大模型 | 大模型之机器学习基本理论
机器学习基本理论
分类
|
对比维度 |
有监督学习 |
无监督学习 |
半监督学习 |
强化学习 |
|---|---|---|---|---|
|
数据类型 |
全标签数据 |
无标签数据 |
少量标签+大量无标签 |
无直接标签,通过奖励反馈 |
|
学习目标 |
学习输入到输出的映射 |
发现数据内在结构 |
利用无标签数据提升泛化能力 |
学习最优行为策略以最大化奖励 |
|
核心特征 |
有“老师”指导 |
自主“发现”模式 |
结合监督与无监督学习 |
通过“试错”与环境互动 |
|
典型应用 |
分类、回归 |
聚类、降维 |
网页分类、NLP |
游戏AI、机器人控制 |
基本术语
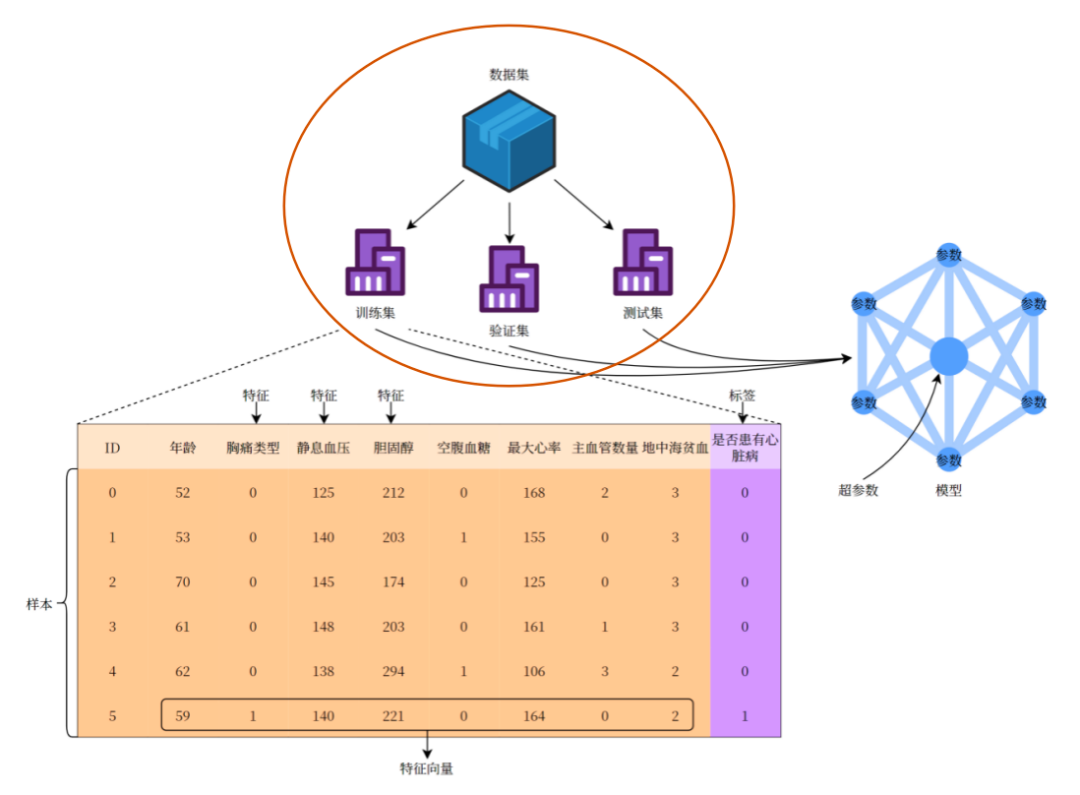
数据集(Data Set):多条记录的集合。
①训练集(Training Set):用于训练模型的数据。
②验证集(Validation Set):用于调节超参数的数据。
③测试集(Test Set):用于评估模型性能的数据。
样本(Sample):数据集中的一条记录是关于一个事件或对象的描述,称为一个样本。
特征(Feature):数据集中一列反映事件或对象在某方面的表现或性质的事项,称为特征或属性。
特征向量(Feature Vector):将样本的所有特征表示为向量的形式,输入到模型中。
标签(Label):监督学习中每个样本的结果信息,也称作目标值(target)。
模型(Model):一个机器学习算法与训练后的参数集合,用于进行预测或分类。
参数(Parameter):模型通过训练学习到的值,例如线性回归中的权重和偏置。
超参数(Hyper Parameter):由用户设置的参数,不能通过训练自动学习,例如学习率、正则化系数等。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

建模流程
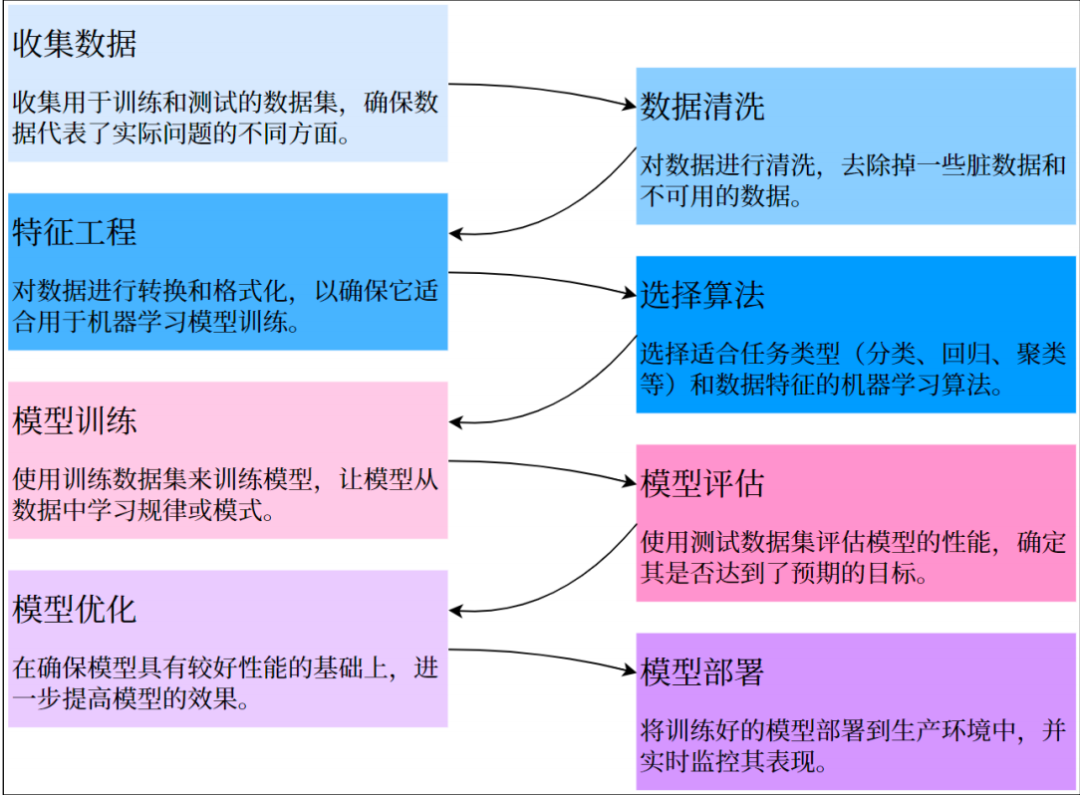
特征工程
特征选择
从原始特征中挑选出与目标变量(标签)关系最密切的特征,剔除冗余、无关或噪声特征。
特征选择不会创建新特征,也不会改变数据结构。
# 低方差过滤
import numpy as np
from sklearn.feature_selection import VarianceThreshold
# 1. 构造特征 1: 均值0 标准差1
a = np.random.randn(10000)
print(f'方差: ${np.var(a)}, 均值: ${np.mean(a)}')
# 2. 构造特征 2: 均值5 标准差0.1
b = np.random.normal(loc=5, scale=0.1, size=10000)
print(f'方差: ${np.var(b)}, 均值: ${np.mean(b)}')
# 3. 构造特征向量
X = np.vstack((a, b)).T
print(X)
# 4. 方差过滤:删除方差低于0.2的特征
var_thresh = VarianceThreshold(0.2)
X_filtered = var_thresh.fit_transform(X)
print(X_filtered)
print(X_filtered.shape)
print(X.shape)
# 皮尔逊相关系数
# 1. 读取数据
adv = pd.read_csv("../data/xxx.csv")
print(adv.head())
# 2. 数据清洗: 去掉id列
adv.drop(adv.columns[0], axis=1, inplace=True)
adv.dropna(inplace=True)
# 3. 提取特征和标签
x = adv.drop("Sales", axis=1, inplace=False)
y = adv["Sales"]
# 4. 计算皮尔逊相关系数
corr = x.corrwith(y, method="pearson")
print(corr)
# 5. 相关系数矩阵
matrix = adv.corr(method="pearson")
print(matrix)
特征转换-数字型
| 特性 | 归一化 (Min-Max) | 标准化 (Z-Score) |
|---|---|---|
| 输出范围 |
固定区间(如 [0,1]) |
无固定范围(正态分布) |
| 异常值敏感 |
非常敏感,易受影响 |
相对鲁棒,影响较小 |
| 适用场景 |
数据有明确边界(如图像) |
分布未知、存在异常值 |
| 核心优点 |
简单直观,范围可控 |
鲁棒性强,通用首选 |
| 核心缺点 |
受异常值影响大 |
改变原始尺度,需计算 |
# 归一化
import numpy as np
from sklearn.preprocessing import MinMaxScaler
x = [[1, 2], [0.5, 6], [0, 10], [1, 18]]
# 得到归一化的缩放器对象
scaler = MinMaxScaler(feature_range=(0, 1))
x = scaler.fit_transform(x)
print(x)
# 标准化
import numpy as np
from sklearn.preprocessing import StandardScaler
x = [[1, 2], [0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler()
x = scaler.fit_transform(x)
print(x)
特征转换-类别型
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

标签编码(Label Encoding):特征是有序的, 把特征映射为有序的整数。
独热编码(One-Hot Encoding):为每个类别创建一个新的二进制特征。对于某个样本,只有其所属类别对应的特征值为1,其余所有新特征的值均为0。
目标编码(Target Encoding):将类别变量的每个类别替换为其对应目标变量(标签)的平均值或其他统计量。
频率编码(Frequency Encoding):用每个类别在整个数据集中出现的频率(或概率)来替换该类别标签,将类别特征转换为数值特征。
# 独热编码
from sklearn.preprocessing import OneHotEncoder
import numpy as np
X = np.array([['红'],
['蓝'],
['绿'],
['红']])
encoder = OneHotEncoder()
result = encoder.fit_transform(X).toarray()
print(result)
特征构造
特征构造是基于现有的特征创造出新的、更有代表性的特征。通过组合、转换、或者聚合现有的特征,形成能够更好反映数据规律的特征。
交互特征:将两个特征组合起来,形成新的特征。例如,两个特征的乘积、和或差等。
统计特征:从原始特征中提取统计值,例如求某个时间窗口的平均值、最大值、最小值、标准差等。
日期和时间特征:日期时间数据中提取如星期几、月份、年份、季度、是否周末等特征。
特征降维
当数据集的特征数量非常大时,特征降维可以帮助减少计算复杂度并避免过拟合。通过降维方法,可以在保持数据本质的情况下减少特征的数量。
主成分分析(PCA):通过线性变换将原始特征映射到一个新的空间,使得新的特征(主成分)尽可能地保留数据的方差。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
n_samples = 1000
# 第 1 个主成分方向
component1 = np.random.normal(0, 1, n_samples)
# 第 2 个主成分方向
component2 = np.random.normal(0, 0.2, n_samples)
# 第 3 个方向(噪声,方差较小)
noise = np.random.normal(0, 0.1, n_samples)
# 构造 3 维数据
X = np.vstack([component1 - component2, component1 + component2,
component2 + noise]).T
# 标准化
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
# 应用 PCA,将 3 维数据降维到 2 维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_standardized)
# 可视化
# 转换前的 3 维数据可视化
fig = plt.figure(figsize=(12, 4))
ax1 = fig.add_subplot(121, projection="3d")
ax1.scatter(X[:, 0], X[:, 1], X[:, 2], c="g")
ax1.set_title("Before PCA (3D)")
ax1.set_xlabel("Feature 1")
ax1.set_ylabel("Feature 2")
ax1.set_zlabel("Feature 3")
# 转换后的 2 维数据可视化
ax2 = fig.add_subplot(122)
ax2.scatter(X_pca[:, 0], X_pca[:, 1], c="g")
ax2.set_title("After PCA (2D)")
ax2.set_xlabel("Principal Component 1")
ax2.set_ylabel("Principal Component 2")
plt.show()
模型评估
损失函数
对于模型一次预测结果的好坏,需要有一个度量标准。 对于监督学习而言,给定一个输入 X,选取的模型就相当于一个“决策函数”f,它可以输出一个预测结果 f(X),而真实的结果(标签)记为 Y。f(X) 和 Y 之间可能会有偏差,我们就用一个损失函数(loss function)来度量预测偏差的程度,记作 L(Y,f(X))。 损失函数用来衡量模型预测误差的大小;损失函数值越小,模型就越好。
常见的损失函数有:0-1 损失函数,平方损失函数,绝对损失函数,对数似然损失函数。
经验误差和泛化误差
给定一个训练数据集,根据选取的损失函数,就可以计算出模型 f(X)在训练集上的平均误差,称为训练误差,也被称作经验误差。类似地,在测试数据集上平均误差,被称为测试误差或者泛化误差。
欠拟合
模型在训练集和测试集表现都很差(高偏差)。
产生原因:模型复杂度不足 ,特征不足,训练不充分,过强的正则化。
解决方法:增加模型复杂度,增加特征或者改进特征工程,增加训练时间,减少正则化强度。
过拟合
模型在训练集表现好,但测试集表现差(高方差)。
产生原因:模型复杂度过高,训练数据不足,特征过多,训练过长。
解决方法:简化模型或者降维降低模型复杂度,增加训练数据,使用正则化,交叉验证,早停。
正则化
正则化(Regularization)是一种在训练机器学习模型时,在损失函数中添加额外项,来惩罚过大的参数,进而限制模型复杂度、避免过拟合,提高模型泛化能力的技术。
类型:
1、L1 正则化(Lasso 回归):惩罚参数绝对值之和,使部分参数为 0,实现特征选择。
2、L2 正则化(Ridge 回归):惩罚参数平方和,使参数值普遍较小,提高模型稳定性。
3、ElasticNet:结合 L1 和 L2 正则化,平衡稀疏性和稳定性。
交叉验证
交叉验证是通过多次划分数据集(训练集 + 验证集),反复进行训练和验证,来评估模型泛化能力的方法,减少数据划分随机性的影响。
通过交叉验证能更可靠地估计型在未知数据上的表现,亦能避免因单次数据划分不合理导致的模型过拟合或欠拟合;在实际工程应用中,通常可以结合网格搜索来确定超参数。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

常用的交叉验证方法:
1、k 折交叉验证:将数据分为 k 份,每次用 k-1 份训练,1 份验证,取平均性能。
2、留一交叉验证:每次留 1 个样本作为验证集,适用于小数据集。
3、简单交叉验证(Hold-Out):一次划分训练集和验证集,结果较粗糙。
模型评估指标
对学习的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价指标,也叫做性能度量。
回归任务常用评价指标:
1、均方误差(MSE):预测值与真实值差的平方均值。重视大误差惩罚严重错误。
2、平均绝对误差(MAE):预测值与真实值差的绝对值均值。追求稳健,避免异常值影响。
3、R²(决定系数):衡量模型整体对目标变量的解释能力,越接近 1 越好。
分类任务常用评价指标:
1、准确率(Accuracy):正确预测样本占比。
2、精确率(Precision):预测为正例的样本中实际为正例的比例。
3、召回率(Recall):实际为正例的样本中被正确预测的比例。
4、F1分数:精确率和召回率的调和平均。
5、ROC曲线与AUC:ROC 曲线以 FPR 为横轴、TPR 为纵轴,AUC 为曲线下面积,衡量模型区分正负类的能力。全面评估模型整体排序能力,对类别比例不敏感,适合评估和比较模型本身性能。
6、AUC-PR曲线:描述不同阈值下精确率和召回率的曲线,特别适用于高度不平衡的数据(异常检测),此时 AUC-PR 曲线比 ROC 曲线更具参考性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)