神经网络如何学习:从损失函数到反向传播
上一篇把神经网络讲成了一个带参数的函数:输入 x 进入 f(x; θ),输出预测值 ŷ。这篇继续回答一个更具体的问题:如果这个函数一开始猜得很差,它怎么知道该把哪些参数调大、哪些参数调小?
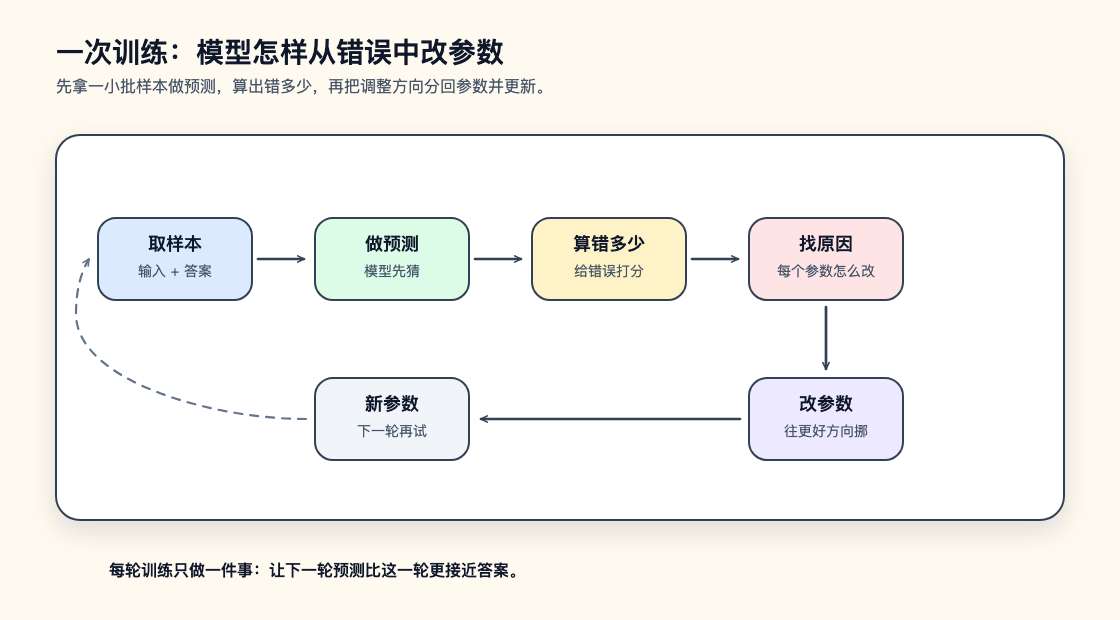
先不要急着给每个步骤起名字。可以先把训练想成调一台老式收音机。旋钮的位置就是模型参数,当前声音的杂音大小就是错误。训练要做的事不是“让机器突然理解音乐”,而是每次听一下现在有多糟,再判断旋钮该往哪边拧一点。
神经网络训练也是这样的训练闭环:先用当前参数做一次预测,再把预测错得有多离谱变成一个数字,然后算出每个参数对这个错误的影响,最后按这个方向更新参数。术语可以晚一点出现,先抓住这一层直觉:模型是被错误一点点推着变好的。
从一条猜错的直线开始
训练听起来像一个很大的系统,其实可以先压缩到一条直线。只要看懂这条直线怎么从“猜错”变成“更接近答案”,后面的神经网络训练就不再神秘。
假设我们要用气温预测一家门店当天卖出的冰淇淋数量。为了让例子足够简单,先只用一个输入 x,模型也只是一个线性模型:
ŷ = ax + b
这里的 x 是气温,ŷ 是模型预测的销量,a 和 b 是模型可以调整的参数。a 控制气温变化会把销量往上推多少,b 控制没有看气温时的基础销量。真实世界当然还会受周末、门店位置、促销活动影响,但这个小例子足够说明训练的第一件事:模型不是从一开始就知道 a 和 b 应该是多少。
假设真实数据大致符合第一篇里的形式 y = ax + b。为了算得具体一点,这里取真实的 a = 2、b = 1。当 x = 1.5 时,真实答案 y 接近 4。模型刚初始化时可能很离谱,比如 a = -0.4、b = 0。这时它会预测:
ŷ = -0.4 × 1.5 + 0 = -0.6
真实答案接近 4,模型却预测 -0.6。这不是模型“想错了”,只是当前参数让这条直线指向了错误方向。训练的任务,就是用一批这样的样本不断修正 a 和 b,让预测值 ŷ 更接近真实值 y。
问题马上变得具体起来。模型知道自己错了还不够,它还需要知道错了多少,以及应该怎么改参数。如果只是对模型说“你错了”,参数不会自动变好;训练必须把“错得离谱”变成一个可计算、可比较、可下降的数。
损失函数:先给错误打一个分
损失函数做的事很像改卷。它不负责预测,也不直接修改参数,只负责把“模型答案”和“标准答案”的差距变成一个分数。这个分数通常叫损失值 loss,越小越好。
MSE = mean((ŷ - y)^2)
这个公式可以直接读成一句话:先看预测值 ŷ 和真实值 y 差多少,把差值平方,再对一批样本求平均。平方有两个直观效果。第一,预测高了和预测低了不会互相抵消;高 3 和低 3 都会变成 9。第二,大错误会被放大;错 10 的惩罚不是错 1 的十倍,而是一百倍。
回到刚才的单个样本。真实答案接近 4,模型预测 -0.6,误差是 -4.6。如果只看这个样本,平方误差就是:
(-0.6 - 4)^2 = 21.16
这个数字不需要有生活语义,它只需要稳定地表达“当前参数很不好”。当参数改得更合适时,这个数字应该下降。比如模型后来预测 3.8,平方误差就变成 0.04。训练就是追着这个数字往下走。
分类任务里的损失函数会换一种形式。比如手写数字识别的真实答案是 7,模型会输出 0 到 9 每个数字的概率。如果它给 7 的概率只有 0.02,说明它对正确答案几乎不相信,损失应该很高;如果它给 7 的概率是 0.93,损失应该很低。交叉熵就是用来衡量这种“正确类别概率够不够高”的损失函数。
语言模型也是类似逻辑。给定前文“今天天气很”,训练数据里的下一个字、词或词片段是“好”。如果模型给“好”的概率很低,交叉熵就会惩罚它;如果概率很高,损失就会下降。所以语言模型训练时不是直接学习“写得优美”,而是在大量位置上学习“真实的下一个片段应该获得更高概率”。
损失函数和评价指标不要混在一起。准确率、F1、BLEU、人工评分可以评价模型效果,但它们未必适合直接推动参数变化。训练需要的是一个对微小参数变化足够敏感、后续能通过梯度传回每个参数的目标。
比如准确率只统计预测对了多少个样本,一次参数微调只要没有改变最终类别,准确率可能完全不变;F1 把精确率和召回率合在一起,适合类别不均衡的分类评估;BLEU 比较生成文本和参考答案的词片段重合度,更常用于机器翻译;人工评分让人按可读性、事实性、相关性等标准打分,能覆盖自动指标漏掉的质量问题,但成本高且不能直接求梯度。这些指标适合在验证集或测试集上回答“模型好不好”,损失函数则要回答“参数下一步怎么改”。
梯度:告诉参数该往哪边动
有了损失函数以后,每一组参数都会对应一个损失值。现在的问题变成:如果 a 和 b 可以动,应该怎么动才能让 loss 变小?
先看最简单的情况:只让 a 变化,暂时把 b 固定住。这时横轴可以画成 a,纵轴可以画成 loss。当前参数落在曲线上的某一点,在这一点画一条切线,切线的斜率就是这一点的导数,也可以先理解成这里的“梯度”。所以在单参数场景里,梯度不是 k 的倒数,而更接近你熟悉的切线斜率 k。
这个斜率的正负已经告诉我们该往哪边改。如果斜率 k > 0,说明 a 稍微变大时 loss 会变大,那就应该把 a 往小调;如果斜率 k < 0,说明 a 稍微变大时 loss 会变小,那就应该把 a 往大调;如果 k 接近 0,说明附近比较平,继续调这个参数带来的变化不明显。
对刚才的直线模型来说,a 决定线的倾斜程度,b 决定线整体上移或下移。如果当前 a = -0.4,模型在 x = 1.5 时预测太低,那么把 a 稍微调大,预测值就会往上走,loss 大概率会下降。梯度把这种“调大一点会变好还是变坏”的判断写成了数学量,而不是靠人凭直觉猜。
当 a 和 b 同时可以调整时,loss 不再是一条只沿着 a 变化的曲线,而是一个铺在 a、b 两个方向上的损失曲面。此时我们需要两个偏导数,也可以先把它们理解成两个斜率:∂loss/∂a 表示只动 a 时 loss 怎么变,∂loss/∂b 表示只动 b 时 loss 怎么变。把这些斜率合在一起,就是梯度。参数更多时也是同样逻辑:梯度就是“每个参数各自该往哪边动、影响有多大”的一组数字。
最朴素的更新公式只有一行:
参数 = 参数 - 学习率 × 梯度
这里的减号可以直接按斜率理解。斜率为正,减去一个正数,参数会变小;斜率为负,减去一个负数,参数会变大。多个参数时也是一样,只是每个参数都有自己的斜率。把这些局部斜率合起来,就能判断哪边更容易让 loss 变大;训练时不往那边走,而是沿相反方向小步移动。学习率控制每次走多远。学习率太小,loss 可能确实下降,但训练会非常慢;学习率太大,参数可能一次跨过低点,在两边来回震荡,甚至让 loss 变成 NaN。
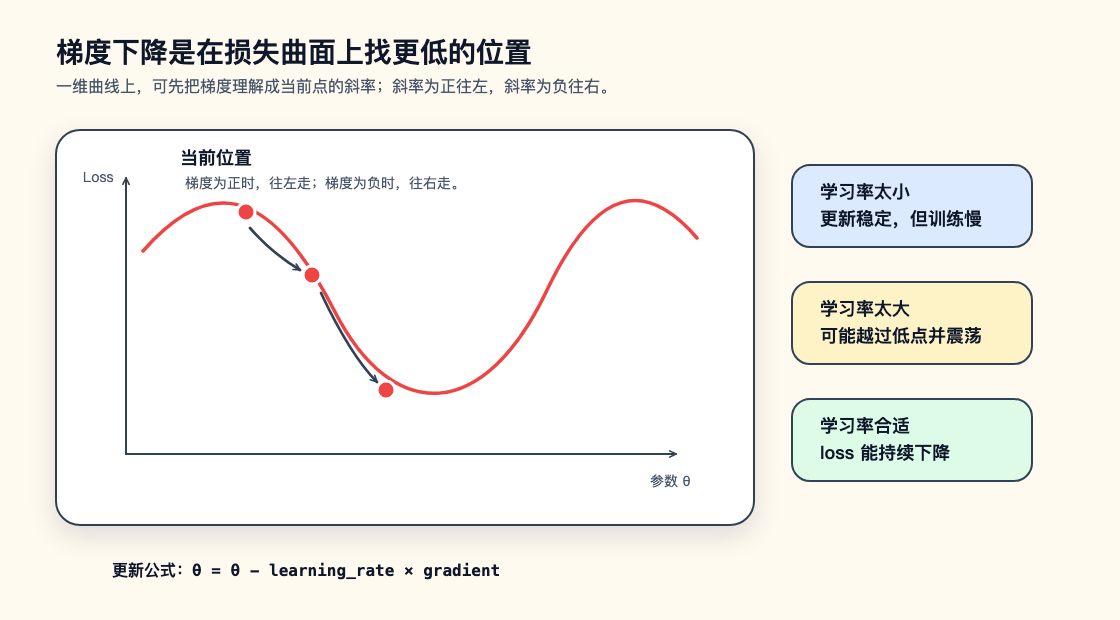
这就是梯度下降。名字听起来重,其实核心动作很朴素:每次只看当前位置的坡度,往 loss 变小的方向挪一步。真实神经网络有几百万、几十亿甚至更多参数,loss 曲面也不会像图里那样平滑,但每一步仍然遵守同一件事:根据当前这一小批数据算梯度,再用梯度更新参数。
前向传播:先用当前参数走一遍
现在可以给“用当前参数做预测”这一步起名字:前向传播。它的意思就是“输入从模型入口一路算到输出”。如果还要训练,前向传播通常会继续把输出交给损失函数,得到 loss。
在直线模型里,前向传播只有一步:
ŷ = ax + b
在神经网络里,前向传播会经过多层线性计算、激活函数、注意力模块或其他结构。虽然中间更复杂,但方向没有变:输入先进来,按模型定义的计算路径一路往前走,最后得到预测。
手写数字识别可以这样理解。输入是一张 28 x 28 的灰度图,模型先把像素变成一串数字,再经过多层计算,最后输出 10 个分数。每个分数对应一个数字类别。前向传播结束后,模型可能认为“7”的分数最高,也可能错误地认为“1”的分数最高。损失函数再把这些分数和真实标签比较,算出本轮预测的 loss。
所以,前向传播不是训练的全部。它只回答“用现在的参数会预测出什么”。模型要变好,还需要下一步:根据 loss 反过来判断每个参数的责任。
反向传播:把最终错误分回每个参数
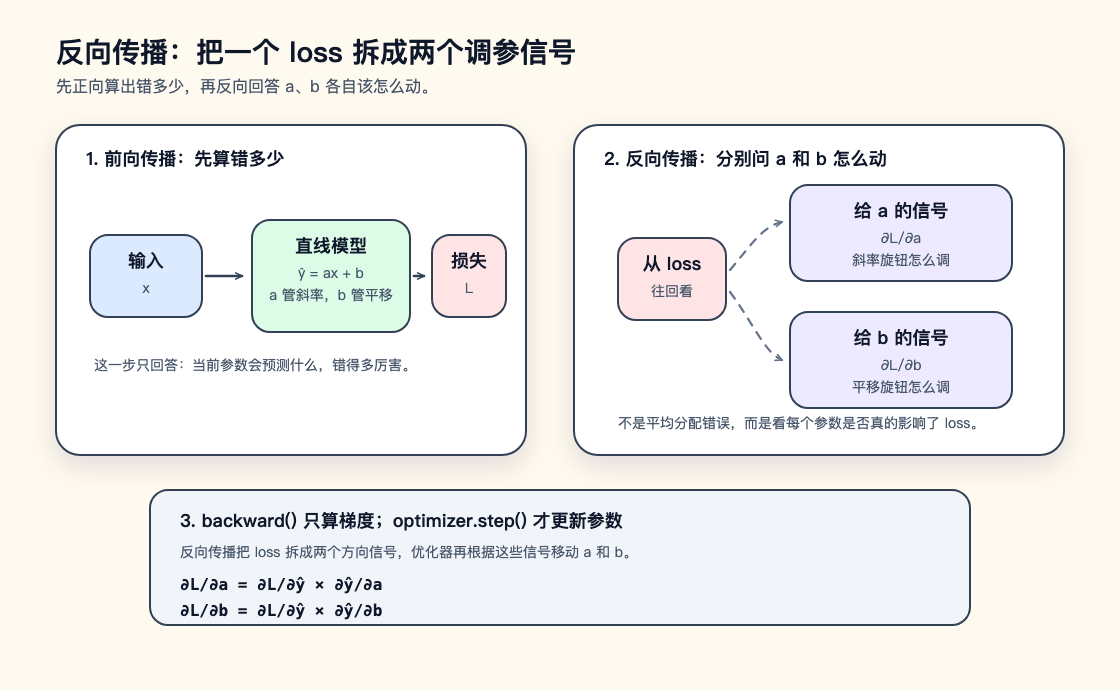
反向传播经常让初学者卡住,因为它听起来像模型在做某种深层反思。其实它只是一个高效的算梯度方法:前向传播先算出这次错了多少,反向传播再把这个错误拆成每个参数各自的调参信号。
继续用 y = ax + b 来看。a 像一个控制直线倾斜程度的旋钮,b 像一个控制整条直线上下平移的旋钮。模型预测错了以后,训练代码要分别判断:a 多拧一点,loss 会变大还是变小;b 多拧一点,loss 会变大还是变小。反向传播做的就是把这两个判断算出来。
先把前向传播写成两行:
ŷ = ax + b
L = loss(ŷ, y)
第一行用当前的 a 和 b 算预测值 ŷ,第二行把预测值 ŷ 和真实答案 y 比较,得到 loss。反向传播倒过来读这条路径:先看 ŷ 变大或变小时 loss 会怎么变,再看 a 和 b 分别会怎样推动 ŷ。
这件事依赖链式法则。如果要知道 a 该怎么改,不能只看 a 本身。a 先影响预测值 ŷ,预测值 ŷ 再影响最终的 L,所以要把这两段影响乘起来。b 也是同样逻辑:
∂L/∂a = ∂L/∂ŷ × ∂ŷ/∂a
∂L/∂b = ∂L/∂ŷ × ∂ŷ/∂b
公式里的 ∂L/∂a 可以读成“loss 对 a 的变化有多敏感”。如果这个值是正的,优化器通常会把 a 调小一点;如果这个值是负的,优化器通常会把 a 调大一点;如果接近 0,说明当前这一小批数据下,继续改 a 对 loss 的影响不明显。∂L/∂b 也是同一种信号,只是它告诉优化器 b 该怎么动。
这就是“把最终错误分回每个参数”的意思。它不是把错误平均分给 a 和 b,而是沿着前向传播留下的计算路径,分别计算每个参数对 loss 的影响方向和影响大小。真实神经网络会有更多中间层和更多参数,但反向传播做的仍然是这件事。深度学习框架的自动微分会记录前向传播的计算图,并在 loss.backward() 时自动填好每个参数的 .grad。开发者不需要手写每一层的偏导数,但需要知道 backward() 只是算出调参信号,真正修改参数的是后面的优化器。
用五行 PyTorch 代码看清训练闭环
大多数 PyTorch 训练代码都可以压缩成下面这几行。它们看起来短,是因为框架把计算图记录、梯度计算和参数更新都封装好了。
for x, y in dataloader:
optimizer.zero_grad()
y_pred = model(x)
loss = loss_fn(y_pred, y)
loss.backward()
optimizer.step()
这段代码可以按训练闭环逐行读。optimizer.zero_grad() 先清空旧梯度,因为 PyTorch 默认会累加梯度;如果忘了这一步,本轮小批数据(batch)的梯度会和上一轮混在一起。model(x) 是前向传播,模型用当前参数做预测。loss_fn(y_pred, y) 把预测和真实答案之间的差距变成一个 loss。
loss.backward() 是反向传播入口,它会沿着前向传播记录下来的计算图,计算每个可学习参数的梯度,并把结果放在参数的 .grad 字段里。optimizer.step() 才真正修改参数;如果只调用 backward(),模型不会自动变好,它只是知道了该怎么改。
验证阶段故意少了两步:
model.eval()
with torch.no_grad():
for x, y in validation_loader:
y_pred = model(x)
loss = loss_fn(y_pred, y)
model.eval() 会让 dropout、batch normalization 这类训练期行为切换到评估模式。torch.no_grad() 告诉框架不要记录计算图,因为验证只看当前模型表现,不更新参数。训练和评估的根本差别就在这里:训练需要梯度来改参数,评估只需要预测结果来算指标。
从零写一个小训练器
为了把训练闭环拆到最小,下面直接用一段普通 Python 代码演示,不依赖 PyTorch。这个例子拟合 y = ax + b,并用真实参数 a = 2、b = 1 生成可验证的样本。模型一开始不知道这两个参数,只能通过“预测、算错多少、算梯度、更新参数”的循环,把 a 和 b 慢慢调到正确位置。
完整代码如下。代码里的注释故意写得比较细,读的时候可以把它当成一个最小训练循环的拆解版:
def make_samples():
# 真实函数是 y = 2x + 1。
# 模型训练前并不知道 a 应该等于 2、b 应该等于 1;
# 这些样本只负责告诉模型:给定某个 x,正确答案 y 是多少。
samples = []
for x in [-2, -1, 0, 1, 2, 3, 4]:
y = 2 * x + 1
samples.append((float(x), float(y)))
return samples
def iter_batches(samples, batch_size):
# 每次只取一小批样本,模拟真实训练里的 batch。
# 这里不打乱样本,是为了让例子更容易阅读;
# 真实训练中通常会在每轮训练前打乱数据顺序。
for start in range(0, len(samples), batch_size):
yield samples[start:start + batch_size]
def predict(a, b, x):
# 模型当前的预测公式也是 y = ax + b。
# a 和 b 是要训练出来的参数,x 是输入。
return a * x + b
def mse_loss(a, b, batch):
# 均方误差会把“预测值 - 真实值”的差距平方后求平均。
# 差距越大,loss 越大;完全预测正确时,loss 等于 0。
total = 0.0
for x, y in batch:
error = predict(a, b, x) - y
total += error ** 2
return total / len(batch)
def mse_gradients(a, b, batch):
# 这里手写 loss 对 a 和 b 的梯度。
# 对单个样本来说:
# error = a * x + b - y
# loss = error ** 2
# 根据求导规则:
# dloss/da = 2 * error * x
# dloss/db = 2 * error
# batch 里有多个样本,所以最后要除以 n,得到平均梯度。
da = 0.0
db = 0.0
n = len(batch)
for x, y in batch:
error = predict(a, b, x) - y
da += 2.0 * error * x / n
db += 2.0 * error / n
return da, db
def train():
samples = make_samples()
# a 和 b 从 0 开始,表示模型一开始只会预测 y = 0。
# 训练的目标,就是把它们逐步更新到接近 a = 2、b = 1。
a = 0.0
b = 0.0
# 学习率控制每次沿梯度反方向移动多远。
# 太大可能来回震荡,太小会学得很慢。
learning_rate = 0.01
# batch_size 表示每次用几个样本估计梯度。
# epochs 表示把全部样本反复看多少轮。
batch_size = 3
epochs = 300
for epoch in range(1, epochs + 1):
epoch_loss = 0.0
batch_count = 0
for batch in iter_batches(samples, batch_size):
# 先用当前参数看看这一小批样本错得多厉害。
loss = mse_loss(a, b, batch)
# 再计算 loss 对 a 和 b 的梯度。
# da 表示 a 增大一点时 loss 会怎么变;
# db 表示 b 增大一点时 loss 会怎么变。
da, db = mse_gradients(a, b, batch)
# 梯度指向 loss 上升的方向。
# 想让 loss 下降,就把参数往梯度的反方向挪一点。
a -= learning_rate * da
b -= learning_rate * db
epoch_loss += loss
batch_count += 1
# 每隔一段时间打印一次,观察 loss 是否下降、参数是否接近真实值。
if epoch == 1 or epoch % 50 == 0:
avg_loss = epoch_loss / batch_count
print(f"epoch={epoch:03d} loss={avg_loss:.6f} a={a:.4f} b={b:.4f}")
return a, b
final_a, final_b = train()
print(f"训练完成: a={final_a:.4f}, b={final_b:.4f}")
运行这段训练代码后,a 会逐渐接近 2,b 会逐渐接近 1。这里没有隐藏机制:error 是预测值和真实值的差,da 表示 loss 对 a 的梯度,db 表示 loss 对 b 的梯度。每个小批数据(batch)都会给出一组新的 da 和 db,训练循环再用它们更新参数。这就是训练的最小版本:先预测,算出错得多厉害,求出参数该怎么动,再把参数往那个方向挪一点。
神经网络只是把这个过程扩展到了更复杂的函数上。参数不再只有 a 和 b 这两个标量,而是许多层里的权重矩阵和偏置;损失函数可能从均方误差变成交叉熵;梯度不再手写,而是由自动微分计算。但训练节奏没有变。
优化器:不改变目标,只改变走法
优化器负责根据梯度更新参数。最朴素的 SGD 会直接按当前梯度走一步。它容易理解,也常常是解释训练的起点。
实际训练里更常见的是小批量梯度下降。模型每次不看完整数据集,而是只看一小批样本。这样计算更快,也会给梯度带来一点噪声。这种噪声并不总是坏事,它有时能帮助模型离开某些不舒服的局部区域。
Momentum 会记住过去几步的方向,像给参数更新加了一点惯性。它能减少参数在狭长区域里左右摇摆的问题,让更新更偏向长期一致的方向。Adam 进一步给不同参数安排不同尺度的步长,所以很多深度学习项目会把它当作默认起点。
优化器再复杂,也没有绕开训练闭环。它不会凭空知道好答案,只是用更聪明的方式处理梯度。数据质量差、损失函数选错、标签和输出对不上、模型结构不适合时,换 Adam 也救不了训练。
训练出问题时先查什么
如果 loss 完全不下降,先不要急着换大模型。更常见的问题是学习率太大或太小,输入没有归一化,标签和模型输出形状对不上,损失函数用错,或者数据加载流程把标签打乱了。一个很实用的检查方法是先拿极小数据集做过拟合测试:让模型只记住十几个样本。如果这都做不到,训练代码本身大概率有问题。
如果训练集 loss 持续下降,但验证集效果变差,模型可能在过拟合。它学会了训练样本里的细节甚至噪声,却没有学到能迁移到新数据的模式。继续降低训练 loss 不一定能解决这个问题,下一篇会专门讲泛化、正则化、dropout 和早停。
如果 loss 变成 NaN,优先检查学习率、输入数值范围和梯度爆炸。语言模型、RNN、深层网络里尤其容易遇到这类数值问题。可以尝试降低学习率、做梯度裁剪、检查是否出现除以零或对非法值取对数。
如果训练很慢,要拆开看瓶颈。可能是批大小(batch size)太小导致硬件利用率低,也可能是数据加载卡住 GPU,还可能是模型参数量过大。训练循环是一个系统,不只是数学公式;数据管道、硬件、内存和日志都会影响速度。
小结
神经网络学习不是神秘过程,而是一个可重复的数值优化闭环。模型先用当前参数预测,损失函数把错误变成一个数字,反向传播计算每个参数的梯度,优化器再根据这些梯度更新参数。
真正写训练代码时,不要只盯着 loss.backward() 这一行。更重要的是确认 loss 是否表达了正确目标,数据是否进入了正确形状,梯度是否稳定,验证集是否真的变好。训练集上的 loss 降下来,只说明模型更适合当前样本;它能不能处理没见过的数据,是下一篇要解决的问题。
名词说明
| 名词 | 解释 | 在本文中的作用 |
|---|---|---|
| 神经网络 | 由线性层、非线性激活和可学习参数组成的函数族。 | 被训练循环不断调整的模型主体。 |
| 函数 | 把输入映射成输出的计算规则。 | 用来把神经网络理解成 f(x; θ) 这样的可调计算过程。 |
| 模型 | 用参数把输入转换成预测结果的计算结构。 | 本文讨论的训练对象。 |
| 训练 | 用数据、损失和梯度反复更新模型参数的过程。 | 解释模型为什么会从错误预测逐步变好。 |
| 训练闭环 / 训练循环 | 预测、计算损失、计算梯度、更新参数并重复执行的流程。 | 串起全文所有训练步骤。 |
| 输入 | 喂给模型用于计算预测结果的数据。 | 在直线例子里是气温 x。 |
| 输出 | 模型完成计算后给出的结果。 | 通常会被拿去和真实答案比较。 |
| 预测 | 模型用当前参数根据输入给出答案的过程。 | 训练闭环的第一步。 |
| 预测值 | 模型输出的具体预测结果,常记为 ŷ。 |
损失函数拿它和真实值比较。 |
| 真实值 | 数据中用于监督模型的标准答案,常记为 y。 |
定义模型当前预测错了多少。 |
| 样本 | 一条训练数据,通常包含输入和对应答案。 | 梯度和损失都从样本中计算出来。 |
| 数据集 | 由许多样本组成的数据集合。 | 可以被切分为训练集、验证集和测试集。 |
| 训练数据 | 训练时用于提供输入和标准答案的数据。 | 语言模型从其中学习下一个片段的概率。 |
| 初始化 | 训练开始前给参数设置初始值的过程。 | 决定模型从哪个位置开始优化。 |
| 线性模型 | 用加权求和和偏置表示输入输出关系的模型,例如 y = ax + b。 |
用最小例子解释参数、损失和梯度。 |
| 参数 | 模型中可被训练更新的权重和偏置,常记为 θ。 |
训练直接修改的对象。 |
| 前向传播 | 从输入开始,按模型结构一路计算到预测值和损失的过程。 | 训练闭环的第一步,用当前参数得到预测。 |
| 损失函数 | 把预测结果和真实答案之间的差距转换成可优化数字的函数。 | 给参数更新提供目标。 |
| 损失值 / loss | 损失函数在某批样本上算出的具体数字。 | 训练要让这个数字逐步下降。 |
| 误差 | 预测值和真实值之间的差。 | 均方误差和梯度计算都从它开始。 |
| 均方误差 | 回归任务常用损失,对预测误差平方后取平均。 | 用来解释连续数值预测如何训练。 |
| 回归任务 | 预测连续数值的任务,例如销量、温度或价格。 | 对应本文里的冰淇淋销量例子。 |
| 分类任务 | 从若干离散类别中选择答案的任务。 | 用手写数字识别解释交叉熵。 |
| 概率 | 模型给某个结果分配的可能性大小。 | 交叉熵会惩罚真实类别概率过低。 |
| 交叉熵 | 分类和语言模型常用损失,惩罚真实类别或真实片段概率过低。 | 说明概率输出如何转成训练目标。 |
| 语言模型 | 根据上下文预测下一个字、词或词片段概率的模型。 | 说明交叉熵如何用于文本训练。 |
| 词片段 / token | 文本被模型处理前切分出的基本单位,可以是字、词或子词。 | 语言模型常以它作为预测目标。 |
| 评价指标 | 训练或验证后衡量模型表现的数值或人工判断,不一定能对参数求梯度。 | 用来区分“优化目标”和“效果评估”。 |
| 准确率 | 预测正确的样本数占全部样本数的比例。 | 说明分类评估里最直观但不总是充分的指标。 |
| 精确率 | 被模型判为正类的样本中,真实正类所占比例。 | F1 的组成部分,关注预测为正时有多可信。 |
| 召回率 | 所有真实正类中,被模型成功找出的比例。 | F1 的组成部分,关注模型漏掉了多少正例。 |
| F1 | 精确率和召回率的调和平均数。 | 类别不均衡或误报、漏报都重要时常用。 |
| BLEU | 文本生成自动评价指标,比较生成文本和参考答案的词片段重合度。 | 说明文本质量评估不等于可直接优化的训练损失。 |
| 人工评分 | 由人按可读性、事实性、相关性等任务标准给模型输出打分或排序。 | 补充自动指标难覆盖的质量判断。 |
| 梯度 | 单参数时可以理解成 loss 曲线在当前位置的导数或切线斜率;多参数时是各个参数对应斜率组成的一组数字。 | 优化器据此决定参数更新方向。 |
| 导数 | 单变量函数在某一点的局部变化率。 | 帮助把单参数梯度理解成切线斜率。 |
| 切线 | 在某一点贴着曲线当前方向的直线。 | 用来直观看到当前位置的局部趋势。 |
| 斜率 | 直线或切线的倾斜程度和方向。 | 单参数情况下可直接类比梯度。 |
| 偏导数 | 多参数函数中,只改变其中一个参数时的变化率。 | 解释 ∂loss/∂a 和 ∂loss/∂b 的含义。 |
| 损失曲面 | 不同参数组合对应不同 loss 时形成的高维形状。 | 说明多参数训练不再是一条简单曲线。 |
| 梯度下降 | 根据当前位置的梯度更新参数,让损失逐步下降的方法。 | 解释参数为什么按“减去学习率乘梯度”的方式变化。 |
| 学习率 | 控制每次沿梯度方向更新多大步长的超参数。 | 决定训练收敛速度和稳定性。 |
| 反向传播 | 从损失出发,沿计算图反向应用链式法则计算梯度的方法。 | 高效得到每个参数的更新依据。 |
| 链式法则 | 复合函数求导规则,用局部导数组合整体导数。 | 反向传播的数学基础。 |
| 计算图 | 记录计算节点以及它们依赖关系的结构。 | 自动微分依赖它从 loss 反推各参数梯度。 |
| 自动微分 | 深度学习框架自动记录计算图并计算梯度的机制。 | 让开发者不必手写每一层偏导数。 |
| 标签 | 训练数据里的标准答案,例如图片所属类别或文本的下一个词片段。 | 损失函数拿它和模型预测比较。 |
| 线性计算 | 通过乘权重、求和、加偏置得到输出的计算。 | 神经网络前向传播中的常见基础操作。 |
| 激活函数 | 在线性计算后加入非线性的函数,例如 ReLU、GELU、sigmoid。 | 让多层网络能表达非线性关系。 |
| 注意力模块 | 根据输入之间的相关性分配权重,让模型聚合更相关的信息。 | 说明前向传播中可能出现的复杂结构。 |
| 灰度图 | 只包含亮度信息的图像,常用一个二维数字矩阵表示。 | 用手写数字识别说明图像输入如何进入模型。 |
| 像素 | 图像中最小的显示或采样单元。 | 会被转换成模型可以处理的数值输入。 |
| 权重矩阵 | 线性层中可训练的矩阵参数,把输入向量映射到新的表示空间。 | 神经网络参数的常见形态。 |
| 偏置 | 在线性计算后额外加上的可训练常数或向量。 | 让模型输出不必强制经过原点。 |
| 深度学习框架 | 提供张量计算、自动微分、模型组件和优化器的开发工具。 | 让 PyTorch 这类工具能封装训练细节。 |
| PyTorch | 常用深度学习框架。 | 用五行代码展示训练闭环的框架写法。 |
| 优化器 | 根据梯度和更新策略修改参数的算法。 | 训练闭环里真正执行参数更新。 |
| SGD | Stochastic Gradient Descent,随机梯度下降。 | 最基本的优化器形式。 |
| 小批量梯度下降 | 每次使用一小批样本估计梯度并更新参数。 | 兼顾计算效率和训练稳定性。 |
| 小批数据 / batch | 一次前向传播和反向传播共同处理的一组样本。 | 决定每一步梯度来自哪些样本。 |
| 批大小 | 一个 batch 中包含的样本数量。 | 影响显存占用、梯度噪声和硬件利用率。 |
| Momentum | 在参数更新中累积历史梯度方向的优化技巧。 | 减少抖动,让更新更稳定。 |
| Adam | 结合梯度一阶矩和二阶矩估计的常用优化器。 | 深度学习训练中的常见默认选择。 |
| 训练集 | 用来计算损失、反向传播并更新参数的数据。 | 模型直接从这些样本中学习。 |
| 验证集 | 训练过程中保留出来评估模型的数据,不参与参数更新。 | 用来观察模型是否真的泛化。 |
| 验证阶段 | 训练过程中只评估模型表现、不更新参数的阶段。 | 对应 model.eval() 和 torch.no_grad() 的使用场景。 |
| 测试集 | 最后评估模型的数据,通常不参与调参。 | 给出更接近真实部署表现的估计。 |
| 过拟合 | 模型在训练集表现很好,但在新数据上表现变差。 | 说明 loss 下降不等于泛化成功。 |
| 泛化 | 模型在没有见过的数据上仍能保持有效表现的能力。 | 解释验证集效果为什么比训练集 loss 更重要。 |
| 正则化 | 通过约束模型复杂度或训练行为来减少过拟合的方法。 | 是应对验证集效果变差的常见手段。 |
| Dropout | 训练时随机关闭一部分神经元输出的正则化方法。 | 解释 model.eval() 为什么会改变模型行为。 |
| Batch Normalization | 用小批数据统计量对中间激活做标准化的层。 | 训练和评估阶段使用的统计量不同。 |
| 训练期行为 | 只在训练模式下启用的随机或统计更新行为。 | 解释为什么验证时要切换到评估模式。 |
| 评估模式 | 深度学习框架中的推理/验证状态,会关闭或固定某些训练期行为。 | 保证验证时只看模型表现,不引入训练随机性。 |
| 早停 | 验证集指标不再改善时提前停止训练。 | 减少继续训练导致的过拟合。 |
| 归一化 | 把输入特征调整到相近数值范围的预处理方法。 | 改善梯度稳定性和训练速度。 |
| 形状 | 张量各维度的大小,例如 batch、通道数、高度和宽度。 | 标签和模型输出形状不匹配会导致训练错误。 |
| 数值范围 | 输入、输出或梯度可能取到的大小区间。 | 范围过大容易带来数值不稳定。 |
| 数据加载流程 | 从磁盘读取、解码、打乱、组成 batch 并送入模型的过程。 | 训练慢或标签错位时需要检查。 |
| 数据管道 | 数据从存储到模型输入的整体处理链路。 | 影响训练吞吐、标签正确性和调试效率。 |
| 过拟合测试 | 让模型尝试记住很小的数据集,用来验证训练代码是否能工作。 | 快速定位 loss 不下降是否来自实现问题。 |
| NaN | Not a Number,浮点计算中的非法数值结果。 | loss 变成 NaN 通常说明训练出现数值不稳定。 |
| 梯度爆炸 | 反向传播中梯度数值变得过大,导致参数更新失控。 | 是 loss 变成 NaN 的常见原因。 |
| 梯度裁剪 | 把过大的梯度限制在指定范围或范数内。 | 用来缓解梯度爆炸。 |
| RNN | Recurrent Neural Network,循环神经网络,按序列逐步传递状态。 | 说明某些序列模型更容易出现梯度问题。 |
| GPU | 擅长并行数值计算的图形处理器。 | 深度学习训练常用硬件。 |
| 硬件利用率 | 计算设备实际忙于有效计算的比例。 | 训练慢时需要判断 GPU 是否被充分使用。 |
| 参数量 | 模型中可训练参数的总数。 | 影响模型容量、显存占用和训练速度。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)