Scale-Up总线分析
本文重点比较两条 Scale-Up 总线技术路线:Flit 原生总线方案和以太网增强方案。
1. 核心结论
Scale-Up 总线的分歧,本质不是“是否使用以太网物理层”,而是远端内存访问的语义、封装效率、端到端延迟和生态可复制性之间的取舍。
- Flit 原生总线方案以 NVLink 和 UALink 为代表,核心目标是把跨 GPU 访问转换为原生内存语义。通过固定 Flit、专用事务层、信用流控和专用交换域来降低小粒度访问的不确定性,更适合张量并行、长上下文推理、远端 Load/Store/Atomic、KV Cache 共享等强同步场景。
- NVLink 是当前工程成熟度最高的专有 Scale-Up 总线,但生态封闭,只能在NVIDIA GPU 系统中使用。
- UALink 是开放 Flit 原生总线路线的主要代表,规范层面已经覆盖 UPLI、TL、DL、PL、管理和 Chiplet 集成,目标是构建跨厂商的 Accelerator Pod。不过其关键风险在于交换芯片、端侧 IP、运行时和通信库的量产成熟度。
- 以太网增强方案以 SUE、ETH-X 和 EthLink 为代表,核心目标是在复用以太网 SerDes、MAC、交换芯片和运维生态的前提下,补齐 Scale-Up 所需的小包效率、可靠性和流控能力。它通过头压缩、事务聚合、LLR、CBFC/PFC、ECMP/QoS 等机制把以太网改造成可承载内存访问事务的低延迟 Scale-Up 总线。
- SUE/ETH-X/EthLink 更贴近以太网产业链,适合希望复用以太网交换芯片、线缆、连接器、运维和多厂商供应链的系统。但由于地址翻译、内存模型和完成语义更多留给 XPU/IOD 端侧实现,软件可见的 Goodput 和尾延迟高度依赖端侧事务代理、保序、聚合和屏障优化。
2. 背景
AI 超节点正在从“多卡通过网络搬运数据”走向“多卡像一个更大的加速器”。这一转变要求互联不只提供带宽,还要让本地 GPU 访问远端 GPU HBM 像访问本地 HBM 一样。DeepLink 白皮书把问题拆成编程模型、内存模型、事务层、网络和远端 HBM 的完整语义链路:如果上层使用 Load/Store/Atomic/Fence,底层互联就必须处理保序、完成确认、地址翻译、重传、拥塞和故障隔离。
从负载看,Scale-Up 需要同时支撑两类通信:
| 类型 | 典型路径 | 数据粒度 | 对互联的核心要求 |
|---|---|---|---|
| Direct Access | GPU SM 直接访问远端 HBM | 字节级到 cache line / 小块 | 低延迟、保序、Atomic、Fence、可见性 |
| Direct Copy | Copy Engine / SU Engine 批量搬运 | KB 到 MB | 高吞吐、聚合效率、DMA 语义、流控和可靠性 |
Scale-Up 不是普通 RoCE/IB 的替代名词。Scale-Out 网络偏消息语义,强调跨机规模、拥塞控制和吞吐;Scale-Up 总线偏内存语义,强调小包、低时延、强同步和地址空间。
3. 技术路线
3.1 总线对比
下表把 Flit 原生总线和以太网增强方案放在同一组维度下比较。以太网增强列包括 SUE、ETH-X 和 EthLink;其中 SUE 侧重 XPU command transport,ETH-X 侧重 PAXI/PRI,EthLink 侧重同时承载 Load/Store 小块访问和 RDMA 大块搬运。
| 特性 | NVLink / UALink | 以太网增强(SUE / ETH-X / EthLink) |
|---|---|---|
| 封装方式 | 固定 Flit,原生承载内存事务语义 | AXI/命令/Load-Store/RDMA 语义映射到以太网帧;SUE 使用 XPU command,ETH-X 使用 PAXI,EthLink 使用 Memory Read/Write/Atomic/Message |
| 帧头开销 | 头部较小且解析固定;UALink 控制 Half-Flit 为 32B,可打包多个事务 | 需要压缩标准以太网头;SUE 使用 AFH,ETH-X 使用 PRI,EthLink 使用 OEFH,并可叠加 RH 做可靠性补充 |
| 事务粒度 | UALink 面向 64B 到 256B 等固定事务粒度,NVLink 早期 packet 可包含 0 到 16 个 128b data payload flit | 变长以太网帧封装,效率依赖聚合和分片策略;EthLink 显式区分 LS 小包和 RDMA 大块搬运 |
| 链路利用率 | 目标接近 93% 到 95%;UALink TL 数据效率约 95.2%,NVLink 早期 256B transfer 约 94% | 标准小包效率偏低;ETH-X 示例从约 56% 提升到 74% 到 77%;SUE/AFH 和 EthLink/OEFH 通过头压缩降低开销,实际 Goodput 依赖聚合、重传和端侧事务引擎 |
| 端到端延迟 | 面向百纳秒到亚微秒级路径;专用交换和信用流控更利于确定性 | 常见目标在亚微秒到数微秒;取决于交换芯片 cut-through、端侧代理、聚合策略、LLR/CBFC 和重传路径 |
| 流控机制 | UALink 有 UPLI/TL/Switch 多层信用域;NVLink 内建链路级 CRC/replay 和专用流控 | LLR + CBFC/PFC 是共性基础;SUE 有 PSN、ACK/NACK、GoBackN,ETH-X 有 PAXI credit,EthLink 有 RH 和 Switch Event Notification |
| 地址空间与路由 | UALink 支持 Fabric/网络地址模型,NVLink 是 NVIDIA 私有统一寻址域 | 地址翻译和内存管理多由 XPU/IOD/协议栈实现;ETH-X 使用 DA Mapping Register,EthLink OEFH 携带源/目的 GPU ID 并由交换机按 GPU ID 转发 |
| 交换芯片 | 专用 NVSwitch / UALink Switch;协议解析、转发和可靠性面向内存事务定制 | 复用或增强以太网交换芯片;需要支持 AFH/PRI/OEFH 解析、LLR、CBFC/PFC、QoS、遥测和故障事件反馈 |
| 网内计算 | NVSwitch SHARP 已部署;UALink 2.0 引入 In-Network Compute | ETH-X 白皮书定义 INCA 术语;SUE/EthLink 更强调传输、可靠性和流控,本身不主张完整网内计算 |
| 生态 | NVLink 私有闭环;UALink 是开放联盟,成员和规范体系快速扩展 | 复用成熟以太网生态;SUE 有 OCP/Broadcom 规范基础,ETH-X 有 ODCC/腾讯路线,EthLink 来自字节跳动白皮书,标准化和跨厂商互操作成熟度仍需观察 |
从这张表可以看出,两条路线的分界不在物理层是否复用以太 SerDes,而在事务语义放在哪里兑现。Flit 原生方案把 Load/Store/Atomic 等内存事务直接放进固定 Flit 和专用交换域,路径短、确定性强,更适合细粒度同步和远端内存访问。以太网增强方案则把以太网改造成 Scale-Up 事务传输层,通过 AFH、PRI、OEFH、LLR、CBFC/PFC、RH 和端侧事务代理补齐小包效率、可靠性与保序能力。
以太网增强路线的语义覆盖更完整:SUE 更像开放的 XPU command transport,ETH-X 更像面向 AXI/PAXI 的超节点互联协议,EthLink 则把 GPU Load/Store 和 RDMA 同时纳入同一协议栈。以太网增强路线的关键价值在于让小块低时延访问和大块带宽型搬运可以共享以太 Scale-Up Fabric;关键风险则是多协议栈、多路径和端侧运行时必须共同处理乱序、可靠性、Cache Coherency 和 P99/P999 延迟。
4. Flit 原生总线方案
Flit 原生方案的核心思想是“用总线方式做互联”,即网络里的最小传输单元从设计之初就服务于内存访问事务,而不是先构造完整以太/IP/UDP 报文再承载事务。
4.1 NVLink
NVLink 是 NVIDIA 的专有 GPU-to-GPU 互联总线,和 NVSwitch、CUDA、NCCL、NVSHMEM、NVIDIA Fabric Manager 等软件栈一起构成 GPU 互联生态。其设计目标不是普通网卡通信,而是让多 GPU 域在带宽、延迟和拓扑上尽量像一个更大的加速器。
Pascal NVLink Packet 示意图如下。这里的格式用于说明早期 NVLink 的报文格式:链路上传输的是可变长度 packet,packet 由多个 128b flit 组成,而不是固定的以太网帧式报文。
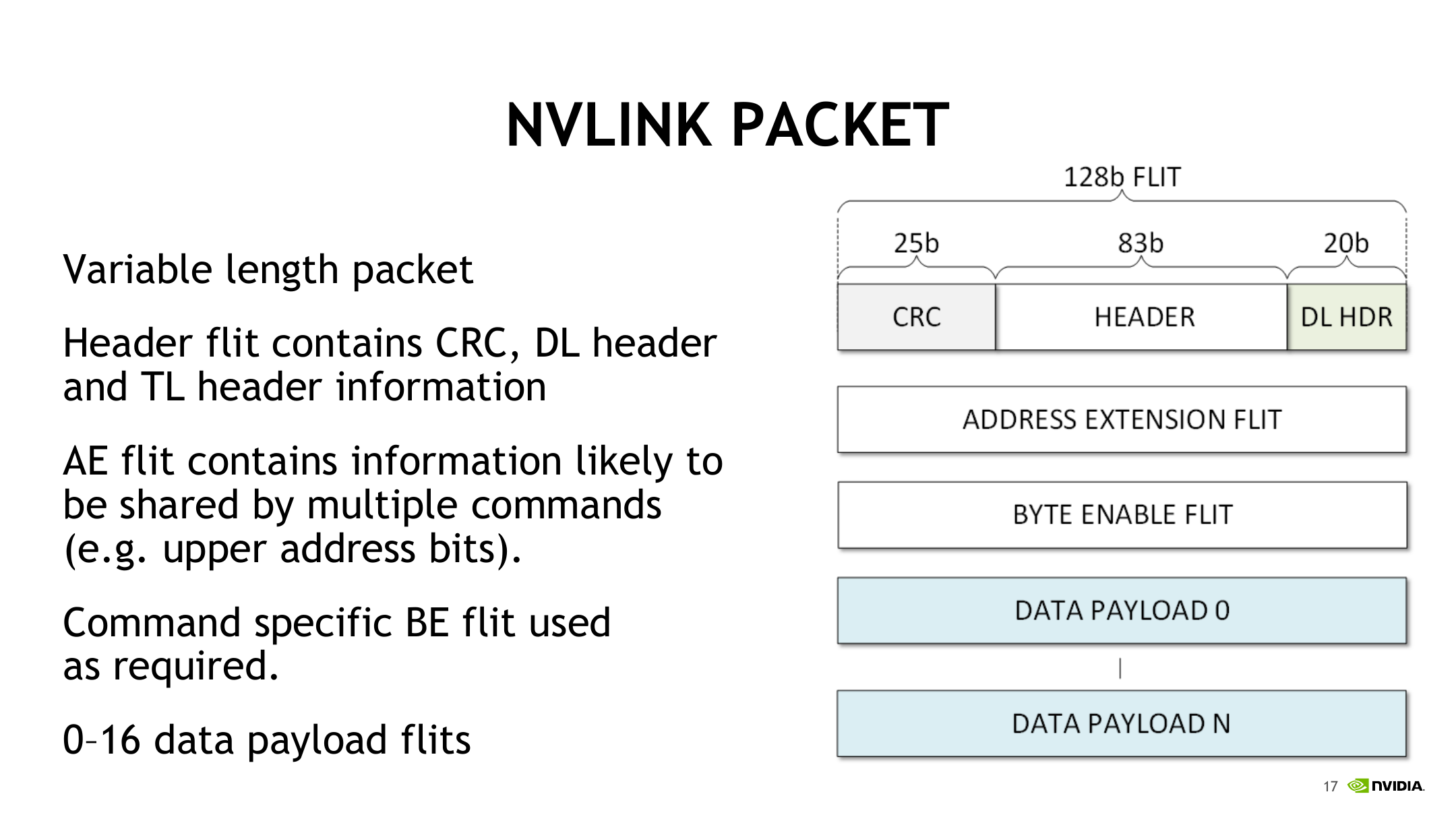
从图中可以看出,一个 NVLink packet 至少包含 header flit。header flit 本身是 128b,由 25b CRC、83b TL header 和 20b DL header 组成;TL header 描述事务层语义,例如 read/write/atomic等;DL header 服务于数据链路层,例如链路控制、packet 边界和重传相关信息;CRC 用于链路错误检测。packet 可以继续附带 Address Extension flit,用来承载多个 command 可能共享的地址扩展信息,例如高位地址;也可以按 command 需要附带 Byte Enable flit,用来描述部分字节有效性;真正的数据则放在 0 到 16 个 data payload flit 中。因为每个 payload flit 是 128b,也就是 16B,所以 16 个 payload flit 对应 256B 最大传输粒度。
Simple Read 的示意图展示了请求和响应如何复用这种 flit 结构。
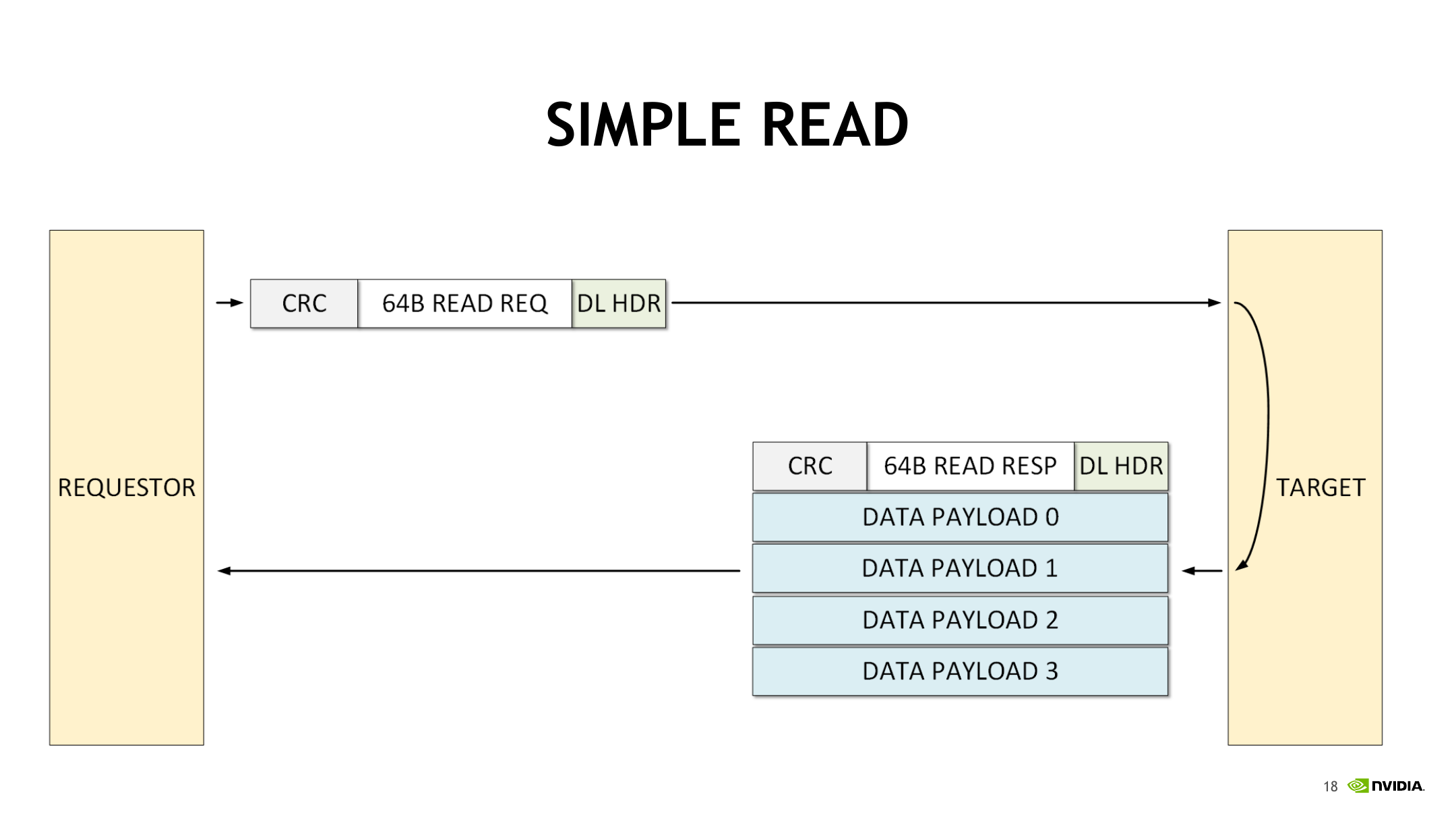
对 64B read 来说,requestor 先发送一个读请求 header flit;target 返回读响应 header flit,并跟随 4 个 data payload flit。4 个 128b payload flit 正好承载 64B 数据。这说明 NVLink 的 read 响应并不是把数据藏在命令头里,而是用 header flit 表达响应语义,再用后续 payload flit 承载数据,从而让小请求和大数据返回都能复用同一套 packet 结构。
NVLink Packet CRC 的作用是支撑链路级可靠性。Pascal NVLink Packet 对 CRC 与 replay 的说明如下。
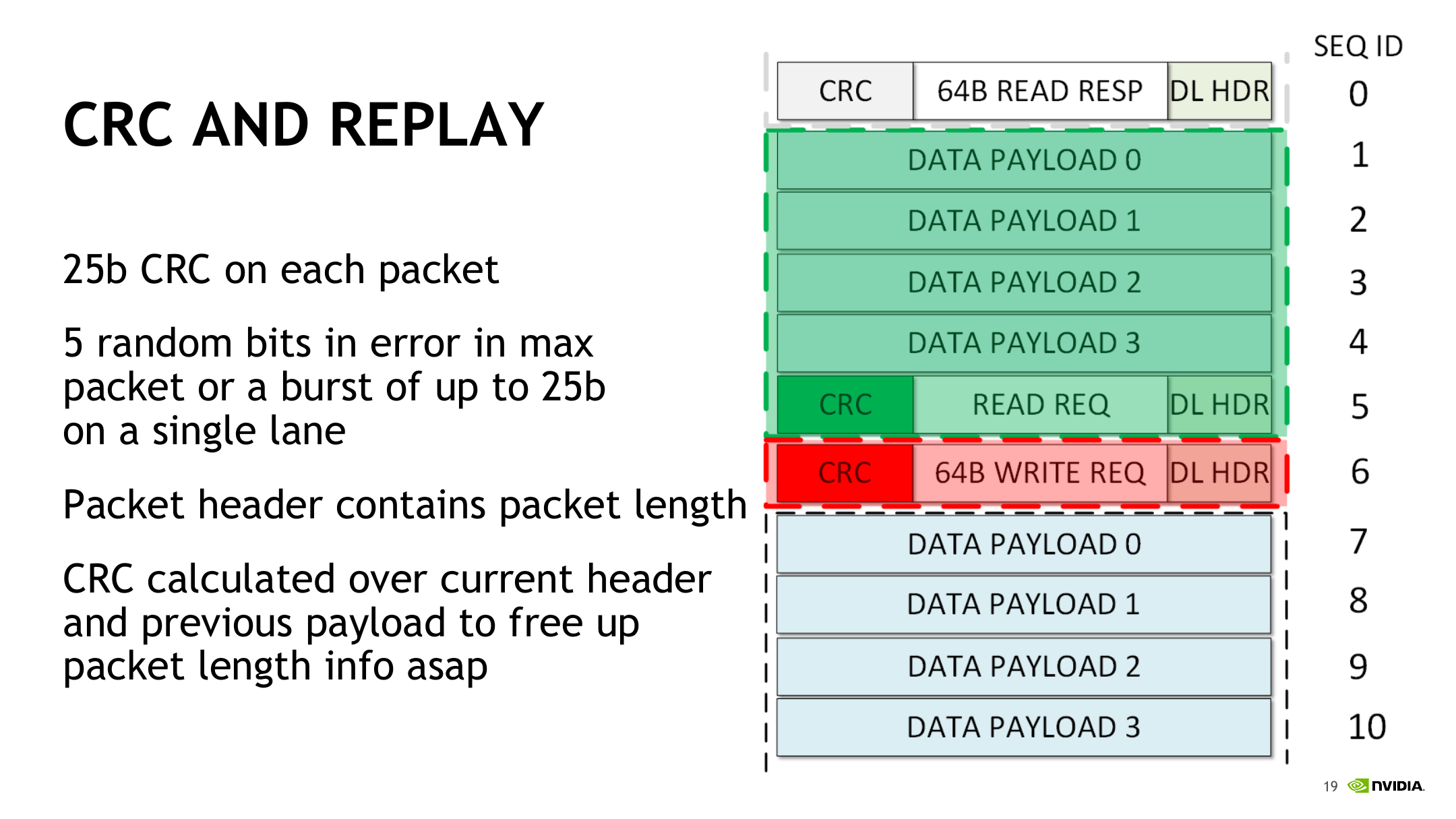

这些图里,虚线框表示 packet 边界,右侧 Seq ID 表示链路上连续 flit 的发送顺序。NVLink 在 header flit 中放置 25b CRC,可检测最大 packet 中最多 5 个随机 bit 错误,或单 lane 上最多 25b 的短 burst 错误。CRC 的计算覆盖当前 header 和前序 payload,这样接收端可以尽早获得 packet 长度与边界信息,同时完成错误检测。发送端会把已发送数据暂存在 replay buffer 中;当接收端确认 CRC 正确后,相关 packet 才能释放。如果出现错误,链路从最后一个已 ACK 的 packet 之后开始 replay。也就是说,NVLink 的 flit 结构不仅服务于事务封装,还直接服务于低延迟解析、链路保序、错误检测和硬件重传。
NVLink 的优势:
- 成熟度最高:GPU、交换芯片、系统软件、通信库和调度工具链协同成熟。
- 延迟和 Goodput 强:低协议开销、专用交换、原生支持 GPU 内存访问模式。
- 网内计算领先:NVSwitch 的 SHARP 已在集合通信中形成硬件加速能力。
- 系统设计确定:NVIDIA 可对端侧、交换、驱动、通信库和拓扑做端到端协同。
NVLink 的约束:
- 私有生态:跨厂商 XPU 很难直接进入同一个 NVLink 内存语义域。
- 成本和供应链绑定:高性能来自端到端封闭协同,也意味着替代和议价空间有限。
- 可观测性与控制权边界由 NVIDIA 定义:系统集成方更多是调优和使用,而不是协议层共建。
4.2 UALink
UALink 是开放 Flit 原生总线路线的主要代表。UALink 规范定义了加速器与交换机之间的低延迟、高带宽互联,目标是在 AI computing pod 中支持最多 1024 个加速器;UALink 2.0 规范引入 In-Network Compute;200G DL/PL 2.0 将数据链路层和物理层从 Common 规范中拆分,以便随物理层速率快速演进。
UALink 2.0 规范显示,UALink 的基本协议栈包括:
- UPLI:面向加速器端的协议层接口,支持 split request/response、多 outstanding、read/write/atomic memory operation。
- TL:把 UPLI 的请求、响应和数据通道编码成 64B TL Flit。每个 64B TL Flit 分为两个 32B Half-Flit,控制 Half-Flit 可以承载请求、读响应、写响应、流控/NOP 信息。
- DL:把 64B TL Flit 打包成 640B DL Flit,并提供链路控制消息、UART 机制、重传和速率适配。
- PL:基于 IEEE 802.3dj 方向的高速物理层,支持 200G serial 相关速率,例如 200GBASE-KR1/CR1、400GBASE-KR2/CR2、800GBASE-KR4/CR4。
UALink 的几个关键点值得注意:
- 固定粒度降低不确定性:64B TL Flit 到 640B DL Flit 的设计,使事务解析、缓存、仲裁和信用回收更容易硬件化。
- 请求压缩依赖地址缓存:TL 定义 Tx/Rx Address Cache 同步机制,未压缩请求可加载地址缓存,后续压缩请求通过 cache way 重构地址字段,用较小头部承载高频访存。
- 内存语义明确:UPLI 支持读、写、Atomic;规范中定义请求/响应排序、Strict Ordering Mode、Single-Copy Atomicity 等机制。
- 地址翻译保持实现灵活:UALink 2.0 的地址翻译模型允许 SPA/NPA 等形式,也允许 flat global addressing;Switch 使用 identifier-based routing,地址翻译可由具体实现选择。
- 物理层复用成熟 SerDes,但不是普通以太网帧:PL 可复用以太相关物理能力,TL/DL 仍是为 Scale-Up 内存事务定制的 Flit 协议。
UALink 的优势:
- 开放性:目标是让多厂商加速器进入同一类 Scale-Up Fabric。
- 语义强:从 UPLI 到 TL/DL 都面向 Load/Store/Atomic 和远端内存访问构建。
- 效率高:固定 Flit、请求压缩、信用流控有利于小包和高频事务。
- 演进空间清晰:Common、DL/PL、Chiplet、Manageability 规范分层推进,便于物理层和管理面独立迭代。
UALink 的约束:
- 交换芯片是关键瓶颈:协议文本成熟不等于系统成熟,UALink Switch 的量产、互操作、RAS 和管理软件决定落地速度。
- 跨厂商语义一致性难:即使 Fabric 统一,端侧 MMU、缓存策略、Atomic、Fence 和驱动运行时也需要统一。
- 网内计算处于规范到产品的过渡期:UALink 2.0 已引入 In-Network Compute,但与 NVSwitch SHARP 的成熟度相比,仍需要硬件和通信库验证。
4.3 NVLink 与 UALink 对比
| 维度 | NVLink | UALink |
|---|---|---|
| 标准属性 | NVIDIA 私有协议 | 开放联盟标准 |
| 成熟度 | 已规模部署,NVSwitch/NCCL/SHARP 闭环成熟 | 规范成熟度提升,硬件生态仍在形成 |
| 语义 | NVIDIA GPU 内存语义深度集成 | 面向跨厂商加速器的 Load/Store/Atomic |
| 交换芯片 | NVSwitch 已量产并持续迭代 | UALink Switch 是落地关键变量 |
| 网内计算 | SHARP 已部署 | UALink 2.0 引入的能力,产品化待观察 |
| 生态取舍 | 性能和确定性强,锁定 NVIDIA | 开放潜力高,但协同成本更高 |
5. 以太网增强方案
以太网增强方案的核心思想是“用以太生态承载 Scale-Up 语义”。它不是把 RoCE 原样搬进 Scale-Up,而是在以太网基础上压缩头部、增强流控、增加链路级重传,并把 AXI/事务语义映射为更高效的以太网帧。
这条路线的典型矛盾是:以太网成熟、便宜、开放、可运维,但原始以太网帧并不是为 GPU 远端内存小事务设计的。对于 128B 数据负载,几十字节的以太/IP/UDP 或自定义头部会显著拉低有效载荷比例。因此 SUE/ETH-X/EthLink 都把头压缩、事务聚合、无损流控和重传机制作为核心。
5.1 SUE
SUE,即 Scale Up Ethernet,是 OCP 发布的以太网 Scale-Up 规范,由 Broadcom 贡献。OCP SUE 1.0.0 规范的 Scope 明确是“transport over Ethernet for Load / Store and single-sided memory operations between XPUs”。这说明 SUE 并不是普通 NIC 协议,而是面向 XPU-to-XPU 内存操作的以太网传输框架。
SUE 的目标能力包括:
- 单跳低延迟:典型部署是 single switch hop。
- 规模:最多 1024 个 XPU。
- 事务类型:one-sided operations,memory load-store-atomics,较小事务。
- 延迟目标:E2E latency 小于 2us RTT。
- 带宽:每个 SUE 实例 800Gbps,并可扩展到 1.6Tbps。
- SerDes:200Gbps,同时支持 100G 和 50G。
- 虚拟通道:最多 4 个,用于独立流量类别和避免死锁。
- 以太兼容:支持标准 Ethernet,也提供 compressed header、LLR、CBFC。
SUE 的协议栈逻辑是:
- XPU NoC 发出 command。command 的具体 opcode 和语义由 XPU 定义,SUE 只看到命令、目的 XPU、数据存在标记和长度等字段。
- Mapping and packing layer 按目的端和 traffic class 聚合多个 command,形成 SUE PDU。
- SUE PDU 映射为单个 Ethernet packet。
- 网络头可使用标准 Ethernet/IP/UDP,也可使用 AFH Gen 1 或 AFH Gen 2。
- LLR 和 PFC/CBFC 提供无损链路服务;SUE transport 在不可恢复错误时提供重传。
- 目的端解包后把 command 交回 XPU NoC。
SUE 的关键取舍:
- 语义边界在端侧:SUE 使用 shared memory model,但地址翻译由 XPU 在 SUE instance 外处理;内存注册、保护域等管理也在 SUE 外部。
- 命令透明:SUE 可承载 put/get/atomic,甚至未来 cache coherency 服务,但这些服务的完整实现不是 SUE 的范围。
- 顺序模式可选:strict ordering 保证同一源、目的、VC 的事务按序交付;unordered mode 则允许多端口负载均衡,但顺序不保持。
- 可靠性分层:SUE transport 使用 PSN、ACK/NACK 和 GoBackN 保序和重传;LLR 处理链路层错误;CBFC/PFC 处理无损流控。
- AFH 头压缩:AFH Gen 2 基于 IEEE 802.c 的 Structured Local Address Plan,定义 12B 和 6B 两种 header 选项,降低头部开销。
5.2 ETH-X
ETH-X 是 ODCC/腾讯等推动的 Scale-Up 以太增强协议路线。《ETH-X Scale Up 互联协议白皮书 V1.0》明确指出,ETH-X 是为超节点架构中跨 GPU 高效数据访问设计的协议,适用于大规模 GPU 间高速、低延迟通信。
ETH-X 的整体目标是让 Scale-Up 域内的 GPU、CPU 和内存池协同工作,逻辑上更接近“超级 GPU”。它既要支持 Direct Access,也要支持 Direct Copy,并在未来考虑 Scale-Up 与 Scale-Out 融合。
ETH-X 协议栈如下:
5.2.1 PAXI 事务层
PAXI,即 Peer-to-Peer AXI,是 ETH-X 定义的 GPU-GPU 访存事务层。它把 GPU 侧 CAXI/DAXI/APB 等接口信号转换为可通过以太链路承载的事务包。
PAXI 发送端的大致流程:
- GPU 发出远端访问请求或响应,进入 PAXI 时表现为 DAXI 或 CAXI 接口信号。
- Scale-Up 判断目的端是否有足够 credit,若不足则反压。
- PAXI 根据 AXI User 字段查找 DA Mapping Register,得到目的 GPU 的网络地址。
- AXI 五个独立通道按仲裁规则打包为 TL Flit。
- 同一 DA 的 TL Flit 可继续合并为 MAC Packet;APB TL Flit 优先级最高,CAXI/DAXI 使用 WRR。
- 对每个目的 GPU 维护 AR/AW credit,控制 outstanding 读写事务数量。
- PAXI 保证相同 DA 的事务按到达 PAXI 接口的顺序发送;相同类型、相同地址事务需要相同路径和相同 Flow Entropy。
这一设计说明 ETH-X 把大量“内存语义兑现”工作放到了端侧 IOD/PAXI:包括 AXI 通道仲裁、目的地址映射、credit、保序、聚合和屏障协同。
5.2.2 PRI 帧格式
ETH-X 的数据链路层重点是提升小包转发效率。PRI,即 Packet Rate Improvement,通过压缩以太头来减少事务的固定开销。
ETH-X 白皮书中的效率例子很直观:假设 Load 请求和响应的 Command 各 16B,Data 为 128B,内存事务本身效率为:
128 / (16 + 16 + 128) = 80%
如果直接放在以太上传输,加入 34B IP 包开销,效率变为:
128 / (16 + 16 + 128 + 34 + 34) = 56%
当头部压缩到 6B 时,效率提升为:
128 / (16 + 16 + 128 + 6 + 6) = 74%
再叠加多事务聚合,例如 4 组请求聚合,白皮书给出的例子可提升到约 77%。这也是以太增强方案必须做头压缩和聚合的直接原因。
ETH-X PRI 帧的关键元素:
- 12B PRI 统一转发头,取代以太网帧中的 DMAC 与 SMAC。
- 前 2B 为 Network DeviceID,用作网络路由字段。
- 其余 10B 为 User Defined Address,供设备内部寻址,网络转发节点忽略。
- 2B EtherType 作为新型以太网标识。
- TTL、DSCP、ECN 和 Flow Entropy 支持生命周期、QoS、拥塞标记和负载均衡。
- VLAN+PRI 增强帧可同时支持隔离和头部压缩。
5.2.3 可靠性、流控和调度
ETH-X 数据链路层还包括:
- L2 LLR:链路层重传机制,利用扩展前导码承载报文序列号,降低链路错误恢复开销。
- CBFC:信用式流控,在链路伙伴之间维护
Credit Consumed与Credit Freed计数器,减少缓冲需求并支持更多无损 VC。 - PFC:基础优先级流控,用于无损优先级队列。
- ECMP:通过 PRI 头部中的 Flow Entropy 做等价路径负载均衡。
- QoS:识别 PRI 的 DSCP 和 VLAN PCP,把 Direct Access、Direct Copy、控制流等送入不同调度队列。
- 物理层:遵循 IEEE 802.3 PMD/PCS,支持 100G、200G、400G、800G 速率,并面向 50G/100G/200G lane 演进。
5.2.4 D2D 与 IO Chiplet
ETH-X 白皮书还把计算 Die 与 IO Die 的 D2D 互联作为重要组成。采用 IO Chiplet 的优势是把计算工艺和 IO 工艺解耦,便于复用已有 IO 芯粒,并按产品档位灵活配置互联带宽。UCIe 可作为计算 Die 与 IO Die 的互联基础,其适配层提供 CRC、重传、电源管理和多协议复用能力。
这意味着 ETH-X 的工程形态更像“XPU + IOD + Ethernet Switch”的组合,而不是单纯在 GPU 上加一个以太口。
5.3 EthLink
EthLink,即 Ethernet Link,是字节跳动在《GPU Scale-up 互联技术白皮书》中提出的自研 Scale-Up 网络协议。EthLink 目标是为 AI 集群提供低延迟、高带宽的高速互联传输。白皮书中更具体地说明,EthLink 同时承载 GPU 发起的 Load/Store 语义和 RDMA 语义,网络范围覆盖 GPU 服务器内部互联和跨机 GPU 互联。
EthLink 的基本判断是:Scale-Up 不应只支持 Load/Store,也不应把传统 RDMA 原样搬进 GPU 内部。Load/Store 适合小块、离散地址和时延敏感场景,例如控制信息、推理和细粒度同步;RDMA 适合 MB 到 GB 级大块数据搬运,可以减少 SM 或计算引擎持续生成 Load/Store 地址的开销,更适合训练中的张量并行、专家并行等大流量通信。因此,EthLink 把双语义支持作为核心设计点。
EthLink 协议栈如下:
5.3.1 语义层与事务层
EthLink 在 GPU 侧把协议栈分为 Scale-Up 语义层和 Scale-Up 网络层。语义层又分为 GPU 操作和 Scale-Up 事务层:GPU 操作包括 Load、Store、RDMA Write、RDMA Write with Immediate、RDMA Read、Atomic 和 Message;事务层则把这些操作转换成 Memory Read、Memory Write、Atomic 和 Message 等基础事务,再形成网络报文发往远端 GPU。
这种映射关系可以概括为:
| GPU 操作 | EthLink 事务映射 | 主要用途 |
|---|---|---|
| Load | 单次 Memory Read | 小块远端读取、低时延访问 |
| Store | 单次 Memory Write | 小块远端写入 |
| RDMA Write | 多个 Memory Write | 大块数据写入远端 Global Memory |
| RDMA Write with Immediate | 多个 Memory Write + 1 个 Write Message | 大块写入并向远端 SM 传递立即数或通知 |
| RDMA Read | 多个 Memory Read | 从远端 Global Memory 读回大块数据 |
| Atomic | Atomic 事务 | 远端同步与计数类操作 |
| Message | Message / Write Message | 控制信息和通知 |
白皮书还给出一个偏软件协同的 Cache Coherency 选择:从片外 Global Memory Load 到 GPU 内 Shared Memory 时,数据可以缓存在 Cache 中;从 Shared Memory Store 回片外 Global Memory 时不写入 Cache,而是直接写入片外内存;必要时由系统软件清除 Cache,保证 Cache 与片外 Global Memory 一致。这个选择体现了 EthLink 的边界:它希望避免在更大 Scale-Up 网络中强行用网络硬件维护完整 cache coherency,把一致性成本转移给更可控的软件和运行时阶段。
5.3.2 报文封装、可靠性和拓扑
EthLink 的网络层重点包括 OEFH、RH、LLR、CBFC 和 Switch Event Notification。
- OEFH,即 Optimized EthLink Forwarding Header,用更短的头部替代标准 ETH+IP+UDP 头,以降低报文开销。OEFH 包含 source GPU ID 和 destination GPU ID,交换机可根据 GPU ID 转发。
- RH,即 Reliability Header,用于端到端可靠性,是对链路层 LLR 的补充。
- LLR 处理链路上的 CRC 错误等丢包。发送端缓存报文,发生错误时在链路层重传,直到对端确认收到。这样可以降低对强 FEC 的依赖,使 RS-272 等低延迟 FEC 更可行;如果引入光互联,也有利于使用 LPO 来降低光链路延迟。
- CBFC/PFC 处理交换机内部 buffer 丢包。白皮书更强调 CBFC,因为它可与 VC 绑定,并通过 credit 更精确地感知对端 buffer 状态。
- Switch Event Notification 用于单层交换拓扑的故障反馈。Scale-Up 为降低延迟通常采用单层交换;一旦远端链路或端口故障,源 GPU 未必天然知道跨交换机的远端链路状态,因此交换机需要快速把 port event 反馈给源 GPU,让 GPU 侧 multi-path 尽快切换路径。
在拓扑上,EthLink 假设每个 GPU 服务器部署多个 EthLink 协议栈,每个协议栈支持 1 到 4 个以太网接口,服务器之间通过低时延以太交换机互联,同一个 Scale-Up 网络域最大支持 1024 个 GPU 节点。多协议栈和多端口可以提升带宽,但 Multi-Path 负载均衡会引入跨协议栈乱序;白皮书明确指出,这类乱序无法完全在 EthLink 内部保序,需要由上层应用处理。
5.3.3 EthLink 的关键取舍
EthLink 的优势在于语义覆盖更完整:它把 Load/Store 和 RDMA 都放进 GPU Scale-Up 域,而不是只强调细粒度访存或只强调大块搬运。对于训练,RDMA 语义有利于大块模型并行流量;对于推理和控制面,Load/Store 语义有利于小块、离散地址和低时延访问。OEFH、RH、LLR、CBFC 和 Switch Event Notification 也说明它不是普通 RoCE,而是面向 GPU Scale-Up 做了头部、可靠性和故障反馈优化。
EthLink 的约束也很清晰:它目前主要来自字节跳动白皮书和产业文章,标准化开放程度、跨厂商互操作、交换芯片支持、通信库适配和外部生态成熟度仍需观察。由于多协议栈负载均衡可能把乱序暴露给上层,实际 Goodput 和 P99/P999 延迟会高度依赖 GPU 端事务引擎、运行时、通信库和应用对乱序的处理能力。
5.4 SUE、ETH-X 与 EthLink 对比
| 维度 | SUE | ETH-X | EthLink |
|---|---|---|---|
| 组织与定位 | OCP 规范,Broadcom 贡献,以太 Scale-Up transport | ODCC/腾讯等白皮书,面向超节点 GPU 互联 | 字节跳动自研白皮书方案,面向 GPU Scale-Up 以太互联 |
| 上层接口 | XPU command,可类似 AXI4 或自定义 signal | PAXI,显式对接 CAXI/DAXI/APB | GPU 操作层,支持 Load/Store、RDMA、Atomic、Message |
| 事务抽象 | SUE command / PDU | PAXI TL Flit / MAC Packet | Memory Read、Memory Write、Atomic、Message |
| 头压缩 | AFH Gen 1 / Gen 2,6B 或 12B 选项 | PRI 12B 统一转发头,VLAN+PRI 可选 | OEFH,按 source/destination GPU ID 转发,替代 ETH+IP+UDP 头 |
| 可靠性 | E2E Retry、PSN、ACK/NACK、GoBackN,LLR | L2 LLR,PAXI credit,CBFC/PFC | RH 补充端到端可靠性,LLR 处理链路错误,CBFC/PFC 处理 buffer 丢包 |
| 顺序 | strict / unordered 模式 | 同 DA 顺序、同类型同地址同路径 Flow Entropy | 同路径需保序;Multi-Path 跨协议栈乱序由上层应用处理 |
| 地址与路由 | XPU 外部处理,SUE 不定义完整内存管理 | DA Mapping Register 映射 GPU ID 到网络地址 | OEFH 携带源/目的 GPU ID,交换机按 GPU ID 转发 |
| 拓扑与规模 | 单跳低延迟,最多 1024 XPU | 面向超节点与 IO Chiplet/D2D 组合 | 每服务器多 EthLink 协议栈,每栈 1-4 个以太口,域内最多 1024 GPU |
| 物理生态 | 以太 SerDes、以太交换、OCP 生态 | 以太 PHY/MAC/交换,加 IO Chiplet/UCIe 适配 | 低时延以太交换、低延迟 FEC、LLR/CBFC,强调以太生态复用 |
| 开放边界 | 规范较清晰,但 XPU opcodes 不透明 | 白皮书较系统,PAXI/PRI/LLR/CBFC 细节更面向实现 | 白皮书披露较完整,但标准化、跨厂商互操作和外部生态仍待观察 |
6. 关键维度横向比较
| 维度 | Flit 原生总线:NVLink / UALink | 以太网增强:SUE / ETH-X / EthLink |
|---|---|---|
| 基本抽象 | 内存事务原生进入 Fabric | AXI/命令/LS/RDMA 语义映射到以太网帧 |
| 封装单位 | 固定或强约束 Flit | 变长以太网帧,靠头压缩与聚合优化 |
| 小包效率 | 头部小、解析固定,目标 90% 以上 | 标准以太小包效率低,需 AFH/PRI/OEFH/聚合提升 |
| 延迟确定性 | 更强,交换与流控为内存事务定制 | 依赖交换芯片 cut-through、端侧代理、聚合与流控 |
| 事务粒度 | 适合细粒度 Load/Store/Atomic | SUE/ETH-X 偏端侧命令或 AXI 事务;EthLink 显式区分 LS 小包和 RDMA 大块搬运 |
| 地址空间 | NVLink 私有统一域;UALink 支持 Fabric/网络地址模型 | 地址翻译多由 XPU/IOD 厂商实现 |
| 流控 | 信用流控、虚拟通道、链路级重传 | LLR + CBFC/PFC + transport replay/credit/RH |
| 交换芯片 | 专用 NVSwitch / UALink Switch | 复用或增强以太交换芯片 |
| 网内计算 | NVSwitch SHARP 成熟;UALink 2.0 规范引入 | ETH-X 白皮书定义 INCA 术语;SUE/EthLink 本身不主张完整网内计算 |
| 生态 | NVLink 封闭成熟,UALink 开放待成熟 | 以太生态成熟,Scale-Up 语义需端侧补齐 |
7. 工程取舍
7.1 性能优先时,Flit 原生更自然
Direct Access 的最大敌人不是平均带宽,而是每一笔远端 Load/Store/Atomic 的尾延迟和顺序不确定性。Flit 原生方案从 TL/DL/PL 到 Switch 都知道自己在承载内存事务,可以更早、更硬件化地处理:
- 请求和响应压缩。
- 同地址保序。
- Atomic 返回。
- Fence 排空。
- 信用回收。
- 多播和规约。
因此,强同步、小包高频、TP-heavy、长上下文 KV Cache 共享等场景更偏向 Flit 原生路线。
7.2 生态优先时,以太增强更现实
以太增强方案的吸引力在于供应链和系统工程:
- SerDes、连接器、线缆、光模块、交换芯片、运维工具成熟。
- 多厂商可以围绕以太交换和开放帧格式协作。
- 产品化可以从标准以太能力渐进增强,例如先支持标准帧,再支持 AFH/PRI/OEFH、LLR、CBFC。
- 与现有数据中心网络、SONiC、遥测和运维体系更容易融合。
但它的代价是,内存语义不天然存在于以太 Fabric 中,必须由端侧 IOD、事务代理、驱动、运行时和通信库共同补齐。只要任何一环处理不好,Goodput、P99 延迟和可调试性都会受影响。
7.3 关键不是峰值带宽,而是 Goodput
Scale-Up 的有效性能取决于:
- 有效载荷比例:头部、FEC、重传、信用消息和空闲填充都会吃掉带宽。
- Outstanding 深度:远端响应越慢,端侧队列越容易被占满。
- 保序粒度:全局保序简单但吞吐低,选择性保序复杂但更高效。
- Fence 代价:系统级屏障可能阻塞多个 GPU 和多个 IOD 平面。
- 负载均衡与顺序冲突:多路径提升带宽,但同地址事务必须避免乱序。
- 可观测性:没有端到端计数器、时间戳和事件关联,就很难定位 Goodput 损失。
8. 选型建议
具体建议:
| 场景 | 更适合的路线 | 原因 |
|---|---|---|
| NVIDIA GPU 机柜级超节点 | NVLink / NVSwitch | 性能、SHARP、NCCL/NVSHMEM 和系统软件成熟 |
| 多厂商 XPU 但追求原生内存语义 | UALink | 开放 Flit 总线,语义更接近 NVLink |
| 国内/自研 XPU,重视以太供应链 | ETH-X | PAXI、PRI、LLR、CBFC 和 IO Chiplet 路线完整 |
| 需要同时覆盖 LS 小包和 RDMA 大块搬运 | EthLink | 语义层同时定义 Load/Store 与 RDMA,并映射到 Memory Read/Write/Atomic/Message |
| 以太交换芯片生态优先,XPU 可自定义命令 | SUE | OCP 规范清晰,AFH/LLR/CBFC 复用以太能力 |
| 大块搬运、Direct Copy、EP/DP 流量占优 | SUE / ETH-X / EthLink | 聚合或 RDMA 化后,以太增强方案效率更容易接近目标 |
| 细粒度同步、远端 Atomic、频繁 Fence | NVLink / UALink | 端到端强语义和低延迟更关键 |
9. 后续跟踪指标
后续判断哪条路线真正可用,不能只看 PPT 上的带宽,而要看以下可量化指标:
- 端到端 RTT 与 P99/P999 延迟,分别测 64B、128B、256B、1KB、4KB。
- 小包 Goodput,区分标准以太网帧、压缩头、聚合开启和聚合关闭。
- Atomic 与 Fence 延迟,尤其是跨多 GPU、多 IOD、多路径场景。
- 同地址保序和 Flow Entropy 策略,是否在负载均衡和正确性之间可调。
- 交换芯片能力,是否支持 cut-through、LLR、CBFC、PRI/AFH/OEFH 解析、QoS 和遥测。
- 通信库承接情况,NCCL、RCCL、OpenSHMEM、NVSHMEM 类库是否真正使用新语义。
- RAS 与故障恢复,链路错误、重传风暴、端点故障、热插拔和降级运行如何处理。
- 多厂商互操作,地址空间、Atomic、Fence、管理面和安全隔离是否一致。
10. 总结
Flit 原生总线和以太网增强方案会长期并存。前者更像“把远端 GPU 继续组织成本地可编程资源”,后者更像“把成熟以太网改造成足够好的 Scale-Up 事务传输层”。
NVLink 已经证明了强语义总线在 AI 超节点中的价值;UALink 试图把这种能力开放化、标准化。SUE、ETH-X 和 EthLink 则试图把以太生态拉进 Scale-Up 域,以更低供应链门槛换取接近专用总线的效率。最终胜负不会只由链路速率决定,而会由端侧事务引擎、交换芯片、通信库、运行时、RAS 和可观测性共同决定。
如果用一句话概括:Flit 原生方案胜在“语义天然、路径短、确定性强”;以太增强方案胜在“生态成熟、成本弹性、产业协同空间大”。真正的系统选型,需要先判断工作负载最缺的是强语义低延迟,还是开放生态和规模化供应链。
11. 参考资料
- DeepLink 超节点白皮书:Scale-Up 总线与互联语义
- NVIDIA NVLink and NVLink Switch
- NVIDIA GB200 NVL Multi-Node Tuning Guide
- NVIDIA Hopper Architecture In-Depth
- NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference
- UALink Consortium Specifications
- OCP Scale Up Ethernet 1.0.0 Specification
- 字节跳动 GPU Scale-up 互联技术白皮书 - 火山引擎开发者社区
- 全国首个!字节跳动发布 EthLink,填补以太网 GPU Scale-up 互联协议空白 - 火山引擎开发者社区
- UALink_Common_Specification_v2.0_Final_evaluationcopy-1.pdf
- UALink_2.0_Link_and_Physical_Layers_200G_Final_evaluationcopy.
- HC28.22.121-Pascal-GPU-DanskinFoley-NVIDIA-v06-6_7.pdf
- ETH-X Scale Up 互联协议白皮书 V1.0.pdf

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)