【RAG】一篇文章搞懂RAG全流程
前言:
大模型很聪明,但它有两个硬伤:不知道最新信息,也不了解你的私有知识。
所以,当你问它公司制度、产品价格、内部文档这类问题时,它可能答不上来,甚至一本正经地胡说。RAG 要解决的就是这个问题。
它的思路很简单:别让大模型凭记忆硬答,先去知识库查资料,再根据资料回答。
这篇文章会用最直白的方式,讲清楚 RAG 为什么出现、传统检索为什么不够用,以及一个完整的 RAG 系统到底是怎么工作的。

目录
1. 为什么需要RAG
可以把大模型理解成一位“读过很多书的文字接龙高手”。当我们向它提问时,它并不是实时去互联网上查资料,而是根据我们输入的内容,以及训练阶段学到的语言规律和知识,预测下一个最可能出现的词,再把这些词一步步串联成完整回答。
这就带来了一个天然限制:大模型的知识会停留在训练完成的那一刻。训练之后发生的新政策、新产品、新论文,模型默认并不知道;企业内部文档、私有数据库、业务知识库等没有出现在训练数据里的内容,它也无法凭空掌握。
理解了工作原理,就很容易理解大模型在实际应用中会遇到的麻烦:
-
幻觉问题:一本正经的胡说八道。大模型有时会生成看起来很合理、但内容完全错误的信息。(现在的大模型大多都有联网搜索功能,出现幻觉的概率大大降低了)
为什么会产生幻觉?因为大模型的本质就是预测概率最高的下一个字,它不理解事实。
-
知识的时效性:大模型的知识是冻结在训练截至日期的
对于企业来说,这个问题很严重——产品在更新、政策在变化、价格在调整,但大模型的知识库不会发生对应的改变。
-
专业性不足:
虽然大模型的训练数据规模极其庞大,但是在特定专业领域往往不够深入。
-
私有数据无法获取:
大模型是在公开的数据上训练的,它无法获取:公司内部文档、客户数据、未公开的研究资料。这就意味着,对于特定公司的制度是什么这种问题,大模型无法回答。
-
黑盒无法追溯
大模型的回答是不能溯源的,我们想定位知识来源往往很难做到。
2. 为什么传统检索不够用
很多人可能会想:既然 RAG 需要先“查资料”,那直接用关键词检索不就行了吗?
在某些简单场景下,确实可以。比如用户的问题非常明确,输入的关键词也刚好和文档里的表达一致,传统检索往往能够命中结果。但在真实使用场景中,用户提问通常不会这么“标准”。传统关键词检索更擅长做字面匹配:你输入什么词,它就去找包含这些词的内容。问题在于,人的语言表达非常灵活,同一个意思可以有很多种说法。例如:
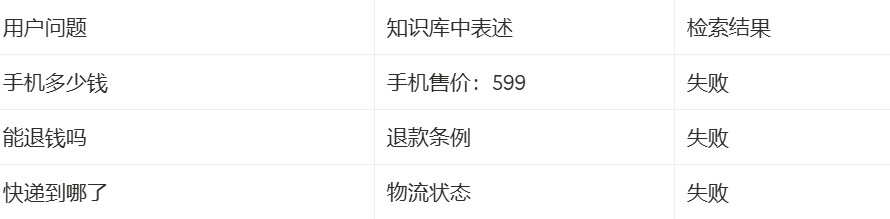
这就是传统检索的核心局限:它能匹配文字,却不真正理解语义。
只要用户换一种说法、使用近义词、口语表达,或者问题稍微绕一点,检索结果就可能偏离。
3. RAG架构
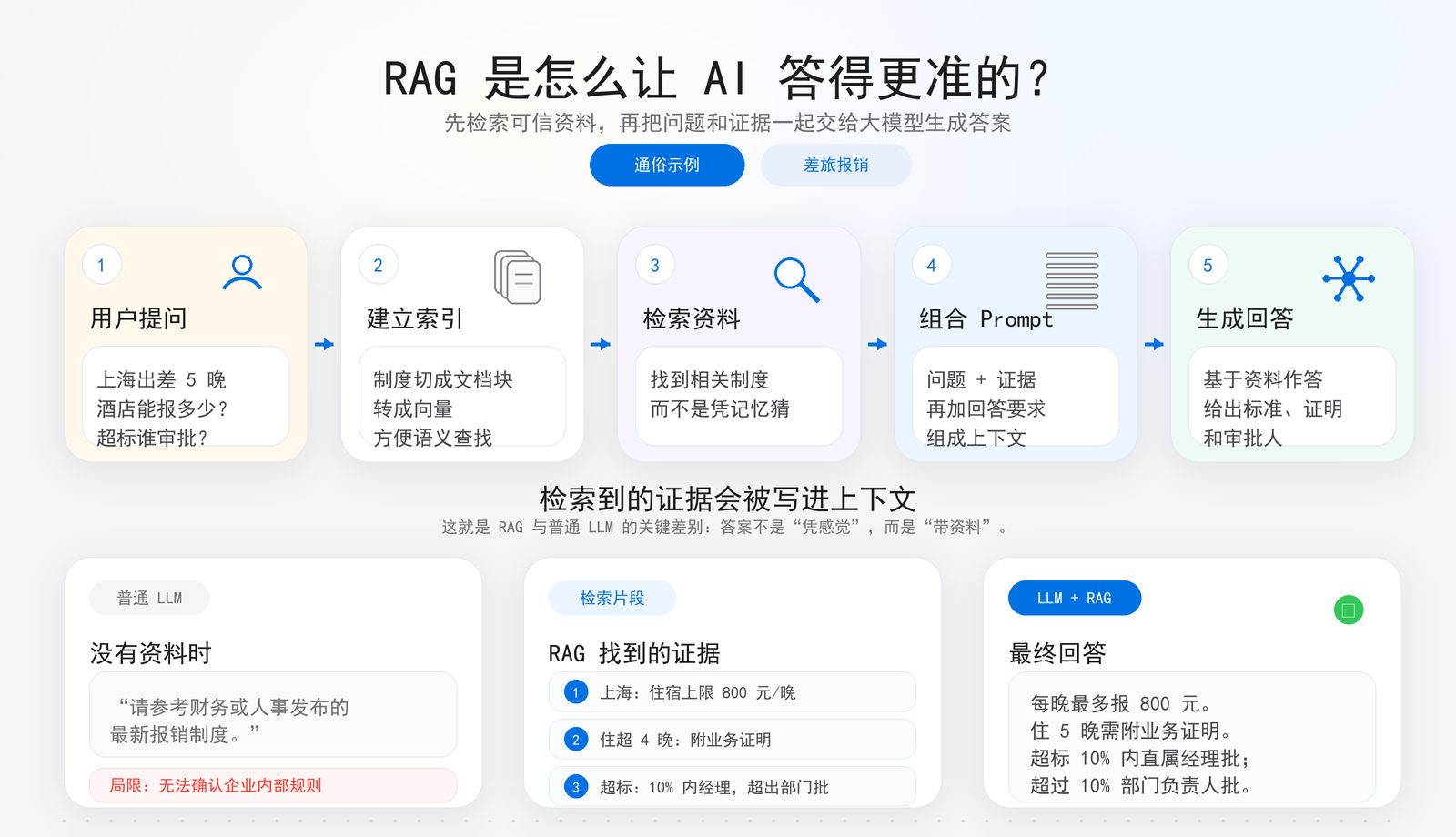
1. 什么是 RAG:让大模型先查资料,再回答
结合前面的内容,我们会发现一个很有意思的矛盾:
大模型擅长理解语义,但它没有你的私有知识,也不一定知道最新信息;传统搜索拥有真实数据,却很难理解用户真正想问什么。
那有没有一种办法,可以把两者的优势结合起来?
这正是 RAG 要解决的问题。
RAG 的全称是 Retrieval-Augmented Generation,中文通常翻译为“检索增强生成”。这个概念通常追溯到 Facebook AI Research,也就是后来的 Meta AI 相关研究。它的核心思路非常直观:不要强迫大模型记住所有知识,而是让它在回答问题之前,先去外部知识库中检索相关资料,再基于检索到的内容生成回答。
换句话说,RAG 给大模型加上了一个“查资料”的步骤。
这样一来,大模型就不再只是凭训练时的记忆回答问题,而是可以结合企业内部文档、知识库、数据库、最新资料等外部信息来生成答案。它既保留了大模型强大的语义理解和表达能力,又能使用更准确、更新、更可控的数据来源。
所以,可以简单理解为:
RAG = 大模型的理解与生成能力 + 外部知识库的实时检索能力。
有了 RAG,大模型就从一个“凭记忆回答的学生”,变成了一个“会先查资料、再组织答案的助理”。
简单来说就是:
这就像开卷考试——大模型不需要记住所有知识,遇到问题直接去书中寻找并回答即可。
2. RAG的核心流程:
一个典型的 RAG 系统,大致可以拆成六个步骤:
Ingest → Chunk → Embed → Index → Retrieve → Answer 数据导入 → 文本切分 → 向量化 → 建立索引 → 检索召回 → 生成回答
这六个步骤可以分为两个阶段:
-
准备阶段:Ingest → Chunk → Embed → Index
这部分通常是离线完成的。也就是说,在用户真正提问之前,我们需要先把知识库整理好、处理好、建好索引。
-
运行阶段:Retrieve → Answer
这部分发生在用户每次提问时。用户提出问题后,系统先去知识库里检索相关内容,再把检索结果交给大模型生成答案。
下面我们把这几个步骤拆开来看。
1.Ingest:把数据导入系统
第一步是 Ingest,也就是把外部数据接入到 RAG 系统中。
这些数据来源可能非常多样,比如:
- PDF 文档
- Word 文件
- 网页内容
- Markdown 文档
- 数据库里的结构化数据
- 企业内部知识库、产品文档、客服记录等
不同类型的数据,处理方式也不一样。
比如,PDF 需要提取其中的文字内容;Word 需要解析文档结构;网页需要爬取正文,并清理导航栏、广告、页脚等无关信息;数据库中的结构化数据,则可能需要转换成适合大模型理解的文本描述。
虽然数据格式五花八门,但这个阶段的目标其实很明确:
把各种来源的数据,统一整理成干净、可用的文本。
这一步看起来简单,但非常关键。因为 RAG 后续的切分、向量化、检索和回答,都是建立在这些文本之上的。如果一开始导入的数据就很脏,比如有大量乱码、重复内容、无关信息,那么后面即使模型再强,也很难给出高质量答案。
所以,Ingest 阶段不只是“把数据拿进来”,更重要的是完成一次基础清洗:把原始资料变成适合后续处理的知识文本。
2.Chunk:把长文档切成小块
文档通常都比较长,如果直接把整篇文档拿来用,会遇到两个问题。
第一,大模型的上下文窗口有限。即使现在很多模型的上下文能力已经很强,也不适合每次都把整篇文档塞进去,成本高、速度慢,还容易引入无关信息。
第二,检索需要尽量精确。用户的问题往往只和文档中的某一小段内容有关。如果每次都召回整篇文档,就像为了查一个词,把整本书都搬到桌上,信息太多,反而会干扰模型判断。
所以,在 RAG 系统中,我们通常会先把长文档切成一个个较小的片段,这个过程就叫 Chunk,也就是“文本切块”。
举个例子,一份 100 页的产品说明书,可以按照章节来切,也可以按照固定长度来切,比如每 500 字切成一块。切完之后,每个小块都会作为独立的知识单元参与后续检索。
不过,切块不是越随意越好,它会直接影响检索质量。
如果切得太大,问题可能是:
- 每个块里包含太多信息,检索结果不够精准;
- 召回内容占用太多上下文,留给模型生成回答的空间变少;
- 无关内容混进来,容易干扰模型回答。
如果切得太小,问题也很明显:
- 单个块里的语义不完整;
- 缺少上下文,模型很难理解这段话的真实含义;
- 重要信息可能被切断,比如定义在上一块,结论在下一块。
所以,实际工程中常见的做法是:每个 chunk 控制在 500 到 1000 字左右,并且相邻 chunk 之间保留一定重叠,比如重叠 100 到 200 字。
这个重叠区域很重要。它就像切蛋糕时故意多留一点边,避免关键信息刚好卡在两块之间,被硬生生切断。
简单来说,Chunk 的目标不是机械地“把长文档切短”,而是把资料拆成适合检索、语义相对完整的小知识块。这样后面检索时,系统才能更精准地找到和用户问题最相关的内容。
3.Embed:把文字变成向量
这一步是 RAG 能够“理解语义”的关键。
前面提到,传统关键词检索主要做的是字面匹配。它很难判断“这东西多少钱”和“产品价格”其实是在问同一件事。那机器要怎么理解这些不同表达背后的相似含义呢?
答案就是:把文字转换成向量。
所谓向量,可以简单理解为一串数字,例如:
[0.18, 0.35, 0.20, ...]
这串数字看起来不像人话,但它编码了文本背后的语义信息。意思相近的文本,转换成向量之后,在向量空间中的位置也会更接近;意思差得很远的文本,向量距离也会更远。
比如:
"手机多少钱" -> [0.18, 0.35, 0.2 ....]
"产品售价" -> [0.17, 0.33, 0.19, .....] <-语义接近
"晚饭吃什么" -> [-0.63, 0.92, 0.77, ...] <-语义较远
这样一来,系统就不再只是看两个句子有没有相同的关键词,而是可以比较它们在语义空间中的距离。
可以把它想象成一张“语义地图”:
“手机多少钱”和“产品售价”会被放在相近的位置,因为它们都和价格有关;而“晚饭吃什么”会被放到很远的地方,因为它讨论的是另一个完全不同的话题。
这个把文本转换成向量的过程,就叫 Embedding。完成这个转换的模型,叫 Embedding 模型。
在实际工程中,我们会对每个 chunk 都做一次 embedding,把每个文本块转换成对应的向量。后续用户提问时,也会把用户的问题转换成向量,然后在向量空间中寻找距离最近的文本块。
常见的 Embedding 模型包括商业模型,也包括开源模型。例如 OpenAI 的 text-embedding 系列模型,以及 BGE、E5、GTE 等开源 Embedding 模型。
简单来说:
Embedding 的作用,就是把人类语言转换成机器可以计算相似度的数字表示。
有了这一步,RAG 才能从“关键词匹配”升级为“语义检索”。
4.Index:存进向量数据库
向量计算出来之后,还需要找个地方把它们存起来,并且能够快速检索。
传统数据库更擅长存储结构化数据,比如用户表、订单表、商品表,然后通过精确条件进行查询,例如“用户 ID 等于 1001”或者“订单状态等于已支付”。
但 RAG 场景里,我们要查的不是“完全相等”,而是“语义相似”。也就是说,给定一个问题向量,系统需要从大量文本向量中,找出和它距离最近、意思最相关的那几个。
这就是 向量数据库 的作用。
向量数据库专门用来存储和检索向量。它做的事情可以简单理解为:
给我一个向量,我帮你在库里找到最接近它的几个向量。
比如用户问“这个产品多少钱”,系统会先把问题转换成向量,然后在向量数据库里查找距离最近的文本块。即使原文里写的是“产品售价为 299 元”,也有机会被正确召回,因为它们在语义上很接近。
常见的向量数据库包括:
- Milvus
- Pinecone
- Weaviate
- Qdrant
- Chroma
- FAISS
其中,Milvus、Pinecone、Weaviate、Qdrant 更偏向完整的向量数据库服务;FAISS 和 Chroma 则更常用于轻量级、本地化或实验场景。
在存储时,通常不会只存向量本身,还会一起存三类信息:
- 向量:用于相似度检索;
- 原文内容:检索命中后,需要把这段文本交给大模型阅读;
- 元数据:用于过滤和管理,比如文档标题、来源、时间、作者、分类、权限等。
举个例子,一个 chunk 存进向量数据库后,可能长这样:
json
{
"id": "doc_001_chunk_003",
"text": "本产品的售价为 299 元,支持企业版批量采购优惠。",
"vector": [0.18, 0.35, 0.20, "..."],
"metadata": {
"source": "产品手册.pdf",
"chapter": "价格说明",
"updated_at": "2026-05-18",
"permission": "internal"
}
}
这样做的好处是,后续检索时不仅可以做语义匹配,还可以结合元数据进行精确筛选。
比如:
- 只检索某个产品线的文档;
- 只检索最近一年更新过的资料;
- 只检索当前用户有权限访问的内容;
- 只检索来自官方文档的内容。
所以,Index 阶段的目标不是简单地“把向量存起来”,而是建立一个既能做语义搜索、又能支持过滤和管理的知识索引。
简单来说:
Index 就是把文本块、向量和元数据一起存进向量数据库,为后续快速检索做好准备。
5.Retrieve:检索相关内容
当用户真正开始提问时,RAG 就进入了运行阶段。
比如用户问:
“手机卖多少钱?”
系统不会直接把这个问题丢给大模型回答,而是会先做一次检索。这个过程主要分为两步:
-
把用户问题转换成向量
也就是用同一个 Embedding 模型,把“手机卖多少钱”转换成一串表示语义的数字。
-
用问题向量去向量数据库中搜索
系统会拿这个问题向量,和知识库中已经存好的文本块向量进行相似度比较,找出距离最近、语义最相关的几个 chunk。
因为语义相近的文本,向量距离也更近,所以即使用户问的是“手机卖多少钱”,而文档里写的是“手机的售价为 3999 元”,系统也有机会把这段内容检索出来。
这就是语义检索和关键词检索最大的区别:
关键词检索看的是“有没有说同样的词”,语义检索看的是“是不是在说同一件事”。
所以,Retrieve 阶段的核心目标,就是从庞大的知识库里,快速找到最可能回答用户问题的那几段内容。
可以把它想象成一次“开卷考试”:
用户提出问题后,系统先不急着让大模型作答,而是先替它翻书、找资料,把最相关的几页挑出来。然后,大模型再基于这些资料组织回答。
一个简化后的检索流程大概是这样:
用户问题:"手机卖多少钱?" ↓ 问题向量:[0.21, 0.34, 0.18, ...] ↓ 向量数据库相似度搜索 ↓ 召回 Top K 个相关 chunk ↓ 返回给大模型作为参考资料
这里的 Top K 指的是返回最相似的前 K 个结果。比如 Top 3 就是返回最相关的 3 个文本块,Top 5 就是返回最相关的 5 个文本块。
当然,真实系统里通常还会做一些额外优化,比如结合关键词过滤、权限过滤、重排序等。但从最核心的流程来看,Retrieve 就是:
把用户问题变成向量,再从向量数据库中找出语义最接近的知识片段。
有了这一步,大模型拿到的就不再是一个孤零零的问题,而是“问题 + 相关资料”。这为下一步生成准确回答打下了基础。
6.Answer:大模型生成回答
最后一步,就是把前面检索到的相关内容,和用户的问题一起打包发给大模型。
这时候,大模型拿到的就不再只是一个孤立的问题,而是类似下面这样的输入:
用户问题:
手机卖多少钱?
参考资料:
根据产品手册,标准版手机售价为 3999 元,Pro 版售价为 4999 元。
接下来,大模型会基于这些参考资料来组织语言,生成最终回答:
这款手机的标准版售价为 3999 元,Pro 版售价为 4999 元。
这一步就是 Answer,也就是生成回答。
它的关键点在于:大模型不是完全依靠自己的“记忆”作答,而是先看检索出来的资料,再根据资料回答用户问题。
可以把这个过程理解成:
以前是“闭卷考试”,大模型只能凭记忆答题; RAG 则把它变成了“开卷考试”,先把相关资料找出来,再让模型作答。
这样做有几个明显好处:
- 更准确:回答有资料依据,减少凭空编造;
- 更新鲜:只要知识库更新,模型就能使用最新内容;
- 更可控:可以限定模型只根据指定资料回答;
- 更可追溯:可以把引用来源一并返回,方便用户核对。
当然,RAG 不是让大模型“看到资料就一定不会出错”。如果检索到的内容本身不相关、不完整,或者提示词没有约束好,模型仍然可能误读资料、遗漏信息,甚至生成不准确的答案。
所以,一个可靠的 Answer 阶段,通常会在提示词中明确告诉模型:
- 优先依据参考资料回答;
- 不要编造资料中没有的信息;
- 如果资料不足,就直接说明无法确定;
- 尽可能返回引用来源。
简单来说:
Answer 阶段,就是让大模型基于检索到的资料生成回答,而不是凭空猜答案。
这也是 RAG 的核心价值:让大模型从“会说话”,进一步变成“会查资料、能依据资料回答”。
写在最后:
RAG 的核心,是让大模型从“凭记忆回答”变成“先查资料再回答”。它通过 Ingest、Chunk、Embed、Index、Retrieve、Answer 六个步骤,把外部知识转化为可检索、可理解、可引用的信息来源。这样,大模型既能发挥语义理解和生成能力,又能结合最新、私有、可控的数据,减少幻觉,提升回答的准确性与可信度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)