大模型推理服务高并发压测方法论:从指标定义到实测工具链
为什么不能信标称数据?
LLM行业的“峰值宣传”和“高压真相”之间,从来都隔着一道巨大的鸿沟。当业务真正接入生产环境,50 甚至 100 并发跑起来的时候,现实往往会给一记响亮的耳光:单并发下跑出 200 Tokens/s 的服务,到了高压场景可能直接跌掉一半,伴随大量超时。标称数据大多是理想实验室环境下的“峰值”,而非高压场景下的“均值”。对于我们这些追求稳定性的后端开发者来说,选型如果只看 PPT,无异于把系统稳定性交给运气。
为了帮大家避坑,本文系统梳理一套可复现的大模型推理压测方法论,并以智谱最新旗舰模型GLM-5.1作为核心参考对象,贯穿全文。
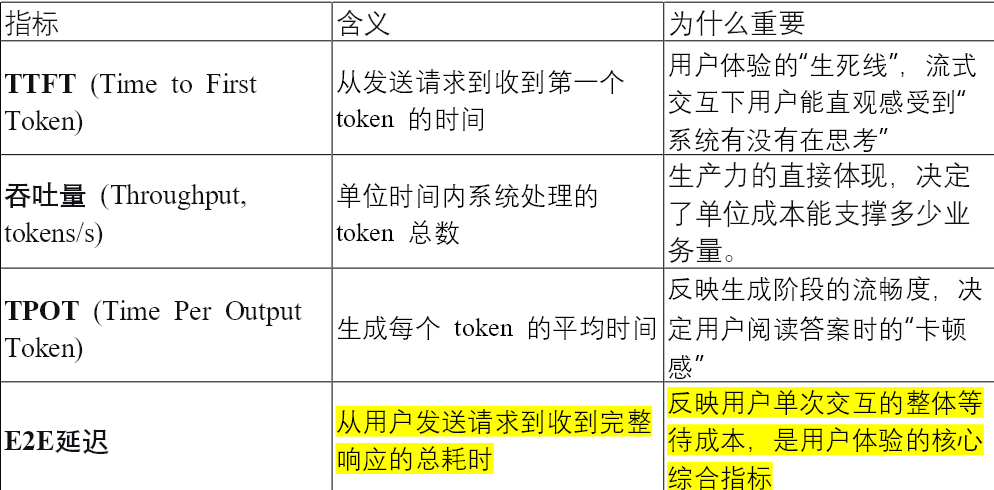
一、大模型压测四大核心指标
在开始压测之前,我们首先需要弄清楚:大模型推理服务到底该看哪些指标?传统的 QPS、成功率已经不够用了。大模型专属的“四大金刚”指标是以下四个:
二、第三方评测平台:如何看数据、避坑
目前已涌现出不少专业的AI模型及API评测平台,开发者可根据自身需求和数据来源进行交叉参考。开发者可借助它们获取大模型的关键数据,从而规避选型中的各种“坑”。比如,像OpenRouter、AI Ping等都是比较知名的第三方评测平台,这些平台虽各有侧重,但都提供了非常有价值的参考。
第三方评测平台一般汇总了主流国产模型(如通义千问、DeepSeek、智谱 GLM、Kimi、MiniMax、腾讯混元等)的调用量、价格、延迟及稳定性等关键数据,并提供了同一模型在不同供应商之间的价格差异(有时相差20%–30%)以及基于真实请求的性能统计。同时,平台还能从各厂商MaaS服务进行实时探测,呈现 P90 延迟和趋势图,帮助开发者发现平台在不同时段的性能波动。
借助数据,你可以快速对比模型的成本与效率、筛选候选平台,并结合实际业务进行压测验证,最终择优而选
三、自测工具链与完整方法
3.1 工具选型

3.2 标准化压测流程(避免数据造假)
- 固定测试参数
- ompt 长度:取你业务真实分布(例如 80% 在 512–1024 tokens,20% 在 4096+)。如果做不到,至少固定一个典型值。
- 输出长度:同样固定(例如 512 tokens),或使用max_tokens限制。
- 模型统一:如GLM-5.1。
- 并发梯度:1 → 20 → 50 → 100 → 150(或直到失败率 >1%)。
- 每阶段运行时长:至少 10 分钟,去掉前 2 分钟预热数据。
- 记录关键字段
- 每次请求的:TTFT、端到端延迟、生成的 token 数、是否报错。
- 计算 P50/P90/P99 延迟、吞吐量、失败率。
- 可复现性要求
- 写明:压测机规格(CPU/内存/带宽)、地域、网络延迟(ping 各平台 API 地址)。
- 提供脚本核心片段(附录或 GitHub gist)。
四、实测数据参考——引用 AI Ping 平台公开评测结果
为了帮助大家理解这套方法论在实际场景中的应用,我们以智谱旗舰模型GLM-5.1为例进行数据采集和参考说明。
4.1 模型简介
GLM-5.1 是智谱 AI 于 2026 年 4 月 8 日正式发布的新一代开源模型,被誉为目前开源模型中 SWE-bench 榜单表现最强的模型之一,总参数量高达 7440 亿,采用 MoE 架构,上下文窗口达到 200K Token,支持最长 131K 输出 Token。在 SWE-bench Pro 基准测试中,GLM-5.1 超过 GPT-5.4、Claude Opus 4.6,刷新全球最佳成绩。
目前 GLM-5.1 已上线华为云、摩尔线程、昆仑芯、壁仞科技等多个平台。华为云昇腾平台通过系统级优化,已实现推理吞吐量 30% 的整体提升。
4.2 实测数据——引用 AI Ping 平台公开评测结果
为了客观反映 GLM-5.1 在不同服务商上的真实服务表现,以下直接引用AI Ping(aiping.cn)的公开评测数据
数据引用说明:
- 来源:AI Ping(aiping.cn)公开评测数据
- 有效期:以下数据基于 AI Ping 平台“近7天”监测结果(快照时间2025年5月15日6时)。AI Ping 数据持续更新,建议读者访问平台获取实时数据
- 评测方法论:AI Ping 采用 7×24 小时持续匿名探测,以普通开发者身份模拟真实使用场景,覆盖不同时段(含工作日/周末、高峰/低谷),从真实用户视角出发,遵循同模型、同输入、同时段的对比原则,通过长周期、高频率的数据监测,有效平滑偶然波动。
- 数据维度:包括 P90 延迟、吞吐量两个核心维度
以下是根据 AI Ping 公开数据整理的,在GLM-5.1模型上性能指标较为突出的五大服务商:
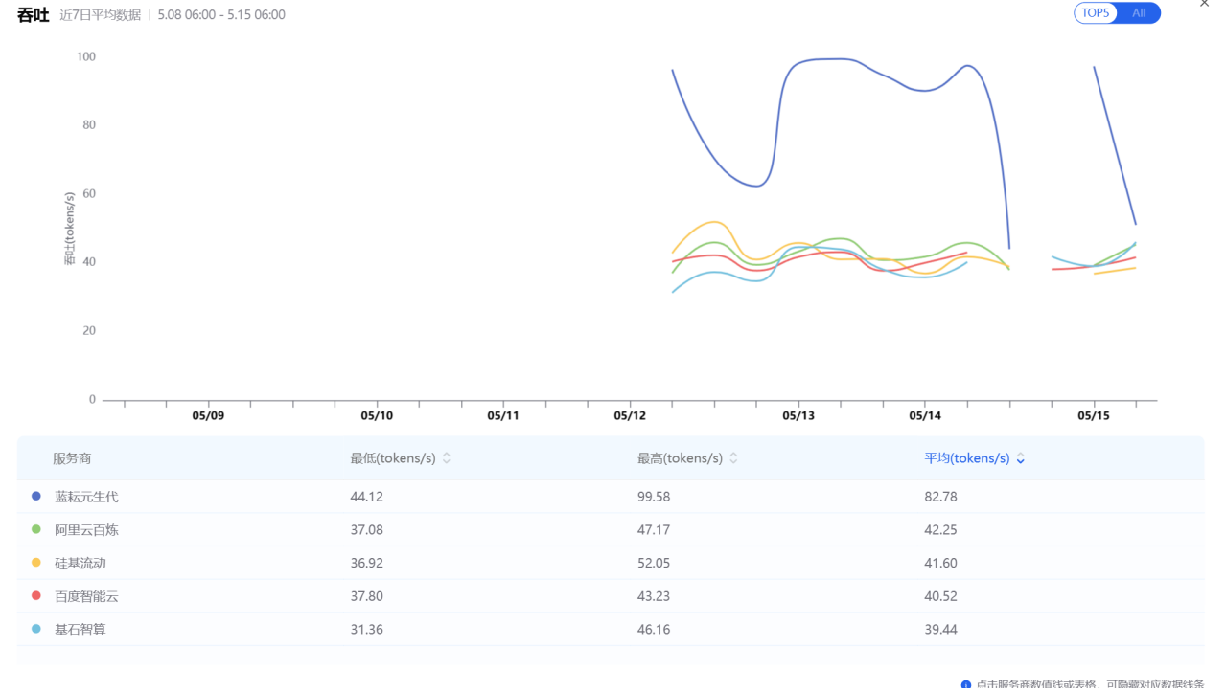
上图:2026年5月8日至15日,GLM-5.1模型吞吐量指标前五
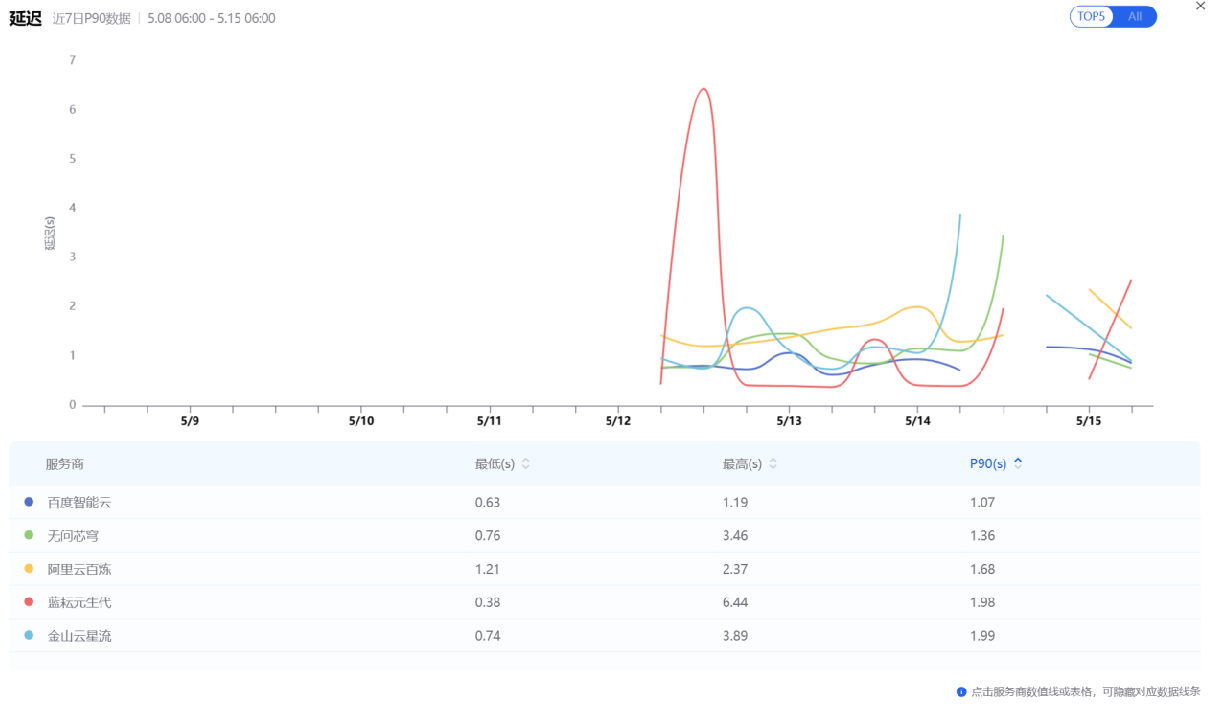
上图:2026年5月8日至15日,GLM-5.1模型P90延迟指标前五
为了更客观地对比不同 MaaS 平台在 GLM-5.1 模型上的真实表现,这里直接引用第三方基准测试平台AI Ping(aiping.cn)的公开评测数据。
4.2 数据说明
- 百度智能云:延迟最低,波动最小,实时交互首选
P90 延迟仅1.07s,在五大厂商中排名第一,且最低延迟 0.63s、最高 1.19s,波动范围极窄(0.56s),稳定性优异。适合对首字响应速度和一致性要求极高的实时对话场景。
- 蓝耘元生代:吞吐量断层领先,但偶发高延迟波动
平均吞吐量 82.78 tokens/s,约为其他厂商的2 倍,高吞吐优势明显。在观察中可以看到蓝耘平时比较稳定,但曾经出现过一次高于 6 秒的 P90 延迟波动,这种偶发高延迟需要通过实测验证其对业务的影响。适合对吞吐量有极致要求、且能容忍极小概率延迟抖动的批量推理任务。
- 阿里云百炼:延迟与吞吐的最佳平衡者
P90 延迟 1.68s,吞吐量 42.25 tokens/s,两者均处于中上水平。相比百度(延迟优但吞吐 40.52)、蓝耘(吞吐优但延迟波动大),阿里云百炼没有明显短板,适合对延迟和吞吐都有一定要求、希望获得稳定均衡表现的主流业务。
- 硅基流动与智谱:各有取舍
硅基流动吞吐 41.60 tokens/s,与阿里云、百度接近,但 P90 延迟 2.86s 相对较高;智谱吞吐最低(33.96),延迟 2.56s。两者均适合对成本或特定生态有偏好的场景,但性能上不占优势。
4.3 数据使用建议与局限说明
1, 关注“近 7 天”数据:建议优先查看平台“近 7 天”时间段的数据,可以有效平滑偶发性的“尖峰”波动,比瞬时快照更具参考价值。
- 按场景筛选:实时对话场景关注低 P90 延迟,批量处理场景关注高吞吐量。AI Ping 的“性能坐标图”可以帮你直观对比不同供应商在延迟—吞吐维度上的表现差异。
- 自行验证:评测平台的数据是重要的初筛参考,但最终选型必须用你自己的业务数据、真实输入长度和目标并发区间进行实际压测验证。以下是一个快速验证脚本示例:
# 快速验证 GLM-5.1 API 性能的 asyncio 脚本片段
import asyncio
import aiohttp
import time
async def test_glm_api(session, url, headers, prompt):
payload = {
"model": "glm-5.1",
"messages": [{"role": "user", "content": prompt}],
"stream": True,
"max_tokens": 512
}
start = time.perf_counter()
first_token_time = None
total_tokens = 0
async with session.post(url, json=payload, headers=headers) as resp:
async for line in resp.content:
if line.startswith(b"data: "):
if first_token_time is None:
first_token_time = time.perf_counter() - start
total_tokens += 1
end = time.perf_counter()
return {"ttft": first_token_time, "total_time": end - start, "tokens": total_tokens}
- 数据局限性说明:AI Ping 的测试以“单次请求”为主,其公开数据的地理位置信息暂无法确定。建议在使用时结合自身的网络环境和业务场景进行二次验证
- 访问实时数据:欢迎访问AI Ping官网(https://aiping.cn/),使用平台的实时性能排行榜、性能坐标图和近 7 天趋势图等工具,以获取最新、最匹配自身需求的 GLM-5.1 性能数据。
最后:压测建议总结
- 自己压测是唯一真理
无论 AI Ping 数据多么漂亮、厂商 PPT 多么诱人,签约前务必用自己的业务数据、真实输入长度和目标并发区间跑一轮压力测试。评测平台只能帮你筛选候选名单,不能替代你的生产验证。
- 盯紧“性能衰减率”,别被低并发峰值迷惑
单并发下 200 tokens/s 毫无意义——重点看 50 并发、100 并发时的 P99 延迟和吞吐量相对于单并发的衰减倍数。衰减率越接近 1,系统在高压下才越“稳”。
- 主力 + 备份,永远留一手
没有哪个平台能保证全年无故障。建议至少接入两家服务商,日常流量跑主力,同时配置健康检查自动切换到备份。成本可控,稳定性翻倍。
数据来源说明:本文第四部分所引用的 GLM-5.1 性能数据,均来源于AI Ping(aiping.cn)公开评测平台,数据快照时间为2025 年 5 月 15 日 6:00(UTC+8)。
免责声明: 评测平台的数据受探测时间、网络环境、服务商调度策略等因素影响,存在一定的偶然波动。本文数据仅反映该快照时间点的实测结果,不构成对任何服务商服务质量的全时段承诺。建议读者结合自身业务场景进行独立压测验证,并以实际测试结果作为选型最终依据。数据实时更新,请访问 AI Ping 官网获取最新动态

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)