值得 Dify 新人收藏的 “高频踩坑点“:我踩过的所有坑,帮你一次性避完
前言
Dify 作为目前最易用的低代码大模型应用开发平台,让很多没有深厚大模型背景的开发者也能快速搭建出智能客服、知识库问答、AI 代理等复杂应用。但 "易用" 不代表 "无坑",尤其是对于刚接触 Dify 的新人来说,从模型配置、知识库搭建到工作流编排、API 扩展,几乎每一步都可能遇到让人卡壳几个小时甚至几天的问题。
我在过去一个月里,从零开始搭建了文章阅读器、AI 图像生成代理、带知识库的智能客服、微博账号分析器等多个 Dify 应用,踩遍了模型、节点、配置、知识库、API 扩展等几乎所有环节的坑。这篇文章就是我所有踩坑经验的浓缩,希望能帮你少走弯路,把更多时间花在业务逻辑本身,而不是解决平台的各种 "玄学问题" 上。
一、模型配置与调用:90% 的新人第一个卡壳的地方
模型是 Dify 应用的核心,但不同模型的兼容性、调用方式、参数配置差异巨大,这也是新人最容易踩坑的第一个环节。
1.1 模型选择与兼容性踩坑
问题现象:明明在模型管理里添加了模型,测试时却提示 "模型不支持该功能";或者同样的 prompt,换一个模型就完全不生效。典型案例:
- 使用 DeepSeek V4 Flash 做代码生成时,输出格式混乱,无法按照指定的 JSON 格式返回
- 用通义万相做图像生成时,提示 "模型不支持对话模式"
- 切换模型后,之前调试好的 prompt 效果一落千丈
原因分析:
- 不同模型支持的能力不同:有些模型只支持文本生成,不支持工具调用、代码执行或图像生成
- 不同模型的 prompt 格式要求不同:比如 DeepSeek 系列对系统提示词的敏感度远高于 GPT 系列
- 部分模型有特殊的参数要求:比如 DeepSeek V4 Flash 需要将 "温度" 参数调低到 0.1 以下才能获得稳定的结构化输出
解决方案:
- 先看模型能力矩阵:在添加模型前,先查看 Dify 官方的模型支持列表,确认该模型支持你需要的功能(工具调用、代码执行、图像理解等)
- 为不同模型单独写 prompt:不要指望一套 prompt 能通吃所有模型,尤其是结构化输出和工具调用场景
- DeepSeek 系列模型专属配置:
- 温度 (Temperature):0.05-0.1(结构化输出)
- 最大 token 数:不要超过模型上下文窗口的 80%
- 系统提示词:放在最前面,用明确的指令格式,避免模糊表述
1.2 流式输出与响应处理踩坑
问题现象:前端调用 Dify API 时,流式输出断断续续;或者非流式调用时,响应超时。原因分析:
- Dify 的流式输出采用 SSE 协议,很多前端框架默认不支持
- 大模型生成长文本时,响应时间会超过默认的超时时间
- 部分反向代理(如 Nginx)会缓存 SSE 响应,导致流式输出失效
解决方案:
- 前端使用专门的 SSE 客户端库,如
eventsource - 将 API 调用的超时时间设置为 60 秒以上
- Nginx 反向代理配置:
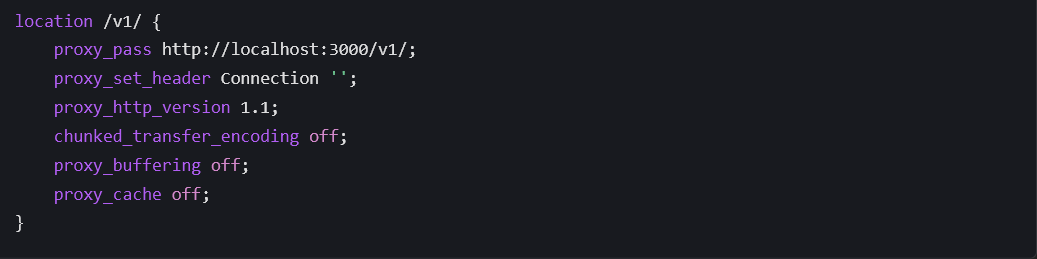
1.3 Token 计算与上下文窗口踩坑
问题现象:明明输入的文本不长,却提示 "上下文长度超过限制";或者模型输出被意外截断。原因分析:
- Dify 显示的 token 数和模型实际计算的 token 数不一致
- 系统提示词、历史对话、知识库召回内容都会占用上下文窗口
- 部分模型的上下文窗口是 "输入 + 输出" 共享的
解决方案:
- 预留至少 20% 的上下文窗口给输出
- 使用 Dify 内置的 "上下文压缩" 功能,自动压缩历史对话
- 对于长文本处理,优先使用 "文档分段" 功能,而不是一次性传入整个文档
二、知识库:新人最容易搞砸的核心功能
知识库是 Dify 最强大的功能之一,但也是坑最多的地方。很多新人抱怨 "知识库问答效果差",其实 90% 都不是模型的问题,而是知识库的配置和使用方式不对。
2.1 文档切分参数踩坑
问题现象:知识库召回的内容不相关;或者召回的内容太碎,上下文不完整。典型案例:上传了一篇 10000 字的技术文章,提问时只能召回零散的句子,无法回答需要上下文的问题。原因分析:
- 默认的文档切分参数(块大小 1000,重叠 200)并不适合所有类型的文档
- 代码文档、表格、列表等特殊内容,用普通的文本切分方式会破坏结构
- 切分块太大,会导致召回精度下降;切分块太小,会导致上下文丢失
解决方案:
| 文档类型 | 推荐块大小 | 推荐重叠大小 |
|---|---|---|
| 普通文章、博客 | 500-800 | 100-150 |
| 技术文档、教程 | 800-1200 | 200-300 |
| 代码文件 | 300-500 | 50-100 |
| 表格、列表 | 按逻辑单元切分 | 0 |
最佳实践:
- 上传文档前,先手动清理掉无关内容(页眉、页脚、广告、导航栏等)
- 对于代码文件,使用 "代码" 类型的文档解析器
- 切分完成后,一定要预览切分结果,手动调整不合理的块
2.2 向量数据库与召回方式踩坑
问题现象:同样的问题,有时候能召回正确内容,有时候却完全不相关;或者召回的内容太多,噪音太大。原因分析:
- 默认的向量数据库(Chroma)在数据量超过 1000 条时,召回性能和精度会明显下降
- 单一的向量召回方式无法处理所有类型的问题
- 召回数量设置不合理:太少会漏召回,太多会引入噪音
解决方案:
- 数据量超过 1000 条时,建议切换到 PostgreSQL+pgvector 或 Milvus
- 使用 "混合召回" 模式(向量召回 + 全文检索),提高召回精度
- 召回数量设置为 3-5 条,最多不超过 10 条
- 开启 "重排序" 功能,使用专门的重排序模型(如 bge-reranker)对召回结果进行二次排序
2.3 知识库更新与同步踩坑
问题现象:更新了知识库中的文档,但问答时还是返回旧内容;或者删除了文档,仍然能召回相关内容。原因分析:
- Dify 的知识库更新是异步的,大文档更新可能需要几分钟甚至十几分钟
- 删除文档时,向量数据库中的向量不会立即被删除
- 应用会缓存知识库的部分内容,导致更新不生效
解决方案:
- 更新文档后,等待 5-10 分钟再测试
- 如果更新不生效,尝试点击知识库的 "重新同步" 按钮
- 删除文档后,清空应用的缓存,或者重启 Dify 服务
三、工作流与节点:从 "能用" 到 "好用" 的最大障碍
当你掌握了基础的对话和知识库功能后,工作流就是你实现复杂业务逻辑的利器。但工作流中的各种节点,尤其是代码节点、分支节点和循环节点,隐藏着很多容易被忽略的坑。
3.1 代码节点:最强大也最危险的节点
问题现象:代码在本地运行正常,但在 Dify 的代码节点中却报错;或者代码执行成功,但无法获取返回结果。典型案例:
- 导入第三方库时,提示 "ModuleNotFoundError"
- 代码中使用了
print()函数,但无法在日志中看到输出 - 返回的 JSON 格式正确,但后续节点无法获取变量
原因分析:
- Dify 的代码节点运行在沙箱环境中,默认只安装了少量基础库
- 沙箱环境有严格的权限限制,无法访问本地文件系统和网络
- 代码节点的返回值必须是一个 JSON 对象,且不能包含特殊字符
解决方案:
- 第三方库安装:
- 先在代码节点顶部使用
pip install命令安装需要的库 - 示例:
- 先在代码节点顶部使用

- 日志输出:使用
console.log()而不是print() - 返回值格式:严格返回一个 JSON 对象,不要返回其他类型
- 网络访问:如果需要访问外部 API,使用 Dify 内置的 "HTTP 请求" 节点,而不是在代码节点中使用
requests
3.2 变量传递与引用踩坑
问题现象:明明在前面的节点中定义了变量,但后面的节点却提示 "变量不存在";或者变量的值不是预期的内容。原因分析:
- Dify 的变量引用有严格的语法:
{{变量名}},大小写敏感 - 不同节点的输出变量格式不同,需要根据节点类型来引用
- 分支节点和循环节点中的变量作用域不同
解决方案:
- 不要手动输入变量名,使用 Dify 的变量选择器自动插入
- 引用变量前,先查看前面节点的输出示例,确认变量的结构
- 在分支节点中,每个分支都需要单独设置输出变量
- 在循环节点中,使用
{{loop.item}}引用当前循环项
3.3 分支与循环节点踩坑
问题现象:分支节点的条件判断永远不成立;或者循环节点陷入死循环。原因分析:
- 分支节点的条件判断是严格的字符串匹配,不支持隐式类型转换
- 循环节点没有设置退出条件,或者退出条件永远不成立
- 循环节点的最大迭代次数默认是 10 次,超过会被强制终止
解决方案:
- 分支节点条件判断:
- 正确:
{{变量名}} == "true" - 错误:
{{变量名}} == true
- 正确:
- 循环节点必须设置明确的退出条件
- 如果需要循环超过 10 次,手动调整循环节点的 "最大迭代次数" 参数
四、API 集成与扩展:生产环境部署的必经之路
当你把 Dify 应用开发完成后,最终都需要通过 API 集成到自己的业务系统中。但 Dify 的 API 虽然看起来简单,实际使用中却有很多容易踩坑的地方。
4.1 API 调用与认证踩坑
问题现象:调用 Dify API 时,提示 "未授权";或者同样的请求,有时候成功有时候失败。原因分析:
- API 密钥错误,或者密钥没有对应的应用权限
- 请求头中的
Authorization格式错误 - Dify 的 API 有频率限制,超过限制会被临时封禁
解决方案:
- 正确的请求头格式:

- 每个应用都有独立的 API 密钥,不要混用
- 合理控制 API 调用频率,避免超过限制(免费版是 60 次 / 分钟)
4.2 FastAPI 扩展踩坑
问题现象:按照官方文档写的 FastAPI 扩展,无法被 Dify 识别;或者扩展的接口调用失败。原因分析:
- FastAPI 扩展的目录结构和文件命名有严格要求
- 扩展的接口必须符合 Dify 的 API 规范
- Dify 和 FastAPI 扩展之间的网络不通
解决方案:
- 使用我整理的生产级 FastAPI Dify 扩展模板(已包含标准格式、错误处理、日志记录和跨域配置)
- 确保 Dify 服务能够访问到 FastAPI 扩展的地址和端口
- 在 Dify 的 "API 扩展" 中,正确填写扩展的基础 URL 和接口路径
4.3 错误处理与日志踩坑
问题现象:API 调用失败,但不知道具体原因;或者 Dify 的日志中没有有用的错误信息。原因分析:
- Dify 的默认日志级别是 INFO,很多错误信息不会显示
- API 返回的错误信息过于笼统,无法定位问题
- 没有对 API 调用的异常情况进行处理
解决方案:
- 将 Dify 的日志级别调整为 DEBUG:
- 修改
docker-compose.yml中的LOG_LEVEL环境变量为DEBUG - 重启 Dify 服务
- 修改
- 在自己的业务代码中,对 API 调用的所有异常情况进行捕获和处理
- 记录完整的请求和响应日志,方便问题排查
五、本地部署与运维:自己搭 Dify 才会遇到的坑
如果你是在本地部署 Dify,而不是使用官方的云服务,那么你还会遇到很多部署和运维相关的坑。
5.1 环境依赖与安装踩坑
问题现象:按照官方文档执行docker-compose up -d,但服务启动失败;或者部分服务一直处于重启状态。原因分析:
- Docker 和 Docker Compose 的版本过低
- 端口被其他程序占用
- 国内网络环境下,无法拉取 Docker 镜像
解决方案:
- 确保 Docker 版本≥20.10,Docker Compose 版本≥2.0
- 检查端口占用:

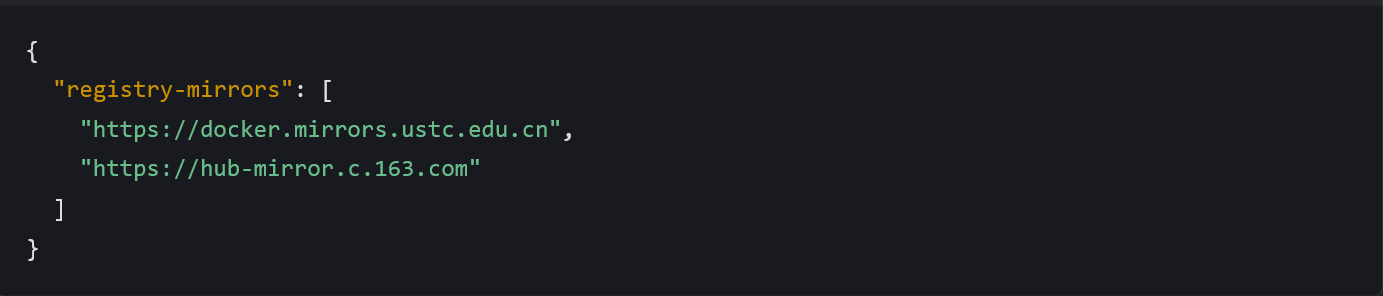
使用国内镜像源加速 Docker 镜像拉取:
- 修改
/etc/docker/daemon.json:
-
- 重启 Docker 服务:
sudo systemctl restart docker
- 重启 Docker 服务:
5.2 数据持久化与备份踩坑
问题现象:重启 Dify 服务后,所有的应用和知识库都消失了;或者数据库损坏,无法恢复。原因分析:
- 没有正确配置 Docker 卷,数据保存在容器内部
- 没有定期备份数据库
- 磁盘空间不足,导致数据库写入失败
解决方案:
- 使用官方的
docker-compose.yml,它已经正确配置了数据卷 - 定期备份 PostgreSQL 数据库:

- 监控磁盘空间,确保至少有 10GB 的可用空间
5.3 性能优化踩坑
问题现象:随着用户量增加,Dify 服务变得越来越慢;或者并发请求稍多就会崩溃。原因分析:
- 默认的资源配置太低,无法支撑高并发
- 向量数据库没有做性能优化
- 没有启用缓存功能
解决方案:
- 调整 Docker 容器的资源限制:
- 修改
docker-compose.yml中的deploy.resources配置 - 建议至少分配 4 核 CPU 和 8GB 内存给 Dify 服务
- 修改
- 为 PostgreSQL 和 Redis 分配更多的内存
- 启用 Dify 的内置缓存功能,减少重复的模型调用和知识库查询
六、避坑总结与新人学习路线建议
6.1 新人最容易犯的 5 个错误
- 上来就搞复杂应用:不要一开始就想做一个无所不能的 AI 代理,先从最简单的对话应用开始,逐步掌握各个功能
- 不看官方文档:Dify 的官方文档非常详细,90% 的问题都能在文档中找到答案
- 盲目切换模型:先把一个模型用熟,搞清楚它的优缺点和最佳配置,再尝试其他模型
- 不做测试:每添加一个节点、修改一个参数,都要立即测试,不要等到整个应用做完才测试
- 遇到问题就放弃:Dify 还在快速发展中,有 bug 很正常,多搜索、多尝试,大部分问题都能解决
6.2 我的 Dify 学习路线建议
- 第 1-3 天:熟悉 Dify 的基本界面和功能,搭建一个简单的对话应用
- 第 4-7 天:学习知识库的搭建和使用,做一个简单的文档问答应用
- 第 8-14 天:学习工作流编排,掌握代码节点、HTTP 请求节点和分支节点的使用
- 第 15-21 天:学习 API 调用和扩展,把自己的应用集成到业务系统中
- 第 22-30 天:学习本地部署和运维,优化应用的性能和稳定性
写在最后
Dify 是一个非常优秀的大模型应用开发平台,它极大地降低了 AI 应用的开发门槛。但任何工具都有学习曲线,踩坑是不可避免的。希望这篇文章能帮你避开那些我已经踩过的坑,让你在 Dify 的学习道路上走得更顺畅。
如果你在学习过程中遇到了文章中没有提到的问题,欢迎大家在评论区留言交流。罗飞怪兽会尽己所能为你解答!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)