选择大模型API服务,需警惕吃掉利润的3个“隐形税”
我们团队是做智能客服的,主要业务是为淘宝等电商用户提供 AI 自动回复和智能助理服务。简单来说,就是向算力平台买大模型 API 能力,做成产品卖给商家。
在这个赛道摸爬滚打了一段时间,随着商家对复杂客服场景的要求越来越高,最近两个月我们把业务模型全线升级为MiniMax-M2.5——选它主要是因为工具调用能力强、中文回复有“人味”,很适合客服场景复杂的对话需求。
运行两个月后,上个月一对账,发现账单比同样用MiniMax-M2.5的同行高出一大截。查了一下,大家业务体量相当,官方 API 输入输出定价完全一致。既然标价一样,为什么两个月下来,我们的实际综合成本比别人多出了上千元?
经过彻夜复盘、搜集底层调用数据,我终于搞明白了这个窟窿:在真实的工程落地中,算力平台的底层能力差异,正逼着我们交三笔昂贵的“隐形税”。
一、延迟税
平台响应慢,你的业务就在流失客户。
我们最开始选了一家知名度很高的算力平台。价格透明,文档齐全,上手很快。
但用了一段时间发现一个问题:慢。
做客服,最重要的就是时效性,用户那边根本等不起。买家发一张商品有问题的照片,模型要思考好几秒才回复。MiniMax-M2.5 官方以响应快著称,结果在这家平台上首Token延迟平均超过 2 秒,高峰时段甚至接近 3 秒。
现在这种快节奏社会,问客服一个问题,3 秒才回——买家早关窗口了。
后来我查了 AI Ping(第三方监测平台)的数据才发现,同样跑 MiniMax -M2.5,不同算力平台的 P90 延迟差距极大:最低的只有 0.37 秒,最高的甚至超过 10 秒,差了 20 多倍。
这意味着什么?你的单位时间服务能力直接被平台延迟卡死。要维持同样的用户体验,你只有两条路:要么加钱上专属资源池(成本飙升),要么忍受响应变慢带来的用户流失(收入损失)。无论哪条路,都是代价。
本质:平台响应慢,逼你为“保持服务水平”支付溢价。
二、波动税
时快时慢,逼你按最差情况做规划。
如果说“慢”还能忍,那“时快时慢”就真的让人崩溃了。
我们踩的第二个坑,仍然是上面那家平台。好处是模型切换灵活,坏处是——不稳。
监控数据显示,白天业务高峰期(淘宝商家咨询最忙的时候),它的吞吐量经常掉到 20 多 tokens/s;到了后半夜没人用,又能飙到 90 多。
这种波动带来的问题是什么?
作为服务商,我们要给商家承诺稳定的 SLA。做容量规划,你不能按“最快的时候”来设计,只能按“最慢的时候”预留资源。
假设一个平台最快 100 tokens/s,最慢只有30,波动 3 倍多。你要保证服务不崩,只能按 30来规划容量。这意味着,在大部分时间里,你预留的资源有 70% 是闲置的。
你为“最差情况”的安全感,付了大量冤枉钱。 这些钱要么自己扛,要么摊给商家,两头不讨好。
我们后来注意到了一个“波动系数”指标:系数 2.0x 意味着最低值是峰值的一半;系数 3.7x 意味着最低值只有峰值的 27%。
波动系数越低,你越不需要为“最差情况”过度配置。这就是“过度配置税”。
本质:平台不稳定,逼你按最差情况规划容量,大量资源闲置。
三、返工税
请求失败,Token 不退,还得重跑。
第三笔税最让人窝火。
有一次我们用 API 跑一个批量任务,跑了两个小时,结果中途网络波动,一批请求超时了。
我去翻账单,发现那些超时的请求已经被扣费了。模型已经生成了部分 Token,但因为连接中断,这些 Token 我没拿到——但钱已经花了。
更过分的是,我要重新跑这些失败的任务,又得再付一次钱。
同一个任务,付两次费,只拿到一次结果。这不是税是什么?
在大规模调用场景下,5% 的失败率意味着每月有 5% 的 Token 支出是纯浪费。
本质:平台不可靠,让你为失败和重试反复付费。
主备容灾,把减税落到实战
被这三笔税毒打之后,我们意识到绝不能将身家性命绑在一家平台上。
我们花了一周时间,通过 AI Ping 重新评估了市面上的主流算力服务商,最终锁定了两家做主备组合:蓝耘元生代 × 阿里云百炼。
先说蓝耘元生代。最初注意到这家,是因为看到有同行做过一轮横评测试。测试覆盖了蓝耘、硅基流动、金山云星流等六家主流服务商,统一跑 DeepSeek-V3.2(数据来源:AI Ping 公开评测,监测区间 2026年3月25日至4月1日)。结果显示,蓝耘在该区间内的综合表现相当亮眼——七日平均吞吐量达到 109.85 token/s,且最低峰也有 81.37 token/s 的吞吐量,延迟约为 1.14 秒。
当然,我们用的模型并非Deepseek,因此我们在评估算力服务商时,主要就是通过AI Ping观测各个服务商在MiniMax-M2.5上的表现,以最近的5月15日的数据快照为例,主备组合的性能指标如下(数据来源AI Ping 2026年5月8日至15日数据):
|
性能指标 |
蓝耘元生代 |
阿里云百炼 |
|
近7日平均吞吐量 |
110.92 token/s |
49.9 token/s |
|
近7日P90延迟 |
0.33 s |
4.77s |
|
波动系数 |
1.23x |
1.47x |
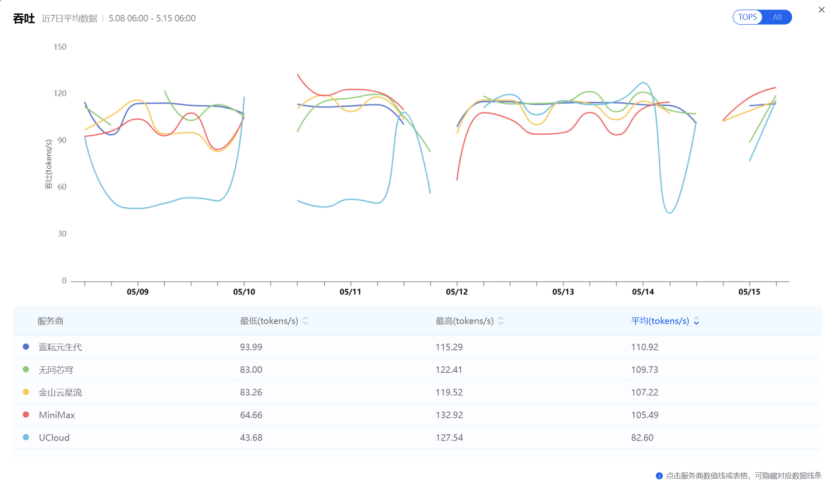
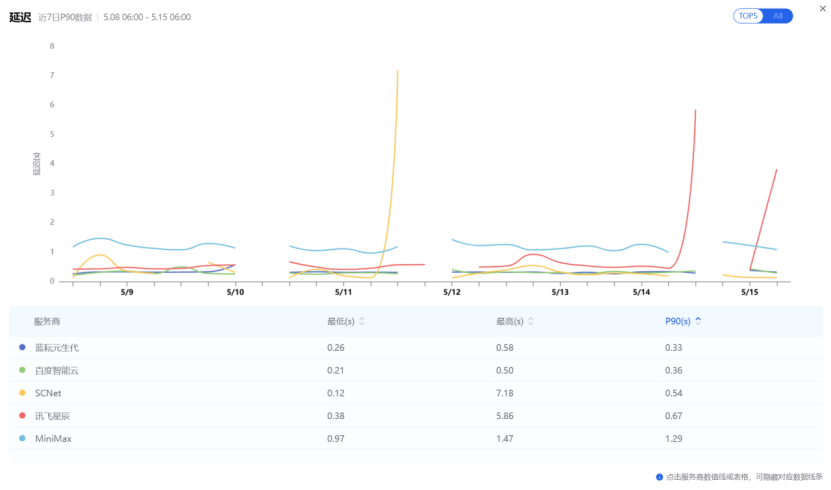
图:区间内,MiniMax-M2.5模型的吞吐量与延迟指标前五
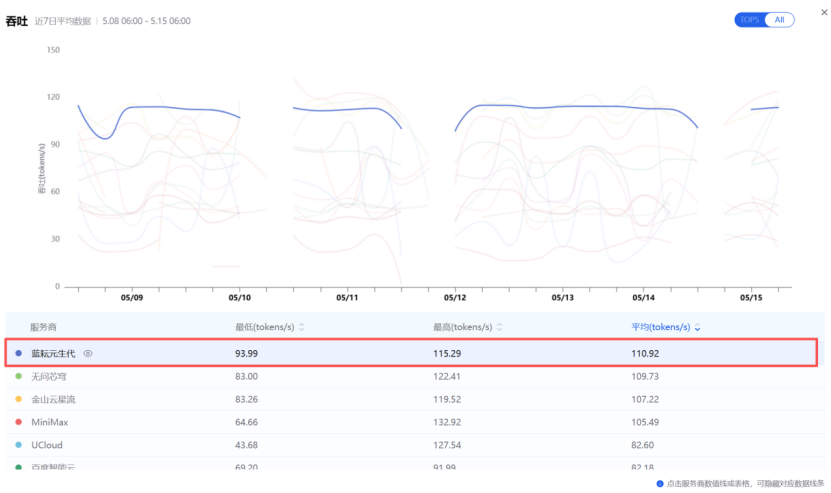
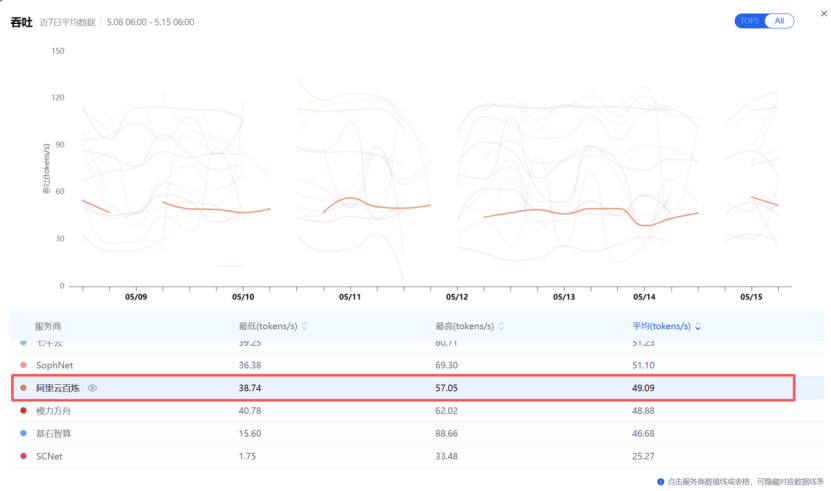
图:区间内,主备组合的吞吐量指标
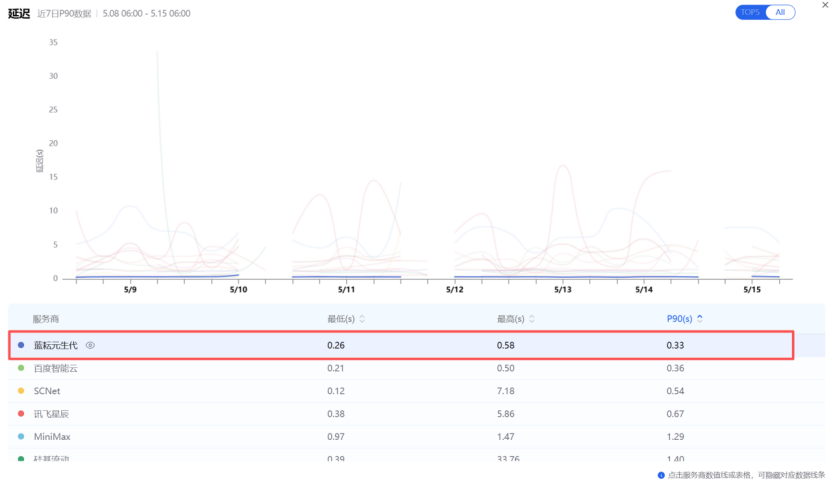
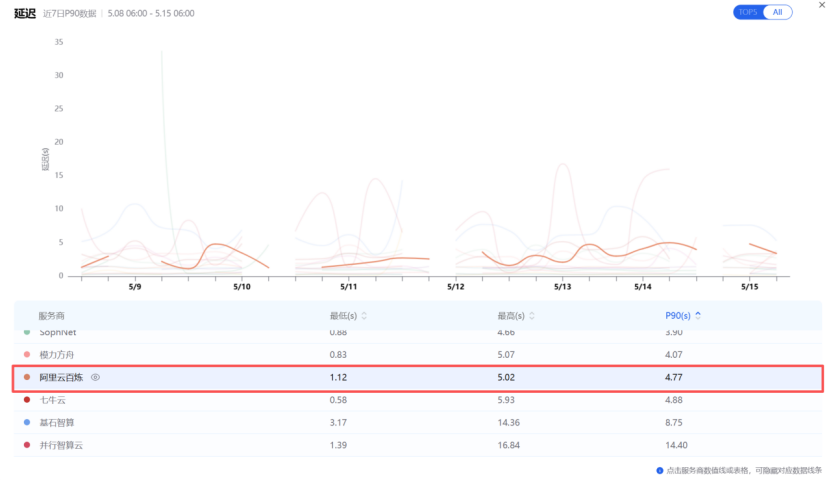
图:区间内,主备组合的延迟指标
数据表现整体可控,日常业务的主力流量都从它这里走。
再说阿里云百炼。 选择它的原因很简单:一方面我们的业务整体处于阿里的生态下,另一方面也是相信大厂品质,追求稳定,我们不指望它跑出多极致的性能,而是要它在我们蓝耘出状况的时候顶上。阿里云百炼一直保持着相对稳定的服务水平,虽然波动系数要高于蓝耘,但也稳定在2x以内,即使是晚高峰也很少出现雪崩式的性能衰退或长时间的瘫痪。
不过,阿里云百炼的API对单位时间内的请求数量和Token用量是有限流规则的,同时限制了请求数与Token量这两个维度。以他们的多模态网关为例,默认限流为10 QPS,支持每分钟新建600通会话、每小时新建超过3万通会话,常规业务场景完全够用,但对突发流量还是需要提前规划。
因此,我们把阿里云百炼定位为“备用节点”,不承担日常主力流量,只有在主路故障时才介入承载部分请求。
主备切换怎么玩:从理论到落地
光说不练假把式。下面是我们压测跑通并已经在生产环境上线的主备切换方案,涉及网关接入、日常流量分配、熔断检测、降级切换和配额管理几个核心环节。
1. 接入网关:抹平各家差异
我们在业务入口接入了一款统一的大模型网关,它屏蔽了蓝耘和阿里云百炼两家的协议差异。业务层的代码只管往统一的API接口发请求,网关在后端动态映射到不同的模型提供商上。网关内部维护了一个实时的“健康度映射表”,持续追踪各模型实际的服务质量,为路由决策提供数据支撑。
2. 日常流量分配:加权轮询
日常场景下,我们用的是加权轮询策略——不同平台被赋予不同的“权重”。蓝耘权重约为70%(主力),阿里云百炼约为30%(备用)。权重比例会根据压测反馈和业务的成本管控要求随时调整。
3. 熔断检测:多维度感知“状态不健康”
我们设定了三个维度的健康阈值:延迟维度(如果蓝耘的P95延迟连续 3 次超过 2 秒,视为不稳定)、错误率维度(如果蓝耘的5分钟错误率超过 5%,触发熔断)、限流维度(主要是监听阿里云百炼的429报错,避免回滚时被限流打崩)。
4. 配额管理:把限流风险提前消化掉
我们还在网关配置了令牌桶限速器,精准控制发往阿里云百炼的请求速率,不让它触达限流阈值,把429错误提前拦住。并且预留了双方的“固定预留资源包”作为安全垫,遇到大规模流量洪水时可以迅速扩容。
5. 未来规划:落地真正的“统一网关”
目前我们自己维护的这套网关,虽然能跑通主备切换,但监控、路由策略、密钥管理等都需要人工维护,本质上还是在交“管理税”。
最近我们调研了蓝耘团队推出的企业级大模型统一网关与调度平台,它的理念是“一套平台管理国内外主流AI模型”,能够“多模聚合·统一标准接入,一套代码调用全球20+主流模型,后台一键热切换”。
下一步我们计划把自建的网关逐步替换成蓝耘的统一网关,由它来承担智能路由、统一鉴权、成本可视化与高可用保障。这样既能彻底甩掉自建网关的运维包袱,又能进一步降低综合成本。
最后想说的是,这3笔“隐形黑洞”让我想明白了一个道理:
Token单价趋同之后,真正的成本差异来自于效率——谁能让你花出去的每个Token都变成有效的产出,谁的实际成本就更低。
最近看到蓝耘官网发了一篇文章,系统性地讲了“有效Token产出率”这个概念,跟我的踩坑经历完全对得上。有人说这叫“词元经济”——Token不再是单纯的计费单位,而是AI时代的生产要素。我觉得这个说法挺贴切的,或许未来的AI行业可能真的会按这个逻辑重新洗牌。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)