【扩散模型原理】(四)Diffusion Models Today: Score SDE Framework(1)
《扩散模型原理:从起源到发展》:第四章 扩散模型的今天:Score SDE 框架
专著:The Principles of Diffusion Models
上一章:【扩散模型原理】(三)Score-Based Perspective: From EBMs to NCSN
Diffusion Models Today: Score SDE Framework
到目前为止,我们已经从两个视角研究了扩散模型:变分视角与基于得分的视角,后者自然地从基于能量的模型(EBM)的公式化中衍生而来。现在我们将迈出下一步,转向连续时间框架。该框架的核心是得分随机微分方程(Score SDE)—— 这一连续极限将 DDPM 与 NCSN 统一为单一的数学表述。
这一视角的强大之处在于,它以微分方程(DE)为基础,用清晰、原理性的描述拓展了离散更新。在该视角下,生成过程被简化为求解一个随时间演化的微分方程。这让我们可以直接应用数值分析中的工具:例如,基础的欧拉法可用于模拟动力学过程,而更先进的求解器则能提升稳定性与效率。
Figure 4.1 | 离散时间加噪步骤示意图:该图展示了从时刻 t t t 到 t + Δ t t+Δt t+Δt 的噪声添加过程,其漂移系数为 f ( x t , t ) \mathbf{f}(\mathbf{x}_t, t) f(xt,t),扩散系数为 g ( t ) g(t) g(t);
4.1 得分 SDE :它的原理(Score SDE: Its Principles)
多噪声尺度的使用,是 NCSN 与 DDPM 框架取得成功的核心要素。在本节中,我们将介绍得分随机微分方程(Score SDE)(Song et al., 2020c)的理论基础:该方法通过考虑连续的噪声尺度谱,对这一核心思想进行了拓展。
前向与反向扩散过程的连续时间极限,其实早已由 Sohl-Dickstein et al. (2015) 提出;但 Song et al. (2020c) 将这一视角置于核心地位,通过将数据演化建模为随机 / 常微分方程,实现了噪声水平随时间的平滑递增。
这种连续时间的公式化表述,不仅统一了此前的离散时间模型,还为生成式建模提供了一套原理清晰、灵活通用的理论基础 —— 将生成问题转化为了求解微分方程的问题。
4.1.1 动机:从离散时间过程到连续时间过程(Motivation: From Discrete to Continuous-Time Processes)
我们重新审视 NCSN 与 DDPM 的前向加噪方案。NCSN 采用一组递增的噪声水平 { σ i } i = 1 L \{\sigma_i\}_{i=1}^L {σi}i=1L,对每个干净样本 x ∼ p d a t a \mathbf{x}∼p_{data} x∼pdata 进行如下扰动:
x σ i = x + σ i ϵ i , ϵ i ∼ N ( 0 , I ) \mathbf{x}_{\sigma_i} = \mathbf{x} + \sigma_i \boldsymbol{\epsilon}_i, \quad \boldsymbol{\epsilon}_i \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xσi=x+σiϵi,ϵi∼N(0,I)DDPM 则通过方差调度 { β i } i = 1 L \{\beta_i\}_{i=1}^L {βi}i=1L 逐步注入噪声:
x i = 1 − β i 2 x i − 1 + β i ϵ i , ϵ i ∼ N ( 0 , I ) \mathbf{x}_i = \sqrt{1 - \beta_i^2} \mathbf{x}_{i-1} + \beta_i \boldsymbol{\epsilon}_i, \quad \boldsymbol{\epsilon}_i \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) xi=1−βi2xi−1+βiϵi,ϵi∼N(0,I)
我们将二者置于同一离散时间网格下分析,其中从 x t \mathbf{x}_t xt 到 x t + Δ t \mathbf{x}_{t+Δt} xt+Δt 的顺序更新形式为:
NCSN: x t + Δ t = x t + σ t + Δ t 2 − σ t 2 ϵ t ≈ x t + d σ t 2 d t Δ t ϵ t \text{NCSN:} \quad\quad \mathbf{x}_{t+\Delta t} = \mathbf{x}_t + \sqrt{\sigma_{t+\Delta t}^2 - \sigma_t^2}\boldsymbol{\epsilon}_t \quad \approx \mathbf{x}_t + \sqrt{\frac{\mathrm{d}\sigma_t^2}{\mathrm{d}t}\Delta t}\boldsymbol{\epsilon}_t NCSN:xt+Δt=xt+σt+Δt2−σt2ϵt≈xt+dtdσt2Δtϵt DDPM: x t + Δ t = 1 − β t x t + β t ϵ t ≈ x t − 1 2 β t x t Δ t + β t Δ t ϵ t \text{DDPM:} \quad\quad \mathbf{x}_{t+\Delta t} = \sqrt{1-\beta_t}\mathbf{x}_t + \sqrt{\beta_t}\boldsymbol{\epsilon}_t \quad \approx \mathbf{x}_t - \frac{1}{2}\beta_t\mathbf{x}_t\Delta t + \sqrt{\beta_t\Delta t}\boldsymbol{\epsilon}_t DDPM:xt+Δt=1−βtxt+βtϵt≈xt−21βtxtΔt+βtΔtϵt其中 ϵ t ∼ N ( 0 , I ) \boldsymbol{\epsilon}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) ϵt∼N(0,I)。值得注意的是,两种加噪过程遵循统一的结构形式: x t + Δ t ≈ x t + f ( x t , t ) Δ t + g ( t ) Δ t ϵ t , (4.1.1) \mathbf{x}_{t+\Delta t} \approx \mathbf{x}_t + \mathbf{f}(\mathbf{x}_t, t)\Delta t + g(t)\sqrt{\Delta t}\boldsymbol{\epsilon}_t, \tag{4.1.1} xt+Δt≈xt+f(xt,t)Δt+g(t)Δtϵt,(4.1.1)其中 f : R D × R → R D \mathbf{f}:\mathbb{R}^D×\mathbb{R}→\mathbb{R}^D f:RD×R→RD, g : R → R g:\mathbb{R}→\mathbb{R} g:R→R,具体定义如下:
NCSN: f ( x , t ) = 0 , g ( t ) = d σ 2 ( t ) d t \text{NCSN:} \quad\quad \mathbf{f}(\mathbf{x}, t) = 0, \quad g(t) = \sqrt{\frac{\mathrm{d}\sigma^2(t)}{\mathrm{d}t}} NCSN:f(x,t)=0,g(t)=dtdσ2(t) DDPM: f ( x , t ) = − 1 2 β ( t ) x , g ( t ) = β ( t ) . \text{DDPM:} \quad\quad \mathbf{f}(\mathbf{x}, t) = -\frac{1}{2}\beta(t)\mathbf{x}, \quad g(t) = \sqrt{\beta(t)}. DDPM:f(x,t)=−21β(t)x,g(t)=β(t).该公式对应如下高斯转移分布:
p ( x t + Δ t ∣ x t ) : = N ( x t + Δ t ; x t + f ( x t , t ) Δ t , g 2 ( t ) Δ t I ) (4.1.2) p(\mathbf{x}_{t+\Delta t}|\mathbf{x}_t) := \mathcal{N}\left(\mathbf{x}_{t+\Delta t}; \mathbf{x}_t + \mathbf{f}(\mathbf{x}_t, t)\Delta t, g^2(t)\Delta t\mathbf{I}\right) \tag{4.1.2} p(xt+Δt∣xt):=N(xt+Δt;xt+f(xt,t)Δt,g2(t)ΔtI)(4.1.2) 此处为简化表述,我们将 x t \mathbf{x}_t xt 视为固定样本, x t + Δ t \mathbf{x}_{t+Δt} xt+Δt 视为随机变量。
当 Δ t → 0 Δt→0 Δt→0(可从概念上理解为引入无穷多层噪声)时,离散时间过程收敛为一个随时间向前演化的连续时间随机微分方程(SDE): d x ( t ) = f ( x ( t ) , t ) d t + g ( t ) d w ( t ) \mathrm{d}\mathbf{x}(t) = \mathbf{f}(\mathbf{x}(t), t)\mathrm{d}t + g(t)\mathrm{d}\mathbf{w}(t) dx(t)=f(x(t),t)dt+g(t)dw(t) 其中 w ( t ) \mathbf{w}(t) w(t) 为标准维纳过程(即布朗运动)。
备注(remark)
尽管此处无需给出完整的形式化定义,但仍说明如下:维纳过程是一个连续时间随机过程 w ( t ) \mathbf{w}(t) w(t),其满足以下性质:从零点开始,具有独立增量;且对任意 s < t s<t s<t,增量 w ( t ) − w ( s ) \mathbf{w}(t) - \mathbf{w}(s) w(t)−w(s) 服从均值为 0 0 0、方差为 t − s t−s t−s 的正态分布。该过程代表了随时间累积的独立高斯涨落。虽然它几乎必然连续,但处处不可导。
在无穷小时间区间 [ t , t + d t ] [t,t+dt] [t,t+dt] 上,维纳过程的增量被定义为:
d w ( t ) : = w ( t + d t ) − w ( t ) \mathrm{d}\mathbf{w}(t) := \mathbf{w}(t+\mathrm{d}t) - \mathbf{w}(t) dw(t):=w(t+dt)−w(t)
其可被建模为一个均值为 0 0 0、方差为 d t dt dt 的高斯随机变量:
d w ( t ) ∼ N ( 0 , d t I ) \mathrm{d}\mathbf{w}(t) \sim \mathcal{N}(\mathbf{0}, \mathrm{d}t\mathbf{I}) dw(t)∼N(0,dtI)
附录 A.2 节简要介绍了随机微分方程(SDE)的基础理论,附录 C 章则提供了更深入的进阶讨论。不过,我们可以从概念层面理解离散与连续公式化表述之间的对应关系如下:
x ( t + Δ t ) − x ( t ) ≈ d x ( t ) \mathbf{x}(t + \Delta t) - \mathbf{x}(t) \approx \mathrm{d}\mathbf{x}(t) x(t+Δt)−x(t)≈dx(t)
Δ t ≈ d t \Delta t \approx \mathrm{d}t Δt≈dt
Δ t ϵ t ∼ N ( 0 , Δ t I ) ≈ d w ( t ) \sqrt{\Delta t}\boldsymbol{\epsilon}_t \sim \mathcal{N}(\mathbf{0}, \Delta t\mathbf{I}) \approx \mathrm{d}\mathbf{w}(t) Δtϵt∼N(0,ΔtI)≈dw(t)
一旦确定了漂移项 f ( x , t ) \mathbf{f}(\mathbf{x}, t) f(x,t) 与扩散项 g ( t ) g(t) g(t),前向时间 SDE 会自动引出一个反向时间 SDE,该方程可将终端噪声分布逆向映射回数据分布。令人惊讶的是,反向动力学仅包含一个未知项:各连续时间尺度下的得分函数。这一结论将得分匹配确立为训练目标:一旦学习到得分函数,采样过程就等价于用学习到的得分对反向时间 SDE 进行数值积分。
4.1.2 前向时间随机微分方程:从数据到噪声(Forward-Time SDEs: From Data to Noise)
基于这一公式化表述,此前基于离散时间的方法(如 NCSN 与 DDPM ),均可在连续时间框架下得到统一:其对应一个由定义在时间区间 [ 0 , T ] [0,T] [0,T] 上的前向随机微分方程(SDE)所支配的随机过程 x ( t ) \mathbf{x}(t) x(t): d x ( t ) = f ( x ( t ) , t ) d t + g ( t ) d w ( t ) , x ( 0 ) ∼ p data , (4.1.3) \mathrm{d}\mathbf{x}(t) = \mathbf{f}(\mathbf{x}(t), t)\mathrm{d}t + g(t)\mathrm{d}\mathbf{w}(t), \quad \mathbf{x}(0) \sim p_{\text{data}}, \tag{4.1.3} dx(t)=f(x(t),t)dt+g(t)dw(t),x(0)∼pdata,(4.1.3)其中, f ( ⋅ , t ) : R D → R D \mathbf{f}(\cdot, t): \mathbb{R}^D \to \mathbb{R}^D f(⋅,t):RD→RD 为漂移项, g ( t ) ∈ R g(t) \in \mathbb{R} g(t)∈R 为标量扩散系数, w ( t ) \mathbf{w}(t) w(t) 表示标准维纳过程。我们将该式称为前向随机微分方程(forward SDE),它描述了干净数据如何随时间逐步被扰动为噪声的过程。
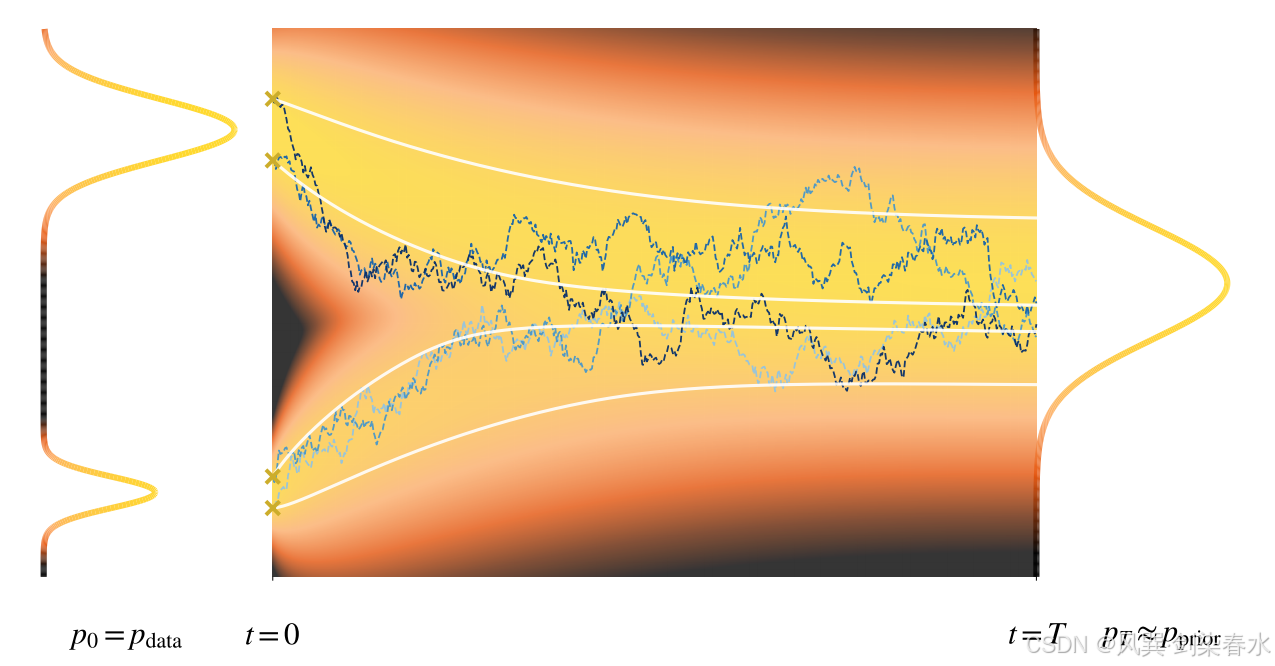
Figure 4.2 | 扩散模型前向过程的(一维)可视化:该过程从从复杂的双峰数据分布( p 0 = p data p_0 = p_{\text{data}} p0=pdata)中采样得到的初始点(标记为 “ × × ×”)开始,向一个简单的单峰高斯先验( p T ≈ p prior p_T \approx p_{\text{prior}} pT≈pprior)演化。背景热力图展示了随时间演化的边缘概率密度 p t p_t pt,其形态随时间逐渐变得平滑。图中展示了样本轨迹从 t = 0 t=0 t=0 到 t = T t=T t=T 的演化过程,对比了随机前向 SDE 过程(蓝色路径)与其确定性对应物 ——PF-ODE(白色路径)。需注意的是,PF-ODE 是用于密度的确定性传输映射,通常并非指从单点出发的样本路径均值;(从左往右)
一旦确定了漂移项 f \mathbf{f} f 与扩散系数 g g g,前向过程便被完全确定,描述了数据变量如何通过注入高斯噪声被逐步破坏。具体而言,该过程会诱导出两类时间依赖的概率密度:
扰动核。 条件分布:
p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0)描述了干净数据样本 x 0 ∼ p data \mathbf{x}_0 \sim p_{\text{data}} x0∼pdata 如何演化到时刻 t t t 对应的含噪样本 x t \mathbf{x}_t xt。一般而言,式 (4.1.3) 中的漂移项 f ( x , t ) \mathbf{f}(\mathbf{x}, t) f(x,t) 可以是 x \mathbf{x} x 的任意函数,但一种常用且便于解析求解的选择是假设其为仿射形式(漂移是线性的): f ( x , t ) = f ( t ) x , (4.1.4) \mathbf{f}(\mathbf{x}, t) = f(t)\mathbf{x}, \tag{4.1.4} f(x,t)=f(t)x,(4.1.4) 其中 f ( t ) f(t) f(t) 是关于 t t t 的标量函数,通常取非正值。 在该结构下,过程在任意时刻均保持高斯分布,且条件分布存在闭式解 —— 可通过求解对应的均值 - 方差常微分方程(ODE)得到(Särkkä and Solin, 2019,另见 4.3.3 节)。具体而言: p t ( x t ∣ x 0 ) = N ( x t ; m ( t ) , P ( t ) I D ) , p_t(\mathbf{x}_t|\mathbf{x}_0) = \mathcal{N}\left(\mathbf{x}_t; \mathbf{m}(t), P(t)\mathbf{I}_D\right), pt(xt∣x0)=N(xt;m(t),P(t)ID),其中
m ( t ) = exp ( ∫ 0 t f ( u ) d u ) x 0 , P ( t ) = ∫ 0 t exp ( 2 ∫ s t f ( u ) d u ) g 2 ( s ) d s \mathbf{m}(t) = \exp\left( \int_0^t f(u)\mathrm{d}u \right)\mathbf{x}_0, \quad\quad P(t) = \int_0^t \exp\left( 2\int_s^t f(u)\mathrm{d}u \right)g^2(s)\mathrm{d}s m(t)=exp(∫0tf(u)du)x0,P(t)=∫0texp(2∫stf(u)du)g2(s)ds初始条件为 m ( 0 ) = x 0 , P ( 0 ) = 0 \mathbf{m}(0) = \mathbf{x}_0, P(0) = 0 m(0)=x0,P(0)=0。
均值 m ( t ) \mathbf{m}(t) m(t): 初始值 x 0 \mathbf{x}_0 x0 被一个指数衰减因子缩放。如果 f ( u ) < 0 f(u)<0 f(u)<0,那么均值会随时间趋向于 0 0 0;
方差 P ( t ) I D P(t)\mathbf{I}_D P(t)ID: P ( t ) P(t) P(t) 积分表示:从 0 0 0 到 t t t 期间,每一步注入的噪声 g ( s ) d w g(s)dw g(s)dw 会被后续的漂移过程放大或缩小,最后累积成总方差;
该显式形式允许在给定 x 0 \mathbf{x}_0 x0 时直接采样 x t \mathbf{x}_t xt,无需对 SDE 进行数值积分,因此被称为 无模拟(simulation-free) 采样。NCSN 与 DDPM 均属于仿射漂移的范畴。
在后续内容中,我们将针对任意漂移项 f ( x , t ) \mathbf{f}(\mathbf{x}, t) f(x,t) 构建通用理论,但在需要闭式分析时会回到仿射漂移的情形。
当 SDE 的漂移项是线性函数 f ( t ) x f(t)\mathbf{x} f(t)x 时,扰动核 p t ( x t ∣ x 0 ) p_t(\mathbf{x}_t|\mathbf{x}_0) pt(xt∣x0) 是高斯的,且均值和方差有显式积分公式,从而可以直接采样 x t \mathbf{x}_t xt,无需模拟随机路径——这就是“无模拟采样”的核心。NCSN 和 DDPM 都符合这一特例。
边缘密度。 时间边缘密度 p t ( x t ) p_t(\mathbf{x}_t) pt(xt) 可通过对扰动核积分得到:
p t ( x t ) : = ∫ p t ( x t ∣ x 0 ) p data ( x 0 ) d x 0 , with p 0 = p data . (4.1.5) p_t(\mathbf{x}_t) := \int p_t(\mathbf{x}_t|\mathbf{x}_0)p_{\text{data}}(\mathbf{x}_0)\mathrm{d}\mathbf{x}_0, \quad \text{with } p_0 = p_{\text{data}}. \tag{4.1.5} pt(xt):=∫pt(xt∣x0)pdata(x0)dx0,with p0=pdata.(4.1.5) 通过合理选择系数 f ( t ) f(t) f(t) 与 g ( t ) g(t) g(t),前向过程会逐步添加噪声,直至初始状态的影响被完全遗忘。当 T T T 足够大时,条件分布 p T ( x T ∣ x 0 ) p_T(\mathbf{x}_T∣\mathbf{x}_0) pT(xT∣x0) 不再依赖于 x 0 \mathbf{x}_0 x0,这是因为其均值满足:
m ( T ) = exp ( ∫ 0 T f ( u ) d u ) x 0 ⟶ 0 , as T → ∞ , \mathbf{m}(T) = \exp\left( \int_0^T f(u)\mathrm{d}u \right)\mathbf{x}_0 \longrightarrow \mathbf{0}, \quad \text{as } T \to \infty, m(T)=exp(∫0Tf(u)du)x0⟶0,as T→∞,前提是 f ( u ) f(u) f(u) 为非正值,从而指数项衰减。与此同时,方差会增长并稳定到与预设先验分布匹配的水平。因此,边缘密度 p T ( x T ) = ∫ p T ( x T ∣ x 0 ) p data ( x 0 ) d x 0 , p_T(\mathbf{x}_T) = \int p_T(\mathbf{x}_T|\mathbf{x}_0)p_{\text{data}}(\mathbf{x}_0)\mathrm{d}\mathbf{x}_0, pT(xT)=∫pT(xT∣x0)pdata(x0)dx0,其初始为数据样本上的复杂混合分布,最终收敛为一个简单的先验分布 p p r i o r p_{prior} pprior(通常为高斯分布)。在该极限下, p T ( x T ) ≈ p prior ( x T ) and p T ( x T ∣ x 0 ) ≈ p prior ( x T ) , p_T(\mathbf{x}_T) \approx p_{\text{prior}}(\mathbf{x}_T) \quad \text{and} \quad p_T(\mathbf{x}_T|\mathbf{x}_0) \approx p_{\text{prior}}(\mathbf{x}_T), pT(xT)≈pprior(xT)andpT(xT∣x0)≈pprior(xT),因此前向过程可将任意数据分布映射为一个易于处理的先验分布,为反向过程与生成任务提供了便捷的起点。
4.1.3 用于生成的反向时间随机过程(Reverse-Time Stochastic Process for Generation)
Figure 4.3 | 用于数据生成的反向时间随机过程可视化:该过程从 t = T t=T t=T 时刻从简单的先验分布( p prior p_{\text{prior}} pprior)中抽取的样本开始(标记为 “ × × ×”),并利用反向 SDE(reverse-SDE)向时间反演演化。最终轨迹在 t = 0 t=0 t=0 时刻终止,并共同形成目标双峰数据分布( p 0 = p data p_0 = p_{\text{data}} p0=pdata)。背景热力图展示了概率密度如何从简单的高斯分布逐步变换为复杂的目标分布;(从右往左)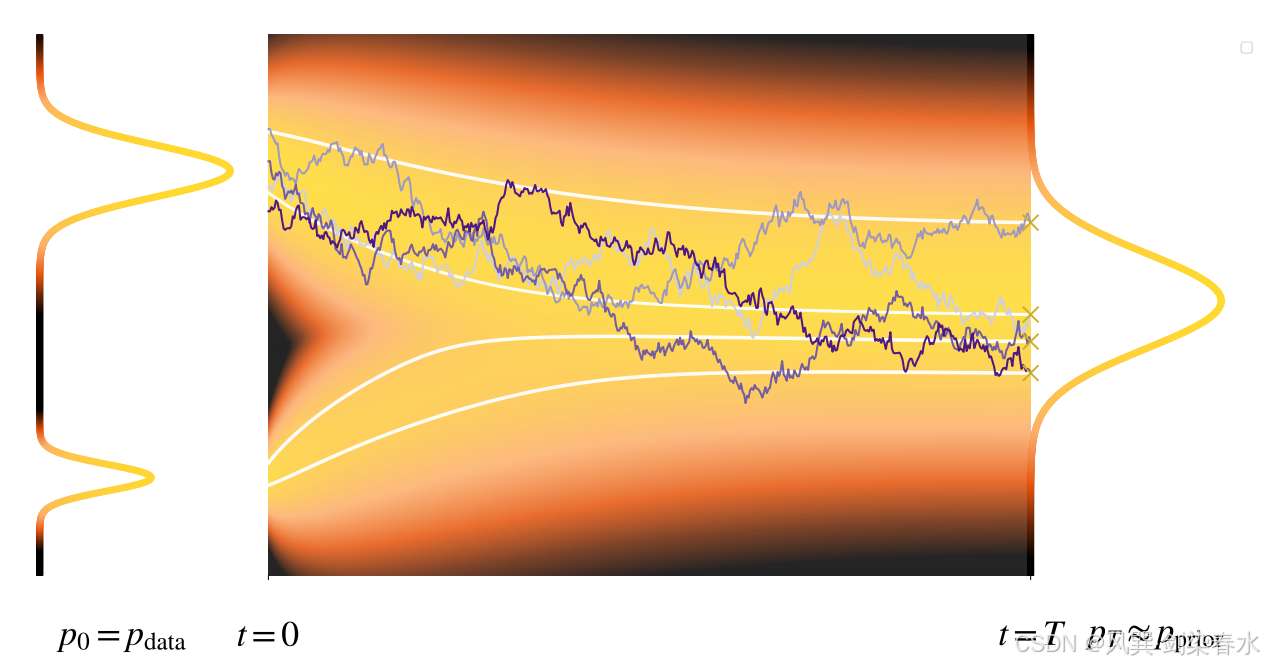
从直观上看,从噪声中生成数据可通过 “逆转” 前向过程实现:从先验分布中采样得到一个随机点,再令其向时间反演演化,即可得到生成样本。对于确定性系统(即常微分方程 ODE),这一思路自然成立。由于不涉及随机性,时间逆转仅意味着沿着与前向过程相同的路径反方向追踪点的轨迹。相比之下,随机微分方程(SDE)在每一步都引入了随机性,意味着单个点可以沿多条合理的随机轨迹演化。因此,逆转此类过程的逻辑更为微妙。
尽管单一的随机轨迹不可逆转,但一个极具价值的关键洞察是:这些轨迹上的分布可以被逆转。这一点由 Anderson (1982) 的基础性结论所形式化证明,该结论表明,式 ( 4.1.3 ) (4.1.3) (4.1.3) 中前向过程的时间逆转过程 { x ˉ ( t ) } t ∈ [ 0 , T ] \{\bar{\mathbf{x}}(t)\}_{t\in[0,T]} {xˉ(t)}t∈[0,T] 自身同样由一个定义良好的 SDE 所支配。该反向时间过程从 T T T 演化至 0 0 0,其动力学由下式给出:
d x ˉ ( t ) = [ f ( x ˉ ( t ) , t ) − g 2 ( t ) ∇ x log p t ( x ˉ ( t ) ) ] d t + g ( t ) d w ˉ ( t ) , x ˉ ( T ) ∼ p prior ≈ p T (4.1.6) \mathrm{d}\bar{\mathbf{x}}(t) = \left[ \mathbf{f}(\bar{\mathbf{x}}(t), t) - \textcolor{orange}{g^2(t)\nabla_{\mathbf{x}} \log p_t(\bar{\mathbf{x}}(t))} \right] \mathrm{d}t + g(t)\mathrm{d}\bar{\mathbf{w}}(t), \quad \bar{\mathbf{x}}(T) \sim p_{\text{prior}} \approx p_T \tag{4.1.6} dxˉ(t)=[f(xˉ(t),t)−g2(t)∇xlogpt(xˉ(t))]dt+g(t)dwˉ(t),xˉ(T)∼pprior≈pT(4.1.6) 此处, w ˉ ( t ) \bar{\mathbf{w}}(t) wˉ(t) 表示反向时间下的标准维纳过程,其定义为: w ˉ ( t ) : = w ( T − t ) − w ( T ) \bar{\mathbf{w}}(t) := \mathbf{w}(T-t) - \mathbf{w}(T) wˉ(t):=w(T−t)−w(T).
为了建立对式 ( 4.1.6 ) (4.1.6) (4.1.6) 的直观理解,我们在 4.1.6 4.1.6 4.1.6 节给出一个具体示例:采用高斯数据分布与线性 - 高斯动力学。该设定在解析上是可处理的:仅需基础微积分与线性代数即可直接推导出时间逆转公式,无需调用 Anderson (1982) 的完整通用理论。
需要注意的是,随机性的存在( g ≠ 0 g \neq 0 g=0)引入了一个额外的校正项 − g 2 ( t ) ∇ x log p t ( x ˉ ( t ) ) -g^2(t)\nabla_{\mathbf{x}} \log p_t(\bar{\mathbf{x}}(t)) −g2(t)∇xlogpt(xˉ(t)),该项用于描述扩散效应,并确保反向动力学能够正确复现前向 SDE 所诱导的边缘分布演化(详见 4.1.5 节)。
从概念上理解:反向过程为何有效? 4.5.2 节通过将反向时间 SDE 与 DDPM 变分框架建立联系,给出了该方程的直观推导(内容为选读,但极具启发性)。在此,我们补充说明反向时间动力学如何从噪声中恢复结构化数据的直观逻辑。
乍看之下,反向时间过程中存在布朗噪声似乎是一个悖论:既然前向扩散会将数据逐步扩散为越来越嘈杂的状态,那么逆转这一过程(尤其是通过 w ˉ ( t ) \bar{\mathbf{w}}(t) wˉ(t) 引入额外随机性),为何能生成集中在数据流形附近的干净、结构化样本?关键在于:反向时间 SDE 并不会注入任意随机性。扩散项 g ( t ) d w ˉ ( t ) g(t)\mathrm{d}\bar{\mathbf{w}}(t) g(t)dwˉ(t) 始终与得分驱动的漂移项 − g 2 ( t ) ∇ x log p t ( x ˉ ( t ) ) -g^2(t)\nabla_{\mathbf{x}} \log p_t(\bar{\mathbf{x}}(t)) −g2(t)∇xlogpt(xˉ(t)) 相互耦合。这两项共同实现了平衡:得分项引导轨迹向高密度区域(即真实数据分布)移动,而噪声项则引入可控的随机性,允许轨迹在不破坏动力学的前提下进行探索。
为了更清晰地说明这一点,我们回到式 (3.1.6) 中的朗之万直观解释。当 f ( t ) ≡ 0 f(t)≡0 f(t)≡0 时,式 (4.1.6) 可写为: d x ˉ ( t ) = − g 2 ( t ) ∇ x log p t ( x ˉ ( t ) ) d t + g ( t ) d w ˉ ( t ) . \mathrm{d}\bar{\mathbf{x}}(t) = -g^2(t)\nabla_{\mathbf{x}} \log p_t(\bar{\mathbf{x}}(t)) \mathrm{d}t + g(t)\mathrm{d}\bar{\mathbf{w}}(t). dxˉ(t)=−g2(t)∇xlogpt(xˉ(t))dt+g(t)dwˉ(t).通过 s : = T − t s:=T−t s:=T−t(因此 d t = − d s dt=−ds dt=−ds)对时间进行前向重参数化,并在分布意义上重命名布朗运动,使得 d w ˉ ( t ) = − d w s \mathrm{d}\bar{\mathbf{w}}(t) = -\mathrm{d}\mathbf{w}_s dwˉ(t)=−dws。令 x ˉ s : = x ˉ ( T − s ) \bar{\mathbf{x}}_s:=\bar{\mathbf{x}}(T−s) xˉs:=xˉ(T−s), π s : = p T − s π_s:=p_{T−s} πs:=pT−s,则可得:
d x ˉ s = g 2 ( T − s ) ∇ log π s ( x ˉ s ) d s + g ( T − s ) d w s = 2 τ ( s ) ∇ log π s ( x ˉ s ) d s + 2 τ ( s ) d w s , τ ( s ) : = 1 2 g 2 ( T − s ) . \begin{aligned} \mathrm{d}\bar{\mathbf{x}}_s &= g^2(T - s)\nabla \log \pi_s(\bar{\mathbf{x}}_s) \mathrm{d}s + g(T - s)\mathrm{d}\mathbf{w}_s \\ &= 2\tau(s)\nabla \log \pi_s(\bar{\mathbf{x}}_s) \mathrm{d}s + \sqrt{2\tau(s)}\mathrm{d}\mathbf{w}_s, \quad \tau(s) := \frac{1}{2}g^2(T - s). \end{aligned} dxˉs=g2(T−s)∇logπs(xˉs)ds+g(T−s)dws=2τ(s)∇logπs(xˉs)ds+2τ(s)dws,τ(s):=21g2(T−s).该式具有时变温度 τ ( s ) τ(s) τ(s) 的朗之万形式,其目标为随时间演化的密度 π s π_s πs。根据 Tweedie 公式(式 (3.3.6)),得分方向 ∇ log π s ∇\text{log}π_s ∇logπs 在每个时间切片上都指向条件干净信号,因此漂移项会持续 “拉回” 去噪后的结构。
至关重要的是, g ( t ) g(t) g(t) 在反向轨迹上是 退火 的:在初始阶段( s ≈ 0 s≈0 s≈0,即 t ≈ T t≈T t≈T), g ( T − s ) g(T−s) g(T−s) 通常取值较大,因此注入的噪声更强,过程会进行大范围探索;随着 s s s 增大, g ( T − s ) g(T−s) g(T−s) 减小,随机项减弱,得分项占据主导,将样本拉向 π s π_s πs 的高密度区域;到 s = T s=T s=T(即 t = 0 t=0 t=0)时,轨迹会集中在数据流形附近。
前期高噪声 → 广泛探索数据空间
后期低噪声 → 精细收敛到数据流形
得分函数始终提供正确的漂移方向,使得整个随机过程最终生成高质量的干净样本;
反向时间 SDE 的能力概述。 时间依赖的得分函数
s ( x , t ) : = ∇ x log p t ( x ) \mathbf{s}(\mathbf{x}, t) := \nabla_{\mathbf{x}} \log p_t(\mathbf{x}) s(x,t):=∇xlogpt(x)自然出现在式 ( 4.1.6 ) (4.1.6) (4.1.6) 中,这一点极具启发性。一旦确定了前向系数 f ( t ) f(t) f(t) 与 g ( t ) g(t) g(t),得分函数便是反向动力学中唯一的未知项。这凸显了其核心地位:掌握得分函数后,反向过程便被完全确定,采样过程等价于用学习到的得分对式 (4.1.6) 进行数值积分。
由于理论上的 “得分” 通常不存在闭式表达式,我们采用第 3 章的方法,训练一个神经网络 s ϕ ( x , t ) \mathbf{s}_\phi(\mathbf{x}, t) sϕ(x,t),通过得分匹配来近似该得分;详见 4.2.1 节。在式 ( 4.1.6 ) (4.1.6) (4.1.6) 中用 s ϕ ( x , t ) \mathbf{s}_\phi(\mathbf{x}, t) sϕ(x,t) 替代 s ( x , t ) \mathbf{s}(\mathbf{x}, t) s(x,t),即可完全确定反向动力学。
生成过程对应于从 t = T t=T t=T 出发(初始样本 x T ∼ p p r i o r x_T∼p_{prior} xT∼pprior),反向求解反向时间 SDE 直至 t = 0 t=0 t=0。重要的是,Anderson (1982) 证明了前向与反向过程的边缘密度是一致的,这确保了当 p p r i o r ≈ p T p_{prior}≈p_T pprior≈pT 时, t = 0 t=0 t=0 时刻的样本近似服从 p d a t a p_{data} pdata。我们将在 4.2.2 节进一步探讨这一点。
4.1.4 用于生成的确定性过程(概率流常微分方程)(Deterministic Process (Probability Flow ODE) for Generation)
尽管式 ( 4.1.6 ) (4.1.6) (4.1.6) 中的 SDE 引入了随机性,且有可能提升生成样本的多样性,但仍存在一个问题:
问题 4.1.1
是否必须使用式 ( 4.1.6 ) (4.1.6) (4.1.6) 中的 SDE 进行采样?
受 Maoutsa et al. (2020) 的启发,Song et al. (2020c) 还提出了一个确定性过程 —— 常微分方程 (ODE),其演化样本的边缘分布与前向 SDE 完全一致。该过程 { x ~ ( t ) } t ∈ [ 0 , T ] \{\tilde{\mathbf{x}}(t)\}_{t\in[0,T]} {x~(t)}t∈[0,T] 被称为概率流常微分方程(Probability Flow ODE, PF-ODE),其表达式为:
d d t x ~ ( t ) = f ( x ~ ( t ) , t ) − 1 2 g 2 ( t ) ∇ x log p t ( x ~ ( t ) ) . (4.1.7) \frac{\mathrm{d}}{\mathrm{d}t}\tilde{\mathbf{x}}(t) = \mathbf{f}(\tilde{\mathbf{x}}(t), t) - \frac{1}{2}g^2(t)\nabla_{\mathbf{x}} \log p_t(\tilde{\mathbf{x}}(t)). \tag{4.1.7} dtdx~(t)=f(x~(t),t)−21g2(t)∇xlogpt(x~(t)).(4.1.7) 与 SDE 的情形类似,我们可以用学习到的近似得分替代真实得分,并从 t = T t=T t=T 到 t = 0 t=0 t=0 对反向时间 ODE 进行积分以生成样本。具体而言,生成样本(即 PF-ODE 在 t = 0 t=0 t=0 时刻的解)的形式为:
x ~ ( T ) + ∫ T 0 [ f ( x ~ ( τ ) , τ ) − 1 2 g 2 ( τ ) ∇ x log p τ ( x ~ ( τ ) ) ] d τ , \tilde{\mathbf{x}}(T) + \int_T^0 \left[ \mathbf{f}(\tilde{\mathbf{x}}(\tau), \tau) - \frac{1}{2}g^2(\tau)\nabla_{\mathbf{x}} \log p_\tau(\tilde{\mathbf{x}}(\tau)) \right] \mathrm{d}\tau, x~(T)+∫T0[f(x~(τ),τ)−21g2(τ)∇xlogpτ(x~(τ))]dτ,其中初始条件为 x ~ ( T ) ∼ p prior \tilde{\mathbf{x}}(T) \sim p_{\text{prior}} x~(T)∼pprior。由于该积分不存在闭式解析解,实际生成过程依赖于数值求解器(例如欧拉法,详见式 (4.2.4))。
与反向时间 SDE 相比,PF-ODE 具有两大关键优势:
(1)ODE 可沿任一方向积分,即从 t = 0 t=0 t=0 到 t = T t=T t=T 或从 t = T t=T t=T 到 t = 0 t=0 t=0,且只需在选定的端点处指定相应的初始条件,即可使用同一形式的方程表达式。这种双向积分的特性与 SDE 形成对比,SDE 通常仅允许正向时间积分;
(2)它可依托大量为 ODE 开发的成熟、现成的数值求解器,应用范围广泛;
需要强调的是,PF-ODE 并非简单地删去式 ( 4.1.6 ) (4.1.6) (4.1.6) 中的扩散项得到;值得注意的是,其漂移项中的系数 1 2 \frac{1}{2} 21 具有严谨的理论渊源。从宏观层面来看,式 ( 4.1.7 ) (4.1.7) (4.1.7) 的构建思路是选取一个 ODE 的漂移项,使其演化过程与式 ( 4.1.3 ) (4.1.3) (4.1.3) 中的正向 SDE 保持相同的边缘密度。确保这种边缘分布一致性的底层原理(即福克 - 普朗克方程(Øksendal, 2003))将在下一节详细阐述。
4.1.5 正向/反向时间随机微分方程与概率流常微分方程中的边缘分布匹配(Matching Marginal Distributions in Forward/Reverse-Time SDEs and PF-ODE)
Figure 4.4 | (二维)边缘密度 p t p_t pt 的时间演化:该正向 SDE 满足 f ≡ 0 f \equiv 0 f≡0,且在区间 [ 0 , T ] [0, T] [0,T] 上 g ( t ) = 2 t g (t) = \sqrt {2t} g(t)=2t。初始分布 p 0 = p data p_0 = p_{\text {data}} p0=pdata,为双峰高斯混合分布;最终分布 p T ≈ p prior : = N ( 0 , T 2 I ) p_T \approx p_{\text {prior}} := \mathcal {N}(\mathbf {0}, T^2 \mathbf {I}) pT≈pprior:=N(0,T2I)。 p t p_t pt 的演化遵循福克 - 普朗克方程;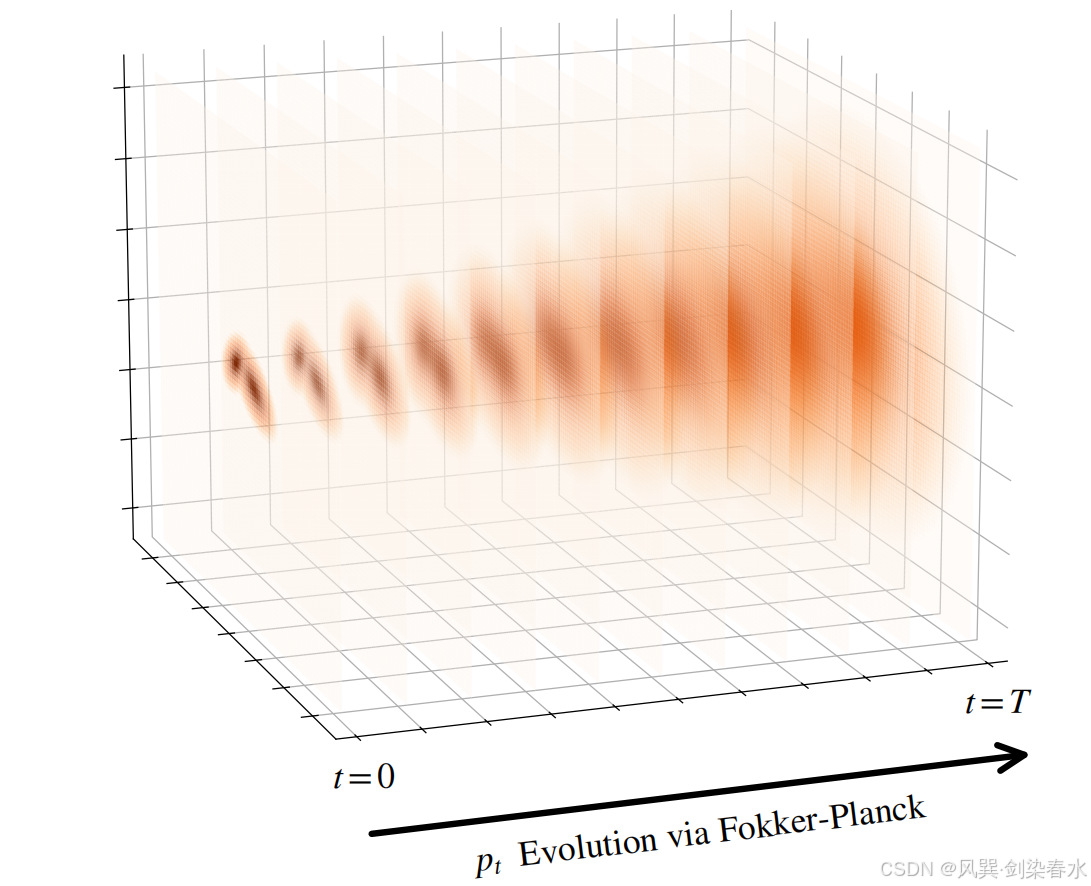
福克 - 普朗克方程:确保边缘密度的一致性。 扩散模型中的一个核心概念是:不同的随机过程可以产生相同的边缘分布序列(我们将在本小节后续部分对此进行说明)。我们的目标是构造一个过程,通过在整个时间维度(尤其是在 t = 0 t=0 t=0 时刻)对齐边缘分布,将 p p r i o r p_{prior} pprior 变换为 p d a t a p_{data} pdata。只要该过程是可处理的、支持高效采样,其具体形式就是次要的。这自然引出了一个根本性问题:
问题 4.1.2
如何确保不同的过程产生完全相同的边缘分布?
回到我们的设定:一旦正向 SDE 被确定,它就定义了从 p d a t a p_{data} pdata 到 p p r i o r p_{prior} pprior 的边缘密度演化。反向时间 SDE 与 PF-ODE 的构造,正是为了让它们的轨迹所产生的边缘分布,与正向过程的边缘分布完全匹配。这种对应关系的核心在于福克 - 普朗克方程,该方程描述了扩散过程下边缘密度的演化规律。下述定理(Anderson, 1982; Song et al., 2020c)为这一关联奠定了基础:


前向 SDE 的边缘分布 p t p_t pt 既可以用一个确定性常微分方程(PF-ODE)复现,也可以用反向时间 SDE 生成,它们共享完全相同的概率密度路径,只是表达方式不同。
固定边缘分布下的多条件分布。 为理解 PF-ODE 如何将 p d a t a p_{data} pdata 沿时间前向传输(或等价地将 p p r i o r p_{prior} pprior 反向传输),我们引入流映射 Ψ s → t : R D → R D \Psi_{s\to t}: \mathbb{R}^D \to \mathbb{R}^D Ψs→t:RD→RD,其中 Ψ s → t ( x s ) \Psi_{s\to t}(\mathbf{x}_s) Ψs→t(xs) 表示:以 s s s 时刻的 x s \mathbf{x}_s xs 为初始状态,PF-ODE 在 t t t 时刻的解,对任意 s , t ∈ [ 0 , T ] s,t∈[0,T ] s,t∈[0,T] 均成立。换言之,该映射将初始状态 x s \mathbf{x}_s xs 直接映射到其在 t t t 时刻的状态:
Ψ s → t ( x s ) : = x s + ∫ s t v ( x τ , τ ) d τ , (4.1.9) \Psi_{s\to t}(\mathbf{x}_s) := \mathbf{x}_s + \int_s^t \mathbf{v}(\mathbf{x}_\tau, \tau)\,\mathrm{d}\tau, \tag{4.1.9} Ψs→t(xs):=xs+∫stv(xτ,τ)dτ,(4.1.9)其中速度场定义为: v ( x , τ ) : = f ( x , τ ) − 1 2 g 2 ( τ ) ∇ x log p τ ( x ) . \mathbf{v}(\mathbf{x}, \tau) := \mathbf{f}(\mathbf{x}, \tau) - \frac{1}{2}g^2(\tau)\nabla_{\mathbf{x}} \log p_\tau(\mathbf{x}). v(x,τ):=f(x,τ)−21g2(τ)∇xlogpτ(x).在此,该积分捕捉了沿 PF-ODE 轨迹 x τ \mathbf{x}_\tau xτ 累积的净位移。在对速度场 v \mathbf{v} v 的轻微光滑性假设下,流映射 Ψ s → t : R D → R D \Psi_{s\to t}: \mathbb{R}^D \to \mathbb{R}^D Ψs→t:RD→RD 是一个光滑的双射(一一映射)。
想象每个数据点是一辆自动驾驶汽车,路面标有每个位置、每个时刻的“最优速度” v ( x , t ) v(x,t) v(x,t) 。汽车严格按这个速度行驶,那么从 s s s 时刻的位置到 t t t 时刻的位置,就是一条确定的轨迹。这个“从起点到终点”的对应关系就是流映射 Ψ s → t \Psi_{s\to t} Ψs→t;
对于任意 t ∈ [ 0 , T ] t∈[0,T] t∈[0,T],前推密度(pushforward density)定义为:
p t fwd ( x t ) : = ∫ δ ( x t − Ψ t → 0 ( x 0 ) ) p data ( x 0 ) d x 0 , p_t^{\text{fwd}}(\mathbf{x}_t) := \int \delta\left(\mathbf{x}_t - \Psi_{t\to 0}(\mathbf{x}_0)\right) p_{\text{data}}(\mathbf{x}_0) \mathrm{d}\mathbf{x}_0, ptfwd(xt):=∫δ(xt−Ψt→0(x0))pdata(x0)dx0,
如果初始时刻 s = 0 s=0 s=0,我们有一批汽车,它们的初始位置分布是真实数据分布 p d a t a p_{data} pdata。如果你知道每辆车从哪出发(初始位置分布),并且知道每辆车的确定性行驶路线(映射),那么你就能算出任意时刻路上车的分布——这就是前推密度。
记为 Ψ t → 0 # p data \Psi_{t\to 0}\# p_{\text{data}} Ψt→0#pdata,其表示在映射 Ψ t → 0 Ψ_{t→0} Ψt→0 作用下 t t t 时刻的分布。定理 4.1.1 保证了 p t fwd = p t p_t^{\text{fwd}}=p_t ptfwd=pt (确定性映射的前推分布 等于 随机扩散的边缘分布),其中 p t p_t pt 是前向 SDE 的边缘密度。这确立了确定性 PF-ODE 与随机核之间的等价关系:
p t ( x t ) = ∫ p t ( x t ∣ x 0 ) p data ( x 0 ) d x 0 = ∫ δ ( x t − Ψ t → 0 ( x 0 ) ) p data ( x 0 ) d x 0 . p_t(\mathbf{x}_t) = \int p_t(\mathbf{x}_t|\mathbf{x}_0) p_{\text{data}}(\mathbf{x}_0) \mathrm{d}\mathbf{x}_0 = \int \delta\left(\mathbf{x}_t - \Psi_{t\to 0}(\mathbf{x}_0)\right) p_{\text{data}}(\mathbf{x}_0) \mathrm{d}\mathbf{x}_0. pt(xt)=∫pt(xt∣x0)pdata(x0)dx0=∫δ(xt−Ψt→0(x0))pdata(x0)dx0.
PF-ODE 的流映射 Ψ s → t \Psi_{s\to t} Ψs→t 将初始数据分布确定性前推到任意时刻,其前推分布恰好等于原随机 SDE 的边缘分布,因此我们可以用这个确定性的 ODE 替代随机过程进行生成或推断;
这意味着存在无穷多组条件分布 Q t ( x t ∣ x 0 ) Q_t(\mathbf{x}_t|\mathbf{x}_0) Qt(xt∣x0),均可得到相同的边缘分布 p t ( x t ) p_t(\mathbf{x}_t) pt(xt),例如:
随机型(无模拟): Q t ( x t ∣ x 0 ) = p t ( x t ∣ x 0 ) Q_t(\mathbf{x}_t|\mathbf{x}_0) = p_t(\mathbf{x}_t|\mathbf{x}_0) Qt(xt∣x0)=pt(xt∣x0)
确定型(需求解 ODE): Q t ( x t ∣ x 0 ) = δ ( x t − Ψ t → 0 ( x 0 ) ) Q_t(\mathbf{x}_t|\mathbf{x}_0) = \delta\left(\mathbf{x}_t - \Psi_{t\to 0}(\mathbf{x}_0)\right) Qt(xt∣x0)=δ(xt−Ψt→0(x0))
混合型: Q t ( x t ∣ x 0 ) = λ p t ( x t ∣ x 0 ) + ( 1 − λ ) δ ( x t − Ψ t → 0 ( x 0 ) ) , λ ∈ [ 0 , 1 ] Q_t(\mathbf{x}_t|\mathbf{x}_0) = \lambda p_t(\mathbf{x}_t|\mathbf{x}_0) + (1-\lambda)\delta\left(\mathbf{x}_t - \Psi_{t\to 0}(\mathbf{x}_0)\right),\ \lambda \in [0,1] Qt(xt∣x0)=λpt(xt∣x0)+(1−λ)δ(xt−Ψt→0(x0)), λ∈[0,1]
Q t ( x t ∣ x 0 ) Q_t(\mathbf{x}_t|\mathbf{x}_0) Qt(xt∣x0) 的这种非唯一性源于:边缘约束无法唯一确定条件分布。这一概念将在 5.2.2 节与 9.2.3 节中再次出现。特别地,存在一整族反向时间 SDE,它们均与同一个边缘分布 p t p_t pt 相容。
观测 4.1.1:匹配预设边缘密度
多个过程均可生成相同的边缘密度序列;真正关键的是满足福克 - 普朗克方程。这一基础性洞见为我们设计生成过程提供了极大的灵活性,可实现从 p p r i o r p_{prior} pprior 到 p data p_{\text{data}} pdata(或反之)的分布转换。
福克 - 普朗克方程是扩散模型的核心,其理论根基是概率密度的变量代换公式(详见附录 B 的系统推导)。这一原理绝非次要的技术细节,而是贯穿全书理论构建的核心思想,在 5.2 节中体现得尤为突出。
4.1.6 一个可计算的示例:高斯动力学的演化(A Computable Example: Evolutions of Gaussian Dynamics)
当 p d a t a p_{data} pdata 服从正态分布(或高斯混合分布)时,得分函数存在闭式表达式。这使其成为理解扩散过程的理想场景:我们仅需基础微积分,即可显式推导逆时随机微分方程(SDE)与概率流常微分方程(PF-ODE),无需借助高等数学工具。在本小节中,我们将展示这些方程在这类易求解情形下的表现形式。
高斯分布下逆时 SDE 的精确计算。 当 p d a t a p_{data} pdata 服从高斯分布时,式 ( 4.1.6 ) (4.1.6) (4.1.6) 中的公式可直接推导,无需依赖 Anderson (1982) 的通用理论与证明。为阐明核心思想,我们以一维情形为例进行说明,向高维的推广遵循完全相同的逻辑。
从正向 SDE 出发:
d x ( t ) = f ( t ) x ( t ) d t + g ( t ) d w t , \mathrm{d}x(t) = f(t)x(t) \mathrm{d}t + g(t) \mathrm{d}w_t, dx(t)=f(t)x(t)dt+g(t)dwt,取步长为 Δ t > 0 Δt>0 Δt>0 的一个小欧拉步:
x t + Δ t = a x t + r ϵ , x_{t+\Delta t} = a x_t + r \epsilon, xt+Δt=axt+rϵ,其中 a : = 1 + f ( t ) Δ t a := 1 + f(t)\Delta t a:=1+f(t)Δt, r : = g ( t ) Δ t r := g(t)\sqrt{\Delta t} r:=g(t)Δt,且 ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0,1) ϵ∼N(0,1)。等价地,正向单步转移核服从高斯分布:
x t + Δ t ∣ x t ∼ N ( a x t , r 2 ) . x_{t+\Delta t}|x_t \sim \mathcal{N}(a x_t, r^2). xt+Δt∣xt∼N(axt,r2).由于假设 p data p_{\text{data}} pdata 服从高斯分布, t t t 时刻的当前边缘分布也服从高斯分布,对于某些标量 m t m_t mt 和 s t s_t st 而言,其形式如下:
x t ∼ N ( m t , s t 2 ) , x_t \sim \mathcal{N}(m_t, s_t^2), xt∼N(mt,st2),因此,条件分布的求解等价于将两个高斯分布相乘并进行归一化处理。这使得相关代数运算保持基础简便。
根据贝叶斯定理,在不计常数的情况下,条件密度为先验分布与转移核的乘积:
p ( x t ∣ x t + Δ t ) ∝ p ( x t + Δ t ∣ x t ) p t ( x t ) ∝ exp ( − ( x t − m t ) 2 2 s t 2 ) exp ( − ( x t + Δ t − a x t ) 2 2 r 2 ) . p(x_t \mid x_{t+\Delta t}) \propto p(x_{t+\Delta t} \mid x_t)p_t(\mathbf{x}_t) \propto \exp\left(-\frac{(x_t-m_t)^2}{2s_t^2}\right)\exp\left(-\frac{(x_{t+\Delta t}-ax_t)^2}{2r^2}\right). p(xt∣xt+Δt)∝p(xt+Δt∣xt)pt(xt)∝exp(−2st2(xt−mt)2)exp(−2r2(xt+Δt−axt)2).该指数项是关于 x t x_t xt 的二次式。展开两个平方项并合并同类项后,可明确得到关键的系数表达式:
− 2 log p ( x t ∣ x t + Δ t ) = A x t 2 − 2 B x t + const , -2\log p(x_t|x_{t+\Delta t})=A x_t^2 - 2B x_t + \text{const}, −2logp(xt∣xt+Δt)=Axt2−2Bxt+const,其中,
A : = 1 s t 2 + a 2 r 2 , B : = m t s t 2 + a x t + Δ t r 2 A := \frac{1}{s_t^2} + \frac{a^2}{r^2}, \quad B := \frac{m_t}{s_t^2} + \frac{a x_{t+\Delta t}}{r^2} A:=st21+r2a2,B:=st2mt+r2axt+Δt其中 A A A 是精度之和(先验精度与经 a a a 变换后的转移核精度之和), B B B 是对应的精度加权目标和。基于这些系数,通过配方法可直接得到后验分布:
A x t 2 − 2 B x t = A ( x t − B A ) 2 − B 2 A , A x_t^2 - 2B x_t = A\left(x_t - \frac{B}{A}\right)^2 - \frac{B^2}{A}, Axt2−2Bxt=A(xt−AB)2−AB2,因此条件分布为高斯分布,其方差为 1 / A 1/A 1/A,均值为 B / A B/A B/A:
V a r ( x t ∣ x t + Δ t ) = 1 1 s t 2 + a 2 r 2 , E [ x t ∣ x t + Δ t ] = m t s t 2 + a x t + Δ t r 2 1 s t 2 + a 2 r 2 . \mathrm{Var}(x_t|x_{t+\Delta t}) = \frac{1}{\frac{1}{s_t^2} + \frac{a^2}{r^2}}, \quad \mathbb{E}[x_t|x_{t+\Delta t}] = \frac{\frac{m_t}{s_t^2} + \frac{a x_{t+\Delta t}}{r^2}}{\frac{1}{s_t^2} + \frac{a^2}{r^2}}. Var(xt∣xt+Δt)=st21+r2a21,E[xt∣xt+Δt]=st21+r2a2st2mt+r2axt+Δt.这些闭式表达式已可描述任意小 Δ t Δt Δt 下的逆向转移。为推导出逆时随机微分方程(SDE),我们接下来对其在小 Δ t Δt Δt 下进行展开。
令 a = 1 + f ( t ) Δ t a = 1 + f(t)\Delta t a=1+f(t)Δt 且 r 2 = g 2 ( t ) Δ t r^2 = g^2(t)\Delta t r2=g2(t)Δt。当 Δ t → 0 Δt→0 Δt→0 时,项 a 2 r 2 ∼ 1 g 2 ( t ) Δ t \frac{a^2}{r^2} \sim \frac{1}{g^2(t)\Delta t} r2a2∼g2(t)Δt1 对精度起主导作用,因此方差变为:
V a r ( x t ∣ x t + Δ t ) = ( 1 s t 2 + a 2 r 2 ) − 1 = g 2 ( t ) Δ t + O ( Δ t 2 ) , \mathrm{Var}(x_t|x_{t+\Delta t}) = \left(\frac{1}{s_t^2} + \frac{a^2}{r^2}\right)^{-1}=g^2(t)\Delta t + \mathcal{O}(\Delta t^2), Var(xt∣xt+Δt)=(st21+r2a2)−1=g2(t)Δt+O(Δt2),这表明逆向步与正向步具有相同的扩散尺度 g ( t ) g(t) g(t)。对于均值,将比率 B / A B/A B/A 展开至一阶项:
E [ x t ∣ x t + Δ t ] = x t + Δ t + Δ t [ − ( f ( t ) + g 2 ( t ) s t 2 ) x t + Δ t + g 2 ( t ) s t 2 m t ] + O ( Δ t 2 ) . \mathbb{E}[x_t|x_{t+\Delta t}]=x_{t+\Delta t} + \Delta t \left[ -\left(f(t) + \frac{g^2(t)}{s_t^2}\right)x_{t+\Delta t} + \frac{g^2(t)}{s_t^2}m_t \right] + \mathcal{O}(\Delta t^2). E[xt∣xt+Δt]=xt+Δt+Δt[−(f(t)+st2g2(t))xt+Δt+st2g2(t)mt]+O(Δt2). 将均值与方差结合,可得到单步逆向转移核:
x t ∣ x t + Δ t ∼ N ( x t + Δ t + Δ t [ − ( f + g 2 s t 2 ) x t + Δ t + g 2 s t 2 m t ] , g 2 Δ t ) + O ( Δ t 2 ) . x_t|x_{t+\Delta t} \sim \mathcal{N}\left(x_{t+\Delta t} + \Delta t\left[-\left(f + \frac{g^2}{s_t^2}\right)x_{t+\Delta t} + \frac{g^2}{s_t^2}m_t\right], g^2\Delta t\right) + \mathcal{O}(\Delta t^2). xt∣xt+Δt∼N(xt+Δt+Δt[−(f+st2g2)xt+Δt+st2g2mt],g2Δt)+O(Δt2).该形式可识别为从 t + Δ t t+Δt t+Δt 向 t t t 反向运行的欧拉 - 丸山更新:
x t − x t + Δ t = Δ t [ − ( f + g 2 s t 2 ) x t + Δ t + g 2 s t 2 m t ] + g Δ t ϵ + O ( Δ t 2 ) . x_t - x_{t+\Delta t} = \Delta t\left[-\left(f + \frac{g^2}{s_t^2}\right)x_{t+\Delta t} + \frac{g^2}{s_t^2}m_t\right] + g\sqrt{\Delta t}\epsilon + \mathcal{O}(\Delta t^2). xt−xt+Δt=Δt[−(f+st2g2)xt+Δt+st2g2mt]+gΔtϵ+O(Δt2).令 Δ t → 0 \Delta t \to 0 Δt→0,可得原时间尺度下的随机微分方程(路径沿时间递减):
d x ( t ) = [ − ( f ( t ) + g 2 ( t ) s t 2 ) x ( t ) + g 2 ( t ) s t 2 m t ] d t + g ( t ) d w ˉ t . \mathrm{d}x(t) = \left[ -\left(f(t)+\frac{g^2(t)}{s_t^2}\right)x(t)+\frac{g^2(t)}{s_t^2}m_t \right]\mathrm{d}t+g(t)\mathrm{d}\bar{w}_t. dx(t)=[−(f(t)+st2g2(t))x(t)+st2g2(t)mt]dt+g(t)dwˉt.该漂移项可通过得分函数表示。对于高斯边缘分布 p t = N ( m t , s t 2 ) p_t = \mathcal{N}(m_t, s_t^2) pt=N(mt,st2),有:
∂ x log p t ( x ) = − x − m t s t 2 ⟹ − ( f + g 2 s t 2 ) x + g 2 s t 2 m t = − f x + g 2 ∂ x log p t ( x ) . \partial_x \log p_t(x) = -\frac{x-m_t}{s_t^2} \implies -\left(f+\frac{g^2}{s_t^2}\right)x+\frac{g^2}{s_t^2}m_t = -fx+g^2\partial_x \log p_t(x). ∂xlogpt(x)=−st2x−mt⟹−(f+st2g2)x+st2g2mt=−fx+g2∂xlogpt(x).为给出标准的时间正向、过程反向参数化形式,定义反向过程 x ˉ ( t ) : = x ( T − t ) \bar{x}(t) := x(T-t) xˉ(t):=x(T−t)(即沿时间 t t t 正向演化)。经时间反转变换后,漂移项化为:
d x ˉ ( t ) = [ f ( t ) x ˉ ( t ) − g 2 ( t ) ∂ x log p t ( x ˉ ( t ) ) ] d t + g ( t ) d w ˉ t , \mathrm{d}\bar{x}(t) = \left[ f(t)\bar{x}(t)-g^2(t)\partial_x \log p_t(\bar{x}(t)) \right]\mathrm{d}t+g(t)\mathrm{d}\bar{w}_t, dxˉ(t)=[f(t)xˉ(t)−g2(t)∂xlogpt(xˉ(t))]dt+g(t)dwˉt,其中 x ˉ ( T ) ∼ p prior ≈ p T \bar{x}(T) \sim p_{\text{prior}} \approx p_T xˉ(T)∼pprior≈pT,此即为标准的时间反向随机微分方程。在向量形式下,将一维导数替换为梯度 ∇ x log p t \nabla_{\boldsymbol{x}} \log p_t ∇xlogpt,即可与通式 (4.1.6) 完全对应。
高斯情形下 PF‑ODE 的精确求解。 当假设数据分布服从高斯分布时,可直接推导 PF‑ODE 的表达式,从而规避福克‑普朗克方程等复杂理论工具。最终可验证,PF‑ODE 的边缘密度与正向随机微分方程、时间反向随机微分方程的边缘密度完全一致,由此可对 4.1.5 节介绍的福克‑普朗克理论进行构造性验证。
设 t t t 时刻状态满足 x t ∼ N ( m t , s t 2 ) x_t \sim \mathcal{N}(m_t,s_t^2) xt∼N(mt,st2)。步长为 Δ t \Delta t Δt 的微小确定性演化可表示为光滑映射:
x t + Δ t = Φ t , Δ t ( x t ) = x t + Δ t v t ( x t ) + O ( Δ t 2 ) , x_{t+\Delta t} = \Phi_{t,\Delta t}(x_t) = x_t + \Delta t\,v_t(x_t) + \mathcal{O}(\Delta t^2), xt+Δt=Φt,Δt(xt)=xt+Δtvt(xt)+O(Δt2),该式本质为关于 Δ t \Delta t Δt 的一阶泰勒展开。我们的目标是确定 v t v_t vt 需满足的形式,使得只要输入服从高斯分布,输出也保持高斯分布。
为此,将 v t v_t vt 在当前均值 m t m_t mt 处进行泰勒展开:
v t ( x ) = v t ( m t ) + v t ′ ( m t ) ( x − m t ) + 1 2 v t ′ ′ ( m t ) ( x − m t ) 2 + ⋯ . v_t(x)=v_t(m_t)+v_t'(m_t)(x-m_t)+\frac12v_t''(m_t)(x-m_t)^2+\cdots. vt(x)=vt(mt)+vt′(mt)(x−mt)+21vt′′(mt)(x−mt)2+⋯.令 y : = x t − m t y:=x_t-m_t y:=xt−mt ,则 y ∼ N ( 0 , s t 2 ) y \sim \mathcal{N}(0,s_t^2) y∼N(0,st2) 。接下来,在 Δ t \Delta t Δt 的一阶近似下,通过减去输出的均值对其做中心化处理(输出减去它的均值后的波动量 z z z):
z : = x t + Δ t − E [ x t + Δ t ] = y + Δ t ( v t ′ ( m t ) y + 1 2 v t ′ ′ ( m t ) ( y 2 − s t 2 ) ) + O ( Δ t 2 ) . z:=x_{t+\Delta t}-\mathbb{E}\left[x_{t+\Delta t}\right]=y+\Delta t\left(v_t'(m_t)y+\frac12v_t''(m_t)\left(y^2-s_t^2\right)\right)+\mathcal{O}(\Delta t^2). z:=xt+Δt−E[xt+Δt]=y+Δt(vt′(mt)y+21vt′′(mt)(y2−st2))+O(Δt2).此处需注意,高斯分布的偏度为零,即其三阶中心矩为 0。因此,在一阶精度下计算 E [ z 3 ] \mathbb{E}[z^3] E[z3],并利用 E [ y ] = 0 \mathbb{E}[y]=0 E[y]=0、 E [ y 2 ] = s t 2 \mathbb{E}[y^2]=s_t^2 E[y2]=st2、 E [ y 3 ] = 0 \mathbb{E}[y^3]=0 E[y3]=0、 E [ y 4 ] = 3 s t 4 \mathbb{E}[y^4]=3s_t^4 E[y4]=3st4,可得:
E [ z 3 ] = 3 Δ t ⋅ 1 2 v t ′ ′ ( m t ) ( E [ y 4 ] − s t 2 E [ y 2 ] ) + O ( Δ t 2 ) = 3 Δ t v t ′ ′ ( m t ) s t 4 + O ( Δ t 2 ) . \mathbb{E}[z^3] = 3\Delta t \cdot \frac12 v_t''(m_t)\big(\mathbb{E}[y^4]-s_t^2\mathbb{E}[y^2]\big)+\mathcal{O}(\Delta t^2)=3\Delta t\,v_t''(m_t)s_t^4+\mathcal{O}(\Delta t^2). E[z3]=3Δt⋅21vt′′(mt)(E[y4]−st2E[y2])+O(Δt2)=3Δtvt′′(mt)st4+O(Δt2).为使任意微小步长 Δ t \Delta t Δt 下输出始终服从高斯分布,该量在 Δ t \Delta t Δt 阶上必须为零,由此推得 v t ′ ′ ( m t ) = 0 v_t''(m_t)=0 vt′′(mt)=0。对更高阶导数重复上述推导,可排除高阶幂次项。综上, v t v_t vt 必须为线性函数叠加常数偏移项(所有二阶以上的导数必须为零):
v t ( x ) = a t x + b t . v_t(x)=a_t x + b_t. vt(x)=atx+bt.将其代回演化步长表达式,可得
x t + Δ t = ( 1 + α t Δ t ) x t + β t Δ t + O ( Δ t 2 ) , α t : = a t , β t : = b t . x_{t+\Delta t}=(1+\alpha_t\Delta t)x_t+\beta_t\Delta t+\mathcal{O}(\Delta t^2),\quad \alpha_t:=a_t,\quad \beta_t:=b_t. xt+Δt=(1+αtΔt)xt+βtΔt+O(Δt2),αt:=at,βt:=bt.
上述表明:如果一开始数据服从高斯分布,并且我们希望经过一个确定性(ODE)演化后,分布仍然是高斯分布,那么这个演化过程的速度场 v t ( x ) v_t(x) vt(x) 必须是关于 x x x 的线性函数(比如 v t ( x ) = a t x + b t v_t(x)=a_t x + b_t vt(x)=atx+bt)。反过来,如果不是线性,高斯性就会被破坏。
要保持高斯性,速度场必须线性;否则高阶项会产生偏度,破坏高斯形状。
现将服从 x t ∼ N ( m t , s t 2 ) x_t \sim \mathcal{N}(m_t,s_t^2) xt∼N(mt,st2) 的随机变量经该映射变换,并在一阶精度下推导其均值与方差:
E [ x t + Δ t ] = m t + Δ t ( α t m t + β t ) + O ( Δ t 2 ) , \mathbb{E}[x_{t+\Delta t}] = m_t+\Delta t(\alpha_t m_t+\beta_t)+\mathcal{O}(\Delta t^2), E[xt+Δt]=mt+Δt(αtmt+βt)+O(Δt2), V a r ( x t + Δ t ) = s t 2 + Δ t ( 2 α t s t 2 ) + O ( Δ t 2 ) . \mathrm{Var}(x_{t+\Delta t}) = s_t^2+\Delta t(2\alpha_t s_t^2)+\mathcal{O}(\Delta t^2). Var(xt+Δt)=st2+Δt(2αtst2)+O(Δt2).另一方面,正向随机微分方程 d x = f ( t ) x d t + g ( t ) d w t \mathrm{d}x=f(t)x\mathrm{d}t+g(t)\mathrm{d}w_t dx=f(t)xdt+g(t)dwt 的基础矩公式如下(见式 (4.3.3)):
m t ′ = f ( t ) m t , ( s t 2 ) ′ = 2 f ( t ) s t 2 + g 2 ( t ) . m_t'=f(t)m_t,\quad (s_t^2)'=2f(t)s_t^2+g^2(t). mt′=f(t)mt,(st2)′=2f(t)st2+g2(t).对比 Δ t \Delta t Δt 的对应系数,可得
α t = f ( t ) + g 2 ( t ) 2 s t 2 , β t = − g 2 ( t ) 2 s t 2 m t . \alpha_t=f(t)+\frac{g^2(t)}{2s_t^2},\quad \beta_t=-\frac{g^2(t)}{2s_t^2}m_t. αt=f(t)+2st2g2(t),βt=−2st2g2(t)mt.代入后,该演化步长可写为
x t + Δ t = x t + Δ t [ ( f ( t ) + g 2 ( t ) 2 s t 2 ) x t − g 2 ( t ) 2 s t 2 m t ] + O ( Δ t 2 ) . x_{t+\Delta t}=x_t+\Delta t\left[\left(f(t)+\frac{g^2(t)}{2s_t^2}\right)x_t-\frac{g^2(t)}{2s_t^2}m_t\right]+\mathcal{O}(\Delta t^2). xt+Δt=xt+Δt[(f(t)+2st2g2(t))xt−2st2g2(t)mt]+O(Δt2).
对于高斯分布 p t = N ( m t , s t 2 ) p_t = \mathcal{N}(m_t, s_t^2) pt=N(mt,st2),其得分函数满足 ∂ x log p t ( x ) = − ( x − m t ) / s t 2 \partial_x \log p_t(x) = -(x-m_t)/s_t^2 ∂xlogpt(x)=−(x−mt)/st2,据此可将上式括号内部分改写为 f ( t ) x t − 1 2 g 2 ( t ) ∂ x log p t ( x t ) f(t)x_t - \frac{1}{2}g^2(t)\partial_x \log p_t(x_t) f(t)xt−21g2(t)∂xlogpt(xt)。由此可得:
x t + Δ t = x t + Δ t [ f ( t ) x t − 1 2 g 2 ( t ) ∂ x log p t ( x t ) ] + O ( Δ t 2 ) . x_{t+\Delta t}=x_t+\Delta t\left[f(t)x_t-\frac12g^2(t)\partial_x\log p_t(x_t)\right]+\mathcal{O}(\Delta t^2). xt+Δt=xt+Δt[f(t)xt−21g2(t)∂xlogpt(xt)]+O(Δt2).最后,将上式两边除以 Δ t \Delta t Δt 并取 Δ t → 0 \Delta t \to 0 Δt→0,即可推得 PF‑ODE:
x ′ ( t ) = f ( t ) x ( t ) − 1 2 g 2 ( t ) ∂ x log p t ( x ( t ) ) . x'(t)=f(t)x(t)-\frac12g^2(t)\partial_x\log p_t(x(t)). x′(t)=f(t)x(t)−21g2(t)∂xlogpt(x(t)). 为说明该常微分方程与正向随机微分方程(及时间反向随机微分方程)具有相同的边缘分布,注意到上述漂移项为线性项叠加常数偏移项。因此 x ( t ) x(t) x(t) 与 x ( 0 ) x(0) x(0) 呈仿射关系,而仿射变换可将高斯分布映射为高斯分布。此外,由前文的系数匹配可知,该常微分方程演化下的均值 m t m_t mt 与方差 s t 2 s_t^2 st2,满足与正向随机微分方程完全一致的两个标量常微分方程,且初值相同。因此,两种演化过程在任意时刻 t t t 的分布 p t = N ( m t , s t 2 ) p_t=\mathcal{N}(m_t,s_t^2) pt=N(mt,st2) 均完全一致。
4.2 得分随机微分方程:训练与采样(Score SDE: Its Training and Sampling)
4.2.1 训练(Training)
延续第 3 章的核心思路,采用时间条件神经网络 s ϕ = s ϕ ( x , t ) \mathbf{s}_\phi=\mathbf{s}_\phi(\mathbf{x},t) sϕ=sϕ(x,t),在全部时间域 t ∈ [ 0 , T ] t\in[0,T] t∈[0,T] 内近似真实得分函数 ∇ x log p t ( x ) \nabla_{\mathbf{x}}\log p_t(\mathbf{x}) ∇xlogpt(x),通过最小化式 (3.2.1) 所示的得分匹配目标函数实现:
L SM ( ϕ ; ω ( ⋅ ) ) : = 1 2 E t ∼ p time E x t ∼ p t [ ω ( t ) ∥ s ϕ ( x t , t ) − ∇ x log p t ( x t ) ∥ 2 2 ] \mathcal{L}_{\text{SM}}(\phi;\omega(\cdot)):=\frac12\mathbb{E}_{t\sim p_{\text{time}}}\mathbb{E}_{\mathbf{x}_t\sim p_t}\left[\omega(t)\left\|\mathbf{s}_\phi(\mathbf{x}_t,t)-\nabla_{\mathbf{x}}\log p_t(\mathbf{x}_t)\right\|_2^2\right] LSM(ϕ;ω(⋅)):=21Et∼ptimeExt∼pt[ω(t)∥sϕ(xt,t)−∇xlogpt(xt)∥22]式中 p time p_{\text{time}} ptime 为时间分布(例如 [ 0 , T ] [0,T] [0,T] 上的均匀分布), ω ( ⋅ ) \omega(\cdot) ω(⋅) 为时间加权函数。
为规避难以求解的真实得分函数 ∇ x log p t ( x ) \nabla_{\mathbf{x}}\log p_t(\mathbf{x}) ∇xlogpt(x),本文采用式 (3.3.2) 中的去噪得分匹配(DSM)损失函数。对于数据点 x 0 \mathbf{x}_0 x0,该方法可通过式 (D.2.4) 得到解析可解的条件得分函数 ∇ x t log p t ( x t ∣ x 0 ) \nabla_{\mathbf{x}_t}\log p_t(\mathbf{x}_t|\mathbf{x}_0) ∇xtlogpt(xt∣x0),4.3 节将给出具体算例。本文具体采用如下损失函数:
L DSM ( ϕ ; ω ( ⋅ ) ) : = 1 2 E t E x 0 E p t ( x t ∣ x 0 ) [ ω ( t ) ∥ s ϕ ( x t , t ) − ∇ x t log p t ( x t ∣ x 0 ) ∥ 2 2 ] (4.2.1) \mathcal{L}_{\text{DSM}}(\phi;\omega(\cdot)):=\frac12\mathbb{E}_t\mathbb{E}_{\mathbf{x}_0}\mathbb{E}_{p_t(\mathbf{x}_t|\boldsymbol{x}_0)}\left[\omega(t)\left\|\mathbf{s}_\phi(\mathbf{x}_t,t)-\nabla_{\mathbf{x}_t}\log p_t(\mathbf{x}_t|\mathbf{x}_0)\right\|_2^2\right] \tag{4.2.1} LDSM(ϕ;ω(⋅)):=21EtEx0Ept(xt∣x0)[ω(t)∥sϕ(xt,t)−∇xtlogpt(xt∣x0)∥22](4.2.1)
其中 x 0 ∼ p data \mathbf{x}_0 \sim p_{\text{data}} x0∼pdata。式 (4.2.1) 可视为式 (3.4.1) 的连续时间形式,即将离散情形中的求和运算替换为积分运算。
与定理 3.3.1 的结论类似,式 (4.2.1) 的极小值解具有唯一性,具体形式如下:
命题 4.2.1:去噪得分匹配(DSM)的极小值解
极小值解 s ∗ \mathbf{s}^* s∗ 满足
s ∗ ( x t , t ) = E x 0 ∼ p ( x 0 ∣ x t ) [ ∇ x t log p t ( x t ∣ x 0 ) ] = ∇ x t log p t ( x t ) (4.2.2) \textcolor{dodgerblue}{\mathbf{s}^*(\mathbf{x}_t,t)=\mathbb{E}_{\mathbf{x}_0\sim p(\mathbf{x}_0|\mathbf{x}_t)}\big[\nabla_{\mathbf{x}_t}\log p_t(\mathbf{x}_t|\mathbf{x}_0)\big]=\nabla_{\mathbf{x}_t}\log p_t(\mathbf{x}_t) \tag{4.2.2}} s∗(xt,t)=Ex0∼p(x0∣xt)[∇xtlogpt(xt∣x0)]=∇xtlogpt(xt)(4.2.2) 去噪得分匹配目标函数可看作最小二乘误差问题。具体而言,对每个时刻 t t t,最优得分函数为条件对数密度梯度的条件期望;由贝叶斯定理可知,该期望等价于对数边缘密度的梯度。详细证明见附录 D.2.6。
4.2.2 采样和推理(Sampling and Inference)
学习阶段结束后
s ϕ × : = s ϕ × ( x , t ) ≈ ∇ x log p t ( x ) , \mathbf{s}_{\phi\times}:=\mathbf{s}_{\phi\times}(\mathbf{x},t)\approx\nabla_{\mathbf{x}}\log p_t(\mathbf{x}), sϕ×:=sϕ×(x,t)≈∇xlogpt(x),我们使用学习得到的代理函数 s ϕ × ( x , t ) \mathbf{s}_{\phi\times}(\mathbf{x},t) sϕ×(x,t),替换时间反向随机微分方程(式 (4.1.6))与 PF‑ODE(式 (4.1.7))中难以直接求解的真实得分函数 ∇ x log p t ( x ) \nabla_{\mathbf{x}}\log p_t(\mathbf{x}) ∇xlogpt(x)。该替换可通过随机微分方程或常微分方程实现可求解的推理。为表述清晰,将二者对应的过程分别记作 x ϕ × SDE ( t ) \mathbf{x}_{\phi\times}^{\text{SDE}}(t) xϕ×SDE(t) 与 x ϕ × ODE ( t ) \mathbf{x}_{\phi\times}^{\text{ODE}}(t) xϕ×ODE(t),后续章节中将不再做此区分。
Figure 4.5 | (二维)Score SDE 的采样示意图:本图沿用与图 4.4 一致的正向随机微分方程设定,分别通过求解时间反向 SDE(蓝色,对应式 (4.2.4))与 PF‑ODE(红色,对应式 (4.2.6))完成采样。采样从先验分布 p prior p_{\text{prior}} pprior 中的随机点 x T \mathbf{x}_T xT(深色 “×” 标记)出发,两条轨迹均在 t = 0 t=0 t=0 时刻收敛至数据分布 p data p_{\text{data}} pdata 的支撑域附近。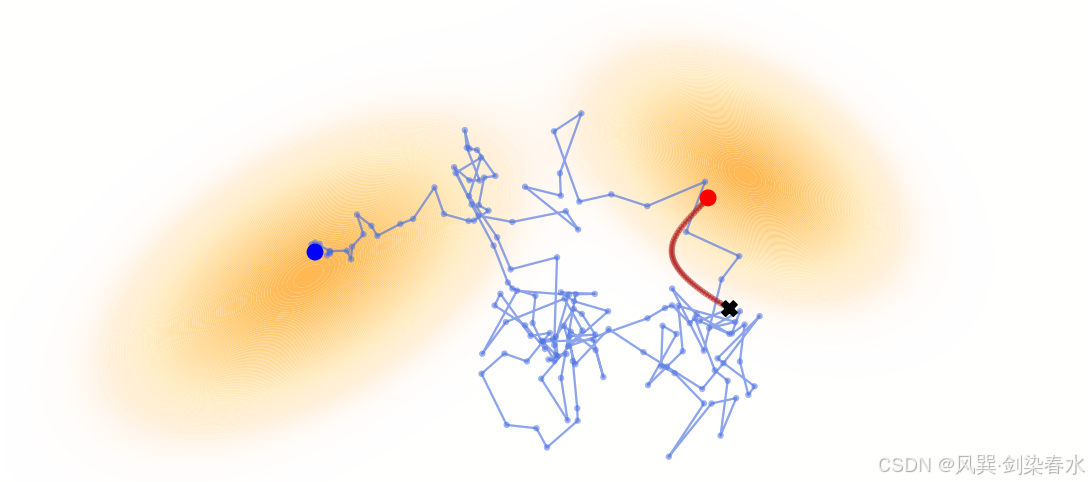
经验反向时间 SDE。 将训练后的得分模型 s ϕ × \mathbf{s}_{\phi\times} sϕ× 代入式 (4.1.6) 以替代真实得分函数,即可得到用于生成任务的参数化反向时间随机微分方程:
d x ϕ × SDE ( t ) = [ f ( x ϕ × SDE ( t ) , t ) − g 2 ( t ) s ϕ × ( x ϕ × SDE ( t ) , t ) ] d t + g ( t ) d w ˉ ( t ) . (4.2.3) \mathrm{d}\mathbf{x}_{\phi\times}^{\text{SDE}}(t)=\left[\mathbf{f}\left(\mathbf{x}_{\phi\times}^{\text{SDE}}(t),t\right)-g^2(t)\mathbf{s}_{\phi\times}\left(\mathbf{x}_{\phi\times}^{\text{SDE}}(t),t\right)\right]\mathrm{d}t+g(t)\mathrm{d}\bar{\mathbf{w}}(t).\tag{4.2.3} dxϕ×SDE(t)=[f(xϕ×SDE(t),t)−g2(t)sϕ×(xϕ×SDE(t),t)]dt+g(t)dwˉ(t).(4.2.3) 生成样本时,首先从先验分布 p prior p_{\text{prior}} pprior 中采样初值 x T \mathbf{x}_T xT,随后在时间上从 t = T t=T t=T 到 t = 0 t=0 t=0 数值求解式 (4.2.3)。常用的标准数值求解器为欧拉‑丸山法,其离散更新规则为:
x t − Δ t ← x t − [ f ( x t , t ) − g 2 ( t ) s ϕ × ( x t , t ) ] Δ t + g ( t ) Δ t ⋅ ϵ , (4.2.4) \mathbf{x}_{t-\Delta t}\leftarrow\mathbf{x}_t-\left[\mathbf{f}(\mathbf{x}_t,t)-g^2(t)\mathbf{s}_{\phi\times}(\mathbf{x}_t,t)\right]\Delta t+g(t)\sqrt{\Delta t}\cdot\mathbf{\epsilon},\tag{4.2.4} xt−Δt←xt−[f(xt,t)−g2(t)sϕ×(xt,t)]Δt+g(t)Δt⋅ϵ,(4.2.4)式中 ϵ ∼ N ( 0 , I ) \boldsymbol{\epsilon}\sim\mathcal{N}(\boldsymbol{0},\mathbf{I}) ϵ∼N(0,I), Δ t > 0 \Delta t>0 Δt>0 为步长。
迭代执行该更新规则,即可得到最终样本 x ϕ × SDE ( 0 ) \mathbf{x}_{\phi\times}^{\text{SDE}}(0) xϕ×SDE(0)。若得分模型精度足够,生成样本的分布(记为 p ϕ × SDE ( ⋅ ; 0 ) p_{\phi\times}^{\text{SDE}}(\cdot;0) pϕ×SDE(⋅;0))可高度逼近真实数据分布:
p ϕ × SDE ( ⋅ ; 0 ) ≈ p data ( ⋅ ) . p_{\phi\times}^{\text{SDE}}(\cdot;0) \approx p_{\text{data}}(\cdot). pϕ×SDE(⋅;0)≈pdata(⋅).事实上,式 (2.2.14) 给出的 DDPM 采样方案,正是该欧拉‑丸山离散形式在选取特定函数 f \mathbf{f} f 与 g g g 时的特例(详见 4.3 节)。
经验 PF‑ODE。 PF‑ODE 构建了连接先验分布 p prior p_{\text{prior}} pprior 与数据分布 p data p_{\text{data}} pdata 的连续流,可实现采样、编码以及精确似然估计。下一节将对上述各项操作展开详细说明。
I. 基于 PF‑ODE 的采样。 将式 (4.1.7) 中的真实得分函数替换为 s ϕ × \mathbf{s}_{\phi\times} sϕ×,可得经验 PF‑ODE:
d d t x ϕ × ODE ( t ) = f ( x ϕ × ODE ( t ) , t ) − 1 2 g 2 ( t ) s ϕ × ( x ϕ × ODE ( t ) , t ) . (4.2.5) \frac{\mathrm{d}}{\mathrm{d}t}\mathbf{x}_{\phi\times}^{\text{ODE}}(t)=\mathbf{f}\big(\mathbf{x}_{\phi\times}^{\text{ODE}}(t),t\big)-\frac12g^2(t)\mathbf{s}_{\phi\times}\big(\mathbf{x}_{\phi\times}^{\text{ODE}}(t),t\big).\tag{4.2.5} dtdxϕ×ODE(t)=f(xϕ×ODE(t),t)−21g2(t)sϕ×(xϕ×ODE(t),t).(4.2.5)生成样本时,首先从先验分布 p prior p_{\text{prior}} pprior 中采样初始样本 x T \mathbf{x}_T xT,随后在时间维度上从 t = T t=T t=T 到 t = 0 t=0 t=0 对式 (4.2.5) 的 PF‑ODE 进行数值求解。该过程等价于对下述积分做近似计算:
x ϕ × ODE ( 0 ) = x T + ∫ T 0 [ f ( x ϕ × ODE ( τ ) , τ ) − 1 2 g 2 ( τ ) s ϕ × ( x ϕ × ODE ( τ ) , τ ) ] d τ . \mathbf{x}_{\phi\times}^{\text{ODE}}(0)=\mathbf{x}_T+\int_{T}^{0}\left[\mathbf{f}\big(\mathbf{x}_{\phi\times}^{\text{ODE}}(\tau),\tau\big)-\frac12g^2(\tau)\mathbf{s}_{\phi\times}\big(\mathbf{x}_{\phi\times}^{\text{ODE}}(\tau),\tau\big)\right]\mathrm{d}\tau. xϕ×ODE(0)=xT+∫T0[f(xϕ×ODE(τ),τ)−21g2(τ)sϕ×(xϕ×ODE(τ),τ)]dτ.求解该积分可得到最终样本 x ϕ × ODE ( 0 ) \mathbf{x}_{\phi\times}^{\text{ODE}}(0) xϕ×ODE(0)。经该确定性过程生成的样本分布记为 p ϕ × ODE ( ⋅ ; 0 ) p_{\phi\times}^{\text{ODE}}(\cdot;0) pϕ×ODE(⋅;0),可近似拟合数据分布,即 p ϕ × ODE ( ⋅ ; 0 ) ≈ p data p_{\phi\times}^{\text{ODE}}(\cdot;0)\approx p_{\text{data}} pϕ×ODE(⋅;0)≈pdata。
设 Δ t > 0 \Delta t>0 Δt>0 为离散步长,欧拉法是常用的数值积分方法,其近似关系为:
f ( x τ , τ ) − 1 2 g 2 ( τ ) s ϕ × ( x τ , τ ) ≈ f ( x t , t ) − 1 2 g 2 ( t ) s ϕ × ( x t , t ) , τ ∈ [ t − Δ t , t ] , \mathbf{f}(\mathbf{x}_\tau,\tau)-\frac12g^2(\tau)\mathbf{s}_{\phi\times}(\mathbf{x}_\tau,\tau)\approx\mathbf{f}(\mathbf{x}_t,t)-\frac12g^2(t)\mathbf{s}_{\phi\times}(\mathbf{x}_t,t),\quad \tau\in[t-\Delta t,t], f(xτ,τ)−21g2(τ)sϕ×(xτ,τ)≈f(xt,t)−21g2(t)sϕ×(xt,t),τ∈[t−Δt,t],由此可得如下更新规则:
x t − Δ t ← x t − [ f ( x t , t ) − 1 2 g 2 ( t ) s ϕ × ( x t , t ) ] Δ t (4.2.6) \mathbf{x}_{t-\Delta t}\leftarrow\mathbf{x}_t-\left[\mathbf{f}(\mathbf{x}_t,t)-\frac12g^2(t)\mathbf{s}_{\phi\times}(\mathbf{x}_t,t)\right]\Delta t\tag{4.2.6} xt−Δt←xt−[f(xt,t)−21g2(t)sϕ×(xt,t)]Δt(4.2.6)
基于上述关联,我们可提炼出生成过程的核心结论:
核心结论 4.2.1:生成过程等价于求解 ODE / SDE
扩散模型的采样过程,本质等价于求解对应的概率流常微分方程或反向时间随机微分方程。
这一等价关系清晰解释了问题 3.5.1 中提及的扩散模型采样速度缓慢的原因。生成过程计算开销较大,根源在于此类微分方程的数值求解器本质为迭代算法,通常需要大量迭代步长才能精确拟合解的轨迹。不过,PF‑ODE 形式也具备优势:我们可借鉴大量关于加速型数值求解器的现有研究成果。第 9 章将重点探究基于这些技术实现扩散模型采样加速的方法。
II. 基于 PF‑ODE 的逆变换。 前文已述,与随机微分方程不同,式 (4.2.5) 可沿时间正向(从 0 0 0 至 T T T)、反向(从 T T T 至 0 0 0)双向求解。正向求解时,该常微分方程流可将数据映射为全部时刻 t ∈ [ 0 , T ] t\in[0,T] t∈[0,T] 下的含噪隐表征,起到编码器的作用。该机制可支撑可控生成领域的诸多应用,例如图像转换、图像编辑等。
III. 基于 PF‑ODE 的精确对数似然计算。 将式 (4.2.5) 的动力学过程重新解读为一种神经常微分方程(Neural ODE)变体(见 5.1.2 节):该变体仅对得分函数做参数化,而非完整速度场。借助变量替换公式,该 PF‑ODE 形式可实现精确对数似然计算。
将式 (5.1.9) 中的恒等式应用于式 (4.2.5) 的 PF‑ODE,定义速度场为
v ϕ × ( x , t ) : = f ( x , t ) − 1 2 g 2 ( t ) s ϕ × ( x , t ) , \mathbf{v}_{\phi\times}(\mathbf{x},t):=\mathbf{f}(\mathbf{x},t)-\frac12g^2(t)\mathbf{s}_{\phi\times}(\mathbf{x},t), vϕ×(x,t):=f(x,t)−21g2(t)sϕ×(x,t),其中 s ϕ × \mathbf{s}_{\phi\times} sϕ× 为学习得到的得分函数。沿 PF‑ODE 轨迹 { x ϕ × ODE ( t ) } t ∈ [ 0 , T ] \{\mathbf{x}_{\phi\times}^{\text{ODE}}(t)\}_{t\in[0,T]} {xϕ×ODE(t)}t∈[0,T],对数密度 p ϕ × ODE ( ⋅ ; t ) p_{\phi\times}^{\text{ODE}}(\cdot;t) pϕ×ODE(⋅;t) 的时间演化满足
d d t log p ϕ × ODE ( x ϕ × ODE ( t ) , t ) = − ∇ ⋅ v ϕ × ( x ϕ × ODE ( t ) , t ) , \frac{\mathrm{d}}{\mathrm{d}t}\log p_{\phi\times}^{\text{ODE}}\big(\mathbf{x}_{\phi\times}^{\text{ODE}}(t),t\big)=-\nabla\cdot\mathbf{v}_{\phi\times}\big(\mathbf{x}_{\phi\times}^{\text{ODE}}(t),t\big), dtdlogpϕ×ODE(xϕ×ODE(t),t)=−∇⋅vϕ×(xϕ×ODE(t),t), 式中 ∇ ⋅ v \nabla\cdot\mathbf{v} ∇⋅v 表示关于 x \mathbf{x} x 的散度。为计算数据点 x 0 ∼ p data \mathbf{x}_0\sim p_{\text{data}} x0∼pdata 的似然,从 t = 0 t=0 t=0 到 t = T t=T t=T 对下述增广常微分方程系统积分:
d d t [ x ( t ) δ ( t ) ] = [ v ϕ × ( x ( t ) , t ) ∇ ⋅ v ϕ × ( x ( t ) , t ) ] , [ x ( 0 ) δ ( 0 ) ] = [ x 0 0 ] , (4.2.7) \frac{\mathrm{d}}{\mathrm{d}t}\begin{bmatrix}\mathbf{x}(t)\\\delta(t)\end{bmatrix}=\begin{bmatrix}\mathbf{v}_{\phi\times}(\mathbf{x}(t),t)\\\nabla\cdot\mathbf{v}_{\phi\times}(\mathbf{x}(t),t)\end{bmatrix},\quad \begin{bmatrix}\mathbf{x}(0)\\\delta(0)\end{bmatrix}=\begin{bmatrix}\mathbf{x}_0\\0\end{bmatrix},\tag{4.2.7} dtd[x(t)δ(t)]=[vϕ×(x(t),t)∇⋅vϕ×(x(t),t)],[x(0)δ(0)]=[x00],(4.2.7)其中 δ ( t ) \delta(t) δ(t) 用于累积随时间变化的对数密度。求解该系统至时刻 t = T t=T t=T,可得终端状态: [ x ( T ) δ ( T ) ] , \begin{bmatrix}\mathbf{x}(T)\\\delta(T)\end{bmatrix}, [x(T)δ(T)], 由此可计算模型下原始样本 x 0 \mathbf{x}_0 x0 的对数似然:
log p ϕ × ODE ( x 0 ; 0 ) = log p prior ( x ( T ) ) + δ ( T ) , \log p_{\phi\times}^{\text{ODE}}(\mathbf{x}_0;0)=\log p_{\text{prior}}(\mathbf{x}(T))+\delta(T), logpϕ×ODE(x0;0)=logpprior(x(T))+δ(T),式中 p prior ( x ( T ) ) p_{\text{prior}}(\mathbf{x}(T)) pprior(x(T)) 为在 x ( T ) \mathbf{x}(T) x(T) 处计算得到的解析形式先验密度。
下一章:【扩散模型原理】(四)Diffusion Models Today: Score SDE Framework(2)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)