【AI入门知识点】RAG 是什么?为什么它能让 AI 不再胡说八道?
为什么 ChatGPT 有时一本正经地胡说八道?
为什么企业知识库问答越来越火?
为什么很多公司做 AI 项目时,都绕不开 RAG?
为什么大模型明明很强,却还是需要“外挂”?
这些问题背后。
其实都指向一个核心概念:
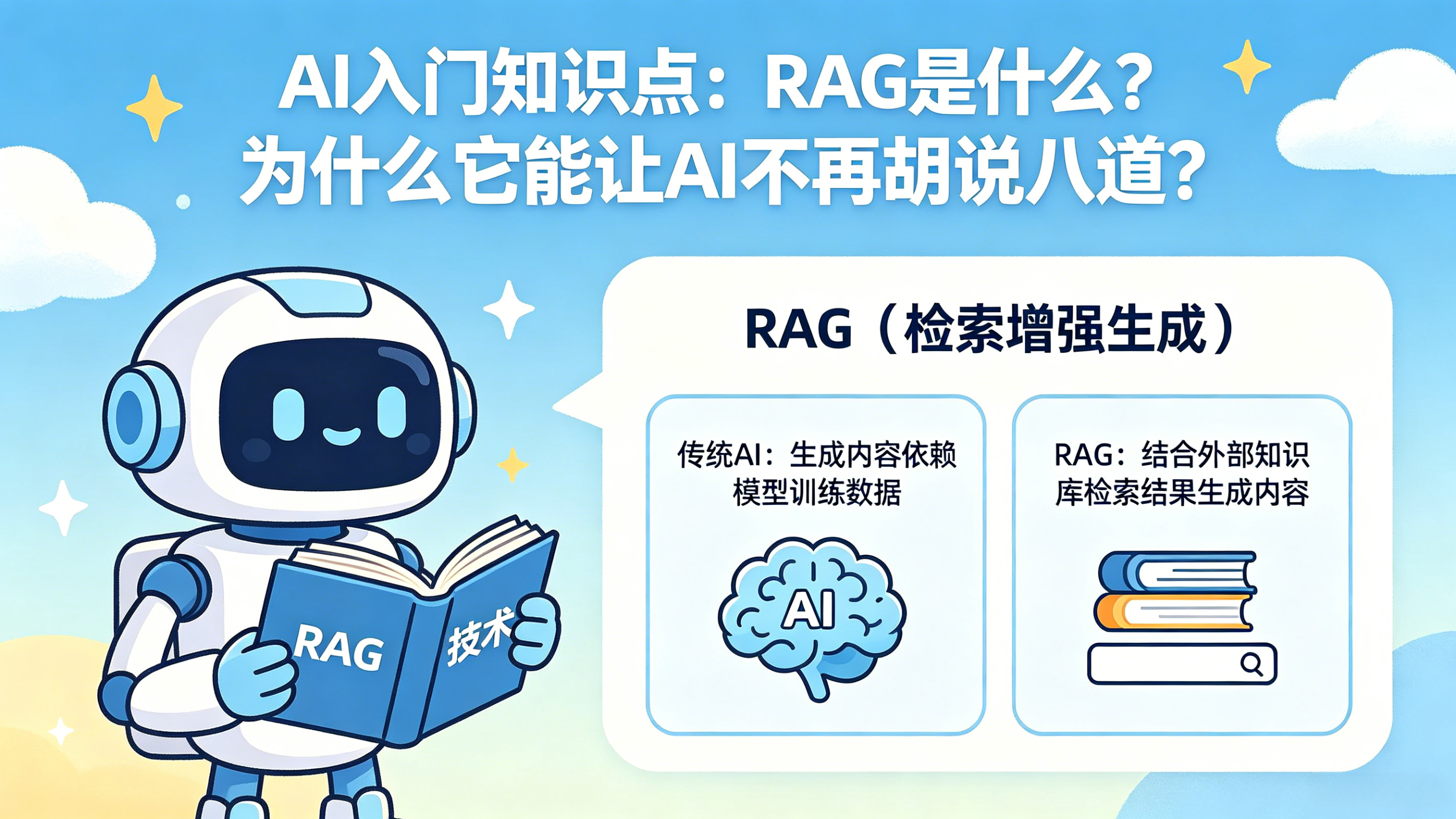
RAG(Retrieval-Augmented Generation)
中文:
检索增强生成
很多人第一次听到 RAG。
都会觉得:
又一个复杂术语?
其实:
RAG 本质上就是给 AI 加了一个“会查资料的大脑外挂”。
今天继续用:
小白视角 + 程序员视角
真正搞懂:
RAG 到底是什么?
一、小白视角:RAG 到底是什么?
先一句话解释:
RAG = 会先查资料,再回答问题的 AI。
什么意思?
你可以理解成:
让 AI 学会“翻书”。
1、为什么普通 LLM 会胡说八道?
上一篇讲过。
LLM 的底层:
其实是:
预测下一个 Token。
它不是:
真在查数据库。
举个例子。
你问:
公司 2026 年最新请假制度是什么?
普通大模型:
可能直接:
瞎猜。
因为:
训练数据里:
根本没有你公司内部制度。
于是:
开始:
一本正经地编。
这就是:
幻觉(Hallucination)
2、RAG 做了什么?
RAG 的核心思想:
特别简单。
以前:
普通 AI
是:
凭记忆回答。
现在:
RAG
变成:
先查资料,再回答。
流程:
用户提问
↓
先搜索知识库
↓
找到相关资料
↓
把资料交给 AI
↓
AI 再组织答案
于是:
准确率暴涨。
3、举个最容易懂的例子
假设:
你问:
公司报销标准是多少?
普通 LLM
像:
一个爱面子的人。
不知道。
也硬答。
可能乱说:
“餐饮标准每日 200 元。”
结果:
错了。
RAG 模式
像:
一个认真员工。
先去翻:
《财务制度.pdf》
找到:
差旅餐补标准:
每天 80 元
然后回答:
根据公司制度,每日餐补标准为 80 元。
明显:
更靠谱。
4、为什么企业都在做 RAG?
因为:
企业知识:
通常:
不在训练数据里。
比如:
-
公司制度
-
技术文档
-
ERP 数据
-
产品手册
-
内部知识库
-
API 文档
-
售后手册
这些:
大模型不知道。
但:
RAG 可以:
临时查。
所以:
企业 AI = 大模型 + RAG
几乎成了标配。
5、RAG 就像“开卷考试”
普通 LLM:
像:
闭卷考试。
靠记忆。
记错就翻车。
RAG:
像:
开卷考试。
不会?
查书。
所以:
正确率高很多。
6、一个最形象的比喻
如果:
普通 ChatGPT
像:
一个知识丰富的人。
那么:
RAG
更像:
一个知识丰富,还会实时翻资料的人。
所以:
回答:
更可靠。
更专业。
也更符合:
企业真实业务。
7、一句话理解 RAG
如果让我一句话解释:
RAG = 给大模型外挂一个知识库。
让它:
先查,再说。
而不是:
靠猜。
二、程序员视角:RAG 的底层原理是什么?
下面进入:
程序员模式。
尽量讲专业,但不搞学术劝退。
1、RAG 的本质是什么?
一句话定义:
RAG 是一种“检索 + 生成”的增强架构。
核心思想:
把外部知识动态注入 LLM。
而不是:
微调模型。
传统方式:
Fine-Tuning(微调)
问题:
-
贵
-
慢
-
更新困难
改文档:
还得重新训练。
很麻烦。
RAG:
不用重新训练。
直接:
查最新知识。
2、RAG 的核心流程
完整流程:
用户问题
↓
Embedding
↓
向量检索
↓
找到相关文档
↓
拼接 Prompt
↓
LLM 生成答案
其实:
就五步。
3、第一步:知识切片(Chunking)
文档不能直接丢。
因为:
太长。
所以:
先拆。
例如:
一本文档:
员工手册.pdf
拆成:
片段1
片段2
片段3
...
叫:
Chunk(文本块)
为什么?
因为:
LLM 上下文有限。
4、第二步:Embedding 向量化
上一篇讲过:
Embedding:
把文本变向量。
例如:
请假制度
变:
[0.13, -0.52, 0.88...]
所有知识块:
都向量化。
存进:
向量数据库。
5、第三步:向量检索
用户提问:
年假怎么算?
先:
做 Embedding。
然后:
查找:
最相似文本。
例如:
找到:
员工连续工作满一年,
享有5天年假
因为:
语义相似。
而不是:
关键词匹配。
所以:
即使问:
带薪休假规则
也能搜到:
年假制度。
6、第四步:Prompt 拼接
找到资料后:
会自动塞进 Prompt:
类似:
请基于以下内容回答:
【知识】
员工连续工作满一年,
享有5天年假
【问题】
年假怎么算?
然后:
交给 LLM。
7、第五步:LLM 组织语言
最后:
模型负责:
语言生成。
输出:
根据公司制度,员工连续工作满一年后可享有 5 天年假。
注意:
这里:
知识来自检索。
表达来自 LLM。
这就是:
RAG 的灵魂。
8、为什么 RAG 比 Fine-Tuning 更火?
因为:
优势1:更新快
改文档即可。
不用重新训练。
优势2:成本低
不训练模型。
节省 GPU。
优势3:可追溯
能知道:
答案来自哪份文档。
企业特别喜欢。
优势4:减少幻觉
让模型:
有依据回答。
而不是:
靠猜。
9、RAG 常见技术栈
通常:
包括:
文档解析
-
PDF
-
Word
-
Excel
-
Markdown
-
TXT
-
PPT
Chunking
文本切片。
Embedding Model
向量化。
例如:
-
BGE
-
E5
-
text-embedding
向量数据库
例如:
Milvus
Qdrant
FAISS
Chroma
LLM
例如:
-
GPT
-
DeepSeek
-
Qwen
最终:
组合成:
企业知识库问答。
10、为什么很多 RAG 项目效果不好?
因为:
很多人以为:
接个向量数据库就行。
实际上:
效果核心:
在:
-
Chunk 切分
-
Embedding 模型
-
Recall 策略
-
Re-ranking
-
Prompt 设计
否则:
容易:
检索错。
答非所问。
三、一个最形象的比喻
如果:
普通 LLM
像:
一个只靠记忆考试的人。
那么:
RAG
像:
一个带着教材去考试的人。
不会?
直接翻书。
所以:
更靠谱。
更少胡说八道。
四、一句话总结
小白版总结:
RAG 是让 AI 学会“先查资料,再回答”的技术。
程序员版总结:
RAG 是通过向量检索动态注入外部知识,再结合 LLM 生成答案的增强架构。
最后
如果你刚开始学习 AI。
建议学习路线:
Token
↓
Embedding
↓
Attention
↓
Transformer
↓
LLM
↓
Prompt
↓
RAG
↓
Agent
因为:
LLM 决定 AI 会不会说。
RAG 决定 AI 说得准不准。
理解 RAG。
你才真正进入:
企业级 AI 应用开发的大门。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)