Multi Agent 驱动数据仓库自动化开发
文章概览
背景:随着大模型技术的发展,"智能体(Agent)"成了新的热点。但在数仓开发领域,如何用 AI 辅助从 PRD 文档自动生成开发交付物,如何实现多智能体协作,仍是实践中的难题。
核心内容:本文从开发者角度出发,系统介绍如何从单智能体演进到多智能体协作,包括 Supervisor 模式设计、5 Phase 执行流程、知识库增强、Playwright 自动化发布等实践。
技术栈:Claude Code + superpowers + Python Multi-Agent + FastAPI + React + Playwright
一、背景
1.1 实际问题
2024 年开始,国内大模型应用开发的热度持续攀升,LangChain、Dify、Coze 等框架层出不穷。作为一线开发人员,我们也被卷入这波浪潮中,亲手搭建过几个 AI 应用。但真正坐下来思考的时候,却发现很多问题并没有标准答案:我们用这些框架搭出来的应用,到底算是一个固定的工作流,还是一个能自主决策的智能体?换句话说,在实际项目中,我们到底该追求流程的可控,还是该放手让 AI 自由发挥?
这种困惑在数仓开发领域尤其突出。说起来我们团队每天面对的工作,说简单也简单——建表、改口径、加字段,几乎每个需求都要走一遍标准流程;说复杂也复杂——业务方的一句话,落到数仓实现上可能就是一次跨层级的表结构调整。更让人头疼的是,不同开发者的命名风格、TTL 设置、数据域划分往往存在差异,规范很难真正统一。业务方说"我要看每天的商品订单量",我们理解了,但实现出来的东西和他们想要的往往有偏差,跨团队沟通成本一直很高。
冷静下来想想,这些问题的本质其实很清晰:我们希望 AI 能像一个资深开发者那样工作,不仅能理解业务,还得熟悉规范、懂得血缘关系。但现实情况是,AI 幻觉、输出不固定、行为不可控等问题依然存在,这让很多人对 AI 落地望而却步——要么觉得 AI 还不够聪明,要么觉得 AI 太不可控。
1.2 解决思路
理想和现实之间的距离,逼迫我们不得不去思考:到底什么样的 AI 应用才真正适合数仓开发场景?
我们一开始设定了两个目标。第一个是业务自助场景:让业务方可以直接提需求,AI 自动生成可上线的建表 SQL。这样业务人员只需要描述清楚需求,AI 就能生成符合数仓规范的表结构,省去了大量沟通成本。
第二个目标更关键:让 AI 真正"学会"数仓规范。一个表名 dwd_ord_order_base_df 背后藏着多少信息——DWD 层、订单域、订单基础表、按天全量。这些信息不是开发者自己知道的,而是数仓建设中长期积累下来的规范。AI 必须理解并严格遵循这些规范,才可能真正融入数仓开发流程。
于是核心问题变成了:如何设计一个既智能又规范的 AI 辅助开发系统?这也是本文想要回答的问题。接下来,我会从实践出发,分享我们是如何一步步从单智能体演进到多智能体协作的。
二、核心概念
2.1 Workflow 还是 Agent?
在深入技术细节之前,有必要先厘清两个概念:Workflow 和 Agent。这两个词在 AI 领域被广泛提及,但它们的边界其实并不清晰。我们先用一个生活中的类比来理解:
Workflow 更像是流水线上的工人。每个步骤都被精确设计好了,工人按照预设的流程执行,效率很高,但只会做被教过的事情。它的优势在于可控、可预测,但缺点是缺乏灵活性,一旦遇到预设之外的情况就束手无策。
Agent 则更像是全能助理。你告诉他一个目标,他会自己思考该怎么做,灵活调用各种工具来达成目标。它的优势在于自主性强、能处理复杂问题,但缺点是需要足够的信任和授权——因为行为路径难以完全预测。
在数仓开发场景中,我认为我们追求的既不是绝对的自主,也不是绝对的可控,而是两者之间的最佳平衡点。这不是一道非黑即白的选择题,而是一个需要根据具体场景灵活调整的问题。
2.2 业界定义与共识
其实不只是我们在思考这个问题,业界也在逐渐形成共识。
Anthropic 在去年发布的一篇文章中明确区分了两者:Workflow 是指"依靠预先编写好的代码路径,协调 LLM 和工具完成任务",而 Agent 是指"由 LLM 动态推理,自主决定任务流程与工具使用"。这个定义给出了两个极端的参考。
LangChain 的创始人 Harrison Chase 在多个场合表达过更务实的观点:大多数所谓的"agentic system",实际上都是 Workflow 和 Agent 的结合体。他说自己更关心的是一个系统有多"agentic",而不是它到底算不算 Agent。这个观点对我们帮助很大——它打破了二元对立的思维惯性。
核心共识是:Workflow 和 Agent 之间并不存在泾渭分明的界限,区别只在于自主性程度的高低。这也启发我们,在设计系统的时候,应该把注意力放在"这个场景需要多少自主性"上面,而不是简单地去站队。
2.3 我们的选择:平衡而非对立
基于上述认知,我们针对数仓开发的不同场景,制定了具体的选择标准:
|
场景 |
推荐模式 |
原因 |
|---|---|---|
|
建表 SQL 生成 |
Workflow |
规范明确,必须遵循数仓建模规范 |
|
需求理解、SOP 设计 |
Agent |
需要推理,理解业务语义 |
|
代码质量 Review |
Workflow |
规则明确,逐条检查 |
为什么会这样划分?我的理解是,数仓开发有一个特殊性——规范是硬约束,业务理解是软需求。分层架构、TTL 标识、命名规范这些内容必须严格遵守,AI 在这些地方不能自由发挥;但需求的业务理解可以有一定灵活性,AI 可以根据自己的判断来推进。
三、系统架构
3.1 整体架构
先给出一个整体架构的全景图:
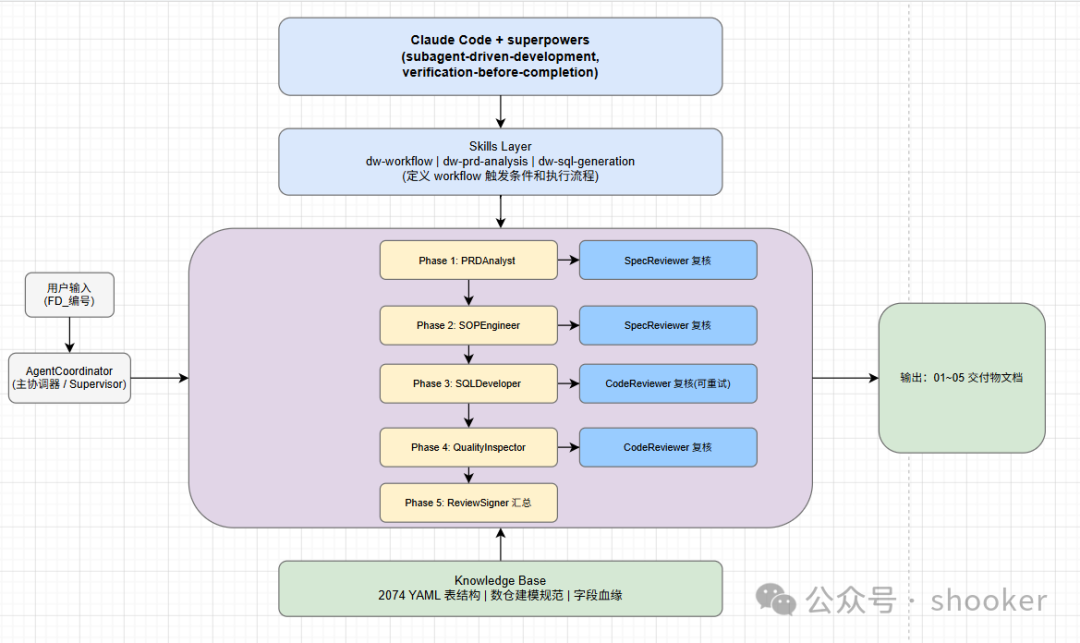
整个系统的设计遵循几个核心原则:
- 术业有专攻
:每个子 Agent 深耕一个领域,积累领域知识,避免"全能型"Agent 带来的上下文膨胀问题
- 文档驱动
:通过阶段性的文档传递信息,每个阶段产出都有实体文件,方便人工 review 和追溯
- Memory 持久化
:每个子 Agent 有独立的记忆文件,跨会话积累经验,而不是每次都从零开始
- 质量门控
:AI 预整理 → Gate 1 人工审核 → 三层 Review → Gate 2 最终确认,层层设防,保证输出质量
3.2 Multi-Agent 系统详解
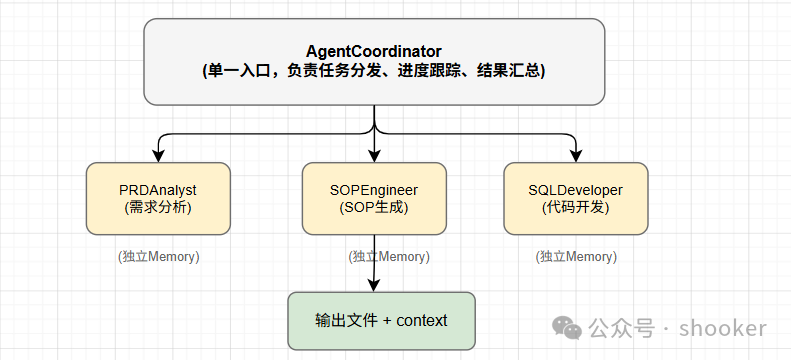
我们的 Multi-Agent 系统采用了 Supervisor 模式。简单来说,就是用一个顶层 Agent(我们叫 AgentCoordinator)来负责任务分发、进度跟踪、Reviewer 复核和最终验收。它就像一个项目的总负责人,按顺序调度各个专业 Agent,确保整个流程可控。
具体来说,系统包含 5 个专业 Agent:
|
Agent |
职责 |
核心能力 |
|---|---|---|
|
PRDAnalyst |
从 PRD 提取数仓需求 |
业务语义理解 |
|
SOPEngineer |
生成开发 SOP |
流程编排 |
|
SQLDeveloper |
实现 SQL 逻辑 |
SQL 编写 |
|
QualityInspector |
生成上线 Checklist |
质检规则 |
|
ReviewSigner |
汇总 Review 结果 |
结果整合 |
此外还有 2 个 Reviewer 专门负责复核工作:
|
Reviewer |
复核范围 |
|---|---|
|
SpecReviewer |
PRD、SOP 规格合规 |
|
CodeReviewer |
SQL、Checklist 代码质量 |
整个协作流程是这样的:
用户输入(FD_编号)
↓
AgentCoordinator 调度
↓ Phase 1: PRDAnalyst → SpecReviewer 复核
↓ Phase 2: SOPEngineer → SpecReviewer 复核
↓ Phase 3: SQLDeveloper → CodeReviewer 复核(可重试)
↓ Phase 4: QualityInspector → CodeReviewer 复核
↓ Phase 5: ReviewSigner 汇总
↓
输出:01~05 交付物文档3.3 技术栈
整个系统的技术栈大致如下:
|
层级 |
技术 |
用途 |
|---|---|---|
|
CLI |
Claude Code + superpowers |
AI Agent 框架 |
|
Skills |
SKILL.md (YAML) |
Workflow 定义 |
|
Agent Memory |
Markdown |
经验沉淀 |
|
后端 |
Python + FastAPI |
API 服务 |
|
Multi-Agent |
Python 自定义 |
专业 Agent |
|
自动化发布 |
Playwright |
浏览器自动化 |
|
前端 |
React + Vite + TypeScript |
UI |
3.4 自动化发布
SQL 代码通过安全校验之后,我们还实现了自动化发布功能。整个链路是这样的:Playwright 负责浏览器自动化,实现 Session 复用登录、建表、INSERT 写入、任务配置、保存这五个步骤的一键触发。这部分内容后文会详细展开。
四、多智能体协作模式
4.1 单智能体 vs 多智能体
在正式介绍多智能体之前,有必要先回答一个根本性的问题:单智能体和多智能体协作到底有什么区别?什么情况下,单智能体会不够用?
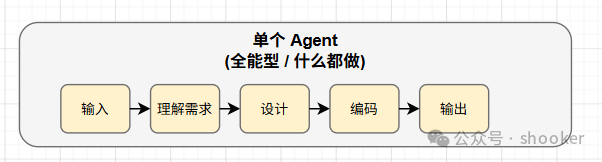
先看单智能体系统的形态:它像是一个全能型选手,一个 Agent 负责所有任务。从输入到输出,这个 Agent 包揽了理解需求、设计方案、编写代码的全流程。它的特点是集中式、自主决策,看起来很灵活,但问题在于行为路径难以预测。
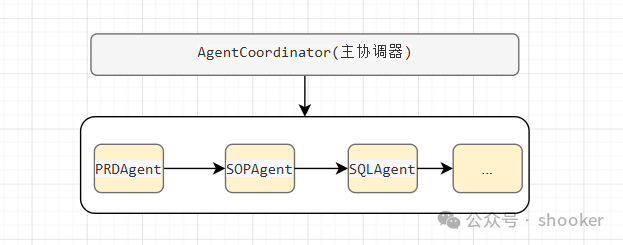
多智能体协作系统则是另一种思路:有一个中心协调者(AgentCoordinator),负责调度多个专业 Agent,每个 Agent 只专注于自己的一亩三分地。它的特点是分布式、中心调度,流程明确、输出稳定。
两者在多个维度上存在本质差异:
|
维度 |
单智能体 |
多智能体协作 |
|---|---|---|
|
职责 |
什么都做 |
单一职责 |
|
上下文 |
容易膨胀 |
按需注入 |
|
可靠性 |
单点故障 |
容错冗余 |
|
可控性 |
行为不确定 |
流程可追溯 |
|
扩展性 |
牵一发动全身 |
解耦可插拔 |
那么什么情况下单智能体会不够用?我的经验是,当任务复杂度超过某个临界点时,单智能体的瓶颈会变得很明显:
|
维度 |
单 Agent 上限 |
多 Agent 触发条件 |
|---|---|---|
|
工具数量 |
< 5 个 |
> 5 个 |
|
任务步骤 |
< 3 步 |
> 3 步 |
|
涉及领域 |
1 个 |
> 1 个 |
|
Prompt 长度 |
< 2000 tokens |
> 2000 tokens |
一个非常实用的判断标准是:当你的 Agent 的 Prompt 开始变得臃肿不堪,里面塞满了"如果你是 A,就做 X;如果你是 B,就做 Y"这样的条件分支指令时,这就是该拆分为多 Agent 的信号。
4.2 为什么需要多智能体?
回到我们的实际场景。为什么我们最终选择了多智能体架构?主要原因有四点。
第一是 Token 爆炸问题。当一个 Agent 需要同时理解 PRD、设计 SOP、编写 SQL 时,Prompt 必须注入大量信息——系统指令、用户交互历史、工具定义库、多步骤执行上下文。这些信息像滚雪球一样膨胀,很容易触及模型的 Token 上限,导致推理质量下降。
第二是注意力稀释问题。大模型虽然强大,但当被海量信息淹没后,关键细节容易被稀释,引发"工具选择幻觉"——面对功能繁多的工具库,Agent 极易混淆功能相似的工具,或者错误调用根本不存在的参数。我们在实际项目中就遇到过 Agent 把"查询"和"统计"两个功能搞混的情况。
第三是维护与扩展困难。当业务需求变化时,修改一个"全能型"Agent 的内在逻辑,远比调整一个专注于某个小任务的 Agent 要困难得多。每一次修改都可能引入意想不到的副作用。
第四是单点故障问题。如果单个 Agent 在某个环节卡住或出错,整个任务链就会中断。缺乏自我纠错和寻找替代方案的机制,可靠性无法保障。
4.3 Supervisor 模式设计
综合以上考量,我们最终采用了 Supervisor 模式:用一个顶层 Agent 负责意图识别和任务规划,其他 Agent 各司其职。
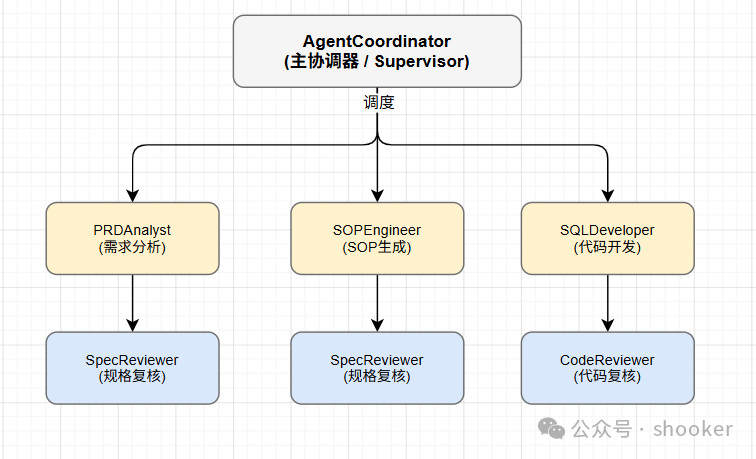
这个模式有几个关键特点:Coordinator 是单一入口,按顺序调度各 Agent;每个 Agent 专注于自己的领域;每个 Agent 有独立的 Memory,经验沉淀不互相干扰;Reviewer 实现了复用,SpecReviewer 复核 PRD 和 SOP,CodeReviewer 复核 SQL 和 Checklist。
4.4 各 Agent 职责
|
Agent |
职责 |
工具/知识 |
|---|---|---|
|
PRDAnalyst |
从 PRD 提取数仓需求 |
知识库表结构 |
|
SOPEngineer |
生成开发 SOP |
数仓建模规范 |
|
SQLDeveloper |
实现 SQL 逻辑 |
建表规范、命名规范 |
|
QualityInspector |
生成上线 Checklist |
质检规则 |
|
ReviewSigner |
汇总 Review 结果 |
结果整合 |
|
SpecReviewer |
规格合规审查 |
数仓规范 |
|
CodeReviewer |
代码质量审查 |
SQL 规范 |
4.5 多智能体的核心优势
从我们的实践来看,多智能体架构带来了几个明显的好处。
首先是领域专家 + 单一职责带来的可靠性提升。将复杂目标分解为小而具体的子任务,分配给特定领域的 Agent 后,每个 Agent 的"注意力"更集中,上下文内聚在领域内,只对外输出必要的上下文。这有效降低了单一 Agent 因任务过于复杂而产生幻觉的风险。
其次是可扩展性。当需要增加新功能时,只需开发一个新的专业 Agent,接入现有协作框架即可,无需对整个系统进行伤筋动骨的改造。我们在实际开发中已经验证过这一点,新增一个 Agent 的成本很低。
第三是鲁棒性。通过系统设计和流程编排扩展容灾节点。如果某个 Agent 执行失败,协调者可以重新分配任务给另一个功能相似的 Agent,或者调整策略继续执行。系统不再存在"单点故障"的问题。
4.6 通信机制
通信机制是很多人关心的问题。我们的设计采用中心化调度 + 顺序传递模式,而非 Agent 之间的点对点通信。
具体来说,调度方式是 AgentCoordinator 按顺序调用各 Agent,属于同步阻塞式调用;信息传递通过 Python 函数调用传参,context 是一个 dict;结果返回格式统一为 {'status': 'success'/'error', 'output_file': '', 'output_content': ''}。
关于状态管理,主要有四类状态:执行上下文存储在 context dict 中,由 Coordinator 按需构造;中间结果以输出文件形式保存(.md/.sql);Agent 经验存储在独立 .md 文件中;Review 结果通过 suggestions list 传递给重试机制。
还有几个关键的设计决策值得分享。第一,我们不支持并行,因为各 Phase 之间有依赖关系,Phase 2 需要 Phase 1 的输出,顺序执行能保证数据一致性。第二,我们不采用点对点通信,因为中心调度简化了通信复杂度,便于统一管理和问题定位。第三,每个 Agent 之间是独立的,有各自独立的 Memory,经验沉淀不互相干扰。
五、5 Phase 执行流程
5.1 流程图
先给出整体流程的全貌:
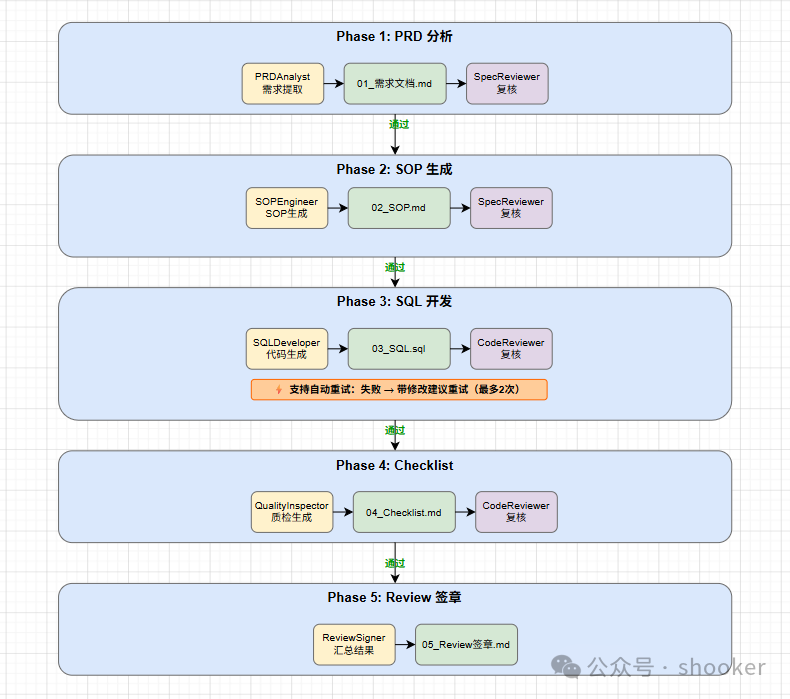
5.2 各 Phase 详解
Phase 1: PRD 分析
|
项目 |
内容 |
|---|---|
|
输入 |
原始 PRD 文档( |
|
Agent |
PRDAnalyst |
|
输出 |
01_数仓需求文档_AI提取版.md |
|
复核 |
SpecReviewer(规格合规) |
PRDAnalyst 会从 PRD 中提取以下关键信息:需求概述(包括背景、目标、系统范围)、需求分类(NEW_TABLE / NEW_FIELD / MODIFY_LOGIC / HISTORY_FIX)、字段定义(表名、字段名、类型、说明、口径)、上游依赖表,以及影响分析(上游影响 / 下游影响 / 指标变化)。
SpecReviewer 的复核重点是:涉及的表是否都已列出、业务口径是否明确、分区字段和 TTL 是否标注、命名是否符合数仓建模规范。
Phase 2: SOP 生成
|
项目 |
内容 |
|---|---|
|
输入 |
Phase 1 输出的需求文档 |
|
Agent |
SOPEngineer |
|
输出 |
02_数仓开发SOP.md |
|
复核 |
SpecReviewer(规格合规) |
SOP 包含 6 大步骤,分别是前置准备(需求确认、字段口径确认、环境确认、建模规范检查)、ODS 层处理(如涉及,需要进行表结构检查、字段同步状态确认)、DWD/DWM 层处理(新增字段 DDL、SQL 重写)、DWS/ADS 层处理(汇总逻辑、聚合逻辑)、数据校验(基础验证、业务验证),以及上线流程(测试验证、发布审批、正式发布,回滚方案)。
Phase 3: SQL 开发
|
项目 |
内容 |
|---|---|
|
输入 |
Phase 1 输出的需求文档 + 数仓规范 |
|
Agent |
SQLDeveloper |
|
输出 |
03_数仓开发代码逻辑.sql |
|
复核 |
CodeReviewer(代码质量) |
|
重试 |
支持(最多2次) |
SQLDeveloper 生成的 SQL 文件使用标记分隔 DDL 和 DML,这样有利于自动化发布时的解析和处理:
-- ==DDL_START==
DROP TABLE IF EXISTS htemp.htemp_xxx;
CREATE TABLE htemp.htemp_xxx (...);
-- ==DDL_END==
-- ==DML_START==
WITH cte AS (...)
INSERT OVERWRITE TABLE htemp.htemp_xxx
PARTITION (dt='${bdp.system.bizdate}')
SELECT ...;
-- ==DML_END==CodeReviewer 的复核涵盖:SQL 语法是否正确、DDL/DROP/CREATE 和 INSERT OVERWRITE 目标表是否为 htemp 库、JOIN 条件是否完整是否有笛卡尔积风险、分区字段是否正确。
Phase 4: Checklist
|
项目 |
内容 |
|---|---|
|
输入 |
Phase 1 需求文档 + Phase 3 SQL 代码 |
|
Agent |
QualityInspector |
|
输出 |
04_上线Checklist.md |
|
复核 |
CodeReviewer(代码质量) |
Checklist 按照模板生成,包含 5 大章节:开发阶段检查项、测试阶段检查项、上线前检查项、上线后检查项、回滚预案。每个子项必须填写具体值,不允许"待配置"、"待确认"等占位符。
Phase 5: Review 签章
|
项目 |
内容 |
|---|---|
|
输入 |
各 Phase 的 Review 结果 |
|
Agent |
ReviewSigner |
|
输出 |
05_Review签章.md |
ReviewSigner 汇总所有 Review 结果,生成结构化签章文档,包含 Spec Review 检查项及结果、Code Quality Review 检查项及结果、人工确认区域、通过标准。
5.3 重试机制
重试机制是我们保证输出质量的核心设计。为什么单独强调 Phase 3?因为 SQL 代码是数仓开发最核心的交付物,质量至关重要。同时 SQL 生成的结果相对明确——要么可执行,要么不可执行——Reviewer 可以给出非常具体的修改建议,这为重试提供了良好的条件。
重试逻辑简单来说就是:第一次执行如果失败,Reviewer 会给出具体建议,带着这些建议进行第二次尝试。最多重试 2 次(包括首次),如果仍然失败,则使用当前版本继续,同时记录警告。
Attempt 1: SQLDeveloper 生成 SQL → CodeReviewer 复核 ↓ 失败 Attempt 2: 带上 suggestions 重试 → CodeReviewer 复核 ↓ 失败 [WARN] 已达最大重试次数,使用当前版本继续
代码层面是这样实现的:
MAX_RETRY = 2 # 最多重试2次(包括首次)
for attempt in range(1, MAX_RETRY + 1):
attempt_start = time.time()
self._emit_log(f"[尝试 {attempt}/{MAX_RETRY}]")
# 第一次正常执行,后续带上修改建议
context = {'requirement_content': requirement_content, 'spec': spec, 'fd_path': fd_path}
if attempt > 1 and review3 and review3.get('suggestions'):
context['improvement_suggestions'] = review3['suggestions']
self._emit_log(f"[INFO] 使用上次Review的修改建议重新生成")
phase3 = self._run_agent('sql_developer', fd_code, context=context)
review3 = self._run_reviewer('code_reviewer', phase3.get('output_file', ''), context=phase3)
if review3.get('passed', True):
self._emit_log(f"[PASS] SQL复核通过")
break
else:
issues_summary = '; '.join(review3.get('issues', [])[:2])
self._emit_log(f"[REJECT] SQL复核未通过: {issues_summary}")
if attempt < MAX_RETRY:
self._emit_log(f"[INFO] 将自动重试(带修改建议)")
else:
self._emit_log(f"[WARN] 已达最大重试次数,使用当前版本继续")improvement_suggestions 传递的是 Review 发现的具体问题和改进建议,比如:DDL中目标表应为htemp.htemp_xxx而非hotel.xxx、分区字段应为dt而非partition_date、INSERT语句缺少PARTITION子句。
从实际效果看,第一次生成基于原始 Prompt 和规范,第二次生成基于原始 Prompt 加上修改建议,精准度明显提升。大多数 SQL 问题都可以在第二次尝试中修复。
六、知识库增强
6.1 知识库构成
知识库是整个 AI 辅助开发系统的"大脑",存储了数仓建设的核心资产。系统维护着三类知识:
|
类型 |
数量 |
用途 |
|---|---|---|
|
表结构 YAML |
~2074 |
字段、血缘、描述 |
|
数仓建模规范 |
- |
分层、TTL、命名 |
|
字段血缘 |
- |
上游追溯(3 层) |
每个表结构 YAML 文件大约长这样:
table_name: dwd_ord_order_base_df
description: 订单域 - 订单基础表
database: hotel
owner: hotel_dw_team
partition_type: dt
ttl: 760
columns:
- name: order_id
type: string
comment: 订单ID
- name: user_id
type: string
comment: 用户ID
upstream_tables:
- ods_qhotel_order
lineage:
- table: ods_qhotel_order
fields:
- order_id -> order_id
- user_id -> user_id6.2 数仓建模规范
数仓建模规范是 AI 必须学会的"语言",也是整个系统的硬约束。这套规范定义了分层架构、TTL 标识、数据域划分等内容。
分层架构规定了各层的定位和命名格式:
|
分层 |
TTL 规范 |
命名格式 |
|---|---|---|
|
ODS |
545 天 (1.5年) |
ods_数据源系统_ttl |
|
DWD |
760 天 (2年) |
dwd_数据域_主题_描述_ttl |
|
DWS |
1095 天 (3年) |
dws_业务场景_描述_ttl |
|
ADS |
760 天 (2年) |
ads_业务场景_描述_ttl |
TTL 标识决定了数据的更新策略:
|
标识 |
含义 |
|---|---|
|
di |
按天分区增量更新 |
|
da |
按天分区全量更新 |
|
hi |
按小时分区增量更新 |
|
ha |
按小时分区全量更新 |
数据域定义则是 DWD 层表命名的依据:
|
数据域 |
英文名 |
说明 |
|---|---|---|
|
流量 |
flow |
搜索、列表、详情页 |
|
订单 |
ord |
订单、交易 |
|
基础信息 |
baseinfo |
城市、商品 |
|
产品力 |
pp |
底价比价、支付价比价 |
|
报价 |
price |
底价、定价、筛选 |
|
用户 |
user |
新老客、画像 |
6.3 知识库查询机制
在 skills/kb_workflow.py 中,我们定义了一套查询函数:
def find_fd_folder(fd_code: str) -> Path:
"""查找 FD 文件夹"""
def find_prd_file(fd_path: Path) -> Path:
"""查找 PRD 文档"""
def load_prd(prd_path) -> Dict:
"""加载 PRD 文档"""
def load_specifications() -> Dict:
"""加载建模规范"""查询触发时机是在每个 Phase 开始时,AgentCoordinator 会自动加载相关知识:
# Phase 0: 验证 & 加载
fd_path = find_fd_folder(fd_code) # 查找 FD 文件夹
prd_path = find_prd_file(fd_path) # 查找 PRD 文档
prd = load_prd(prd_path) # 加载 PRD
spec = load_specifications() # 加载建模规范关于效率和智能程度的平衡,这是我们遇到的核心挑战之一。知识库信息量庞大,全部注入会导致 Token 爆炸,选择性注入又可能遗漏关键信息。我们的解决方案包括四个方面:一是按需查询,只在需要时加载相关表的信息;二是结构化存储,YAML 格式便于按字段快速检索;三是分层管理,规范文档和表结构分离;四是上游追溯限制,血缘查询限制 3 层,避免无限递归。
6.4 知识库同步
为了保证知识库的时效性,我们实现了每日自动同步机制:
python src/scripts/kb_sync.py # 执行同步
python src/scripts/kb_sync.py --dry-run # 预览变化
python src/scripts/kb_sync.py --full # 全量同步
python src/scripts/kb_sync.py --check # 检查是否需要同步七、Playwright 自动化发布
7.1 为什么需要自动化发布?
传统的数仓开发流程中,SQL 代码生成之后,还需要人工登录系统、上传 SQL、执行建表、配置任务等一系列操作。这些操作重复性很高,耗时长,而且容易出错。特别是当我们需要频繁发布任务时,人工操作的效率就成了瓶颈。
为了解决这个问题,我们引入了 Playwright 浏览器自动化技术,实现从"SQL 生成"到"任务上线"的全流程自动化。
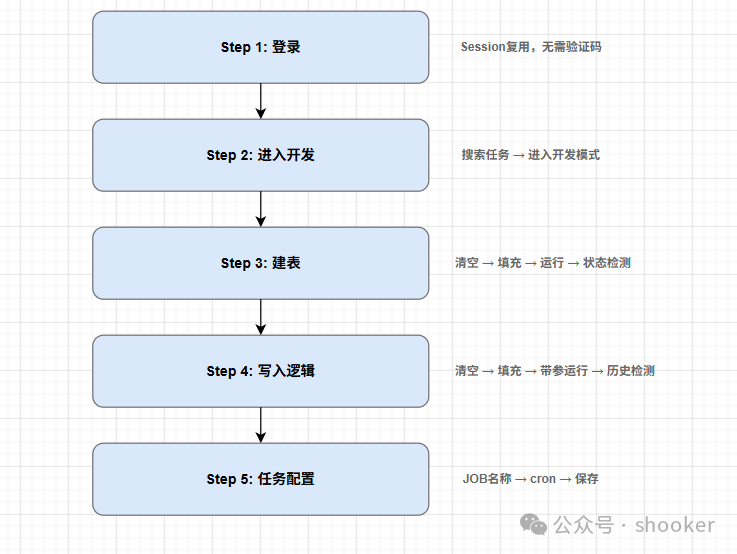
7.2 5 步流程
整个自动化发布流程分为 5 个步骤:
7.3 门禁机制
门禁机制是保证自动化发布安全性的核心设计。简单来说,每一步执行前,必须检查前一步是否成功完成。如果前一步失败了,后续步骤不仅没有意义,反而可能污染数据环境。因此,及时阻断是最小化损失的方式。
|
Step |
名称 |
门禁检查 |
说明 |
|---|---|---|---|
|
Step 1 |
Session复用登录 |
无(第一步) |
Session有效则免验证码 |
|
Step 2 |
搜索任务进入开发模式 |
检查 login |
填写任务ID → 搜索 → 进入开发 |
|
Step 3 |
建表(DDL) |
检查 enter_dev_mode |
清空→填充→运行→状态检测 |
|
Step 4 |
INSERT写入逻辑 |
检查 create_table |
清空→填充→带参运行→运行历史检测 |
|
Step 5 |
任务配置+保存 |
检查 insert_logic |
打开配置→填写JOB→选择SPARK→保存 |
门禁检查的代码逻辑很清晰:
# Step 3: 建表
if not self.fill_and_run_create_table(create_table_sql, verbose):
result["error"] = "建表失败"
# ⭐ 包含详细错误日志
if self.last_detailed_error_log:
result["detailed_error_log"] = self.last_detailed_error_log
return result # 不进入下一步
result["steps"]["create_table"] = True
# Step 4: 写入逻辑
if not self.fill_and_run_insert_logic(insert_logic_sql, verbose):
result["error"] = "写入逻辑失败"
return result # 不进入下一步
result["steps"]["insert_logic"] = True7.4 失败反馈闭环
自动化发布难免会遇到失败的情况。我们的设计是:INSERT 失败时,自动调用 Claude API 分析错误原因并重新生成 SQL。
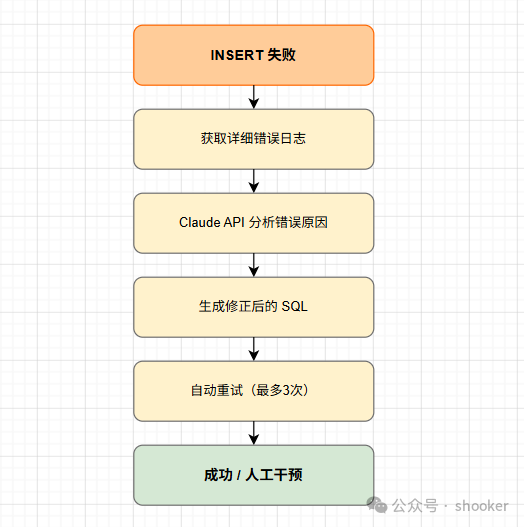
完整反馈循环的代码逻辑如下:
class CompleteFeedbackLoop:
"""失败反馈闭环"""
def run_with_feedback(self, create_table_sql, insert_logic_sql, max_attempts=3):
for attempt in range(1, max_attempts + 1):
result = self._run_single_attempt(create_table_sql, insert_logic_sql)
if result.get("success"):
return result
# 获取错误日志
error_log = result.get("detailed_error_log")
if not error_log:
continue
# 调用 Claude API 重新生成 SQL
print(f"[Attempt {attempt}] INSERT失败,开始分析错误...")
new_sql = self._regenerate_sql(error_log, insert_logic_sql)
if new_sql:
insert_logic_sql = new_sql
print(f"[Attempt {attempt}] SQL重新生成成功,将重试")
else:
print(f"[Attempt {attempt}] SQL重新生成失败")
continue
# 达到最大次数,人工干预
return {
"success": False,
"error": "已达最大重试次数,需要人工干预"
}Claude API 重新生成 SQL 的逻辑很直接:把原始 SQL 和错误日志一起发给大模型,让它分析错误原因并生成修正后的 SQL。
def _regenerate_sql(self, error_log: str, original_sql: str) -> str:
"""调用 Claude API 分析错误并重新生成 SQL"""
prompt = f"""
原始 SQL:
{original_sql}
执行错误:
{error_log}
请分析错误原因,并生成修正后的 SQL。
要求:
1. 修正错误
2. 保持原有逻辑
3. 仅输出 SQL 代码,不要解释
"""
response = call_minimax_api(prompt)
return extract_sql(response)重试策略分为三个层级:Attempt 1 正常执行建表加 INSERT,失败后获取错误日志并发给 Claude 分析,生成新 SQL;Attempt 2 使用新 SQL 重试 INSERT,失败则重复上述流程;Attempt 3 是最后一次尝试,仍失败则转入人工干预流程。
从实际效果来看,大多数 INSERT 错误(比如分区字段不正确、JOIN 条件缺失)都可以在重试中修复。系统同时记录详细错误日志,便于人工介入时快速定位问题。
八、技术选型思考
8.1 为何自研而非 LangGraph4j?
LangGraph4j 是 Java 生态中相当不错的一个多智能体框架。在决定技术方案之前,我们认真评估过它,但最终选择了自研。主要原因有三点:
首先,团队技术栈匹配。我们的后端使用 Python + FastAPI,自研可以直接复用现有技术栈,不需要额外的跨语言适配。其次,数仓场景的特殊性。通用框架难以满足我们特殊的业务需求——规范的硬约束、Review 闭环、重试机制、安全校验,这些深度定制的功能自研更灵活。第三是 Agent Memory 集成。我们的系统需要每个 Agent 有独立的记忆文件,跨会话积累经验。通用框架的 Memory 支持往往不够细致,无法满足我们的需求。
这里需要说明的是,选择自研并不意味着我们认为 LangGraph4j 不好。它的设计思路值得借鉴,只是在我们当前的规模和场景下,自研的定制化开发和维护成本更低。
8.2 何时单 Agent 已足够?
虽然我们最终采用了多智能体架构,但必须承认,在许多场景下,一个精心设计的单 Agent 不仅足够,而且是更优的选择。
比如,当任务范围被严格限定在单一领域内时——典型的如"订单查询助手",唯一职责就是调用订单系统查询数据——单 Agent 完全够用。再比如,当 Agent 需要调用的工具数量有限(通常少于 5 个)、且功能边界清晰不易混淆时,单 Agent 的效率更高。还有,如果任务可以被分解为一系列相对固定的步骤,即使有分支也数量有限且逻辑清晰,单 Agent 的可控性优势就更明显了。
8.3 单 Agent 到多 Agent 的阈值参考
对于何时该从单 Agent 扩展到多 Agent,我们总结了一个参考阈值:
|
维度 |
单 Agent 上限 |
多 Agent 触发条件 |
|---|---|---|
|
工具数量 |
< 5 个 |
> 5 个 |
|
任务步骤 |
< 3 步 |
> 3 步 |
|
涉及领域 |
1 个 |
> 1 个 |
|
Prompt 长度 |
< 2000 tokens |
> 2000 tokens |
判断是否该拆分的那个关键信号是:当你的 Agent 的 Prompt 变得臃肿不堪,里面充满了"如果你是 A,就做 X;如果你是 B,就做 Y"这类条件分支指令时,就是该拆分为多 Agent 的信号。
8.4 Harness 设计的重要性
Harness 是测试框架和状态管理机制的总称。在我们的系统中,_log_callback、ancellation_flags、stop_event 等都是 Harness 的一部分。
为什么 Harness 这么重要?我总结为四点:一是状态追踪,results['phases'] 记录每个 Phase 的执行状态,便于问题定位;二是可观测性,实时日志回调让用户随时了解进度;三是可控性,取消标志、停止事件让用户能中断长时间运行的任务;四是可重试性,上下文传递和重试机制依赖 Harness 设计。
这里有一个惨痛的教训:早期我们忽略了 Harness 的设计,导致 Agent 行为不可预测、问题难以复现。后来投入了大量时间进行重构,才解决了"Agent 不可控"的问题。所以建议大家在设计 Agent 系统时,Harness 部分要提前规划,不要走我们的弯路。
8.5 Agent 不可控的教训
说到"Agent 不可控",这可能是所有从事 AI 应用开发的同行都会遇到的问题。我们的具体表现包括:生成内容不固定,同一输入可能生成完全不同的 PRD 或 SQL;模型幻觉,AI 可能"幻觉"出不存在的字段或表名;工具选择错误,功能相似的工具被混淆;流程偏移,Agent 不按预设路径执行。
针对这些问题,我们采取了几项应对措施:Review 闭环通过自动重试机制和具体修改建议传递来保证质量;知识库约束通过表结构 YAML 限制 AI 的"幻觉"空间;安全校验通过 htemp 库检查确保不会污染生产环境;内容完整性校验通过 DDL/DML 标记检查确保格式正确。
核心经验是:Agent 的"不可控"不是 AI 的问题,而是系统设计的问题。通过合理的约束和反馈机制,可以让 Agent 在可控的范围内发挥最大的能力。
九、总结
9.1 核心观点
经过这段时间的实践,我们总结出几个核心观点。
第一,不是非此即彼,而是程度问题。Workflow 与 Agent 不是非此即彼的选择,而是根据场景找到控制与自主的最佳平衡点。在数仓开发中,建表 SQL 生成偏向 Workflow(规范明确),需求理解偏向 Agent(需要推理)。
第二,领域专家 + 单一职责。每个 Agent 专注于一个领域,注意力更集中,上下文内聚在领域内。这有效降低了单一 Agent 因任务过于复杂而产生幻觉的风险。
第三,Review 闭环保证质量。每个 Phase 后都有 Reviewer 把关(SpecReviewer / CodeReviewer),支持自动重试加修改建议传递,确保交付物质量。
第四,知识库增强一致性。2074 张表的表结构知识库加数仓建模规范,保证 AI 生成的输出符合数仓标准。
第五,Harness 设计决定可控性。Agent 的"不可控"不是 AI 的问题,而是系统设计的问题。通过合理的约束和反馈机制,可以让 Agent 在可控的范围内发挥最大的能力。
9.2 适用场景
关于这套方案适用和不适用的场景,这里也做一个说明:
|
场景 |
推荐模式 |
原因 |
|---|---|---|
|
标准化建表 SQL |
Workflow |
规范明确,必须遵循数仓建模规范 |
|
需求理解 + SOP 设计 |
Agent |
需要推理,理解业务语义 |
|
复杂多领域任务 |
Multi-Agent(Supervisor) |
各司其职,协同完成 |
|
高频重复需求 |
自动化发布 |
Playwright 一键发布 |
不适用场景包括:涉及实时数据或外部 API 依赖的复杂查询;需要多轮交互才能澄清的模糊需求,这种情况下建议人工介入;高度敏感的财务或合规数据,建议人工审核。
9.3 后续演进方向
关于后续的演进,我们有三个方向在探索。
一是网络模式。未来的某天,Agent 之间可以相互调用,形成更灵活的协作。比如当 SQLDeveloper 发现需求涉及新领域时,可以自动调用 PRDAnalyst 重新澄清需求,而不需要人工介入。
二是人机协同。在关键节点设置人工确认环节。比如 Phase 1 的 PRD 分析结果需要人工确认后才能进入 Phase 2,确保 AI 没有理解偏差。
三是 Claude Code API 集成。当 Playwright 自动化失败时,自动调用 Claude API 重新生成 SQL,实现端到端的自动化闭环。
9.4 写在最后
这篇文章从数仓开发的实际痛点出发,分享了我们如何从单智能体演进到多智能体协作的设计思路和实践经验。
最后想说的是,AI Agent 的"不可控"不是 AI 的本身的问题,而是系统设计的问题。通过合理的架构设计、规范约束、质量门控,我们可以让 AI 在可控的范围内发挥最大的能力,真正成为数仓开发者的智能助手。
这条路还在探索中,希望我们的经验对大家有所帮助。如果有任何问题或想法,欢迎交流。
参考资料
- Anthropic - Building Effective Agents
: https://www.anthropic.com/engineering/building-effective-agents
- LangChain Blog
: https://blog.langchain.dev

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)