收藏备用|2026年AI大模型学习指南(小白+程序员必看,避坑+实操全干货)
最近很多朋友私信问我:“2026年想提升技术,选什么方向最有前景、最容易落地?” 我的回答从来都是一致的——AI大模型。其实我刚入门时,也是个跨行零基础的纯小白,没有系统教程、没有行业资源,全靠摸索和前辈分享的经验,才避开了无数无效内耗和入门深坑。今天就把这份沉淀了很久的“避坑指南+实操学习干货”整理出来,不管你是想转行切入AI赛道的零基础小白,还是想拓展技能边界、破解35岁职业焦虑的程序员,都能通过这篇内容快速理清AI大模型的学习逻辑,掌握可落地、能复用的进阶方法,少走半年弯路。
一、2026年学AI大模型,为什么是最明智的选择?
在技术迭代越来越快的当下,选对学习方向,比盲目努力更重要。AI大模型能成为2026年技术圈的“香饽饽”,不是偶然,核心源于这4个不可替代的优势,小白和程序员都能看懂:
1、技术优势:碾压传统模型,入门门槛大幅降低
和传统机器学习模型相比,以Transformer架构为核心的AI大模型,堪称技术圈的“全能选手”——在自然语言处理(NLP)、计算机视觉(CV)、多模态交互等核心领域,表现远超传统模型,能轻松应对文本生成、图像识别、语音合成、代码自动生成等复杂场景,甚至能完成简单的数据分析和决策。
更关键的是,2026年AI大模型的技术生态已经非常成熟,大量开源预训练模型(如GPT-4o、Llama 3、Qwen 2、BERT进阶版)可供直接调用,不用从零搭建模型架构、不用反复调试底层代码;配套的低代码开发平台、可视化微调工具也层出不穷,极大降低了开发者的入门门槛,哪怕是不懂算法、没接触过AI的纯小白,跟着教程操作,也能快速上手实操。
2、应用场景:覆盖全行业,就业选择无局限
现在的AI大模型,早已走出“实验室”,渗透到我们生活和工作的方方面面,不再是“小众技术”。除了大家熟知的智能聊天机器人、实时翻译工具,它还深度赋能电商智能推荐、医疗影像辅助诊断、自动驾驶决策系统、企业智能客服、短视频内容批量生成、金融风控分析等多个领域,甚至在传统行业的数字化转型中,也扮演着核心角色。
几乎所有需要“数据处理”“智能决策”“效率提效”的行业,都在争抢AI大模型人才。这意味着,学会这项技术后,不管你是想进互联网大厂、传统国企数字化部门,还是投身新兴AI创业公司,甚至想做自由职业者(接单做模型微调、内容生成),都有大量机会可选,完全不用愁“学完没处用”“学会后被淘汰”。
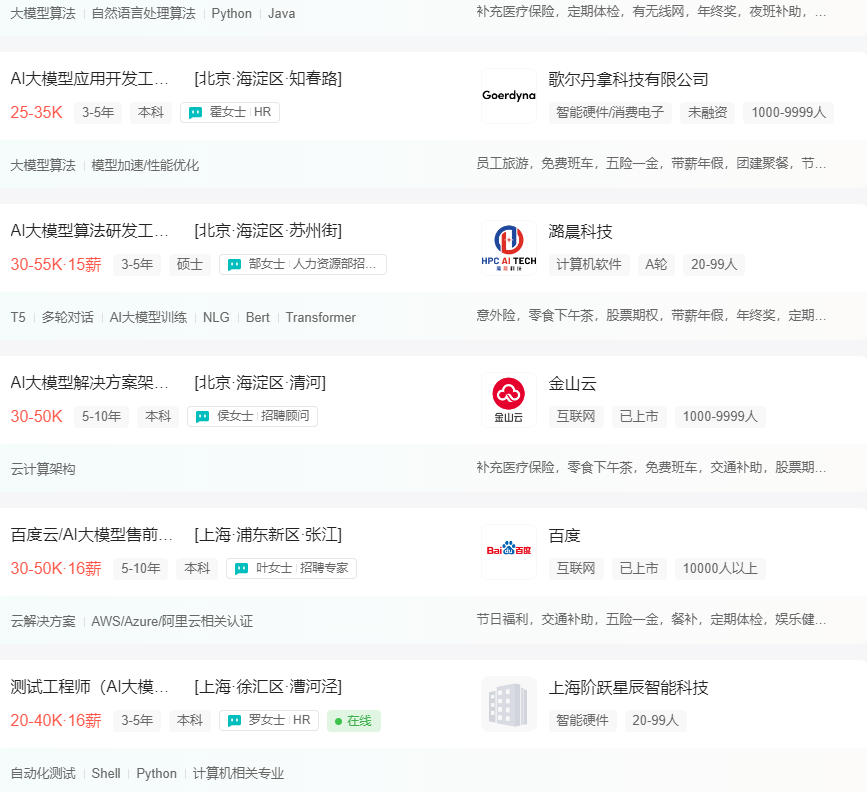
3、薪资待遇:行业红利期,薪资远超同年限岗位
随着AI被纳入国家核心战略,企业数字化转型需求爆发,2026年AI大模型相关岗位的需求缺口持续扩大,薪资水平也水涨船高,成为技术圈“高薪赛道”的代表。
根据最新行业招聘数据显示,二线、三线城市,零基础入门的AI大模型工程师,年薪就能达到 18-30万,入门薪资比同年限的后端、测试岗位高出20%-30%;一线城市更不用说,资深大模型工程师年薪突破 60万 很常见,部分头部企业还会提供股权分红、项目专项奖金、人才落户补贴、带薪培训等额外福利。对于想提升薪资、突破职业瓶颈的程序员来说,这无疑是最好的赛道之一。
4、行业前景:技术生态完善,长期发展有保障
书籍PDF及配套代码可点赞文章后添加小助手获取

2026年,随着算力基础设施(如国产算力芯片、分布式训练平台)的不断完善,AI大模型的训练成本持续降低,技术迭代速度只会更快,不会出现“学完就过时”的情况。
国内外的开源平台(如Hugging Face、ModelScope、TensorFlow Hub)越来越成熟,不仅有免费的模型资源、海量的开源项目,还有完善的教程文档和活跃的社区支持,形成了“学习-实践-贡献”的良性循环技术生态。哪怕是小白,也能在社区里找到免费的学习资料、请教行业前辈,快速提升自己。
对于学习者来说,不用担心里程碑式学习后技术过时——AI大模型作为连接算法、算力、数据三大核心要素的“核心枢纽”,未来10年都将是行业发展的核心方向,长期发展极具保障,更是程序员应对“AI替代焦虑”、提升核心竞争力的关键。
二、零基础也能学会!2026年AI大模型学习全攻略(附时间规划)
很多人觉得AI大模型“高深莫测”,动辄就要懂算法、懂数学,普通人根本学不会。但其实,只要找对方法、循序渐进,零基础也能在 6-12个月 内实现入门到就业的跨越。下面分享我亲测有效的5个学习要点,尤其适合小白和想转型的程序员参考,每一步都有具体方向,不用盲目跟风:
1、先定方向:明确学习目标,不做“无用功”
AI大模型的细分方向很多,不同方向的学习重点、就业岗位差异很大,盲目“全面学习”只会分散精力,最后什么都学不精。常见的细分方向有:NLP(自然语言处理,聚焦文本生成、情感分析、代码生成)、CV(计算机视觉,聚焦图像识别、目标检测、图像生成)、多模态学习(文本-图像-语音联动)、大模型微调与部署、RAG检索增强生成等。
建议大家先结合自己的兴趣和基础选择方向,精准发力:比如喜欢文字、有一定编程基础,就侧重 NLP+代码大模型 方向(适合程序员转型,就业需求大);喜欢图像、视频剪辑,就侧重 CV+多模态 方向(适合小白入门,实操性强);想做落地项目、追求快速就业,就侧重大模型微调与部署方向(2026年热门需求)。不用一开始就追求“全精通”,先深耕一个方向,形成核心竞争力后,再拓展其他领域,效率会高很多。
2、制定阶段计划:按“基础-高级-专家”逐步进阶(附具体时间)
学习AI大模型,最忌讳“急于求成”,一步登天根本不现实。我结合自己的学习经历,把2026年AI大模型的学习分为三个阶段,每个阶段有明确的学习重点和目标,大家可以根据自己的时间(全职/兼职)调整进度,小白可直接照搬:
基础阶段(1-3个月):打牢核心基础,拒绝“空中楼阁”
- 重点学习:计算机科学基础(数据结构、算法核心知识点,不用深入钻研,掌握基础即可)、深度学习入门知识(神经网络原理、梯度下降法,理解逻辑比记公式重要)、Python编程语言(AI领域主流语言,必学,重点掌握函数、类、AI相关库的使用)、数据处理工具(Pandas、NumPy,核心用于数据清洗和预处理)。
- 阶段目标:理解AI大模型的核心基础概念,能独立完成简单的数据清洗、可视化任务,熟练使用Python编写基础代码。这个阶段不用追求速度,基础越牢,后续学习越轻松,避免后期学模型原理、调参时“听不懂、跟不上”。
- 小白小贴士:每天花1-2小时,先学Python基础(推荐B站免费教程),再搭配简单的数据处理练习,不用急于接触大模型本身。
高级阶段(3-6个月):掌握核心技术,实现“理论落地”
- 重点学习:主流深度学习框架(TensorFlow、PyTorch二选一即可,2026年更推荐PyTorch,生态更活跃、上手更友好,适合小白和程序员)、大模型核心原理(重点攻克Transformer架构、注意力机制,这是大模型的核心,必须吃透)、细分方向核心技术(如NLP的文本分类、CV的目标检测,根据自己选定的方向深耕)。
- 阶段目标:能熟练调用开源预训练模型完成小项目,比如用Llama 3做文本情感分析、用Qwen-VL做图像描述生成、用Transformers库做简单的代码生成,把理论知识落地到实际项目中,积累基础实操经验。
- 程序员小贴士:可结合自己的编程基础,尝试用PyTorch复现简单的模型结构,加深对Transformer架构的理解。
书籍PDF及配套代码可点赞文章后添加小助手获取
专家阶段(6-12个月):深化技术能力,冲刺就业/进阶
- 重点学习:聚焦更前沿的技术方向,比如多模态学习(图像-文本联动,2026年热门趋势)、大模型微调(LoRA微调技术,必备技能,上手简单、落地性强)、模型部署(轻量化部署、边缘计算适配,企业核心需求)、RAG(检索增强生成,解决大模型幻觉问题)、Agent智能体开发。
- 阶段目标:尝试参与开源项目或企业实战项目,比如给大模型做行业知识库微调、搭建智能客服系统、开发简单的Agent智能体,积累完整的项目经验,为就业、进大厂或职业进阶加分。
- 通用小贴士:把自己的项目上传到GitHub,完善项目文档,既能形成个人作品集,也能吸引行业大佬的关注,后续找工作、请教问题都会更有优势。
3、夯实基础:这4个知识点,决定你的学习上限

“万丈高楼平地起”,AI大模型的学习尤其依赖基础。很多小白入门后觉得学不下去、越学越吃力,核心就是基础没打牢。2026年学习大模型,不用贪多,重点掌握这4个基础知识点,就能应对80%的入门和进阶需求:
\1. 数据结构与算法:理解常见的排序、查找算法,以及数组、链表、树等基础数据结构,不用深入钻研复杂算法,重点是理解核心逻辑,这是看懂模型底层架构的关键。
\2. 深度学习原理:搞懂神经网络的正向传播、反向传播,不用死记硬背复杂公式,能理解“模型如何学习、如何优化”即可,比如梯度下降法的核心作用是什么。
\3. Python编程:熟练使用Python的函数、类、模块,重点掌握AI相关的库(如PyTorch、Transformers、Pandas),能独立编写简单的代码,完成数据处理和模型调用。
\4. 数据清洗与预处理:掌握缺失值处理、异常值检测、数据标准化等技巧,记住一句话:数据决定模型上限,哪怕模型再先进,没有干净、高质量的数据,也训练不出好的效果,这一步至关重要,小白千万不要跳过。
4、多动手实操:AI大模型,越练越熟练(附实操路径)

很多人学习大模型,只看教程、记笔记,却从不动手实操,最后导致“一看就会、一做就废”。AI大模型是“实操性极强”的技术,光靠理论根本学不会,必须多动手、多练项目,实践才是检验真理的唯一标准。2026年的学习资源非常丰富,建议从简单的小项目开始,循序渐进提升,小白可参考这个实操路径:
- 入门级(1-3个月,对应基础阶段):用Hugging Face的Transformers库调用预训练模型做文本情感分析、生成一段短文,或者用OpenCV+预训练模型做简单的图像识别(比如识别猫狗),重点熟悉模型调用的流程。
- 进阶级(3-6个月,对应高级阶段):尝试用LoRA技术对开源大模型做轻量化微调,比如训练一个专属的“小说生成模型”“代码助手模型”,重点掌握微调的核心步骤和参数调试方法。
- 实战级(6-12个月,对应专家阶段):搭建一个RAG知识库系统,解决大模型“胡说八道”(幻觉)的问题,或者开发一个简单的智能体(Agent),实现“自主查询-分析-生成”的完整流程,重点积累项目实战经验,完善个人作品集。
小贴士:每学一个知识点,就找对应的小项目练手,遇到问题多查社区、多请教,不要死磕,实操越多,进步越快。
5、链接行业大佬:少走弯路,加速成长(小白必备)

书籍PDF及配套代码可点赞文章后添加小助手获取
学习过程中遇到问题很正常,单靠自己琢磨可能要花好几天,甚至走进死胡同,但如果能有行业大佬指点,可能几分钟就能解决,还能了解行业最新趋势和招聘需求,少走很多弯路。2026年链接前辈的渠道很多,小白和程序员可这样做,零成本就能链接优质资源:
- 加入AI相关的技术社区:比如CSDN AI板块(重点关注,适合小白提问、找教程)、GitHub社区(找开源项目、学习实战代码)、知乎AI话题圈、阿里云开发者社区,每天花10分钟浏览,既能学到干货,也能遇到同路人。
- 参加线下技术沙龙、线上直播课:很多大厂(如字节、阿里、腾讯)的技术专家,会定期分享大模型实战经验,线上直播课大多免费,还能直接提问互动,针对性解决自己的问题。
- 关注行业大佬的博客或视频号:比如大模型微调、部署相关的技术博主,他们的分享往往比书本更接地气,会讲解很多实操中的坑和技巧,小白可跟着博主的教程一步步练习,提升效率。
我当初入门时,很多关于模型调参、项目部署的问题,都是靠前辈的指点才解决的,不仅节省了大量时间,还提前了解了行业最新的招聘需求和技术趋势,少走了很多弯路。对于小白来说,学会链接资源,比埋头苦学更重要。
最后想说:2026年,AI大模型的红利还在持续,不管你是零基础小白,还是想突破瓶颈的程序员,现在开始学习,都不算晚。不用害怕自己学不会,只要找对方法、循序渐进、多动手实操,就能在这个赛道上站稳脚跟,实现技术提升和薪资翻倍。
不管你是零经验的编程小白,还是想转型大模型的传统程序员,这份学习路线和资源都能精准匹配你的需求——基础薄弱?有入门专题帮你补;想练实战?有项目案例带你做;要找工作?有面试资源助你通关。
所有资源均已整理打包,扫描下方二维码即可免费领取,无需转发,直接获取。2025年,抓住大模型的风口,从这份系统化学习路线开始,一步步实现从入门到精通的蜕变!
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。
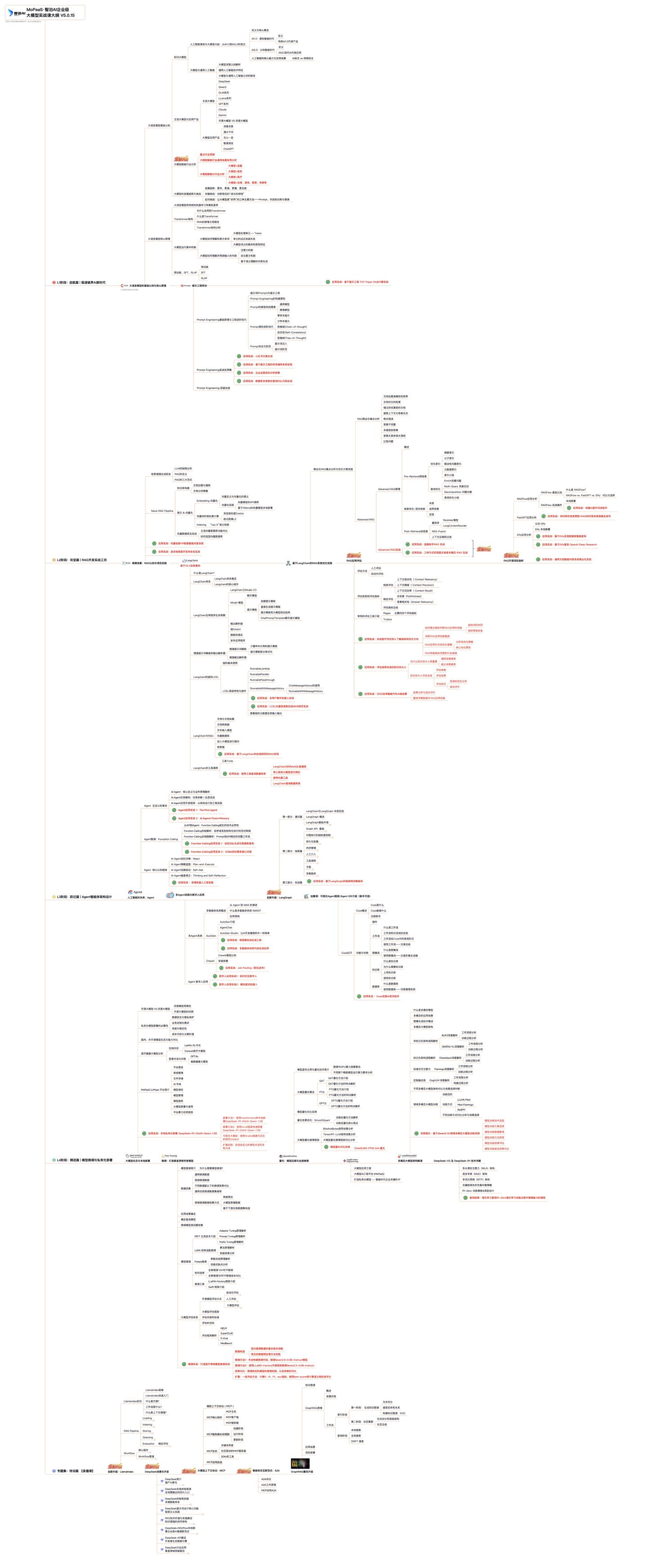
L1级别:大模型核心原理与Prompt
L1阶段: 将全面介绍大语言模型的基本概念、发展历程、核心原理及行业应用。从A11.0到A12.0的变迁,深入解析大模型与通用人工智能的关系。同时,详解OpenAl模型、国产大模型等,并探讨大模型的未来趋势与挑战。此外,还涵盖Pvthon基础、提示工程等内容。 目标与收益:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为AI应用开发打下坚实基础。
L2级别:RAG应用开发工程
L2阶段: 将深入讲解AI大模型RAG应用开发工程,涵盖Naive RAGPipeline构建、AdvancedRAG前治技术解读、商业化分析与优化方案,以及项目评估与热门项目精讲。通过实战项目,提升RAG应用开发能力。
目标与收益: 掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
书籍PDF及配套代码可点赞文章后添加小助手获取
L3级别:Agent应用架构进阶实践
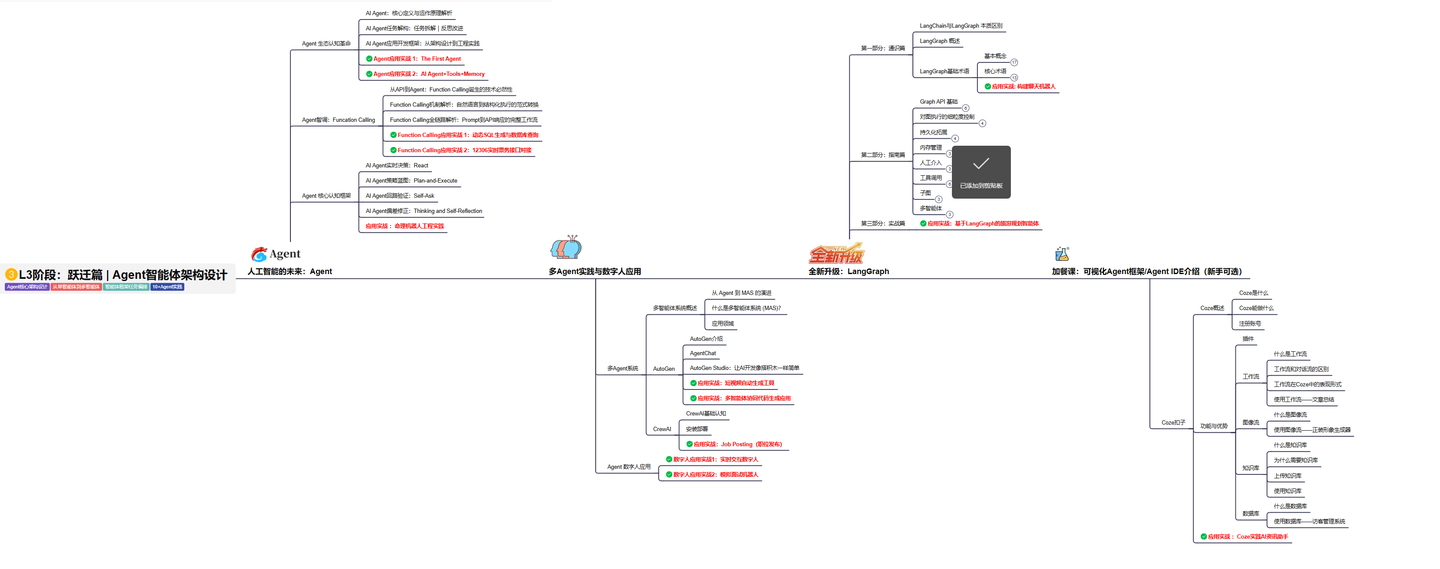
L3阶段: 将 深入探索大模型Agent技术的进阶实践,从Langchain框架的核心组件到Agents的关键技术分析,再到funcation calling与Agent认知框架的深入探讨。同时,通过多个实战项目,如企业知识库、命理Agent机器人、多智能体协同代码生成应用等,以及可视化开发框架与IDE的介绍,全面展示大模型Agent技术的应用与构建。
目标与收益:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
L4级别:模型微调与私有化大模型
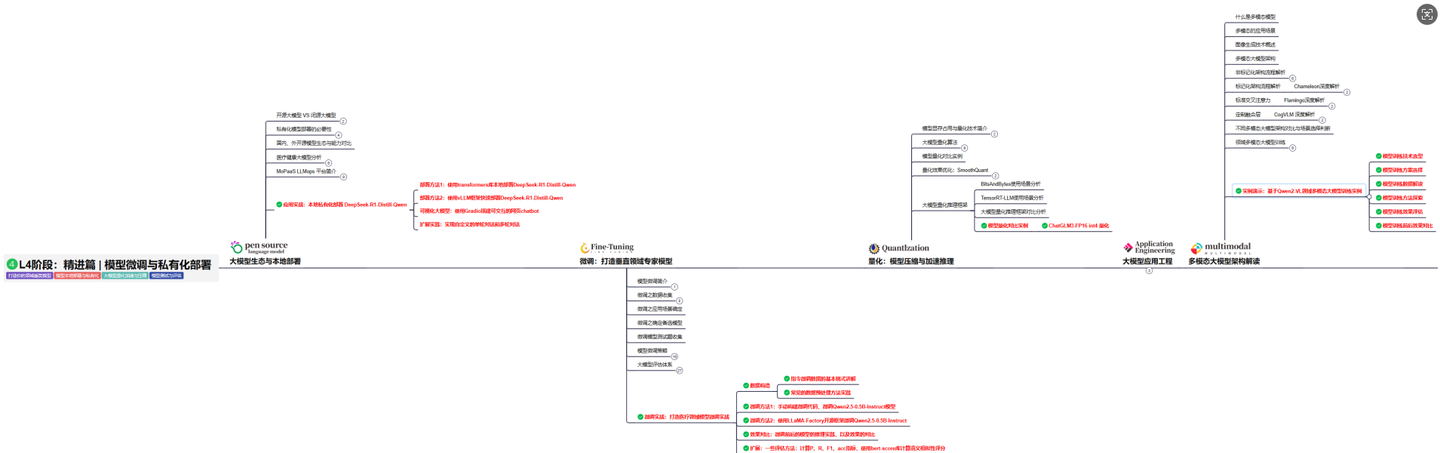
L4级别: 将聚焦大模型微调技术与私有化部署,涵盖开源模型评估、微调方法、PEFT主流技术、LORA及其扩展、模型量化技术、大模型应用引警以及多模态模型。通过chatGlM与Lama3的实战案例,深化理论与实践结合。
目标与收益:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识
四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题

面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。
书籍PDF及配套代码可点赞文章后添加小助手获取

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)