重新理解RAG
为什么写这篇文章?
过去两年我参与和观察了不少 RAG 项目,发现一个反复出现的模式:团队花两周搭了个 Naive RAG,效果还行;花两个月调优,效果反而没有质变。原因很少是"技术选错了",更多是不知道每个环节的天花板在哪,也不知道该在哪个点上花力气。
2024-2025 年 RAG 领域变化很快——Anthropic 的 Contextual Retrieval、微软 GraphRAG 从 v1 到 LazyGraphRAG、Jina 的 Late Chunking、淘天团队的 CoT 查询分解实践——但这些进展分散在各自的论文和博客里。我想做的是把它们放到同一条数据流里,让你看清楚哪些是真正的改进,哪些是该跳过的弯路。
- 2026 年,RAG 还有必要吗?
0.1 长窗口时代的灵魂拷问
Gemini 给了 1M token 窗口,Claude 给了 200K,GPT-4.1 也到了 128K。一个自然的想法浮出来:把文档全塞进上下文不就行了?还折腾什么检索?
这个想法在某些场景确实成立——十几页的合同、一份会议纪要、一篇论文,直接丢进去让模型读,比搭 RAG 管线省事得多。但一旦业务往下走两步,你就会撞上五堵墙,每一堵都是长窗口绕不过去的。
第一堵:钱。
200K token 的窗口不是免费的。按 Claude 3.5 Sonnet 的定价,一次 200K 输入大约 0.6 美元。一个日活 1 万的内部知识库问答系统,每人每天问 5 次,一个月光输入就是 90 万美元。同样的事,RAG 检索 Top-10 chunk(约 4K token)+ 生成,单次成本不到 0.02 美元。差 30 倍。 这不是优化空间,是商业模式能不能跑通的问题。
第二堵:时效。
窗口再大也是"你手动塞进去的那些文档"。你的产品文档昨晚更新了三处、公司政策今早改了一条、竞品凌晨发了新版——这些变化不会自动出现在上下文里。RAG 接了 CDC(变更数据捕获)管线,新文档写入后分钟级可检索。长窗口做不到这件事,除非你每次都手动重新组装 prompt,但那本质上就是在手搓一个简陋的 RAG。
第三堵:规模。
1M token 听着大,换算成文字大约 70 万汉字,也就是两三本书。企业知识库动辄几万篇文档、几十 GB,远超任何模型窗口。你不可能把所有东西都塞进去,必须有一个"先找到相关的"环节——这就是检索。
第四堵:合规与可审计。
金融、医疗、法律场景有一条硬要求:每条结论必须能追溯到原始出处。 审计人员要点一下引用就能看到原文段落。长窗口模式下,模型读了 200K 上下文然后输出一段话,你问它"这句话依据哪里",它只能指个大概。RAG 天然具备引用链——答案来自哪个 chunk、哪篇文档、第几页,全链路可追踪。
第五堵:安全与权限。
企业里不同角色能看不同文档。法务能看合同全文,普通员工只能看摘要。如果把所有文档塞进一个超长上下文,权限隔离就废了——模型读到了不该给这个用户看的内容,你拦不住它在回答里泄露。RAG 在检索阶段就做了权限过滤,没权限的文档根本不会进入上下文。
所以答案很清楚:长窗口是 RAG 的补充,不是替代。 小规模、低频、对成本不敏感的场景,直接塞窗口更省事。但凡涉及成本控制、实时更新、大规模知识库、合规审计、权限隔离中的任何一项,RAG 仍然是唯一正经的工程方案。
确认了这一点之后,我们从 Naive RAG 的天花板开始,一步步往深里走。
0.2 Naive RAG:大多数团队的第一版
既然确认了 RAG 仍然有必要,我们来看最基础的形态——也是大多数团队第一版上线时的样子:
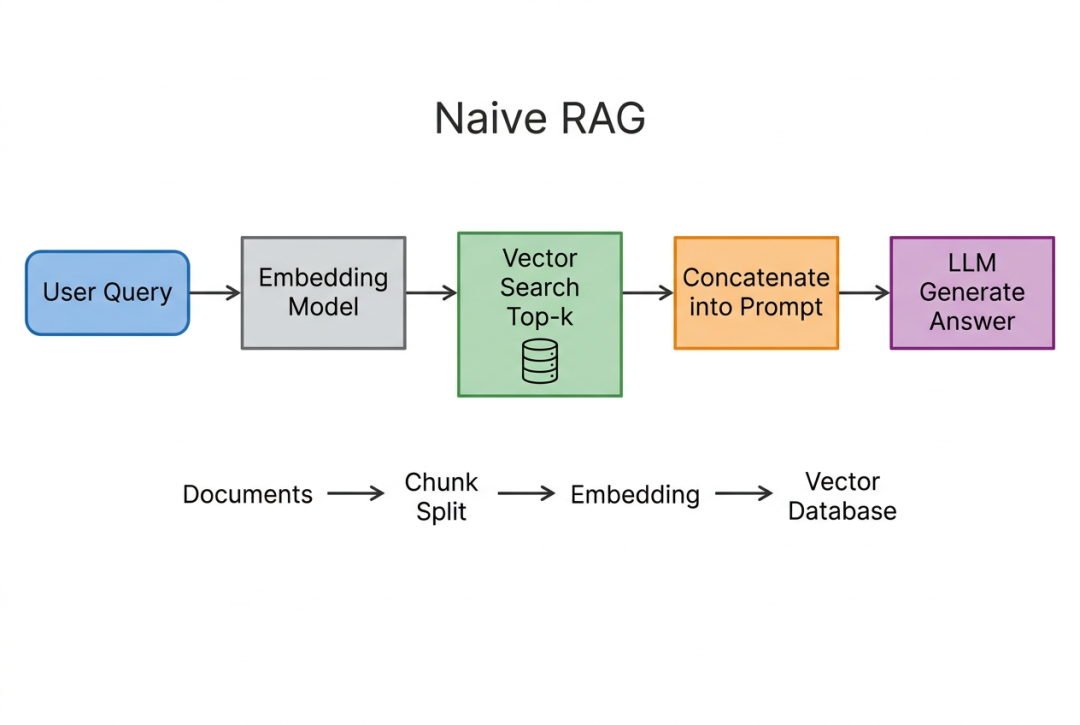
图:Naive RAG 基础流程——离线阶段将文档切分、向量化存入数据库;在线阶段将用户问题向量化后检索 Top-k,拼入 prompt 生成回答。
两个阶段,三步动作:
-
离线阶段
:把文档切成 chunk → 用 Embedding 模型转成向量 → 存入向量数据库。
-
在线阶段
:用户提问 → 同样的 Embedding 模型把问题转向量 → 在向量库里找最相似的 Top-k chunk → 拼进 prompt → LLM 生成。
能跑通,甚至对简单 FAQ 效果还不错。但上线跑一段时间,三个结构性瓶颈一定会暴露——不是"你实现得不好",而是这个架构本身的天花板。
0.3 三个结构性瓶颈:不是调参能解决的
| 瓶颈 | 具体表现 | 根因 |
|---|---|---|
| 对提问方式高度敏感 | 同义改写、口语化表达、省略主语,召回结果差异巨大 | 用户 query 直接当检索 key,没有任何理解和规划 |
| 知识碎片化 | 文档按固定长度切块,上下文被物理切断;多跳推理需要的两段知识分散在不同 chunk 里 | 只做了"存储",没做"组织" |
| 缺乏闭环反馈 | 改了 prompt 或 chunk 策略,不知道效果是好了还是坏了;"感觉变好了"是周会高频句 | 没有评测体系,优化全凭直觉 |
这三个瓶颈分别指向更深层的三个问题:你怎么理解用户在问什么(意图识别)、你怎么组织知识让它可被有效检索(知识组织)、你怎么知道系统在变好(评测闭环)。
后面五章,逐个击破。
- 文档输入与知识组织
1.1 Chunk 的本质问题:切出来的片段不知道自己是谁
文档解析的重要性就不展开了——PDF 表格、多栏排版、页眉页脚,用 Unstructured / Marker / MinerU 等专业解析器处理,表格转 Markdown 保留结构,这是基本功。
真正值得花篇幅讲的是切分之后的事。
大多数团队的第一版 RAG,chunk 流程长这样:文档 → 按 512 token 切块 → Embedding → 存向量库。能跑通,但有一个根本问题被忽略了:每个 chunk 被切出来之后,它不知道自己是谁。
一个真实的例子:一份 SEC 财报里有这么一句话——“The company’s revenue grew by 3% over the previous quarter.” 切成 chunk 后,这句话丢失了三个关键信息:哪家公司?哪个季度?上一季度营收是多少?用户问"ACME Corp 2023 年 Q2 营收增长多少",这个 chunk 的向量和问题的向量在语义空间里未必很近,因为 chunk 里根本没有"ACME"和"Q2 2023"这两个词。
这不是切分策略的问题——你换成语义边界切分、换成 Small-to-Big,这个 chunk 照样不知道自己在讲 ACME 的 Q2。问题出在:chunk 和它所在的文档上下文之间的关系,在切分的那一刀就被切断了。
2024 年下半年,两个方案几乎同时给出了解法,思路完全不同但目标一致:让 chunk 保留文档级上下文。
Contextual Retrieval(Anthropic, 2024.09)
Anthropic 的做法很直接:在 Embedding 之前,用 LLM 给每个 chunk 补一段上下文前缀。
具体流程:
- 把整篇文档和当前 chunk 一起喂给 Claude(用的是 Haiku,够便宜)
- Prompt 大意是:“这是整篇文档,这是其中一个 chunk,请给一段简短的上下文说明,帮助检索时定位这个 chunk”
- 模型返回 50-100 token 的上下文描述,拼到 chunk 前面
- 拼接后的 chunk 再做 Embedding 和 BM25 索引
上面那个财报 chunk,处理后变成:
This chunk is from an SEC filing on ACME corp's performance in Q2 2023;the previous quarter's revenue was $314 million.The company's revenue grew by 3% over the previous quarter.
现在这个 chunk 带着公司名、季度、基线数字,检索时匹配精度完全不一样了。
Anthropic 的实验数据(多领域知识库,Recall@20):
| 方法 | 检索失败率 | 相对基线下降 |
|---|---|---|
| 传统 Embedding(基线) | 5.7% | — |
| Contextual Embeddings | 3.7% | ↓ 35% |
| Contextual Embeddings + Contextual BM25 | 2.9% | ↓ 49% |
| 上述 + Reranking(Cohere) | 1.9% | ↓ 67% |
检索失败率从 5.7% 降到 1.9%,三分之二的错误被消除了。而且这个收益和 Hybrid 检索、Rerank 是正交可叠加的。
成本方面,配合 Prompt Caching(文档只加载缓存一次,所有 chunk 复用),每百万文档 token 的上下文生成成本约 1 美元。对大多数企业知识库来说,这是一次性的离线开销,完全可接受。
Late Chunking(Jina, 2024.09)
Jina 团队几乎同时提出了另一个思路:不是给 chunk 补信息,而是改变切分的时序——先编码,后切分。
传统流程是"先切后编码":文档 → 切成 chunk → 每个 chunk 独立过 Embedding 模型。Late Chunking 反过来:
- 把整篇文档(或尽可能长的文本)一次性送入长上下文 Embedding 模型(如 jina-embeddings-v2,支持 8K token)
- Transformer 的自注意力让每个 token 都能看到整篇文档
- 编码完成后,再按预设的 chunk 边界切分 token-level embeddings
- 每个 chunk 内的 token embeddings 做 mean pooling,得到最终 chunk 向量
效果:每个 chunk 的向量里天然带着文档级上下文,代词消解、指代模糊等问题自动解决。而且不需要额外 LLM 调用,计算开销和传统方法基本一样,只是改变了切分的时机。
两种方案怎么选
| 维度 | Contextual Retrieval | Late Chunking |
|---|---|---|
| 核心思路 | LLM 生成上下文前缀,拼到 chunk 前 | 先整文档编码,后切分 token embeddings |
| 额外成本 | 离线 LLM 调用(~$1/百万文档 token) | 几乎无额外成本 |
| 对 BM25 的帮助 | 有(Contextual BM25) | 无(只改善向量) |
| 对 Embedding 模型的要求 | 无特殊要求 | 需要长上下文 Embedding 模型 |
| 可解释性 | 高(上下文前缀可读) | 低(隐式编码在向量中) |
| 实操推荐 | 默认首选 ,尤其配合 Hybrid 检索 | 适合纯 Dense 检索 + 长上下文模型已就位的场景 |
我的建议:大多数团队优先上 Contextual Retrieval。原因很实际——它同时改善了向量检索和 BM25 检索两条通路,而且生成的上下文前缀是人可读的,出了问题好排查。Late Chunking 作为补充手段,在你已经用了长上下文 Embedding 模型的情况下几乎是免费的升级。
切分策略仍然重要,但不再是瓶颈
有了上下文增强之后,切分策略的重要性降了一档——但没降到可以不管的程度。快速参考:
| 切分策略 | 做法 | 适用场景 | 风险 |
|---|---|---|---|
| 固定 token | 每 512 token 切一刀 | 快速原型(不推荐生产) | 语义边界被切断 |
| 语义边界 | 按段落 / 标题 / 分隔符切分 | 结构化文档 | 段落长短差异大 |
| Small-to-Big | 小 chunk 检索,命中后返回父 chunk | 通用场景(推荐默认) | 存储翻倍 |
| 按文档类型混合 | 代码用 AST、表格保持完整、正文用语义边界 | 混合文档库 | 工程复杂度高 |
2026 年的基准测试结论比较一致:512 token + 10-20% overlap 是一个稳健的默认值,在此基础上配合 Contextual Retrieval 做上下文增强,比花两周调 chunk size 的收益高得多。
向量化选型不展开——bge-large / jina-v3 / text-embedding-3-large 都能用,Embedding 选型的影响力远小于"是否做了上下文增强"和"是否上了 Rerank"。不要在这上面花超过一周。
1.2 从扁平 chunk 到结构化知识
上面的标准流程把文档变成了"扁平的 chunk 集合"——每个 chunk 是独立的文本片段,向量是它在语义空间里的坐标。这种方式有一个根本局限:它不知道 chunk 之间的关系。
举个例子:一篇技术文档里,"WebView 是渲染容器"在第 3 页,"WebView 支持离线包加载"在第 15 页,“离线包加载失败会导致白屏"在第 22 页。扁平 chunk 里,这三个信息是三个独立点。用户问"为什么我的小程序白屏”,单次 Top-k 很难同时召回这三段并理解它们的因果链。
知识图谱就是为了解决这个问题:把实体和关系显式抽取出来,让知识从"散落的点"变成"连通的网"。
目前有两种主流的图增强知识组织方案:
GraphRAG(微软,2024-2025):从论文到工程的阵痛
GraphRAG 的核心想法:不光存 chunk,还要把文档里的实体和关系抽出来建图谱,再用 Leiden 算法做社区发现,给每个社区生成一份结构化摘要。
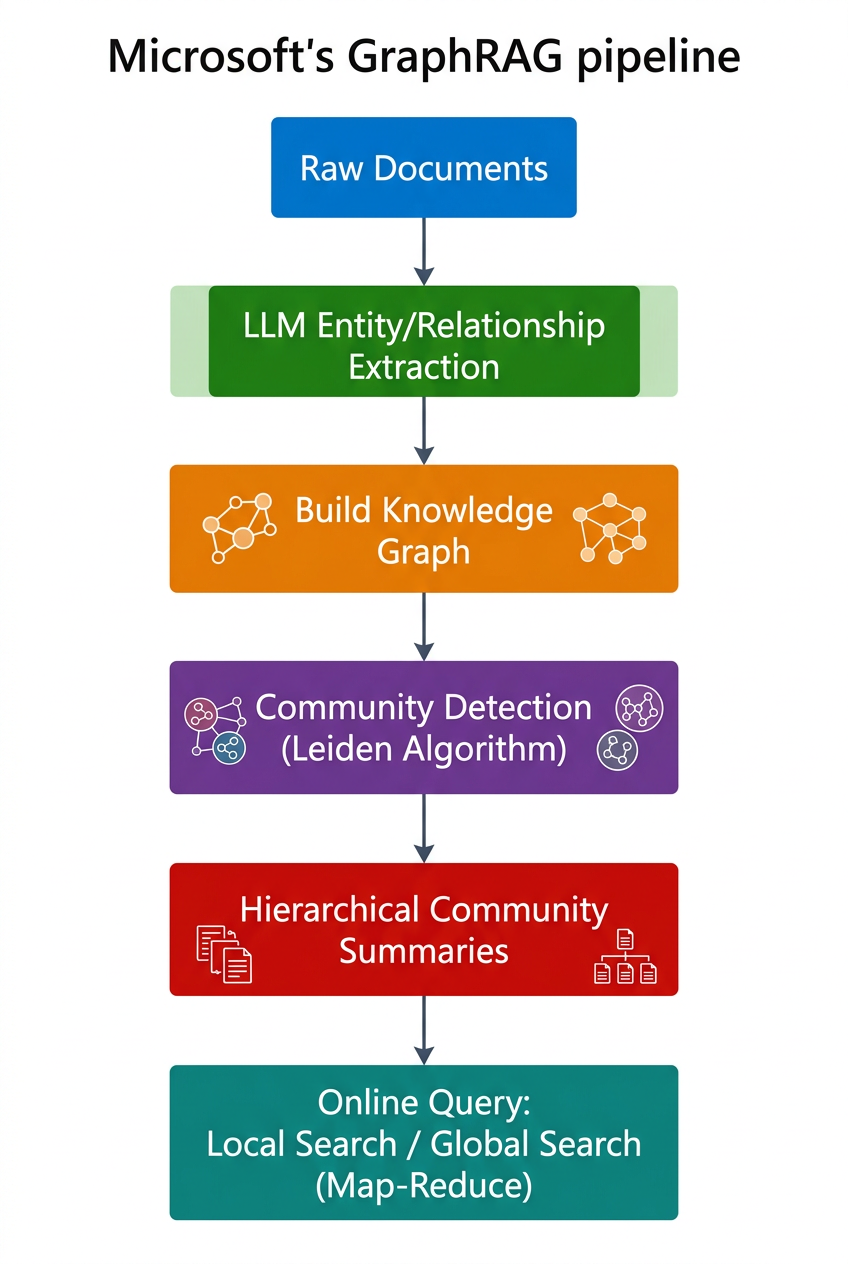
图:GraphRAG 构建流水线——从文档到图谱到社区摘要的完整索引过程。
图源:GraphRAG 论文 Figure 3. Leiden 社区发现层级可视化。
当用户问"整体趋势是什么"这类全局问题时,系统不走向量检索,而是在社区摘要上做 Map-Reduce 汇总——这是 GraphRAG 对 Naive RAG 最大的能力增量。论文数据也确认了这一点:在 Comprehensiveness 和 Diversity 上 GraphRAG 全面胜出。
图源:GraphRAG 论文 Figure 4. Graph RAG 在 Comprehensiveness 和 Diversity 上全面胜出 Naive RAG(SS)。
但真正落地时,四个工程问题会依次砸过来:
| 问题 | 说明 |
|---|---|
| 索引成本爆炸 | 每篇文档三次 LLM 调用(实体抽取 + 关系描述 + 摘要生成),百万 token 语料成本比 Naive RAG 高 2-3 个数量级 |
| 增量更新近似重建 | 新文档 → 图谱变化 → 社区边界重划 → 摘要重新生成 |
| 查询延迟过高 | Global Search 可能分钟级,Local Search 也显著高于向量检索 |
| 对抽取质量高度敏感 | 弱模型 / 不规范文档 → 图谱充满噪音 → 质量反而不如 Naive RAG |
微软自己也清楚这些问题。从 2024 年底到 2025 年初,GraphRAG 经历了三次重要迭代:
DRIFT Search(2024.11):第三种查询模式,结合了 Global 和 Local 的优势。先用社区摘要粗筛定方向,再沿图结构动态下钻到具体实体做精细推理。解决了"要全局视角又要细节精度"的问题,但没解决索引成本。
LazyGraphRAG(2024.11):这才是对成本问题的正面回应。核心思路是把所有 LLM 推理延迟到查询阶段——索引时不调 LLM,用传统 NLP 名词短语提取来识别概念和共现关系,照样构建图结构和社区层级。只在查询时,才对相关的文本块调 LLM 做相关性评估和 claim 提取。
结果很惊人:索引成本降到完整 GraphRAG 的 0.1%,和普通 Vector RAG 持平。查询质量呢?在 AP 新闻 5590 篇文章的测试集上,LazyGraphRAG 以仅 4% 的 GraphRAG Global Search 查询成本,在 Local 和 Global 查询上同时显著优于所有竞争方法——包括 GraphRAG 自己 。
GraphRAG v2.0(2025.02):把上面这些进展整合到了一个正式版本里——模块化管线、增量索引支持(update 模式)、NLP 图提取(非纯 LLM)、DRIFT Search 修复、多索引查询。API 做了大幅重构,配置方式也变了,升级成本不低,但方向是对的。
一句话总结 GraphRAG 的演进:v1 是学术 demo,证明了"图 + 社区摘要"对全局问答有用;v2 + LazyGraphRAG 是在努力把它变成工程可用的东西。但截至 2026 年中,它仍然是整个 RAG 技术栈里工程复杂度最高的选项。
LightRAG(HKU,2024-2026):轻量图 RAG 的生产化之路
LightRAG 的出发点很务实:大部分问题是具体的、局部的,真正需要"全局鸟瞰"的查询占比很低。能不能去掉社区摘要那套重型机制,用更轻的方式实现图增强?
核心设计是三个函数替代 GraphRAG 的整条流水线:
-
R(·) 实体与关系抽取
:和 GraphRAG 一样用 LLM 抽,但简化了实体类型分类。
-
P(·) 键值对生成
(关键区别):每个实体和关系生成 (Key, Value) 文本对——Key 是检索用的短语,Value 是聚合了该实体在所有文档中出现时的总结文本。用键值对直接替代社区摘要,不做 Leiden 聚类也能实现信息聚合。
-
D(·) 去重与合并
:识别不同文档中的相同实体并合并。这让增量更新天然可行——新文档的实体匹配到已有实体时直接合并,不影响图谱其他部分。
在线检索同时触发两层:
-
低层
:聚焦具体实体及直接关联关系(类似 GraphRAG Local Search)
-
高层
:聚焦抽象主题关键词 → 沿边关联实体(部分替代 Global Search)
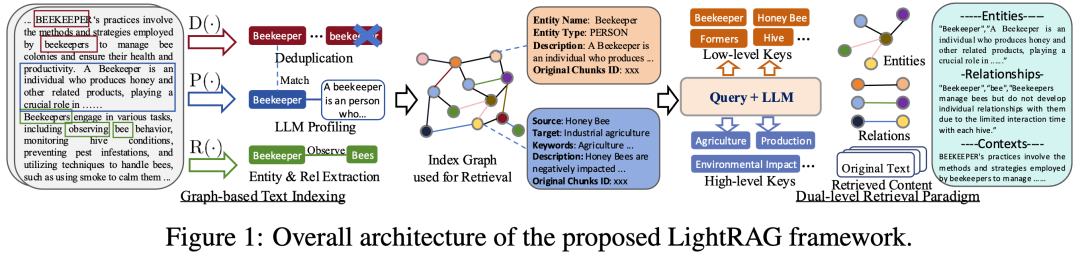
图源:LightRAG (HKU, 2024) 官方仓库——从文档到图构建到双层检索的完整架构。
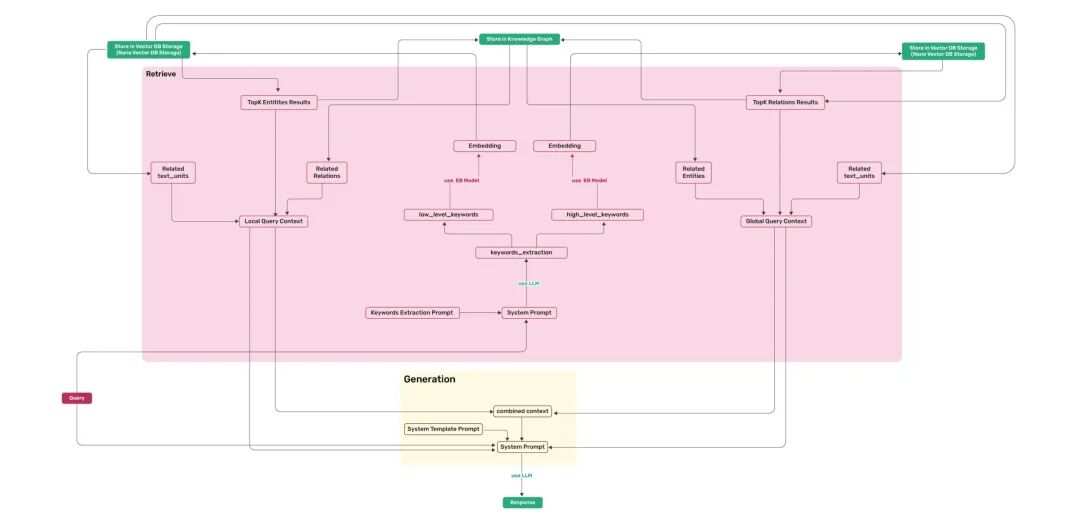
图源:LearnOpenCV 对 LightRAG 的技术解析——双层检索流程。
论文数据显示,LightRAG 在多样性维度上大幅领先 GraphRAG(法律领域 73.6% vs 26.4%),全面性和赋能性上小幅领先,混合领域基本持平。核心差异化优势是回答的视角丰富度。
2025-2026 年的生产化进展:
LightRAG 从 2024 年底开始快速迭代,到 2026 年已经变成了一个相当完整的生产级框架:
| 时间 | 关键进展 | 解决的问题 |
|---|---|---|
| 2025.01 | PostgreSQL 一体化存储 | 脱离文件系统,支持生产部署 |
| 2025.02 | MongoDB 统一数据管理 | 更多存储后端选择 |
| 2025.06 | RAG-Anything 多模态集成 | 支持 PDF/图像/表格/公式 |
| 2025.08 | 文档删除 + 自动 KG 重建 | 知识库维护和实体过期问题 |
| 2025.09 | 开源 LLM 抽取准确性提升 | 降低对 GPT-4 级模型的依赖 |
| 2025.10 | 大规模数据集瓶颈消除 | 百万级文档场景 |
| 2025.11 | Langfuse 追踪 + RAGAS 评估 | 可观测性和质量闭环 |
| 2026.03 | OpenSearch 统一存储 + Docker 安装向导 | 一键部署 |
但生产落地后暴露的问题也很真实——实体膨胀是图 RAG 的头号工程杀手。
先说清楚 LightRAG 的 D(·) 到底是怎么去重的:纯粹的 entity_name 字符串精确匹配。代码在 operate.py 的 merge_nodes_and_edges 函数里——同名节点的 description 合并(少于 5 条时简单拼接,超过 5 条时调 LLM 生成摘要)。就这么简单。
这意味着两个致命盲区:
| 盲区 | 举例 | 后果 |
|---|---|---|
| 异名同义 (False Negative) | “微信支付” / “WeChatPay” / “微信钱包”——三个名字同一个东西 | 图中产生三个独立节点,边和描述各自累积,图谱膨胀 |
| 同名异义 (False Positive) | "苹果"在食品文档 vs 科技文档里——完全不同的实体 | 被强制合并成一个节点,描述混成一锅粥 |
跑三个月不清理,实体节点从几十万膨胀到几百万,检索时噪声大幅增加,Recall 可以掉 10-15 个点。这不是 LightRAG 独有的——GraphRAG、HippoRAG 用 LLM 做实体抽取,一样会产生命名不一致的重复实体。
怎么解决?实操中分三层做。
第一层:抽取阶段的源头控制。
在实体抽取的 prompt 里加上领域实体规范表(canonical entity list),强制模型输出标准化名称。比如你的知识库是金融领域,prompt 里附上"以下实体请使用标准名:微信支付(不要用 WeChatPay / 微信钱包)"。这一步能在源头消除 40-60% 的异名同义问题,成本最低。
第二层:离线 Entity Resolution(实体消歧)。
这是核心。按 Anthropic 在 Claude Cookbook 里给出的方案,流程是这样的:
-
按实体类型分组
:把 PERSON、ORG、PRODUCT 等类型分开处理,降低每组的规模
-
Blocking(分块缩小候选集)
:同组内,用 embedding 相似度或 token 重叠率找出潜在的重复对。不是全量 N² 两两比较——万级实体时 N² 直接炸掉。先 blocking 到 50-100 个小候选组
-
LLM 聚类判断
:把每个候选组连同实体的 description 一起传给 LLM,让模型判断哪些是同一实体的不同名称,输出
{canonical_name, aliases[]}结构 -
合并执行
:在图谱上把别名节点合并到 canonical 节点,边和描述一起归并
# 伪代码:Entity Resolution 核心流程for entity_type in ["PERSON", "ORG", "PRODUCT", ...]: entities = get_entities_by_type(entity_type) candidates = blocking(entities, method="embedding_similarity", threshold=0.8) for group in candidates: clusters = llm_resolve(group, prompt=RESOLVE_PROMPT) # 用强模型 for cluster in clusters: merge_aliases_to_canonical(graph, cluster.canonical, cluster.aliases)
关键细节:
-
描述驱动消歧
:传给 LLM 的不只是名字,还有 description。“Armstrong——首位登月宇航员” vs “Armstrong——爵士小号手” 靠名字无法区分,靠描述一目了然
-
用强模型做消歧
:抽取用 Haiku 级模型就够,但消歧需要推理能力,建议用 Qwen3-30B 以上
-
单元素聚类兜底
:确实不同的实体给一个只含自己的聚类,确保不丢节点
第三层:定期 Reconsolidation(图谱重整)。
Entity Resolution 做的是"合并重复的",Reconsolidation 还要做"清理过期的"和"修剪噪声的":
| 动作 | 做什么 | 频率建议 |
|---|---|---|
| 过期淘汰 | 删除超过 N 天未被任何新文档引用的实体节点 | 周级 |
| 孤立节点清理 | 删除度为 0 或只连接被删除文档的节点 | 周级 |
| 低质量边修剪 | 用 TransE / DistMult 等 KG Embedding 方法对三元组打可信度分,裁剪低分边 | 月级 |
| 社区/聚类重算 | 如果用了 GraphRAG,社区边界要随图谱变化重新跑 Leiden | 月级 |
DEG-RAG [论文:Zheng et al., 2025] 的实验已经验证了"Less is More"——对 LightRAG、GraphRAG、HippoRAG 等多个系统做图去噪后,检索和生成质量都有显著提升。精简的高质量图谱优于包含噪声的大规模图谱。
实操建议:大多数团队不需要从零搭这套 pipeline。第一层(prompt 规范化)今天就能做,成本为零。第二层(Entity Resolution)可以用 Claude/GPT 的 structured output + 定期批量任务跑,频率取决于文档更新速度——日更知识库建议每周跑一次。第三层的 KG Embedding 打分比较重,先不急上,等图谱规模超过 50 万实体再考虑。
LLM 选型敏感度也比预期高。官方建议索引阶段用 ≥32B 参数、≥32K 上下文的模型,查询阶段用比索引阶段更强的模型。用 7B 小模型做实体抽取,图谱质量会断崖式下降——这一点和 GraphRAG 是一样的。2025 年 9 月专门优化了 Qwen3-30B 等开源模型的抽取准确性,但仍然不推荐用太小的模型。
四种知识组织方式横向对比
| 维度 | 扁平 Chunk | GraphRAG(完整版) | LazyGraphRAG | LightRAG |
|---|---|---|---|---|
| 索引成本 | 低(只需 Embedding) | 极高(LLM × 3 + 社区摘要) | ≈ 向量 RAG (NLP 提取,无 LLM) | 中等(LLM 抽取 + 键值对) |
| 增量更新 | 天然支持 | v2 支持但仍有社区重划开销 | 天然支持(近零索引成本) | 天然支持 (局部子图合并) |
| 跨文档关联 | 无 | 强(显式图谱 + 社区摘要) | 中等(概念共现图,无 LLM 描述) | 较强(显式图谱 + 键值对聚合) |
| 全局问答 | 无 | 最强(社区摘要层级汇总) | 强 (查询时 claim 提取) | 中等(高层关键词部分替代) |
| 查询延迟 | 毫秒级 | 秒-分钟级 | 秒级(随预算可调) | 秒级 |
| 工程复杂度 | 低 | 高(v2 好于 v1 但仍最重) | 中等 | 中低 |
| 适合场景 | 通用入门 | 静态 + 大规模 + 强全局需求 | 成本敏感 + 探索性分析 | 动态 + 频繁更新 |
选型建议:如果你之前因为成本问题在 GraphRAG 和纯向量之间纠结,LazyGraphRAG 给了一个中间选项——索引成本和向量 RAG 一样,但全局查询能力接近完整 GraphRAG。LightRAG 的优势在增量更新和多样性,适合知识库频繁变动的场景。完整 GraphRAG 只在"静态语料 + 强全局需求 + 预算充裕"三条同时满足时才值得上。
1.3 增量更新:被忽视的工程分水岭
学术论文很少讨论增量更新,但在生产环境里,能否增量更新往往是决定方案可行性的核心因素。
上面讲了图 RAG 的实体膨胀问题和三层解法。这里补充向量 RAG 侧的增量更新——问题不一样,但同样容易踩坑。
向量 RAG 的增量走标准三段式:CDC(变更数据捕获)→ 异步 Embedding → ANN 增量插入 + tombstone(标记删除)。流程不复杂,但有一个隐藏的定时炸弹:Embedding 模型迁移。
场景是这样的:你用 text-embedding-ada-002 跑了半年,积累了 200 万条向量。现在想换成 text-embedding-3-large 提升检索质量。问题来了——新旧模型的向量空间不兼容,老向量和新 query 之间的相似度计算是无意义的。你必须把 200 万条全部重新 Embed。
正确做法是"双库灰度":新旧模型并行索引,按比例切流(5% → 20% → 50% → 100%),指标稳定后下线旧库。过去一年,Embedding 模型迁移是很多团队踩过的最贵的坑——永远预留迁移窗口预算。
如果你用了 Contextual Retrieval(1.1 节讲的),增量更新还多了一步:新文档不光要切 chunk + Embedding,还要跑一遍 LLM 上下文生成。好在这是离线 batch 任务,用 Prompt Caching + Haiku 级模型,成本可控。
1.4 知识组织的选型决策树
用一个简单决策帮你判断该用哪种知识组织方式:
- 你的文档库更新频率如何?
- 月度以上更新 + 静态 + 规模大 → 考虑 GraphRAG
- 日 / 周更新 → LightRAG 或纯向量
-
你的查询里"全局性问题"占比多少?
(如"整体趋势"“主要结论”)
- < 10% → 纯向量 + Rerank 足够
- 10-30% → LightRAG
-
30% + 静态语料 → GraphRAG
- 你的预算能支撑多少索引构建成本?
- 紧张 → 纯向量起步,不要碰图 RAG
- 充裕 → 按上面两条选
知识组织到这里差不多了。接下来的问题是:知识准备好了,但用户说了一句话,你怎么知道该去找什么?
- 意图识别与查询规划
2.1 为什么不能拿到 query 就直接检索
传统 RAG 的检索入口是"用户原始 query → Embedding → 向量相似度"。这个做法有两个本质局限:
| 局限 | 说明 | 举例 |
|---|---|---|
| 改写是"平面"的 | 传统 query rewriting 只做语义层同义替换,没理解问题内在结构 | 用户问"我的小程序上线后白屏了,之前本地开发都正常"——简单改写只产出"小程序白屏排查",但实际需要查:环境差异、渲染链路断点、资源加载异常等多个维度 |
| 检索是串行的 | 改写后仍然只用一个 query 做一次检索,召回覆盖面受限于单次检索上限 | 一次 Top-10 只能覆盖一个语义角度,多维度问题的其他角度全部漏掉 |
Andrej Karpathy(2025)的观点精确概括了这个问题:
上下文工程 > Prompt 工程。 LLM 应用的质量瓶颈,往往不在模型本身,而在你喂给它的上下文是否足够好。
意图识别和查询规划,本质上就是上下文工程在查询侧的实践:不是"用户问什么就检索什么",而是先理解问题结构,再有目的地规划检索策略。
2.2 第一步:意图分类与复杂度路由
并非所有问题都需要复杂的检索策略。用户问"你好"也走全套 RAG 流水线,2 秒才回,是资源浪费。用户问"对比 A B C 三家产品的优劣势",单轮 RAG 给了一个干瘪答复,是能力不足。
解法是加一层"任务复杂度路由"——先判断问题该走哪条通路:
| 档位 | 典型任务 | 通路 | 预算 |
|---|---|---|---|
| L1 简单 | 闲聊 / 常识 / FAQ / 单跳事实 | 基座直答 或 Advanced RAG(Hybrid + Rerank) | < 1.5s,1 次 LLM |
| L2 中等 | 多跳问答 / 跨文档比较 / 业务分析 | Advanced RAG + 查询分解 + 迭代检索 | 3-10s,3-10 次 LLM |
| L3 研究级 | 深度研究 / 报告生成 / 跨源综合 | Deep Research 异步任务 | 分钟级,50-200 次 LLM |
路由器实现可以很轻量——一个 qwen-turbo 级别的小模型做意图分类,延迟 < 100ms。关键原则:默认走 L1,只在置信度高时升档。L1 误判成 L3(烧钱)比 L3 误判成 L1(答不好)危险得多。
踩坑现场:某团队接入 Deep Research API 没做路由,所有请求都走深度通路。一个"我们 H2 OKR 是什么"触发 80+ 次 LLM 调用 + 30s 延迟。一周账单 8000 美元,用户满意度反而下降 。
2.3 第二步:CoT 驱动的查询分解与并行召回
路由之后,进入查询规划的核心动作。这里淘天团队的实践,提供了一个非常值得借鉴的方案:
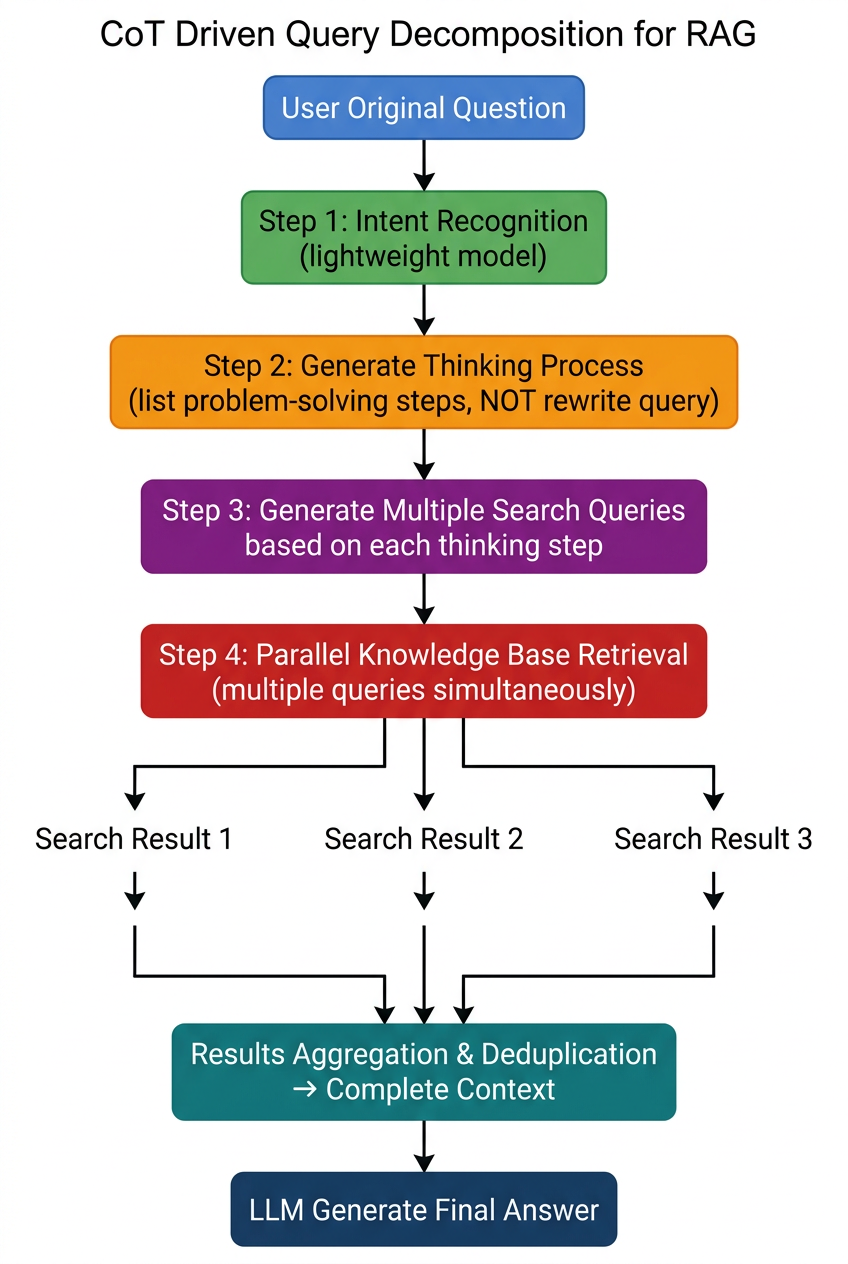
图:CoT 查询分解流程——不直接改写 qung 的两个核心区别:
1. 思维链作为分解骨架
模型不直接输出改写后的检索 query,而是先给出"解决这个问题的思维步骤"。比如用户问"小程序上线后白屏,本地正常",思维链会输出:
- 排查环境差异(本地 vs 线上构建配置)
- 检查渲染链路断点(WebView 容器 / JS 资源加载)
- 确认监控日志报错
然后每个思维步骤再生成多条具体的知识库检索 query。这样召回的知识天然具有逻辑递进关系,不是零散片段的堆砌。
2. 多组查询并行执行
传统改写后仍然只有 2-3 条 query 串行检索。CoT 分解后一次性产出十几条覆盖不同维度的查询,并行发送向量检索,召回率显著高于单次检索。
| 传统 RAG(被动检索) | CoT 方案(主动规划) |
|---|---|
| 用户问什么就检索什么 | 先理解问题结构 |
| 检索到什么就塞什么 | 规划需要哪些维度的信息 |
| 上下文质量取决于提问质量和运气 | 有目的地检索和组装 |
| 一次 Top-k 覆盖一个角度 | 并行多组 Top-k 覆盖多个角度 |
2.4 "是否检索"也是一个决策
还有一类更基础的判断:这个问题需不需要检索?
用户问"1+1 等于几",走 RAG 反而可能召回噪声干扰。Self-RAG [论文:Self-RAG,2024] 把这个决策内化为模型行为——训练模型输出 Retrieve / IsRel / IsSup 等特殊 token,在推理时按 token 决定是否触发检索。
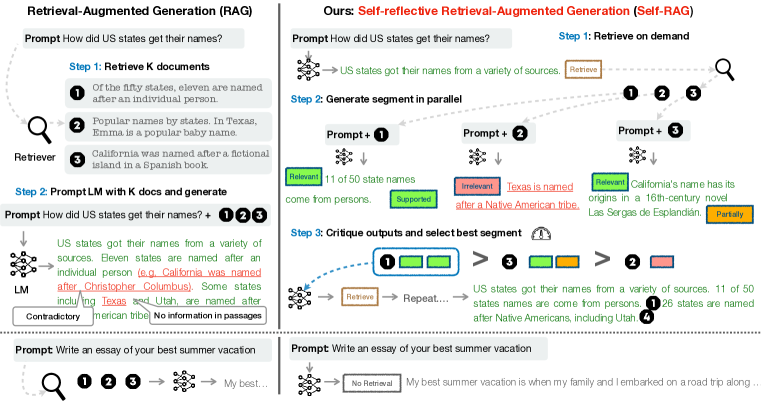
图源:Asai et al., “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection”, ICLR 2024. Figure 1——Self-RAG 通过特殊反思 token(Retrieve/IsRel/IsSup/IsUse)在推理时自主决定是否检索、评估相关性和可信度。
但在 2026 年,Self-RAG 的 SFT 训练成本越来越不划算。强基座模型用 prompt + JSON Schema 就能模拟类似的决策:
你是一个 RAG 决策器。判断以下问题是否需要检索外部知识库:- 如果问题是常识/闲聊/数学计算,输出 {"need_retrieval": false}- 如果问题涉及特定事实/政策/产品信息,输出 {"need_retrieval": true, "queries": [...]}
把 Self-RAG 当架构模式用比训一个专属 SFT 模型更划算。
2.5 上下文工程的本质
把 2.1-2.4 串起来,意图识别做的事情可以用一句话概括:
用 CoT 规划上下文的结构,用并行检索填充上下文的内容,确保最终上下文既完整又有条理。
这就是上下文工程。它不是一个具体的技术,而是一种思维方式:RAG 系统的核心任务不是"检索文档",而是"为 LLM 构建足够好的上下文"。检索只是手段,上下文才是目的。
想清楚了要找什么,下一步就是怎么找。
- 检索与排序
3.1 从单路 Dense 到 Hybrid 检索
Naive RAG 只有一条检索通路:Dense(向量相似度)。它的问题是对精确匹配无能为力——用户查产品型号"MX-7823"、错误码"ERR_CERT_AUTHORITY_INVALID"、人名"张伟",纯向量检索经常抓瞎,因为这些是词汇匹配问题,不是语义匹配问题。
Advanced RAG 的第一个关键动作是上 Hybrid 检索:BM25(精确词汇匹配)+ Dense(语义匹配)+ RRF 融合。
最终排序 = RRF_融合(BM25_排序, Dense_排序)RRF(d) = Σ 1/(k + rank_i(d)) # k 常取 60
实操经验:
-
BM25 权重根据数据类型给 0.3-0.5。政策/条款/代码等精确匹配重的场景,BM25 权重调高。
-
没上 Hybrid 就讨论 Embedding 选型是浪费时间
——Hybrid 的增益通常比换 Embedding 大一个量级。
3.2 Cross-Encoder Rerank
Hybrid 检索拿到 Top-100 候选后,下一步是用 Cross-Encoder 重排序截到 Top-10。
为什么需要 Rerank?因为第一阶段检索(无论 BM25 还是 Dense)用的是"双塔"模型——query 和 document 分别编码再算相似度,效率高但精度有上限。Cross-Encoder 是把 query 和 document 拼在一起过一个模型,能捕捉更细粒度的交互信号。
Rerank 是 RAG 系统里性价比最高的一个组件:
- 同一份数据,上 Rerank 后 nDCG@10 常从 0.46 拉到 0.55+
- 90% 的"检索上不去"问题,上 Rerank 就能解决
- 成本:50-300 ms 延迟 + 一块 GPU(或量化版 CPU)
主流选型:bge-reranker-large / Cohere Rerank / jina-reranker-v2,差距不大,选一个先上比花两周选型重要。
3.3 图检索:当向量检索的天花板被触及
Hybrid + Rerank 是绝大多数场景的正确答案。但有两类问题它解决不了:
场景 A:多跳推理
“A 公司 CEO 的母校在哪国”——答案散落在至少两个 chunk 里(chunk1: A 公司 CEO 是张三;chunk2: 张三毕业于 MIT),单次 Top-k 跨不过去。
场景 B:全局问答
“这 500 份判决书里最频繁的争议焦点是什么”——Top-10 只能看到 0.001% 的语料,它不知道"主线"是什么。
这就是图检索登场的地方。前面在知识组织章节构建的知识图谱在这里发挥作用:
| 检索模式 | 机制 | 适用场景 | 延迟 |
|---|---|---|---|
| GraphRAG Local | Embedding 找实体节点 → 沿图谱边扩展 → 拼装原始文本 + 社区报告 | 实体密集的具体问题 | 秒级 |
| GraphRAG Global | 在社区摘要上做 Map-Reduce 汇总 | 全局性问题(趋势/总结) | 分钟级 |
| LightRAG 双层 | 低层:向量找实体 + Value 文本;高层:主题关键词 → 沿边关联 | 具体 + 中等全局,频繁更新 | 秒级 |
| HippoRAG-2 PPR | 查询识别种子节点 → Personalized PageRank → 对应 chunk | 实体密集 + 关系密集的多跳 | 秒级 |
下图为 HippoRAG-2 论文(Gutiérrez et al., 2025)的方法论架构,展示了离线索引和在线 PPR 检索的双阶段流程:
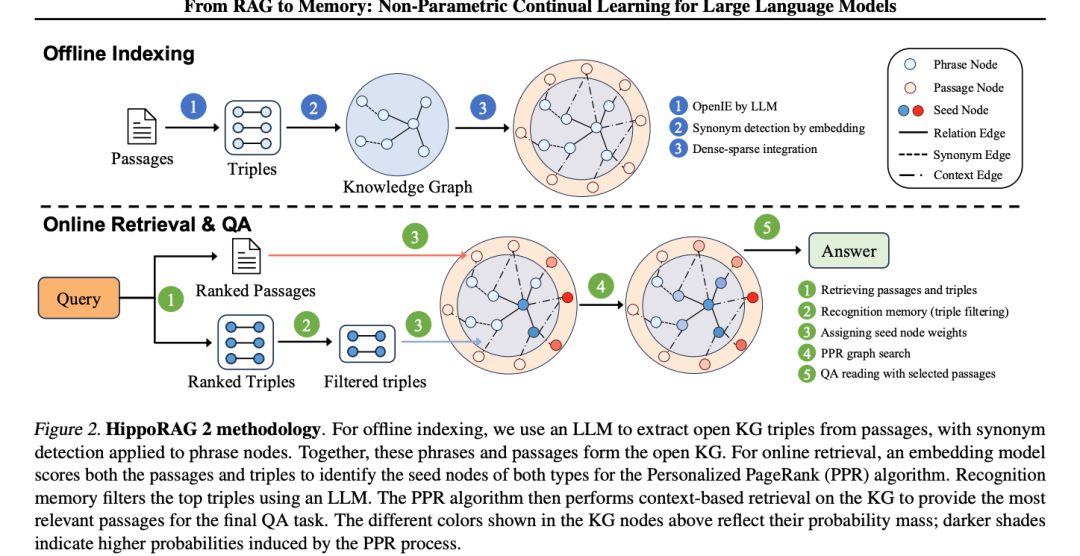
图源:Gutiérrez et al., “From RAG to Memory: Non-Parametric Continual Learnin声称的"多跳"其实是"复杂单跳 + 一段叙事铺垫”——拆解后事实链长度 ≤ 1.5。这类伪多跳用 Advanced RAG + Query Decomposition(前面讲的 CoT 分解)就能解决,上 HippoRAG-2 是负 ROI。
上图检索之前先做一次"真伪多跳分类":50 条多跳样本,超过 60% 拆开后是伪多跳的,图 RAG 不必上。
3.4 检索结果质量评估:CRAG 评估器
检索完成后,还有一个经常被跳过的步骤:评估这次检索的结果够不够好。
CRAG(Corrective RAG)[论文:CRAG,2024] 引入了一个轻量评估器,对检索结果打三档分:
| 评估结果 | 含义 | 后续动作 |
|---|---|---|
| Correct | 检索结果充分支撑回答 | 直接用 |
| Ambiguous | 部分相关但不够 | 本地结果 + 兜底源补充 |
| Incorrect | 检索结果与问题无关 | 抛弃本地,走兜底或拒答 |
这个评估器的价值在于:它让系统知道"自己不知道"——这恰恰是 Naive RAG 最大的盲区。没有评估器,模型拿到一堆不相关的 chunk 也会硬答,然后就是幻觉。
关键洞察:CRAG 80% 的价值来自"拒答",20% 才来自"Web 兜底"。 高风险场景(金融/医疗/法律),拒答的边际价值远高于多答几个错答。很多团队该上的不是 CRAG-with-Web,而是 CRAG-without-Web(只要评估器 + 拒答能力)。
图:检索层完整架构——从并行 Hybrid 检索到 Rerank 再到 CRAG 三档评估及后续分支处理。
下图为 CRAG 论文(Yan et al., 2024)的推理流程概览:
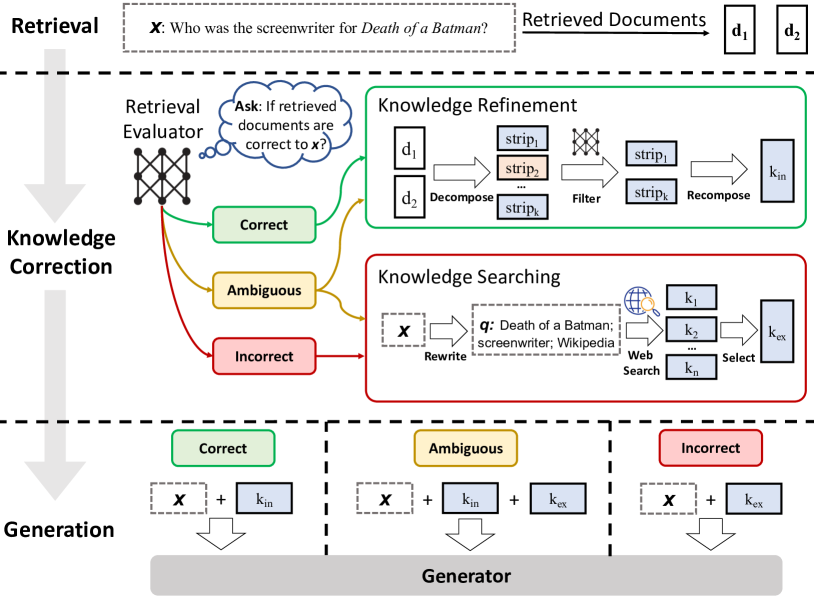
图源:Yan et al., “Corrective Retrieval Augmented Generation”, 2024. Figure 2——检索评估器基于置信度触发 Correct / Incorrect / Ambiguous 三种知识检索动作。
3.5 检索层的子场景细分
同样是"事实问答",不同子场景的检检索重点
| 政策 / 条款 | BM25 权重大(精确条款号匹配),Dense 是补充 |
| 产品规格(型号/编号/数字) | 保留原始 token,关闭过激 normalization |
| 代码 / API 文档 | 代码专用 Embedding(jina-code 等)+ 符号感知分词 |
| 医疗 / 法律指南(术语 + 同义词) | 词典扩展 + Rerank 必上 |
| 多语言混合 | 多语言 Embedding + 语言路由 |
检索到了相关 chunk,但直接拼进 prompt 就完事了吗?没那么简单。
- 上下文构建与生成
4.1 从"检索到什么给什么"到"有目的地组装"
Naive RAG 的做法是:检索到 Top-k chunk → 按相似度排序拼进 prompt → 让模型自己看着办。这有三个问题:
-
噪声 chunk 干扰
:Top-10 里可能有 3-4 个不太相关的 chunk,模型被噪声带偏。
-
重要信息位置不对
:大模型的"中间遗忘"(Lost in the Middle
[论文:Liu et al.,2023])——放在 prompt 中间的信息容易被忽略。关键 chunk 应该放在头尾。
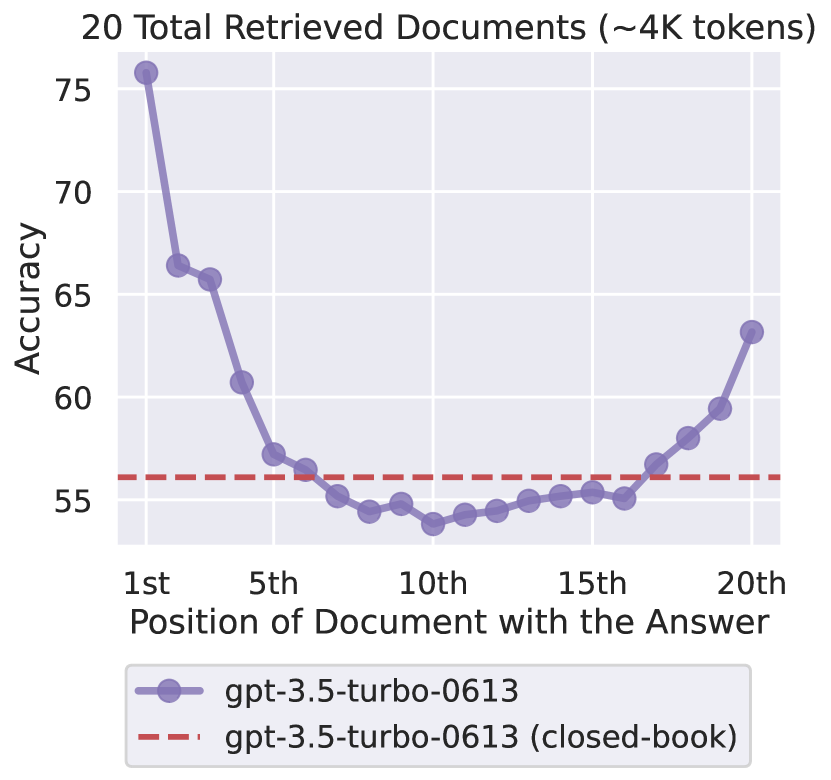
图源:Liu et al., “Lost in the Middle: How Language Models Use Long Contexts”, 2023. Figure 1——当相关信息放在上下文开头或结尾时模型表现最好,放在中间时性能显著下降(U 形曲线)。
-
上下文没有逻辑结构
:10 个 chunk 拼在一起就是 10 段互不相关的文本,模型要自己理清关系。
进阶做法:
-
去噪
:只保留 Rerank 分数高于阈值的 chunk,宁少勿多。
-
排序优化
:关键 chunk 放开头和结尾,次要信息放中间。
-
结构化提示
:给每个 chunk 标上来源、ID、与问题的关系标签,帮助模型理解上下文的组织方式。
4.2 引用强约束:降幻觉最有效的工程动作
如果你只能做一件事来降低幻觉,做引用强约束。
引用不是"在 prompt 里写一句’请加引用’"就完了。必须在三层同时强制:
第一层:Prompt
每条事实陈述必须紧跟 [doc_id:chunk_id] 标签。没有标签的陈述视为非法输出。示例:WebView 支持离线包加载 [doc_3:chunk_7]。
第二层:解码约束
用结构化输出(JSON Schema / 约束解码)强制输出 {statement, citations[]} 结构。无引用的字段直接报错。
第三层:后处理校验
对每条 statement,用嵌入相似度 + Rerank 检查它是否真的被 citations 段落支撑(Groundedness 校验)。不通过的整条丢弃或降级显示。工具:TruLens Groundedness / RAGAS Faithfulness。
实测数据:只做 prompt 层时,Faithfulness 通常在 0.65-0.78;补上后处理校验后,普遍抬到 0.85+ 。
踩坑现场:某金融客服上线时只做了 prompt 层,月度审计抽 200 条,发现 18% 的"引用"指向的段落里根本没有该结论。后处理校验补上后降到 < 2% 。只做 prompt 不做校验 = 引用是装饰。
4.3 自反思与迭代:从一次生成到多轮修正
有些问题不是一次检索 + 一次生成就能答好的。这时需要"反思 + 迭代"机制:
CRAG 兜底(轻量级)
前面讲的 CRAG 评估器判为 Ambiguous/Incorrect 时,触发兜底策略:
- L1 本地库 → L2 关联库/权威源 API → L3 白名单 Web 搜索 → L4 拒答
每一级带置信度阈值。Web 兜底千万不能用通用搜索——SEO 垃圾页面会直接污染答案。某券商 RAG 因 Web 兜底搜到 SEO 财经站的错误推断,输出"乐观业绩指引"被截图传播 。
Agentic RAG(中量级)
把"是否再查一轮"从模型内省变成可观测、可干预的外部决策回路:图:Agentic RAG 迭代回路——Critic 评估答案充分性,不充分则识别缺失信息生成补充查询,超过轮次限制则输出当前最佳结果。
关键工程约束:
-
必须有硬性预算闸门
:最大轮数、最大 Token、最大耗时,三条线任一触发立刻终止。没有闸门的 Critic ↔ Planner 回路必然有任务跑飞。
-
2026 年的共识:在 70% 场景下,"单 Agent + 工具调用 + 一次自检"比四角色 Multi-Agent 更好。准确率持平,成本和延迟降一半。
踩坑现场:某客服团队搭了 6 个 Agent Deep Research(重量级)
当任务是"产出一份带计划、过程、引用、反驳的研究报告"时,进入 Deep Research 通路:
- 显式研究计划 → 迭代式探索(50-200 次 LLM)→ 跨源交叉验证 → 引用透明的合成
Deep Research 的真正瓶颈不是模型,是"好题目"。同一系统,问题质量决定上限。前置一个"题目澄清 Agent"——1-2 轮反问把模糊题转成可研究的题——带来的报告质量提升通常远大于再调 Critic / Synthesizer。
必须异步任务化:任务 ID + SSE/WebSocket 进度流 + 中途可查看草稿 + 可中断重跑。分钟级任务不能阻塞前端。
4.4 Memory-Augmented RAG:跨会话的上下文持续构建
如果说 RAG 解决的是"从知识库给 LLM 补充上下文",那 Memory 解决的是"从用户历史给 LLM 补充上下文"。
但 90% 的"AI 没记忆"抱怨根本不是 Memory 系统能解决的,而是产品层问题:
- 前端每次新会话不传 history
- 多端不同步
- 会话窗口被过早截断
先排查产品层三个洞,再考虑 Memory 系统。 这三个洞补完,仍有跨数十轮、需要主动抽取偏好的场景,才轮到 Memory。
真需要时,分层落地:
| 记忆层 | 存什么 | 怎么存 |
|---|---|---|
| 工作记忆 | 当前 context window(最近 N 轮) | 直接在 prompt 里 |
| 情景记忆 | 历史对话事件(带时间戳) | 向量库,按相关性召回 |
| 语义记忆 | 抽取出的偏好/画像 | 结构化 KV 或图谱 |
| 程序记忆 | 高频成功路径 | 沉淀为技能模板 |
代表方案:MemGPT(LLM 当 OS) / Mem0(显式抽取+冲突合并+衰减) / A-MEM(Zettelkasten 风格带 link) [论文:MemGPT,2023][论文:A-MEM,2025]。
踩坑现场:某长程对话产品上 Mem0 一个月,每次回复带 5-10 条记忆,token 成本上涨 3.8 倍,NPS 反而下降——用户抱怨"它老提我之前说过的事,有点烦" 。Memory 系统的核心配置不是"能记住多少",而是"什么时候不该被提起"。
4.5 生成侧各范式速览
| 范式 | 解决什么 | 核心机制 | 典型成本 | 适用场景 |
|---|---|---|---|---|
| 引用强约束 | 幻觉 + 可追溯 | prompt + 解码 + 后处理校验 | +50-200ms | 所有场景必配 |
| CRAG 兜底 | 长尾/时效/覆盖不全 | 评估器分级 + 多源回退 | +1-4s(触发时) | 知识库覆盖率 < 90% |
| Agentic RAG | 复杂多步任务 | 单 Agent + 工具 + Critic | 3-10 次 LLM | 多跳/跨源/业务分析 |
| Deep Research | 研究级报告 | 显式计划 + 迭代探索 | 50-200 次 LLM | 研究/尽调/深度分析 |
| Memory-RAG | 跨会话个性化 | 四层记忆 + 写入/遗忘策略 | 随使用时长线性增长 | 长程助手/客服 |
到这里,从文档输入到答案生成的链路走完了。但还有一个问题没解决:你怎么知道系统在变好?
- 评测闭环与持续迭代
5.1 为什么 BLEU/ROUGE 不行
很多团队还在用 BLEU/ROUGE 评 RAG 系统。问题在于:这些指标衡量的是"答案和标准答案的词重叠度",而 RAG 系统的答案形式千变万化——同一个正确答案可以有完全不同的措辞。
RAG 评估必须是多维度的,至少覆盖六个方面:
| 维度 | 工具/指标 | 衡量什么 |
|---|---|---|
| 检索质量 | nDCG@k / Recall@k / MRR | Embedding/Rerank 的召回精度 |
| 答案忠实度 | RAGAS Faithfulness / Answer Relevance | 答案是否基于检索到的上下文,是否切题 |
| 可追溯性 | TruLens Groundedness / 自研引用对齐 | 每句话是否有可靠出处 |
| 复杂任务 | GAIA / FRAMES / MultiHop-RAG | Agentic/Deep Research 的端到端能力 |
| 长程记忆 | LongMemEval / LoCoMo | Memory 系统的跨会话一致性 |
| 业务指标 | 解决率 / 转人工率 / NPS / 拒答率 | 上线后的真实用户体验 |
5.2 指标门禁:不准跌破的红线
评估指标的核心不是"看它有多高",而是设一条"不准跌破"的红线。每次发版前跑回归,任一维度跌破红线直接回滚。
实操建议:
-
Faithfulness ≥ 0.80
:低于这条线幻觉率让用户无法信任。
-
Recall@10 ≥ 0.70
:低于这条线意味着 30% 的相关信息被漏掉。
-
引用准确率 ≥ 0.90
(合规场景):低于这条线审计过不去。
-
拒答率监控
:有效拒答率(拒答里确实是无证据的占比)应 > 80%,否则说明拒答太激进。
没有门禁 = 每次发布都在赌运气。
5.3 线上 trace 回流:RAG 持续变好的唯一办法
离线评测集有一个天然缺陷:三个月不更新就完全脱离线上分布。用户的提问方式、热点话题、知识库内容都在变化。
解决方案:把线上(用户问 + 检索召回 ID + Rerank 分数 + 模型答 + 用户反馈)每周回流到离线评测集,跑回归。这就是评测闭环:
线上 trace → 采样标注 → 加入离线评测集 → 跑回归 → 发现退化 → 修复 → 发版 → 线上 trace ...
5.4 评测 Agent 的"乐观偏差"
在实践中发现了一个重要现象:
| 评测 Agent 判定 | 人工校验结果 | 含义 |
|---|---|---|
| “需改进” | 几乎都确认为坏 | 精准率高 |
| “优秀” | 相当比例标为"坏" | 召回率低 |
模型在评估自身或同类模型输出时,有显著的"乐观偏差"——在证据不足或知识覆盖不全时,模型往往无法意识到自己"不知道",反而给出看似合理的高分。
结论:LLM-as-Judge 可以用,但人工校验不可或缺。 建议每周抽检 50-100 条,校准 LLM 评估器的偏差。
5.5 不同范式的评估口径速查
| 范式 | 必看离线集 | 必看在线指标 |
|---|---|---|
| Advanced RAG | BEIR / MTEB / 自建集 | 引用 CTR、无结果率 |
| GraphRAG | 论文 Podcast/News + 自建全局集 | 单次成本、全面性反馈 |
| LightRAG | UltraDomain + 增量评测集 | 索引更新 P99、Token 成本 |
| HippoRAG-2 | MuSiQue / HotpotQA / 2WikiMultiHopQA | 多跳解决率、平均轮次 |
| CRAG | PopQA / Biography / PubHealth | 兜底触发率、触发后准确率 |
| Agentic RAG | GAIA / FRAMES / 业务任务集 | 任务成功率、平均调用轮次 |
| Deep Research | GAIA L1-L3 / BrowseComp | 引用准确率、用户采纳率 |
| Memory-RAG | LongMemEval / LoCoMo / PerLTQA | 跨会话事实一致性 |
- 最后
6.1 全链路回顾
回顾全文的数据流:
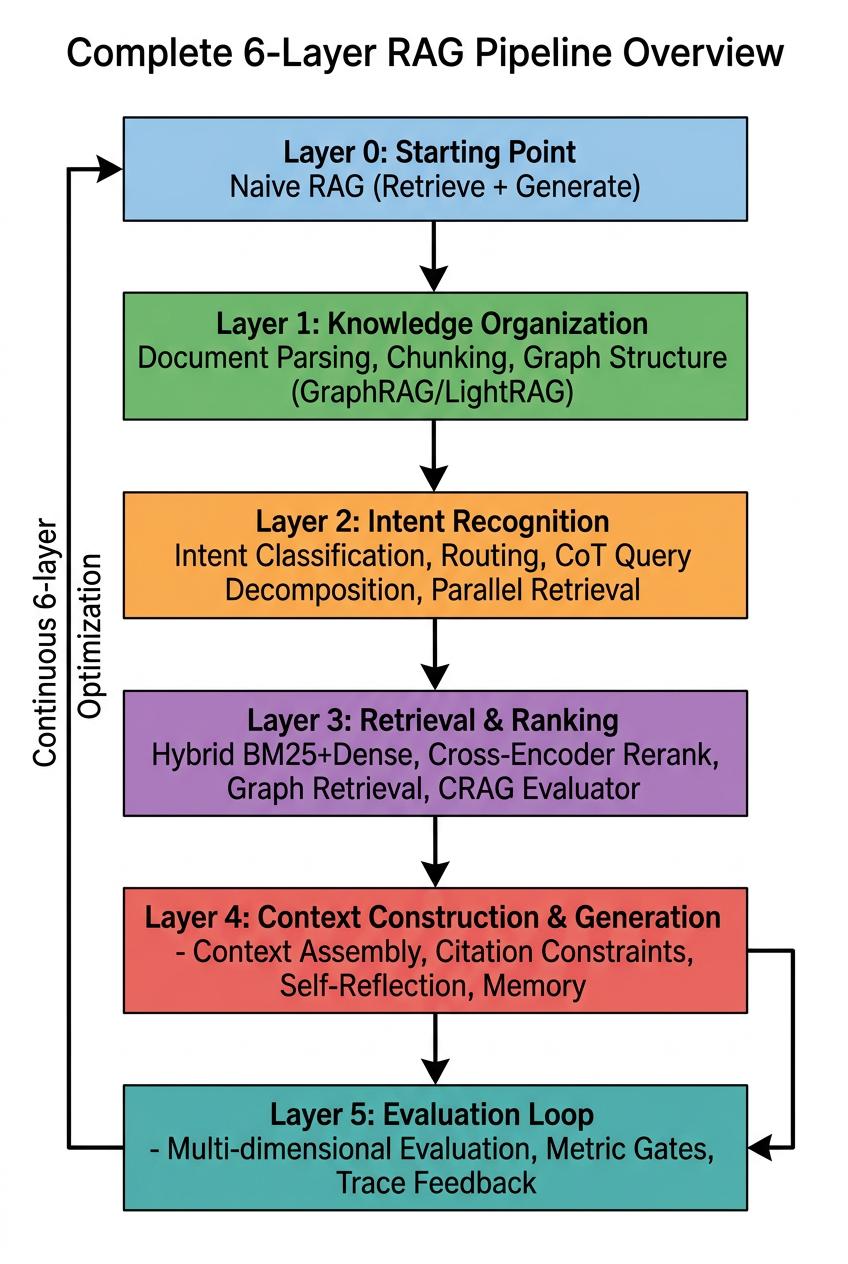
图:RAG 系统数据流全景——从 Naive RAG 起点,经知识组织、意图识别、检索排序、上下文构建,到评测闭环驱动持续优化。
这些环节的关系是递进的:知识组织决定检索上限,意图识别决定检索方向,检索决定上下文质量,上下文决定答案质量,评测闭环驱动所有环节持续改进。
6.2 实践建议
-
由浅入深,逐步加固
:先跑通 Naive RAG,再沿数据流逐步升级。跳过 Hybrid + Rerank 直接堆 GraphRAG 是本末倒置。
-
意图识别先于检索
:拿到 query 不要直接检索。先理解、分类、分解、规划,再去找。
-
Rerank 是性价比之王
:多数业务加一层 Cross-Encoder Rerank 比换 Embedding 收益高一个量级。
-
引用强约束是降幻觉最显效的动作
:prompt + 解码 + 后处理三层缺一不可。
-
每个范式都要预算"副作用"
:上 GraphRAG 预算索引成本、上 Agentic 预算延迟、上 Memory 预算合规、上 Deep Research 预算 Token。
-
可观测性建在第一天
:trace / Faithfulness / token 成本 / 延迟分位线 / 检索召回 ID 全要落地。
-
灰度回滚是底线
:Embedding / Chunk 策略 / Reranker 变更必须支持双库并行 + 流量切分 + 一键回滚。
-
评测口径锁死再上线
:没有评估闭环 = 没有改进。指标不固化等于没评估。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)