open_prj25_MIPI与图像显示
MIPI摄像头及HDMI显示
概述
a)MIPI全称Mobile Industry Processor Interface即移动产业处理接口,最初由Intel、Motorola,Nokia,NXP,Samsung,ST和TI共同提出,后来随着ARM,Apple,Lattice,ADI,TOSHIBA,Cadence,Dell,Google,Hisilicon等大厂的加入,MIPI协议逐渐被行业认可和接受,并广泛的应用于嵌入式图像设备中,如手机、VR、电视等。
b)MIPI并不是一个单一的接口或协议,而是包含了一套协议或标准,如摄像头接口CSI、显示接口DSI、射频接口DigRF、麦克风/喇叭接口SLIMbus等。使用最多的是多媒体方向也就是常见的音视频接口,在多媒体方向的MIPI协议大致可以分为三层,分别是应用层、协议层和物理层。如下图所示:
c)整个MIPI的通信过程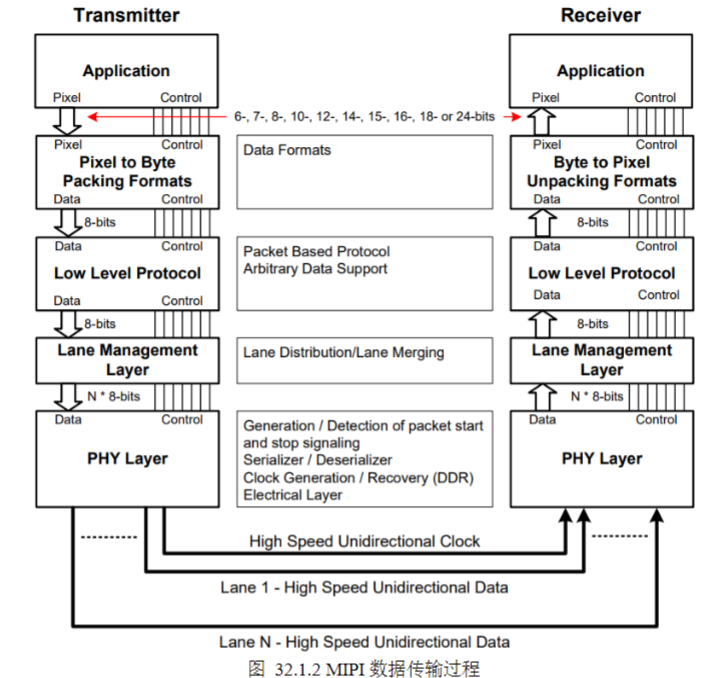
1)Pixel/BytePacking/Unpacking Layer:像素字节打包拆包层,这一层对于发送端来说是将应用层发送进来的像素数据打包成字节的形式发送给下一层;对于接收端来说是将下一层的字节数据解包成像素数据发送给应用层。
2)Low Level Protocol:低级协议层,对于发送端来说是根据数据类型,为每个为新生成的数据加上包头包尾,形成符合协议要求的数据流;对于接收端来说是将数据流的包头包尾拆掉,取出有效数据。
3)Lane Management:通道管理层,对于发送端来说是将生成的数据流按照一定次序和要求,合理分配到每个通道上;对于接收端来说是将各个通道上的数据汇总到一起,形成数据流。
d)本节实验使用的CSI协议层是CSI2,除了CSI2之外还有CSI3,这二者的主要区别是对应的PHY层不一样,CSI2对应的是D-PHY,而CSI3对应的是M-PHY。(对于MIPI感兴趣的同学,可以翻看我之前的博客。关于MIPI的基础知识,会在那些博客上更新。)
OV5645摄像头简介
a)OV5645彩色图像传感器是一款低电压、高性能、1/4英寸、500万像素的CMOS图像传感器,它采用OmniBSl(背面照度)技术,在更小封装的情况下提供单芯片500万像素(2592x1944)相机的全部功能。
b)OV5645内部集成了丰富的图像处理功能,如曝光控制、伽马、白平衡、色彩饱和度、色调控制、缺陷像素消除、噪声消除等。此外,OmniVision图像传感器采用专有的传感器技术,通过减少或消除常见的照明/电源对图像的污染(如固定图案噪声和涂抹)来提高图像质量,从而产生干净、稳定的彩色图像。OV5645还具有嵌入式微控制器,可与内部自动对焦引擎和可编程通用I/O模块(GPIO)相结合,用于外部自动对焦控制。它还提供了一个内置防抖引擎的防抖功能。为了识别和存储的目的,OV5645还包括一个一次性可编程(OTP)存储器。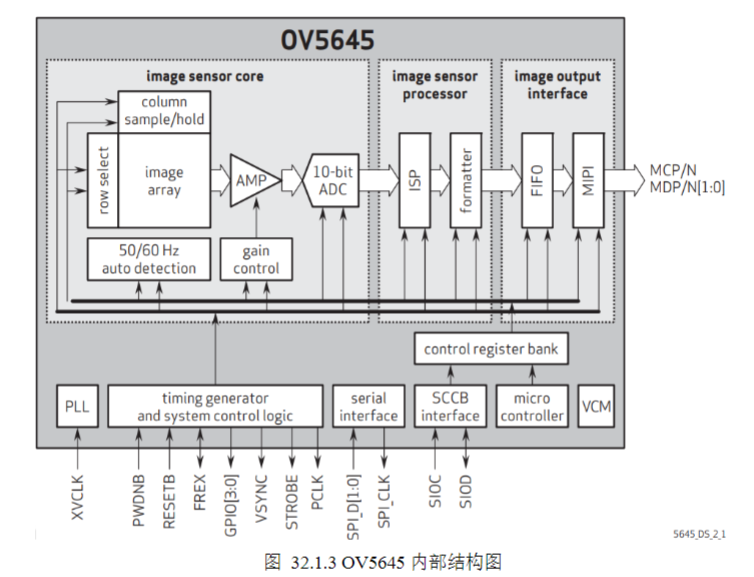
//----------
☆提问☆
问题:OV5645内部结构图解释
解答:
①时序发生器(timing generator)控制着感光阵列(image array)、放大器(AMP)、AD转换以及输出外部时序信号(VSYNC、HREF、PCLK),外部时钟XVCLK经过PLL锁相环后输出的时钟作为系统的控制时钟。感光阵列将光信号转化成模拟信号,经过增益放大器之后进入10位AD转换器;AD转换器将模拟信号转化成数字信号,并且经过ISP进行相关图像处理,最终输出所配置格式视频数据流。增益放大器控制以及ISP等都可以通过寄存器(registers)来配置,配置寄存器的接口就是SCCB接口,该接口协议兼容IIC协议。
②row select/column sample/hold由时序发生器控制,逐行选中像素阵列中的行,同时采样选中行的所有列像素的电荷信号,实现逐行扫描读取。这是CMOS传感器比CCD传感器速度更快的关键:CCD是串行读取,CMOS是并行列读取。
③AMP(可编程增益放大器)对模拟电荷信号进行放大,增益由gain control模块控制,分为模拟增益和数字增益两部分,模拟增益在ADC之前,数字增益在ADC之后。gain control(增益控制)接收ISP的自动曝光(AE)算法输出,动态调整放大器的增益,低光环境下提高增益,强光环境下降低增益。
④每个像素输出10位的原始拜耳数据(Raw Data)。
⑤50/60Hz auto detection(工频自动检测)自动检测环境光的工频频率(50Hz或60Hz),用于消除日光灯等工频光源导致的图像闪烁问题,通过调整曝光时间为工频周期的整数倍实现。
⑥ISP无需外部处理器参与,实时处理10位原始拜耳数据。核心功能包括:白平衡AWB校正不同光源下的颜色偏色;自动曝光AE自动调整增益和曝光时间,获得合适的亮度;自动对焦AF驱动VCM马达,实现自动对焦;去马赛克Demosaic将拜耳原始数据转换为RGB彩色图像;去噪Denoising去除图像中的噪声,提高画质;伽马校正Gamma Correction校正人眼的非线性视觉特性;颜色校正Color Correction调整颜色饱和度和色调;锐化Sharpening提高图像的清晰度。
⑦formatter(格式化器)将ISP处理后的RGB图像转换为指定的输出格式,支持的输出格式包括YUV422、RGB565、RGB888、原始拜耳数据等,可以设置输出图像的分辨率和帧率,比如2592×1944@15fps、1280×720@30fps。
⑧SCCB interface(串行相机控制总线)是OmniVision自定义的串行控制接口,与I2C接口完全兼容,只是协议略有不同,包含时钟线SIOC和数据线SIOD,用于后端处理器读写控制寄存器。SPI interface(串行外设接口)可选的控制接口,速度比SCCB更快,用于批量下载固件或配置参数。
//----------
c)SCCB(Serial Camera Control Bus,串行摄像头控制总线)是由OV(OmniVision的简称)公司定义和发展的三线式串行总线,该总线控制着摄像头大部分的功能,包括图像数据格式、分辨率、图像处理参数等。OV公司为了减少传感器引脚的封装,现在SCCB总线大多采用两线式接口总线。OV5645使用的是两线式SCCB接口总线,该接口总线包括SIO_C串行时钟输入线和SIO_D串行双向数据线,分别相当于IIC协议的SCL信号线和SDA信号线。我们在前面提到过SCCB协议兼容IIC协议,是因为SCCB协议和IIC协议非常相似。
1)OV5645是用16位(两个字节)表示寄存器地址。OV5645SCCB的读写传输协议如下图所示: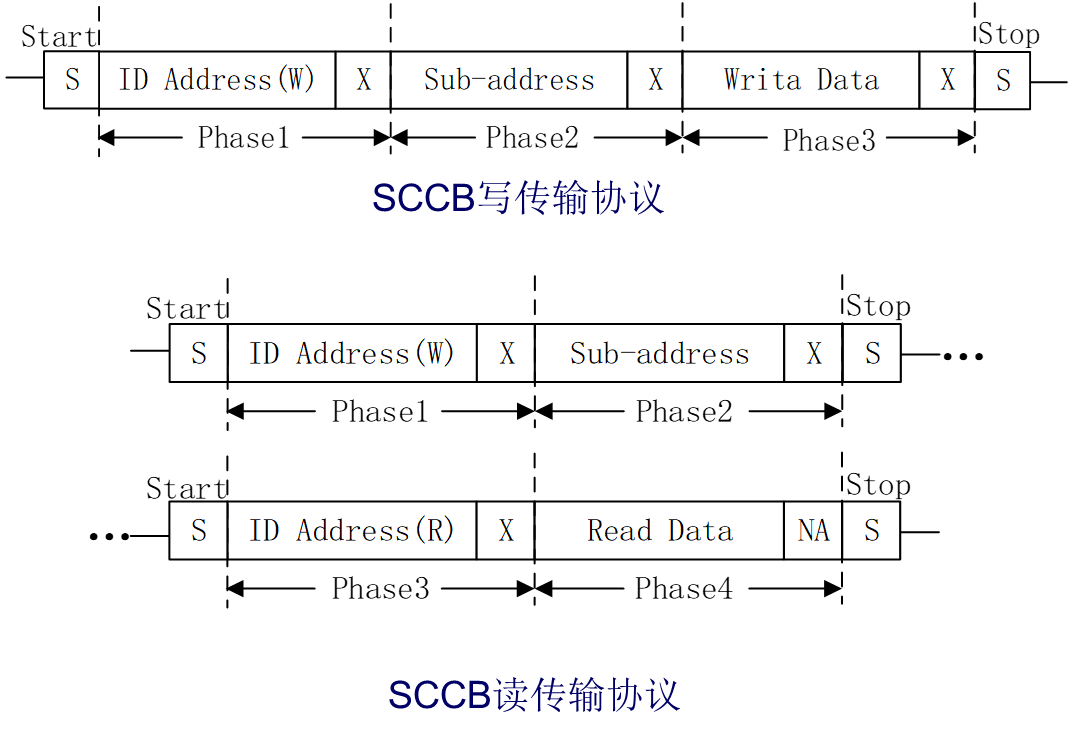
2)上图中的ID ADDRESS是由7位器件地址和1位读写控制位构成(0:写1:读),OV5645的器件地址为7’h3c,所以在写传输协议中,IDAddress(W)= 8’h78(器件地址左移1位,低位补0);Sub-address(H)为高8位寄存器地址,Sub-address(L)为低8位寄存器地址,在OV5645众多寄存器中,有些寄存器是可改写的,有些是只读的,只有可改写的寄存器才能正确写入;Write Data为8位写数据,每一个寄存器地址对应8位的配置数据。上图中的第9位X表示Don’tCare(不必关心位),该位是由从机(此处指OV5645)发出应答信号来响应主机表示当前ID Address、Sub-address和Write Data是否传输完成,但是从机有可能不发出应答信号,因此主机(此处指FPGA)可不用判断此处是否有应答,直接默认当前传输完成即可。
3)SCCB和IIC写传输协议是极为相似的,只是在SCCB写传输协议中,第9位为不必关心位,而IIC写传输协议为应答位。SCCB的读传输协议和IIC有些差异,在IIC读传输协议中,写完寄存器地址后会有restart即重复开始的操作;而SCCB读传输协议中没有重复开始的概念,在写完寄存器地址后,发起总线停止信号。
4)SCCB读传输协议分为两个部分。第一部分是写器件地址和寄存器地址,即先进行一次虚写操作,通过这种虚写操作使地址指针指向虚写操作中寄存器地址的位置,当然虚写操作也可以通过前面介绍的写传输协议来完成。第二部分是读器件地址和读数据,此时读取到的数据才是寄存器地址对应的数据,注意ID Address(R)= 8’h43(器件地址左移1位,低位补1)。上图中的NA位由主机(这里指FPGA)产生,由于SCCB总线不支持连续读写,因此NA位必须为高电平。
d)在OV5645正常工作之前,必须先对传感器进行初始化,即通过配置寄存器使其工作在预期的工作模式,以及得到较好画质的图像。因为SCCB的写传输协议和IIC几乎相同,因此我们可以直接使用IIC的驱动程序来配置摄像头。当然这么多寄存器也并非都需要配置,很多寄存器可以采用默认的值。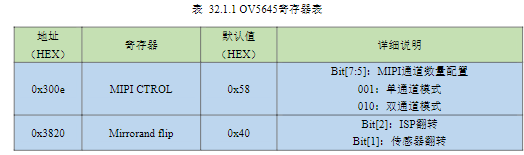
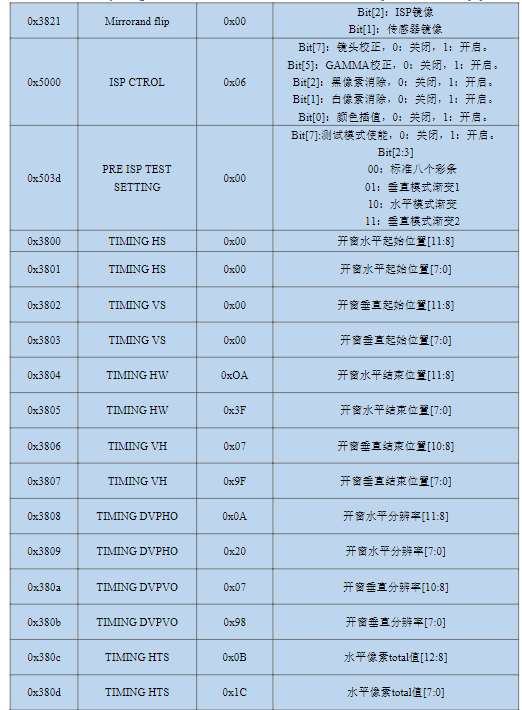
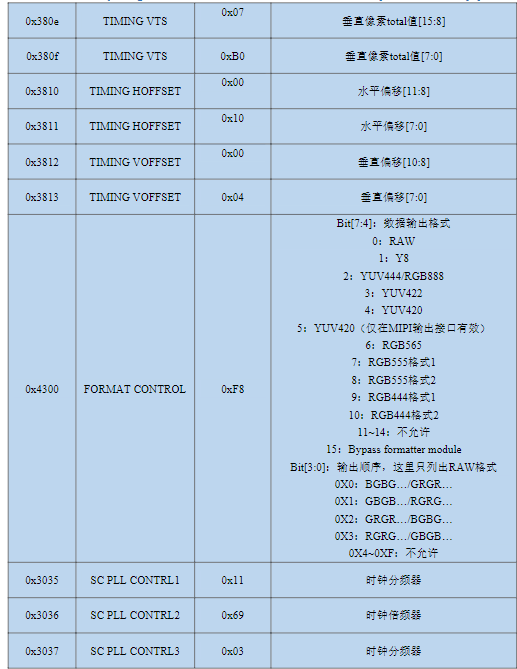
→关键寄存器解析
1)时钟配置:在上表中列出了0x3035、0x3036、0x3037三个时钟配置寄存器,这三个寄存器在整个时钟链路当中的作用如下图所示: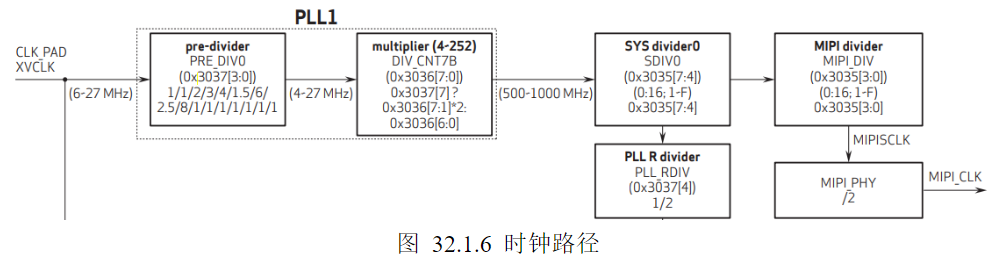
OV5645外部输入时钟范围是6-27Mhz(板载24Mhz),外部输入时钟进入摄像头内部PLL,先经过pre-divider,根据0x3037寄存器bit0-bit3的值将时钟降为4-27Mhz(本节实验降低到8Mhz);之后再经过multiplier,判断寄存器0x3036的bit7位是否为1,如果是1则将时钟倍频到0x3036[7:1]2倍的值,如果不为1则倍频到0x3036[6:0]倍的值(本节实验倍频到0x3036[6:0]倍的值,即105倍,最终输出值为840Mhz),最终输出时钟范围是500-1000Mhz;再之后时钟会经过SYS divider0和MIPI divider,前者是判断0x3035寄存器bit4-bit7的值是否为0,如果为0则时钟分频16倍,否则分频0x3035[7:4]倍,后者是判断0x3035寄存器bit0-bit3的值是否为0,如果为0则时钟分频16倍,否则分频0x3035[3:0]倍(本
节实验先分频1倍,再分频2倍,最终输出420Mhz);最后时钟到达MIPI PHY,在这个模块之中直接对时钟进行2分频,最终输出MIPI CLK(本节实验最终的MIPI CLK为210Mhz)。
预分频器 (pre-divider, PRE_DIV0)是整个时钟树最精妙的设计之一。PLL的VCO有一个固定的最佳工作范围,输入频率必须在这个范围内才能获得最优的相位噪声和锁定时间。预分频器的作用就是将任意6-27MHz的外部输入时钟,统一转换为4-27MHz的PLL输入时钟,保证PLL始终工作在最佳状态。
系统分频器0 (SYS divider0, SDIV0)的输入是PLL输出的500-1000MHz VCO时钟,输出是系统主时钟,供给ISP、像素阵列、时序发生器、ADC等核心模块。芯片上电时,所有寄存器的默认值都是0。如果0对应1分频,那么上电时系统时钟会直接是1000MHz,远远超过内部逻辑的最大工作频率,导致芯片无法启动甚至损坏。而0对应16分频,上电时系统时钟最高只有1000/16=62.5MHz,保证芯片能够安全启动,然后软件再逐步提高频率。
PLL R分频器 (PLL R divider)的输入是SYS divider0的输出,输出是低速外设时钟,供给SCCB/I2C、SPI、GPIO、微控制器等低速模块。低速外设的工作频率通常是系统时钟的一半,这些模块对时钟频率的要求不高,不需要灵活可调,固定分频器的面积和功耗远小于可编程分频器。
2)图像开窗位置:OV5645的开窗大小是用(“开窗水平结束位置”减去“开窗水平起始位置”)(“开窗垂直结束位置”减去“开窗垂直起始位置”),通过寄存器0x3800-0x3807来控制。开完窗后还可以通过水平方向和垂直方向的偏移寄存器(0x3810-0x3813)来进一步调整大小,最终输出的图像就上图中白色区域部分。这里大家需要注意一下,在整体图像分辨率水平:垂直=4:3的情况下按上图去配置是可以的,如果是其他尺寸比例那么按上图配置不一定能成功,具体的配置需要原厂协助。当寄存器0x5001的bit5压缩使能打开(0关闭,1开启),就可以在开窗的基础上输出压缩后的图像,压缩图像等于开窗图像减去2倍水平垂直偏移量。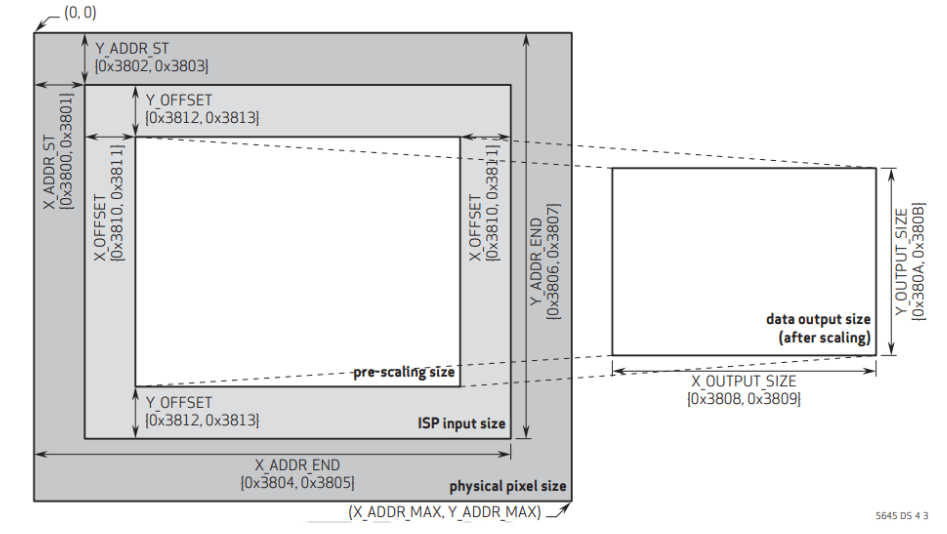
//----------
☆提问☆
问题:为什么要画两个窗?这两个窗有什么区别?
解答:现代CMOS传感器通用的三级窗口分层架构,即物理像素阵列→ISP输入窗→数据输出窗。物理像素阵列从左上角(0,0)到右下角(X_ADDR_MAX, Y_ADDR_MAX),所有像素都在持续曝光和读出,但只有被后续窗口选中的像素才会被处理和输出。ISP输入窗左上角X_ADDR_ST(0x3800/0x3801)+Y_ADDR_ST(0x3802/0x3803),右下角X_ADDR_END(0x3804/0x3805)+Y_ADDR_END(0x3806/0x3807),定义ISP算法处理的统计区域和像素读出区域,只有这个窗口内的像素会被送入ADC进行模数转换/自动曝光AE/自动白平衡AWB/自动对焦AF的统计计算,经过去噪、去马赛克、伽马校正等ISP处理。数据输出窗左上角偏移X_OFFSET(0x3810/0x3811)+Y_OFFSET(0x3812/0x3813),
输出大小X_OUTPUT_SIZE(0x3808/0x3809)+Y_OUTPUT_SIZE(0x380A/0x380B),定义最终输出到MIPI接口的图像区域。
//----------
3)输出像素格式:从寄存器的配置表中就可以看到OV5645摄像头支持的像素格式非常多,可以通过配置寄存器0x4300,让摄像头输出不同格式的像素数据。本节实验使用的是RAW格式数据,所以接下来只介绍RAW格式的像素数据输出,如下图所示: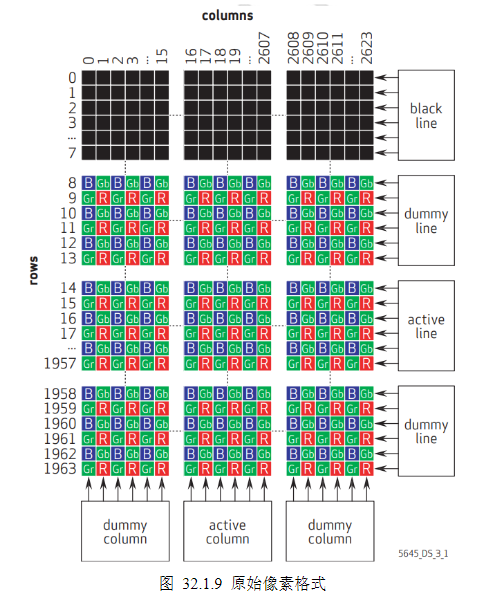

上图中红色方框框出来的就是一个2*2的Byer阵列,可以看到它的组合方式是BGGR,这是摄像头的原始配置,当寄存器0x4300配置为0x00时输出的就是这种组合,第一行数据全部是BGBG,第二行数据全部是GRGR,组成Byer阵列就是BGGR。当然也可以通过改变寄存器0x4300的配置值来改变输出的像素格式,具体的格式配置在前面已经列出。这种Byer阵列数据可以通过插值法来进一步转换成RGB数据,最终在显示屏幕上显示出来。
4)彩条测试模式:图像传感器配置成彩条测试模式后,会输出彩色的条纹,方便测试图像传感器是否正常工作,通过配置寄存器0x503d的Bit[7]位打开和关闭彩条模式。当需要打开彩条模式时,寄存器0x503d配置成0x80,关闭时配置成0x00,下图为打开彩条模式后图像输出的条纹(8个颜色条)。
AXI协议简介
a)AXI协议是一种高性能、高带宽、低延迟的片内总线,具有如下特点:总线的地址/控制/数据通道是分离的、支持不对齐的数据传输、支持突发传输,突发传输过程中只需要首地址、具有分离的读/写数据通道、支持随机地址访问、更加容易进行时序收敛。
//----------
☆提问☆
问题:站在芯片架构工程师角度,分析上述特点?
解答:
①地址/控制/数据通道分离是从传输级到事务级的革命,这是AXI与AHB/APB最本质的区别,也是所有其他特点的基础。传统AHB总线是单共享通道架构,地址/控制/数据必须串行传输,一个完整的读操作必须是发地址→等从设备响应→传数据→下一个地址,总线在等从设备响应的时间里完全空闲,利用率最高只能到50%,所有事务必须严格按顺序执行,无法隐藏不同从设备的延迟差异。而AXI通道分离设计的本质是将总线分为五个完全独立互不依赖的通道,将地址控制流和数据流完全解耦,允许它们并行传输,主机可以连续发送100个读地址而不需要等待任何一个数据返回,从设备可以在准备好数据时通过数据通道返回而不需要按地址顺序,写操作时主机可以先发写数据再发地址或者相反。这可以提高总线利用率,隐藏从设备的访问延迟,且支持事务级的乱序执行和完成,但代价是逻辑复杂度提升,且每个通道都需要独立的FIFO缓存。其本质是面积换带宽。
②软件世界的内存访问天然是不对齐的,例如视频和图像数据的行宽通常不是总线宽度的整数倍、网络数据包的载荷永远从任意地址开始。如果总线不支持不对齐传输,软件就必须将一个不对齐的访问拆分为多个对齐的访问,然后手动拼接数据,这会导致指令数、总线事务数上升。AXI的不对齐传输完全由硬件自动完成,对软件透明。主机发送首地址和突发长度,总线接口自动计算首地址的偏移量,第一个传输周期只传输首地址到下一个对齐地址之间的字节,后续传输周期按对齐地址传输完整的总线宽度数据,最后一个传输周期只传输剩余的字节。这完全消除了软件的对齐负担,大幅提高了系统的整体性能,但数据通路必须增加一个字节对齐和拼接单元,增加了约1ns的延迟。在高性能DMA设计中,软件应尽量使用对齐传输,以获得最低的延迟和最高的带宽,只有在无法避免的情况下才使用不对齐传输。
③AXI定义了三种突发类型,分别对应不同的应用场景:INCR 增量突发用于普通内存访问,这是最常用的突发类型,占所有总线事务的90%以上;FIXED固定突发用于FIFO和寄存器访问,每次传输都读写同一个地址,适合流数据处理;WRAP 回绕突发专门用于CPU缓存行填充,当地址到达缓存行末尾时,自动回绕到开头,正好匹配缓存的工作方式。突发传输要求从设备必须具备地址生成能力,从设备可以提前预取数据,隐藏内部的访问延迟。
④支持随机地址访问和乱序传输是AXI最强大也是最复杂的特点,是它能支持多核处理器的关键。AXI的每个事务都是完全独立的,每个事务都有自己的ID、地址、控制信息。主机可以按照任意顺序发送事务,从设备也可以按照任意顺序返回数据,只要相同ID的事务顺序完成即可。例如主机发送ID0的读地址A,然后发送ID1的读地址B,从设备B的访问延迟比A小,可以先返回ID1的数据。乱序传输可以隐藏不同从设备的延迟差异,大幅提高总线的利用率。多核处理器的多个核心可以同时访问总线,不会相互拥塞。乱序传输是AXI最复杂的部分,需要基于ID的仲裁逻辑、基于ID的排序逻辑、每个ID都需要独立的缓存空间。这也是为什么很多外设只支持AXI-Lite接口,而不支持完整的AXI接口。AXI-Lite去掉了乱序传输和突发传输的功能,复杂度降低了一个数量级,适合低速外设。
⑤AXI的握手协议是完全流水线友好的。你可以在任何两个模块之间插入任意数量的流水线寄存器,而不会改变协议的语义。这使得 AXI 可以很容易地在长距离传输中插入寄存器,解决时序收敛问题。在7nm工艺下,片内互连线的延迟已经超过了门延迟。总线的时序收敛已经成为了芯片设计中最大的挑战之一。AXI 的点对点握手设计,使得它可以很容易地适应先进工艺的要求,这是它能长期存在的最重要的原因。
//----------
b)AXI4协议支持突发传输,主要用于处理器访问存储器等需要指定地址的高速数据传输场景。AXI-Lite为外设提供单个数据传输,主要用于访问一些低速外设中的寄存器。而AXI-Stream接口则像FIFO一样,数据传输时不需要地址,在主从设备之间直接连续读写数据,主要用于如视频、高速AD、PCIe、DMA接口等需要高速数据传输的场合。
c)AXI-Lite
1)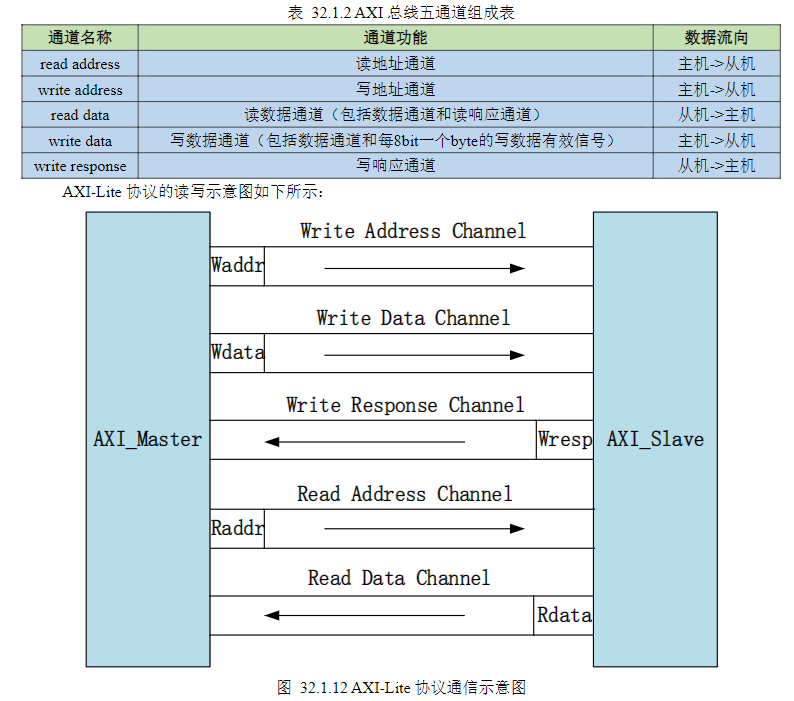
2)AXI-Lite协议通信中读写都是由主机发起,在写操作中主机发起写地址操作,然后给出写数据,成功写入后从机给出写应答;而在读操作中主机只需要给出读地址即可,从机会根据读地址给出相应的读数据。
3)信号列表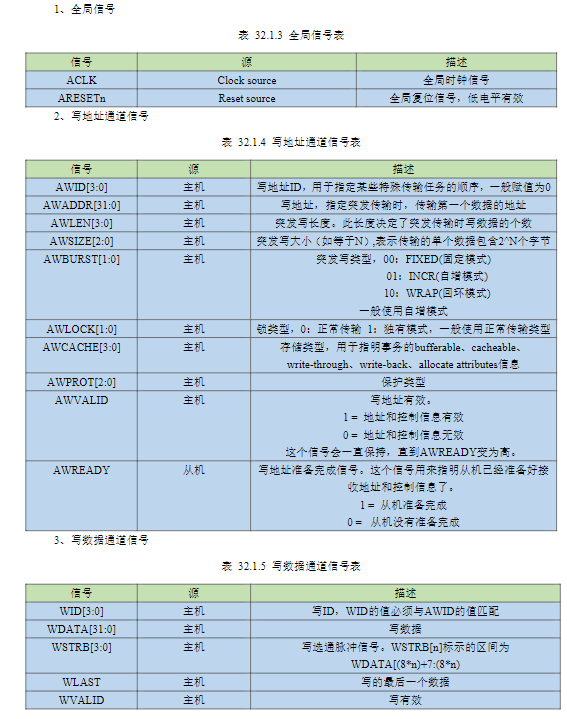
AWID[3:0]:写地址ID。用于指定特殊传输任务的顺序,一般赋值为0。乱序传输的唯一标识,是AXI协议最核心的创新之一。不同ID的事务可以完全乱序执行和完成,相同ID的事务必须严格按顺序执行和完成,从设备可以同时处理多个不同ID的事务,不需要等待前一个事务完成。在多核 SoC中,每个CPU核心分配一个唯一的AWID,这样多个核心的写事务可以并行执行,不会相互阻塞。
AWLOCK[1:0]:锁类型。0为正常传输,1为独有模式。原子操作的原始实现。这是AXI3遗留下来的信号,用于实现总线级的原子锁操作。锁传输会阻塞整个总线,直到锁释放,严重影响系统性能。在AXI4中已经被废弃,取而代之的是AXI5的原子事务(Atomic Transactions)。所有新设计都应该将AWLOCK设为0,不要使用锁传输。
AWCACHE[3:0]:存储类型。指明事务的bufferable、cacheable、write-through、write-back、allocate属性。系统级缓存一致性的控制开关,是 AXI协议中最复杂也最容易出错的信号。Bufferable事务可以被总线桥缓冲,不需要等待从设备响应;Cacheable事务可以被缓存;Read Allocate读事务时分配缓存行;Write Allocate写事务时分配缓存行。0000(Non-bufferable, Non-cacheable)保证读写操作立即生效;1111(Write-back, Read and Write Allocate)获得最高的缓存性能;0011(Bufferable, Cacheable, No Allocate)避免缓存一致性问题。
AWPROT[2:0]:保护类型。事务的权限和安全属性。在有TrustZone的系统中,用于隔离安全世界和普通世界的内存空间。在有内存管理单元 (MMU) 的系统中,用于实现用户态和内核态的权限隔离。防止非法访问敏感的外设和内存区域。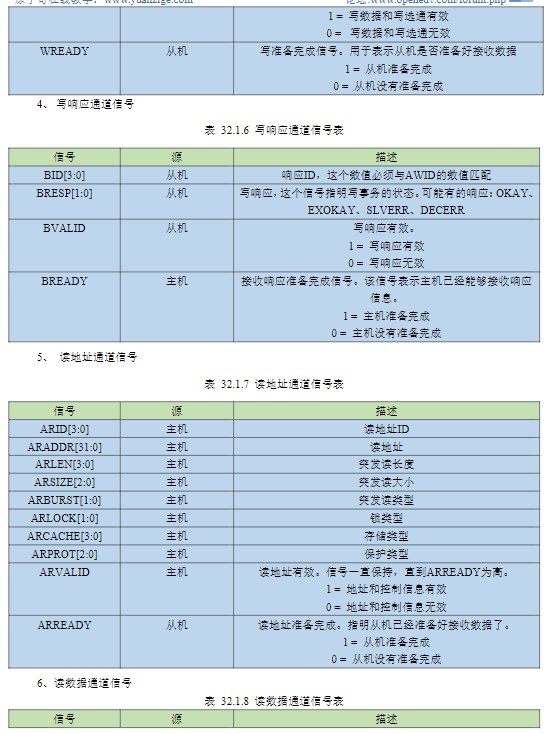
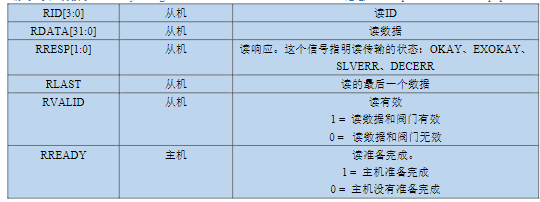
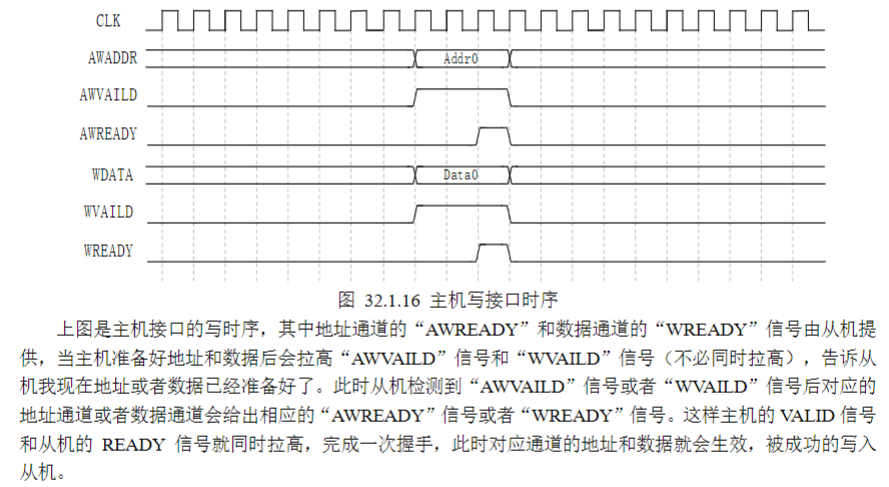
4)
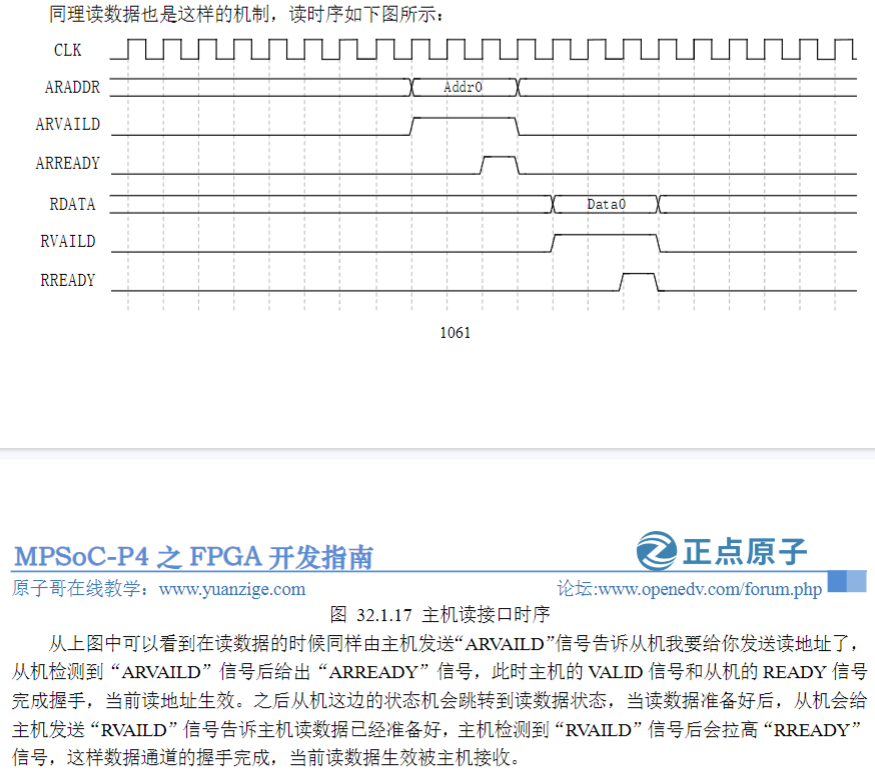
5)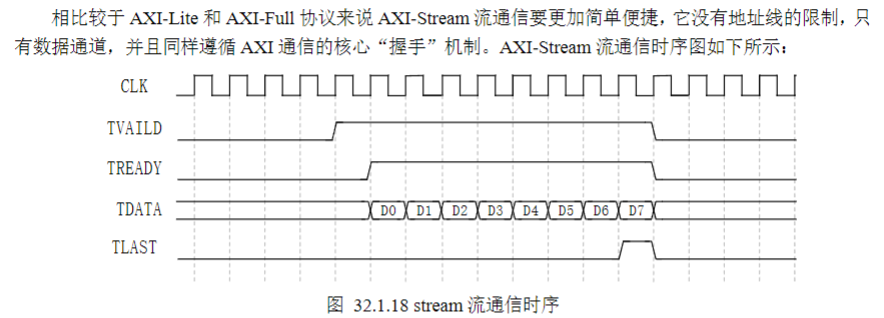
stream流通信除了上述的数据通道信号外,在一些视频流传输过程中还会用到TUSER(支持自定义位宽,最大128位)信号。当视频流每传输完一帧图像后TUSER信号会拉高(当作场结束标志信号使用,位宽定义为1位),当下一帧开始传输的时候TUSER信号重新拉低,所以在视频流当中TUSER信号又被当作场同步信号使用。
硬件设计
程序设计
a)总体模块设计
通过试验任务可知本节实验需要将OV5645摄像头采集到的数据显示在HDMI屏幕上,但是OV5645是MIPI接口的摄像头,在配置的时候我们使用的是RAW10的原始数据格式。原始数据格式是没办法直接显示在HDMI显示屏幕上的,我们需要将原始数据转换成RGB数据才可以显示在HDMI显示屏上。因此第一步需要配置OV5645摄像头,让它正常工作;第二步使用Xilinx自带的csi2_rx_subsystem IP核完成MIPI接口的数据接收;第三步使用Xilinx自带的demosaic IP核对原始数据进行解码,得到RGB数据;第四步使用Xilinx自带的gamma_lut IP核对解码后的RGB数据进行GAMMA校准;第五步使用Xilinx自带的subset_converter IP核对RGB数据做一下调整;第六步对调整后的数据进行接口转换,因为前面的IP核全是Stream流接口,这里我们通过自定义一个IP核将Stream流数据转成普通接口数据。第七步将转换后的数据缓存进DDR4进行调度;第八步将DDR4中的数据读取出来通过HDMI驱动模块显示到屏幕上。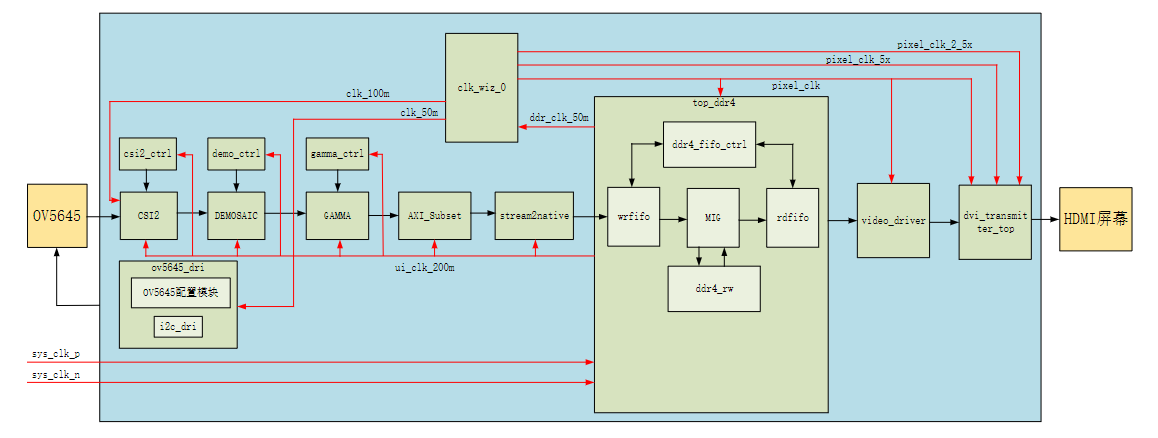
整体的时钟结构是板载晶振提供100Mhz的差分系统时钟,系统时钟sys_clk_p进入DDR4的MIG IP核。MIG会产生两路时钟,一路ui_clk(ui_clk的频率为DDR4颗粒工作时钟的四分之一,在2EG或者3EG中是300Mhz,在4EV中是266Mhz),本例程中,三种型号的开发板的工作时钟都是配置的800Mhz(DDR IP中配置如下图所示),所以用户时钟都是ui_clk_200m(200Mhz=800Mhz/4),该时钟给DDR4读写控制器使用,同时本例程中该时钟还给“csi2_rx_subsystem”、“demosaic”、“gamma_lut”以及他们对应的配置IP使用。另一路50Mhz的ddr_clk_50m时钟会接入锁相环clk_wiz_0产生如上图所示的clk_100m、clk_50m、pixel_clk(150Mhz)、pixel_clk_5x(750Mhz)、pixel_clk_2_5x(375Mhz)共五路时钟,其中clk_100m、clk_50m两路时钟接到其对应的模块中去使用。其它三路时钟pixel_clk(150Mhz)、pixel_clk_5x(750Mhz)与pixel_clk_2_5x(375Mhz)去给HDMI显示模块使用。
//----------
☆提问☆
问题:通过这个工程的时钟网络,可以看出时钟网络设计的哪些基本思路?
解答:
1.这是一个以内存控制器为中心的时钟架构,颠覆了传统的以MMCM为中心的设计思想,其核心目的是最大化DDR4内存系统的稳定性,同时将系统的跨时钟域数量降到了理论最低值。
2.为什么100MHz晶振直接输入MIG核,而不先经过MMCM?MIG核对时钟抖动的敏感度是整个系统最高的,DDR4的时序裕量只有几十皮秒,输入参考时钟的抖动每增加1ps,DDR4的误码率就会呈指数级上升。MMCM会引入额外的抖动,即使是最好的MMCM,也会引入约5-10ps的附加抖动,对于DDR4-800来说,这已经吃掉了10%以上的时序裕量。晶振的抖动是最小的,工业级100MHz差分晶振的典型抖动只有1-2ps,远小于MMCM输出的抖动。Xilinx MIG核内部有一个专门为DDR4优化的低抖动PLL,它的相位噪声性能比通用MMCM好30%以上。这个设计的本质是把最宝贵的、抖动最小的时钟资源,分配给对抖动最敏感的模块。DDR4是整个系统的瓶颈,只要DDR4稳定,整个系统就稳定;如果DDR4不稳定,其他模块做得再好也没用。
3)为什么前端处理、AXI总线、DDR4全部工作在同一个200MHz时钟域?消除了视频流水线和内存系统之间的跨时钟域。如果前端工作在 100MHz,总线工作在200MHz,就必须在中间插入一个异步FIFO。这个FIFO会引入至少10个时钟周期的延迟,同时会损失10-20%的带宽。CSI2接口接收的数据,经过去马赛克和伽马校正后,可以直接写入AXI总线,不需要任何同步逻辑。
3)为什么MMCM的输入是50MHz,而不是200MHz或100MHz?MMCM的最佳输入频率范围是50-100MHz,在这个范围内,MMCM的VCO可以工作在最佳的频率区间,相位噪声最低,锁定时间最短。此外,整数和半整数倍频的相位噪声远好于分数倍频,如果用200MHz输入产生 150MHz,需要0.75倍的分数分频,相位噪声会增加10dB以上。这个设计把MMCM当成了一个专用的HDMI时钟发生器,而不是系统主时钟发生器。它只负责产生HDMI需要的三个特殊频率的时钟,其他所有时钟都直接使用MIG核输出的干净时钟。
4)永远把最宝贵的资源分配给系统中最关键的瓶颈模块。在视频处理系统中,这个瓶颈永远是DDR4内存控制器。
//----------
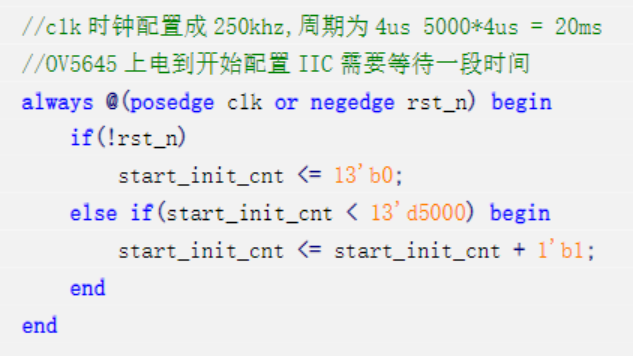
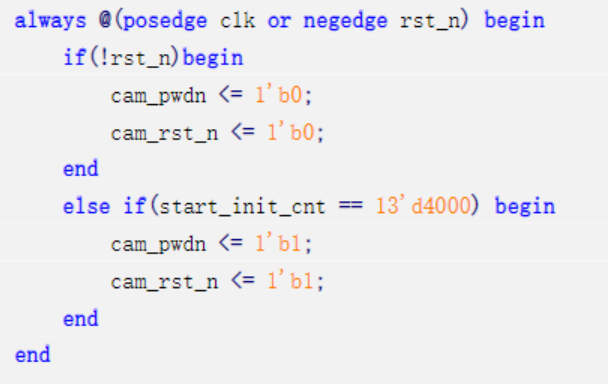
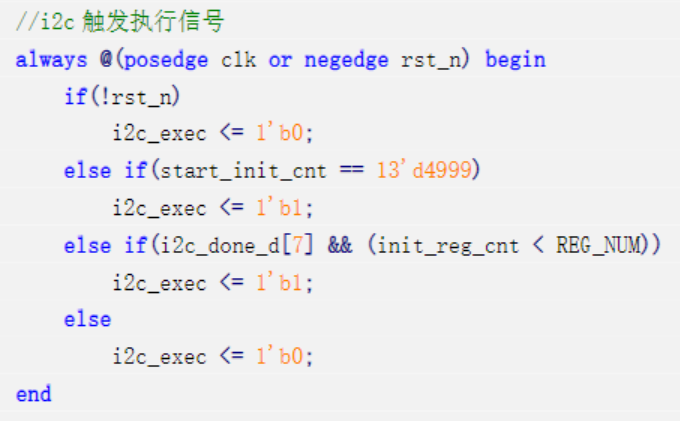
b)OV5645摄像头配置模块
1)

c)csi2_rx_subsystemIP配置
1)
//----------
☆提问☆
问题:video_clk的频率选择原理和思路?
解答:
①ideo_aclk1 (MHz) = Line Rate (Mb/s) × Data Lanes / (8 × 4)描述的是MIPI IP核内部32位并行FIFO的最小读出带宽要求。Xilinx的MIPI CSI-2 RX IP核内部有一个深度为1024的字节FIFO,用于缓存从D-PHY接收到的串行数据。这个FIFO的读出端口固定为32位宽,因此它的最大读出带宽是video_aclk × 4字节。为了保证FIFO不会溢出,读出带宽必须大于等于写入带宽。
②video_aclk2 (MHz) = (Line Rate (Mb/s) × Data Lanes) / (Pixels per Clock × Bits per Pixel)描述的是IP 核像素级输出的最小带宽要求。
③当Line Rate>1500Mb/s时,video_aclk=video_aclk2。当单lane速率超过1500Mb/s时,字节FIFO的带宽不再是瓶颈,只需要满足像素输出的要求即可。
//----------
2)
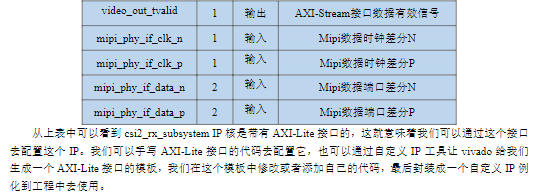
d)自定义AXI接口IP
1)我们在日常开发的过程中往往需要对一些IP核进行配置,从而使其能够正常工作。配置IP一般有两种配置方法,一种是在创建IP的配置页面进行配置,另一种是通过AXI-Lite接口去配置。对于一些简单的IP我们选择第一种方法在配置页面配置即可,但是对于一些复杂的IP我们就需要使用第二种配置方法通过AXI-Lite接口去配置。
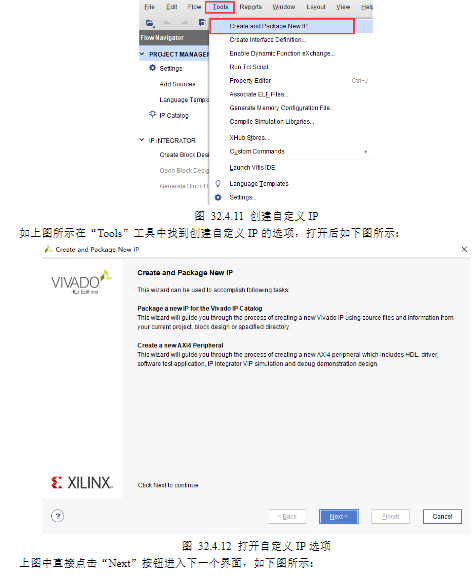
2)在前文简介当中就给大家介绍过AXI-Lite协议了,本节实验为了更快速的完成AXI-Lite接口的配置代码,我们选择使用vivado自带的IP生成工具给我们生成一个带有AXI-Lite接口的模板,在这个模板上去添加我们需要的逻辑代码。
3)
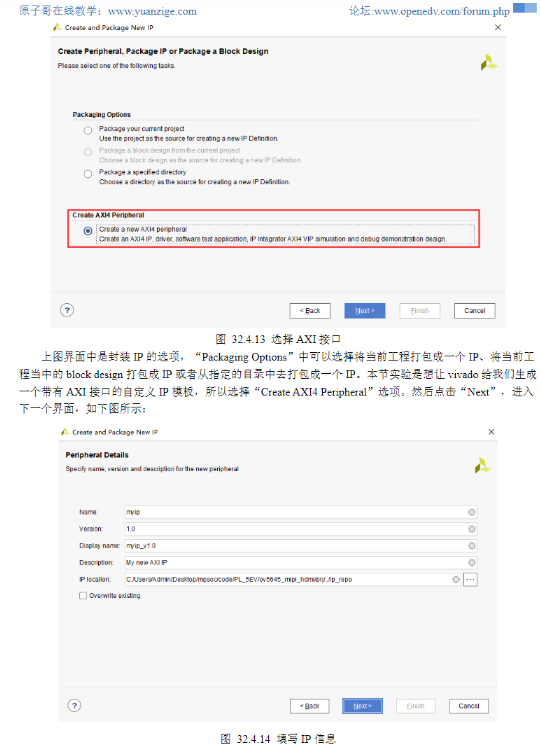
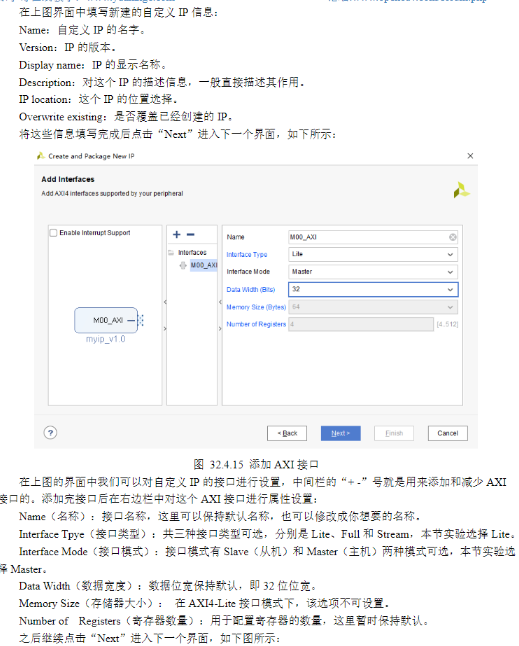
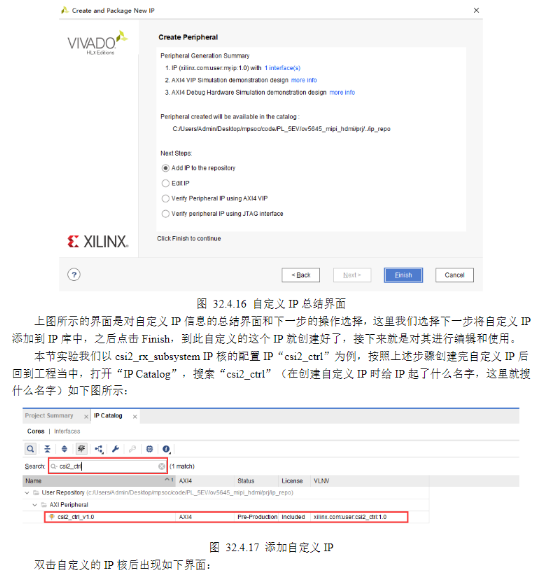
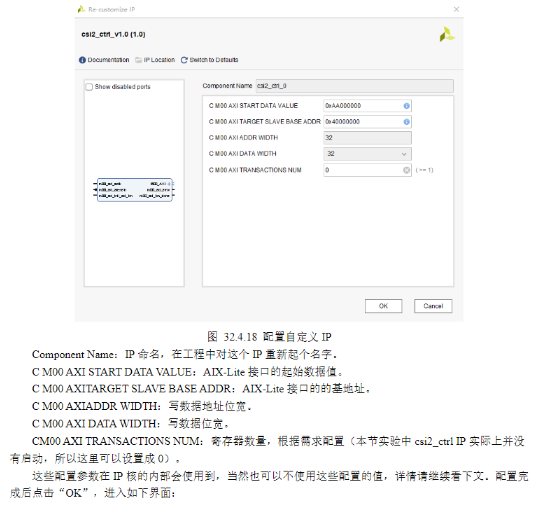
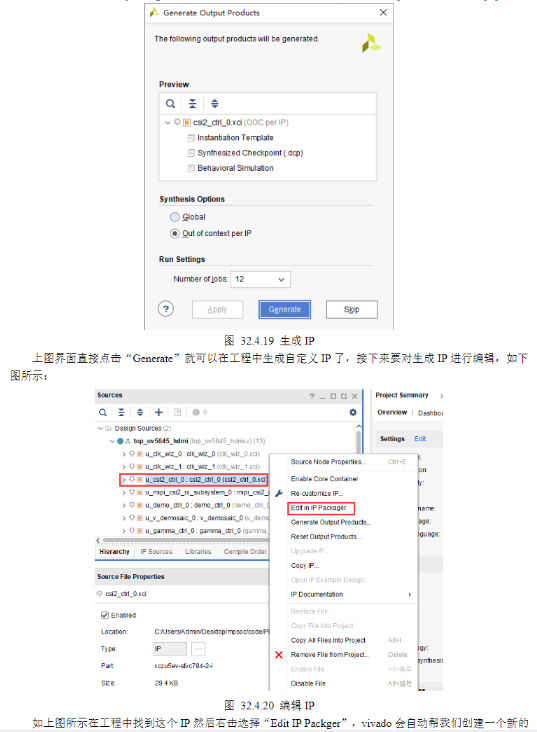
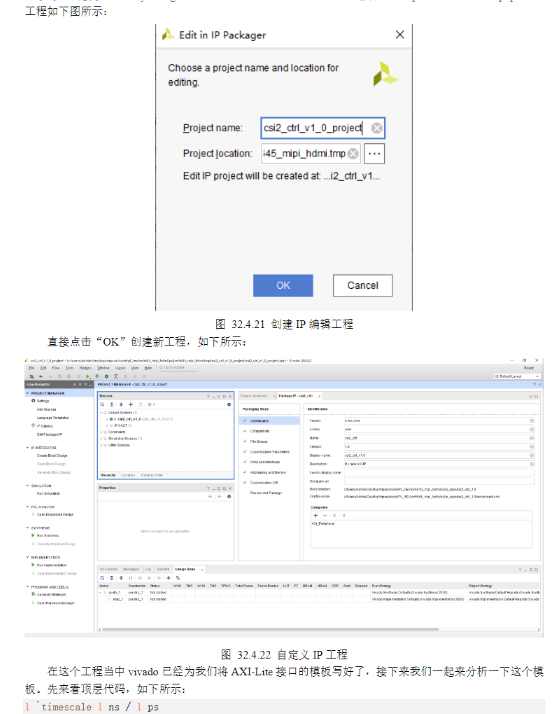
4)代码解析


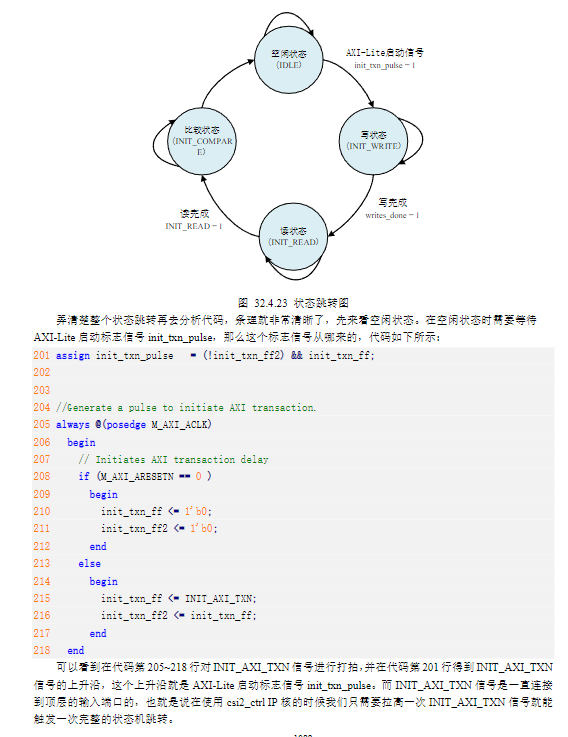



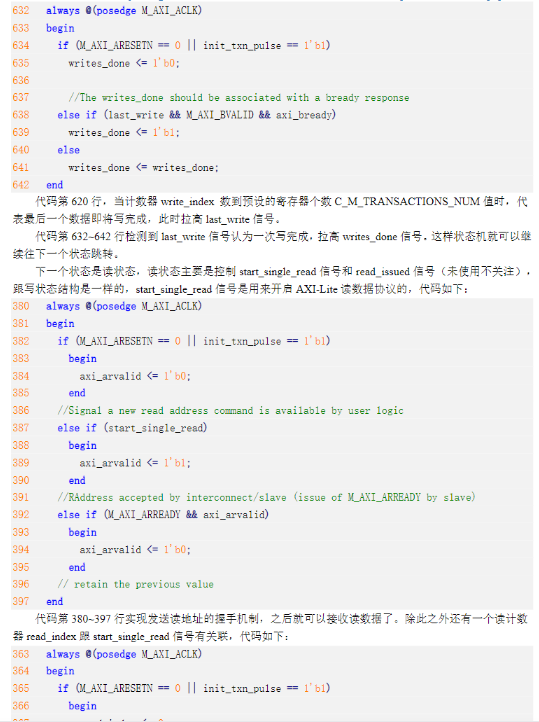

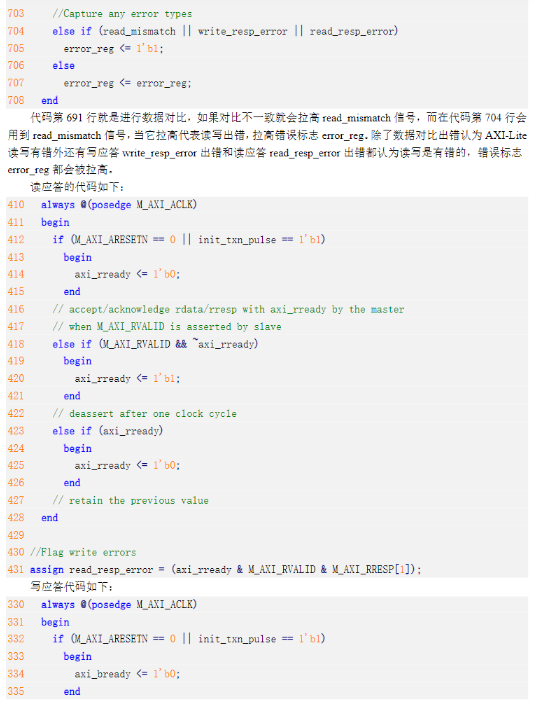
5)接下来关于IP封装的流程,参考正点原子官方文档。
e)demosaic IP配置
1)之后我们继续添加Sensor Demosaic IP,这个IP主要是用来解Bayer数据的,即可重构被称为Bayer的子样本色彩数据,也可重构图像传感器捕获的RAW图像。传感器生成的图像需要完成从RAW数据到RGB数据的转换,由Demosaic和Debayer进行处理。AMD Sensor Demosiac LogiCORE能生成与数字摄像机系统常用的Bayer模式相关的、缺失的颜色分量。Sensor Demosaic IP提供一款高效的薄封装解决方案,可为每个像素插入缺失的色彩分量。(注意:这个IP是HLS IP,需要对vivado打一个补丁,否则添加IP会报错,打补丁教程链接http://www.openedv.com/forum.php?mod=viewthread&tid=346650&extra=)。
2)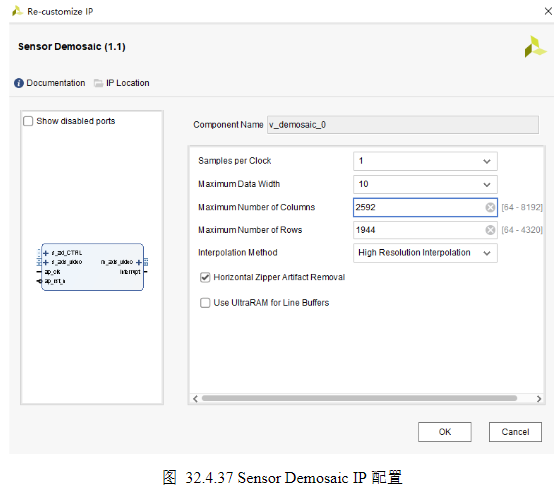
Interpolation Method:插值方法,Sensor Demosaic IP支持两种插值方法:Fringe Tolerant Interpolation(这种方法产生带有抑制条纹伪影的更柔和的图像。使用这一选项的低成本光学器件,可能会引入彩色条纹伪影);High Resolution Interpolation(该方法适用于高质量光学器件和高分辨率应用。选择这种方法会使用更多的块ram和slice,并且大约会使dsp48的使用数量增加一倍)
Horizontal Zipper Artifact Removal:这个选项添加了一个后期处理平滑过滤器来去除水平拉链伪影。后处理过滤器软化输出图像,会额外占用一部分片资源。
Use UltraRAM for Line Buffers:在UltraScale+设备中,用于插值像素的行缓冲器可以存储在UltraRAM中,而不是块RAM中,本节实验没有勾选。
f)
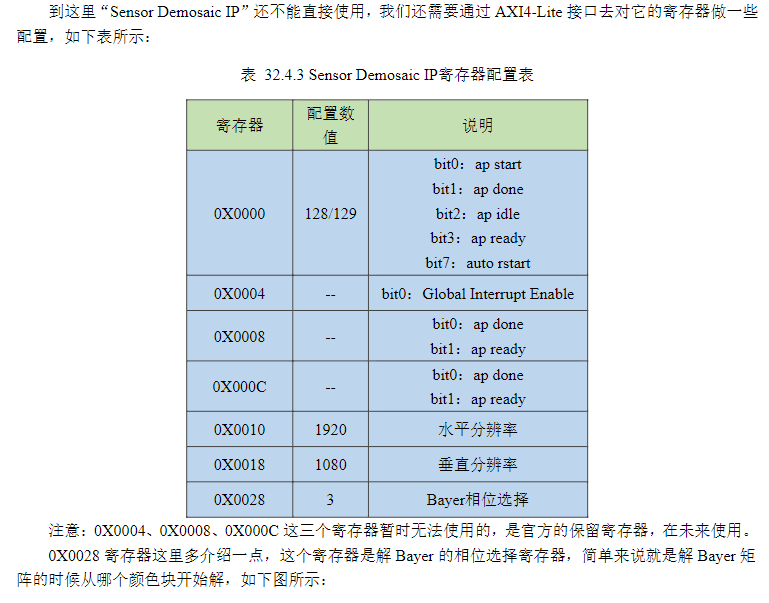
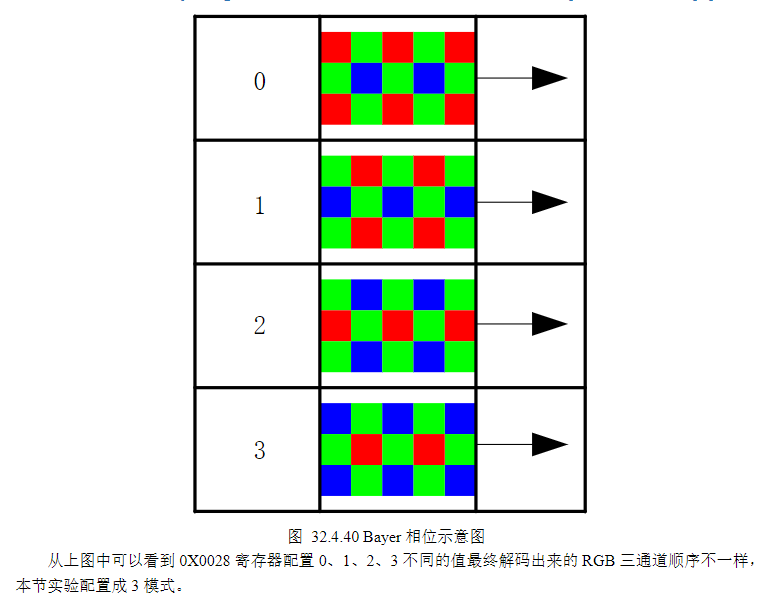
//----------
☆提问☆
问题:不同bayer相位解析有什么区别?
解答:
①PHASE_RGGB是正相位;PHASE_GRBG是行偏移相位;PHASE_GBRG是行偏移相位; PHASE_BGGR是行列偏移相位。这个寄存器告诉IP核的解串器,输入的RAW数据流中,第一个像素是什么颜色。
②这是MIPI CSI-2协议的一个设计缺陷,也是所有RAW格式摄像头必须面对的问题:MIPI CSI-2协议只传输像素的灰度值,不传输任何关于这个像素是什么颜色的信息。传感器输出的Bayer阵列是一个二维的颜色滤镜阵列,但MIPI接口是一个串行的一维数据流。当数据从传感器通过MIPI总线传输到FPGA时,它只是一串连续的10位(或8位/12位)数字,没有任何标记说明哪个数字对应R、哪个对应G、哪个对应B。
③OV5645 的Bayer阵列是标准的RGGB排列,第一行第一个像素是红色,因此0x0028应该设置为0x00(PHASE_RGGB)。如果相位设置错误,IP核会将一个颜色的像素解析成另一个颜色,导致整个画面出现固定的偏色,且这种偏色无法通过白平衡或颜色校正修复。
④注意,传感器的任何镜像或翻转操作都会改变Bayer相位。
//----------
g)gamma_lut IP配置
1)这个IP是一个专门针对图像数据处理优化的处理模块,可满足显示器件的各种需求。该核使用查找表结构实现,这个查找表结构编程后,可实现输入图像数据的伽马校正曲线转换。一般应用于摄像头传感器或显示控制器的图像传感器捕获。
2)同理GammaIP也需要通过AXI-Lite接口对其寄存器进行配置。因为GammaIP的主要功能就是对图像进行Gamma校准,所以这里还需要一份Gamma校准表写入GammaIP才能使其正常工作。
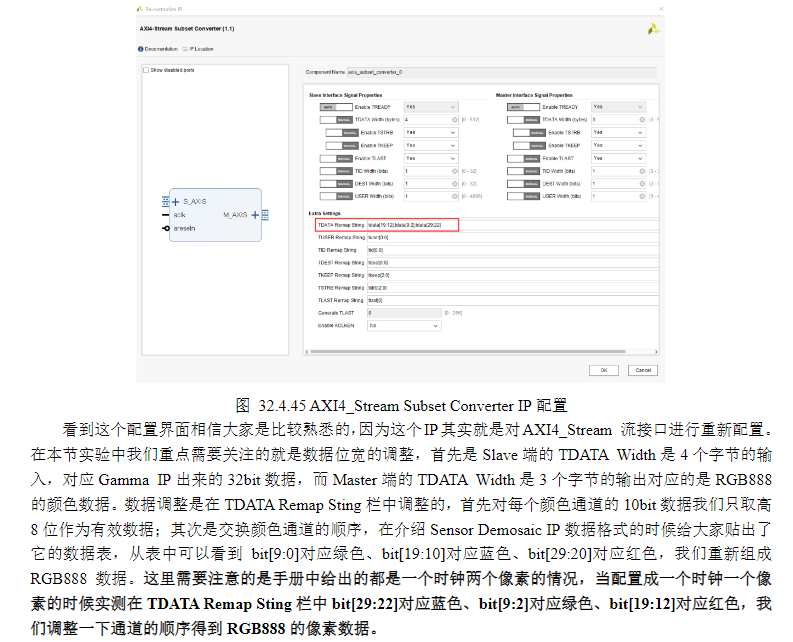
h)RGB数据调整和接口转换
1)
i)DDR4控制器模块
1)DDR4控制器模块的主要功能就是将摄像头采集到的数据缓存进外部DDR4颗粒,并进行读写调度从而使数据流的吞吐速度符合HDMI驱动模块的时序要求。
2)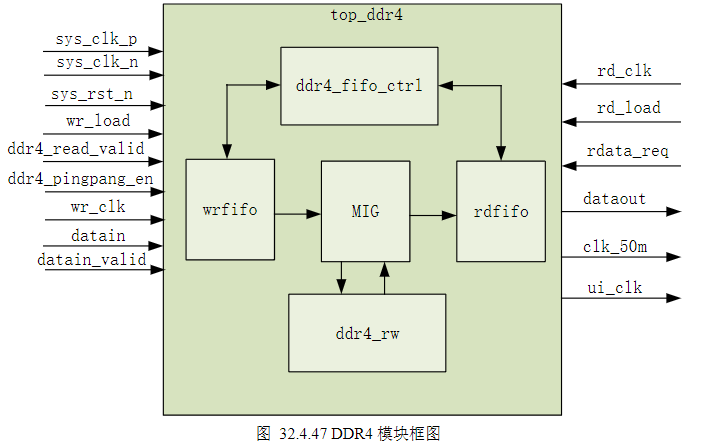
3)我们在DDR中开辟出2个存储空间进行乒乓操作用于缓存帧图像。在摄像头初始化结束后输出的第一个数据对应图像的第一个像素点,将其写入存储空间的首地址中。通过在DDR控制模块中对输出的图像数据进行计数,从而将它们分别写入相应的地址空间。计数达存入DDR的最大写地址后,完成一帧图像的存储,然后当帧复位到来时来切换BANK以达到乒乓操作的目的,并同时回到存储空间的首地址继续下一帧图像的存储。在显示图像时,LCD顶层模块从DDR存储空间的首地址开始读数据,同样对读过程进行计数,并将读取的图像数据分别显示到显示器相应的像素点位置。
4)图像数据总是在两个存储空间之间不断切换写入,而读请求信号在读完当前存储空间后判断哪个存储空间没有被写入,然后去读取没有被写入的存储空间。对于本次程序设计来说,数据写入较慢而读出较快,因此会出现同一存储空间被读取多次的情况,但保证了读出的数据一定是一帧完整的图像而不是两帧数据拼接的图像。当正在读取其中一个缓存空间,另一个缓存空间已经写完,并开始切换写入下一个缓存空间时,由于图像数据读出的速度总是大于写入的速度,因此,读出的数据仍然是一帧完整的图像。下面给出ddr4_rw模块的代码,一起来看看BANK是如何切换的。
板级验证
MIPI摄像头及LCD显示
双目OV5640摄像头RGB-LCD显示
概述
a)OV5640是一款1/4英寸单芯片图像传感器,其感光阵列达到25921944(即500W像素),能实现最快15fpsQSXVGA(25921944)或者90fps VGA(640*480)分辨率的图像采集。传感器采用OmniVision推出的OmniBSI(背面照度)技术,使传感器达到更高的性能,如高灵敏度、低串扰和低噪声。传感器内部集成了图像处理的功能,包括自动曝光控制(AEC)、自动白平衡(AWB)等。同时该传感器支持LED补光、MIPI(移动产业处理器接口)输出接口和DVP(数字视频并行)输出接口选择、ISP(图像信号处理)以及AFC(自动聚焦控制)等功能。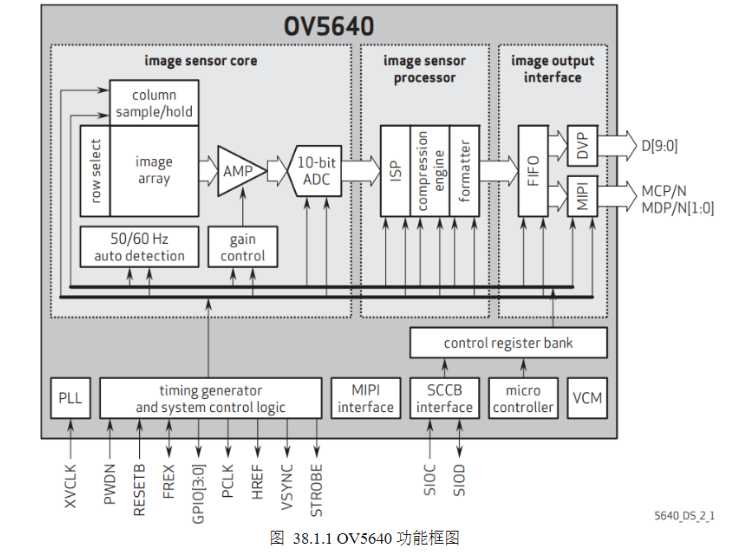
b)时序发生器(timing generator)控制着感光阵列(image array)、放大器(AMP)、AD转换以及输出外部时序信号(VSYNC、HREF和PCLK),外部时钟XVCLK经过PLL锁相环后输出的时钟作为系统的控制时钟;感光阵列将光信号转化成模拟信号,经过增益放大器之后进入10位AD转换器;AD转换器将模拟信号转化成数字信号,并且经过ISP进行相关图像处理,最终输出所配置格式的10位视频数据流。增益放大器控制以及ISP等都可以通过寄存器(registers)来配置,配置寄存器的接口就是SCCB接口,该接口协议兼容IIC协议。
c)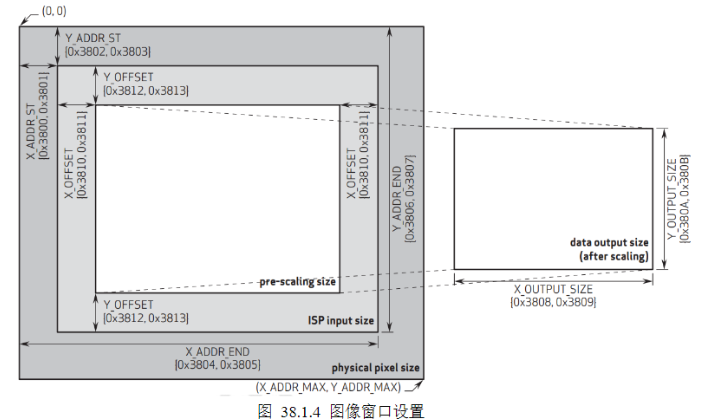
1)ISP输入窗口设置(ISP Input Size)允许用户设置整个传感器显示区域(physical pixel size,26231951,其中25921944像素是有效的),开窗范围从00~26321951都可以任意设置。也就是上图中的X_ADDR_ST(寄存器地址0x3800、0x3801)、Y_ADDR_ST(寄存器地址0x3802、0x3803)、X_ADDR_END(寄存器地址0x3804、0x3805)和Y_ADDR_END(寄存器地址0x3806、0x3807)寄存器。该窗口设置范围中的像素数据将进入ISP进行图像处理。
2)预缩放窗口设置(pre-scaling size)允许用户在ISP输入窗口的基础上进行裁剪,用于设置将进行缩放的窗口大小,该设置仅在ISP输入窗口内进行X/Y方向的偏移。可以通过X_OFFSET(寄存器地址0x3810、0x3811)和Y_OFFSET(寄存器地址0x3812、0x3813)进行配置。
3)输出大小窗口设置(data output size)是在预缩放窗口的基础上,经过内部DSP进行缩放处理,并将处理后的数据输出给外部的图像窗口,图像窗口控制着最终的图像输出尺寸。可以通过X_OUTPUT_SIZE(寄存器地址0x3808、0x3809)和Y_OUTPUT_SIZE(寄存器地0x380A、0x380B)进行配置。注意:当输出大小窗口与预缩放窗口比例不一致时,图像将进行缩放处理(图像变形),仅当两者比例一致时,
输出比例才是1:1(正常图像)。
硬件设计
程序设计
a)总体模块设计
1)本次实验中OV5640的像素时钟频率为48Mhz,而LCD屏根据屏的分辨率不同时钟也不同,首先就有时钟不匹配的问题,其次是时序方面的不匹配,LCD屏驱动对时序有着严格的要求。我们在“RGB-LCD彩条显示实验”的章节中可以获知,LCD一行或一场分为四个部分:低电平同步脉冲、显示后沿、有效数据段以及显示前沿,各个部分的时序参数很显然跟OV5640并不是完全一致的。因此必须先把一帧图像缓存下来,然后再把图像数据按照LCD的时序发送到LCD屏上显示。
2)本次实验采用OV5640支持的最大分辨率25921944,摄像头的输入时钟为24Mhz,摄像头的输出时钟为48Mhz,摄像头输出的分辨率由外接的RGB-LCD屏幕分辨率决定,使用OV5640的缩放处理,本次实验使用的RGB-LCD屏幕分辨率为800480,由此我们可以计算出摄像头的输出帧率,以PCLK=48Mhz(周期为21ns)为例,计算出OV5640输出一帧图像所需的时间如下:一帧图像输出时间:tFrame=18001000(行长HTS与帧长VTS根据实际经验得出)21ns=37800000ns=37.8ms;摄像头输出帧率:1000ms/37.8ms≈26Hz。
3)OV5640根据本次实验使用的LCD屏幕分辨率输出对应的分辨率的RGB565格式数据,一帧图像的数据量达到80048016bit =6114000bit=6000kbit=5.859375Mbit(1k= 1024),带宽(每一秒的数据量)为5.859375Mbit26Hz(帧率,OV5640 QSXGA帧时序下已经介绍)=152.34375Mbit/S,我们MPSoC-P4开发板从Xilinx提供的器件手册可以发现,最大的片内存储资源为20.6Mbit,远不能达到存储要求。因此我们只能使用板载的外部存储器DDR4来缓存图像数据,开发板板载的DDR4容量为4096Mbit(1块ddr4的容量),带宽为25Gbit/S(本次实验使用DDR3的物理位宽是16bit的,DDR3工作时钟频率是800MHz,时钟上下沿都采样,所以带宽为:800MHz216bit=1600MHz16bit= 25Gbit/S),足以满足缓存图像数据的需求。
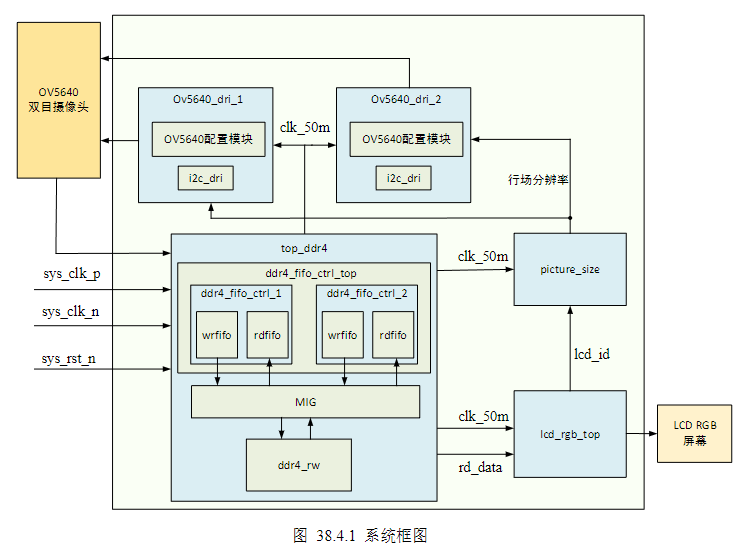
4)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)