【vLLM-Ascend】基于PyTorch Profiler的性能数据采集实践
作者:昇腾实战派
背景概述
在大模型推理服务的性能调优过程中,精准定位计算瓶颈、分析算子执行效率与资源利用率是提升系统吞吐与响应速度的关键。vLLM-Ascend作为基于昇腾NPU的高性能推理框架,集成了Ascend PyTorch Profiler能力,支持从框架层到硬件层的全栈性能数据采集。本文以Qwen3-32B模型为例,详细介绍如何在v0.14.0rc1版本中配置并采集在线服务的profiling数据,涵盖环境准备、服务拉起、采集触发、结果解析等全流程操作,帮助开发者快速掌握性能分析工具链的使用方法。
一、环境准备
1.1 软硬件环境
| 项目 | 配置 |
|---|---|
| 设备款型 | Atlas 800I A2 |
| 驱动版本 | 25.3.rc1.2 |
| vLLM-Ascend版本 | v0.14.0rc1 |
| 模型名称 | Qwen3-32B |
⚠️ 注意:若当前环境未安装Ascend-CANN-Toolkit开发套件,将无法使用
msprof命令进行性能分析,请确保已正确部署相关依赖。
1.2 模型权重准备
参考Qwen3-Dense模型部署指南,完成模型权重的下载与本地化存储。对于多节点部署场景,建议将模型文件统一放置于共享存储路径下,以保证各节点访问一致性。

1.3 镜像与容器配置
拉取指定版本镜像
docker pull quay.io/ascend/vllm-ascend:v0.14.0rc1
创建运行容器
docker run --rm \
--name vllm-ascend-env \
--shm-size=1g \
--net=host \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-it quay.io/ascend/vllm-ascend:v0.14.0rc1 bash
✅ 参数说明:
--rm:容器退出后自动清理--shm-size=1g:设置共享内存大小,避免因内存不足导致异常--net=host:使用主机网络模式,便于API服务访问--device:挂载所有NPU设备节点-v:挂载关键驱动与工具路径,保障profiling功能正常运行-it:交互式终端运行
二、常用配置说明
vLLM-Ascend在初始化NPUWorker时自动创建torch_npu.profiler实例,相关代码位于vllm-ascend/vllm_ascend/worker/worker.py。默认配置如下:
核心参数说明
| 参数 | 说明 |
|---|---|
profiler_level |
默认为Level1,建议在分析AI Core性能时设置为Level1或Level2 |
aclgraph 模式 |
vLLM默认启用分段图模式(cudagraph_mode=PIECEWISE)如需单算子模式,启动时添加 --enforce_eager True如需整图模式,添加 --compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY"}' |
aic_metrics |
用于采集AI Core关键性能指标,如PipeUtilization(流水线利用率)、ArithmeticUtilization(算术利用率)等,需配合profiler_level=L1使用 |
📌 提示:若需获取
aic_mac等底层硬件指标,必须设置profiler_level=L1且启用aic_metrics=PipeUtilization。
三、Profiling数据采集流程
3.1 启用采集功能
根据vLLM-Ascend版本不同,启用方式略有差异:
-
v0.14.0 及之前版本:通过环境变量开启
export VLLM_TORCH_PROFILER_DIR="./vllm-prof" -
v0.14.0 与 v1.0.0 版本:使用命令行参数
--profiler-config.torch_profiler_dir "./vllm-prof/curl-piecewise/" -
v0.16.0 及以上版本:推荐使用JSON格式配置
--profiler-config '{"profiler": "torch", "torch_profiler_dir": "<save-path>", "torch_profiler_with_stack": false}'
3.2 启动在线推理服务
在容器内执行以下命令拉起服务:
python -m vllm.entrypoints.openai.api_server \
--model "/data/Qwen3-32B" \
--served-model-name qwen3 \
--async-scheduling \
--no-enable-prefix-caching \
--tensor-parallel-size 4 \
--port 8113 \
--max-num-seqs 128 \
--max-model-len 256 \
--dtype bfloat16 \
--profiler-config.torch_profiler_dir "./vllm-prof/curl-piecewise/"
✅ 参数解释:
--model:指定本地模型路径(必须为真实目录)--served-model-name:对外服务别名,客户端请求时使用--async-scheduling:启用异步调度,提升并发能力--no-enable-prefix-caching:关闭前缀缓存,节省显存--tensor-parallel-size:TP并行度,控制模型切分粒度--port:API监听端口,默认8000--max-num-seqs:最大并发请求数--max-model-len:最大上下文长度(输入+输出)--dtype:推理数据类型,bfloat16可兼顾精度与性能--profiler-config.torch_profiler_dir:指定profiling输出路径
✅ 成功标志:控制台输出“Application startup complete.”,表示服务已就绪。

3.3 采集方式一:curl命令触发
1. 开始采集
curl -X POST http://localhost:8113/start_profile
2. 发送推理请求
curl http://localhost:8113/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3",
"prompt": "San Francisco is a",
"max_tokens": 12,
"temperature": 0
}'
🔍 说明:
temperature=0确保生成结果确定,便于复现与分析。
3. 停止采集
curl -X POST http://localhost:8113/stop_profile
✅ 若返回
{"detail":"Not Found"},请检查服务是否正确配置profiler_config路径。
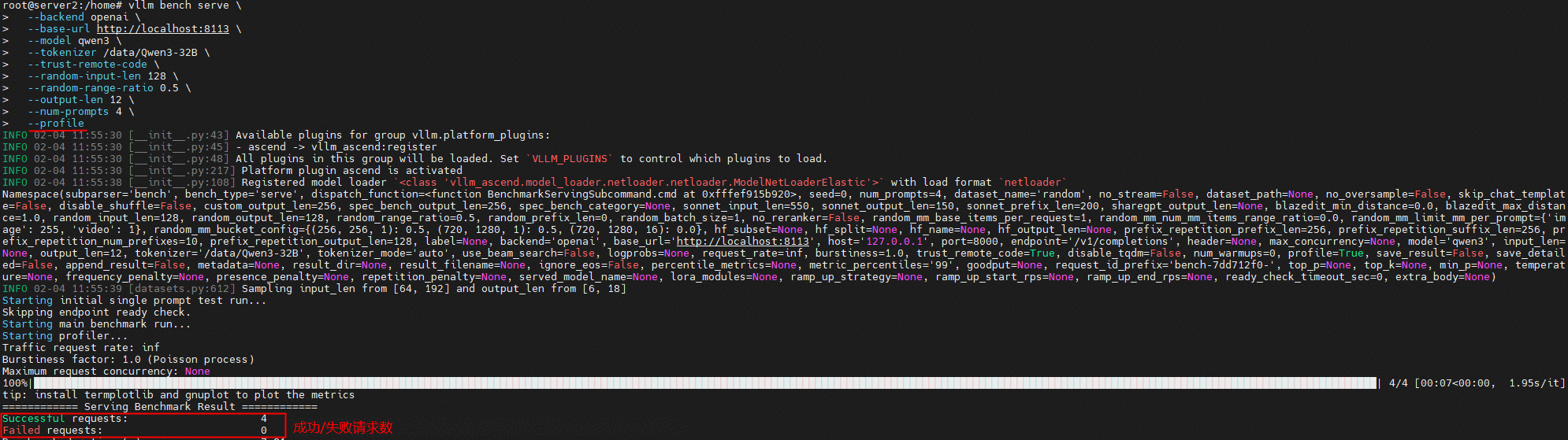
3.4 采集方式二:benchmark工具采集
使用vLLM内置的基准测试工具,自动完成请求生成与profiling采集:
vllm bench serve \
--backend openai \
--base-url http://localhost:8113 \
--model qwen3 \
--tokenizer /data/Qwen3-32B \
--trust-remote-code \
--random-input-len 128 \
--random-range-ratio 0.5 \
--output-len 12 \
--num-prompts 4 \
--profile
✅ 参数说明:
--backend openai:使用OpenAI兼容接口--base-url:服务地址,bench工具会自动拼接接口路径--model:请求中使用的模型名称(非路径)--tokenizer:本地tokenizer路径,用于token化输入--trust-remote-code:允许加载自定义代码--random-input-len:输入长度基准值--random-range-ratio:输入长度波动范围--output-len:最大生成长度--num-prompts:生成请求数量--profile:开启服务端profiling采集
⚠️ 注意:控制输入长度,避免因过长导致内存溢出或采集失败。
四、Profiling结果解析
4.1 解析命令
使用torch_npu.profiler.analyse接口对采集结果进行解析:
python3 -c "from torch_npu.profiler.profiler import analyse; analyse('/home/vllm-prof/curl-piecewise/')"
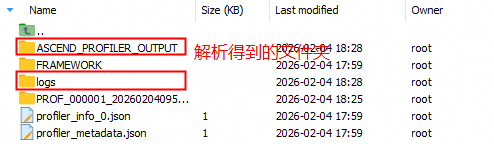
✅ 成功后将在指定目录生成
ASCEND_PROFILER_OUTPUT文件夹,包含以下两类核心文件:
1. Timeline文件(trace_view.json)
- 使用 MindStudio Insight 打开,可视化展示:
- 各层级算子调用关系
- 执行时序与重叠情况
- 框架调用栈(需开启
with_stack) - AI Core算子执行时间与下发路径
2. Summary文件
- 多维度性能统计摘要,典型文件包括:
kernel_details.csv:算子详细信息(名称、耗时、输入输出形状等)communication.json:通信算子信息(HCCL通信时间、带宽等)aicore_metrics.csv:AI Core性能指标(流水线、算术、内存利用率等)
📊 建议结合
Overlap Analysis分析计算、通信、空闲时间占比,定位性能瓶颈。
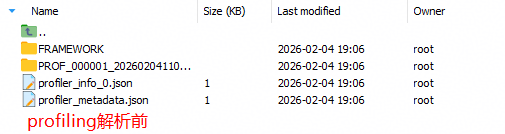
4.2 解析前后对比
解析前目录结构:
解析后目录结构:
可将解析后的文件直接导入MindStudio Insight进行分析。
五、总结与建议
本文系统介绍了在vLLM-Ascend框架中使用PyTorch Profiler进行性能数据采集的完整流程,涵盖环境准备、服务拉起、采集触发、结果解析等关键环节。通过合理配置profiler_level与aic_metrics,可深入分析AI Core算子执行效率;结合curl与benchmark两种采集方式,满足不同场景下的性能验证需求。
✅ 推荐实践:
- 在性能调优阶段,优先使用
benchmark方式批量采集- 在定位特定请求瓶颈时,采用
curl方式精准控制采集范围
📚 参考资料:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)