【人工智能】从零搭建AI问答助手项目(七):Top_K调优
引言
上一篇我们完成了本地文档处理、文本切块与知识库向量化入库,搭建好了完整的向量知识库。有了向量库之后,AI 问答助手就能根据用户问题,检索匹配相关文档片段。
但检索并不是简单拿取内容就行,召回多少条内容、筛选哪些片段,会直接影响最终回答的精准度、上下文长度与模型输出质量。其中,Top-K 检索数量就是 RAG 项目里最关键、最容易被忽略的调优项。
K 值设置过大,会引入大量无关冗余内容,增加 Token 消耗,还容易稀释有效信息;K 值设置过小,又会漏掉关键上下文,导致答案残缺、答非所问。
本篇就围绕 AI 问答助手实战,讲解Top-K 的作用、取值逻辑、场景化调优思路,结合实际使用场景给出合理参考范围,进一步优化检索效果,提升问答准确性。
版本目标
一、什么是Top_K
Top-K = 从向量库中取“最相似的K个片段”
例如:
K = 1 → 只取最相关的1段
K = 3 → 取最相关的3段
K = 5 → 取5段
二、为什么Top_K很关键
因为目前项目的流程是:
用户问题
↓
检索K个chunk
↓
拼成context
↓
LLM回答
所以K决定了“喂给大模型的信息量和质量”。
三、K取值的典型问题
1、K太小(比如1)
那么命中的结果会信息不完整,回答不全面,比如:
问题:Java特点?
只命中:
→ “Java是面向对象语言”
2、K太大(比如10)
那么命中的结果会噪声多、LLM被干扰、容易“胡编乱造”,比如:
命中:
→ Java特点
→ Java历史
→ Java生态
→ Java语法
→ 乱七八糟一堆
四、实际项目Top_K取值的最优范围(经验值)
| 场景 | 推荐K |
|---|---|
| 小知识库 | 2~4 |
| 中等文档 | 3~6 |
| 大规模RAG | 5~10 |
目前做的这个属于小型RAG项目,所以推荐K=3~5。
五、如何验证确定哪个Top_K取值更合适
1、调优方法
固定问题,多次测试,比如这个项目可以用的测试问题:
Java有哪些特点?
然后依次测试K=1、K=3、K=5的情况,最后观察不同的K值结果是否如下:
| K值 | 结果 |
|---|---|
| 1 | 是否太少 |
| 3 | 是否刚好 |
| 5 | 是否开始有噪声 |
2、实践验证
(1)修改代码中的top_k值进行测试,观察不同K值的结果
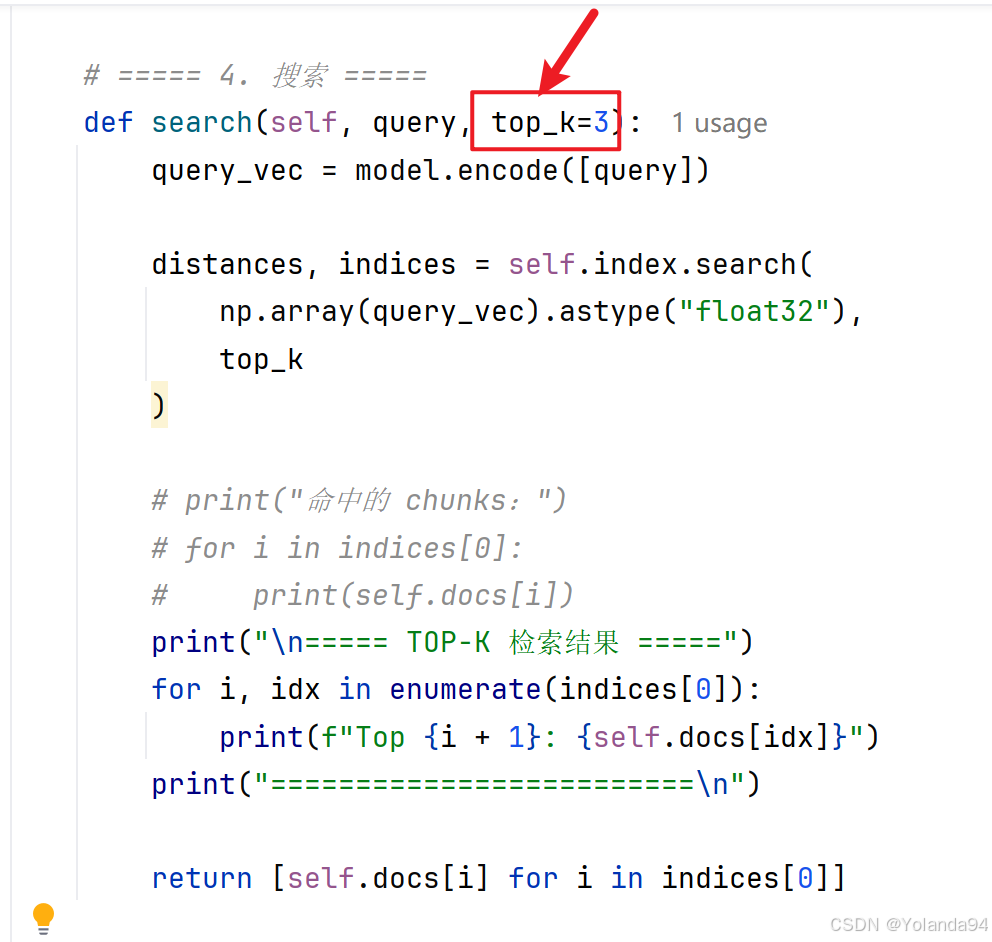
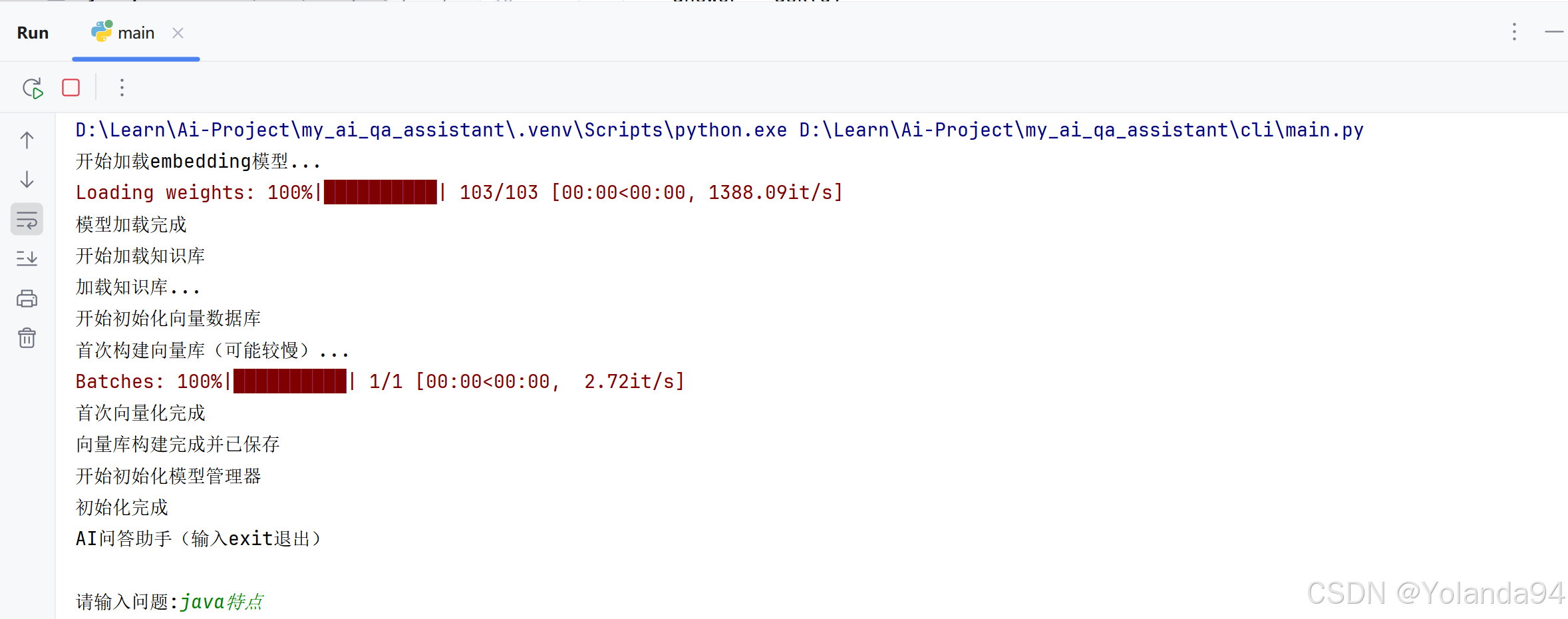
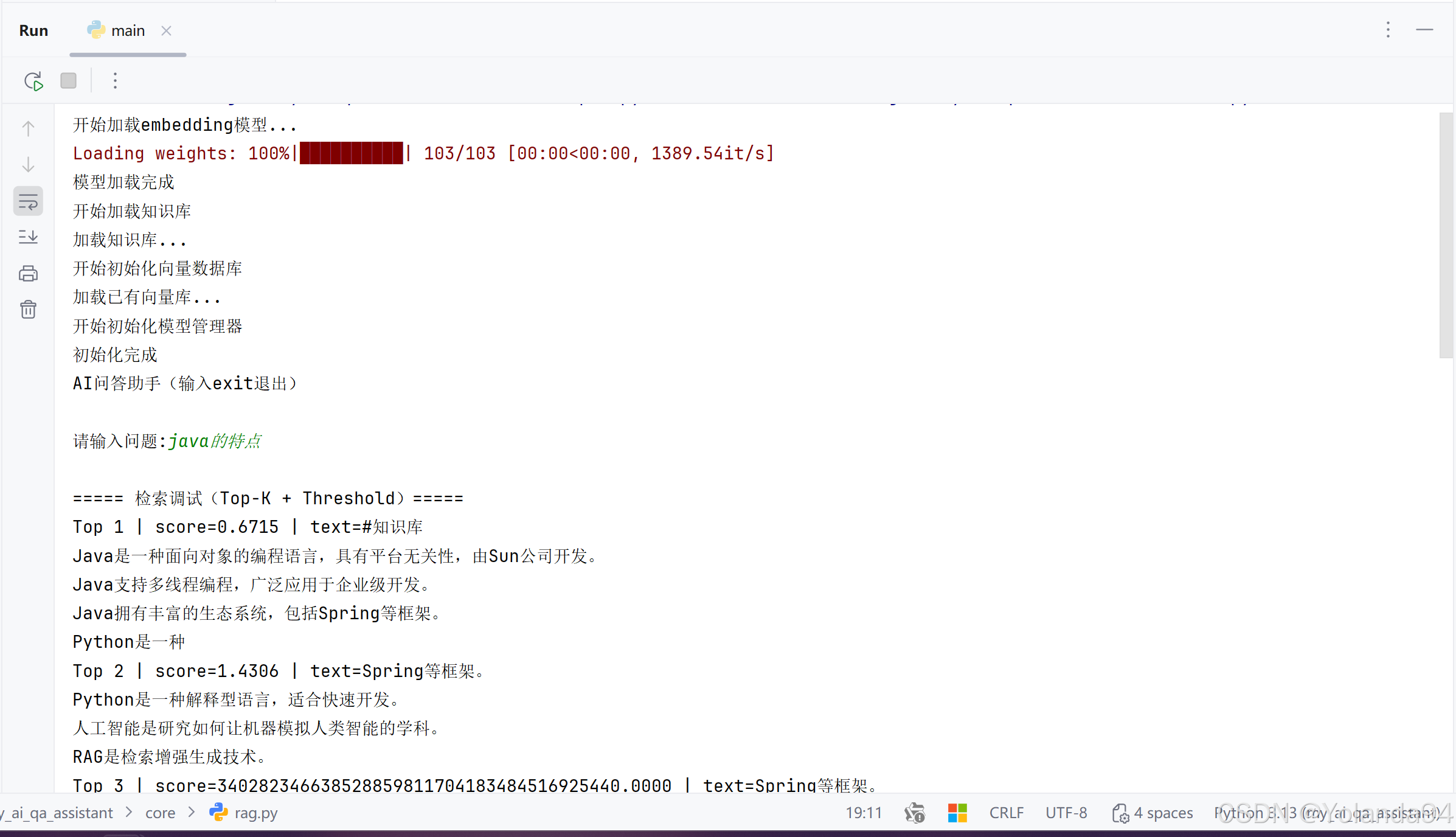
(2)增加命中的Top_K及其内容的日志打印
加这个日志但因是为了方便看到检索内容里的Top1、Top2、Top3等的内容。
print("\n===== TOP-K 检索结果 =====")
for i, idx in enumerate(indices[0]):
print(f"Top {i + 1}: {self.docs[idx]}")
print("=========================\n")
(3)各个Top_K取值测试结果
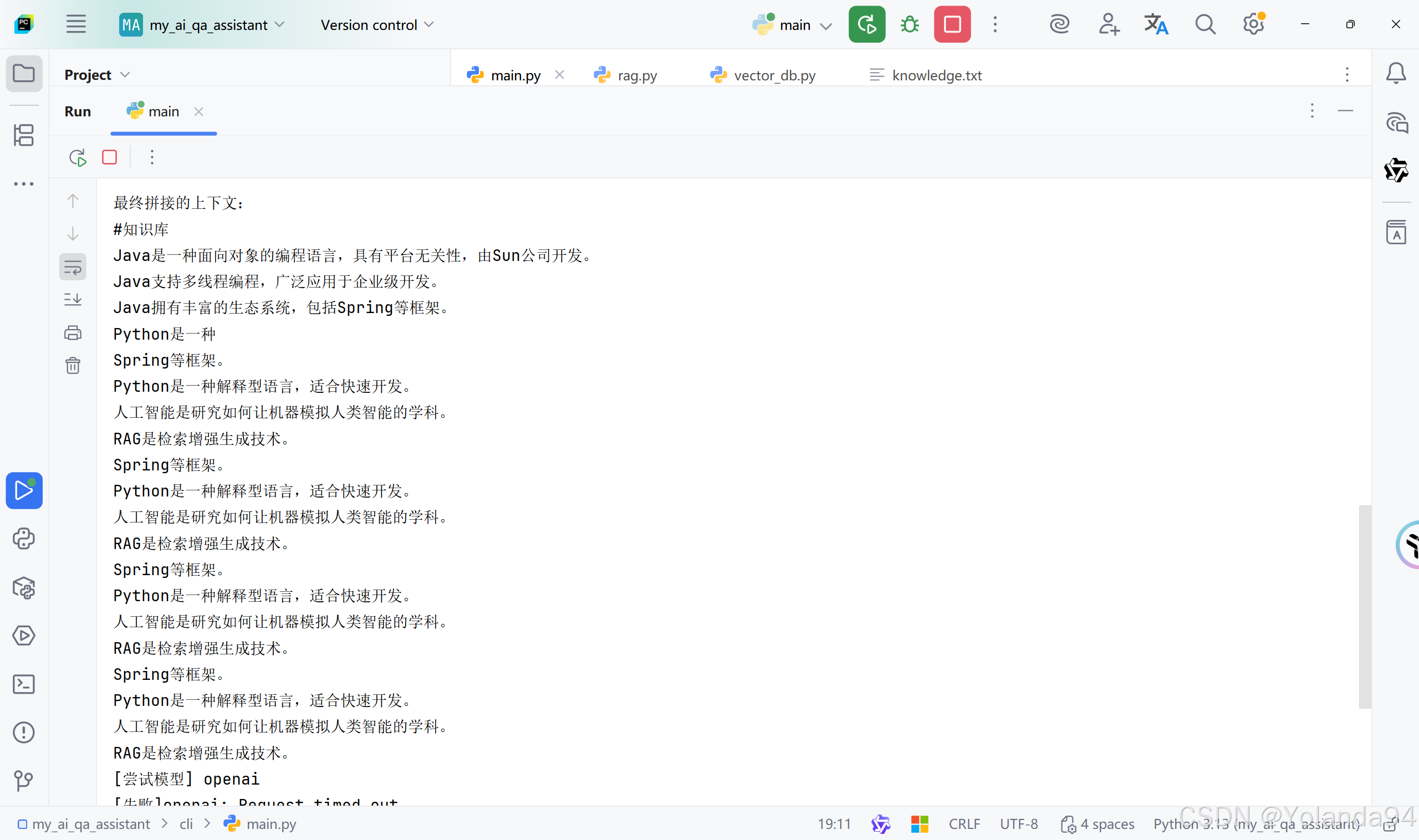
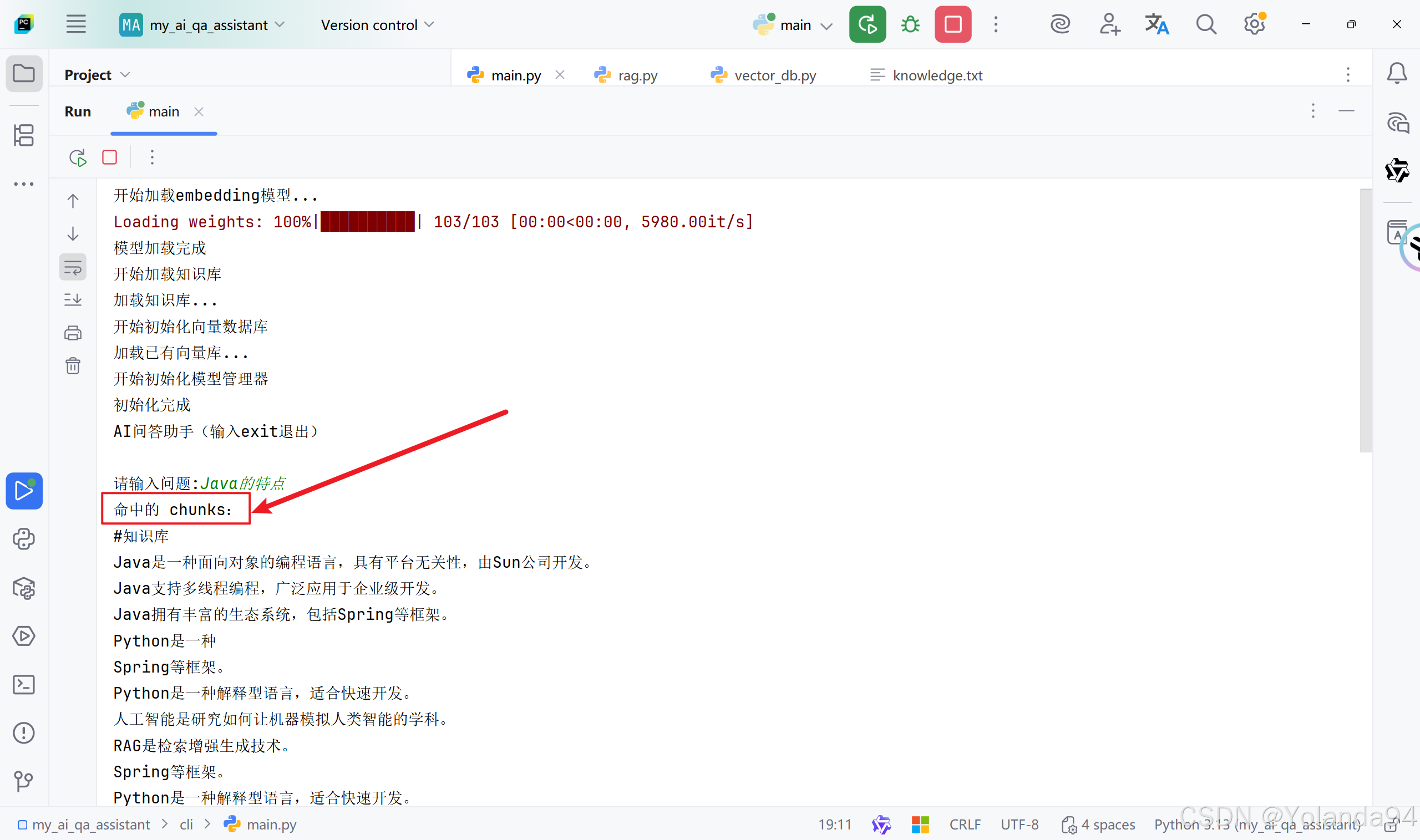
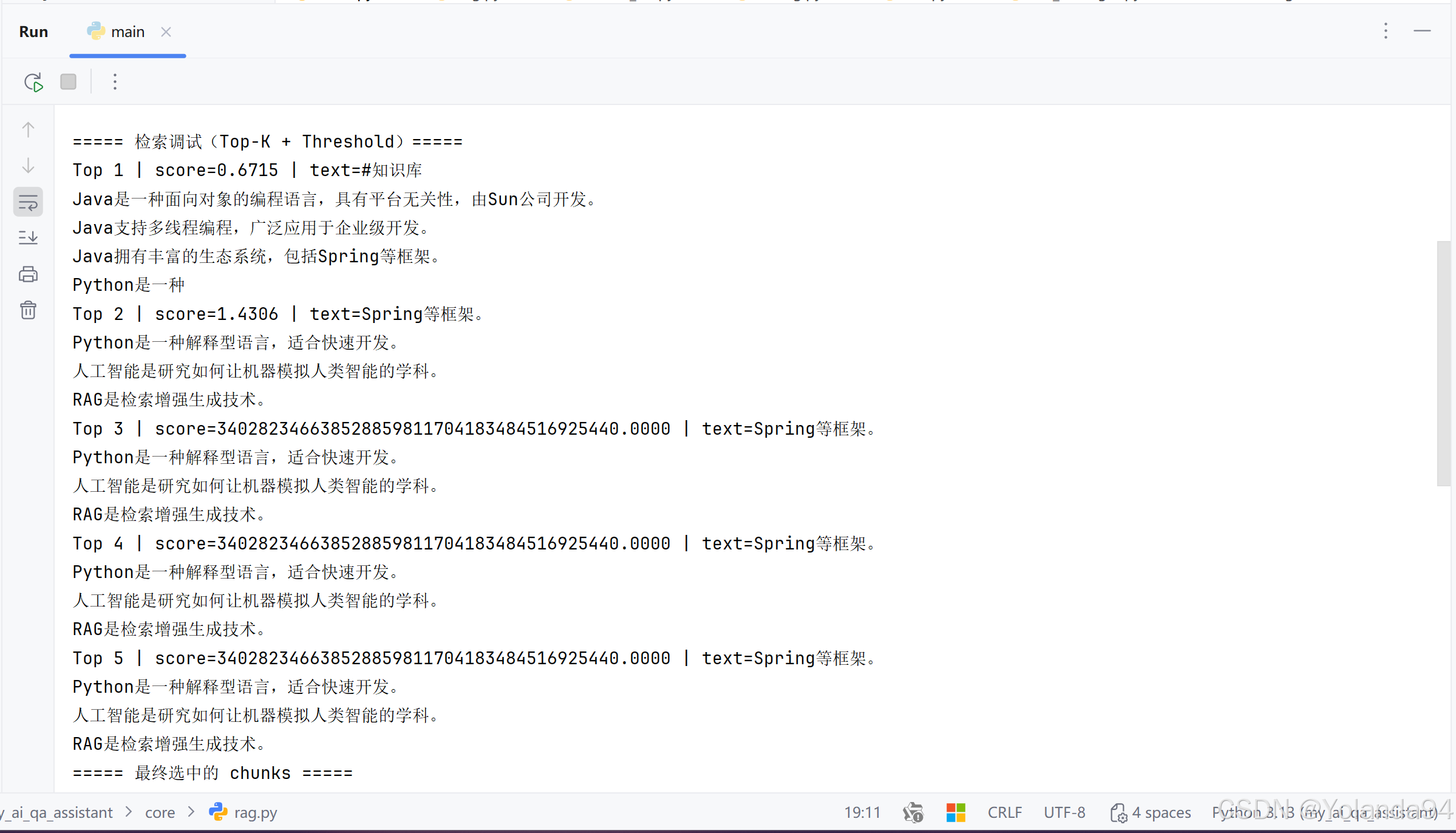
1)Top_K=1 测试结果
可以从最终模型给出的答案看出,发送给LLM的内容不够,导致最后输出的答案不够完善。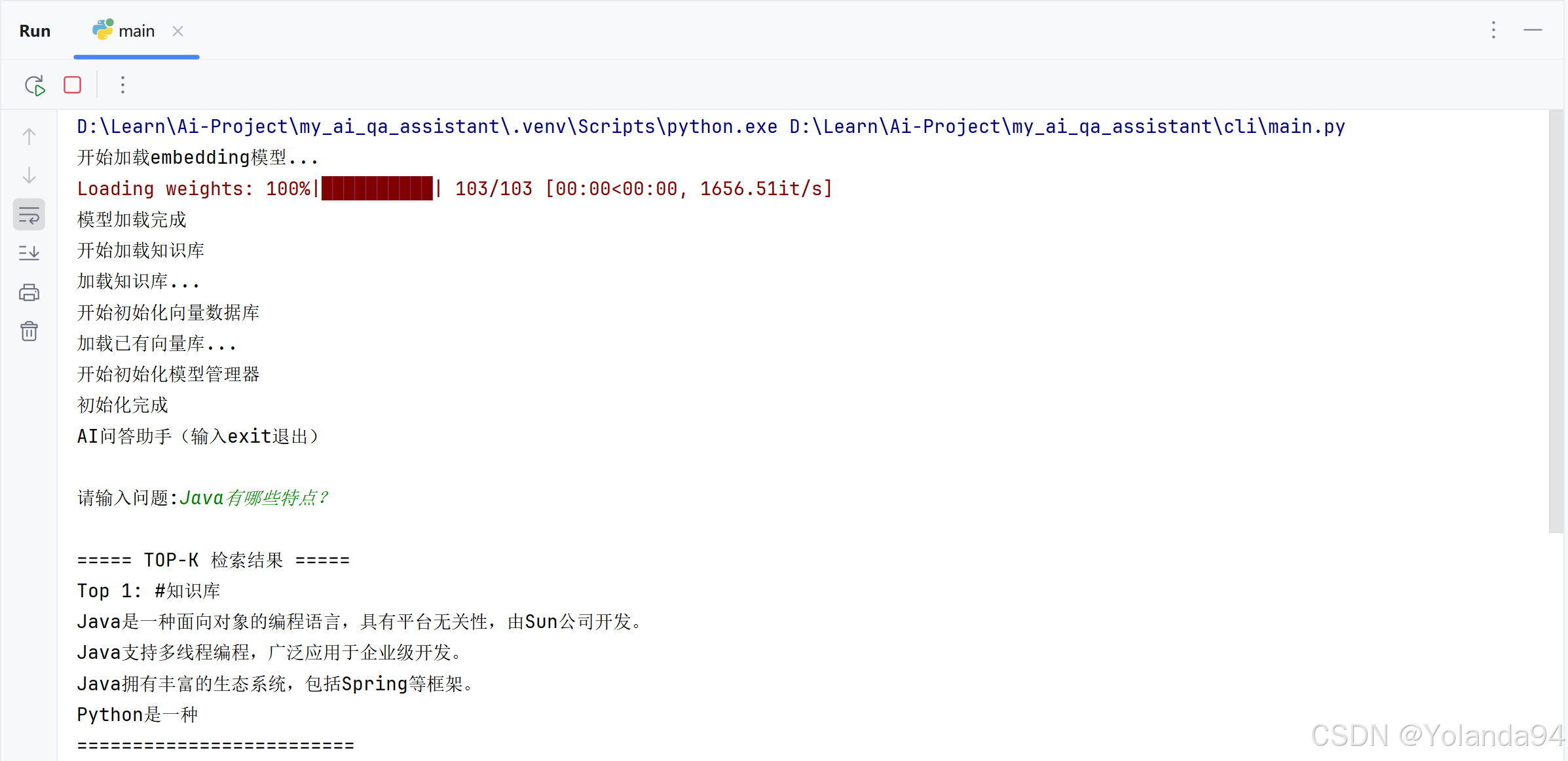
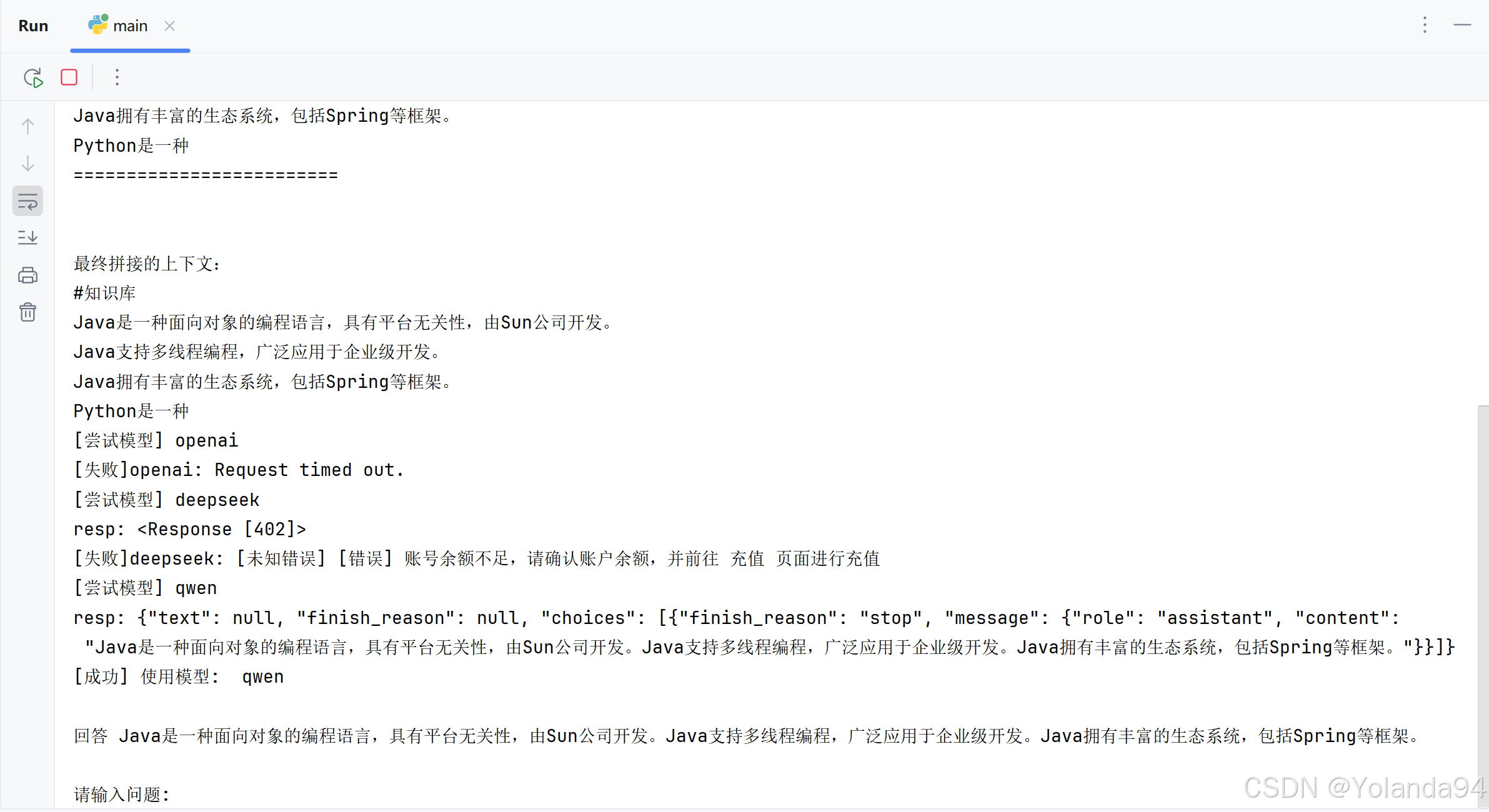
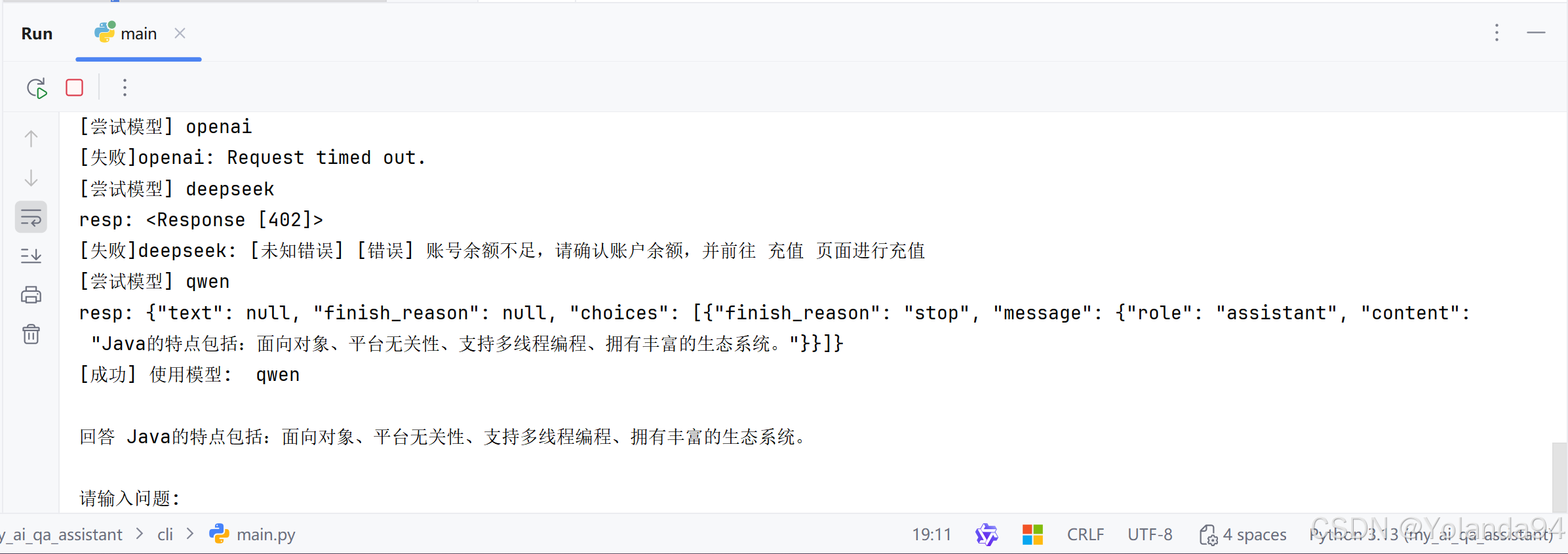
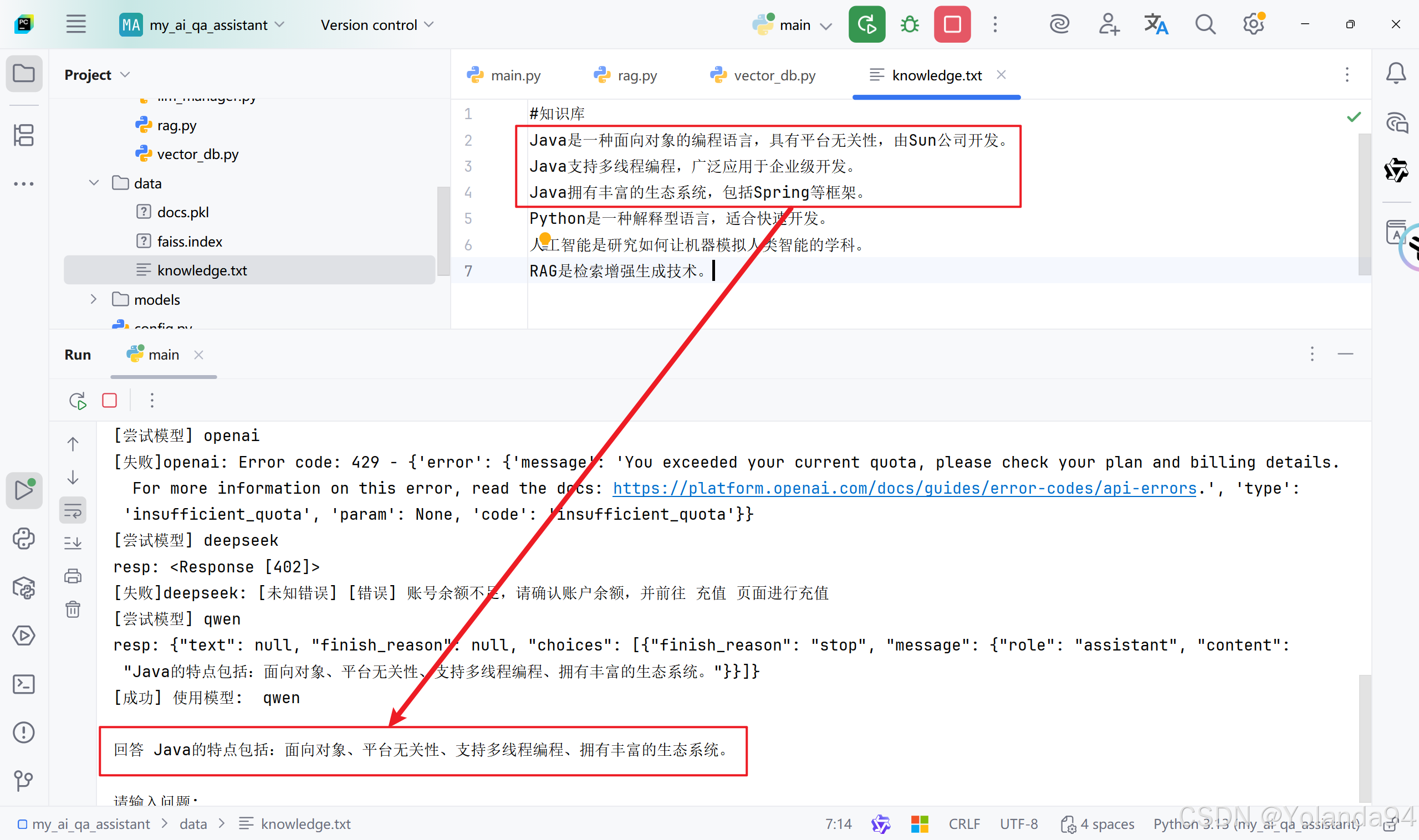
2)Top_K=3 测试结果
可以看到最终的答案是比较符合的。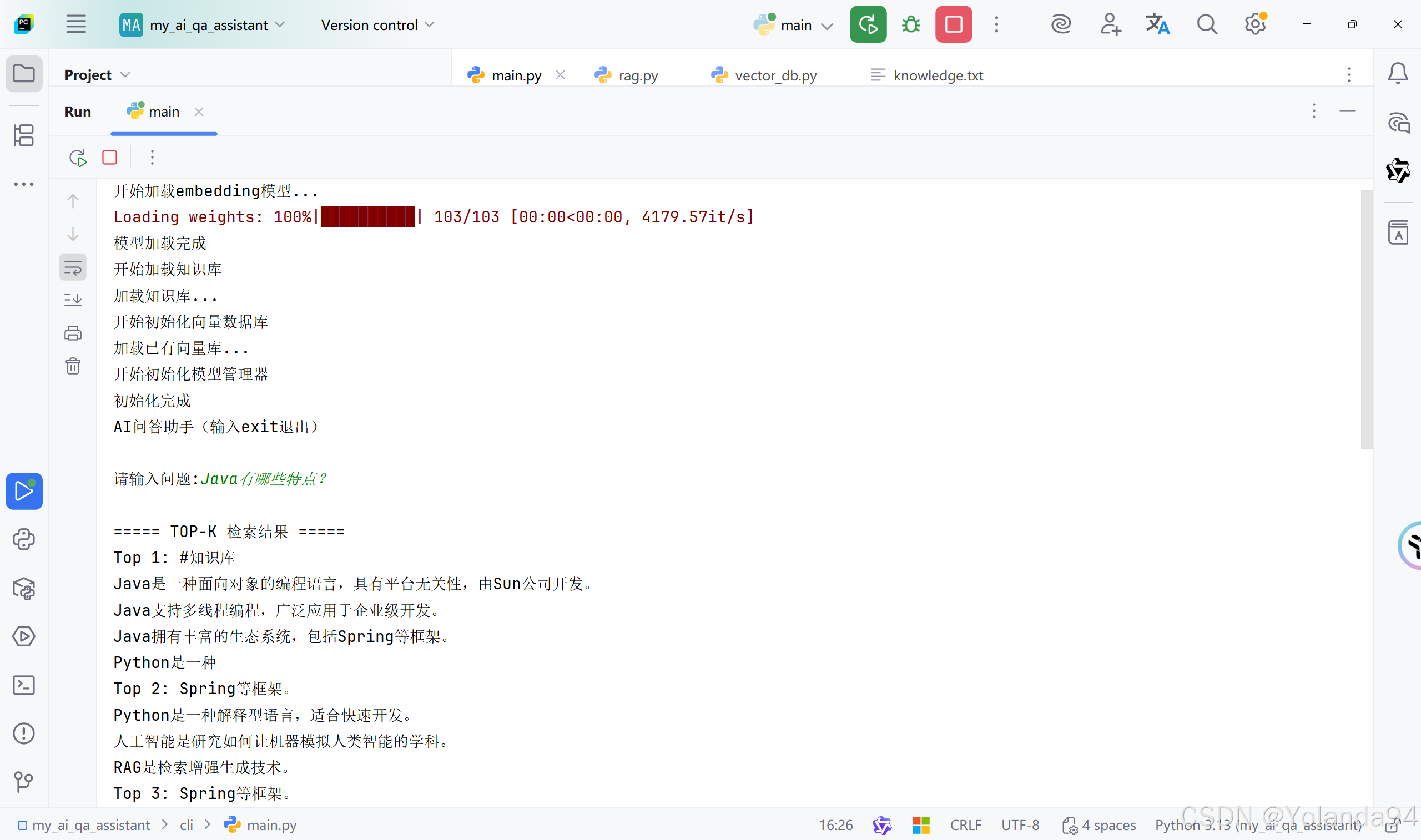
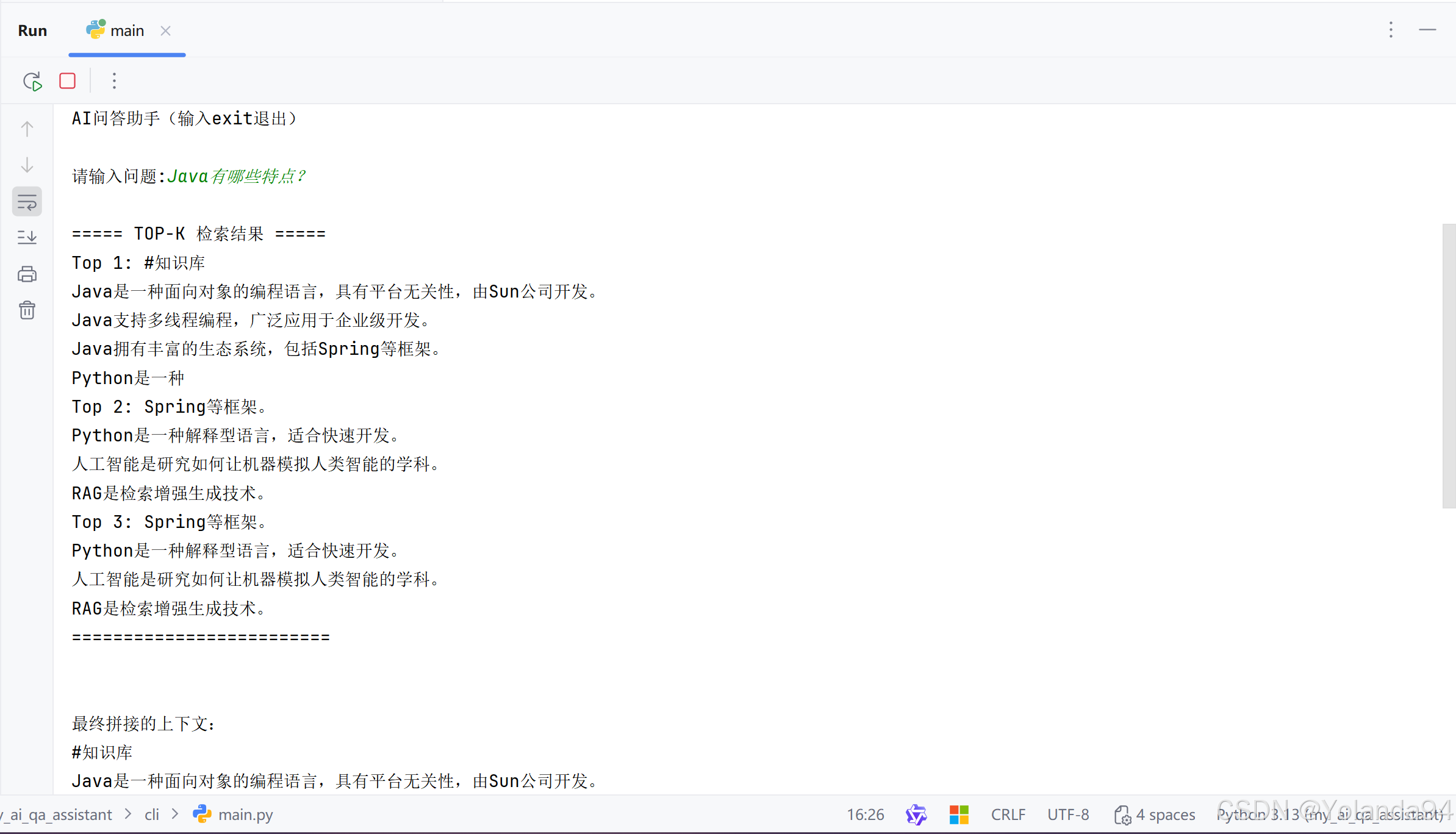
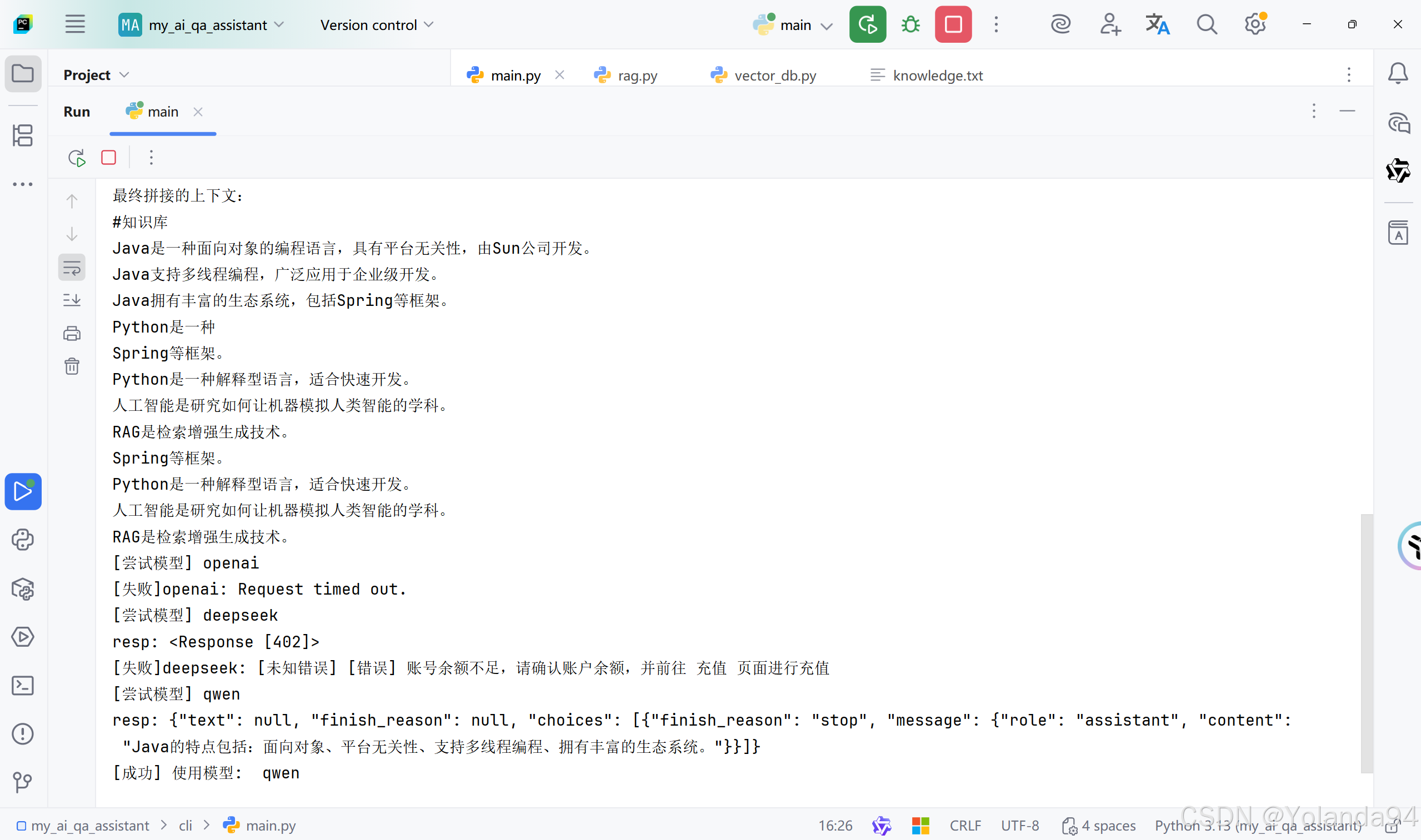

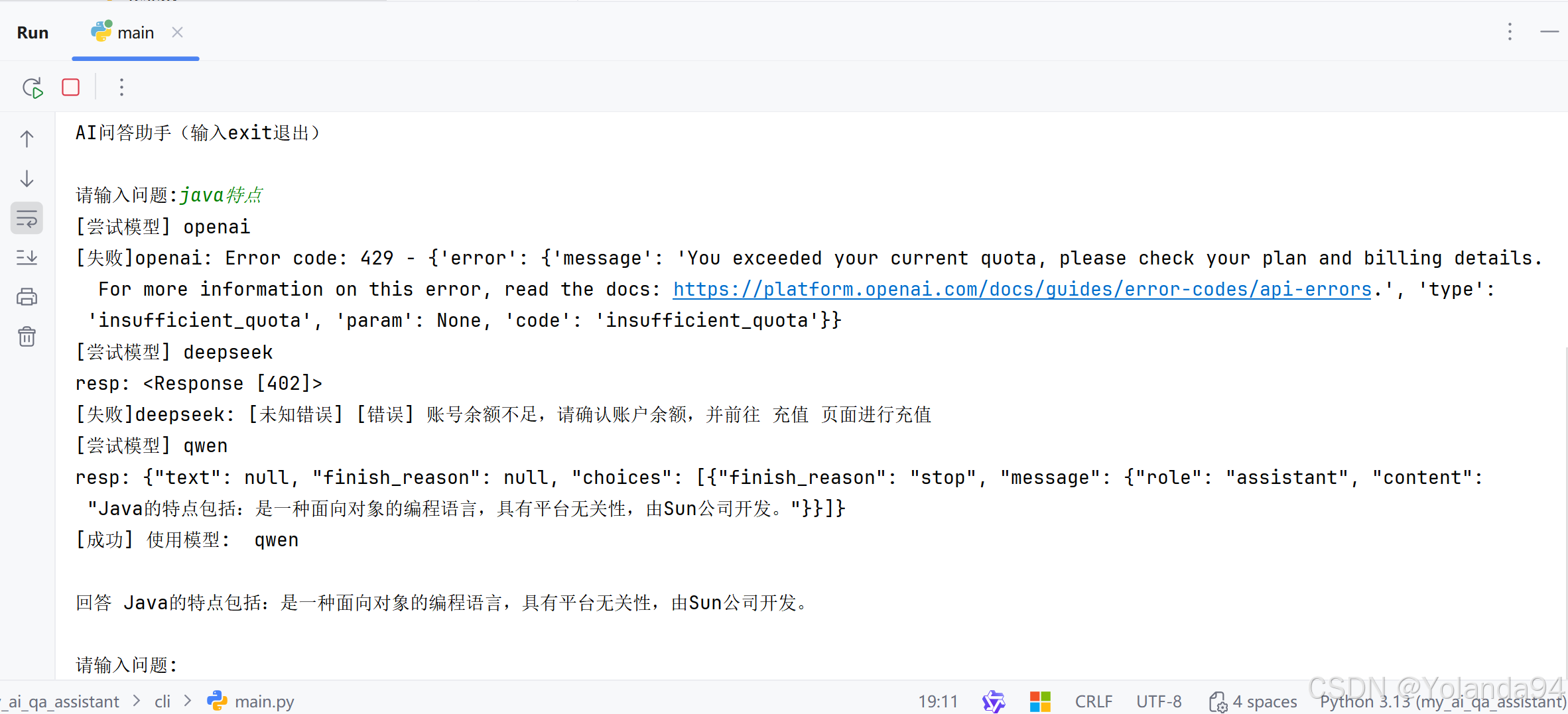
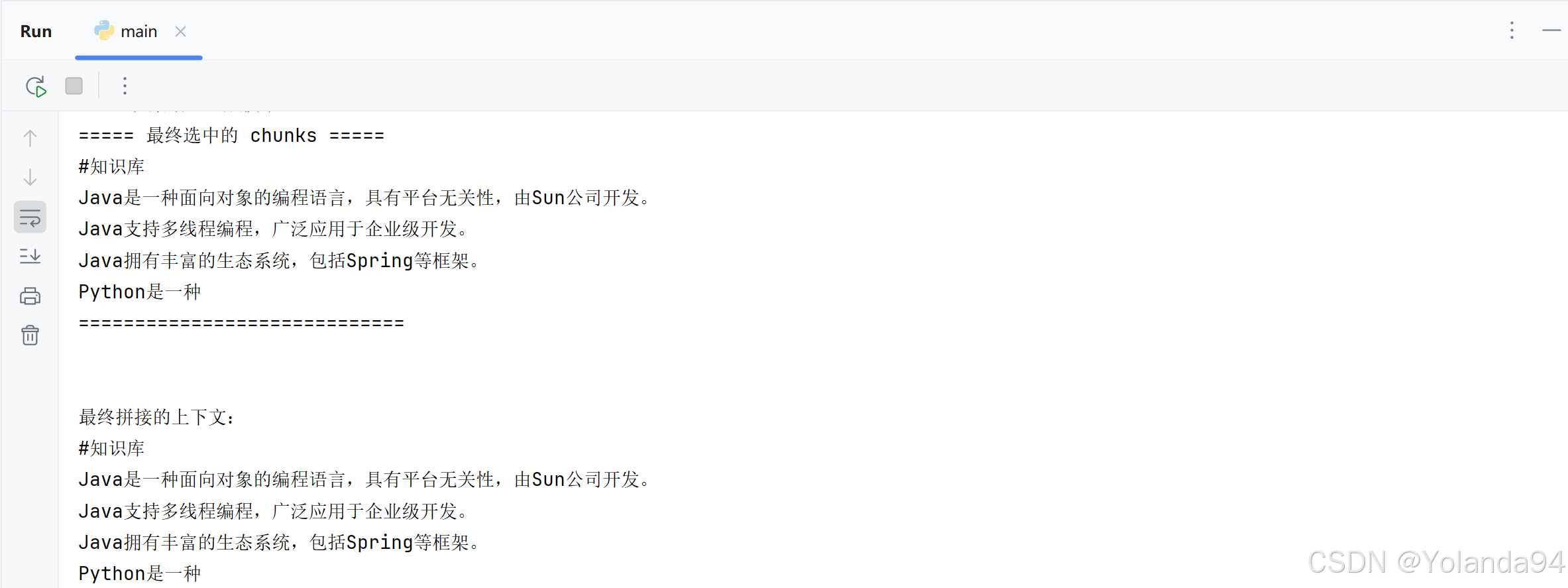
3)Top_K=5 测试结果
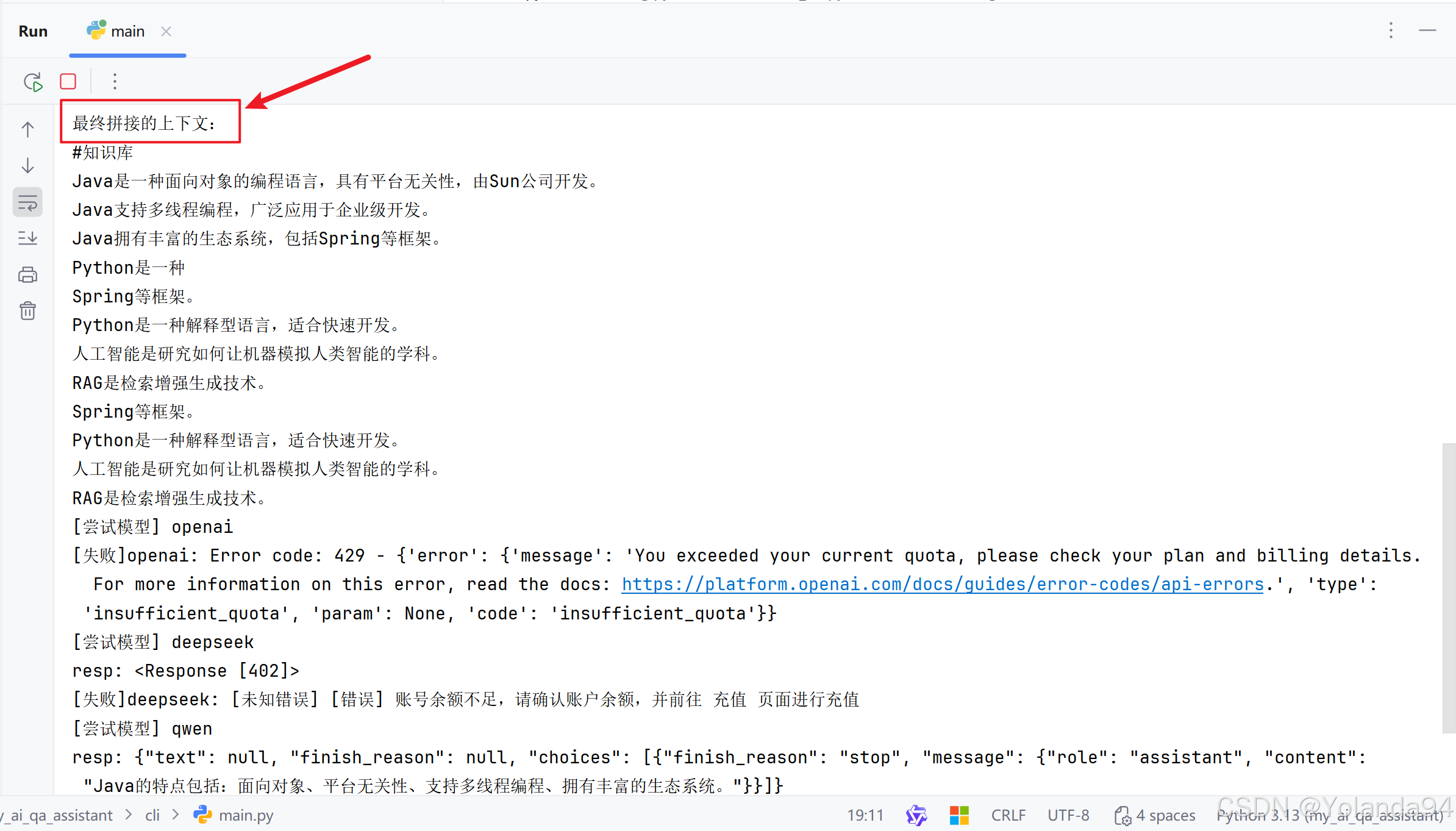
可以看到由于本地知识库太小,切片内容太少,检索到的Top_K后三条完全是跟第二条重复的,到最后发送给LLM之前的内容拼接里也拼接上了重复的内容(这完全是在浪费token)。
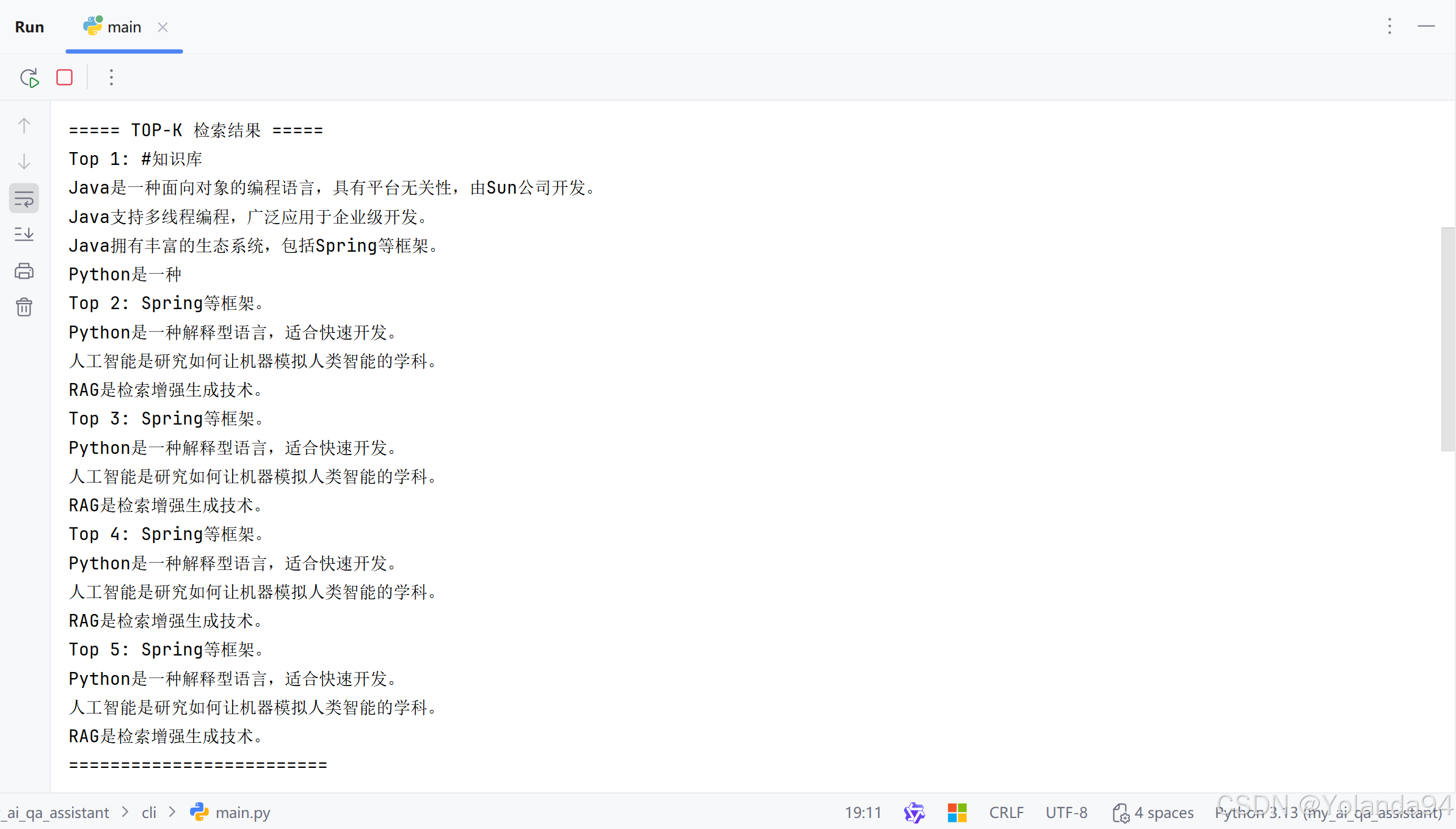
最终Top_K调优测试效果
Top_K优化技巧
不要只拼接,要“限制长度”。
如果你直接:
context = "\n".join(...)
当 K 大时:
context 太长 ❌
优化写法:
context = ""
for idx in I[0]:
if len(context) < 500: # 限制长度
context += self.docs[idx] + "\n"
作用:防止prompt爆炸,提高回答质量
进阶优化
方案1:Top-K + 相似度阈值
作用:过滤掉“不够相关”的chunk
THRESHOLD = 0.5
for score, idx in zip(D[0], I[0]):
if score < THRESHOLD:
continue
方案2:动态K(更高级)
短问题 → 少拿
长问题 → 多拿
注意:这里的query是指query 字符串的长度(字符数)
if len(query) < 10:
K = 2
else:
K = 4
示例1:
query = "Java特点?"
len(query) = 7
属于短问题 → K = 2
示例2
query = "Java有哪些主要特点以及应用场景?"
len(query) = 18
属于长问题 → K = 4
用 len(query) 只是一个简化策略,是“粗略估计复杂度”的方法,它并不真正“聪明”,因为长度 ≠ 信息复杂度。
反例:
问题1:Java特点?
问题2:Java优缺点?=
长度差不多,但语义复杂度不同
所以这个灵活策略是想表达根据“问题复杂度”决定取多少chunk,而不是单纯的长度。
更合理的优化方式(进阶)
方案1:简单优化
if len(query) <= 10:
K = 2
elif len(query) <= 20:
K = 3
else:
K = 4
比原来更细一点
方案2:按“问题类型”判断(更智能)
if "什么是" in query:
K = 2
elif "特点" in query or "优点" in query:
K = 3
elif "如何" in query or "怎么" in query:
K = 4
else:
K = 3
思路:
| 问题类型 | K |
|---|---|
| 定义类 | 小 |
| 列举类 | 中 |
| 复杂问题 | 大 |
方案3 工程思维
不写死规则,而是先取K=5 → 再用相似度过滤
TOP_K = 5
THRESHOLD = 0.6
results = []
for score, idx in zip(D[0], I[0]):
if score >= THRESHOLD:
results.append(self.docs[idx])
这样自动控制数量、更稳定、更工程化。
RAG效果 ≈ Chunk质量 × Top-K策略 × Prompt设计
注
其实测试验证的时候发现了一个问题——chunk切分太大,且本地知识库太小,导致其实top_k选择3其实也并不是最合适的。这个问题涉及的是数据规模的问题,准备单开一篇博客来讲,敬请期待~✿✿ヽ(°▽°)ノ✿
下一步
【人工智能】《从零搭建AI问答助手项目(八):THRESHOLD相似度设计》

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)