[一天一个Skill]第1天:查单词Skill
即读即弃
即读即弃是我的写作风格。
我不是按照瀑布式的方式写文章的。所谓瀑布式,就是把整篇文章拆成多个步骤,你必须一路读到最后才能做出一个完整的东西。如果读到一半弃了,那就只能得到一个半成品。
现在这个时代节奏太快了,我自己都没时间长时间阅读一篇文章。我的文章是迭代式的。你看一小段,就可以先做出一个东西,然后我们再继续扩展,把这个东西做得更好。你如果没时间,就看多少算多少。
所以我会把文章分成多个部分。每读完一个部分,如果你不想继续往下读,就可以直接弃了下课。
第一部分:一个简单的查单词 Skill
背景知识
Skill 是什么
Skill 是 Claude 的母公司 Anthropic 在 2025 年底提出的一个规范。
支持这个规范的工具很多,比如 openclaw、codex、claude code 等等。
你不一定要跟我用同样的工具。只要你的 agent 智能体支持 Skill,就可以使用。
学会方法之后,你自己装到自己的智能体里就行了。不懂怎么装,就直接问你的智能体。
都什么年代了,别再"百度一下""Google 一下"了,太低效了。
如果你的智能体回答不上来,或者一直回答错,那就考虑换一个智能体吧。
个人习惯
我个人喜欢用 openclaw,因为它是目前最接近"下一代普通人个人智能体"的东西,对生活帮助很大。
但 openclaw 太不稳定了,不适合演示,所以这里我会用 claude code。
痛点
如果你只是把一个单词直接发给 AI,它通常会按自己猜测的意思返回结果。
比如你想查 apple 这个单词,你直接对 AI 说:
apple
它大概率会返回:
Apple 是一家美国科技公司,总部位于美国加州库比蒂诺(Cupertino)。
它最著名的产品包括:
- iPhone
- MacBook
...
所以我们可以做一个专门查单词的 Skill。
开始制作 Skill
- 建立一个文件夹:
en-cn-dict - 在文件夹里面建立文本文件
SKILL.md
SKILL.md 内容
---
name: 查单词
description: 当用户消息中出现"查单词:"或"查单词:"后跟英文单词时,返回音标、中文解释和发音。
---
## 处理规则
提取冒号后面的英文单词或短语。
兼容中文冒号 `:` 和英文冒号 `:`。
## 输出格式
必须严格使用以下格式:
单词:<英文单词>
音标:<音标>
中文解释:
1. <解释1>
2. <解释2>
3. <解释3>
部署 Skill
然后把这个文件夹放到:
~/.claude/skills/
里面。
如果没有 skills 文件夹,就自己创建一个。
部署完成后的路径:
skills
⎿ en-cn-dict
⎿ SKILL.md
加载 Skill
现在重启 claude code,然后问它:
查单词:tea
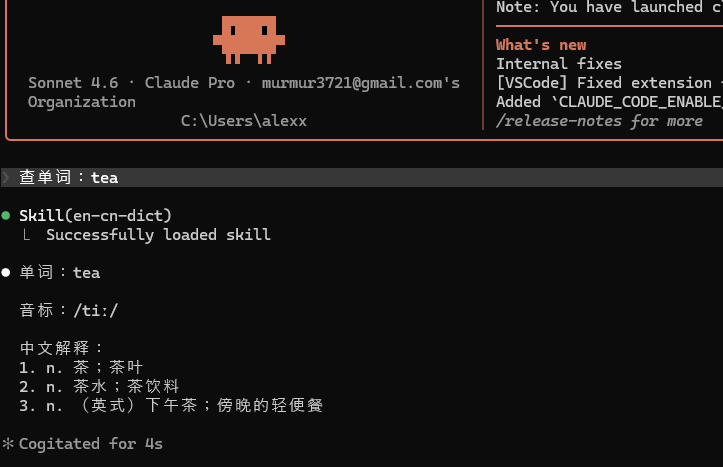
可以看到,它加载了 en-cn-dict 这个 Skill。
第一部分完成。
第二部分:真正的 Skill 编写方式
AI 时代最大的改变之一就是:
不要自己手写代码。
我们一定要慢慢改掉"所有东西都手写"的习惯。
其实 Skill 也一样,应该让 AI 自己去写。
比如我们这个查单词 Skill,本来就应该让 agent 自己生成。
如果你用的是 codex、openclaw、claude code 这种 agent 工具,你甚至可以直接让 agent 完成整个 Skill 的构建过程。
如果你只有 ChatGPT、Claude、Gemini 这种 chat app,那你就手动创建文件,然后让 chat app 告诉你 SKILL.md 该怎么写。
我这里用 claude code 演示创建 Skill。
我对 claude code 说:

claude code 帮我把 Skill 文件创建好了:
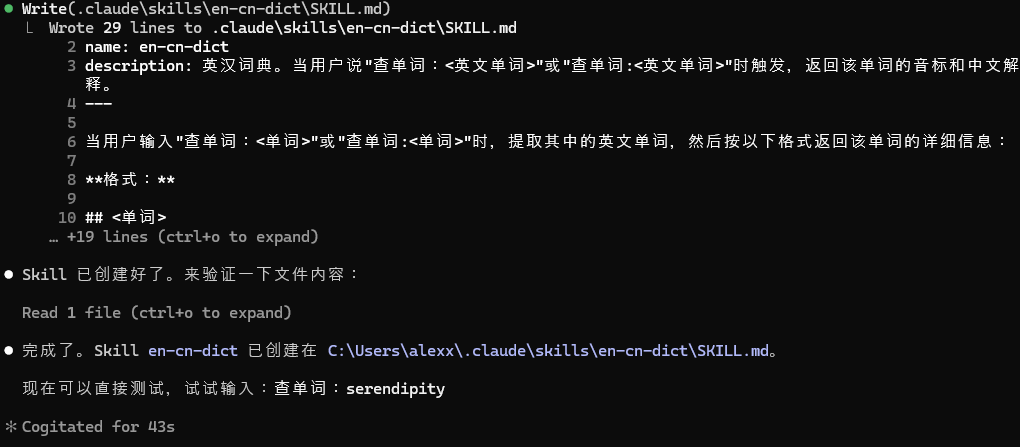
现在测试一下。
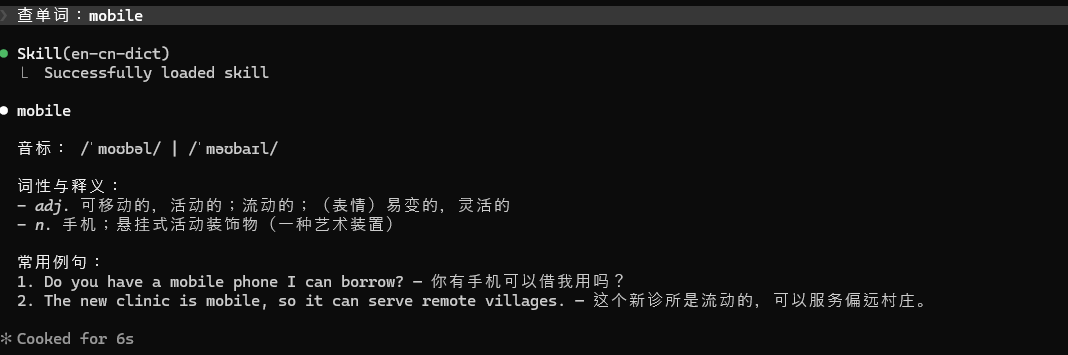
成功了。
不过它还是输出了一些我们没要求的内容。
AI 写代码就是会自由发挥。不过没关系,多出来的东西如果你不要,就继续让它删掉就好了。
第三部分:编写 Skill 的常用模式和问题
触发词
在这个例子里,我用了"触发词"的模式。
因为 agent 本质上是一个什么都能聊的对话框。什么都能说的代价,就是很容易混乱。
有时候 agent 并不能自动判断该使用哪个 Skill。
这时候你就可以通过"触发词"来缩小范围,精准定位要使用的 Skill。
这个触发词,有点像你手机里的一个 App 图标。你通过触发词,把 agent 导航到对应的 Skill。
如果你去看别的 Skill 入门教程,多半会看到"总结会议内容"这种例子。
那些教程里的 Skill 经常会写:
直接说"帮我总结会议"或类似请求
这里其实有两个问题:
- 太长,不好记
- "或类似请求"以后会给你带来麻烦
你的 Skill 最好有一个:
- 简短
- 明确
- 不歧义
的触发词。
因为当你的 Skill 越来越多的时候,"类似请求"这种模糊匹配,会慢慢变成不确定因素。
触发词抢夺
有了触发词,就会有"触发词抢夺"问题。
我在 openclaw 里做这个例子的时候,它死活不按我的 Skill 来。
原因是:
我的 openclaw 用的是 OpenAI 的 API。
而"查单词:"这个词,在我使用的 model 里,本身就有很高的默认优先级。
这个 model 每次看到"查单词",就会强行用自己的理解来处理。
这种现象,我把它叫做:
“触发词抢夺”。
如果遇到这种问题,也不用慌。
因为这通常说明:
其实 model 自己已经能很好地完成这件事了。
你甚至可能根本不需要专门做这个 Skill。
如果你真的想强制自定义,就换一个非常特殊、不容易被模型误判的触发词。
Skill 标记模式
如果你用的是 claude code,它会显式告诉你调用了什么 Skill。
但如果你用的是别的工具,比如 openclaw,它通常不会告诉你到底用了哪个 Skill。
这样就会让人很不安心。
你根本不知道它到底有没有调用你的 Skill。
这时候,你可以在 Skill 输出的最后,强制加一句:
使用了 [xxx skill]
这样你就能知道:
它到底有没有真正调用你的 Skill。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)