大模型后训练大比拼:SFT、RLHF、PPO、DPO、GRPO、AsymRE、OD,哪个才是你的“神技”?
本文对比了六种主流大模型后训练算法:SFT(监督微调)、RFT(拒绝采样微调)、PPO(近端策略优化)、GRPO(组相对策略优化)、AsymRE(非对称REINFORCE)和OD(同策略蒸馏)。SFT和RFT属于纯监督派,PPO和GRPO是同策略强化学习派,而AsymRE和OD则属于异策略与蒸馏派。文章分析了每种算法的核心逻辑、优缺点及适用场景,强调了没有一种算法是万能的,实际应用中往往需要组合使用。
最近看到了SDPO和AsymRE这两篇论文,对于后训练技术区别有点混淆,所以正好总结一下和各个主流算法的区别,给自己做一个笔记。
如果你在过去一年里关注过大语言模型(LLM)的训练,你一定被满天飞的缩写词轰炸过:SFT、RLHF、PPO、DPO、GRPO……最近又冒出了 AsymRE 和各类蒸馏(Distillation)大法。
如果把预训练(Pre-training)比作让模型“博览群书获取知识”,那么后训练(Post-training)就是“教它如何懂礼貌、有逻辑地回答问题”。今天,我们就来扒一扒,目前主流后训练与对齐算法,到底都在玩什么套路,它们之间又有什么爱恨情仇。
第一梯队:纯监督派
1. SFT (Supervised Fine-Tuning / 监督微调)
- 核心逻辑:“照我说的做,死记硬背。”
- 怎么玩:人类或强模型写好高质量的“问题-答案”对,强迫模型逐字逐句地模仿(交叉熵损失)。
- 优点:简单、直接、稳定。只要数据质量极高,模型很快就能学会特定格式(比如 JSON 输出、礼貌用语)。
- 致命伤:分布偏移与上限锁死。模型只是在“模仿”表面规律,并不知道“为什么”好。一旦遇到没见过的问题,容易胡言乱语(幻觉);而且上限被人类标注者/数据集的水平死死卡住。
2. RFT (Rejection Sampling Fine-Tuning / 拒绝采样微调)
- 核心逻辑:“海选大比拼,只留状元郎。”
- 怎么玩:面对一个问题,让模型自己生成 N 个不同的回答,用奖励模型(Reward Model)或规则打分, 把低分的直接扔进垃圾桶,只留下最高分的回答,拿最高分的回答做 SFT。
- 优点:极其适合起步!它是很多开源大模型(如 Llama 早期版本)极爱用的 Baseline,能迅速提升模型下限。
- 致命伤:数据极度浪费且缺乏梯度感知。生成 100 个回答扔掉 99 个,算力在燃烧!更惨的是,80分和100分的回答在 SFT 损失函数里权重一模一样,模型学不到“更好”和“一般好”的连续差异。
第二梯队:同策略强化学习派
为了突破 SFT 的天花板,强化学习(RL)登场了。模型不再死记硬背,而是通过不断试错,根据环境给的“分数(Reward)”来调整自己的策略(Policy)。这一派的特点是 On-policy(同策略),即必须用当前自己最新生成的答案来更新自己。
3. PPO (Proximal Policy Optimization)
- 核心逻辑:“稳扎稳打的六边形战士。”
- 怎么玩:OpenAI 掀起 RLHF 浪潮的绝对核心。引入了一个庞大的系统:Actor(生成网络)、Critic(打分网络,预测当前状态有多好)、Reward Model(奖励模型)和 Reference Model(参考模型,防止学偏)。
- 优点:数学基础扎实,上限极高,能真正激发模型的涌现能力和探索精神。
- 致命伤:显存杀手,极其难调。要同时在显存里塞下 4 个模型!而且超参数极多,奖励稍微崩坏一点,模型就会变成只会钻系统漏洞的“刷分狂魔”。
4. GRPO (Group Relative Policy Optimization)
- 核心逻辑:“同侪压力下的内卷之王。”
- 怎么玩:DeepSeek Math 和 R1 将其发扬光大。砍掉了极其占显存的 Critic 模型。面对一个问题,模型生成一组(Group)回答(比如 8 个),然后在这 8 个回答内部算平均分。比平均分高的给正反馈,低的给负反馈。
- 优点:极度省显存! 计算逻辑极其优雅,非常适合做数学、代码这种有明确客观标准的任务。
- 致命伤:高度依赖 On-policy。这组回答必须是模型“刚刚”生成的。如果模型变强了,你拿它三天前生成的旧数据喂给 GRPO,算出来的新旧策略概率比值会爆炸,直接把训练搞崩。
第三梯队:异策略与蒸馏派
On-policy 强化学习好是好,但每次更新都要让模型实时生成一大堆数据,推理算力成本高得吓人。于是,近两年前沿研究开始探索如何高效利用旧数据和外部力量。
5. AsymRE (Asymmetric REINFORCE)
- 核心逻辑:“淘金旧日记忆,无视过往败绩。”
- 怎么玩:引入经验回放(Experience Replay)缓冲区。把模型历史生成的旧数据存起来循环利用。为了解决旧数据带来的方差爆炸,它扔掉了 GRPO/PPO 里的重要性采样比率,并设置了一个“刻意压低的及格线 V”。
- 优点:省下海量推理算力! 模型不再需要频繁实时生成数据,而是可以不断“反刍”历史高分错题本。它不对旧日的低分失败经验进行严厉惩罚(非对称),只强化那些突破阈值的成功轨迹。
- 定位:它是为了解决大规模 RL 训练成本过高而诞生的工程补丁,也是RFT的精神继承,或许对现在的Agent和长程(Long-Horizon)任务有帮助。
6. OD(On-policy Distillation/同策略蒸馏)
- 核心逻辑:“名师不仅给标准答案,还要亲自批改你的作业。”
- 怎么玩:传统的 SFT 蒸馏(用 GPT-4 生成数据喂给小模型)会有分布差异(GPT-4 的说话习惯小模型学不来)。On-policy 蒸馏是让小模型(Student)自己生成回答,然后让大模型(Teacher)对小模型生成的特定轨迹进行打分或提供 Logits 引导。最近提出的SDFT和SDPO算法通过Prompt工程构造自教师(Self-Teacher)省去了教师模型的束缚。
- 优点:完美弥合了分布鸿沟。小模型是在自己的能力边界(自己的生成分布)内,接受最强老师的“手把手定向辅导”。这是目前将复杂推理能力下放给小参数模型最有效的手段。
- 定位:仍然处于探索阶段,比如GLM-5中用到了OD来蒸馏不同阶段的能力。
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
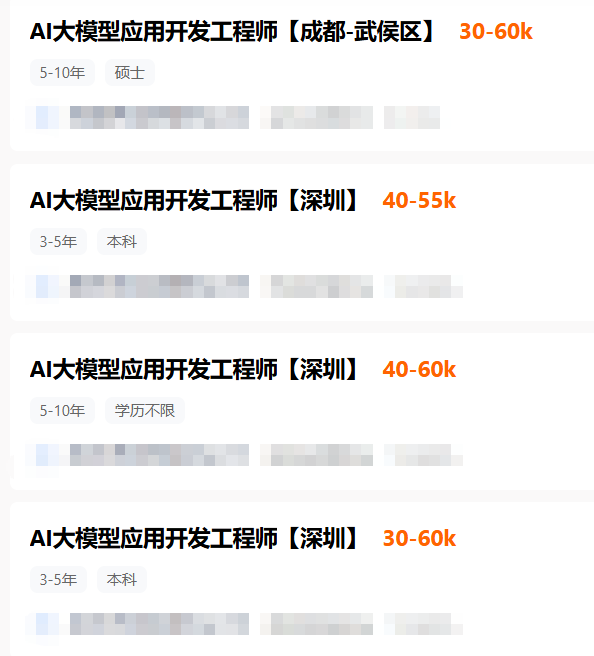
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献198条内容
已为社区贡献198条内容

所有评论(0)