【三维重建】Scal3R:适用于大规模三维重建的可扩展测试时训练系统(CVPR 2026)

标题:《Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction》来源:浙江大学 ;Horizon Robotics ; 浙江实验室项目:https://zju3dv.github.io/scal3r.
目录标题
摘要
本文致力于解决从长视频序列中进行大规模三维场景重建的问题。近年来,前馈式重建模型通过直接从RGB图像中回归三维几何结构(无需显式的三维先验知识或几何约束),已展现出令人鼓舞的成果。然而,由于内存容量有限且难以有效捕捉全局上下文线索,这些方法在处理长序列时往往难以保持重建精度与一致性。相比之下,人类能够自然地利用对场景的整体理解来指导局部感知。
基于这一理念,我们提出了一种创新的神经全局上下文表示方法,该方法能高效压缩并保留长距离场景信息,使模型能够充分利用丰富的上下文线索,从而提升重建精度与一致性。该上下文表示通过一组轻量级神经子网络实现,这些子网络在测试时可通过自监督目标快速适应,显著提升了内存容量且未产生显著计算开销。在 KITTI Odometry[22]和Oxford Spires[70]等多个大规模基准数据集上的实验表明,我们的方法在处理超大规模场景时效果显著:不仅实现了领先的姿态精度和最先进的3D重建精度,同时保持了高效性。
一、预备知识
1.VGGT
VGGT 的核心是一个统一的 Transformer 模型 f f f。它的任务是输入一段观测同一 3D 场景的 RGB 图像序列,然后将每一个视频帧映射(预测)出对应的 3D 标注: f ( { I i } i = 1 N ) = { c i , D i , P i , T i } i = 1 N f(\{I_i\}_{i=1}^N) = \{\mathbf{c}_i, D_i, P_i, T_i\}_{i=1}^N f({Ii}i=1N)={ci,Di,Pi,Ti}i=1N输入为 * I = { I i ∈ R 3 × H × W ∣ i = 1 , … , N } \mathcal{I} = \{I_i \in \mathbb{R}^{3 \times H \times W} \mid i = 1, \dots, N\} I={Ii∈R3×H×W∣i=1,…,N}:包含 N N N 张空间分辨率为 H × W H \times W H×W 的 RGB 图像序列。输出(对每一帧 I i I_i Ii 预测四个维度): c i ∈ R 9 \mathbf{c}_i \in \mathbb{R}^9 ci∈R9:相机参数(包含内参和外参)。 D i ∈ R 1 × H × W D_i \in \mathbb{R}^{1 \times H \times W} Di∈R1×H×W:深度图(Depth map)。 P i ∈ R 3 × H × W P_i \in \mathbb{R}^{3 \times H \times W} Pi∈R3×H×W:点云(Point cloud)。 T i ∈ R C × H × W T_i \in \mathbb{R}^{C \times H \times W} Ti∈RC×H×W:用于点追踪(Point tracking)的特征网格(Feature grid)。
VGGT 网络架构由以下三个部分串联组成:
-
特征提取编码器 (DINOv2 Encoder):对输入图像进行“分块”(Patchfies)并提取特征,拼接成图像 Token 集合 F = ⋃ i = 1 N { F i ∣ F i ∈ R K × C } \mathcal{F} = \bigcup_{i=1}^N \{F_i \mid F_i \in \mathbb{R}^{K \times C}\} F=⋃i=1N{Fi∣Fi∈RK×C},其中 K K K 是每帧的 Token 数量。
-
注意力层堆栈 (24 Attention Layers),包含 24 层 帧内自注意力与全局帧间注意力。
-
多专用输出头 (Multiple Dedicated Output Heads),从上述多模态 Token 中,分别解码、还原并预测出最终需要的 4 种结果(即相机参数、深度图、点云和特征网格)。
2. Test-Time Training
传统方法局限:在处理一维序列 x t x_t xt(每个 token x t ∈ R d x_t \in \mathbb{R}^d xt∈Rd )时,Transformer的Softmax 注意力机制,计算复杂度是序列长度的平方级( O ( N 2 ) O(N^2) O(N2)),处理长序列时显存和算力开销巨大。传统 RNN 及其变体:为了降低复杂度,RNN 将历史序列上下文压缩到一个固定大小的隐状态(Hidden State) h t ∈ R d h_t \in \mathbb{R}^d ht∈Rd 中。其更新公式为: h t = σ ( θ s s h t − 1 + θ s x x t ) — (2) h_t = \sigma(\theta_{ss}h_{t-1} + \theta_{sx}x_t) \quad \text{--- (2)} ht=σ(θssht−1+θsxxt)— (2)这种压缩方式受到隐状态向量维度的严格限制(表示能力上限)。在处理长序列时,早期的信息会被不可避免地稀释和遗忘(信息降级)。
TTT 的核心原理。为了突破固定大小隐状态的容量限制,TTT 引入了快速权重(Fast Weights, 记为 W W W),包括两个层级的学习过程:
- 外循环(Outer Loop):负责训练主网络的静态参数(比如将输入 x t x_t xt 投影为 Query q q q、Key k k k、Value v v v 的投影矩阵),参数在大量训练数据上学习,负责维持模型稳定的泛化能力。
- 内循环(Inner Loop):在推理/测试阶段(Test-Time)动态运行。它维护一套快速不固定的权重 W W W,随着序列的读取不断进行自我更新,用来动态存储当前的上下文信息。
具体的,在获取当前 token 映射出的 q q q(查询)、 k k k(键)和 v v v(值)之后,TTT 在每个时间步执行以下两个关键操作:
-
- 更新 (Update)。利用当前的 k k k 和 v v v 来更新快速权重 W W W: W ← W − η ∇ W L ( f W ( k ) , v ) — (3) W \leftarrow W - \eta \nabla_W \mathcal{L}(f_W(k), v) \quad \text{--- (3)} W←W−η∇WL(fW(k),v)— (3)把当前的上下文当作一个“无标签的数据集”。模型构建了一个自监督的局部任务:用当前的权重网络 f W f_W fW 处理键 k k k,期望它的输出能尽可能逼近值 v v v。通过计算两者之间的损失 L \mathcal{L} L,并执行一步(或多步)梯度下降(学习率为 η \eta η),将当前的键值映射关系(Key-Value mapping)“写入”到权重 W W W 中。
-
- 应用 (Apply)。利用更新后的权重来生成当前时间步的输出: o = f W ( q ) — (4) o = f_W(q) \quad \text{--- (4)} o=fW(q)— (4)
二、算法介绍
1.痛点与分块策略 (Chunking Strategy)
由于 Transformer 注意力机制的计算复杂度,直接将原始的 VGGT 模型应用于大量的 RGB 图像序列( I \mathcal{I} I)是不可行的,VGGT-Long将长序列切分成重叠的“块”(Chunks),独立处理每个块然后再对齐结果。但这会导致模型丢失长程的上下文信息,并且容易在局部产生不一致的预测:
为了处理海量图像,输入序列 I \mathcal{I} I 被划分为 K K K 个有重叠的块,记作 { I k ∣ k = 1 , … , K } \{\mathcal{I}_k \mid k = 1, \dots, K\} {Ik∣k=1,…,K}。如果设 M M M 为每个块的大小(包含的图像数), O O O 为相邻块之间的重叠大小,那么第 k k k 个块 I k \mathcal{I}_k Ik 包含的图像序列为: { I ( k − 1 ) ( M − O ) + 1 , … , I ( k − 1 ) ( M − O ) + M } \{I_{(k-1)(M-O)+1}, \dots, I_{(k-1)(M-O)+M}\} {I(k−1)(M−O)+1,…,I(k−1)(M−O)+M}这些块会被分配到不同的 GPU 上并行处理,以此预测出相对应的相机参数 c k \mathbf{c}_k ck、深度图 D k D_k Dk 和点云 P k P_k Pk。
2. 核心创新:全局上下文记忆 (Global Context Memory, GCM)
整体模型依然是一个大型 Transformer,包含 DINOv2 编码器、交替的注意力层以及用于预测 3D 信息的多个输出头。受“测试时训练(Test-Time Training, TTT)”的启发,在模型中引入了 GCM 模块,参数由多个自适应记忆单元(AMUs)实现。这些 AMU 是轻量级的神经网络子网络,能够在推理阶段通过自监督更新进行快速适应。其被附加在“全局注意力层(Global Attention Layer)”之后,用于捕获并持久化存储长跨度的上下文信息。
假设 X k i \mathcal{X}_k^i Xki 表示第 k k k 个数据块在第 i i i 层全局注意力层的输出 Token:
GCM 的门控输出:通过一个可学习的门控向量 α ∈ R d \alpha \in \mathbb{R}^d α∈Rd 来平衡“提取到的长程记忆(GCM 的输出)”与“原始局部 Token”的相对贡献比例:
gate ( GCM , X k i ; α ) = α ⊗ GCM ( X k i ) + X k i — (5) \text{gate}(\text{GCM}, \mathcal{X}_k^i; \alpha) = \alpha \otimes \text{GCM}(\mathcal{X}_k^i) + \mathcal{X}_k^i \quad \text{--- (5)} gate(GCM,Xki;α)=α⊗GCM(Xki)+Xki— (5)
标准的交替注意力:GCM 之前,VGGT 的标准交替注意力:先做帧内注意力( fattn \text{fattn} fattn),再做帧间全局注意力( gattn \text{gattn} gattn),加上残差连接: X ˉ k i = gattn ( fattn ( X k i ) ) + X k i — (6) \bar{\mathcal{X}}_k^i = \text{gattn}(\text{fattn}(\mathcal{X}_k^i)) + \mathcal{X}_k^i \quad \text{--- (6)} Xˉki=gattn(fattn(Xki))+Xki— (6)
整合 GCM 后的全新公式 :将GCM的门控机制包裹在标准的帧间/帧内注意力操作之外,得到最终融合了长程记忆的 Token 更新公式:
X ˉ k i = gate ( GCM , gattn ( fattn ( X k i ) ) ; α ) + X k i — (7) \bar{\mathcal{X}}_k^i = \text{gate}(\text{GCM}, \text{gattn}(\text{fattn}(\mathcal{X}_k^i)); \alpha) + \mathcal{X}_k^i \quad \text{--- (7)} Xˉki=gate(GCM,gattn(fattn(Xki));α)+Xki— (7)
三、测试时训练 作为记忆
尽管可适应的神经网络子网络(AMUs)比传统的固定大小的 RNN 隐状态具有更大的记忆容量,现有的 TTT 通常采用细粒度、小批量(small-batch)的更新方式。这种频繁的微小更新严重阻碍了计算吞吐量,导致 GPU 利用率低下,从而限制了模型所能处理的最大序列长度。
方案1:按块更新机制 (Chunk-wise Update)
受 LaCT 模型的启发,将整个数据块(Chunk)中的所有 Token 视为一个单一的更新单元。输入第 k k k 个数据块的 Tokens X k ∈ R M × d \mathcal{X}_k \in \mathbb{R}^{M \times d} Xk∈RM×d 时( M M M 为块大小):
首先投影为键矩阵 K K K 和值矩阵 V V V(大小均为 R M × d \mathbb{R}^{M \times d} RM×d),这代表了当前的上下文。接着,通过按块更新(Chunk-wise update)操作,将这些上下文信息编码到 AMUs(权重 W W W)中: W ← W − ∇ W ∑ i = 1 M η i L ( f W ( k i ) , v i ) W \leftarrow W - \nabla_W \sum_{i=1}^M \eta_i \mathcal{L}(f_W(k_i), v_i) W←W−∇Wi=1∑MηiL(fW(ki),vi)自监督目标为标准的点积损失(Dot-product loss):
L ( f W ( K ) , V ) = ∑ i = 1 M − f W ( k i ) ⊤ v i ( 9 ) \mathcal{L}(f_W(K), V) = \sum_{i=1}^M -f_W(k_i)^\top v_i(9) L(fW(K),V)=i=1∑M−fW(ki)⊤vi(9)更新完成后,权重 W W W 就存储了当前块的上下文信息。随后,模型将查询矩阵 Q Q Q 输入更新后的网络 f W ( Q ) f_W(Q) fW(Q),以此产生最终的输出 Token。
方案2:局上下文同步 (Global Context Synchronization, GCS)
当前GCM 模块捕获的上下文仅局限于单个数据块内部,缺乏序列级别的全局视角。 作者将长序列划分到不同 GPU 上处理的过程视为一种“上下文并行”。每个 GPU 负责一部分数据,并计算其本地的 AMU 更新梯度,然后对所有 GPU 上计算出的梯度进行求和,然后再广播给每一个 GPU。同步后的全局梯度 g g g 表示为( K K K 是切分总块数,对应 GPU 的数量, M M M 是每个块的大小): g = ∇ W ∑ j = 1 K ∑ i = 1 M η i L i = ∑ j = 1 K ∇ W ∑ i = 1 M η i L i g = \nabla_W \sum_{j=1}^K \sum_{i=1}^M \eta_i \mathcal{L}_i = \sum_{j=1}^K \nabla_W \sum_{i=1}^M \eta_i \mathcal{L}_i g=∇Wj=1∑Ki=1∑MηiLi=j=1∑K∇Wi=1∑MηiLi
工程实现:利用 PyTorch 的 all-reduce 通信原语,模型能够以极低的通信开销高效地将聚合后的梯度 g g g 应用到所有 GPU 的 W W W 上。
实验
1.长序列位姿精度
数据集与评估指标。Virtual KITTI 是一个领域内合成数据集,包含5个涵盖多种天气与光照条件的序列;另外两个则是领域外的真实世界基准数据集: KITTI Odometry 包含11个来自不同长度城市驾驶场景的序列;Oxford Spires 包含6个涉及室内外场景中复杂环形闭合路径的序列。报告了与真实轨迹对齐后的绝对轨迹误差(ATE)、相对旋转误差(RRE)和相对平移误差(RTE)。
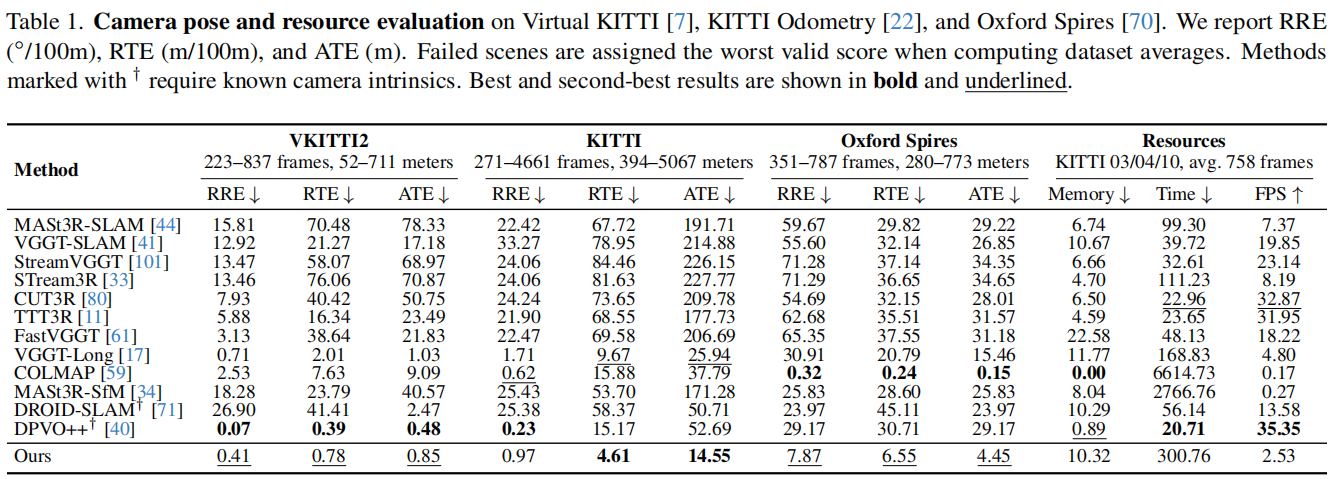
2.几何精度
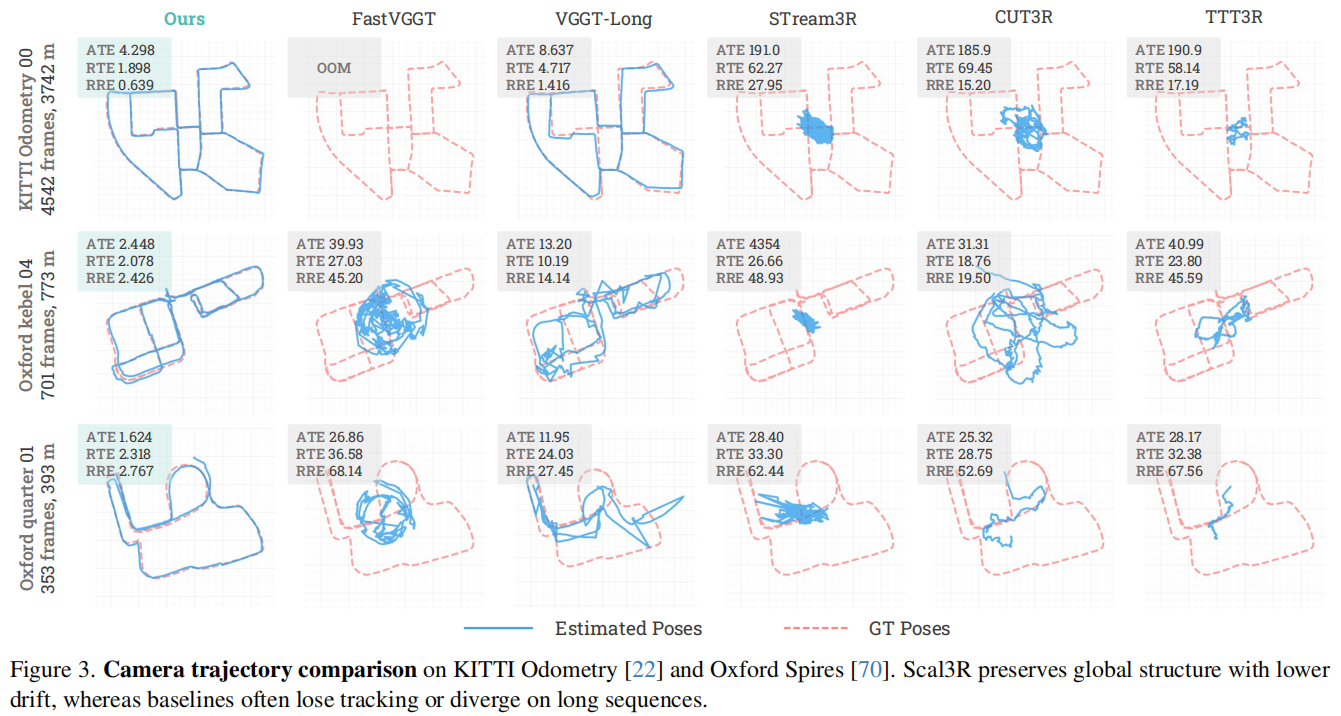
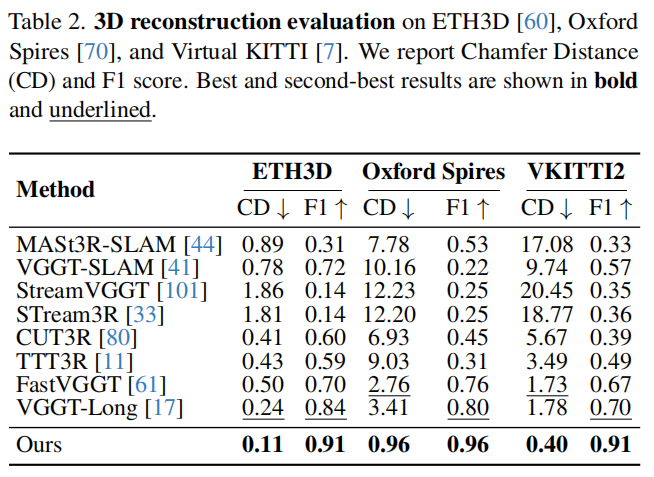
数据集与评估指标。在ETH3D、Virtual KITTI 和Oxford Spires数据集上分别评估了三维重建性能,对应场景数量分别为11个、50个和6个。这些数据集涵盖了具有不同尺度和复杂度的多样化室内外环境。在使用Umeyama算法[74]将预测的姿态和深度图与真实数据对齐后,我们报告了基于这些数据重建的点云的倒角距离和F1分数。基线对比:在与第5.1节相同的实验条件下,表2显示Scal3R实现了优异的几何精度。与姿态评估结果一致,遭遇跟踪失败、超出内存(OOM)错误或较大姿态偏差的方法通常无法生成有效重建结果。此外,在ETH3D[60]上的表现表明Scal3R能良好迁移至较短的室内序列,体现了其鲁棒性。图4展示了定性对比结果:Scal3R生成的大规模重建更为精确,局部几何特征也更具一致性。

#pic_center =60%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)