从零开始学AI16——SVM
摘要:支持向量机(SVM)是一种基于"最大间隔"原则的分类算法,其核心思想是寻找能最大化分类间隔的超平面。SVM通过支持向量(离分界线最近的关键数据点)确定决策边界,具有鲁棒性强、适合小样本和高维数据的特点。对于非线性可分数据,SVM使用核函数将数据映射到高维空间实现分割。本文通过军事比喻直观解释了SVM原理,详细推导了数学公式,并提供了Python实现代码,展示了SVM在非线性数据上的分类效果。SVM特别适用于文本分类、生物信息学等场景,但在大数据量时计算效率较低。
简单理解
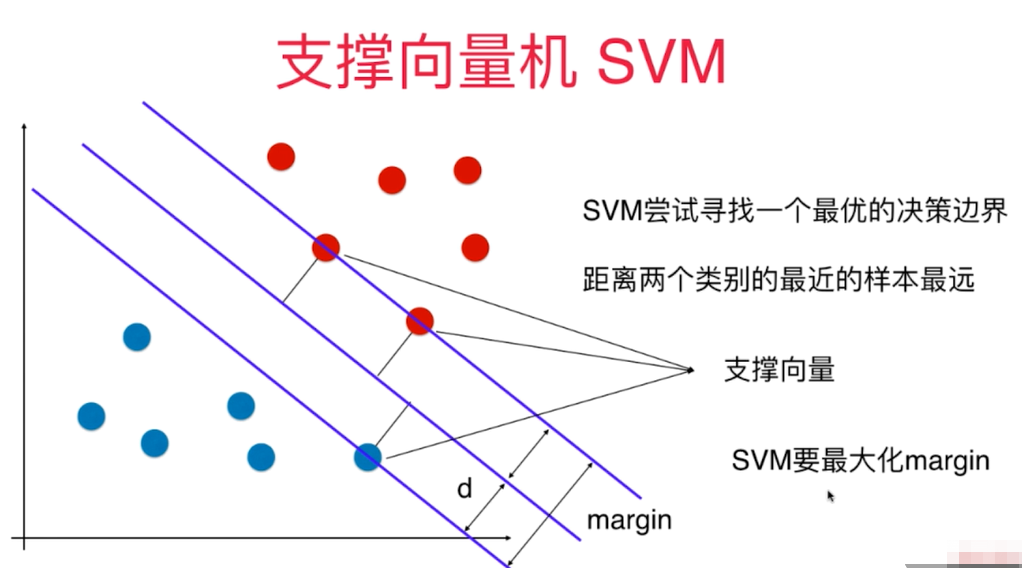
支持向量机 (SVM),名字听起来超级高大上,其实它的核心思想只有三个字:“找宽路”。
如果说逻辑回归是“画一条线把两类人分开”,那么 SVM 就是**“画一条最宽的路把两类人彻底隔开”**。
我们用**“楚河汉界”**的打仗故事来比喻。
1. 核心目标:不光要分得开,还要分得稳
假设你面前有一张地图,上面有两支军队:
- 红军(正样本): 聚集在左下角。
- 蓝军(负样本): 聚集在右上角。
你的任务是:在地图上画一条“停火线”,把两军分开。
-
普通算法(比如感知机):
随便画一条线,只要红军都在左边,蓝军都在右边就行。- 隐患: 如果这条线紧贴着红军的帐篷画,万一红军有个士兵晚上起夜多走了一步,就过界了(被误判成蓝军)。这叫泛化能力差。
-
SVM(支持向量机):
它不仅要画一条线,它还要修一条最宽的马路(间隔 Margin)。- 这条马路的中线,就是最终的分类界线。
- 马路越宽,红军和蓝军离界线就越远,哪怕大家稍微乱跑一点,也不会轻易过界。这就叫鲁棒性好,不容易出错。
2. 谁是“支持向量” (Support Vector)?
在修这条最宽马路时,并不是所有的士兵都重要。
- 在大后方喝茶的士兵(离前线很远的点),根本不影响马路怎么修。
- 只有最前线、最靠近敌人的那几个士兵,才决定了马路的边界在哪里。
这几个决定马路宽度的关键士兵,就叫**“支持向量”**。
SVM 的名言:
“我眼里只有那几个关键人物(支持向量),其他几千几万个普通数据,我根本不在乎。”
(这也是为什么 SVM 即使数据量很大,计算也比较快,因为它只看关键点。)
3. 如果直线分不开怎么办?(核函数 Kernel Trick)
上面的情况是红蓝两军泾渭分明。但如果情况是这样的:
- 红军被包围在地图中间。
- 蓝军围成一个圈,把红军包在里面。
这时候,你在纸上画任何一条直线,都切不开它们。SVM 怎么办?
SVM 的绝招:升维打击(核函数)。
想象这不仅是一张平面的纸,而是一张有弹性的桌布。
- SVM 猛地一拍桌子底下(红军所在的位置)。
- 红军(中间的点)被震飞到了空中。
- 蓝军(周围的点)还在桌面上。
现在,红军在空中,蓝军在地上。SVM 只要拿一块平板(超平面),在空中横着切过去,就能完美地把红军和蓝军分开了!
- 在二维(纸面)看: 分界线是一个圈。
- 在三维(空中)看: 分界线是一个平面。
这就是核函数的作用:把低维分不开的数据,映射到高维空间,用一个平面切开。
总结
- SVM 做什么? 找一条最宽的分界线(最大间隔)。
- 什么是支持向量? 离分界线最近的、决定路有多宽的那几个关键数据点。
- 分不开咋办? 用核函数把数据扔到高维空间,进行降维打击。
应用场景
SVM 曾经是机器学习界的“扛把子”(在深度学习爆发之前),因为它数学理论优美、泛化能力强、且适合小样本。即使在今天,在很多特定场景下,SVM 依然比神经网络更好用。
SVM 的应用场景主要取决于它的两大特性:
- 适合小样本、高维度: 不需要几万张图,几百个样本就能训练出不错的模型。
- 二分类专家: 虽然能做多分类,但本质上最擅长做“是/否”的判断。
以下是 SVM 的经典应用场景:
1. 文本分类 (Text Categorization) —— 王牌主场
这是 SVM 最擅长的领域,甚至在很多轻量级任务上优于深度学习。
- 场景: 垃圾邮件识别、新闻分类(体育/财经/政治)、情感分析(好评/差评)。
- 原因: 文本数据转化为向量(如 TF-IDF)后,维度极高(几万个词汇特征),且大多是稀疏的。SVM 的**线性核(Linear Kernel)**处理高维稀疏数据非常快,且不容易过拟合。
- 例子: 判断一封邮件是不是 Spam(垃圾邮件)。
2. 图像识别 (Image Recognition) —— 曾经的王者
在 CNN(卷积神经网络)流行之前,SVM 是做图像分类的标准配置。
- 场景: 人脸识别、手写数字识别(MNIST)、行人检测。
- 做法: 通常配合 HOG(方向梯度直方图)等特征提取算法。先提取图像特征,再扔给 SVM 分类。
- 现状: 虽然现在被 CNN 取代了,但在样本非常少(比如只有几张样品图)的工业缺陷检测中,SVM 依然活跃。
3. 生物信息学 (Bioinformatics)
这是 SVM 目前依然占据统治地位的领域之一。
- 场景: 蛋白质结构预测、基因分类、癌症诊断。
- 原因:
- 样本极少: 只有几十个病人的数据。
- 维度极高: 每个病人有上万个基因测序点。
- 这正是 SVM 最喜欢的“宽路”逻辑——在极少的数据中找到最稳健的规律。
4. 异常检测 (Anomaly Detection)
- 场景: 机器故障预测、信用卡欺诈检测。
- 变种算法: One-Class SVM。
- 原理: 训练时只有“正常数据”。One-Class SVM 会在正常数据周围画一个圈(超球面)。新数据来了,只要落在圈外,就是异常。这比简单的阈值判断要精准得多。
SVM 什么时候不好用?(避坑指南)
- 数据量巨大(几十万以上):
- 原因: SVM 需要计算两两样本之间的关系(核矩阵),计算复杂度接近 O(N2)O(N2)。数据量一大,内存爆炸,训练极慢。这时候请用神经网络或 LightGBM。
- 噪声极多(数据重叠严重):
- 原因: SVM 试图找一个“完美间隔”。如果数据里有很多脏数据(标错的签、乱跑的点),SVM 会为了容忍这些点而把间隔弄得很窄,或者过拟合。
- 多分类问题:
- 原因: SVM 本质是二分类。做多分类(比如分10类)需要训练 10 个 SVM(一对多)或者 45 个 SVM(一对一),效率低且麻烦。
一句话总结
如果你手里数据不多(几百几千条),但特征很多(几千几万维),且对模型的解释性和稳定性有要求,SVM 是首选。
数学推导
SVM 的数学推导涉及了几何间隔、拉格朗日乘子法、对偶问题、KKT 条件等一系列高等数学概念。
把推导过程简化为三个核心阶段:
- 原问题 (Primal):把“找最宽路”翻译成数学公式。
- 转化 (Transform):利用拉格朗日乘子法,把有约束问题变成无约束问题。
- 对偶问题 (Dual):为了引入核函数,把问题换个角度解。
第一阶段:原问题 —— 定义“最宽间隔”
我们有一个分类超平面:wTx+b=0wTx+b=0。
- ww:法向量,决定平面的方向。
- bb:截距,决定平面的位置。
1. 怎么判断分得好不好?
对于任意一个样本 (xi,yi)(xi,yi)(yiyi 取 +1 或 -1):
- 如果 wTxi+b>0wTxi+b>0,预测为 +1。
- 如果 wTxi+b<0wTxi+b<0,预测为 -1。
为了统一,我们要让 yi(wTxi+b)≥1yi(wTxi+b)≥1。
(为什么要 ≥1≥1 而不是 ≥0≥0?为了给中间留出一条宽度)
2. 间隔(Margin)有多宽?
根据点到直线的距离公式,支持向量(离线最近的点)到超平面的距离是 1∣∣w∣∣∣∣w∣∣1。
那么总的马路宽度(几何间隔)就是:
Width=2∣∣w∣∣Width=∣∣w∣∣2
3. 我们的目标:
我们要让宽度 2∣∣w∣∣∣∣w∣∣2 最大化。
这等价于让 12∣∣w∣∣221∣∣w∣∣2 最小化(为了方便求导,把分母倒过来并平方)。
最终优化的数学模型(原问题):
minw,b12∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,...,mw,bmin21∣∣w∣∣2s.t.yi(wTxi+b)≥1,i=1,...,m
s.t. 是 subject to(受限于),也就是所有的点必须在马路两边,不能在马路上。
第二阶段:拉格朗日乘子法 —— 消除约束
这是一个带约束的凸优化问题。为了去掉那个讨厌的 s.t.s.t.,我们引入拉格朗日乘子 αiαi(每个样本对应一个 αi≥0αi≥0)。
构造拉格朗日函数 L(w,b,α)L(w,b,α):
L(w,b,α)=12∣∣w∣∣2−∑i=1mαi[yi(wTxi+b)−1]L(w,b,α)=21∣∣w∣∣2−∑i=1mαi[yi(wTxi+b)−1]
现在的目标变成了“极小极大”问题:
minw,bmaxαL(w,b,α)minw,bmaxαL(w,b,α)
第三阶段:对偶问题 (Dual Problem) —— 为了核函数
根据对偶性(Slater条件满足时),我们可以交换 min 和 max 的顺序,把问题变成更容易解的对偶问题:
maxαminw,bL(w,b,α)maxαminw,bL(w,b,α)
步骤 1:先对 ww 和 bb 求偏导,并令其为 0(求内层的 min)。
- ∂L∂w=w−∑αiyixi=0 ⟹ w=∑i=1mαiyixi∂w∂L=w−∑αiyixi=0⟹w=∑i=1mαiyixi
(这一步非常重要!它告诉我们最佳的 ww 其实就是样本向量的线性组合。) - ∂L∂b=−∑αiyi=0 ⟹ ∑i=1mαiyi=0∂b∂L=−∑αiyi=0⟹∑i=1mαiyi=0
步骤 2:把求出的 ww 代回原式 LL。
经过一通复杂的代数运算(消去 ww 和 bb),我们得到了只包含 αα 的最终公式:
maxα[∑i=1mαi−12∑i=1m∑j=1mαiαjyiyj(xiTxj)]s.t.∑i=1mαiyi=0,αi≥0αmax[i=1∑mαi−21i=1∑mj=1∑mαiαjyiyj(xiTxj)]s.t.i=1∑mαiyi=0,αi≥0
这就是 SVM 的最终形态!
观察这个公式的两个神奇之处:
- 没有 ww 和 bb 了: 我们只需要解出 αα。解出来后,大部分 αiαi 都是 0,只有少数 αi>0αi>0,这些对应的样本就是支持向量。
- 内积出现: 公式里唯一的计算量在于 xiTxjxiTxj(两个样本的内积)。
- 这就意味着,我们可以直接把 xiTxjxiTxj 替换成核函数 K(xi,xj)K(xi,xj)!
- 这就是为什么 SVM 可以轻松引入核函数的原因。
第四阶段:求解与决策
- 解 αα: 使用 SMO (Sequential Minimal Optimization) 算法解出最优的 αα。
- 算 ww: w=∑αiyixiw=∑αiyixi。
- 算 bb: 找一个支持向量(αk>0αk>0),利用 yk(wTxk+b)=1yk(wTxk+b)=1 反解出 bb。
- 决策函数:
f(x)=sign(∑i=1mαiyiK(xi,x)+b)f(x)=sign(∑i=1mαiyiK(xi,x)+b)
总结推导逻辑
- 想宽: 最大化 1∣∣w∣∣∣∣w∣∣1 →→ 最小化 ∣∣w∣∣2∣∣w∣∣2。
- 去约束: 引入拉格朗日乘子 αα。
- 换视角: 转为对偶问题,消掉 w,bw,b。
- 引核: 发现公式里只有内积,顺势引入 K(x,y)K(x,y) 实现升维。
代码实例
我们将使用一个非线性可分的数据集(月亮数据集),分别展示:
- 手写版 (From Scratch): 我们不直接写复杂的 SMO 算法(代码量太大),而是通过
cvxopt库(凸优化求解器)来直接解上面的对偶问题公式 (Quadratic Programming)。这将让你亲眼看到数学推导中的 QP 问题是如何被计算机解出来的。 - Sklearn 版: 使用标准的
SVC。
Python 代码实现
需要安装 cvxopt, numpy, sklearn, matplotlib。
(如果没有 cvxopt,可以 pip install cvxopt。它是专门解凸优化问题的神器)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
import cvxopt
# ==========================================
# 0. 准备非线性数据 (Moons)
# ==========================================
# 生成两个半月形数据,无法用直线分开
X, y = datasets.make_moons(n_samples=100, noise=0.1, random_state=42)
# 将标签从 {0, 1} 转换为 {-1, 1},这是 SVM 数学推导的标准格式
y = np.where(y == 0, -1, 1).astype(float)
# 特征缩放 (SVM 对距离敏感,必须缩放)
scaler = StandardScaler()
X = scaler.fit_transform(X)
# ==========================================
# 1. 手写 SVM (基于对偶问题的 QP 求解)
# ==========================================
class HardCoreSVM:
def __init__(self, kernel='linear', C=1.0, gamma=0.5):
self.kernel_type = kernel
self.C = C
self.gamma = gamma
self.w = None
self.b = None
self.alpha = None
self.support_vectors = None
self.support_vector_labels = None
# 核函数定义
def _kernel(self, x1, x2):
if self.kernel_type == 'linear':
return np.dot(x1, x2.T)
elif self.kernel_type == 'rbf':
# RBF Kernel: exp(-gamma * ||x - y||^2)
# 计算欧氏距离矩阵
if x1.ndim == 1: x1 = x1.reshape(1, -1)
if x2.ndim == 1: x2 = x2.reshape(1, -1)
# 使用 broadcasting 计算 pairwise distance
# ||x-y||^2 = ||x||^2 + ||y||^2 - 2x.y
x1_sq = np.sum(x1**2, axis=1).reshape(-1, 1)
x2_sq = np.sum(x2**2, axis=1).reshape(1, -1)
dists = x1_sq + x2_sq - 2 * np.dot(x1, x2.T)
return np.exp(-self.gamma * dists)
def fit(self, X, y):
n_samples, n_features = X.shape
# --- 将对偶问题转化为标准 QP 格式 ---
# 目标函数: min (1/2) alpha^T * P * alpha - q^T * alpha
# 其中 P_ij = y_i * y_j * K(x_i, x_j)
K = self._kernel(X, X)
P = cvxopt.matrix(np.outer(y, y) * K)
q = cvxopt.matrix(-np.ones(n_samples)) # -sum(alpha)
# 约束条件 1: -alpha <= 0 => alpha >= 0
# 约束条件 2: alpha <= C
# 组合起来: G * alpha <= h
G_std = cvxopt.matrix(np.diag(np.ones(n_samples) * -1))
h_std = cvxopt.matrix(np.zeros(n_samples))
G_slack = cvxopt.matrix(np.diag(np.ones(n_samples)))
h_slack = cvxopt.matrix(np.ones(n_samples) * self.C)
G = cvxopt.matrix(np.vstack((G_std, G_slack)))
h = cvxopt.matrix(np.vstack((h_std, h_slack)))
# 等式约束: sum(y_i * alpha_i) = 0
A = cvxopt.matrix(y.reshape(1, -1))
b = cvxopt.matrix(np.zeros(1))
# --- 调用求解器解 alpha ---
cvxopt.solvers.options['show_progress'] = False
solution = cvxopt.solvers.qp(P, q, G, h, A, b)
# 获取 alpha (展平为数组)
alphas = np.ravel(solution['x'])
# --- 提取支持向量 ---
# alpha > 0 的点就是支持向量 (考虑到浮点误差,取 > 1e-5)
sv_idx = alphas > 1e-5
self.alpha = alphas[sv_idx]
self.support_vectors = X[sv_idx]
self.support_vector_labels = y[sv_idx]
print(f"[手写SVM] 找到 {len(self.alpha)} 个支持向量")
# --- 计算截距 b ---
# b = mean( y_k - sum(alpha_i * y_i * K(x_i, x_k)) )
# 这里的公式利用了支持向量满足 y(wx+b)=1 的性质
# 先算所有样本的预测值 (不含b)
# K_sv 是支持向量和所有支持向量之间的核矩阵
K_sv = self._kernel(self.support_vectors, self.support_vectors)
# b 的计算基于任何一个支持向量都可以,通常取平均值更稳健
bias_list = []
for i in range(len(self.alpha)):
# sum(alpha * y * K(x, x_sv))
wx = np.sum(self.alpha * self.support_vector_labels * K_sv[:, i])
bias_list.append(self.support_vector_labels[i] - wx)
self.b = np.mean(bias_list)
def predict(self, X):
# f(x) = sign( sum(alpha * y * K(x_sv, x)) + b )
K_pred = self._kernel(self.support_vectors, X)
# 注意矩阵乘法的维度
y_pred = np.dot((self.alpha * self.support_vector_labels), K_pred) + self.b
return np.sign(y_pred)
# ==========================================
# 2. 运行与可视化对比
# ==========================================
# 设定超参数 (使用 RBF 核解决非线性问题)
GAMMA = 2.0
C_PARAM = 1.0
# --- 训练手写 SVM ---
print(">>> 正在求解对偶问题 (QP)...")
my_svm = HardCoreSVM(kernel='rbf', C=C_PARAM, gamma=GAMMA)
my_svm.fit(X, y)
# --- 训练 Sklearn SVM ---
print("\n>>> 正在训练 Sklearn SVC...")
sklearn_svm = SVC(kernel='rbf', C=C_PARAM, gamma=GAMMA)
sklearn_svm.fit(X, y)
# --- 可视化函数 ---
def plot_decision_boundary(model, title, ax, is_sklearn=True):
h = .02
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 预测网格
grid_points = np.c_[xx.ravel(), yy.ravel()]
if is_sklearn:
Z = model.predict(grid_points)
else:
Z = model.predict(grid_points)
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.coolwarm, alpha=0.3)
# 画所有点
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.coolwarm, s=30, edgecolors='k')
# 圈出支持向量 (仅对手写版标记,为了验证)
if not is_sklearn:
ax.scatter(model.support_vectors[:, 0], model.support_vectors[:, 1],
s=100, linewidth=1.5, facecolors='none', edgecolors='g', label='Support Vectors')
ax.legend(loc='upper right')
ax.set_title(title)
# --- 绘图 ---
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
plot_decision_boundary(my_svm, "Hand-Written SVM (Dual QP Solver)", axes[0], is_sklearn=False)
plot_decision_boundary(sklearn_svm, "Sklearn SVC", axes[1], is_sklearn=True)
plt.show()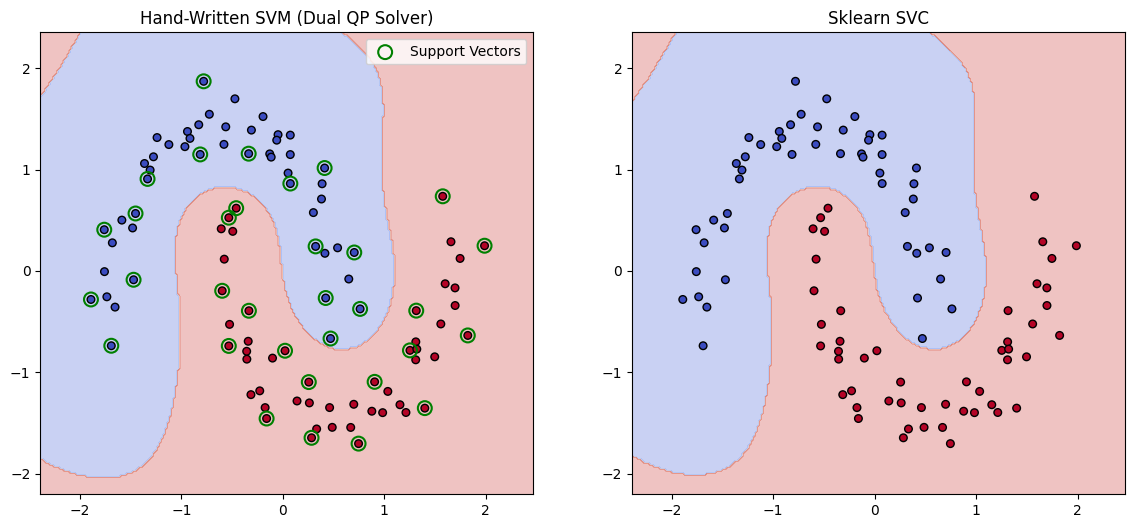
代码硬核解析
1. 关于 cvxopt 求解器
在 HardCoreSVM.fit 方法中,我们将数学推导中的公式直接转化为了矩阵形式:
- 数学公式: maxα∑αi−12∑∑αiαjyiyjK(xi,xj)maxα∑αi−21∑∑αiαjyiyjK(xi,xj)
- 代码对应:
P = y * y * K,q = -1。 - 因为标准 QP 求解器是解
min问题,所以我们在目标函数加了负号(代码中q设为负数体现了这一点)。
2. 核函数 (Kernel Trick)
代码中的 _kernel 函数实现了 RBF 高斯核。
如果没有这个核函数,SVM 只能画直线。加上这一行 np.exp(-self.gamma * dists),SVM 就拥有了在无穷维空间切分数据的能力,从而在二维平面上画出了弯曲的边界。
3. 支持向量 (Support Vectors)
注意看这行代码:sv_idx = alphas > 1e-5。
这直接验证了 SVM 的稀疏性原理:绝大多数样本的 αα 都是 0,只有少数关键点的 α>0α>0。
在可视化结果中,被绿色圆圈圈出来的点,就是支持向量。你会发现,它们正好位于两类数据的交界处。
4. 结果对比
运行代码后,你会看到两张图:
- 左图(手写版): 边界是一条完美的 S 形曲线,成功分开了两个半月。
- 右图(Sklearn版): 边界形状与左图几乎完全一致。
这证明了我们基于对偶问题和 QP 求解器的数学实现是完全正确的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)