SinSR:基于扩散的单步图像超分辨率(SinSR: Diffusion-Based Image Super-Resolution in a Single Step)
摘要
基于扩散模型的超分辨率(SR)方法具有良好的效果,但其实际应用受到大量推理步骤的限制。最近的方法利用初始状态下的退化图像,从而缩短马尔可夫链。然而,这些解决方案要么依赖于精确的退化过程公式,要么仍然需要相对较长的生成路径(例如,15次迭代)。为了提高推理速度,我们提出了一种简单而有效的方法来实现单步SR生成,称为SinSR。具体地说,首先,我们从最新的用于加速基于扩散的SR的最先进的(SOTA)方法导出确定性采样过程。分辨率的图像,以获得在减少和可接受的推理步骤数在训练过程中。我们表明,这种确定性的映射可以提炼成一个学生模型,执行SR在只有一个推理步骤。此外,我们提出了一种新的一致性保持损失以在蒸馏过程中同时利用地面实况图像,确保学生模型的性能不仅仅受教师模型的特征流形的约束,在合成的和真实的-世界数据集表明,与先前的SOTA方法和教师模型相比,所提出的方法可以在仅一个采样步骤中实现相当的或甚至上级的性能,从而导致推理速度显著提高到10倍。
我们的主要贡献总结如下:
(1)我们将基于扩散的SR模型加速到一个具有可比甚至上级性能的单一推理步骤,而不是缩短生成过程的马尔可夫链,我们提出了一种简单而有效的方法,直接将确定性生成函数提取到学生网络中。
(2)为了进一步加快训练,我们从最近的SOTA方法[46]中推导出一种确定性采样策略来加速SR任务,从而能够有效地生成匹配良好的训练对。
(3)我们提出了一种新的一致性保持损失,可以在训练过程中利用地面实况图像,防止学生模型只专注于拟合教师扩散模型的确定性映射,从而获得更好的性能。
(4)在合成数据集和真实数据集上的大量实验表明,与SOTA方法和教师扩散模型相比,我们提出的方法可以实现相当甚至上级的性能,同时将推理步骤的数量从15个大大减少到1个。
1、 数据集和代码
1.1 代码
https://github.com/wyf0912/SinSR/
1.2 数据集
采用RealSR [3]和RealSet65 [46]来评估模型对不可见真实世界数据的泛化能力。具体来说,在RealSR [3]中,有100张不同场景下由两个不同相机拍摄的真实的图像。此外,RealSet65 [46]总共包括65张LR图像,从广泛使用的数据集和互联网上收集。
2.1 扩散模型存在的问题
目前采用扩散模型的策略可以大致分为两类:将LR图像连接到扩散模型中的去噪器的输入,并调整预训练扩散模型的逆过程。尽管实现了有希望的结果,但这两种策略都遇到了计算效率问题。值得注意的是,这些条件扩散模型的初始状态是一个纯高斯噪声,而没有利用LR图像的先验知识,因此需要大量的推理步骤来获得令人满意的性能,这严重阻碍了基于扩散的SR技术的实际应用。
2.2 文章发现的问题
人们一直在努力提高扩散模型的采样效率,从而提出了各种技术。然而,在保持高保真度至关重要的低水平视觉领域,这些技术往往不够,因为它们以性能为代价实现加速。最近,出现了创新技术来重新制定图像恢复任务中的扩散过程,着重于提高初始扩散状态的信噪比,从而缩短马尔可夫链。
例如,[43]用输入噪声图像启动去噪扩散过程,而在SR任务中,[46]将初始步骤建模为LR图像和随机噪声的组合。尽管如此,即使在这些最新的作品中[43,46],局限性仍然存在。例如,虽然[43]在三个推理步骤中显示了有希望的结果,它需要图像退化过程的清晰公式。此外,[46]仍然需要15个推理步骤,并且如果推理步骤的数量进一步减少,则表现出明显的伪影的性能下降。
2.2 图像超分辨率的问题
基于扩散的SR方法可以大致概括为两类,将LR图像连接到去噪器的输入,以及修改预先训练的扩散模型的向后过程。虽然取得了有希望的结果,但它们依赖于大量的推理步骤,这极大地阻碍了基于扩散的模型的应用。
2.3 扩散模型的加速
针对一般扩散模型提出了几种算法,并且被证明对于图像生成非常有效。其中一种直观的策略是将扩散模型提取为学生模型。然而,求解的巨大训练开销推理过程的常微分方程(ODE)使得该方案在大规模数据集上不那么有吸引力。为了减轻训练开销,通常采用渐进蒸馏策略。同时,不是简单地通过蒸馏模拟教师扩散模型的行为,而是以迭代方式探索更好的推理路径,虽然渐进蒸馏有效地降低了训练开销,但同时误差累积,导致SR的明显性能损失。最近,针对图像恢复任务,一些作品通过使用退化过程的知识或初始状态的预定义分布来重新制定扩散过程,产生生成过程的缩短的马尔可夫链,并且比在低级任务中直接应用DDIM 具有更好的性能。然而,它们要么需要明确的降级公式,要么仍然需要相对大量的推理步骤。
3、提出的创新点
3.1 提出的方法
为了解决这些挑战,我们引入了一种新的方法,该方法可以在仅一个采样步骤中生成高分辨率(HR)图像,而不会损害扩散模型的多样性和感知质量。我们建议直接学习一个配对良好的双-输入随机噪声和从教师扩散模型生成的HR图像之间的方向确定性映射。为了加速良好匹配的训练数据的生成,我们首先从最新的最先进的工作[46]中推导出一种确定性采样策略,其设计用于加速基于扩散的SR,从其原始的随机公式。此外,我们提出了一种新的一致性保持损失来利用地面实况图像,通过最大限度地减少地面实况(GT)之间的误差,进一步增强生成的HR图像的感知质量图像和从预测的初始状态生成的图像。实验结果表明,与SOTA方法和教师扩散模型[46]相比,我们的方法实现了相当甚至更好的性能,同时将推理步骤从15步减少到1步,从而使推理速度提高了10倍。
3.2 动机
初始状态为 xT∼N(0,I)。扩散模型的作用可以看作是在低分辨率图像 y的条件下,将输入域(标准高斯噪声)转换到高分辨率图像域。由于 xT与 x0之间的匹配关系未知,通常需要一个扩散模型 通过迭代方式学习/推断 xT 与 x0之间的未知映射。
我们的方法基于以下思想:给定低分辨率图像 y,如果有一个 SR 模型能够有效捕捉条件分布 q(x0∣y),并建立 xT 与x^0 之间的确定性映射,那么我们可以通过另一个网络fθ^ 来学习 x^0 与 xT 之间的对应关系,从而将推理过程简化为单步,如图 3 所示。
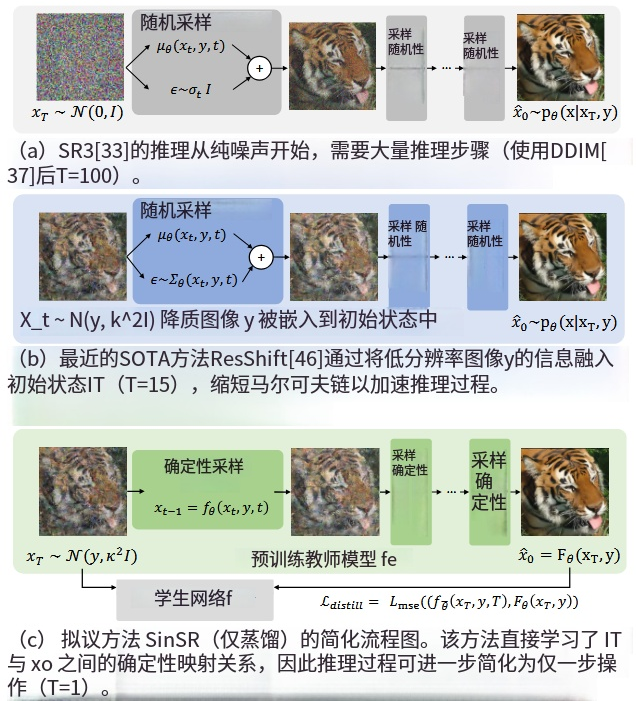
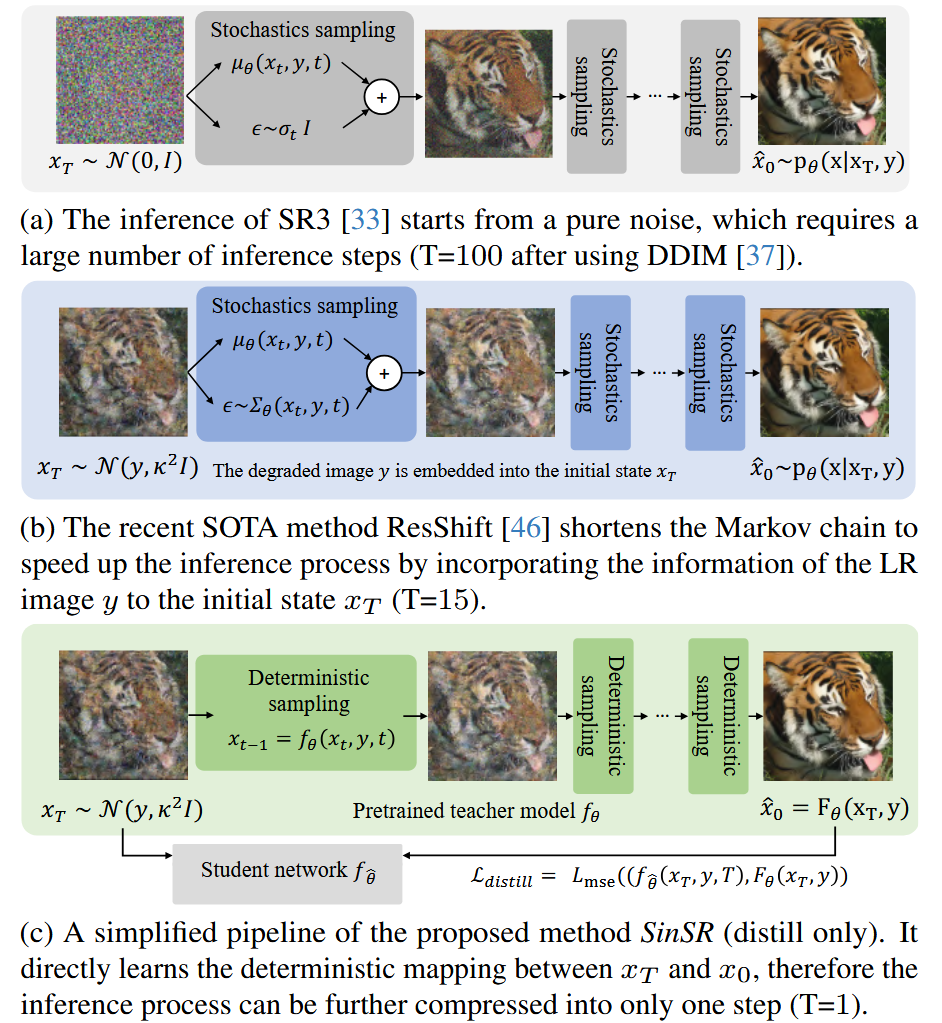
图3.基于扩散的SR方法[33](一种最新的基于扩散的SR [46]加速方法)与所提出的单步SR之间的比较。与最近缩短马尔可夫链以加速推理过程的工作不同[43,46],所提出的方法直接学习确定性生成过程,细节可以在图4中找到。
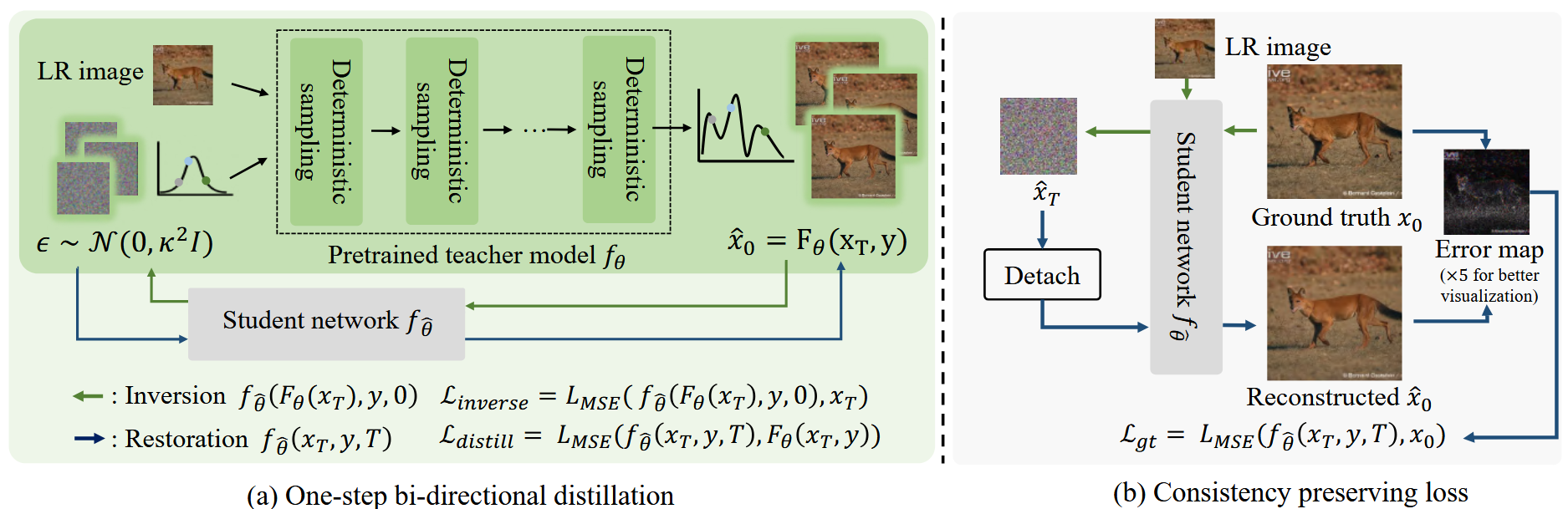
图4.所提出方法的总体框架。通过最小化Ldistill和Linverse,学生网络fθ一步学习从预先训练的教师扩散模型中获得的xT和x 0之间的确定性双向映射。同时,提出的一致性保留损失Lgt在训练期间进行优化,以利用来自GT图像的信息来追求更好的感知质量,而不是简单地拟合具体地,GT图像首先被转换成其潜码x <$T = fθ <$(x 0,y,0),然后被转换回以计算其重构损失LMSE(fθ <$(x <$T,y,T),x 0)。
3.3 具体方法
3.3.1 确定性采样
ResShift [46]和LDM [32]之间的核心差异是初始状态xT的公式化。具体地,在ResShift [46]中,来自LR图像y的信息被如下积分到扩散步骤xt中
![]()
其中ηt是一系列超参数,其随着时间步长t单调增加并且服从ηT → 1和η0 → 0。因此,扩散过程的逆过程从具有来自LR图像y的丰富信息的初始状态开始,如下:xT = y + κ ∈ ηT ε其中ε ∈ N(0,I)。为了从给定图像y生成HR图像x,[46]的原始逆过程如下
![]()
其中μθ(xt,y,t)由深度网络重新参数化。如等式2所示,给定初始状态xT = y + κ ηT ε,由于在从pθ(xt-1)采样期间存在随机噪声,所以所生成的图像是随机的|受DDIM采样[37]的启发,我们发现一个非马尔可夫逆过程q(xt-1| xt,x 0,y)存在,其保持边际分布q(xt| x 0,y)不变,因此为了便于呈现,LR图像y被预上采样到与HR图像x相同的空间分辨率。此外,类似于[32,46],扩散在潜在空间中进行。它可以直接用于预训练模型。重新制定的确定性反向过程如下
![]()
其中δ是单位冲量,kt、mt、jt如下
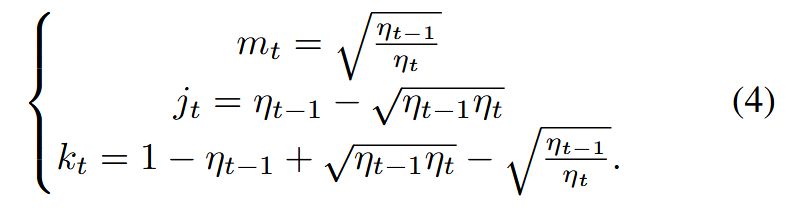
推导的细节可以在补充材料中找到。因此,对于推理,以y为条件的逆过程重新表述如下
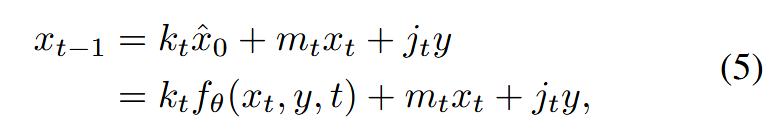
其中fθ(xt,y,t)是来自预训练ResShift [46]模型的预测HR图像。通过从公式5中的重新公式化过程中采样,可以获得xT(或ε)和x 0之间的确定性映射,并表示为Fθ(xT,y)。
3.3.2 一致性保持蒸馏
香草蒸馏。我们建议利用学生网络fθ从教师扩散模型学习随机初始化状态xT与其确定性输出Fθ(xT,y)之间的确定性映射Fθ。香草蒸馏损失定义如下
![]()
其中fθ(xT,y,T)是仅在一步中直接预测HR图像的学生网络,Fθ表示第4.1节中ResShift [46]通过使用预训练的迭代方式提出的确定性推理过程我们观察到,仅用等式6中的蒸馏损失训练的学生模型已经在仅一个推理步骤中实现了有希望的结果,如结果表中的“(仅蒸馏)”所示。
通过地面真实图像进行正则化。上述香草蒸馏策略的局限性在于在训练期间不使用GT图像,从而限制了学生模型的性能上限。为了进一步提高学生的性能,我们提出了一种新的策略,该策略结合了HR图像的学习反演,以从地面实况图像提供额外的正则化。蒸馏损失,学生网络通过最小化以下损失在训练期间同时学习逆映射,
![]()
其中,fθ τ的最后一个参数从等式6中的T设置为0,指示模型预测反演而不是x θ τ 0。然后,给定其预测反演x θ τ T,GT图像x0可以用于正则化输出SR图像,如下所示
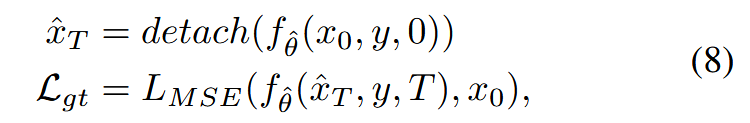
其中Lgt是建议的一致性保持损失。通过重用fθ同时学习fθ(·,·,T)和fθ(·,·,0),我们可以从教师模型的参数θ初始化学生模型的参数θ,以加快训练速度。
总体训练目标。学生网络被训练为同时最小化上述三种损失,如下所示
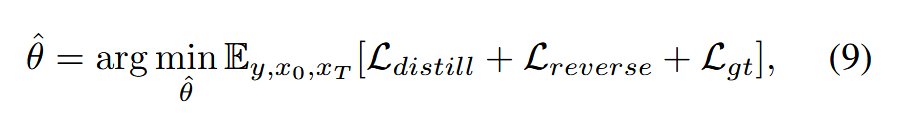
其中损失分别在公式6、7和8中定义。我们为每个损失项分配相等的权重,并且消融研究在补充材料中。算法1和图4中总结了所提出的方法的总体。
4、结论与不足
在本文中,我们提出一种新的策略来加速基于扩散的SR模型到一个单一的推理步骤.具体地说,我们提出了一个一步双向蒸馏来学习输入噪声和生成的高分辨率图像之间的确定性映射,反之亦然,从一个教师扩散模型与我们导出的确定性采样.同时,在提取过程中同时优化了一种新的一致性保持损失,使得学生模型不仅利用了来自预先训练的教师扩散模型的信息,而且直接从地面学习。实验结果表明所提出的方法仅需一步就能达到与教师模型相当甚至更好的性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)