 YOLOv8 的基础上进行了多项关键优化:
- 轻量化架构设计:通过深度(depth)、宽度(width)等缩放系数(如 n 版本的 [0.33, 0.25, 1024])平衡模型大小与性能,满足边缘设备部署需求;
- 创新模块引入:整合 SCDown(空间通道下采样)、PSA(金字塔自注意力)、C2fCIB 等模块,提升特征提取效率和多尺度目标检测能力;
- 检测头优化:采用 v10Detect 检测头,优化正负样本匹配策略,降低漏检和误检率。
1.2 工业缺陷检测适配性
工业零件缺陷检测对实时性和精度要求严苛:生产线检测需毫秒级响应,且缺陷(如外框破损、固定板断裂)往往尺寸小、特征不明显。YOLOv10 的轻量化特性可满足实时检测需求,而其增强的特征提取能力能精准识别微小缺陷,是工业质检的理想选择。
二、项目环境与数据集配置
2.1 环境准备
YOLOv10 基于 Ultralytics 框架实现,需提前配置依赖环境:
# 安装核心依赖
pip install ultralytics opencv-python pyyaml glob2
Ultralytics 框架封装了 YOLOv10 的训练、推理接口,无需手动实现网络结构,大幅降低开发成本。
根据YOLOv10框架中,有个文件requirements.txt,其中有很多库以及对应版本
创建一个虚拟环境,前面博客有讲,根据pyCharm中的终端输入下面语句,安装库:
pip install -r requirements.txt如果不行:
pip install -r F:\前面加上绝对路径\requirements.txt其中,torch和torchvision库被注释掉了,由于这两个库太大,终端安装可能有冲突,所以要手动下载,我前面写的博客有下载教程
2.2 数据集结构设计
本文以工业零件缺陷检测为例,数据集包含三类目标:Pass(合格件)、Outer broken(外框破损)、Fixed plate broken(固定板断裂)。数据集目录结构如下:
dataset_part/
├── images/
│ ├── train/ # 训练集图片(.jpg/.bmp)
│ ├── val/ # 验证集图片
│ └── test/ # 测试集图片
├── labels/ # 标签文件(与图片同名,.txt格式,YOLO格式标注)
│ ├── train/
│ ├── val/
│ └── test/
├── mydata.yaml # 数据集配置文件
└── yolov10n.yaml # 模型配置文件
2.3 核心配置文件编写
(1)数据集配置文件(mydata.yaml)
该文件定义数据集路径、类别数和类别名称,是训练时数据加载的核心配置:
# 数据集根路径
path: F:\pyper\yolov10\yolov10-main\dataset_part
# 训练/验证/测试集图片路径(相对path的路径或绝对路径)
train: F:\pyper\yolov10\yolov10-main\dataset_part\images\train
val: F:\pyper\yolov10\yolov10-main\dataset_part\images\val
test: F:\pyper\yolov10\yolov10-main\dataset_part\images\test
# 类别名称(索引对应标注文件中的类别ID)
names:
0: Pass
1: Outer broken
2: Fixed plate broken
# 类别总数
nc: 3
关键说明:
path为数据集根目录,后续train/val/test路径可基于此使用相对路径(如train: images/train),提升配置文件可移植性;names的索引需与标注文件中的类别 ID 完全一致(如标注文件中 “1” 对应 “Outer broken”);nc需与类别数匹配,否则训练时会报维度不匹配错误。
(2)模型配置文件(yolov10n.yaml)
该文件定义 YOLOv10n 的网络结构和超参数,核心配置如下:
# 核心参数
nc: 3 # 需与mydata.yaml中的nc一致,否则模型输出维度不匹配
scales:
n: [0.33, 0.25, 1024] # n版本缩放系数,对应轻量化模型
# 骨干网络(backbone):特征提取
backbone:
- [-1, 1, Conv, [64, 3, 2]] # 卷积层,输出64通道,3x3卷积,步长2
- [-1, 1, Conv, [128, 3, 2]]
- [-1, 3, C2f, [128, True]] # C2f模块,增强特征复用
- [-1, 1, Conv, [256, 3, 2]]
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 空间通道下采样,提升特征融合效率
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]]
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 空间金字塔池化,增强全局特征提取
- [-1, 1, PSA, [1024]] # 金字塔自注意力,聚焦关键特征
# 检测头(head):特征融合与预测
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 上采样,融合多尺度特征
- [[-1, 6], 1, Concat, [1]] # 拼接骨干网络P4层特征
- [-1, 3, C2f, [512]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # 拼接骨干网络P3层特征
- [-1, 3, C2f, [256]]
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]]
- [-1, 3, C2f, [512]]
- [-1, 1, SCDown, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]]
- [-1, 3, C2fCIB, [1024, True, True]] # 增强型C2f模块,提升检测精度
- [[16, 19, 22], 1, v10Detect, [nc]] # 检测头,输出nc类目标的边界框和置信度
关键说明:
nc必须与数据集类别数一致,否则模型输出层维度与标签不匹配;- 骨干网络的 SCDown、PSA 模块是 YOLOv10 的核心创新,无需手动修改,仅需根据类别数调整
nc; - 不同版本(n/s/m/l/x)的模型仅需修改
scales参数,其余结构通用。
三、YOLOv10 模型训练
3.1 训练脚本编写(train1.py)
基于 Ultralytics 的 YOLO 类,可快速实现模型训练,核心代码如下:
from ultralytics import YOLO
if __name__ == '__main__':
# 加载YOLOv10n模型配置文件,初始化模型
model = YOLO(r'F:\pyper\yolov10\yolov10-main\dataset_part\yolov10n.yaml')
# 启动训练
model.train(
data=r'F:\pyper\yolov10\yolov10-main\dataset_part\mydata.yaml', # 数据集配置文件路径
lr0=0.001, # 初始学习率
epochs=3, # 训练轮数(实际场景建议设为100-300)
batch=4 # 批次大小(根据GPU显存调整,显存不足可设为2或1)
)
3.2 训练参数详解
data:指定数据集配置文件路径,是训练的核心参数;lr0:初始学习率,YOLOv10 建议设置为 0.01(小批量数据可适当降低至 0.001);epochs:训练轮数,需根据数据集大小调整(本文示例设为 3 仅作演示,实际需训练至损失收敛);batch:批次大小,需匹配 GPU 显存(如 RTX 3060 12G 可设为 8-16,显存不足可启用batch=-1自动适配);- 其他可选参数:
imgsz=640(输入图片尺寸)、weight_decay=0.0005(权重衰减,防止过拟合)、device=0(指定 GPU 设备)等。
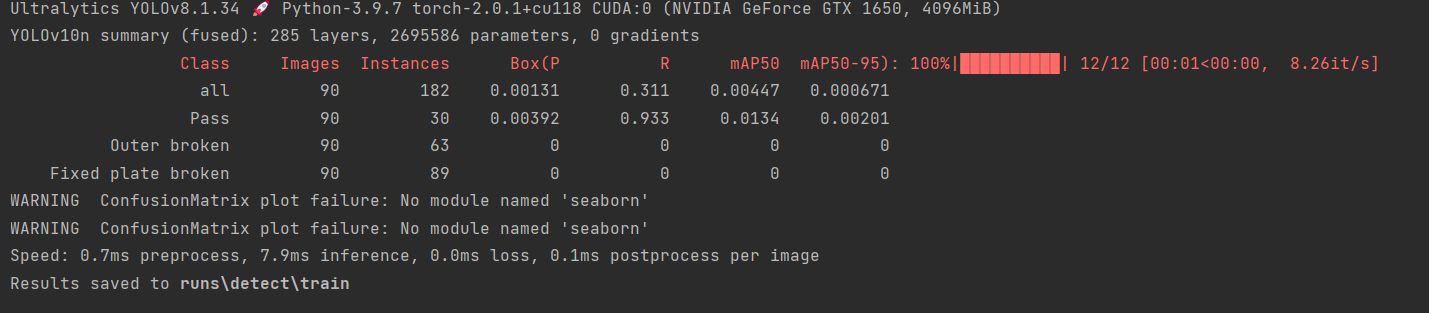
3.3 训练过程与结果分析
训练启动后,Ultralytics 框架会自动完成以下流程:
- 加载数据集并解析标注文件;
- 初始化 YOLOv10 网络权重;
- 按批次训练,输出每轮的损失值(box_loss/obj_loss/cls_loss);
- 每轮验证集评估,输出 mAP@0.5、mAP@0.5:0.95 等指标;
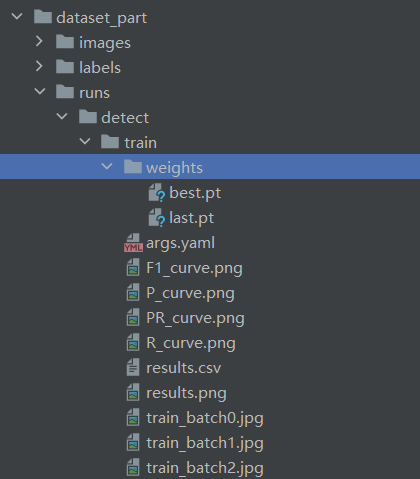
- 保存最优权重(best.pt)和最后一轮权重(last.pt)至
runs/detect/train/weights/目录。
关键指标解读:
- mAP@0.5:IoU 阈值 0.5 时的平均精度,越高表示检测精度越好;
- box_loss:边界框回归损失,越低表示边界框预测越精准;
- cls_loss:分类损失,越低表示类别预测越准确。
四、模型推理与部署
4.1 推理脚本编写(predict.py)
训练完成后,加载最优权重(best.pt)实现图片、批量图片、视频的缺陷检测,核心代码如下:
import glob
import os
import cv2
import sys
# 添加YOLOv10主目录到系统路径,确保模块可导入
sys.path.insert(0, r'F:\pyper\yolov10\yolov10-main')
from ultralytics import YOLO
# 加载训练好的最优模型权重
model = YOLO(r'F:\pyper\yolov10\yolov10-main\dataset_part\runs\detect\train\weights\best.pt')
# 单张图片检测
def image_load(image_path):
# 读取图片
frame = cv2.imread(image_path)
# 模型推理
res = model.predict(frame)
# 绘制检测框和标签
ann = res[0].plot()
# 显示检测结果
cv2.imshow('yolov10_image', ann)
cv2.waitKey(0)
# 解析检测结果
boxes = res[0].boxes
if boxes is not None:
# 边界框坐标(xyxy格式:x1,y1,x2,y2)
xyxy = boxes.xyxy.cpu().numpy()
# 置信度
conf = boxes.conf.cpu().numpy()
# 类别ID
cls = boxes.cls.cpu().numpy()
print("检测结果:边界框=", xyxy, "置信度=", conf, "类别ID=", cls)
# 批量图片检测(保存结果)
def images_load(images_path):
# 获取目录下所有jpg图片
imgs = glob.glob(os.path.join(images_path, '*.jpg'))
for img in imgs:
# 推理并保存检测结果(默认保存至runs/detect/predict)
model.predict(img, save=True)
# 视频实时检测
def video_load(video_path):
# 打开视频文件/摄像头(0表示摄像头)
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if ret:
# 模型推理
res = model.predict(frame)
# 绘制检测框
ann = res[0].plot()
# 显示视频流
cv2.imshow('yolov10_video', ann)
# 按ESC键退出
if cv2.waitKey(1) == 27:
break
else:
break
# 释放资源
cv2.destroyAllWindows()
cap.release()
if __name__ == '__main__':
# 测试单张图片检测
image_load(r'F:\pyper\yolov10\yolov10-main\dataset_part\images\train\c91.bmp')
# 批量图片检测示例
# images_load(r'F:\pyper\yolov10\yolov10-main\dataset_part\images\test')
# 视频检测示例
# video_load(r'F:\pyper\yolov10\yolov10-main\test_video.mp4')


4.2 推理功能详解
(1)单张图片检测
cv2.imread读取图片,支持 bmp/jpg/png 等格式;model.predict(frame)执行推理,返回结果包含边界框、置信度、类别等信息;res[0].plot()自动绘制检测框和标签,便于可视化;- 解析
boxes对象可获取原始检测数据,用于后续业务逻辑(如缺陷判定、报表生成)。
(2)批量图片检测
通过glob遍历指定目录下的所有图片,调用model.predict(img, save=True)自动保存检测结果至runs/detect/predict目录,适合批量质检场景。
(3)视频实时检测
通过cv2.VideoCapture读取视频流,逐帧推理并显示检测结果,满足生产线实时检测需求。cv2.waitKey(1)控制帧速率,确保视频流畅播放。
4.3 部署优化建议
(1)模型轻量化
- 导出 ONNX/TensorRT 格式:
model.export(format='onnx'),通过 TensorRT 加速推理,提升检测速度; - 量化模型:使用 INT8 量化降低模型精度,减小模型体积并提升推理速度(需牺牲少量精度)。
(2)推理加速
- 设置
model.predict(imgsz=640, conf=0.5),降低输入尺寸或提高置信度阈值,减少推理计算量; - 启用多线程 / 多进程处理视频流,提升并发检测能力。
(3)工业场景适配
- 结合硬件触发(如相机拍照信号),实现自动检测;
- 将检测结果接入 MES 系统,生成缺陷统计报表,助力生产优化。
五、常见问题与解决方案
5.1 训练报错
- 维度不匹配:检查
mydata.yaml和yolov10n.yaml中的nc是否一致; - 显存不足:降低
batch大小,或启用imgsz=480减小输入尺寸; - 标注文件错误:确保标注文件格式为 YOLO 格式(class_id x_center y_center width height),且类别 ID 与
names索引一致。
5.2 推理精度低
- 增加训练轮数,或使用更大的数据集(如数据增强:翻转、裁剪、亮度调整);
- 调整
conf阈值(如设为 0.3),降低漏检率; - 优化标注质量,确保标注框准确覆盖缺陷区域。
5.3 推理速度慢
- 导出 ONNX/TensorRT 格式,利用 GPU 加速;
- 关闭可视化(
plot=False),减少 CPU 计算; - 使用轻量化模型(如 YOLOv10n),而非 YOLOv10l/x。
六、总结与展望
本文以工业零件缺陷检测为例,完整讲解了 YOLOv10 从数据集配置、模型训练到推理部署的全流程。YOLOv10 凭借其轻量化和高精度的特性,在工业质检场景中展现出显著优势。通过 Ultralytics 框架的封装,开发者无需深入理解网络底层实现,即可快速落地目标检测项目。
未来可进一步优化方向:
- 数据增强:引入 Mosaic、MixUp 等增强策略,提升模型泛化能力;
- 半监督学习:利用未标注数据提升模型性能,降低标注成本;
- 边缘部署:将模型部署至嵌入式设备(如 Jetson Nano),实现端侧实时检测;
- 多任务融合:结合分类、分割任务,实现缺陷的精准定位与类型判定。
YOLOv10 的出现为实时目标检测带来了新的可能,在工业质检、智能交通、安防监控等领域具有广阔的应用前景。开发者可基于本文的流程,结合自身业务场景快速适配,实现算法的落地应用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)