从碎片到体系:为什么要放弃 RAG,转向 LLM Wiki
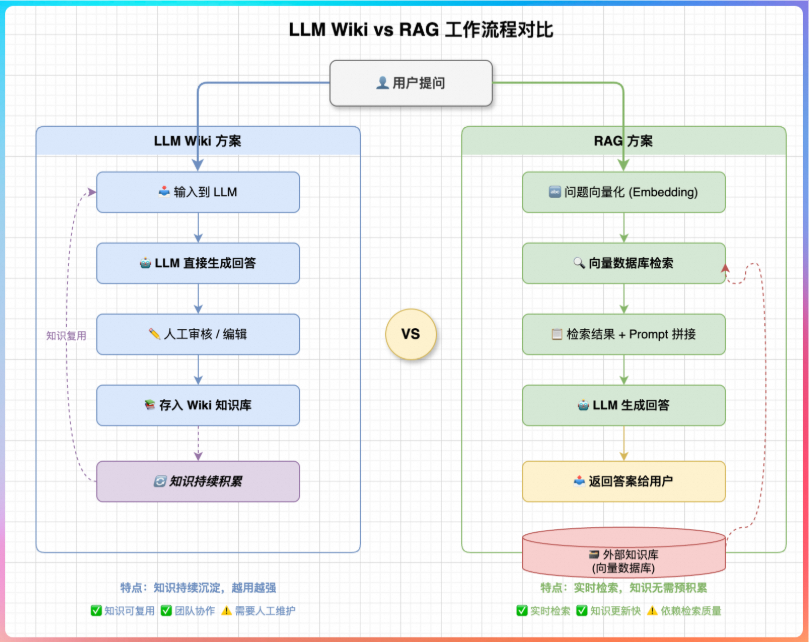
你是否曾满怀期待地将几十份技术文档喂给 AI,却在提问时发现它依然像第一次听说这个话题?答案东拼西凑、逻辑断裂,甚至自相矛盾——这并非模型不够强,而是你用错了范式。当前主流的 RAG(Retrieval-Augmented Generation,检索增强生成),本质上是一种“一次性问答”机制:它不积累、不综合、不进化。每一次查询,AI 都在重新发明轮子。
而一种由前 Tesla AI 总监 Andrej Karpathy 提出的新方法——LLM Wiki——正在颠覆这一局面。它不再让 AI 在查询时临时翻找碎片,而是提前将原始材料“编译”成一个结构清晰、交叉引用、持续演化的知识库。正如 Karpathy 所言:“我把绝大多数 token 花在构建一个围绕研究兴趣的可演化知识库上。”
这不是工具升级,而是一场知识管理范式的革命。
一、RAG 是什么?以及它为何注定“无积累”
RAG 是当前企业级 AI 应用的标准架构:用户上传文档 → 系统将其切分为小块(chunks)→ 生成向量嵌入并存入数据库 → 查询时检索最相关的片段 → LLM 基于这些片段生成答案。
这一流程看似合理,却被多位实践者指出存在根本缺陷:
-
每次查询都是从零开始:AI 不会记住上次的结论,也无法利用历史交互优化理解。
-
无法实现跨文档综合:若问题需整合五篇论文的观点,RAG 只能召回若干片段,由 LLM 临时拼接,极易遗漏关键上下文或逻辑链条。
-
矛盾被忽略:当文档 A 说“X 成立”,文档 B 说“X 不成立”,RAG 不会主动发现或标注这一冲突。
-
知识无法沉淀:用户的探索成果(如深度分析、对比表格)消失在聊天记录中,无法反哺知识库。
二、LLM Wiki:从“检索碎片”到“编译知识”的范式跃迁
LLM Wiki 的核心思想极为简洁却深刻:不是在查询时检索原始文档,而是在写入时让 LLM 增量地“编译”原始材料,生成一个持久化、结构化的 Wiki。
这意味着:
-
知识只需被处理一次;
-
后续所有查询都基于已综合好的高密度知识单元;
-
系统能自动维护一致性、发现矛盾、强化关联。
这种转变,类似于软件开发中从“解释型语言”到“编译型语言”的演进——牺牲一点写入开销,换取巨大的读取效率与系统稳定性。
三、LLM Wiki 的核心原理与设计细节
LLM Wiki 的强大源于其三层分离架构与三大核心机制,每一部分都针对 RAG 的缺陷精准施策。
1. 知识 → 编译提取:从原始材料到结构化知识单元
当新材料(如一篇论文)进入系统,LLM 并非简单索引,而是执行深度“编译”:
-
识别核心概念(如“分布式事务”、“两阶段提交”),为其创建独立页面(
wiki/concepts/distributed-transactions.md); -
提取关键实体(如“Redis”、“Kafka”),生成百科式条目(
wiki/entities/redis.md); -
归纳实践方法(如“缓存穿透解决方案”),形成可复用指南(
wiki/concepts/caching-strategies.md)。
wiki/
index.md # 全局目录
log.md # 时间线日志
overview.md # 全局综合判断
concepts/ # 概念页面
entities/ # 实体页面
sources/ # 来源摘要
syntheses/ # 回答积累这些页面不是原文摘录,而是经过提炼、去冗余、标准化的知识原子。后续查询直接基于这些高信噪比内容,而非原始噪声。
2. 显式构建关联关系:让知识成为网络而非孤岛
LLM Wiki 的关键创新在于主动建立语义链接:
-
每个概念页面末尾包含“相关概念”列表,并通过 Markdown 链接双向跳转;
-
当不同来源对同一事实有分歧时,页面中会显式标注“争议点”并引用对立观点;
-
新摄入的文档会触发对多个现有页面的联动更新(一次可能触及 10–15 个页面)。
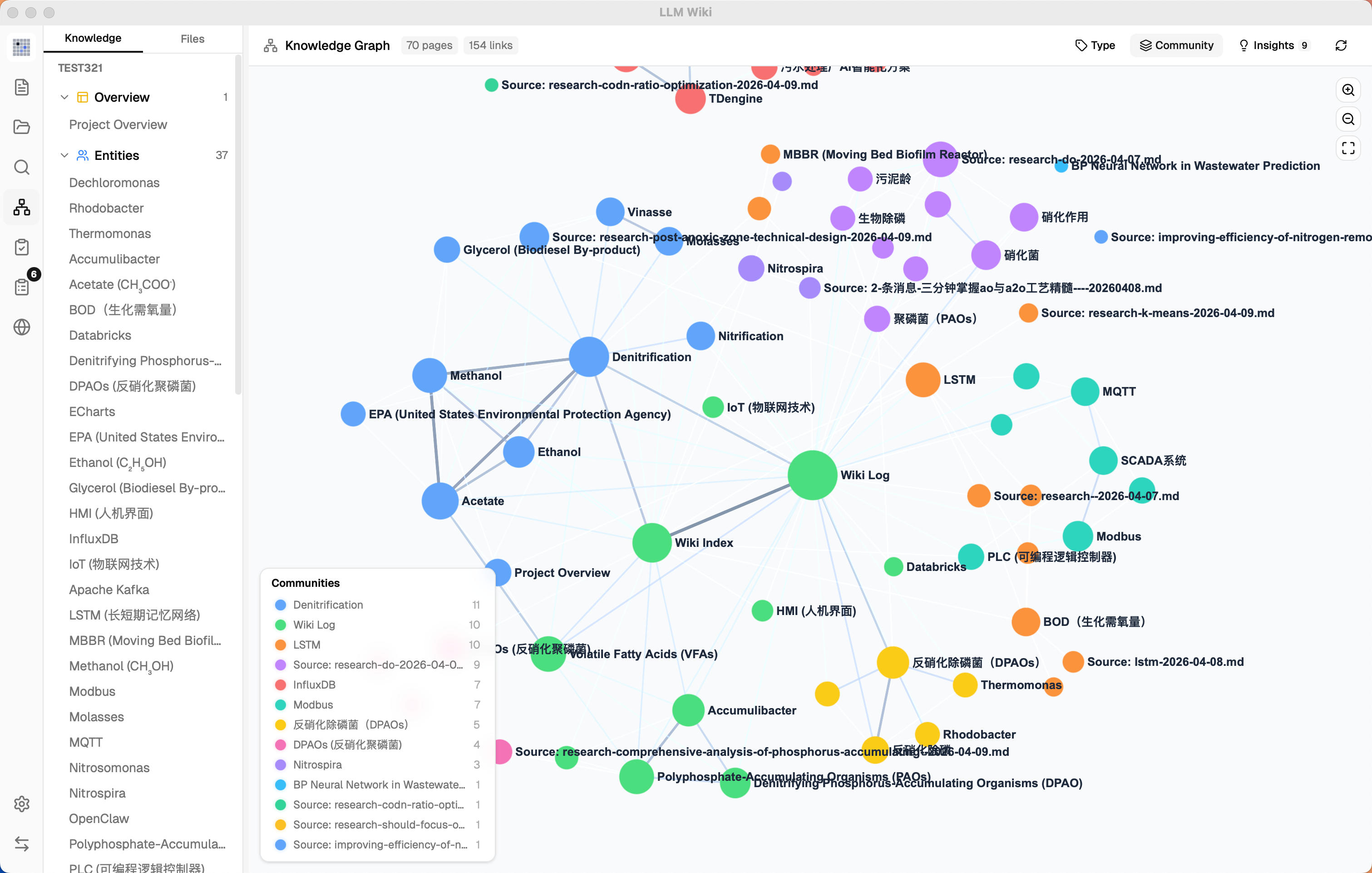
例如,在 entities/raft.md 中,不仅会描述 Raft 协议本身,还会链接到 concepts/consensus-algorithms.md,并与 entities/paxos.md 形成对比。这种显式的交叉引用使知识库具备推理能力,用户可通过 Obsidian 的图谱视图直观看到知识网络的连接密度。
3. 高效检索:基于索引与结构,而非向量相似度
LLM Wiki 在中小规模(<1000 文档)下无需向量数据库。其检索机制依赖两个精心设计的文件:
-
INDEX.md:全局导航页,按类别列出所有知识页面,并附带一句话摘要。LLM 查询时首先阅读此文件,快速定位相关主题。 -
内部链接结构:每个页面通过
[[ ]]或[link](path)显式引用其他页面,形成可遍历的知识图谱。
Karpathy 指出:“在一个约 100 篇文章、40 万字的项目中,我直接向 LLM Agent 提出复杂系统性问题……没有引入 RAG,而是依赖 LLM 对 Wiki 的‘内生理解’能力。”
此外,用户的高质量查询结果(如对比表、综述)会被自动归档至 wiki/queries/,成为新知识节点,实现“探索即贡献”。
四、结尾:人机协同的新契约:AI 负责记账,人类专注思考
Karpathy 并未提出新的算法或架构,他真正贡献的是一种回归本质的工作流设计:将大语言模型从“即时问答工具”重新定位为“知识系统的长期维护者”。正如他在 X 上所强调的,他把“绝大多数 token 花在构建一个围绕研究兴趣的可演化知识库上”,而非反复生成临时回答。
这一模式之所以有效,是因为它精准匹配了人与 AI 的能力边界。人类擅长提出深刻问题、判断信息价值、设定研究方向;而 LLM 擅长执行重复性认知劳动——阅读大量文本、提取结构化信息、建立交叉引用、保持格式一致,并在新证据出现时更新旧结论。这些任务对人而言枯燥且难以持久,对 AI 却是天然适配的“体力活”。
开源项目 WikiLLM 进一步验证了这一理念:“LLM 编写和维护所有 Wiki 数据,手动编辑很少见……用户的探索和查询结果被归档回 Wiki,增强知识库。”这意味着,知识不再随对话结束而消失,而是沉淀为可复用、可追溯、可演化的资产。
最终,LLM Wiki 不是关于“让 AI 替代思考”,而是关于构建一个值得信赖的认知伙伴——它不会遗忘,不会偷懒,也不会因情绪而忽略细节。在这个系统中,AI 负责“记账”,你负责“决策”;机器维护一致性,人类专注创造性。这或许正是个人知识管理在 AI 时代最务实也最有力的进化方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)