Transfomer的位置嵌入理解
·
Transformer的位置嵌入详解
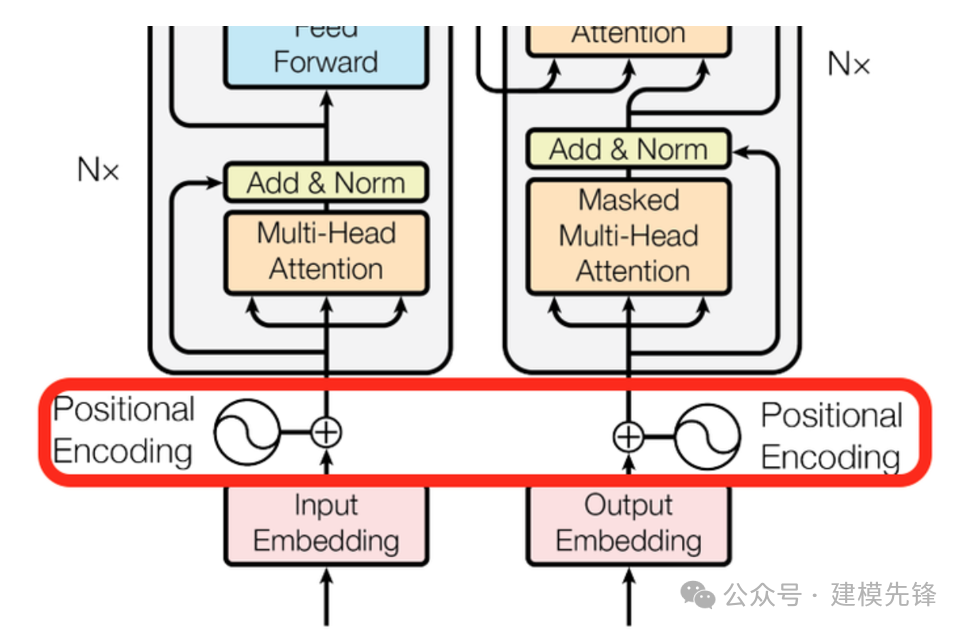
🎯 为什么需要位置嵌入?
核心问题:Transformer的自注意力机制本身是位置无关的
- 与RNN不同,Transformer并行处理所有token,没有天然的顺序概念
- 如果不加位置信息,"我爱你"和"你爱我"对模型来说是一样的
- 但在语言中,词序非常重要!
📍 "位置"怎么理解?
位置 = token在序列中的索引
句子: 我 爱 吃 苹果
位置: 0 1 2 3
就这么简单!位置就是每个词在句子中的排列顺序。
🔧 位置嵌入的工作原理
核心思路:为每个位置生成一个向量,与词向量相加
# 伪代码示例
token_embedding = [0.2, 0.5, 0.1, ...] # 词"苹果"的语义向量
position_embedding = [0.1, 0.3, 0.2, ...] # 位置3的位置向量
final_input = token_embedding + position_embedding
📊 两种主流方法
1️⃣ 固定正弦编码(原始Transformer)
PE(pos, 2i) = sin(pos / 10000^(2i/d))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d))
- ✅ 不需要训练
- ✅ 可处理任意长度序列
- 使用不同频率的正弦/余弦波
2️⃣ 可学习位置嵌入(BERT等)
position_embeddings = Embedding(max_length=512, d_model=768)
- ✅ 可以学到更适合任务的位置表示
- ❌ 受限于最大序列长度
💡 直观例子
输入句子:"猫 吃 鱼"
位置0: "猫" = [词向量_猫] + [位置向量_0]
位置1: "吃" = [词向量_吃] + [位置向量_1]
位置2: "鱼" = [词向量_鱼] + [位置向量_2]
# 如果是"鱼 吃 猫"
位置0: "鱼" = [词向量_鱼] + [位置向量_0] ← 注意!向量不同了
🎓 关键要点
- 位置 = 序列索引(0, 1, 2…)
- 位置嵌入 = 把位置编码成向量
- 目的 = 让模型知道词的先后顺序
- 方式 = 加到词向量上,一起输入模型
这样Transformer就既知道"这是什么词"(词嵌入),又知道"词在哪里"(位置嵌入)了!
图像Transformer的位置编码详解
🖼️ 图像 vs 文本:位置的区别
| 维度 | 文本 | 图像 |
|---|---|---|
| 空间结构 | 一维序列 | 二维平面 |
| 位置表示 | 0, 1, 2, 3… | (行, 列) |
| 顺序重要性 | 强依赖顺序 | 空间邻近关系 |
📐 图像如何变成"序列"?
步骤1:图像分块(Patching)
原始图像 224×224 像素
↓ 分成 16×16 的 patches
得到 14×14 = 196 个 patches
可视化示例:
原图: 分块后:
┌─────────┐ ┌─┬─┬─┬─┐
│ │ │1│2│3│4│ ← 每个小块是一个patch
│ 🐱 │ → ├─┼─┼─┼─┤
│ │ │5│6│7│8│
└─────────┘ └─┴─┴─┴─┘
步骤2:展平成序列
二维排列: 一维序列:
┌──┬──┬──┐
│ 0│ 1│ 2│ [0, 1, 2, 3, 4, 5, 6, 7, 8]
├──┼──┼──┤ →
│ 3│ 4│ 5│ 但要记住它们的2D位置!
├──┼──┼──┤
│ 6│ 7│ 8│
└──┴──┴──┘
🎯 图像中的"位置"是什么?
位置 = 每个patch在图像中的空间坐标
# 示例:3×3的patch网格
Patch 0: 位置 = (行0, 列0) - 左上角
Patch 1: 位置 = (行0, 列1) - 上方中间
Patch 4: 位置 = (行1, 列1) - 正中心
Patch 8: 位置 = (行2, 列2) - 右下角
🔧 Vision Transformer (ViT) 的位置编码方法
方法1: 1D位置编码(ViT原始论文)
# 简单地按顺序编号
patches = [patch_0, patch_1, ..., patch_195]
position_ids = [0, 1, 2, ..., 195]
# 每个位置学习一个向量
position_embedding = Embedding(196, 768)
✅ 简单有效
⚠️ 忽略了2D空间结构
方法2: 2D位置编码(更符合直觉)
# 分别编码行和列
for i in range(14): # 行
for j in range(14): # 列
pos_embed = row_embed[i] + col_embed[j]
方法3: 相对位置编码
- 编码patch之间的相对距离
- 例如:patch_4 和 patch_5 是"水平相邻"
💡 直观例子
输入图像:一只猫的照片 (224×224)
步骤1️⃣ 分成 196 个 patches (14×14 网格)
┌────┬────┬────┬────┐
│耳朵│耳朵│ 空 │ 空 │ ← patches 0-3
├────┼────┼────┼────┤
│眼睛│鼻子│眼睛│ 空 │ ← patches 4-7
├────┼────┼────┼────┤
│ 嘴 │ 嘴 │ 嘴 │ 空 │ ← patches 8-11
└────┴────┴────┴────┘
步骤2️⃣ 每个patch加上位置信息
patch_5 (鼻子) = [图像特征] + [位置向量_5]
↑
告诉模型:这是第1行第1列
(即图像中心偏左上的位置)
步骤3️⃣ 送入Transformer
模型既知道"这是鼻子"(内容)
又知道"在脸部中心"(位置)
🆚 关键对比
| 特性 | 文本位置 | 图像位置 |
|---|---|---|
| 含义 | 词在句子中的顺序 | Patch在图像中的空间坐标 |
| 打乱影响 | 完全改变语义 | 破坏空间结构 |
| 例子 | 位置3表示"第4个词" | 位置(2,3)表示"第2行第3列" |
📊 位置编码的作用
没有位置编码:
模型看到 [天空, 草地, 猫],但不知道谁在上谁在下
有了位置编码:
模型知道 天空(上方) → 猫(中间) → 草地(下方)
理解出正确的空间布局!
🎓 核心要点
- 图像位置 = Patch的2D坐标(虽然常简化为1D)
- 分块是关键:先把图像切成小块
- 保留空间信息:让模型知道每个patch来自图像的哪个区域
- 与文本类比:
- 文本:词的先后
- 图像:块的上下左右
为什么重要?
如果没有位置编码,同样的patches打乱顺序后,模型会给出相同的结果——但一只猫和一堆散乱的猫碎片可完全不同!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)