从0到1:企业级AI项目迭代日记 Vol.27|没写出来的假设,终究会以 Bug 的形式写出来
我们的 AI,在没有任何人下达指令的情况下,自己导入了一份文件。
没有报错。没有异常日志。系统运行一切正常。
只是有一份不该出现在知识库里的文件,安安静静躺在那里。
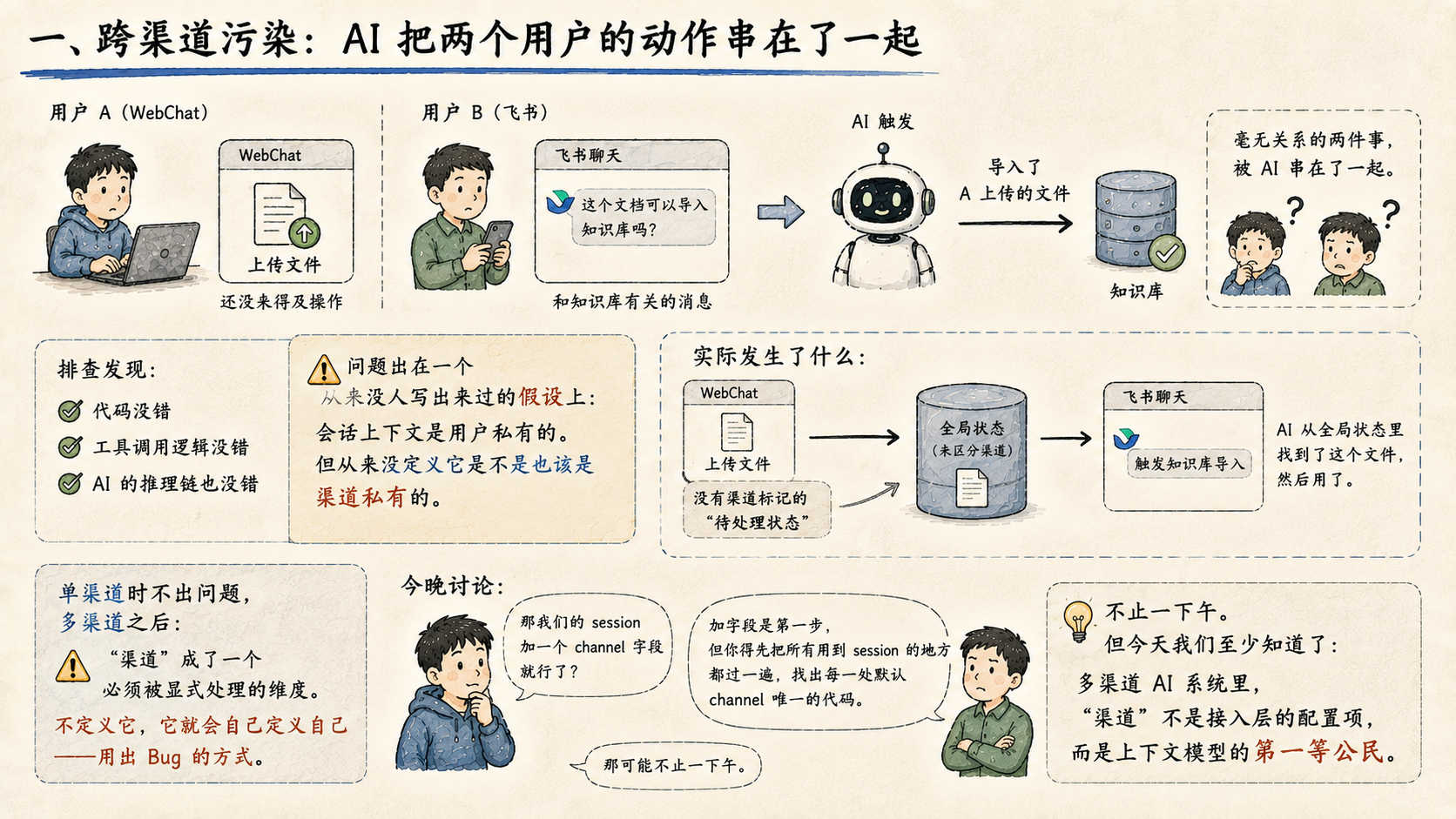
一、跨渠道污染:AI 把两个用户的动作串在了一起
某个用户在 WebChat 端上传了一份文件,还没来得及操作。另一个用户,在飞书聊天里,发了一条和知识库有关的消息。AI 触发了,把那份 WebChat 的文件导入到了知识库。
两个人,两个渠道,两件毫无关系的事,被 AI 串在了一起。
排查发现:代码没错,工具调用逻辑没错,AI 的推理链也没错。问题出在一个从来没人写出来过的假设上——我们把“会话上下文”当成了用户私有的,但从来没定义它是不是也该是渠道私有的。
WebChat 的上传动作在系统里留下了一个没有渠道标记的“待处理状态”。飞书的消息触发知识库导入时,AI 从全局状态里找到了这个文件,然后用了。
单渠道时这个问题不存在。多渠道之后,“渠道”成了一个必须被显式处理的维度。 不定义它,它就会自己定义自己——用出 Bug 的方式。
今晚和同事讨论,他说:“那我们的 session 加一个 channel 字段就行了?”我说:“加字段是第一步,但你得先把所有用到 session 的地方都过一遍,找出每一处默认 channel 唯一的代码。”他沉默了一会儿:“那可能不止一下午。”
不止一下午。但今天我们至少知道了:多渠道 AI 系统里,“渠道”不是接入层的配置项,而是上下文模型的第一等公民。
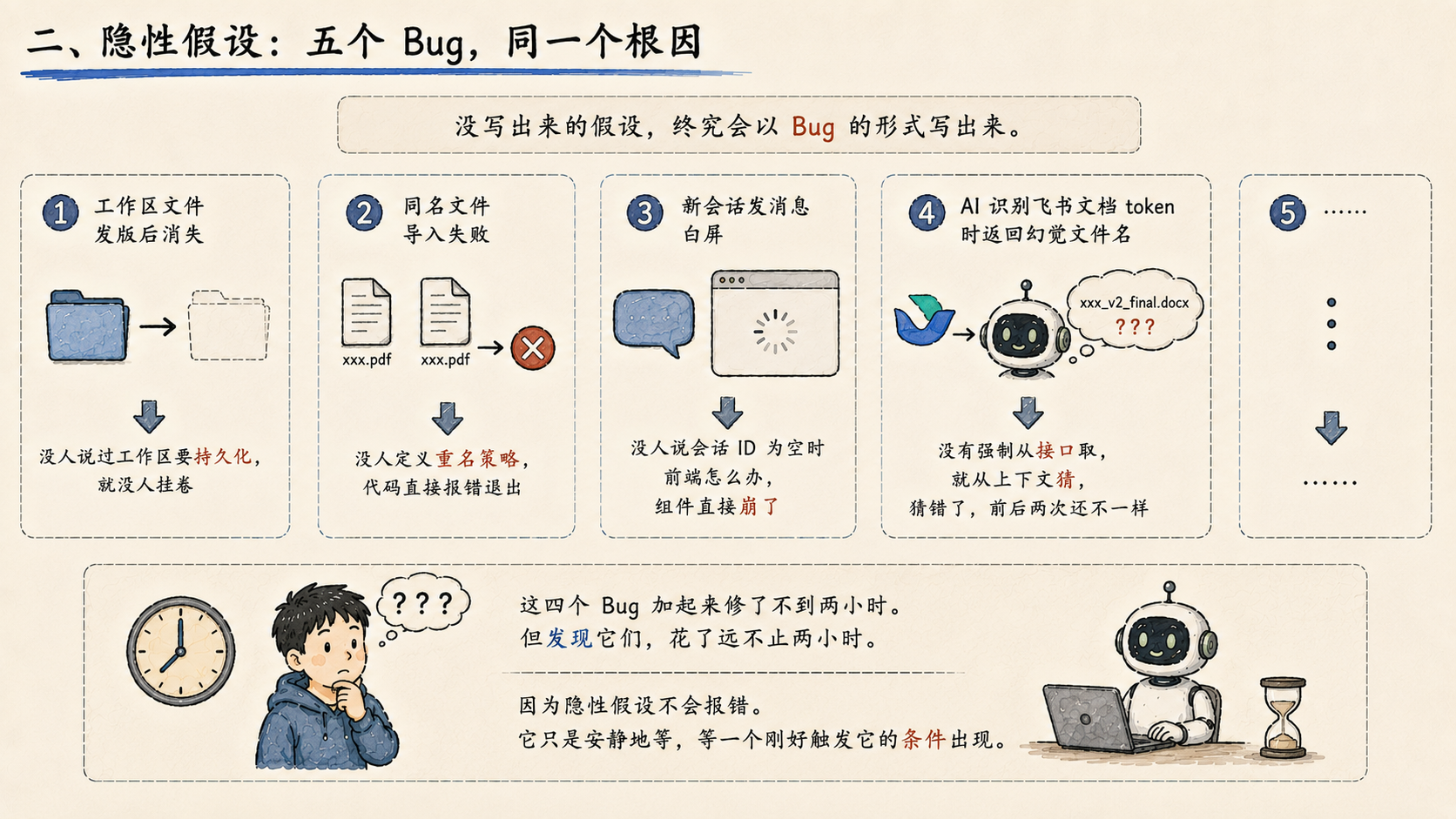
二、隐性假设:五个 Bug,同一个根因
今天另外四个 Bug,拆开来各有各的问题,合起来是同一件事:没写出来的假设,终究会以 Bug 的形式写出来。
-
工作区文件发版后消失 → 没人说过工作区要持久化,就没人挂卷
-
同名文件导入失败 → 没人定义重名策略,代码直接报错退出
-
新会话发消息白屏 → 没人说会话 ID 为空时前端怎么办,组件直接崩了
-
AI 识别飞书文档 token 时返回幻觉文件名 → 没有强制从接口取,就从上下文猜,猜错了,前后两次还不一样
这四个 Bug 加起来修了不到两小时。但发现它们,花了远不止两小时。因为隐性假设不会报错。它只是安静地等,等一个刚好触发它的条件出现。
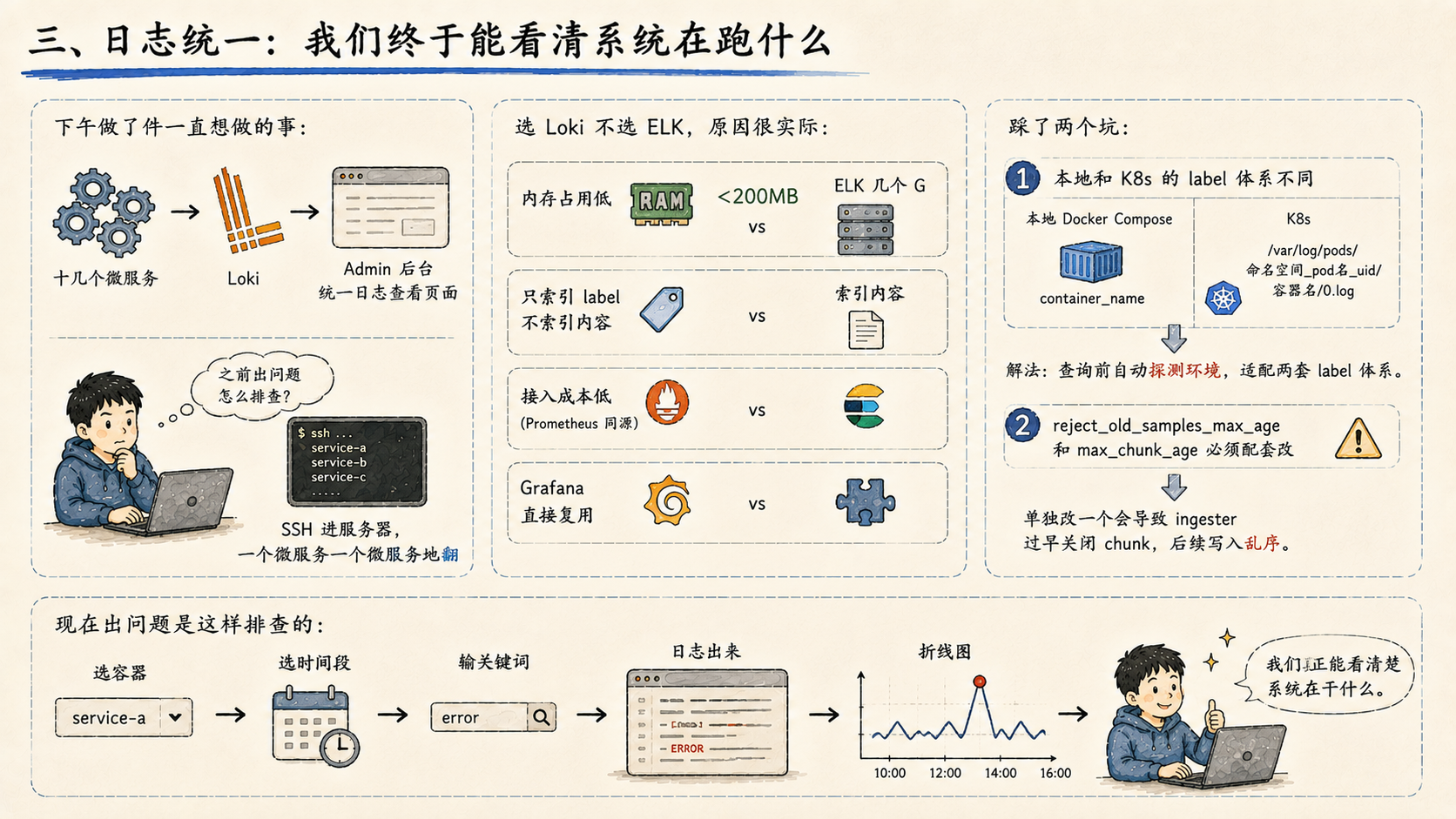
三、日志统一:我们终于能看清系统在跑什么
下午做了件一直想做的事:把十几个微服务的日志接入 Loki,在 Admin 后台做了统一的日志查看页面。
之前出问题怎么排查?SSH 进服务器,一个微服务一个微服务地翻。
选 Loki 不选 ELK,原因很实际:内存占用低(单节点 <200MB vs ELK 几个 G),只索引 label 不索引内容,接入成本低(Prometheus 同源,Grafana 直接复用)。
踩了两个坑:
-
本地和 K8s 的 label 体系不同:本地 Docker Compose 日志自动带
container_name,K8s 上只有/var/log/pods/命名空间_pod名_uid/容器名/0.log这种路径。解法:查询前自动探测环境,适配两套 label 体系。 -
reject_old_samples_max_age和max_chunk_age必须配套改:单独改一个会导致 ingester 过早关闭 chunk,后续写入乱序。
现在出问题是这样排查的:选容器,选时间段,输关键词,日志出来,折线图告诉你哪个时间点出现了异常抖动。我们真正能看清楚系统在干什么。
这,是第二十七天。
《从0到1:企业级AI项目迭代日记》记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)