【Dify】工作流和agent
目录
简单来说,工作流就是把一个复杂的任务,拆解成一步一步固定的、自动化的“流水线”。
1. 为什么要用工作流?(对比普通聊天的降维打击)
你可能会问:“我直接在 ChatGPT 或 DeepSeek 里写一段很长的 Prompt,不也能完成任务吗?”
确实可以,但普通聊天有三个致命痛点,而工作流完美解决了它们:
| 维度 | 普通对话(Chat) | 工作流(Workflow) |
|---|---|---|
| 稳定性 | 碰运气。这次回答得好,下次可能就翻车。 | 极高。步骤和逻辑固定,结果高度可控。 |
| 复杂度 | 无法处理太复杂的业务(如先算数学题,再查数据库)。 | 极强。可融合大模型、代码、传统 API、数据库。 |
| 自动化 | 必须人工一句一句盯着喂数据。 | 全自动。网页一键触发,或通过 API 批量处理成千上万条数据。 |
2. 工作流的“四大支柱”
一个完整的工作流,一定由以下四种角色组成:
-
输入(原材料)
用户塞给这条流水线的东西。可以是一段文本、一个文件,或者一个勾选项。 -
处理(加工厂)
- AI 节点:负责需要“理解、创作、翻译”的脑力活。
- 代码/工具节点:负责需要“精准、计算、查外部数据”的体力活(如格式化时间、获取今天的天气)。
-
控制(交通警察)
即条件分支(IF/ELSE),根据上一步的结果决定往哪走。例子:检查 AI 生成的文章,如果字数大于 2000 字,走“压缩体积”分支;如果小于 2000 字,直接走“发布”分支。
-
输出(成品包装)
把最终加工好的数据,以漂亮的格式呈现给用户。
3.Dify中的两种工作流
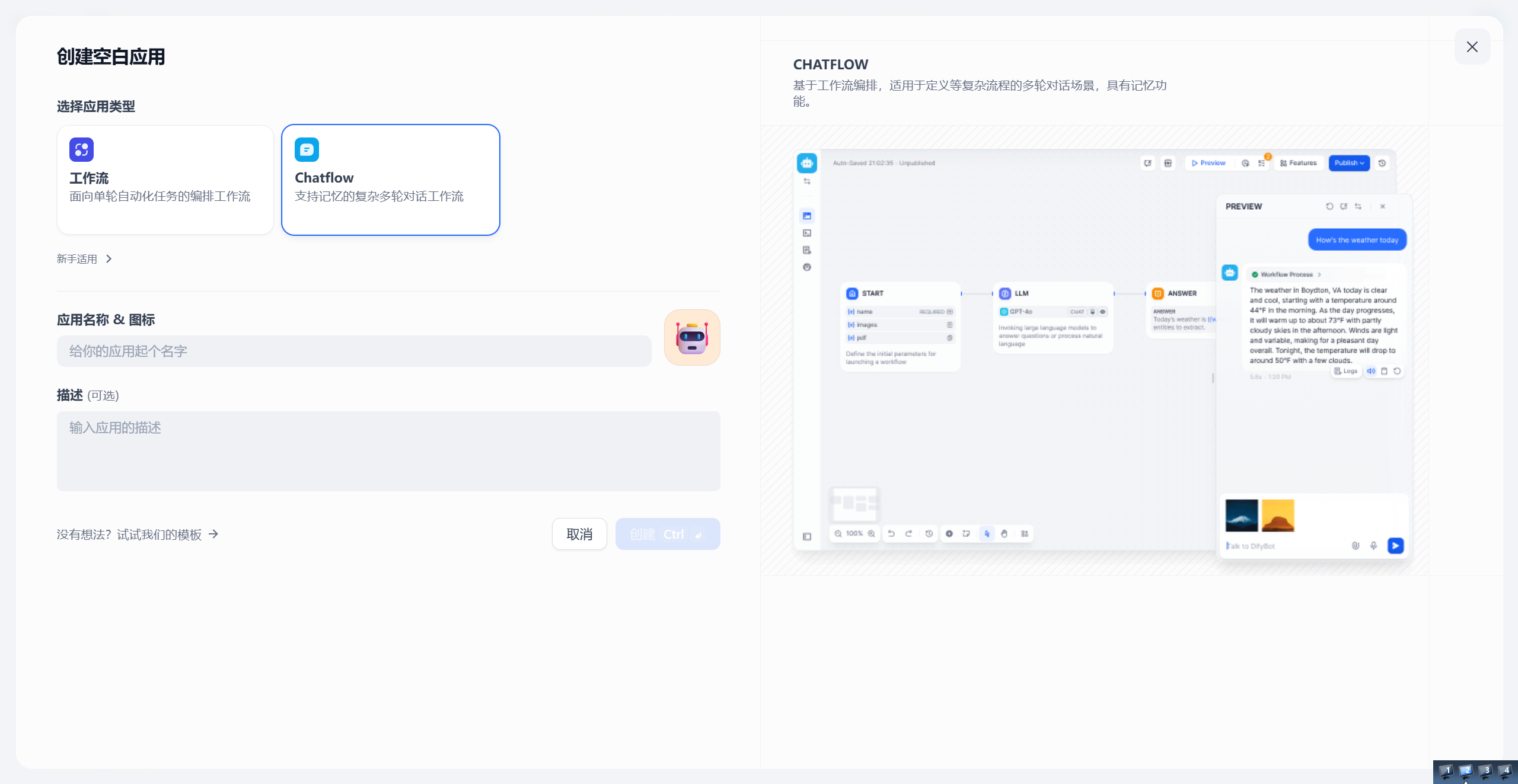
可以看到这里有两种工作流,一种是Workflow,一种是Chatflow。
以下是它们的区别:
| 特性 | Chatflow(对话型) | Workflow(任务型) |
|---|---|---|
| 最终输出节点 | Answer 节点(可以有多个,边跑边输出) | End 节点(只能有一个,作为最终出口) |
| 对话记忆(Memory) | 🧠 有,能进行多轮连续对话 | ❌ 无,单次输入,单次输出 |
| 用户界面呈现 | 类似微信的聊天对话框 💬 | 表单输入框 + 结果展示面板 📄 |
| 主要使用方式 | 网页聊天、嵌入网页的 Chat 插件 | 批量运行、作为 API 接口供第三方系统调用 |
1.实例:做一个电商问答助手(工作流)
我们现在来做一个电商问答助手,首先创建一个空白应用,然后点击工作流(为了练习,不然要用Chatflow更合适,不过工作流也可以当作技能插件内嵌到对话流中)。
最开始的节点应该是获取用户输入而不是触发,所以点击用户输入来到以下页面:
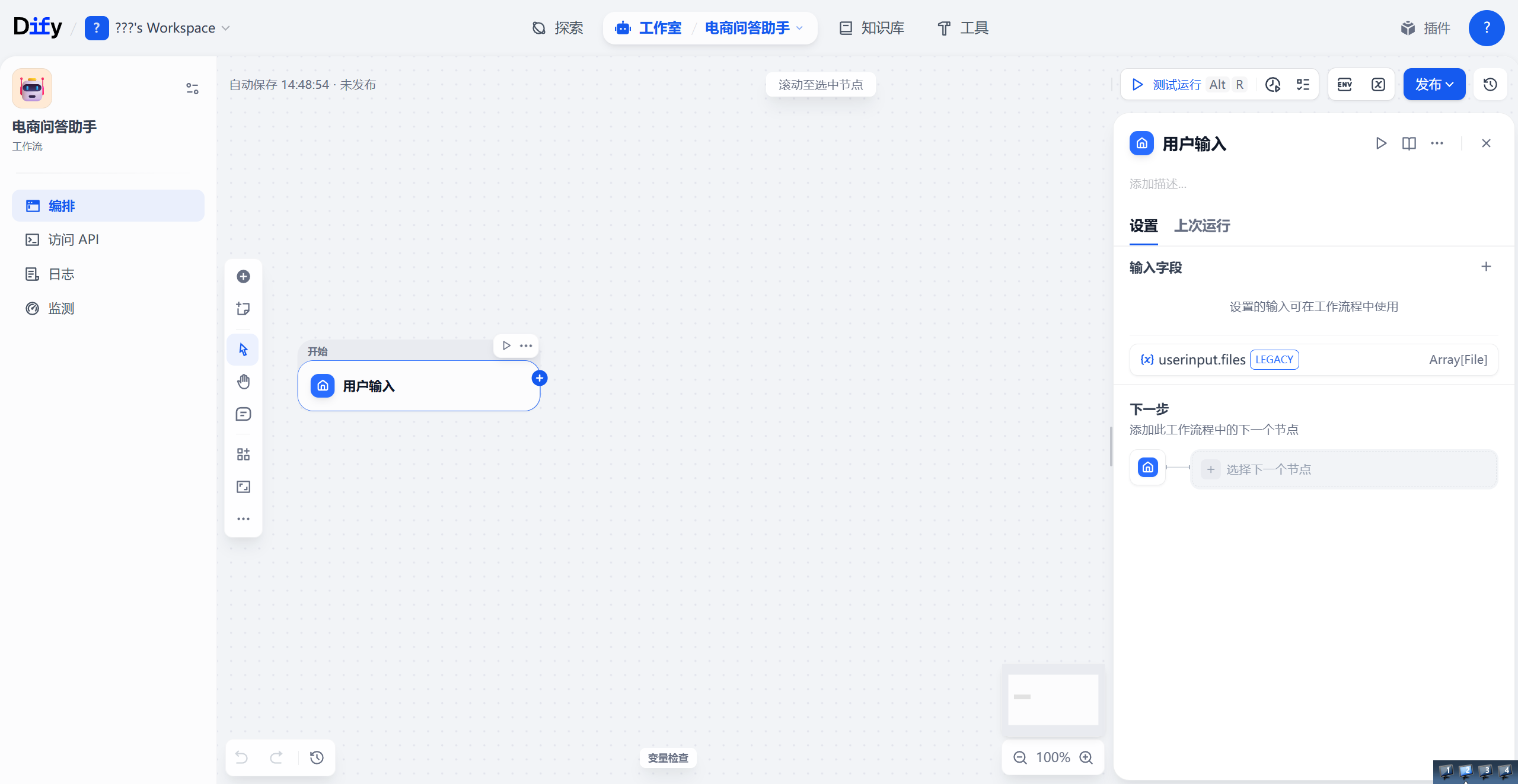
中间就是我们创建节点和连线的地方,当你点击画布上的任何一个节点时,右侧就会弹出这个节点的详细配置面板。
在右边,默认会有个userinput.files参数,代表用户可以上传文件,如果想关上这个功能可以在应用的全局设置里关上文件上传的功能。
我们点击加号,添加一个参数,作为用户输入的问题。
接下来要右键创建下一个节点了,在这之前,先了解下这些节点的功能。
-
基础类节点
🟣 LLM(大模型)
核心功能:调用指定的大语言模型(如 GPT、Claude 等),根据你编写的提示词(Prompt)和输入的变量,进行文本生成、推理、翻译或摘要。它是工作流中处理非结构化文本的“智力核心”。🟢 知识检索
核心功能:基于外部向量数据库(RAG 架构),将输入的文本(如用户的问题)转化为向量,在已上传的知识库文档中进行语义匹配,自动筛选出相关度最高的内容段落并输出。🟠 输出 / 结束
核心功能:定义整个工作流的终点。负责将工作流最终运行出来的变量、文本或数据打包,作为整个工作流的最终结果返回给调用者。🔵 Agent(智能体)
核心功能:在固定的工作流中嵌入一个“具备自主规划能力”的独立单元。该节点拥有自己的大模型、独立的系统提示词和可调用的工具集,能够采用 ReAct 等推理模式,自主决定执行步骤。 -
问题理解类
🟢 问题分类器(Question Classifier)
核心功能:利用大模型的语义理解能力,对输入的文本进行意图意向识别。你需要预先定义好几个分类标签(Class),它会自动判断输入文本属于哪一个标签,并以此作为分支依据。 -
逻辑类
🔀 条件分支(IF/ELSE)
核心功能:根据明确的硬性规则进行逻辑分流。你可以设定条件(如:某个变量是否包含特定字符、某个数字是否大于指定值、变量是否为空等),满足条件走分支 A,不满足走分支 B。🔄 人工介入
核心功能:用于构建“人机协同(Human-in-the-loop)”的流程。当工作流运行到此节点时会自动挂起(暂停),等待人类操作员在后台查看当前上下文、手动输入数据或确认后,工作流才继续向下执行。🔄 迭代(Iteration)
核心功能:专门用于处理数组/列表(Array)数据。它会遍历输入的列表,对列表中的每一个元素重复执行一遍内部包裹的子节点流程,最终将所有执行结果重新组装成一个新的列表输出。♾️ 循环(Loop)
核心功能:重复执行一段特定的节点流程,直到满足你设定的终止条件(比如计数器达到上限,或者某个变量的状态发生了改变)才会跳出循环。 -
转换类
🔵 代码执行(Code)
核心功能:提供一个纯净的沙箱环境,允许你编写 Python 或 JavaScript 代码。用于处理大模型不擅长的硬编码逻辑,例如复杂的数学计算、高精度的字符串裁剪、数组重组或时间格式转换。🔵 模板转换(Template)
核心功能:文本拼接与排版工具。采用类似 Jinja2 的模板语法,允许你自由定义一段文本格式,并在其中插入前方节点的多个变量,将它们一键拼装成一段结构化的新文本。🔵 变量聚合器
核心功能:多路分支的“收流阀门”。在工作流中,如果因为使用了条件分支(IF/ELSE)或问题分类器导致数据走向了不同的平行路径,变量聚合器可以将这些不同路径产生的最终变量统一映射为一个新变量,确保后续节点引用时只有单一的数据源。🟢 文档提取器(Doc Extractor)
核心功能:文件解析桥梁。由于大模型本身无法直接读取 PDF、DOCX、XLSX 等原始文档文件,该节点专门负责读取输入的文件变量,将文件中的文字、段落乃至图片附件提取出来,转换成下游节点(如 LLM)能够直接阅读处理的纯文本格式。🔵 变量赋值(Variable Assigner)
核心功能:持久化数据管理。普通的全局变量在单次工作流运行结束时就会被重置清空,而变量赋值节点允许你将运行过程中的临时数据,写入并存储到可以长期存在的“会话变量”中。它支持覆盖、追加(往数组里塞新东西)或算术运算,用来在多轮对话之间留存上下文、用户偏好或历史记忆。🔵 参数提取器(Parameter Extractor)
核心功能:结构化信息榨取。利用大模型的推理能力,从一段杂乱的非结构化长文本中,按照你指定的字段名称和数据类型(如字符串、数字、布尔值、数组),精准地把核心关键信息“提炼”并整理出来,生成一组规范的参数,专为喂给下游的代码节点或 API 工具使用。 -
工具类节点(连接外部世界)
🟣 HTTP 请求
核心功能:系统对外的任意通道。允许工作流发送标准的 HTTP 请求(支持 GET、POST、PUT、DELETE 等各种方法),用来调用任何公司内部的私有接口或市面上的第三方公开 API。它可以向外部系统发送数据,也能实时抓取外部系统的数据返回给工作流。🔵 列表操作(List Operator)
核心功能:数组数据过滤器。专门用来对多项数据组成的列表/数组(如:混合上传的多个文件列表、一组数字或字符串列表)进行数据清洗。它提供筛选(按文件类型/大小/名字过滤)、排序(升降序)以及选择(只取前 N 个、第一条或最后一条记录)三大功能,将杂乱的数组整理成下游节点方便处理的单一或专一流。
在了解了这些节点的功能后,我们发现还有工具可以使用。
和之前那篇讲解的工具作用是一样的。
整体的设计大致如下:
首先,系统通过用户输入节点抓取用户的问题文本。接着,让大模型充当“前台大堂经理”,对用户意图进行分类判断,然后使用代码执行节点将分类结果翻译成标准参数,以便后续路由使用。
根据意图分类结果进行路由:如果用户问的是商品或物流相关问题,就走条件分支的IF线路,先去知识检索节点查询标准答案,再连接一个LLM节点组织语言回答。如果用户问的是退款、发票或投诉,就走ELSE线路,复杂的业务调用HTTP请求节点对接后台接口,实在搞不定的直接连转人工节点。如果是打招呼闲聊,同样走ELSE线路,但不用查知识库,直接让另一个LLM节点放飞自我陪用户聊天。
最后,无论走哪条线路,都将最终结果统一送到直接回复节点,返回给用户。
下面就是完整的流程图(人工客服和api调用暂时没写)
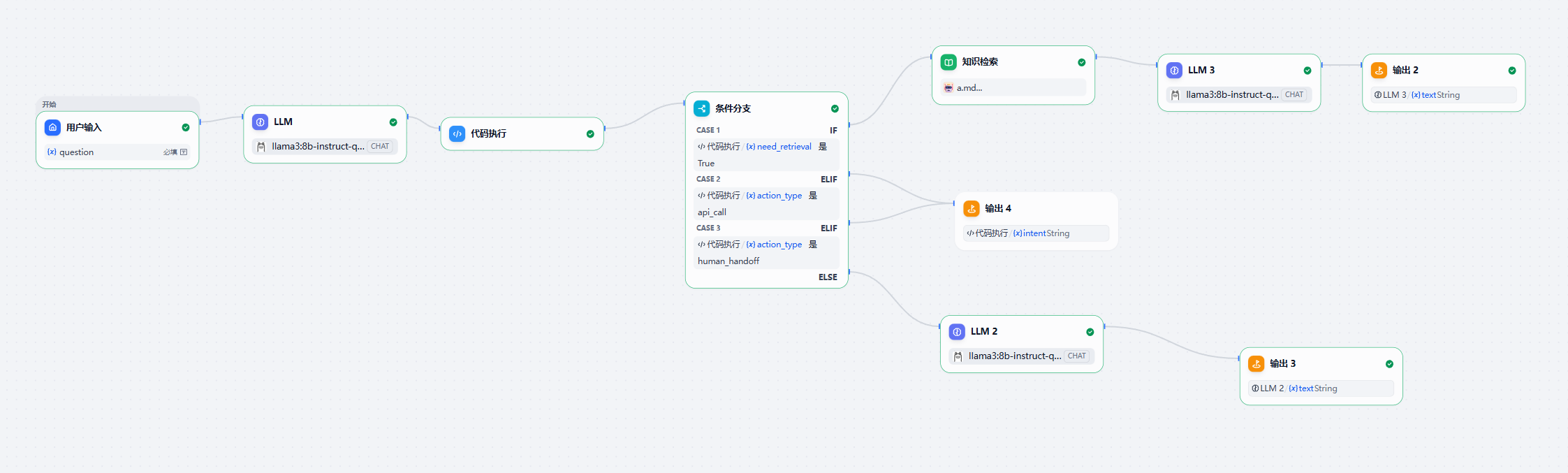
设置完成后,点击发布更新,就可以在页面中测试整个流程,还可以通过访问API的方式让别人也能用,但待会再说吧。
2.实例:做一个NLP2SQL数据库查询助手(对话工作流)
NLP2SQL(Natural Language Processing to SQL,自然语言转 SQL)是一种技术或系统,它的核心功能是把人类日常说的普通话(自然语言)自动翻译成数据库能够理解的 SQL 查询语句。
简单来说,它的目标是让不懂编程、不会写 SQL 的普通人,也能直接通过“说人话”来查询数据库。
首先,我们要下载两个关键工具,分别是database,Echarts图标生成。
我们可以在下载的时候看到这两个工具是做什么的。
database还需要进行API配置,凭据名称也要填,URL可以通过以下操作来得到。
如果Dify是本地部署的,并且是Mysql数据库,需要填写:
mysql+pymysql://user:password@host:3306/database/你的数据库名称,host不能是localhost,会指向Docker容器内部,需要根据情况来填写。
如果数据库也在Docker里,那么就填Docker网络中的容器名称。
如果数据库在宿主机上,那就填写host.docker.internal。
配置好后,我们就可以开始创建一个chatflow了。
进入到画布,这里会有三个节点,其它的和workflow都没有什么不同,但是注意这里多了一个‘直接回复’的节点。
它的作用是实现流式输出(Streaming)和中间结果的实时反馈。它打破“必须等所有流程走完”的限制,实现了‘边想边说’,而且可以有多个,那么它的主要作用就是用来提示用户目前我进行到哪一步了。
现在的思路是,先让大模型根据用户输入生成SQL语句,然后用代码格式化这些语句(可能前后会有多余的空格,或者是其他格式问题),在这个过程中,通过直接回复来提示用户SQL语句是正在生成还是在格式化。
接着,用迭代来处理这些SQL语句,放入database中执行,然后就是在迭代外整理database
返回的内容,分别是整理格式,判断是否生成图表,最后回复。
大致流程如下: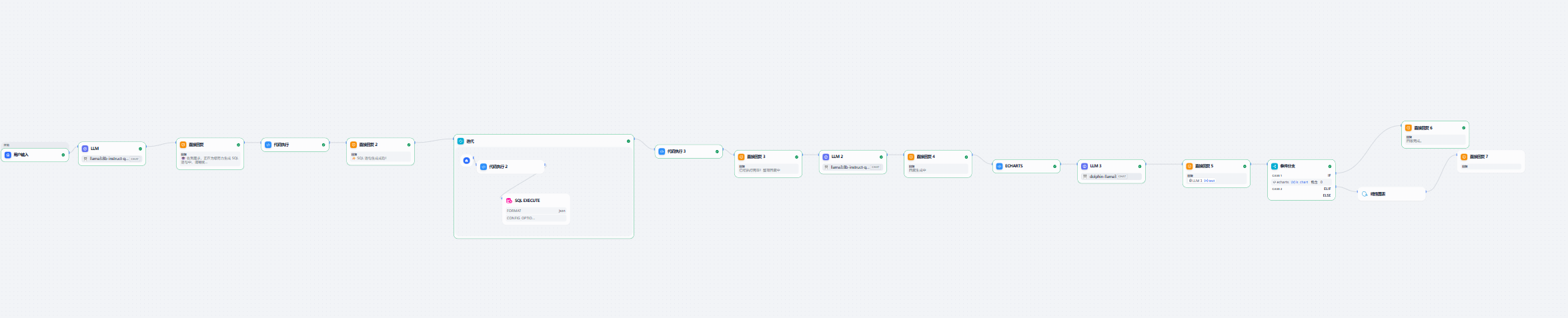
最后的分支语句根据前面的参数再加上饼状图等就行。
4.Agent嵌入网站应用
在发布的时候,可以选择嵌入网站,然后将生成的js代码粘贴到自己的html文件或者js文件即可。
如果选择作为独立窗口的话,将iframe放到希望它出现的地方就行。
5.Agent封装API应用
选择访问API,在弹出的新的界面中的右上角新建一个密钥。
复制到postman里面就可以测试了。
![]()
这就是我们测试的URL,在header中改一下api密钥,然后向它发送请求就可以看到结果了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)