【自然语言处理】词性标注-HMM与条件随机场
内容来自syq老师的自然语言课程,侵删
我去,突然发现HMM可以用贝叶斯公式推导,这样公式就好记了:
贝叶斯到HMM
贝叶斯公式
贝叶斯公式的核心思想是:后验概率 似然度
先验概率。
在HMM中,如果想推断隐藏状态(比如通过衣服推断天气),这本身就是一个求后验概率的过程
-
先验概率 P(A):对应HMM中的状态转移概率矩阵 A(结合初始状态
)。它代表了在没有看到任何观测数据之前,我们对隐藏状态(天气变换规律)的先验认知。
-
似然度 P(B|A):对应HMM中的发射/观测概率矩阵 B。它代表了在特定隐藏状态下,生成某种观测数据(特定天气穿某种衣服)的可能性。
-
后验概率 P(A|B):对应我们在给定观测序列后,反推隐藏状态的概率。
明确HMM的几个基本要素:
-
隐藏状态集合:
,N 为状态总数。
-
观测集合:
,M 为可能观测到的结果总数。
-
模型参数
:
-
:初始状态概率(第1天是状态 $i$ 的概率)。
-
:状态转移概率矩阵(从状态 i 转移到状态 j 的概率)。
-
:观测/发射概率矩阵(在状态 j 下,观测到结果 k 的概率)。
-
-
特定观测序列:
,T 为时间长度。
前向概率递推
前向概率的定义:
给定模型,定义到时刻 t 为止,观测序列为
,且时刻 t 的隐藏状态为 qi 的联合概率为前向概率,记作
:
前向算法的计算分为三步:初始化、递推、终止。
1. 初始化 (时刻t=1)
我们要计算第一天发生特定观测的概率。
-
公式拆解:
-
-
:在隐藏状态为 qi 的条件下,恰好观测到结果 o1 的概率。
-
两者相乘,表示“系统在状态 i 启动,并且吐出了观测值 o1的联合概率。
-
2. 递推 (时刻 )
这是算法的核心。已知前一时刻 t 所有状态的前向概率 ,如何求下一时刻 t+1 处于状态 j 且观测到
的前向概率
?
-
公式深度拆解:
-
:根据定义,这是在时刻 t 到达状态 i 并输出历史观测序列
的累积概率。
-
:这是系统从时刻 t 的状态 i,转移到时刻 t+1 的状态 j 的概率。
-
:表示通过路径 i,在时刻 t+1 到达状态 j,且历史观测为
-
:这里运用了全概率公式。因为在 t+1 时刻到达状态 j 的路径,可能来自 t 时刻的任意一个状态 i(从1到 N)。把所有可能通向状态 j 的路径概率加起来,我们就得到了:在时刻 t+1 处于状态 j,且已经观测到
-
:最后,既然系统在 t+1 时刻已经处于状态 j 了,它还需要“发射”出当前的观测值
。乘以这个发射概率,我们就得到了完整的
。
-
3. 终止 (时刻 t=T)
当递推到最后一个时刻 T 时,我们得到了 。这表示在时刻 T 处于状态 i,并且生成了完整观测序列
的联合概率。
为了求生成整个观测序列 O 的概率 ,我们只需要把最后一个时刻处于所有可能状态 i 的概率加起来:
贝叶斯公式
假设我们要求的是:在看到前 t+1 天的观测数据后,第 t+1 天处于状态 j 的概率
我们根据前一天的状态,预测今天处于状态 j 的概率:
这里的 就是状态转移矩阵中的
现在,我们看到了今天的真实观测值 。我们用贝叶斯公式来更新我们的预测:
根据贝叶斯公式展开:
在这个公式里:
-
就是发射概率
-
就是我们在第一步预测出的先验。
-
分母
是一个归一化常数。
而前向算法的递推公式:
逻辑回归到CRF
在机器学习中,逻辑回归(LR)和条件随机场(CRF)都属于对数线性模型(Log-linear Model),同时也都是最大熵模型(Maximum Entropy Model)的具体实现。
它们的唯一区别在于预测的维度:
-
LR 解决的是单点分类问题(给定一个输入 x,预测一个离散标签 y)。
-
CRF 解决的是结构化预测问题(给定一个输入序列 X,预测一个关联的标签序列 Y)。
通常我们见到的多分类逻辑回归(Softmax 回归)公式是这样的:
为了和 CRF 对齐,我们引入特征函数 f(x, y)。我们定义一个全局权重向量 w 和一个指示特征向量 f(x, y)(例如:当 y=c 时激活对应的特征维度)。那么,LR 的公式可以完全等价地写成:
其中,配分函数 ,
是所有可能类别的集合。
现在,我们把单点的 x 和 y,升级为序列 和序列
。
根据我们之前的推导,线性链 CRF 的公式为:
其中, 是序列所有位置局部特征的总和,配分函数
吉布斯分布
Gibbs Distribution,也叫玻尔兹曼分布
1.在物理学中,它描述了一个系统在温度为 T 时,处于能量为 E(x) 的状态 x 的概率
直观含义:能量越高的状态,出现的概率呈指数级下降。其中Z 是配分函数(Partition Function),作用仅仅是把所有状态的指数值加起来,用于除法归一化,保证总概率为 1。
2.在机器学习中,把公式里的 替换成了特征函数与权重的线性组合:
物理学家用指数函数是因为热力学定律,那机器学习领域,为什么非要用 exp() 这个特定的数学形式来做概率模型呢?它不是人为规定的,而是最大熵原理推导出来的唯一解
最大熵定理

推导:
要最大化系统的香农熵
1.定义目标函数
直觉告诉我们,一个事件发生的信息量 I(x) 必须满足以下三个公理:
-
概率越小,信息量越大:明天太阳升起(概率大),没啥信息量;明天陨石撞地球(概率小),信息量巨大。即 I(x) 应该是 P(x) 的单调递减函数。
-
确定事件的信息量为零:如果 P(x) = 1,那么 I(x) = 0。
-
独立事件的信息量可加:如果两个事件 x 和 y 是相互独立的,它们同时发生的概率是 P(x, y) = P(x)P(y)。我们希望它们总的信息量是各自信息量之和,即 I(x, y) = I(x) + I(y)。
在数学上,满足 的函数只有对数函数 log。
因此,为了满足上述三个条件,单个事件 $x$ 的信息量被唯一地定义为:
注:加上负号是因为概率 ,其对数值为负或零。加负号可以保证信息量始终非负。
定义了单个事件的信息量后,整个系统 P$处于各种可能状态时的平均信息量是多少?在概率论中,求平均值就是求数学期望。将系统所有可能状态的信息量 I(x) 按照它们发生的概率 P(x) 进行加权求和:
将第一步的 代入,就得到了香农熵的最终定义,也就是我们优化的目标函数:
2.设定约束条件
(1)基础概率约束:所有状态的概率和必须为1
(2)特征期望约束:模型给出的特征期望,必须等于训练数据中统计到的真实期望(比如上述例子的骰子的平均值为4.5),假设只有一个特征函数f(x),对应的已知期望为μ
3.拉格朗日乘子求解
由于这是一个带等式约束的极值问题,我们构造拉格朗日函数 L。引入两个乘子 和
:
为了找到极值,我们对未知的概率 P(x) 求偏导,并令其等于 0:
看到,前一部分 是一个与具体状态 x 无关的常数。为了满足约束一(总概率为1),这个常数必然等于
,也就是配分函数
我们将 视作机器学习中需要训练学习的特征权重 w。公式化简为:
Hammersley-Clifford 定理
1.图论中的定义
-
团(Clique):指的是图中的一个节点子集,在这个子集里,任意两个节点之间都有边相连。
-
最大团(Maximal Clique):指的是一个团,如果你再往里面加任何一个图中的其他节点,它就不再是一个团了(即新加的人不可能认识圈子里的所有人)。
2.条件随机场中变量依赖
-
节点:有两种节点。一种是未知的隐藏状态序列
,另一种是已知的、全局可见的观测序列 X。
-
连线(边):
-
因为是“线性链”,隐藏状态之间只有相邻的节点才有连线(即 y1 连 y2,y2 连 y3)。这代表了马尔可夫性:当前状态只与相邻状态直接相关。
-
因为是“条件”随机场,且我们不假设观测独立性,所以全局观测变量 X 被认为与所有的 yi 都有连线。
-
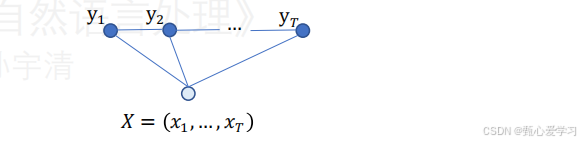
我们来找线性链 CRF 中的最大团:
看序列中的相邻节点和
,它们两个是相连的。同时,全局观测 X 与
相连,也与
相连。所以,集合
构成了一个团。
我们能再往这个团里加节点吗?
比如加入 不行,因为在线性链中,
和
之间没有直接连线。
因此, 就是线性链 CRF 图结构中的最大团。
随着时间步 i 从 1 走到 T,我们就得到了图中所有的最大团:
(假设有个起始虚拟节点 y0)
...
3.定理内容
任何一个无向图模型的联合概率分布,都可以表示为图上所有“最大团”上的势函数的连乘积,再进行全局归一化。
用数学语言表达就是:
-
V 是图上所有节点的集合。
-
C 是图中所有最大团的集合。
-
是属于最大团 c 的节点。
-
是定义在最大团 c 上的势函数(要求严格大于 0)。
我们的目标分布是在给定 X 的条件下的 Y 的分布 P(Y|X)。在这个条件分布下,X 被视为常数条件。根据我们在第二步找到的 CRF 的最大团集合,最大团的索引就是时间步 i,每个最大团包含的节点是 。
直接代入定理公式,全局条件概率 P(Y|X),就被拆解成了:
4.势函数
数学家对势函数 提了一个极其严格的硬性要求:它必须严格大于 0(即
)。
为什么?
-
概率非负:概率累乘的结果不能是负数。
-
避免绝对的零:如果图模型中某个局部的
,整个连乘的结果瞬间归零。这意味着模型武断地判定某种路径“绝对不可能发生”。在概率计算(尤其是还要取对数计算熵)中,我们要极力避免 0 概率的出现。
如何保证一个函数的输出永远大于 0,不管输入什么离谱的负数?数学中最自然、性质最完美的函数就是指数函数exp(E)。(在物理学中,这里的 E 就是能量函数,系统能量越高,指数计算出的非规范化概率就越低)
因此,为了满足定理的非负要求,我们顺理成章地将势函数定义为某个实数域函数 的指数形式:
现在,势函数变成了 exp(E)。接下来的问题是:这个未知的内部函数 E 应该长什么样?
在机器学习中,我们面对的是极其复杂的观测序列 X。我们需要把这种复杂的上下文信息,提炼成机器能看懂的分数。最简单、最鲁棒的做法就是线性组合:
-
我们定义一堆特征函数
,作为特征提取器(比如判断当前词是不是名词,前一个词是不是动词)。
-
我们给每一个特征函数分配一个权重
,代表这个特征有多重要。
-
将它们线性相加。
于是,内部函数 E 就被具象化为特征向量和权重向量的内积(或者叫加权求和):
将第二步代回第一步,我们就得到了在工程上最常见、计算最方便的势函数定义:
展开形式与简化写法
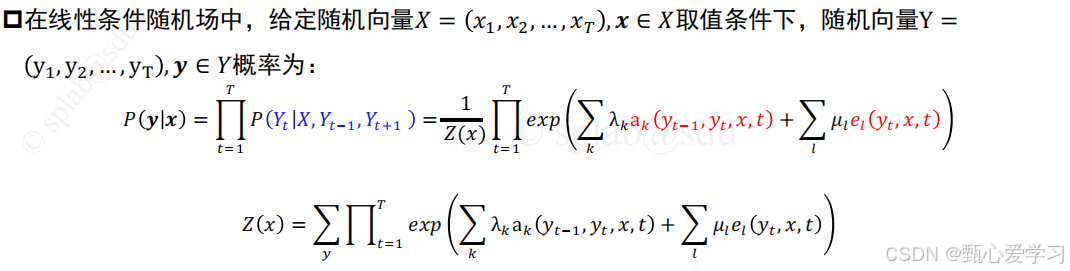
在数学上,转移特征 和状态特征
并没有本质区别,它们都是关于当前上下文的函数,这里其实只是分来写了。我们完全可以将它们拼接成一个统一的特征向量,并将对应的权重拼接成一个权重向量。
简化写法
-
统一定义局部特征函数 fk:
假设有 K1 个转移特征,K2个状态特征,令总特征数 K = K1 + K2。我们定义新的统一特征函数
:
当
时,
;
当
时,
(此时函数内部直接忽略
的输入)。
-
统一定义权重 wk:
同理,当
;当
。
时间步 t 上的局部打分被极简压缩为向量内积:
矩阵形式
这里的 是对所有可能的隐藏状态序列求和。
假设序列长度为 T,每个位置有 m 种可能的标签状态。那么长度为 T 的序列总共有种可能。如果要计算 Z(x),难道我们要计算
条路径的得分再相加吗?这在时间复杂度上是无法接受的(指数级爆炸),为了破解这个困境,数学家引入了线性代数中的矩阵乘法:
我们回到每一个局部时间步 t。在时刻 t,前一个状态 有 m 种取值,当前状态
也有 m$种取值。
我们可以据此定义一个 的状态转移矩阵
。矩阵中的每一个元素,代表了从特定的前一个状态i 转移到特定当前状态 j$的非规范化转移概率:
根据这个定义,图片中分子部分的连乘,实际上就是在 T 个矩阵中,依次挑出对应状态下标的元素相乘。
线性代数中矩阵相乘的定义是 ,其元素
。物理意义是:从状态 i 到状态 j 的总路径权重,等于中间经过所有可能状态 k 的路径权重之和。
如果我们将所有 T 个时间步的矩阵依次相乘,得到一个最终的全局矩阵 M(x):
根据矩阵乘法的展开律,M(x) 第 i 行第 j 列的元素 ,恰好等于所有以状态 i 为起点、以状态 j 为终点的可能路径的非规范化概率之和!
因此,我们要求的所有 条路径的总和 Z(x),根本不需要穷举。我们只需要:
-
算出行列式为
的 T 个矩阵相乘。
-
将最终得到的矩阵 M(x) 的所有元素加起来(假设引入特殊的起点和终点状态,通常表现为起始行向量乘以最终矩阵再乘以结束列向量)。
此时,计算配分函数 Z(x) 的时间复杂度,从 直接降维到了
。
上述矩阵连乘的计算过程,比如从左往右依次计算:
这与我们在最开始讨论的 HMM 前向算法的递推公式在数学本质上是完全等价的。唯一的区别是,HMM 中矩阵的元素是真实的条件概率且和为1,而 CRF 的矩阵元素是没有归一化的指数分数()。
Nice,终于知道为什么写成这个形式了
基础定义
词性标注是一种评估基准
词性:词汇在句子中承担的句法角色。根据词汇的语法特征和词义进行划分,如名词、动词等
(有界集合词类,相对稳定,如介词;无界集合词类,随着时代发展不断扩充新词,如动词名词)
词性标注:对于句子中的词汇进行词类标记。对于英文,需要为每个单词预测对应的词性,中文还需要同时完成分词
词性分析的意义:理解语言的语义和语法结构,辅助其他自然语言任务比如句法分析、命名实体识别、双语翻译和文本理解等
词性标注的难点
单词多样性带来的词性多样性;词类的无界性;中文分词结果影响词性标注
隐马尔可夫模型
假设:对于给定的文本序列,每个词汇的词性仅依赖于前一个词汇
马尔可夫模型
隐马尔可夫模型:包括两个过程,生成不可观测的随机状态序列Y,再由各个状态生成一个可观测符号的随机序列X,是解决序列标注任务的生成模型
HMM五元组
隐马尔可夫模型(Hidden Markov Model)定义五元组
λ = (S,V,p,A,E)
S为有限状态
V为有限的观测状态
p为初始状态概率分布,和为1
A为转移概率矩阵,也就是由si转为sj的概率,j和为1
E为发射概率矩阵,就是由sj转为vk的概率,k和为1
(突然发现,这个跟信息检索课程中学的内容一样,见:信息检索3-CSDN博客)
两个假设
1.齐次马尔可夫假设
任意时刻的隐藏状态只依赖于前一时刻的隐藏状态,而与更早的历史状态无关。同时,状态转移的概率不随时间变化
2.独立观测假设
任意时刻的观测值只依赖于当前时刻的隐藏状态,而与其它时刻的隐藏状态或观测值无关。给定当前状态,观测是条件独立的。
三个基本问题
1.可观测序列的概率计算问题
1.针对序列和特定状态序列的概率计算:给定λ,观测序列X和状态序列Y,求 P(X,Y|λ)
2.针对序列的所有状态序列的概率计算:给定λ和观测序列X,求P(X|λ)
对于1,P(X,Y|λ) = P(X|Y,λ)P(Y|λ)
根据齐次马尔可夫假设:
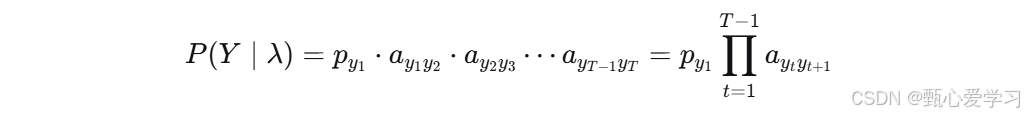
根据独立观测假设:


HMM 生成过程是:
-
以概率 py1 选择第一个状态 y1。
-
在状态 y1 下,以概率 ey1(x1) 生成第一个观测 x1。
-
从状态 y1 转移到下一个状态 y2,概率为 ay1y2。
-
在状态 y2下,以概率 ey2(x2) 生成第二个观测 x2。
对于2,求P(X|λ) = sum(P(X,Y|λ));或者是用动态规划算法:前向算法或是后向算法



αt(i)为到时刻 t 为止观测到 x1…xt,并且当前时刻 t 的状态正好是 si 的联合概率。注意,这里没有指定之前的状态是什么,而是把所有可能的之前路径的概率都累加到了这个 αt(i) 中


前向后向算法复用了之前的计算过程

| 步骤 | 暴力计算 | 前向算法 |
|---|---|---|
| 计算 P1P1 | 独立算 p1e1(x1)a11e1(x2) | 不单独算 |
| 计算 P3P3 | 独立算 p2e2(x1)a21e1(x2) | 不单独算 |
| 得到 P1+P3 | 算完两个值后相加 | 直接通过 α2(1) 得到,只用一次乘法加一次加法就同时得到了两条路径的和 |
| 对 P2+P4 | 同样独立算再相加 | 通过 α2(2)得到 |
2.可观测序列的状态估计问题
1.预测给定序列的特定位置状态的概率:已知λ和X,计算t时刻的状态概率P(Yt = st|λ,X)
2.预测给定序列的最大概率状态序列:已知λ,Y,求P(Y|λ,X)最大的Y
对于1,计算前向和后向概率。




对于2,用维特比算法:


维特比算法不是贪心:贪心每步只保留一个全局最优状态,而维特比为每个状态保留一条最优路径(共 N 条),最后才从这 N 条中选出全局最优



3.可观测序列的模型学习问题
1.已标记数据的隐马尔可夫模型学习:已知X和对应的Y,估计λ使得P(X,Y|λ)最大
2.未标记数据的模型学习:已知X,估计λ使得P(X|λ)最大
对于1


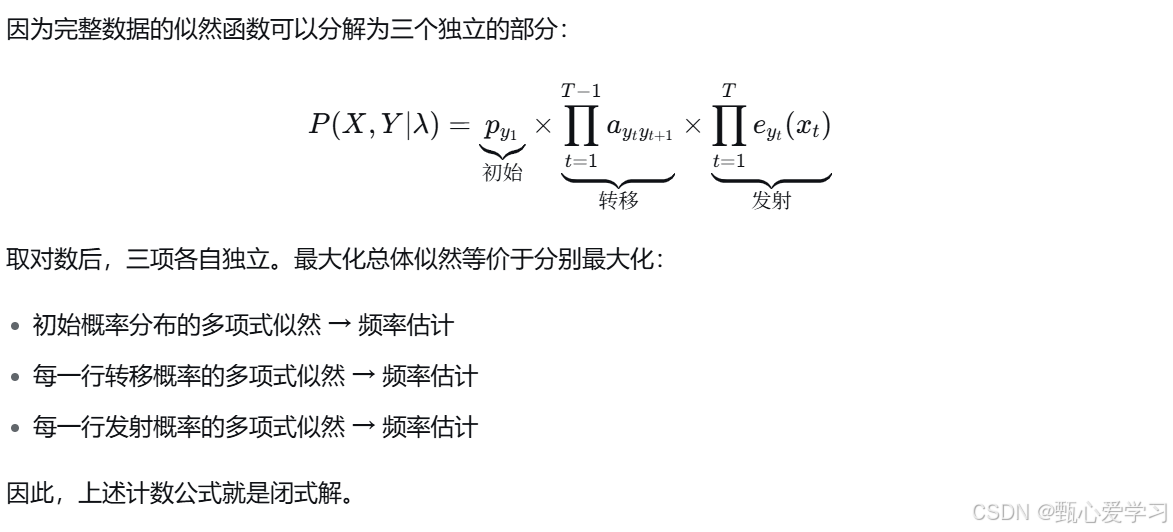
对于2,属于无监督学习





对于更新的理解:



Baum-Welch 算法是 EM 算法在 HMM 上的特例。E 步计算了完整数据(X,Y)的对数似然的期望(对 Y 后验分布求期望)。M 步最大化这个期望,得到的新参数恰好就是上述“期望计数”的比例形式。这可以严格从数学上推导出来,这里不展开。
直观上:如果我们知道每个时刻状态的后验分布,那么对于每个样本,我们可以把后验概率视为“软标签”,然后像监督学习那样计数,只不过每次计数时不是加 1,而是加一个概率值(例如 0.7)。这样更新出来的参数,就是当前模型下最合理的估计。
条件随机场
基本定义
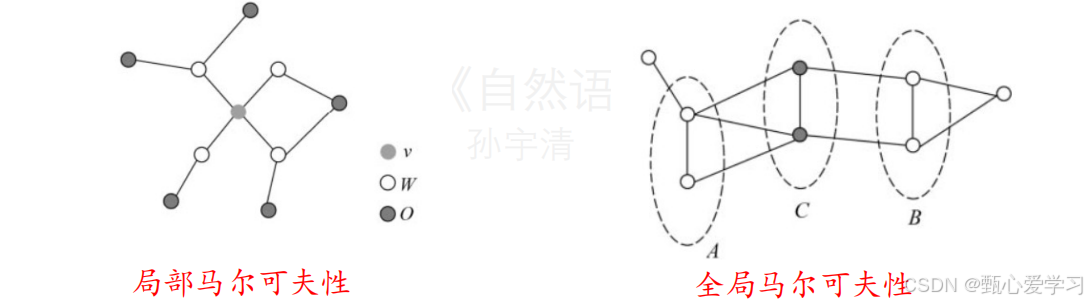
马尔可夫随机场:多个随机变量Y的联合概率分布P(Y),又称概率无向图G = (Y,E),yi对应顶点,随机变量yi和yj之间的依赖关系构成边eij,联合概率分布P(Y)满足成对、局部或全局马尔可夫性。
成对马尔科夫性:设u、v是无向图G中任意两个没有边连接的结点,节点u和v分别对应随机变量Yu和Yv,其他所有结点表示为o,对应的随机变量组为Yo。成对马尔科夫性是指给定随机变量组Yo的条件下,Yu和Yv是条件独立的:P(Yu,Yv|Yo) = P(Yu|Yo)P(Yv|Yo)
局部马尔可夫性:设v为无向图G中的任意一个节点,W是与v有边连接的所有结点,O是除v,W以外的其他节点。W,O,v对应的随机变量组分别表示为Yw,Yo和Yv,局部马尔可夫性指给定Yw的条件下,Yo和Yv是条件独立的:P(Yo,Yv|Yw) = P(Yo|Yw)P(Yv|Yw)
全局马尔可夫性:设节点集合AB是在无向图G中被节点集合C分开的任意节点集合,节点集合ABC所对应的随机变量组分别为YAYBYC,全局马尔可夫性指的是,在给定YC条件下,YAYB是条件独立的:P(YA,YB|YC) = P(YA|YC)P(YB|YC)
团与最大团
团:无向图G中的结点子集称为团当且仅当任何两个结点均有边连接
最大团:若C是无向图G的一个团,并且不能再加进任何一个G的结点使其成为一个更大的团,则称这个C为最大团
将概率无向图模型的联合概率分布P(Y)表示为其最大团上的随机变量的函数的乘积,即为概率无向图模型的因子分解:
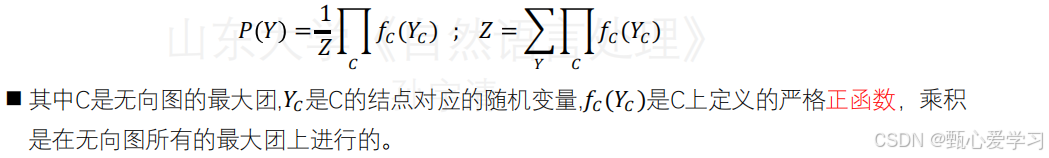
条件随机场
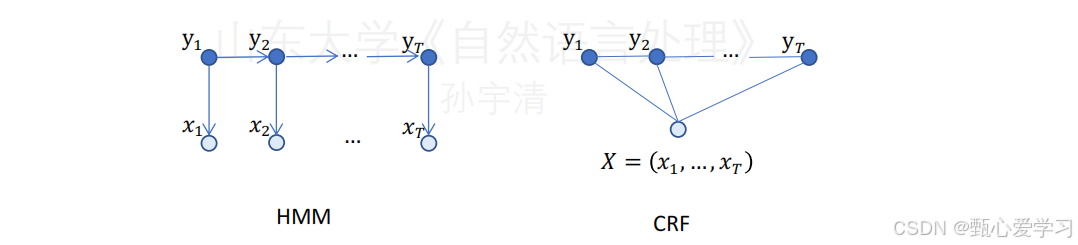
给定一组输入随机变量条件下,另一组输出随机变量的条件概率分布模型P(Y|X)
随机变量Y构成一个由无向图G=(V,E)表示的马尔可夫随机场

线性链条件随机场




简化形式
原始公式中,转移特征 ak 和状态特征 el 分别用两套参数 λk 和 μl,写起来很长。为了便于数学推导和编程实现,我们可以把它们全部放入一个总特征向量中。

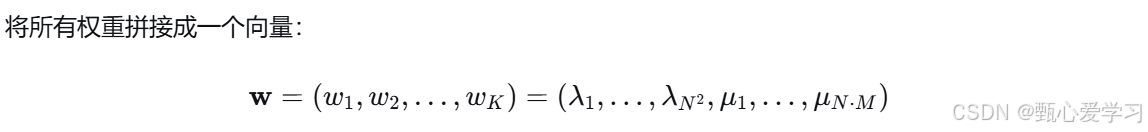

矩阵形式

求解方法:要求出所有的情况,但通常情况下简化,比如:前向后向算法,维特比算法等
| 模型 | 优点 | 缺点 |
|---|---|---|
| HMM | 训练简单(计数),推理快,适合数据量小或观测独立假设近似成立的场景 | 特征表达能力弱,对观测独立性假设敏感,可能发生标签偏置(label bias problem) |
| CRF | 特征极其灵活,可融合任意上下文,无标签偏置问题,精度通常更高 | 训练慢(需迭代且计算配分函数),需要更多训练数据,特征工程依赖人工设计(深度CRF可自动学习特征) |
三个基本问题
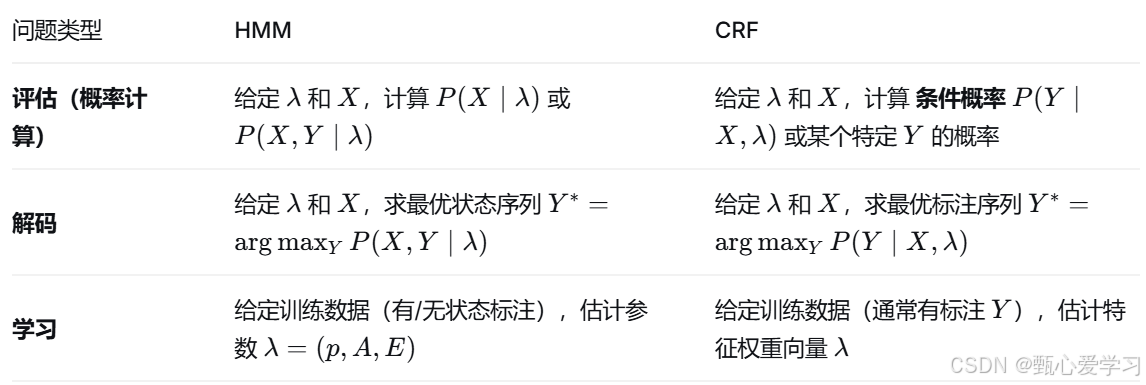





案例



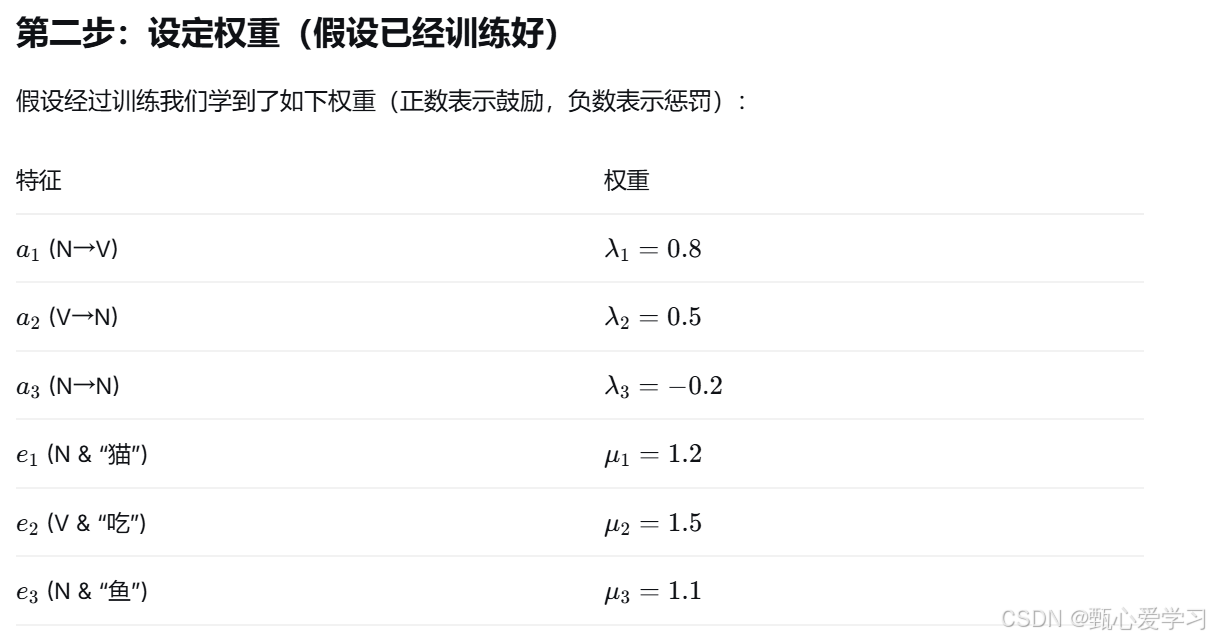





CRF用在句子中的完整流程:
-
定义特征模板:对于每个位置 tt,生成大量二值特征(比如“前一个词性是名词且当前词是‘吃’”)。
-
给每个特征分配一个权重(初始随机,后由训练得到)。
-
对给定句子,提取每个位置的特征值(0或1)。
-
计算每个候选标签序列的得分:累加所有位置上特征值×权重,然后取指数。
-
归一化:除以所有序列的指数和,得到真正的概率。
-
预测:用维特比算法找到得分最高的序列(无需显式计算归一化)。
-
训练:用标注数据,通过梯度下降调整权重,使正确序列的概率尽可能大。
问题来源
无论是 HMM 还是 CRF,它们都定义了一个概率分布(联合分布或条件分布)来描述观测序列 X 和状态序列 Y 之间的关系。一旦有了这个模型,我们自然就会问三类问题:
1. 评估问题(Evaluation)
-
问题:给定模型参数 λ 和一个观测序列 X,这个模型有多大的可能性生成 X?或者说,某个特定的状态序列 Y 与 X 的联合概率(条件概率)是多少?
-
为什么需要:用于模型选择(比较两个 HMM 哪个更符合数据)、语音识别中计算声学得分、异常检测等。
-
本质:计算概率值(求和/积分)。
2. 解码问题(Decoding)
-
问题:给定模型 λ 和观测序列 X,最有可能的隐藏状态序列 Y 是什么?
-
为什么需要:这是预测任务的核心,例如词性标注(给定句子,猜每个词的词性)、命名实体识别(给定文本,标记实体边界)。
-
本质:寻找最优状态序列(最大化)。
3. 学习问题(Learning)
-
问题:给定一组训练数据(观测序列,有时也包括状态序列),如何估计模型的参数 λ,使得模型能最好地拟合数据?
-
为什么需要:模型参数未知时,必须从数据中学习。这是构建实际系统的前提。
-
本质:参数估计(最大似然或最大条件似然)。
一些问题
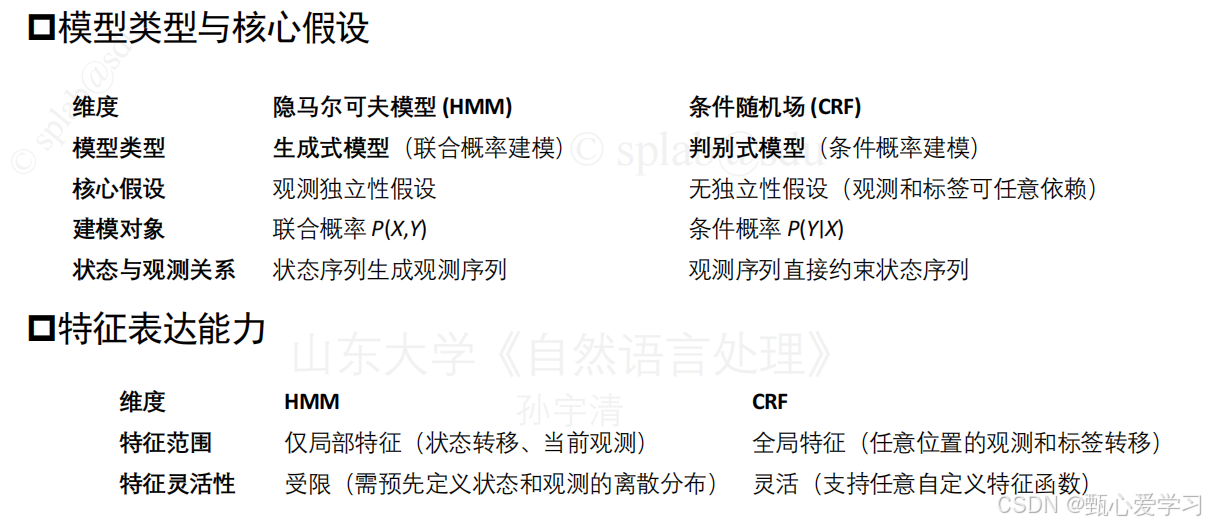

1. HMM两个假设的意义?词性标注任务能严格满足吗?有什么弊端?
两个假设的意义:
-
齐次马尔可夫假设:当前隐藏状态只依赖前一状态,使得状态序列的概率可以分解为初始概率和转移概率的乘积,极大减少了参数数量,使模型可计算。
-
独立观测假设:给定当前状态,观测值与其他所有变量(包括历史观测和其他状态)条件独立,从而将观测序列的概率分解为各时刻发射概率的乘积,便于用动态规划求解。
词性标注能否严格满足?
不能。词性标注中,当前词的词性往往不仅依赖前一个词性,还可能依赖更远的词性(如长距离搭配);且当前词的出现不仅依赖当前词性,还受前后词的影响(如上下文搭配、歧义消解)。因此两个假设在真实语言数据中都是近似成立,而非严格满足。
弊端:
-
一阶马尔可夫假设丢失长距离依赖信息,可能导致错误标注(如动词后面跟名词的规律可能被局部最优掩盖)。
-
独立观测假设忽略了观测之间的相关性,例如“an apple”中的“an”强烈提示下一个词以元音开头,但HMM只能通过状态间接建模,无法直接利用这种跨词特征。
-
导致模型表达能力有限,尤其在标注稀有词或歧义词时效果较差。
2. 关于HMM模型学习,存在什么问题?
主要有以下问题:
-
监督学习(状态已知):需要大量人工标注的状态序列(如词性标注语料),标注成本高;且如果训练数据覆盖不全,会出现零概率问题(未出现的转移或发射概率为0),需要平滑处理。
-
无监督学习(Baum-Welch):
-
可能收敛到局部最优,对初始值敏感。
-
训练速度慢(每次迭代需要前向后向算法)。
-
观测序列必须足够长且具有统计规律,否则参数估计不准确。
-
无法处理状态数未知的情况(状态数需预先指定)。
-
-
通用问题:HMM假设观测独立,对于特征重叠或长程依赖强的序列(如命名实体识别中“New York”这种跨词实体)效果较差。
-
可扩展性:当观测符号集很大(如连续语音特征或大词汇量文本)时,发射概率矩阵巨大,需要高斯混合模型等近似,增加复杂度。
3. HMM求解过程是否能够得到全局最优解?是否能够解决开放预测问题?
求解过程:
-
解码问题(维特比算法):对于给定的模型和观测序列,维特比算法可以找到全局最优的状态序列(因为动态规划遍历了所有可能路径,保留了到每个状态的最优子路径,最后回溯)。所以在这一意义上是全局最优。
-
学习问题(Baum-Welch):只能找到局部最优的模型参数,因为似然函数非凸,初始值影响最终结果。
-
概率计算(前向算法):精确计算 P(X∣λ),是全局精确值。
开放预测问题:
“开放预测”指遇到训练集中未出现的新词或新观测。HMM无法直接处理未知观测,因为发射概率 ej(vk) 对于未登录词 vnew 为0。常见的解决方法:
-
将罕见词映射为特殊类别(如
<UNK>)并估计其发射概率。 -
使用子词单元(如字符级)或平滑技术。
-
结合词典或外部知识。
因此HMM本身不具备自动处理开放预测的能力,但通过预处理可以一定程度上解决。
4. 比较隐马模型和条件随机场模型的本质区别,讨论其在文本序列标注问题上的优势和不足,分析两个模型是不是总能得到合理解释?
本质区别:
-
HMM是生成式模型,建模联合概率 P(X,Y)P(X,Y);CRF是判别式模型,直接建模条件概率 P(Y∣X)P(Y∣X)。
-
HMM有严格的独立性假设(观测独立、一阶马尔可夫);CRF没有这些假设,可以定义任意特征函数(依赖整个观测序列)。
-
HMM参数估计简单(计数或EM),CRF需要迭代优化且计算配分函数。
文本序列标注上的优缺点:
| 模型 | 优势 | 不足 |
|---|---|---|
| HMM | 训练快、可解释性强、小数据集上不易过拟合 | 表达能力有限,难以融入复杂特征,对长距离依赖和观测相关建模弱 |
| CRF | 特征灵活,可融合词形、词典、上下文等任意特征,精度通常更高 | 训练慢、需要更多数据、特征工程复杂(传统CRF),易过拟合 |
是否总能得到合理解释?
-
HMM:如果数据严格满足两个假设,其概率解释是合理的。但自然语言不满足时,给出的概率可能失真(例如零概率问题)。不过通过平滑,仍能得到有意义的相对排序。
-
CRF:条件概率 P(Y∣X)P(Y∣X) 的定义在数学上总是合理的,但特征工程不当或数据稀疏时,可能学到虚假的相关性,导致预测结果不合理(例如过度依赖某个词形特征)。但整体上CRF更灵活,更能拟合真实分布。
结论:两个模型在足够数据且合理配置下都能给出合理解释,但CRF更接近实际序列标注问题的本质。
5. 反思词性标注任务是不是自然语言处理领域必要的?为什么?
是必要的,原因如下:
-
基础句法分析:词性是句法结构(如短语、依存关系)的基础,很多下游任务(句法解析、命名实体识别、语义角色标注)需要词性作为输入特征。
-
消歧:词性能够消除词语的歧义,例如“record”作名词或动词时发音和含义不同,有助于机器翻译、语音合成等。
-
简化模型:词性将词汇量巨大的具体词抽象为几十个类别,极大缓解数据稀疏问题,使模型能够泛化到未登录词。
-
历史地位:早期NLP系统普遍以词性标注为第一道工序,尽管现在端到端深度学习可以绕过显式词性标注,但词性仍然作为有用的中间特征融入多任务学习或预训练模型中。
不过,随着预训练语言模型(如BERT)的发展,很多任务不再显式依赖词性标注,但词性信息仍隐含在模型内部表示中。因此,词性标注作为一个独立任务的重要性有所下降,但作为理解语言结构的基本工具,其必要性依然存在。
6. 神经网络实现CRF和概率CRF模型有什么本质区别?
传统概率CRF(线性链CRF):
-
特征函数是人工设计的(如词是否为数字、是否大写等),权重通过极大似然估计学习。
-
模型结构固定(线性链),参数规模小,可解释性强。
-
依赖特征工程,泛化能力受限于特征覆盖。
神经网络CRF(如BiLSTM-CRF、Transformer-CRF):
-
发射分数由神经网络(如BiLSTM、BERT)自动学习得到,不再需要手工设计特征。神经网络从原始文本中提取丰富的上下文表示。
-
CRF层仍然使用转移矩阵和维特比解码,但特征函数被神经网络的输出层替代,即 score(Y∣X)=∑t(emitt,yt+transyt−1,yt)score(Y∣X)=∑t(emitt,yt+transyt−1,yt)。
-
本质区别:特征学习自动化。概率CRF是浅层线性模型,依赖人工特征;神经网络CRF是深层非线性模型,端到端训练,能够捕捉复杂的语义和结构模式。
其他区别:
-
训练方式:概率CRF用L-BFGS等优化器,神经网络CRF用反向传播和随机梯度下降。
-
计算效率:神经网络CRF通常更慢但精度更高。
-
数据需求:神经网络CRF需要更多标注数据。
本质:神经网络CRF将CRF的结构化预测能力与神经网络的表示学习能力结合,前者提供序列解码框架,后者提供强大的特征提取器。而传统CRF的特征工程是静态的、局部的。
(条件随机场的部分还会继续完善,此刻看不动了。。。)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)