让图神经网络学会读懂化工流程图:一种知识驱动的图自编码和注意力时空卷积的故障诊断方法(PyTorch)
化工过程故障诊断中,有一个长期被忽视的问题:
传感器测点之间的物理连接关系,能不能像人类看工艺流程图那样,被模型用来理解故障的传播路径?
传统的深度学习方法将每个传感器变量看做独立的时序信号,完全忽略了它们之间由管道、反应器、换热器等设备决定的空间拓扑结构。当某个故障发生时(例如进料阀卡死),影响会沿着工艺流程向下游传播——一个仅仅盯着单变量时间序列的模型,很难推理出这种谁影响了谁的因果关系。
而纯数据驱动的图神经网络虽然能学习节点间的隐式关系,却往往需要大量标注数据才能收敛,且学习到的边权缺乏物理可解释性——无法确认模型是否学到了真实的物料流向。
提出方法试图将工艺知识与图深度学习融合:预先构造一个基于工艺流程拓扑的知识图谱(52个节点对应传感器/操作变量,84条边对应物料或能量传递关系),然后在这个物理骨骼上分别部署两个互补的图神经网络——一个无监督的图自编码器用于故障检测,一个监督的注意力时空图卷积网络用于故障分类。
01 问题动机:时序模型的结构性盲区和纯GNN的不可解释
化工过程安全运行依赖及时准确的故障诊断。TEP过程包含52个过程变量(41个测量值+11个操作变量),它们通过反应器、冷凝器、气液分离器、压缩机等单元相互连接。当故障注入时——例如进料成分变化、冷凝器冷却水不足、压缩机效率下降——异常会沿着物料流和能量流逐级扩散。
标准的LSTM或CNN模型将每个变量的时间序列独立处理,然后在全连接层混合信息。这种晚融合策略的缺陷是:模型必须从数据中自己学习变量间的关系,样本效率低,且对训练数据中未出现过的故障传播路径毫无泛化能力。
图卷积网络天然适合处理图结构数据,但大多数GNN的边是数据驱动的(如基于相似度学习),或者固定为单位权重。工程师无法判断模型是否真的利用了反应器出口温度异常会影响到下游分离器这种物理知识——模型可能只是记住了训练集中的统计相关性。
两全的路径在哪里?
可以显式的将工艺流程拓扑编码为邻接矩阵,作为图神经网络的固定输入。 这样,模型从一开始就知道哪些节点之间存在直接物理连接。在此基础上:
-
检测阶段:训练一个图自编码器仅使用正常工况数据。当故障发生时,重构误差会显著增大,通过马氏距离设定阈值即可实现灵敏检测。
-
诊断阶段:训练一个注意力时空图卷积网络,同时捕捉空间(图拓扑)和时间(滑动窗口内的动态)两个维度的特征,输出21类故障(正常+20种故障类型)。
02 知识图谱的构建:让模型拥有流程图视野
2.1 节点与边:从P&ID到邻接矩阵
田纳西-伊士曼过程的工艺流程已有成熟文献,按照以下规则构造了52个节点的有向图(实现中转为无向图存储):
-
节点:每个传感器或操作变量对应一个节点。包括22个连续过程测量值、19个成分分析值、11个操作变量。
-
边:如果两个变量在物料流或能量流上存在直接的上下游关系(例如反应器出口温度→反应器冷却水流量),则添加一条边。
最终获得84条边。这个邻接矩阵被固定,在GAE和ASTGCN中均不参与训练更新,这种设计的物理意义在于:模型看到的图结构与工程师眼中的流程图一致——任何通过该图传播的信息都可以追溯到真实的工艺连接。
2.2 GAE:无监督重构检测异常
GAE采用切比雪夫图卷积层(ChebConv,K=2)作为编码器,将52维节点特征逐步压缩到2维嵌入;解码器则从2维嵌入逐层上采样,重构每个节点的原始信号。
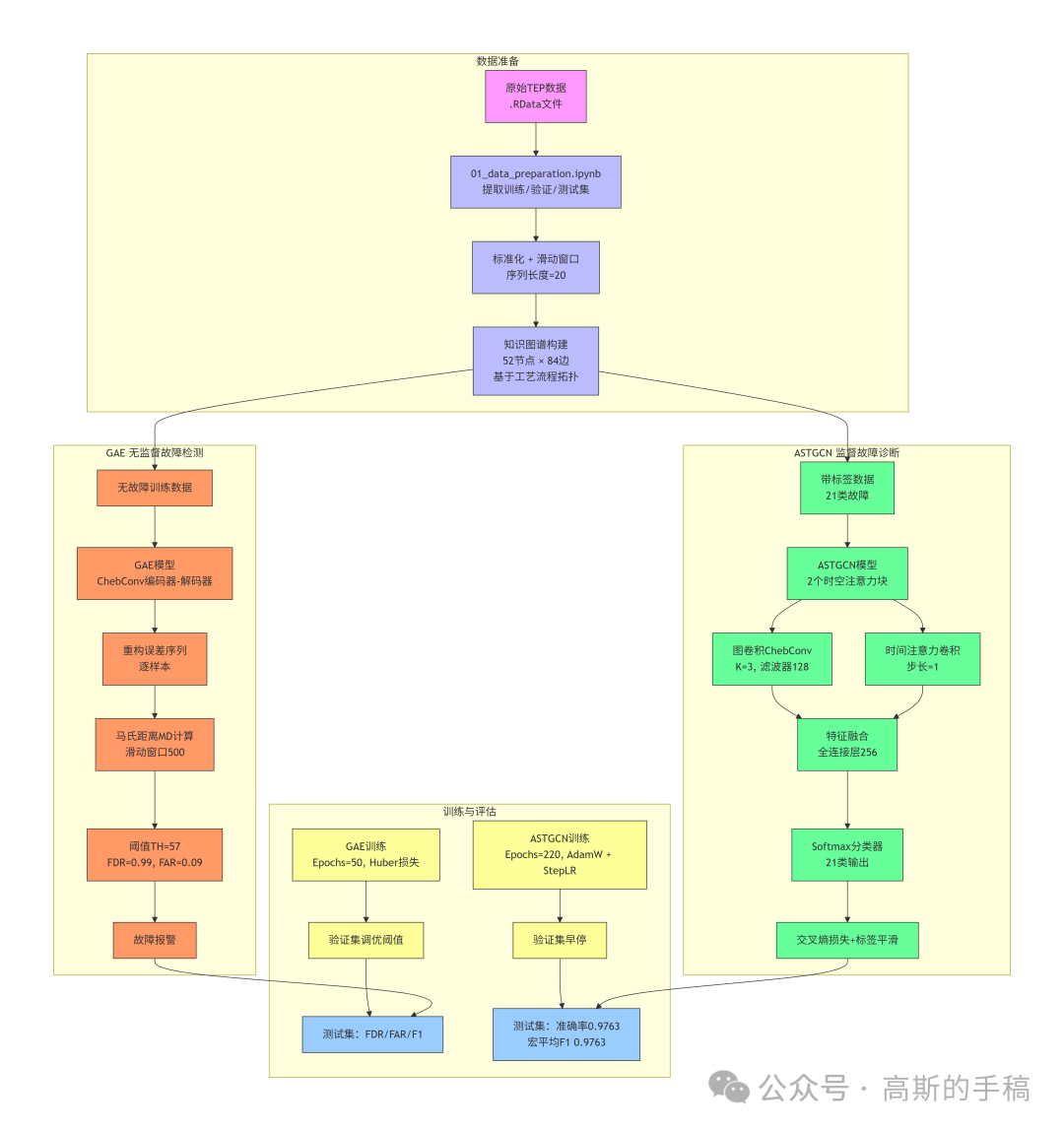
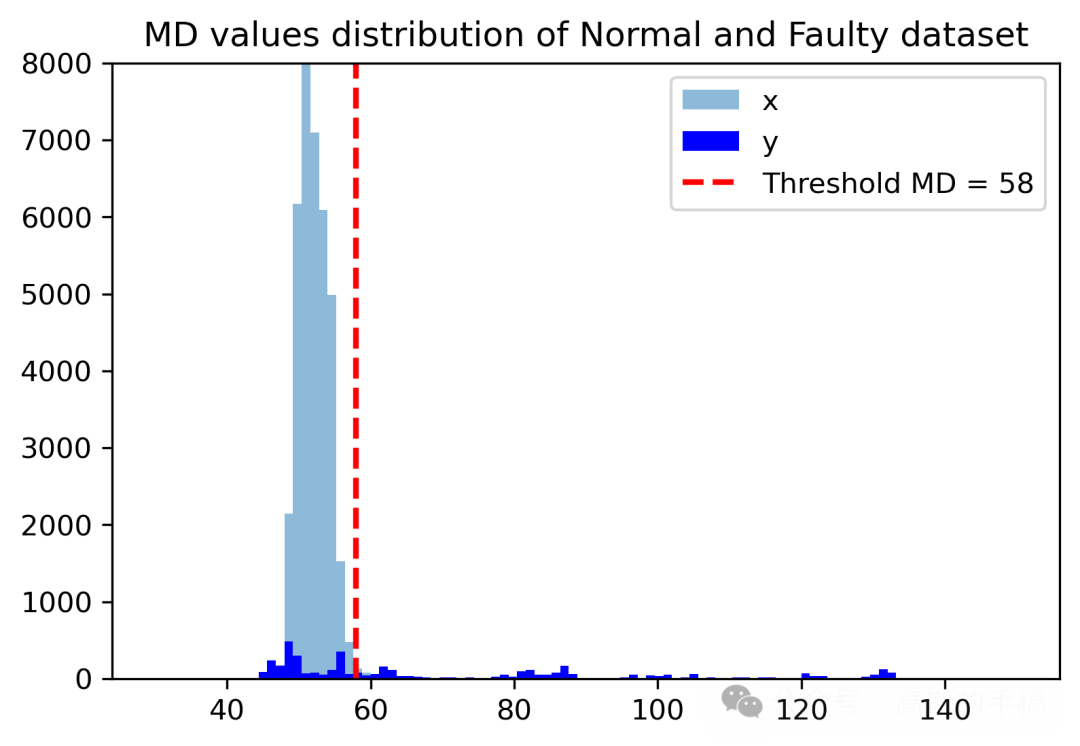
训练时仅使用无故障数据。训练完成后,对于任意一个新样本,计算其重构误差。由于正常工况的误差分布遵循多元高斯分布(在足够长的时间窗口下),采用马氏距离而不是简单的欧氏距离来融合不同节点的误差相关性。滑动窗口(500个样本)上的MD序列中,超过阈值(经调优取57)的点即触发故障报警。
该检测器的优势:
-
无需任何故障标签,完全无监督;
-
对微弱故障敏感——重构误差会在故障发生初期就开始偏离,而非等到偏差累积到阈值。
2.3 ASTGCN:注意力驱动的时空分类
ASTGCN是诊断阶段的核心,由两个顺序堆叠的时空注意力块组成,每个块包含:
-
空间注意力机制:计算每个时间步下节点之间的动态相关性权重(即使图的拓扑是固定的,节点间的相互作用强度可以随时间变化,例如某个阀门开度变化会影响下游节点的敏感度)。
-
图卷积模块:使用切比雪夫多项式(K=3)对空间注意力加权的邻接矩阵进行谱域卷积,提取每个节点的局部邻域特征。
-
时间注意力机制:计算不同时间步之间的相关性,捕捉长周期动态模式。
-
时间卷积模块:标准1D卷积沿时间维度进行,进一步编码时序依赖。
两个块堆叠后,输出一个包含时空信息的特征张量(维度为节点数×时间步×滤波器数)。随后通过全局最大池化(跨节点)压缩为一个固定长度的向量,再经过两层全连接网络(256→256→21)输出分类logits。
损失函数采用交叉熵+标签平滑(平滑系数0.1),优化器为AdamW,学习率按StepLR每20轮衰减至0.8倍。
如果你对信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测有疑问,或者需要论文思路上的建议,欢迎学术付费咨询(kang20224)哦
工学博士,《MSSP》《中国电机工程学报》《宇航学报》《控制与决策》等期刊审稿专家,擅长领域:信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)