读研三年才明白:论文速读才是核心竞争力,手把手教你用AI实现
读研三年才明白:论文速读才是核心竞争力,手把手教你用AI实现
📌 导读
读研的朋友,有没有过这种体验——导师丢给你30篇论文让你“快速了解一下这个领域”,你对着电脑坐了一整天,只看完3篇,头已经开始发懵了?
或者花了两小时精读一篇论文,结果关上电脑,发现自己只记得个大概,具体贡献点想了半天才想起来。
这太正常了。传统论文阅读方式,天然就是一场和遗忘曲线的赛跑。
今天这篇文章,我想手把手教你一套用AI工具重构论文阅读流程的方法。重点工具是我自己开发的 TLDR Scholar(https://www.tldrscholar.cn),但更重要的是背后的方法论——30秒速读筛选 → 精读核心内容 → 整理笔记沉淀,这套三步法让处理论文的效率提升了至少5倍。
不管你是科研新人还是老手,这套方法都能帮你把“读论文”这件事,从苦力活变成有策略的技术活。
一、先说痛点:你是不是也在经历这些?
1.1 读不完的论文山
Nature曾做过一个调查,一个科研工作者平均每年要阅读近300篇论文。但这还只是“读”,不算筛选的时间。现实中,真正花在找论文、筛论文上的时间可能比读论文还多。
想象一下这个场景:
- 导师让你调研某个方向,你兴冲冲地去搜文献
- 搜出来200多篇,你开始一篇篇点开看摘要
- 看了半小时,眼睛开始发酸,发现大部分论文:
- 要么太老旧
- 要么和你的研究问题不太相关
- 要么专业性太强看不懂
你陷入了无尽的循环:搜索 → 看摘要 → 判断 → 继续搜索。 一整天下来,真正有价值的论文可能就那么几篇,但你的精力已经消耗殆尽了。
1.2 读不懂的论文墙
好不容易找到一篇“看起来相关”的论文,你决定好好读一读。
然后你发现:
- Introduction 还好,能看懂个七七八八
- Methodology 开始蒙圈,各种公式和术语扑面而来
- Results 彻底懵了,图看不懂,数据分析过程看不懂
- Discussion 勉强能跟上,但不知道作者的结论是否可靠
最要命的是,你从头读到尾,花了2个小时,合上电脑,发现自己好像什么都没记住。
1.3 读了就忘的论文坑
更扎心的是,你确实认真读了几篇论文,也做了笔记。但过了一周,你已经不记得自己读了什么。
原因很简单:逐字阅读 + 没有结构化整理 = 白读。
人脑对碎片化信息的记忆是短暂的。如果没有在阅读时建立清晰的知识结构,没有把新知识和已有知识关联起来,那读过的论文很快就会被遗忘。
二、为什么传统阅读方式注定低效?
在说正确方法之前,我们先来剖析一下传统论文阅读方式的问题出在哪里。
2.1 问题一:从不筛选,直接硬读
很多同学找论文的方式是这样的:
- 在 Google Scholar / Web of Science 搜索关键词
- 按引用量排序
- 从第一篇开始读
这是一个极其低效的策略。 引用量高的论文不一定是和你研究最相关的,也不一定是最新进展的。
正确的方式应该是:先通过快速浏览摘要,确定论文和自己的研究是否相关,再决定是否深入阅读。
2.2 问题二:逐字阅读,不分主次
拿到一篇论文,很多人的阅读顺序是:
Introduction → Method → Results → Discussion → Conclusion
从头读到尾,一个字都不放过。
但实际上,论文不同部分的价值是不同的:
- Abstract:价值最高,包含核心发现
- Introduction:帮助你理解研究背景
- Method:核心实现逻辑,但如果你不打算复现,其实可以略过
- Results:展示数据,需要仔细看
- Discussion:作者对结果的解读
不是每个部分都需要同等精力去读的。
2.3 问题三:读完不整理,遗忘率90%
心理学研究表明,24小时内不复习,我们会遗忘70%以上的信息。
但大部分人读论文的流程是:
打开PDF → 从头读到尾 → 关闭PDF → 打开下一篇
没有任何整理、没有笔记、没有知识沉淀。 你以为你在“读论文”,实际上你只是在“浏览文字”。
三、AI辅助阅读的正确姿势:三步法
那么,什么是正确的论文阅读方式呢?
结合我自己的实践和TLDR Scholar的功能设计,我总结了一套 “三步法”:
步骤一:速读筛选(30秒/篇)
目标:用最短时间判断“这篇论文值不值得读”。
具体操作:
- 提取论文的核心信息(研究问题、方法、结论)
- 判断是否和自己的研究相关
- 标记需要精读的部分
工具推荐:TLDR Scholar
我设计TLDR Scholar的初衷,就是帮助大家快速完成这个筛选环节。上传PDF,30秒内就能得到一份结构化摘要: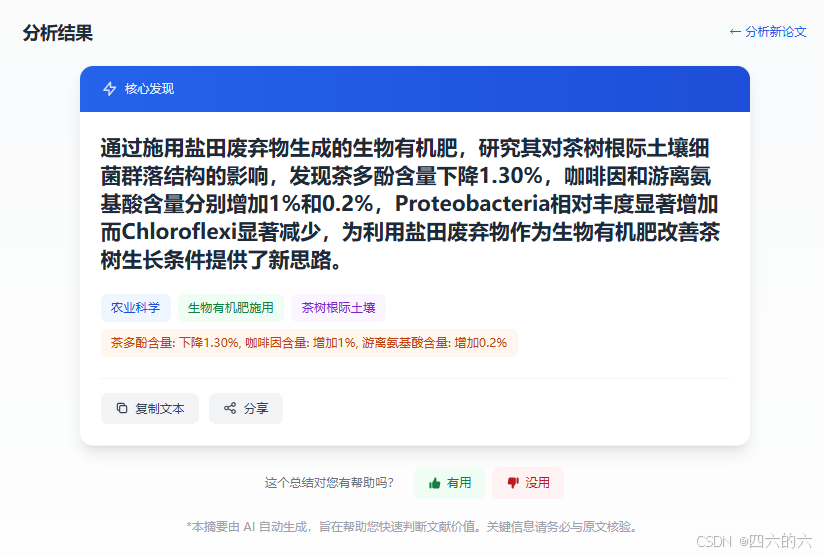
这份结构化摘要包含了论文最精华的部分:
- 学科领域:快速判断论文是否属于你的研究方向
- 研究方法:了解作者用了什么方法,评估是否值得借鉴
- 核心发现:一句话抓住论文的主要贡献
- 可重现指标:评估研究结果的可靠程度
步骤二:精读核心(15-30分钟/篇)
目标:深入理解论文的创新点和关键细节。
通过速读筛选出值得读的论文后,你已经有了基本的背景了解。这时候再精读,效率会高很多。
精读的正确姿势:
- 带着问题读:这篇文章解决了什么问题?用了什么方法?有什么创新点?
- 跳过你已经掌握的内容:如果速读时已经理解了研究背景,可以快速略过Introduction
- 重点关注Results和Discussion:理解数据、分析、结论
步骤三:整理笔记沉淀(10分钟/篇)
目标:把论文内容转化为自己的知识。
精读完成后,不要急着关掉论文。花10分钟做笔记,把:
- 论文的主要贡献
- 你的理解和思考
- 这篇论文和你研究的关联
记录下来。
推荐工具组合:
- TLDR Scholar:速读筛选
- Notion/Obsidian:笔记整理
- Zotero:文献管理
四、实战演示:完整走一遍TLDR Scholar使用流程
说了这么多理论,让我们来一场实战演示。我会用一篇真实论文,完整展示从打开网站到完成速读的全过程。
4.1 第一步:打开网站
浏览器访问:https://www.tldrscholar.cn
界面非常简洁,没有花里胡哨的功能堆砌。点击中间的上传区域,或者直接把PDF拖进去。
4.2 第二步:上传论文
支持PDF和Word两种格式,单个文件大小限制在30MB以内。
我这里上传一篇关于生物检测的论文。
上传完成后,系统会自动开始处理。底部会有一个进度条。
4.3 第三步:等待30秒,查看结构化摘要
处理完成后,你会看到一份非常清晰的结构化摘要:
以这篇论文为例:
| 字段 | 内容 |
|---|---|
| 学科领域 | 农业科学 |
| 研究方法 | 生物有机肥施用 |
| 核心发现 | 茶树根际土壤 |
| 可重现指标 | 茶多酚含量: 下降1.30%, 咖啡因含量: 增加1%, 游离氨基酸含量: 增加0.2% |
4.4 第四步:判断是否值得精读
基于这份结构化摘要,你可以快速做出判断:
如果你是做NLP研究的:
- ✅ 这篇论文和你的研究高度相关
- ✅ 方法新颖,值得深入学习
- → 标记为“精读”
如果你是做计算机视觉的:
- ❌ 和你的研究关联度一般
- → 可以快速略过,或者收藏备用
整个判断过程,只需要30秒。
4.5 第五步:阅读笔记
如果决定精读,你可以记录下:
- 论文基本信息
- 研究动机
- 核心贡献
- 方法原理
- 个人思考
你可以在这个基础上添加自己的理解,让笔记真正变成你的知识。
五、效率对比:传统方式 vs AI方式
让我们来算一笔时间账:
5.1 传统方式
| 环节 | 时间 | 说明 |
|---|---|---|
| 搜索论文 | 30分钟 | 找到20篇候选论文 |
| 逐篇读摘要 | 60分钟 | 20篇 × 3分钟/篇 |
| 判断相关性 | 10分钟 | 犹豫不决,反复确认 |
| 总计 | 100分钟 | 完成20篇论文的筛选 |
5.2 AI方式
| 环节 | 时间 | 说明 |
|---|---|---|
| 搜索论文 | 30分钟 | 找到20篇候选论文 |
| TLDR Scholar速读 | 10分钟 | 20篇 × 30秒/篇 |
| 判断相关性 | 5分钟 | 结构化摘要,一目了然 |
| 总计 | 45分钟 | 完成20篇论文的筛选 |
节省55分钟,效率提升122%。
而且,AI方式还有一个隐藏优势:速读的质量更稳定。
人眼疲劳时,读摘要可能会漏掉关键信息。AI工具则每次都能保持同样的标准,不会因为“看了太多篇累了”而降低判断准确率。
5.3 精读环节的效率提升
速读筛选还有一个更大的价值:它能帮你筛选出真正值得精读的论文。
传统方式,你可能每篇论文都读30分钟,但有些论文根本不值得你花这么多时间。
AI方式,先用30秒判断“这篇值不值得花30分钟”,精读的命中率大大提高。
把有限的时间花在真正值得的论文上,这本身就是效率的跃升。
六、进阶技巧:如何用TLDR Scholar做文献综述
掌握了基本用法之后,这里分享几个进阶技巧,帮助你更好地做文献综述。
6.1 批量处理 + Excel管理
做文献综述时,通常需要处理几十甚至上百篇论文。我的建议是:
- 用TLDR Scholar批量速读(虽然每次只能处理一篇,但速度够快)
- 把速读结果导出到Excel,整理成文献筛选表
Excel表格可以包含:
- 论文标题
- 发表年份
- 核心发现
- 研究方法
- 相关程度(高/中/低)
- 后续动作(精读/略过/待定)
6.2 按研究问题聚类
读完一批论文后,你会发现很多论文其实在讨论同一个问题。
这时候,可以按照研究问题对论文进行聚类:
研究问题A:
- 论文1:提出了XX方法
- 论文3:改进了YY方法
- 论文7:从ZZ角度验证了XX方法
研究问题B:
- 论文2:提出了AA方法
- 论文5:和AA方法做了对比
- 论文9:在BB场景下验证了AA方法
这种聚类方式,能帮你快速理清这个领域的研究脉络:有哪些核心问题?每个问题有哪些代表性方法?这些方法之间的关系是什么?
6.3 追踪最新研究
做研究不能只关注经典论文,最新发表的研究同样重要。
建议定期:
- 在arXiv上搜索你关注领域的最新论文
- 用TLDR Scholar快速筛选
- 标记值得关注的新论文
养成习惯后,你对这个领域最新进展的把握,会远超同龄人。
6.4 工具组合使用
TLDR Scholar擅长的是速读筛选,但它不是万能的。
这些场景,建议配合其他工具使用:
| 场景 | 推荐工具 |
|---|---|
| 精读复杂论文 | ScholarReader |
| 文献管理 | Zotero |
| 笔记整理 | Notion/Obsidian |
| 论文翻译 | 知云文献翻译 |
| 思维导图 | XMind/Miro |
工具组合使用,效率翻倍。
七、常见问题解答
Q1:论文太长了怎么办?支持几十万字的长论文吗?
TLDR Scholar对论文长度有一定限制(建议30MB以内),但对于大部分学术论文来说,这个限制是够用的。
如果论文实在太长,可以:
- 先只读Abstract部分,看看是否值得继续
- 分章节处理:先看Introduction + Method + Conclusion,判断价值
Q2:支持中文论文吗?
支持。 TLDR Scholar可以处理中英文论文。不过需要说明的是,目前AI生成结构化摘要的能力,对英文论文的解析效果会更好一些(因为英文论文的训练数据更多)。
对于中文论文,功能同样可用,只是部分细节可能需要人工核实。
Q3:AI总结的准确率如何?会不会瞎编?
这是个好问题。TLDR Scholar基于大语言模型能力,核心目标是提取论文中的关键信息,而非生成新内容。
它的原理是:
- 解析论文的文本内容
- 提取关键信息(研究问题、方法、结论等)
- 以结构化格式输出
所以,摘要内容是基于原文提取的,不是生成的,不存在“瞎编”的风险。
但也需要提醒大家:AI提取的信息可以作为参考,重要论文的核心内容建议还是自己读一遍原文确认。
Q4:上传的论文数据安全吗?会被用来训练模型吗?
不会。 TLDR Scholar不会将用户上传的论文用于模型训练。所有处理都在服务器端完成,文件会在处理完成后自动删除。
如果对数据安全有特别要求,建议使用本地部署的AI工具。
Q5:免费吗?有没有使用限制?
目前TLDR Scholar可以免费使用,但可能有每日处理次数的限制。具体政策可以在官网查看。
Q6:除了学术论文,能读其他类型的文档吗?
目前主要面向学术论文优化。如果是其他类型的文档(如技术博客、商业报告等),也可以尝试使用,但结构化输出的字段可能不完全适用。
八、总结
回到开头的问题:为什么你读了那么多论文,却感觉没什么收获?
因为传统阅读方式,从根上就是低效的:
- 不筛选,直接硬读
- 逐字阅读,不分主次
- 读完不整理,遗忘率90%
这套AI辅助阅读三步法,改变的不只是工具,更是阅读策略:
- 30秒速读筛选 → 把有限的时间花在值得的论文上
- 精读核心内容 → 带着目标和背景去读,效率翻倍
- 整理笔记沉淀 → 让读过的论文真正变成你的知识
工具只是手段,方法才是核心。 TLDR Scholar能帮你加速前两步,但第三步——整理笔记——还是需要你自己完成。
因为知识只有经过自己的思考和整理,才能真正内化为你的能力。
工具链接:https://www.tldrscholar.cn
写在最后:这篇文章是CSDN写作计划的第9篇。前几篇分别从不同角度聊了论文阅读这件事——产品设计、开发者视角、技术实现、产品思维、AI局限、技术架构、转行经历、竞品对比等。
这一篇是纯纯的实战教程,就是想手把手教会你怎么用这个工具。
如果觉得有用,欢迎点赞、收藏、转发给需要的朋友。
有问题也可以评论区留言,我会尽量解答。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)