RAG技术爆火背后:它到底解决了什么难题?这一篇讲透核心与应用
衔接上一章 # Embedding不是魔法:把文字变成数字的底层逻辑。
在AI技术落地的实践中,LLM模型与Embedding模型虽同属“文字向量化”的技术范畴,却在核心定位与目标产物上展现出本质差异,二者的协同与边界,正是理解RAG技术价值的关键。
LLM模型: 推理模型,根据用户的问题,进行回答,是Agent主力模型;训练方式是监督学习+强化学习。
Embedding模型: 语义向量模型,1024维向量,进行向量上的相似度比较,帮我们进行数据的快速过滤,是过滤模型。
Word2Vec与Embedding模型的区别,核心在于定位不同:Word2Vec是Google开发的词向量训练工具,它的核心价值在于提供训练方法与技术路径;而Embedding模型是训练完成后沉淀的完整模型产物,Word2Vec正是打造这一模型的核心手段之一。
简言之,Word2Vec是“造模型的工具”,Embedding模型则是“工具产出的成果”,二者是技术实现链条上的上下游关系。
RAG的核心基石:切分策略决定效能上限
在RAG技术的落地过程中,文本的切分策略是容易被忽视却至关重要的环节。不同的切分方式、粒度把控,直接影响知识片段的完整性与关联性,进而决定检索时的匹配精度,最终左右RAG的整体效果。
可以说,切分策略的优劣,直接决定了RAG能否真正发挥检索增强的价值,是RAG落地的关键前提。
遇到Agent问题,我们会先去思考,处理流程:prompt —> context —> RAG —> llm
- 首先,我会检查写的prompt有没有问清楚;
- 然后再检查上下文是否缺乏背景知识,1、查看system prompt;2、历史会话信息;3、记忆系统;4、rule规则;5、RAG知识库;
- 最后再检查模型的能力是否不足,更换其他模型,或者Fine Tuning微调模型,做模型预训练;
这里简单说下Agent的架构:
Agent = LLM + Context + Prompt + Memory(RAG) + Tool(Function Call、MCP、Skill)+ Plan
RAG 虽能精准赋能知识储备,却难以实现能力的实质性进阶;
微调则如同一场系统化的知识深耕之旅,恰似历经大学四年的潜心研习,逐步沉淀并掌握专业能力(具体而言,可选取特定领域的问答数据开展针对性训练)。
RAG(Retrieval-Augmented Generation):
- 检索增强生成,是一种结合信息检索(Retrieval)和文本生成(Generation)的技术
- RAG技术通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性。
简单来说,你准备了一个向量知识库,从知识库找了一些跟它相关的知识,给到大模型,让大模型去完成任务
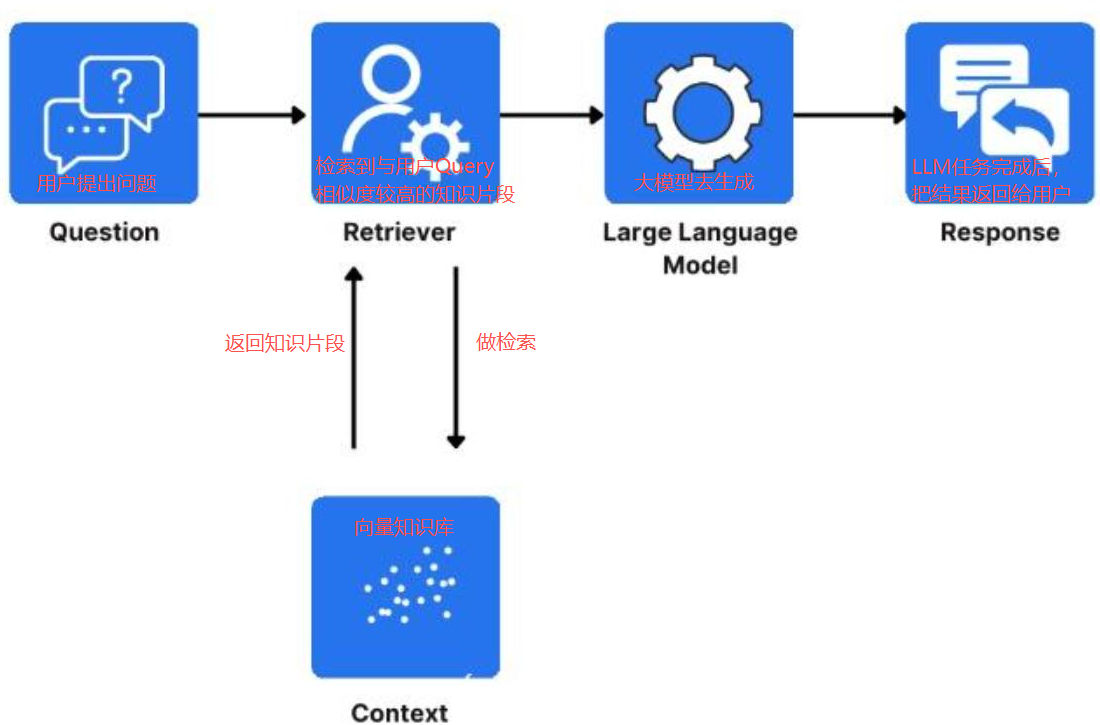
想了解prompt、RAG基础知识,可以看下我之前的文章 # 浅聊Prompt、向量知识库、RAG。
当LLM上下文迈向1M,RAG还有必要吗?
如今,LLM模型的上下文窗口持续扩容,已突破1M,未来似乎有望将所有知识直接纳入大模型。但现实问题是:RAG还用不用?它的核心价值究竟在哪?
答案很明确——RAG不仅不可替代,更能精准补足LLM的短板。
RAG的不可替代优势:直击LLM三大核心痛点
- 破解知识时效性困局:LLM训练数据存在明确截止时间,比如2025年3月,面对当下实时信息,其时效性天然不足。而RAG能直接检索外部知识库,实时获取最新资讯,轻松补上时效短板。
- 规避大token惩罚与幻觉风险:LLM存在大token惩罚机制,若Agent反馈信息不加筛选,极易触发限制,还可能滋生幻觉。RAG通过向量知识库检索关键内容,再经上下文工程压缩,为LLM精准输送核心信息,既规避了大token问题,又大幅减少幻觉。
- 约束LLM,深耕专业领域:LLM是通用型选手,缺乏垂直领域的专业约束,输出往往不够精准。RAG能为LLM划定专业边界,注入垂直知识库,让LLM的推理能力聚焦专业场景,大幅提升回答的专业度与精准度。
甚至,未来LLM能处理无限上下文,RAG仍有不可替代的意义!
- 效率与成本更优:LLM处理长上下文时,计算资源消耗巨大,响应速度也会变慢。RAG仅检索相关片段,大幅缩短输入长度,既省资源,又提效率。
- 知识更新更灵活:LLM知识固定在训练节点,无法实时迭代,而RAG可随时连接外部知识库,持续获取新信息,始终保持时效性。
- 可解释性更强:RAG的检索过程全程透明,用户能直接查看信息来源,可信度拉满;LLM的生成逻辑则难以追溯。
- 定制更精准:RAG可针对特定领域定制检索体系,输出结果更贴合需求;LLM的通用性难以满足细分场景的精准诉求。
- 隐私更有保障:RAG支持本地或私有数据源检索,敏感数据无需上传云端,完美适配高隐私要求的场景。
RAG核心价值:精准筛选,为LLM减负增效
RAG的核心价值,就在于高效过滤掉不相关的信息片段,为LLM精准筛选出关键知识。结合LLM的生成能力与RAG的检索能力,既能发挥LLM的推理优势,又能依托RAG的精准筛选,让整体性能再升级,输出更全面、准确的答案。
简言之,RAG的筛选能力,正是其不可替代的关键所在!
RAG检索增强生成架构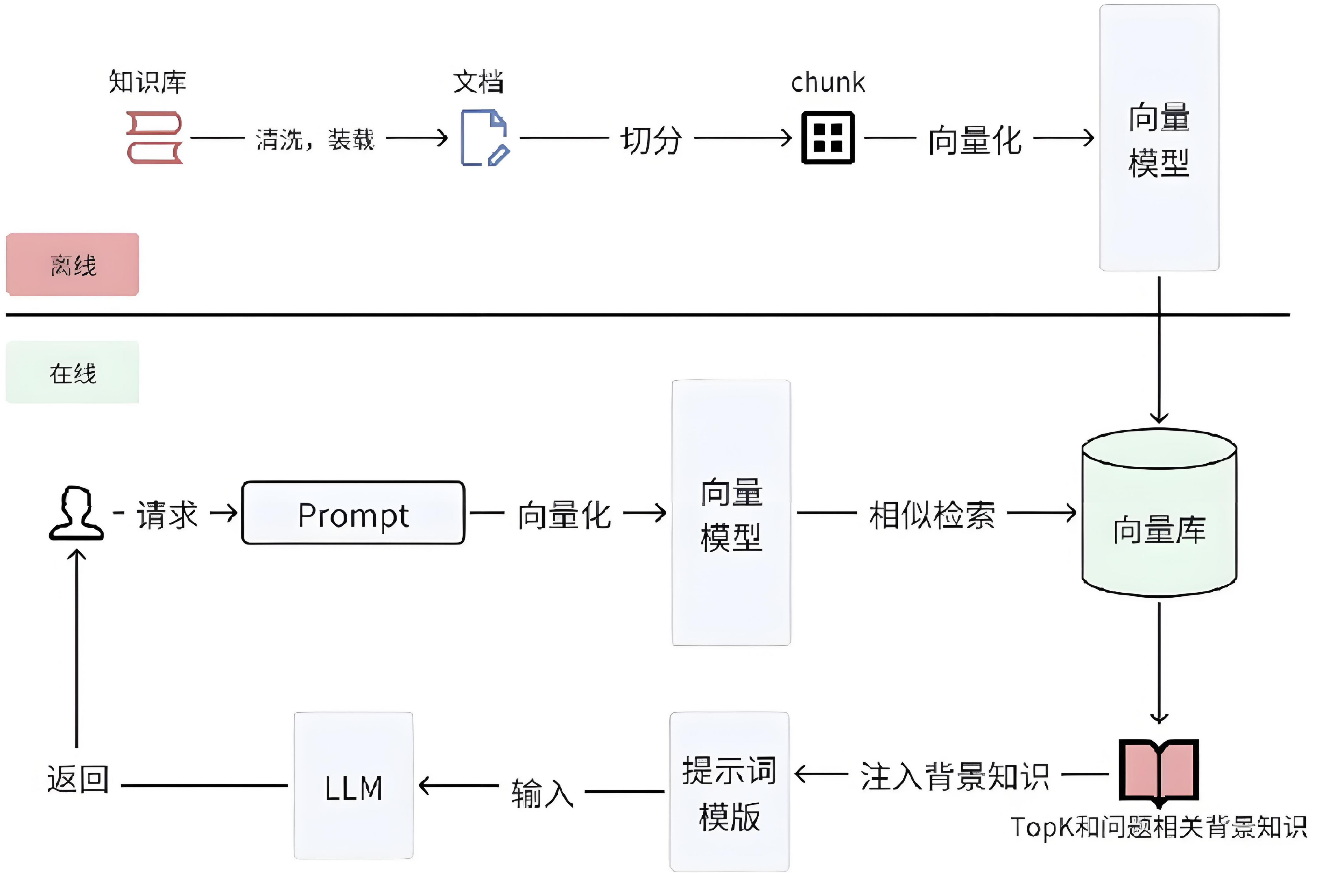
RAG的核心原理与流程
在众多企业的数字化实践中,搭建专属的RAG引擎已成为核心布局;RAG的落地绝非千篇一律,处处渗透着按需定制的个性化巧思。
它绝非一款简单的工具,而是一套环环相扣的完整系统,更是一套贯穿全流程的闭环运作体系。
搭建RAG流程
Step1,数据预处理, 80%的工作都在这里:
- 知识库构建: 收集并整理文档、网页、数据库等多源数据,构建外部知识库;时间越久,你收集到得知识就会有很多重复得知识、冲突得知识、过期得知识、无用得知识等等,你需要对这些知识做清洗。 未来想要做一个好得任务,就要花时间在这里做数据清洗,通过沟通、迭代、校验手段进行
- 文档分块: 因为知识是要再做一层切分,比如你有一个文档,是有1000页,如果不切分,这个颗粒度就很大,检索得时候很不方便,而且你要把它通过Embedding向量化,每个Embedding工具得数学向量都是有固定维度得,比如1024维,你直接把1000页得内容放到1024维得数学向量中,肯定会被稀释,我们为了保证语义得完整度,一般颗粒度都会比较小,我们会将文档切分为适当大小的片段(chunks),以便后续检索。分块策略需要在语义完整性与检索效率之间取得平衡;
- 向量化处理: 使用嵌入模型(如BGE、M3E、Chinese-Alpaca-2等)将文本块转换为向量,其实就是使用第三方模型得映射空间,将知识映射到固定向量,并存储在向量数据库中,
Step2,检索阶段,目的是做信息过滤:
- 召回: 将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段,相似度计算,我们可以通过faiss库,通过欧式距离或者余弦相似度,帮我们快速检索,也叫召回,比如1000万chunks召回1000个chunks(粗筛,速度快,批量进行)
- 重排序: 对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入,是精确打分,1 vs 1进行,通过rerank模型进行打分,速度就会慢下来
Faiss库,帮我们计算embedding的相似度 —> 召回(检索)
Step3,生成阶段:
- 上下文组装: 将检索到的文本片段与用户问题结合,形成增强的上下文输入。
- 生成回答: 大语言模型基于增强的上下文生成最终回答。
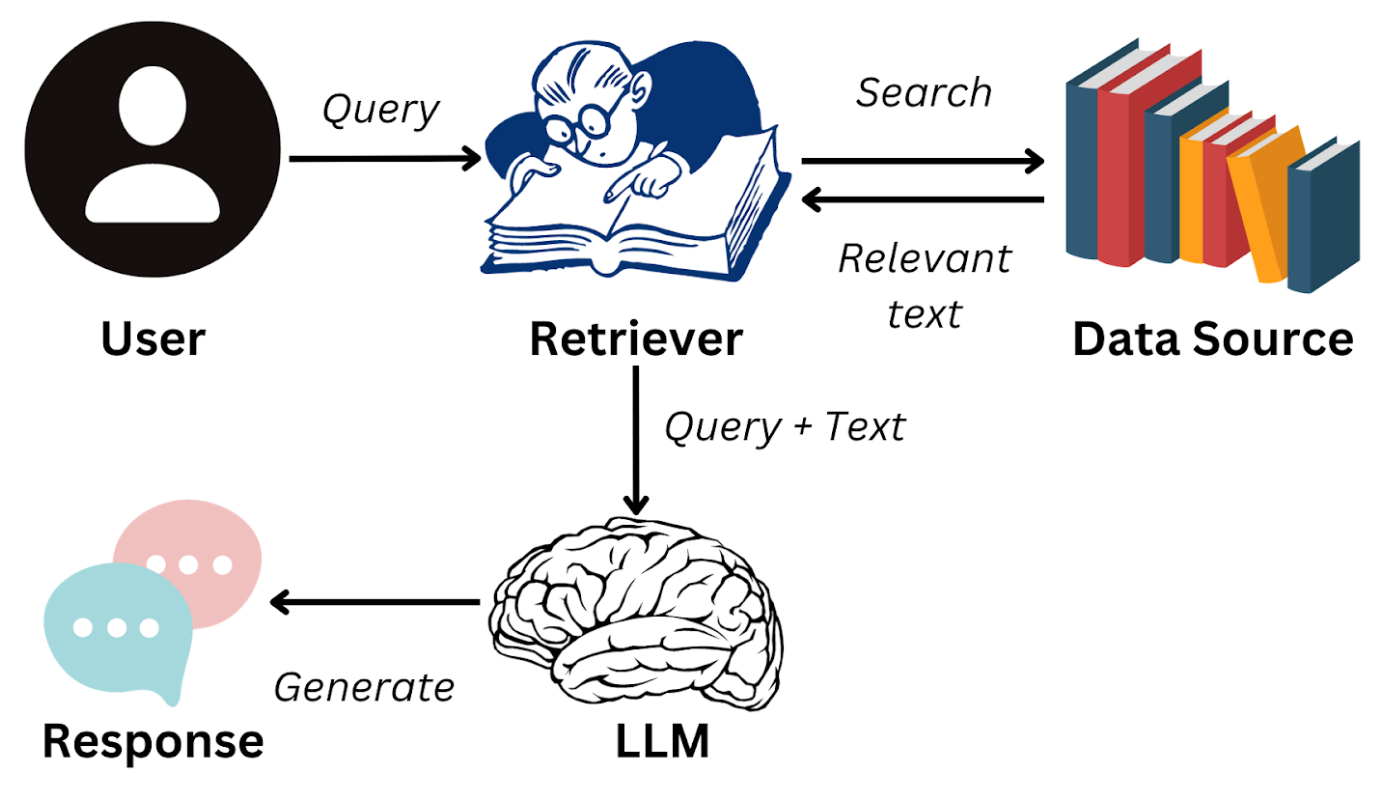
NativeRAG
RAG的步骤:
- Indexing: 如何更好地把知识存起来。
- Retrieval: 如何在大量的知识中,找到一小部分有用的,给到模型参考。
- Generation: 如何结合用户的提问和检索到的知识,让模型生成有用的答案。
这三个步骤虽然看似简单,但在 RAG 应用从构建到落地实施的整个过程中,涉及较多复杂的工作内容。
Embedding模型选择
想详细了解得,可以去看下我之前的文章 # Embedding不是魔法:把文字变成数字的底层逻辑。
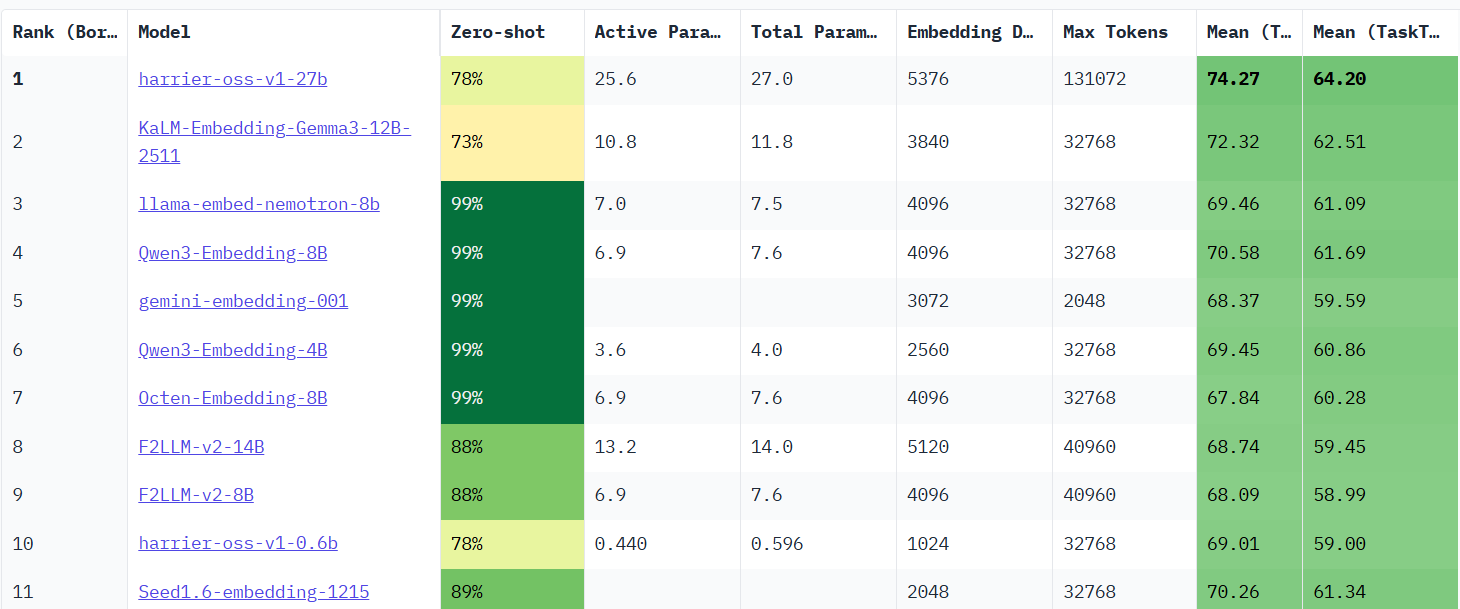
MTEB榜单
MTEB (Massive Text Embedding Benchmark)是一个全面的评测基准,它涵盖了分类、聚类、检索、排序等8大类任务和58个数据集。
通过MTEB榜单,可以清晰地看到不同模型(如BGE系列,GTE,Jina 等)在不同任务类型上的性能表现。
比如例如,某些模型在检索任务上表现优异,而另一些则可能在聚类或分类任务上更具优势。这有助于我们根据具体应用场景,做出初步的模型筛选。
我们可以到魔塔社区直接搜索Embedding库,可以直接把开源模型下载下来,本地部署使用,也可以直接使用商业版的Embedding模型,通过API_KEY密钥进行调用。
通用文本嵌入模型
BGE-M3(智源研究院):
- 特点:支持100+语言,输入长度达8192 tokens,融合密集、稀疏、多向量混合检索,适合跨语言长文档检索。
- 适用场景:跨语言长文档检索、高精度RAG应用。
- 文件大小:2.3G
text-embedding-3-large(OpenAI):
- 特点:向量维度3072,长文本语义捕捉能力强,英文表现优秀。
- 适用场景:英文内容优先的全球化应用。
Jina-embeddings-v2-small(Jina AI):
- 特点:参数量仅35M,支持实时推理(RT<50ms),适合轻量化部署。
- 适用场景:轻量级文本处理、实时推理任务。
中文嵌入模型
xiaobu-embedding-v2:
- 特点:针对中文语义优化,语义理解能力强。
- 适用场景:中文文本分类、语义检索。
M3E-Base:
- 特点:针对中文优化的轻量模型,适合本地私有化部署。
- 适用场景:中文法律、医疗领域检索任务。
- 文件大小:0.4G (m3e-base)
stella-mrl-large-zh-v3.5-1792:
- 特点:处理大规模中文数据能力强,捕捉细微语义关系。
- 适用场景:中文文本高级语义分析、自然语言处理任务。
指令驱动与复杂任务模型
gte-Qwen2-7B-instruct(阿里巴巴):
- 特点:基于Qwen大模型微调,支持代码与文本跨模态检索。
- 指令优化:经过大量指令-响应对的训练,特别擅长理解和生成高质量的文本。
- 性能表现:在文本生成、问答系统、文本分类、情感分析、命名实体识别和语义匹配等任务中表现优异。
- 适用场景:适合复杂指令驱动任务、智能问答系统,处理复杂的多步推理问题,能够生成准确且自然的答案。
E5-mistral-7B(Microsoft)
- 特点:基于Mistral架构,Zero-shot任务表现优异。
- 适用场景:动态调整语义密度的复杂系统。
企业级与复杂系统
BGE-M3(智源研究院)
- 特点:适合企业级部署,支持混合检索。
- 适用场景:企业级语义检索、复杂RAG应用。
E5-mistral-7B(Microsoft)
- 特点:适合企业级部署,支持指令微调。
- 适用场景:需要动态调整语义密度的复杂系统。
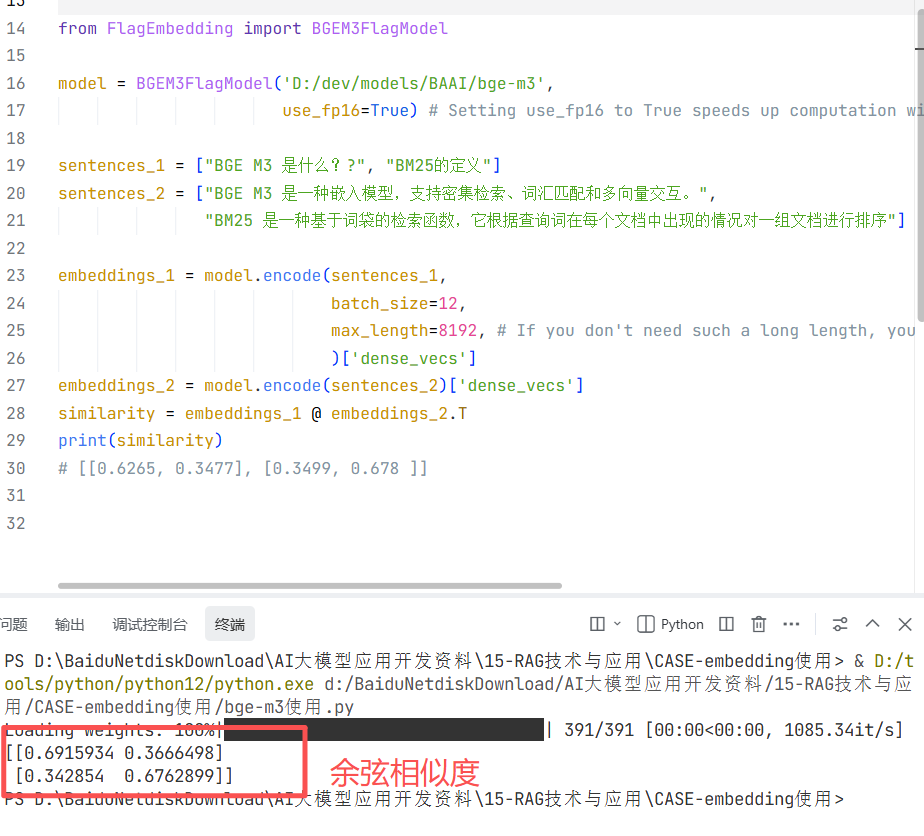
案例:bge-m3 使用
RAG知识库的处理逻辑
Step1:文档预处理
PDF文件 → 文本提取 → 文本分割 → 页码映射
-
PDF文本提取
- 逐页提取文本内容
- 记录每行文本对应的页码信息
- 处理空页和异常情况
-
文本分割策略
- 使用递归字符分割器
- 分割参数:chunk_size=1000, chunk_overlap=200
- 分割符优先级:段落 → 句子 → 空格 → 字符
RAG知识库切分有2种:
- 规则切分:使用chunk_size(切分大小),chunk_overlap(重叠大小),这种是最简单,快捷的方式;
- LLM切分:成本高,质量好。每个知识都让LLM过一次,语义相同的在一个chunk内。
- 页码映射处理(元数据管理)
- 基于字符位置计算每个文本块的页码
- 使用众数统计确定文本块的主要来源页码
- 建立文本块与页码的映射关系
Step2:知识库构建
文本块 → 嵌入向量 → Faiss索引 → 本地持久化
-
向量数据库构建
- 使用bge-m3嵌入模型生成向量
- 将向量存储到Faiss索引结构
-
数据持久化
- 保存Faiss索引文件(.faiss)
- 保存元数据信息(.pkl)
- 保存页码映射关系(page_info.pkl)
Step3:问答查询
用户问题 → 向量检索 → 文档组合 → LLM生成 → 答案输出
-
相似度检索
- 将用户问题转换为向量
- 在Faiss中搜索最相似的文档块,返回Top-K相关文档
-
问答链处理
- 使用LangChain的load_qa_chain
- 采用 stuff 策略组合文档
- 将组合后的上下文和问题发送给LLM
-
答案生成与展示
案例:bge-m3 + Faiss搭建本地知识库检索
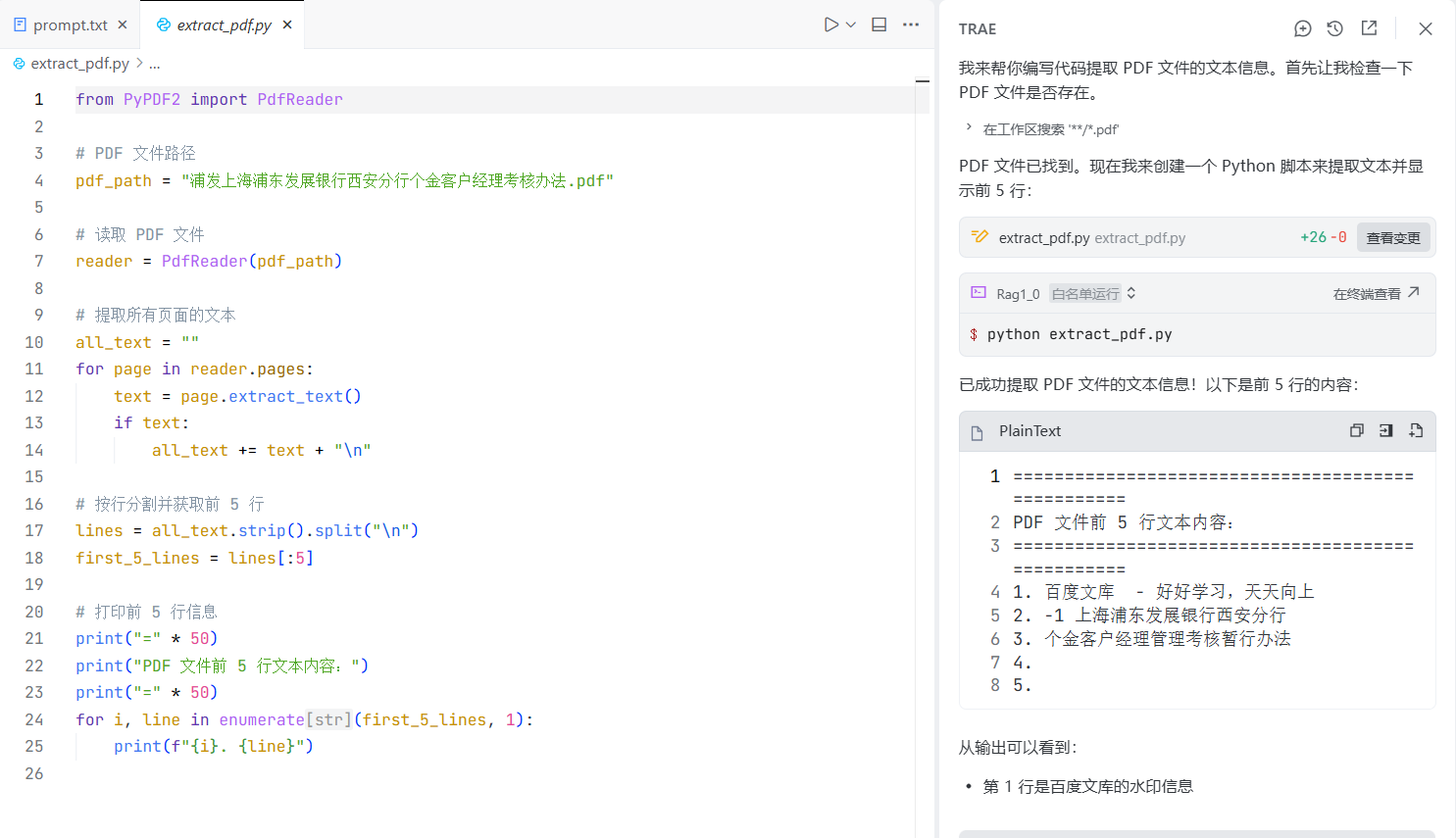
step1:通过PyPDF2库提取pdf文件信息。
prompt:使用PyPDF2库提取 浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf 文件内的文本信息,打印台显示前5行信息
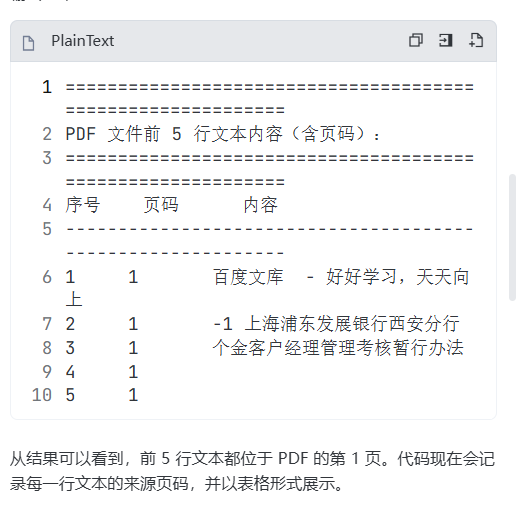
step2:元数据绑定
prompt:记录每行文本对应的页码信息,打印台显示前5行信息与页码
step3:数据清洗
prompt:处理空页与汽车

step4:知识库构建
使用本地bge-m3嵌入模型生成向量,(本地路径:D:/dev/models/BAAI/bge-m3),然后将向量储存到Faiss引索结构;
进行数据持久化:保存Faiss索引文件(.faiss)、元数据信息(.pkl)、页码映射关系(page_info.pkl)

step5:查看向量是否满足要求;
prompt:展示前5个向量信息,以文字的形式展示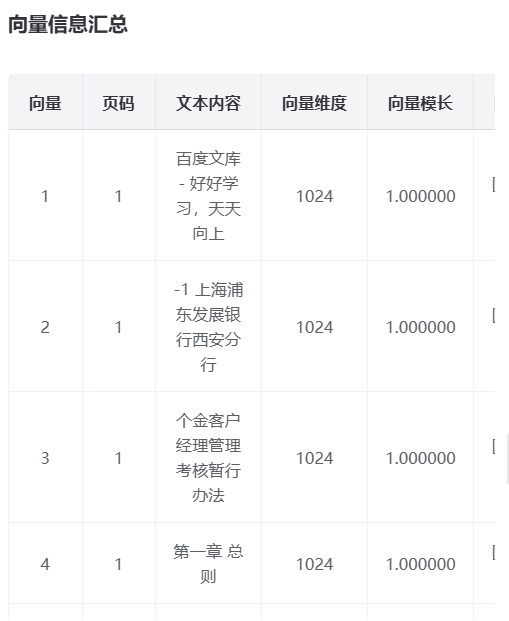
按照行来切分,是有问题的,我们要进行优化。
step6:优化文本分割策略
prompt:文本分割策略:
使用递归字符分割器;
分割参数:chunk_size=1000, chunk_overlap=200;
分割符优先级:段落 → 句子 → 空格 → 字符;
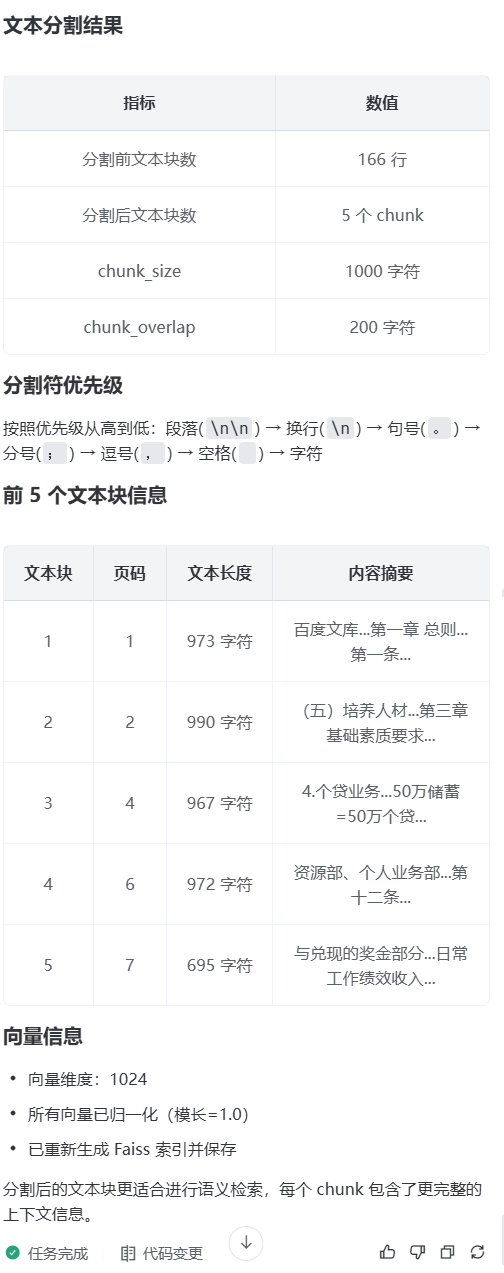
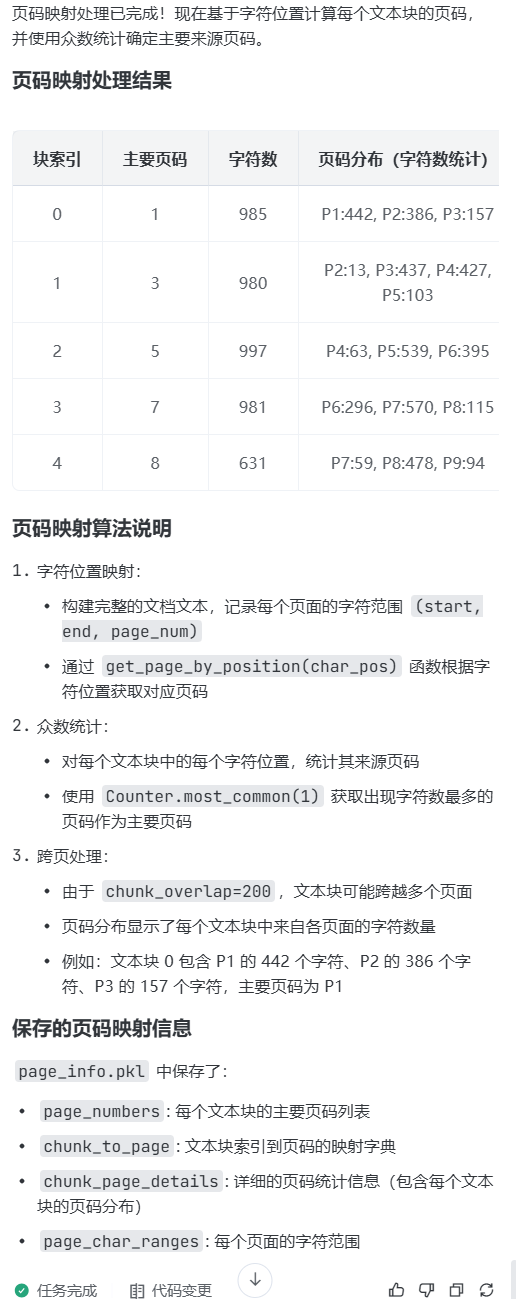
step7,
prompt:页码映射处理:
基于字符位置计算每个文本块的页码;
使用众数统计确定文本块的主要来源页码;
建立文本块与页码的映射关系;
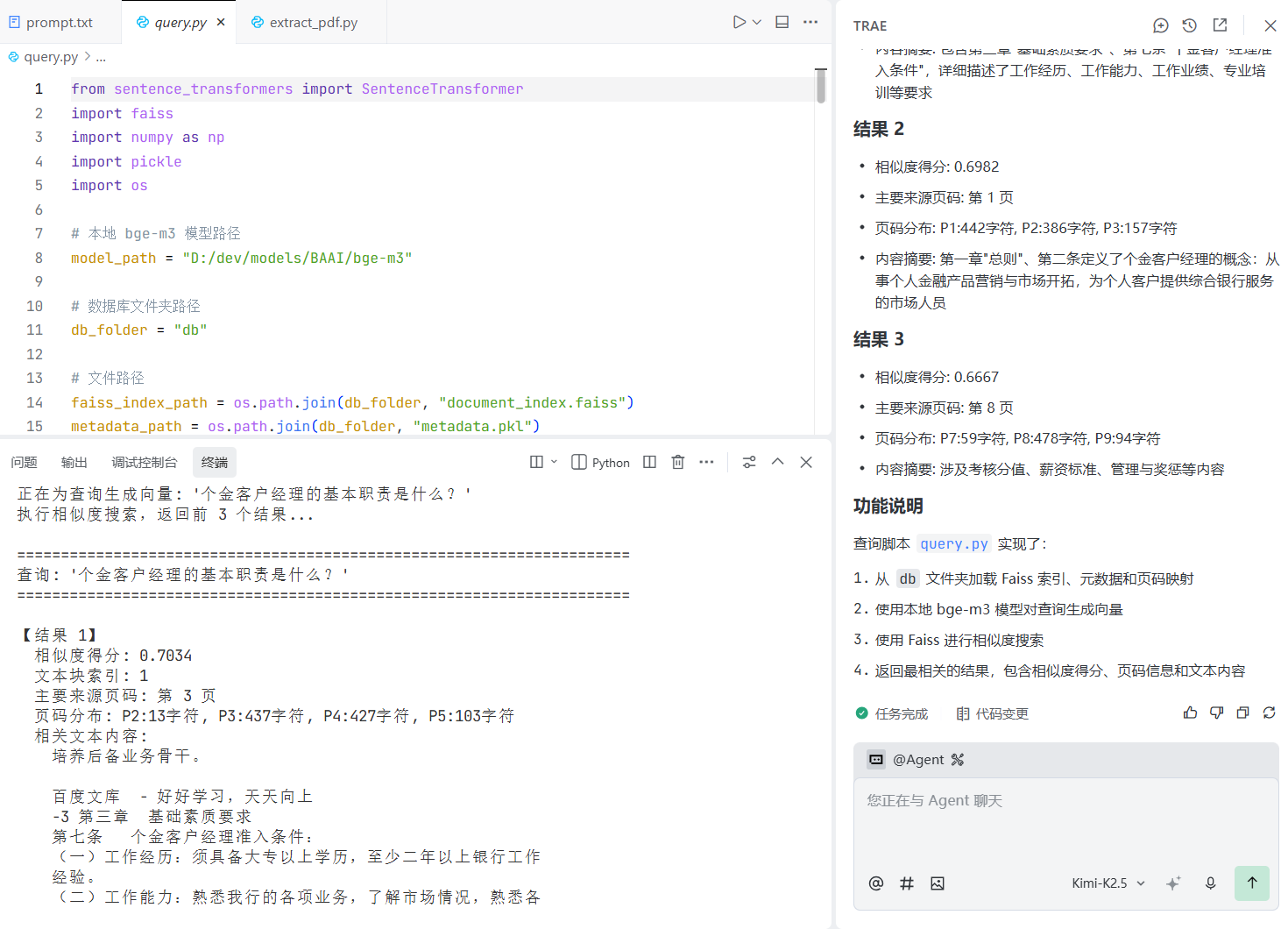
step8,使用本地知识库进行查询;
用户在查询时,使用从本地db文件夹加载向量数据库,使用faiss在加载的知识库内进行查询,并且返回页码。
用户查询:个金客户经理的基本职责是什么?
step9:使用deepseek v4 flash模型进行答案生成
直接在 @query.py上进行修改代码,
问答查询逻辑:
用户问题 → 向量检索 → 文档组合 → LLM生成 → 答案输出
1)将用户问题转换为向量,用Faiss库进行搜索最相似的chunk,返回Top-K = 2的相关信息;
2)使用langchain的load_qa_chain,采用stuff策略组合文档,将组合后的上下文和问题发送给LLM;
3)LLM使用请参考 @example01.py;
4)答案生成的文案风格,简单直接、拟人点,让人可以一眼看懂是什么意思
LangChain
Langchain是LLM应用开发框架,类似android开发的framwork.jar,里面有各类工具、框架等,属于综合性开发框架,该框架是把规范流程搭建起来了,里面的参数、业务还是需要人去处理。
想了解 Langchain的SQL Agent(SQLDatabase),可以去看下我之前的文章 Text2SQL到数据智能。
LangChain问答链中的4种chain_type:
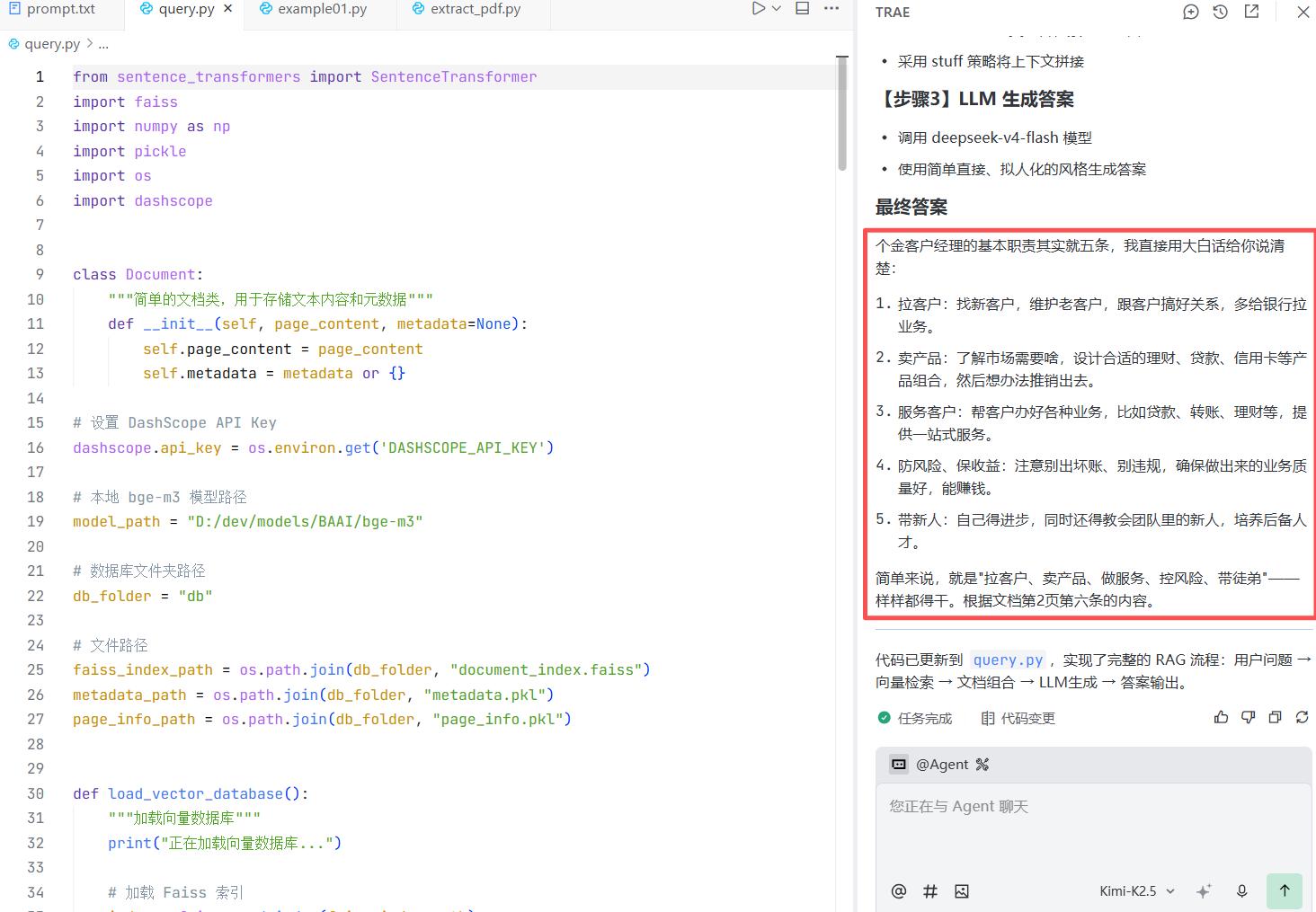
- stuff(主流方法):直接把文档作为prompt输入给OpenAI
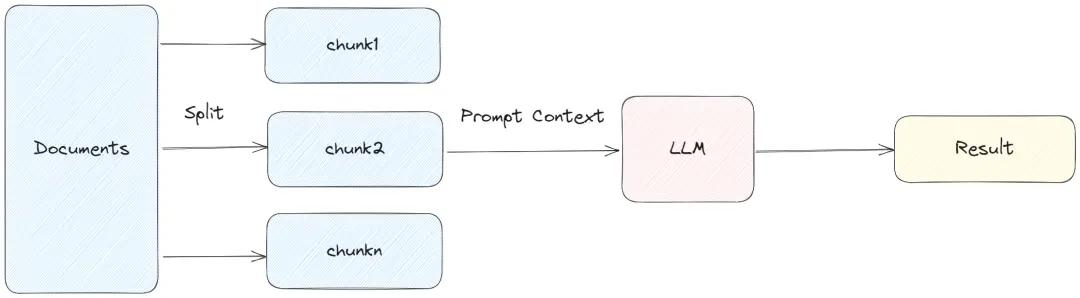
- map_reduce:对于每个chunk做一个prompt(回答或者摘要),然后再做合并
- refine:在第一个chunk上做prompt得到结果,然后合并下一个文件再输出结果
- map_rerank:对每个chunk做prompt,然后打个分,然后根据分数返回最好的文档中的结果
stuff
针对文档体量偏小、单次调取量有限的场景,stuff模式堪称理想之选——它能有效控制LLM的调用频次,兼顾效率与成本。
若在主流方案中举棋不定,无需纠结,直接锁定这一方式即可。
当文件送达,先对其进行精准切分,拆解为多个信息块;随后依托LLM,针对这些信息块进行整合后发起提问,快速获取精准回应。整个过程,仅需一个LLM,便能集中承载所有检索到的信息块,高效完成核心任务。
map_reduce
采用单文档独立处理的模式,能够实现并发调用,大幅提升处理效率,但不可忽视的是,各文档间存在上下文衔接的缺口。
具体操作中,先将文档拆分为独立模块,逐一交由LLM处理,待各模块结果汇总整合后,再送入LLM开展深度推理。这种多轮调用LLM的方式,不可避免地会带来token资源的消耗。
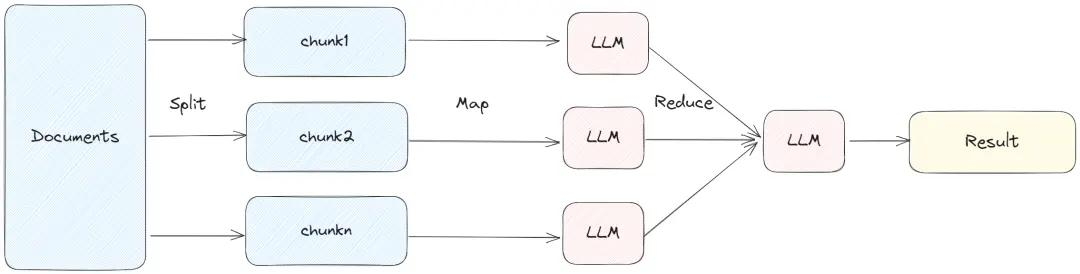
refine
Refine模式优势显著,既能在一定程度上留存上下文脉络,又可将token的消耗精准把控在合理区间。
当面对长篇幅的上下文时,可先以chunk1驱动LLM开展推理,待产出结果后,将其与chunk2整合,再次输入LLM迭代推理,如此循环优化。这种多轮调用LLM的策略,虽能持续打磨输出质量,但也会同步产生token的消耗。
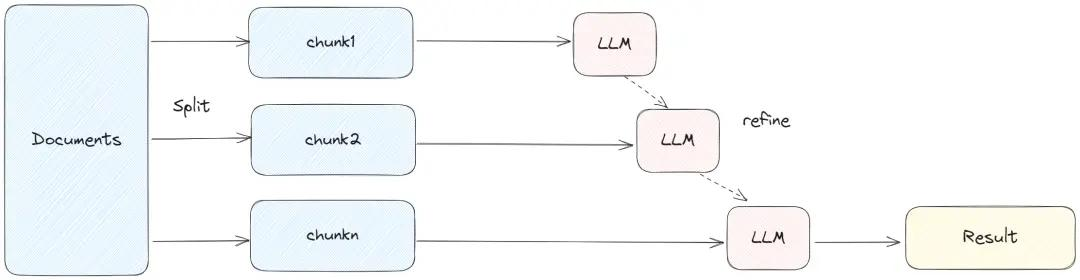
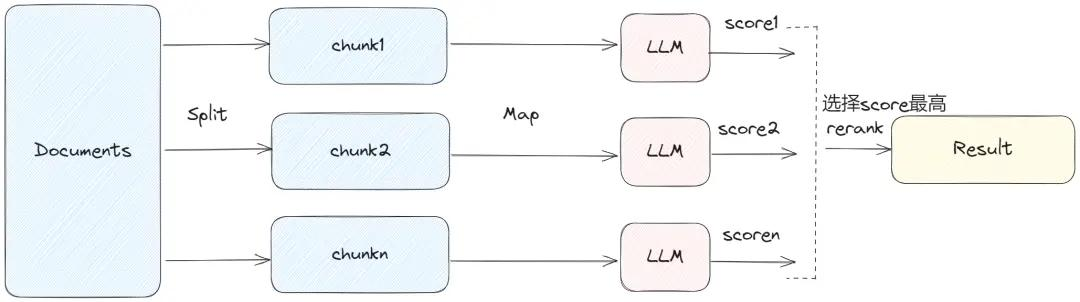
map_rerank
这种方案会高频调用LLM,所有文档均以独立单元推进处理;每个文本块都会交由大模型完成推理,同时依托LLM开展打分筛选,最终将得分最高的结果反馈给客户,这一模式也被称为llm_rerank。它堪称精度拉满的方案,却也是token消耗最为剧烈的方式。
Query
Query改写
RAG 的核心在于“检索-生成”。通过Query改写让你的RAG检索更强大
RAG的流程,高度依赖于query!
query —> query embedding —> 找知识
为什么需要 Query 改写?
RAG 的核心在于“检索-生成”。如果第一步“检索”就走偏了,那么后续的“生成”质量也会降低。
用户提出的问题往往是口语化的、承接上下文的、模糊的,甚至是包含了情绪的。
而知识库里的文本(切片/Chunks)通常是陈述性的、客观的。
=> 需要一个翻译官的角色,将用户的“口语化查询”转换成“书面化、精确的检索语句”
如何针对不同类型的Query进行改写?
通过精心设计的 Prompt 来引导 LLM完成这项任务。
想详细了解的,可以看下我之前写的文章 # 浅聊Prompt、向量知识库、RAG_prompt知识库。
上下文工程 + thinking模式
上下文依赖型
通过提示词的方法,让它扮演一个智能查询优化助手
"""上下文依赖型Query改写"""
instruction = """
你是一个智能的查询优化助手。请分析用户的当前问题以及前序对话历史,判断当前问题是否依赖于上下文。
如果依赖,请将当前问题改写成一个独立的、包含所有必要上下文信息的完整问题。
如果不依赖,直接返回原问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
对话历史:
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了'疯狂动物城'主题园区,这里有朱迪警官和尼克狐的互动体验。"
用户: "这个园区有什么游乐设施?"
AI: "'疯狂动物城'园区目前有疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店等设施。"
当前查询: 还有其他设施吗?
改写结果: 除了疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店之外,'疯狂动物城'园区还有其他设施吗?
对比型
通过提示词的方法,让它扮演一个智能查询分析专家
"""对比型Query改写"""
instruction = """
你是一个查询分析专家。请分析用户的输入和相关的对话上下文,识别出问题中需要进行比较的多个对象。然后,将原始问题改写成一个更明确、更适合在知识库中检索的对比性查询。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史/上下文信息 ###
{context_info}
### 原始问题 ###
{query}
### 改写后的查询 ###
"""
对话历史:
用户: "我想了解一下上海迪士尼乐园的最新项目。"
AI: "上海迪士尼乐园最新推出了疯狂动物城主题园区,还有蜘蛛侠主题园区"
当前查询: 哪个游玩的时间比较长,比较有趣
改写结果: 哪个游玩时间更长、更有趣:上海迪士尼乐园的疯狂动物城主题园区和蜘蛛侠主题园区?
模糊指代型
通过提示词的方法,让它扮演一个消除语言歧义的专家
"""模糊指代型Query改写"""
instruction = """
你是一个消除语言歧义的专家。请分析用户的当前问题和对话历史,找出问题中 "都"、"它"、"这个" 等模糊指代词具体指向的对象。
然后,将这些指代词替换为明确的对象名称,生成一个清晰、无歧义的新问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
对话历史:
用户: "我想了解一下上海迪士尼乐园和香港迪士尼乐园的烟花表演。"
AI: "好的,上海迪士尼乐园和香港迪士尼乐园都有精彩的烟花表演。"
当前查询: 都什么时候开始?
改写结果: 上海迪士尼乐园和香港迪士尼乐园的烟花表演都什么时候开始?
多意图型
通过提示词的方法,让它扮演一个任务分解机器人
可以参考我之前写的文章,了解下思维链,# 初识Agent。
进行约束,跟现在流行的Harness Engineeing 驾驭工程的约束思维一致。想详细了解Harness Engineeing,可以去看下我之前写的文章 # Harness Engineering:从入门到精通。
"""多意图型Query改写 - 分解查询"""
instruction = """
你是一个任务分解机器人。请将用户的复杂问题分解成多个独立的、可以单独回答的简单问题。以JSON数组格式输出。
"""
prompt = f"""
### 指令 ###
{instruction}
### 原始问题 ###
{query}
### 分解后的问题列表 ###
请以JSON数组格式输出,例如:["问题1", "问题2", "问题3"]
"""
原始查询: 门票多少钱?需要提前预约吗?停车费怎么收?
分解结果: ['门票多少钱?', '需要提前预约吗?', '停车费怎么收?']
反问型
通过提示词的方法,让它扮演一个沟通理解大师
核心在召回,通过llm对prompt进行补全,让召回更精准,召回精准了,对话历史就全面,回复客户的问答就精准
"""反问型Query改写""“
instruction = """
你是一个沟通理解大师。请分析用户的反问或带有情绪的陈述,识别其背后真实的意图和问题。
然后,将这个反问改写成一个中立、客观、可以直接用于知识库检索的问题。
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 当前问题 ###
{current_query}
### 改写后的问题 ###
"""
对话历史:
用户: "你好,我想预订下周六上海迪士尼乐园的门票。"
AI: "正在为您查询... 查询到下周六的门票已经售罄。"
用户: "售罄是什么意思?我朋友上周去还能买到当天的票。"
当前查询: 这不会也要提前一个月预订吧?
改写结果: 迪士尼乐园门票是否需要提前一个月预订?
意图识别
从上面可以知道,我们的改写都有5种情况了,每个改写都是一次意图识别,
真实场景,是五花八门的,意图也是各种各样,在我们的应用中,我们要识别不同的意图,走不同的流程,query改写也是一样,我们就需要通过综合型的prompt,其实说白了,万事万物都是prompt工程,不管是你驾驭工程、上下文工程,都是prompt工程的翻版,简单的来说,你是通过提示词的管理来驱动LLM工作的,
通过提示词的方法,让它扮演一个智能的查询分析专家
"""自动识别Query类型并进行改写"""
instruction = """
你是一个智能的查询分析专家。请分析用户的查询,识别其属于以下哪种类型:
1. 上下文依赖型 - 包含"还有"、"其他"等需要上下文理解的词汇
2. 对比型 - 包含"哪个"、"比较"、"更"、"哪个更好"、"哪个更"等比较词汇
3. 模糊指代型 - 包含"它"、"他们"、"都"、"这个"等指代词
4. 多意图型 - 包含多个独立问题,用"、"或"?"分隔
5. 反问型 - 包含"不会"、"难道"等反问语气
说明:如果同时存在多意图型、模糊指代型,优先级为多意图型>模糊指代型
请返回JSON格式:
{
"query_type": "查询类型",
"rewritten_query": "改写后的查询",
"confidence": "置信度(0-1)"
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 上下文信息 ###
{context_info}
### 原始查询 ###
{query}
### 分析结果 ###
"""
Query+联网搜索
LLM都有联网查找的能力,如果想做一些定制的查找能力,可能会在公司内网,或者专门的旅游网站等地方
联网搜索和 function call 其实有着千丝万缕的联系,它们的关键不同就在于判断的方式。
function call 是大模型自己内置的提问功能,这事儿我们根本做不了主。
要是用了 function call,那咱们就没办法掌控局面了;但要是换成 prompt,再结合置信度来打分,模型觉得该联网的时候,就一定会果断联网。
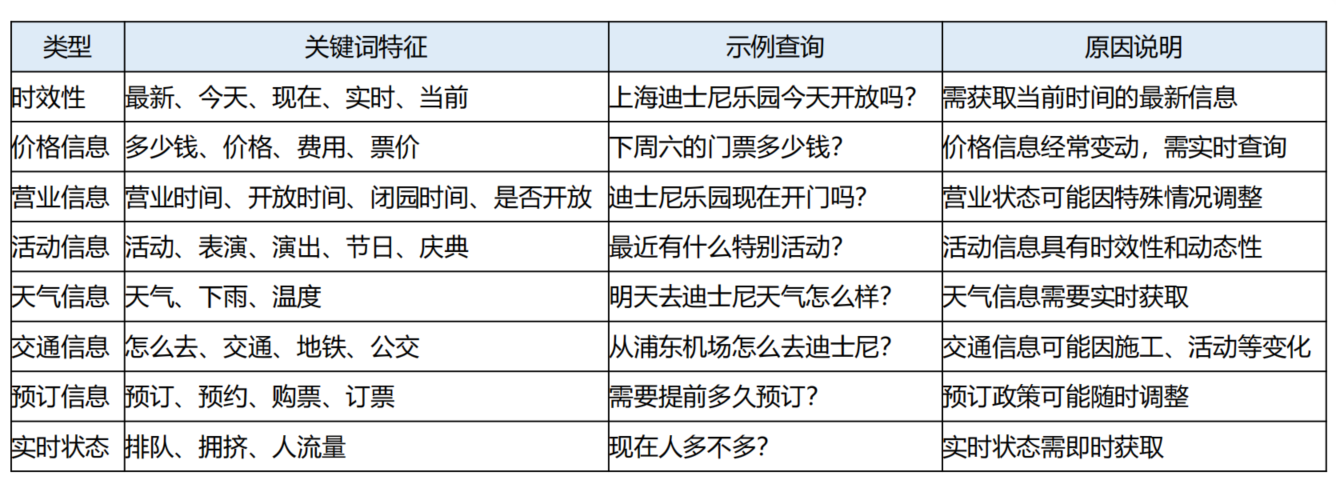
以迪士尼RAG助手为例,用户Query需要联网的情况都有哪些?
识别查询是否需要联网搜索
instruction = """
你是一个智能的查询分析专家。请分析用户的查询,判断是否需要联网搜索来获取最新、最准确的信息。需要联网搜索的情况包括:
1. 时效性信息 - 包含"最新"、"今天"、"现在"、"实时"、"当前"等时间相关词汇
2. 价格信息 - 包含"多少钱"、"价格"、"费用"、"票价"等价格相关词汇
3. 营业信息 - 包含"营业时间"、"开放时间"、"闭园时间"、"是否开放"等营业状态
4. 活动信息 - 包含"活动"、"表演"、"演出"、"节日"、"庆典"等动态信息
5. 天气信息 - 包含"天气"、"下雨"、"温度"等天气相关
6. 交通信息 - 包含"怎么去"、"交通"、"地铁"、"公交"等交通方式
7. 预订信息 - 包含"预订"、"预约"、"购票"、"订票"等预订相关
8. 实时状态 - 包含"排队"、"拥挤"、"人流量"等实时状态
请返回JSON格式:
{
"need_web_search": true/false,
"search_reason": "需要搜索的原因",
"confidence": "置信度(0-1)"
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 对话历史 ###
{conversation_history}
### 用户查询 ###
{query}
### 分析结果 ###
"""
为联网搜索改写查询
instruction = """
你是一个专业的搜索查询优化专家。请将用户的查询改写为更适合搜索引擎检索的形式。
改写技巧:
1. 添加具体地点 - 如"上海迪士尼乐园"、"香港迪士尼乐园"
2. 添加时间范围 - 如"2024年"、"今天"、"本周"
3. 使用关键词组合 - 将长句拆分为关键词
4. 添加搜索意图 - 明确搜索目的
5. 去除口语化表达 - 转换为标准搜索词
6. 添加相关词汇 - 增加同义词或相关词
请返回JSON格式:
{
"rewritten_query": "改写后的搜索查询",
"search_keywords": ["关键词1", "关键词2", "关键词3"],
"search_intent": "搜索意图",
"suggested_sources": ["建议搜索的网站类型"]
}
"""
prompt = f"""
### 指令 ###
{instruction}
### 原始查询 ###
{query}
### 搜索类型 ###
{search_type}
### 改写结果 ###
"""
生成搜索策略
instruction = f"""
你是一个搜索策略专家。请为用户的查询制定详细的搜索策略。
当前日期:{current_date}
搜索策略包括:
1. 主要搜索词 - 核心关键词
2. 扩展搜索词 - 相关词汇和同义词
3. 搜索网站 - 推荐的搜索平台
4. 时间范围 - 具体的搜索时间范围
请返回JSON格式:
{{
"primary_keywords": ["主要关键词"],
"extended_keywords": ["扩展关键词"],
"search_platforms": ["搜索平台"],
"time_range": "具体的时间范围"
}}
"""
prompt = f"""
### 指令 ###
{instruction}
### 用户查询 ###
{query}
### 搜索类型 ###
{search_type}
### 搜索策略 ###
"""
RAG+Query智能流程驱动
依托 Prompt 对大语言模型(LLM)进行精准调控,借助上下文工程,将精心构建的 Prompt 输送至 LLM,触发其生成针对用户查询(Query)的改写 Prompt。随后,再次调用 LLM 对联网需求进行智能判断。若判定需联网,则进一步驱动 LLM 优化 Prompt,最终与 RAG 系统协同,开展基于 Embedding 的向量化相关度精准计算。
![![[Pasted image 20260519141437.png]]](https://i-blog.csdnimg.cn/direct/38df593f7bb04ec39dc2bba5c7558e5f.png)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)