(NeurIPS-2025)MAGE 以简驭繁:线性自适应图学习赋能时空预测
主要内容:本文聚焦时空预测领域痛点,介绍了中科大团队提出的 MAGE 模型。传统时空图模型存在图拓扑噪声大、计算复杂度高(O (N²))、难以适配大规模场景的问题。MAGE 以 “少而精” 为理念,核心创新包括移除 ReLU 激活净化图拓扑、采用线性自适应图将复杂度降至 O (N),并设计稀疏平衡多专家结构突破线性低秩瓶颈。实验覆盖交通、能源、气象等 17 个真实数据集,MAGE 在 94% 指标上达最优,训练速度与内存占用均大幅优于主流模型,兼顾高精度与高效率,为大规模时空建模提供了新范式。
一、引言
1.1 时空预测:智慧城市与交通调度的核心挑战
在智慧城市、交通管理、能源调度、气象预测等关键场景中,时空预测(Spatiotemporal Forecasting) 始终是支撑智能决策的核心技术。它的目标是基于历史的多节点时间序列数据,预测未来一段时间内各节点的状态变化 —— 比如城市路网中未来 1 小时的交通流量、电力网络中不同节点的负载波动、或者城市各区域的气象数据变化。
这类任务的核心难点在于,数据同时包含时间维度的动态依赖(比如早晚高峰的周期性变化、突发拥堵的短期波动)和空间维度的关联依赖(比如主干道拥堵会影响周边支路、相邻区域的气象变化存在联动)。时空图神经网络(STGNN)凭借 “用图结构建模空间关联、用时序模块建模时间依赖” 的思路,成为这类任务的主流方案,也在多个场景中取得了不错的效果。但随着应用场景从小规模路网拓展到城市级、甚至跨城市的大规模场景,传统 STGNN 的短板也逐渐暴露出来。
1.2 传统时空图模型的两大痛点:拓扑不准与计算低效
在实际应用中,传统时空图模型面临着两个难以兼顾的核心问题:
-
图拓扑质量差,噪声放大问题突出:早期 STGNN 依赖地理距离、道路连通性等先验知识构建静态图拓扑,但真实场景中节点间的关联往往是隐式、动态变化的 —— 比如两条不直接连通的道路,也可能因为车流绕行形成强关联,静态图完全无法捕捉这类依赖。后续的自适应图学习方法,通过节点嵌入的内积动态学习图拓扑,试图解决这个问题。但这类方法普遍使用 ReLU 激活函数来过滤负相关边,却意外放大了噪声:原本微弱的噪声信号经过 ReLU 后会被强化,反而生成了大量无效的假边,破坏了图拓扑的可靠性,最终导致模型预测精度下降。
-
计算复杂度高,难以适配大规模场景:传统自适应图学习的核心瓶颈是节点数平方级的复杂度(O (N²))。对于城市级路网这类包含上万节点的大规模场景,O (N²) 的复杂度会导致模型训练时内存占用爆炸、推理速度极慢,甚至无法正常运行。虽然部分工作通过稀疏化、采样等方式降低复杂度,但又会损失模型的表达能力,无法兼顾效率与性能。
1.3 MAGE 的破局思路:线性自适应图 + 多专家结构,实现高效与性能双赢
为了同时解决 “拓扑不准” 和 “计算低效” 这两大痛点,论文提出了 MAGE(Mixture of Adaptive Graph Experts) 模型,以 “Less but More(少而精)” 为核心设计理念,用线性复杂度的自适应图学习,实现了比传统方法更优的预测性能。
MAGE 的核心破局思路可以概括为两点:
- 线性自适应图:解决拓扑噪声与复杂度问题:放弃传统自适应图中的 ReLU 激活函数,用纯线性的方式生成图拓扑,避免噪声放大问题;同时将复杂度从 O (N²) 降到 O (N),让模型能轻松适配大规模场景。
- 多专家自适应图模块:突破线性模型的低秩瓶颈:纯线性模型存在低秩瓶颈,表达能力不足。为此,MAGE 引入多专家自适应图结构,通过多个线性专家的组合,在保持线性复杂度的同时,大幅提升模型的表达能力;再搭配稀疏平衡机制,避免专家偏科,让每个专家都能学到有效的关联模式。
这套 “线性 + 多专家” 的设计,让 MAGE 在保持 O (N) 线性复杂度的同时,在 17 个真实数据集上实现了 94% 的最优性能,真正做到了 “高效不打折,性能再升级”。接下来我们将从模型架构的核心模块,一步步拆解 MAGE 的设计细节。
二、模型架构:线性自适应图的高效设计
2.1 整体框架:从联合建模到线性解耦的设计思路
MAGE 的整体设计,是对传统时空图神经网络(STGNN)的一次 “解耦重构”。传统 STGNN 往往将图拓扑学习与时空特征耦合在一起,导致复杂度居高不下且难以优化;而 MAGE 的核心设计理念,是将自适应图学习模块从时空建模中解耦出来,用线性结构保证效率,再通过多专家结构补足表达力。
模型的整体流程可以分为三步:
- 输入层:接收多节点的历史时间序列数据(如交通流量、气象数据);
- 线性自适应图学习:通过无 ReLU 的线性投影生成初始邻接矩阵,再由多专家模块增强表达力;
- 时空建模与融合:将线性图拓扑与时序特征结合,通过门控融合模块整合时空信息,输出预测结果。
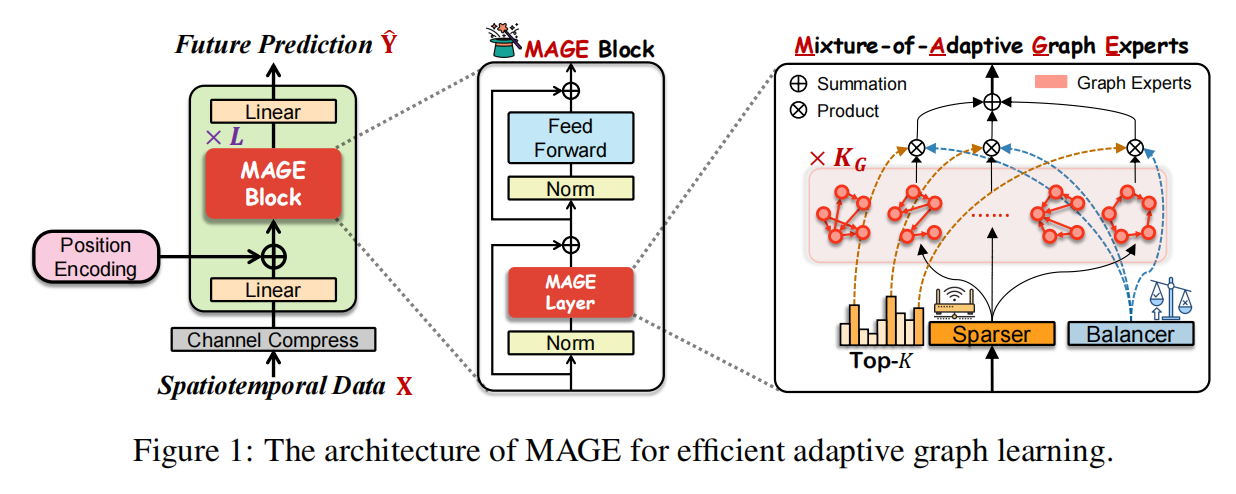
2.2 去 ReLU 的线性自适应图:净化拓扑、消除噪声放大
传统自适应图学习普遍依赖 ReLU 激活函数过滤无效边,但论文发现 ReLU 会放大微小噪声,生成大量虚假关联,严重降低图拓扑质量。
MAGE 的核心改进之一,就是直接移除 ReLU,用纯线性方式学习图结构。这样做能从根源避免噪声放大,生成更干净、更可靠的空间依赖关系,同时把计算复杂度从节点平方级降到线性级,显著提升效率。
2.3 多专家自适应图模块:突破线性模型的低秩瓶颈
纯线性自适应图虽然高效,但表达能力有限,存在低秩瓶颈,难以捕捉复杂动态依赖。
为解决这个问题,MAGE 引入多专家自适应图模块。它同时训练多个独立的线性图专家,每个专家专注学习一种空间关联模式,最后把所有专家的结果动态融合。多个专家组合后,模型表达能力大幅增强,有效突破单一低秩限制。
2.4 稀疏平衡机制:避免专家偏科,提升表达能力
多专家结构容易出现 “专家偏科” 问题:少数专家频繁被激活,多数专家闲置,导致资源浪费、表达单一。
为此,MAGE 设计稀疏平衡机制:
- 稀疏激活:每个节点只选择最相关的少量专家参与计算,减少冗余;
- 平衡约束:通过正则化让所有专家被均匀激活,避免冷热分化,确保每个专家都学到独特关联模式,整体表达更多样、鲁棒。
2.5 时空建模模块:线性图与时序特征的融合
得到高质量线性图结构后,模型进行时空特征融合:
- 空间建模:基于线性图拓扑聚合邻居节点信息,捕捉空间依赖;
- 时序建模:通过轻量级时序模块,捕捉时间维度的趋势与周期。
两者无缝融合,兼顾空间关联与时间动态,形成完整时空特征表示。
2.6 门控融合模块:动态整合时空特征,实现精准预测
把稀疏平衡的多专家图卷积与时序特征整合,形成完整 MAGE 层。模型通过动态权重融合不同专家输出,自适应选择最优空间依赖模式,同时保留线性高效优势,最终输出高质量时空特征,支撑精准预测。
三、实验结果与分析
3.1 实验数据集与实验结果
为全面验证 MAGE 的有效性,实验覆盖交通、能源、气象、移动通信四大领域、共 17 个真实数据集,包括大规模路网、电力负荷、空气质量、手机流量等不同场景。
对比模型涵盖多种主流时空模型:传统图模型、自适应图模型、线性基线、Transformer 类方法等,共 14 个先进模型。
评价指标采用时空预测通用标准:MAE(平均绝对误差)、RM(均方根误差)、MAPE(平均绝对百分比误差),数值越低表示预测精度越高。
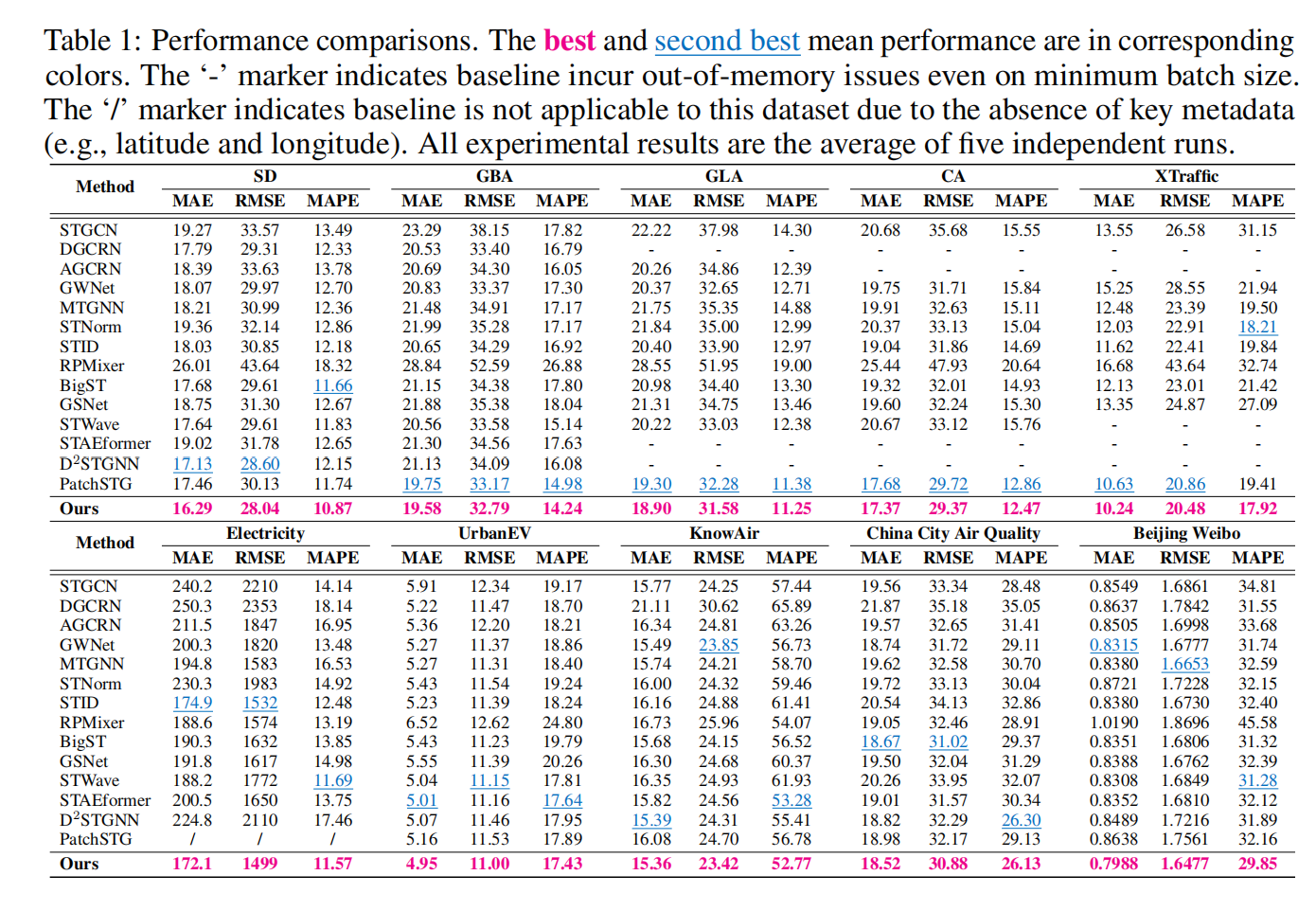
实验结果显示,MAGE 在 94%(51/53)指标上取得最优,在交通、能源、气象、移动通信等所有领域均大幅领先对比模型。
尤其在大规模数据集(如 GBA、GLA、CA、XTraffic)上,传统模型因内存限制无法运行,而 MAGE 依然保持高精度,充分证明其线性复杂度带来的大规模适配能力。
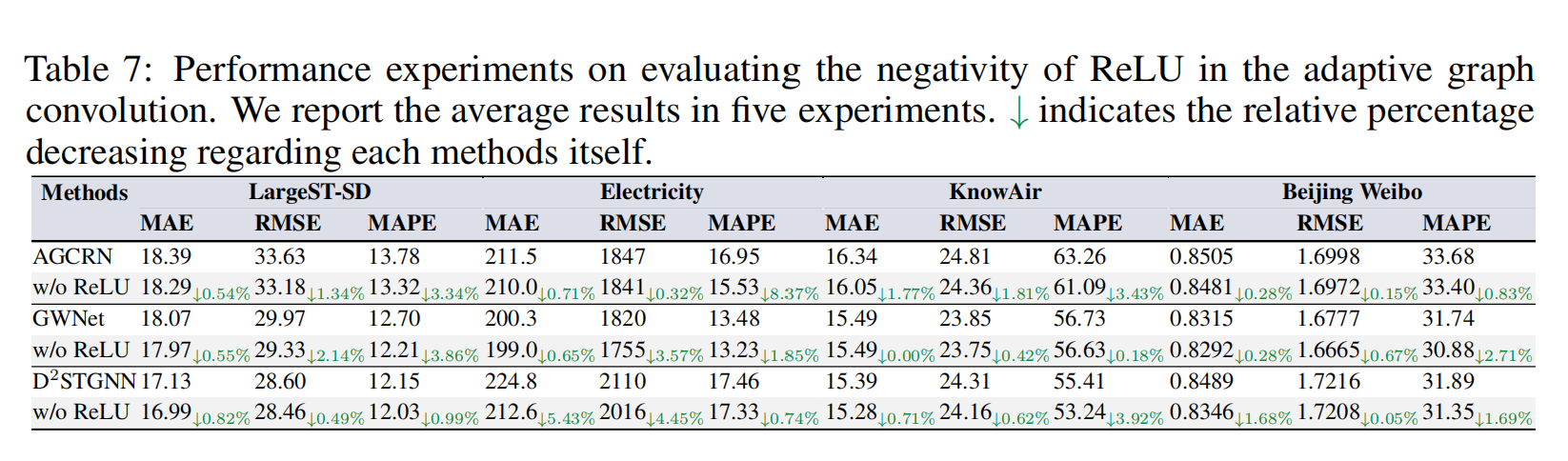
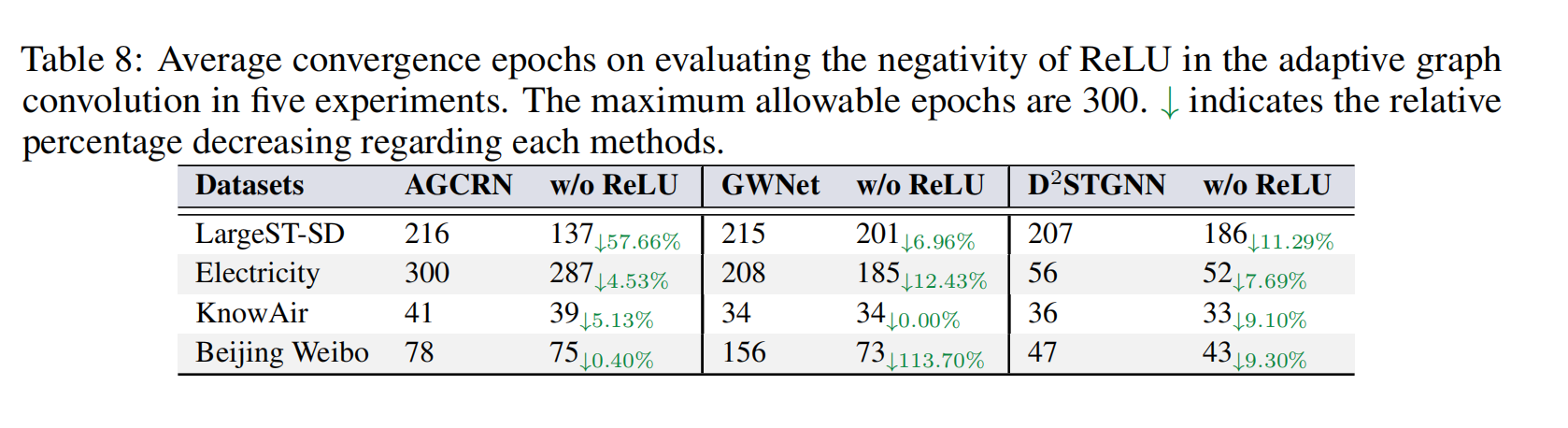
3.2 自适应线性图的有效性分析
论文通过对比有无 ReLU 的自适应图,验证线性图的优势:去掉 ReLU 后,所有模型精度均显著提升,证明 ReLU 确实放大噪声、破坏拓扑,而 MAGE 的线性图能生成更干净、可靠的空间依赖。
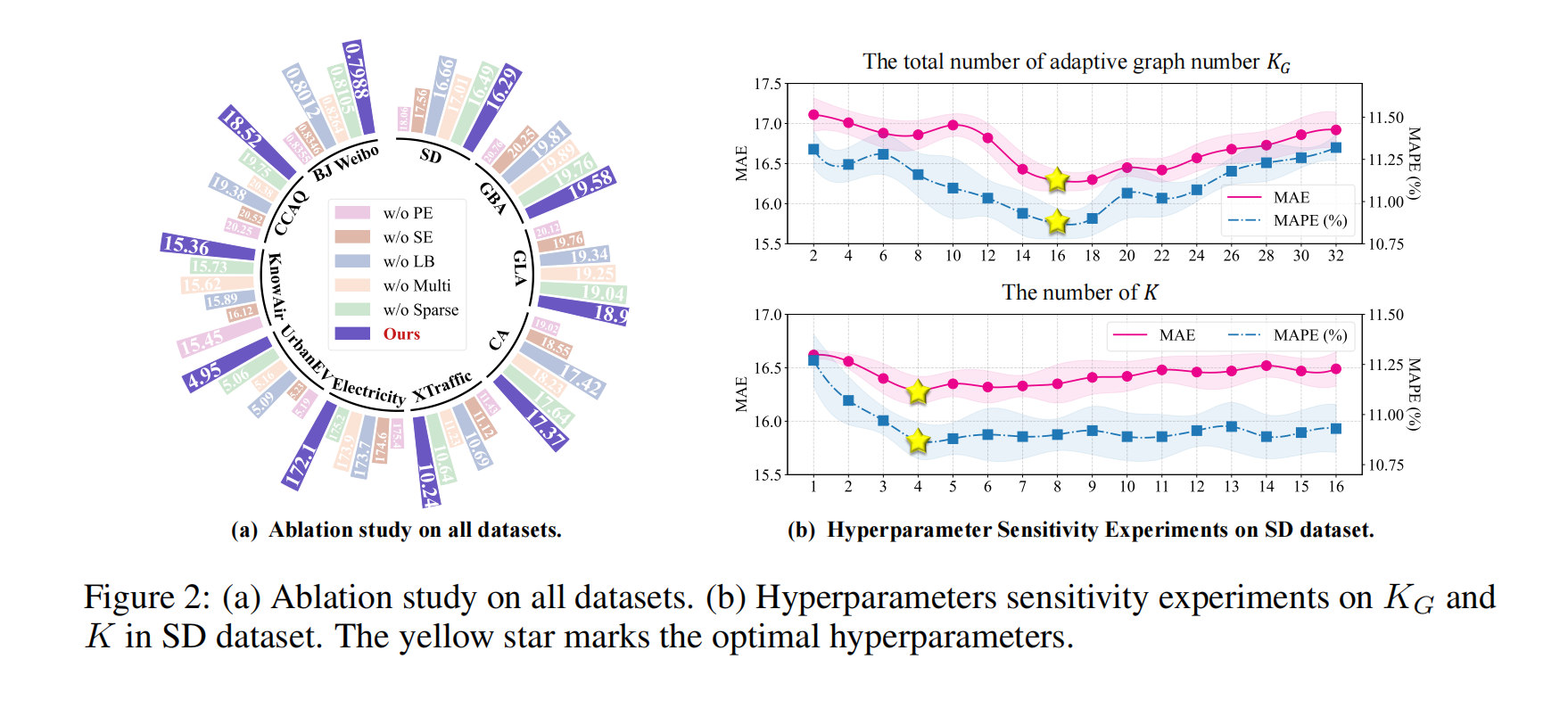
3.3 多专家模块的消融实验验证
消融实验显示:
- 去掉多专家(单专家):精度明显下降,证明多专家能显著提升表达力;
- 去掉稀疏激活:精度下降,说明稀疏能减少冗余;
- 去掉平衡机制:精度下降,证明平衡能避免专家偏科。
- 候选专家数 KG=16、激活专家数 K=4 时最优;
- 过大 / 过小均会导致精度下降,证明参数选择的合理性。
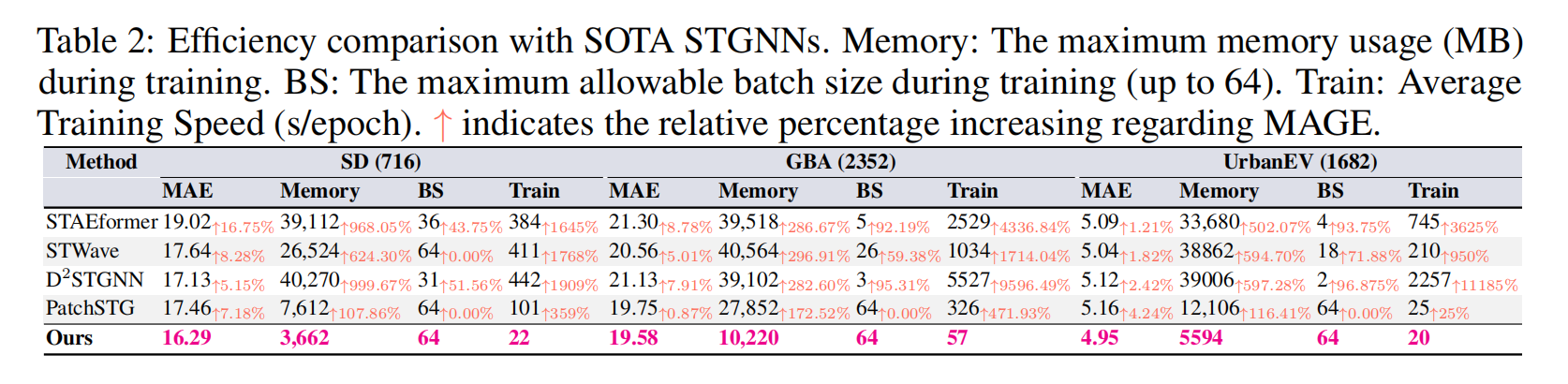
3.4 复杂度与效率分析:线性模型的性能优势
效率对比显示:
- MAGE 训练速度比 Transformer 类模型最高快 960 倍;
- 内存占用比基线模型低 1.72–10 倍;
- 上万节点数据集下,传统模型无法运行,MAGE 仍高效训练。
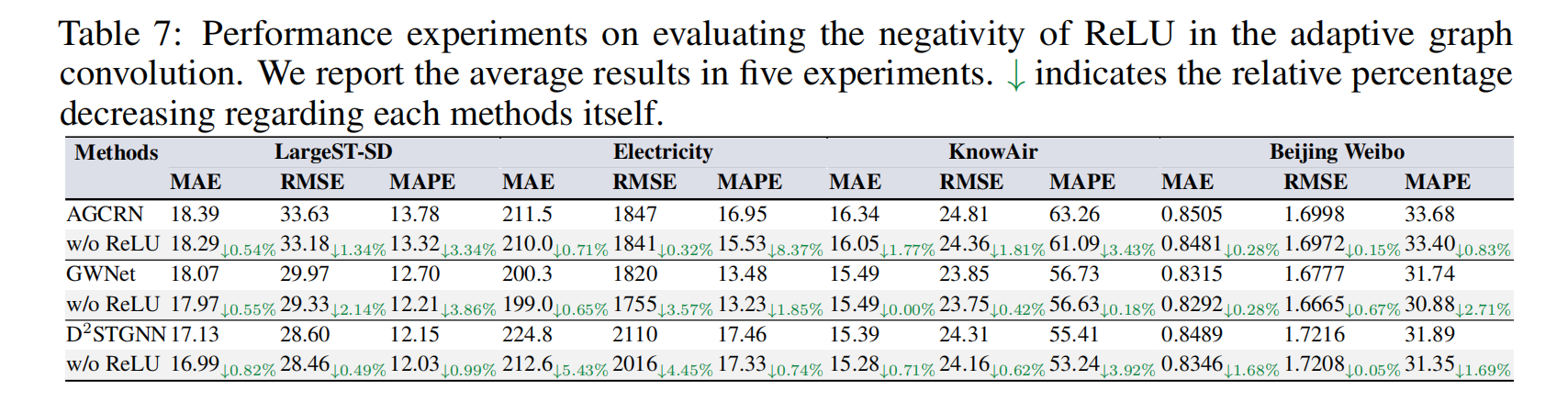
3.5 ReLU 影响验证:去噪带来的性能提升
进一步实验验证:
- ReLU 会放大边噪声,降低预测精度;
- 去掉 ReLU 后,模型收敛更快、精度更高。
四、总结与展望
4.1 工作总结
本文介绍了 MAGE(Mixture of Adaptive Graph Experts),一种面向时空预测的线性自适应图学习框架。
MAGE 的核心创新可以概括为三点:
- 去噪线性自适应图:移除传统 ReLU 激活,避免噪声放大,生成更可靠的空间依赖关系;
- 稀疏平衡多专家结构:用多个线性专家突破低秩瓶颈,兼顾高效与强表达力;
- 线性复杂度设计:把复杂度降到节点线性级别,支持上万节点的大规模时空场景。
在 17 个真实数据集、四大领域的实验中,MAGE 在 94% 的指标上达到最优,同时在速度、内存上全面优于现有模型,兼顾高精度、高效率和强通用性。
4.2 未来展望
虽然 MAGE 取得了很好的效果,但仍有进一步探索空间:
- 时序模块升级:当前时序建模较简单,后续可引入更强的时序模块,捕捉长期复杂依赖;
- 动态专家机制:让专家数量自适应变化,进一步降低冗余、提升效率;
- 轻量化部署:面向端侧设备,设计更小、更快的模型变体;
- 通用图任务拓展:把线性自适应图思路推广到节点分类、图预测等通用图任务。
总体来看,少即是多的设计思路在时空预测领域非常有效,线性化 + 多专家的组合为大规模时空建模提供了新的研究方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)