AI Agent 设计模式:ReAct 深度解析
·
AI Agent 设计模式:ReAct 深度解析
一、ReAct 的定义与起源
Reasoning + Acting,2022 年 10 月由普林斯顿大学与 Google 联合提出(arXiv: 2210.03629)。
核心思想一句话:强迫大模型交替进行推理与行动,不允许一步给出最终答案。
为什么需要 ReAct?
在 ReAct 之前有两条路线,各有缺陷:
| 路线 | 做法 | 缺陷 |
|---|---|---|
| 纯推理(Chain of Thought) | “一步步想,然后给答案” | 只能靠模型参数里的知识,遇到训练截止后的信息、需要实时查询的问题 → 产生幻觉 |
| 纯行动(Action-only) | “直接干,不行再说” | 没有事前规划,方向偏差后无法纠偏 |
ReAct 的破局点:推理为行动提供方向,行动结果修正推理 — “交错才能纠错”。
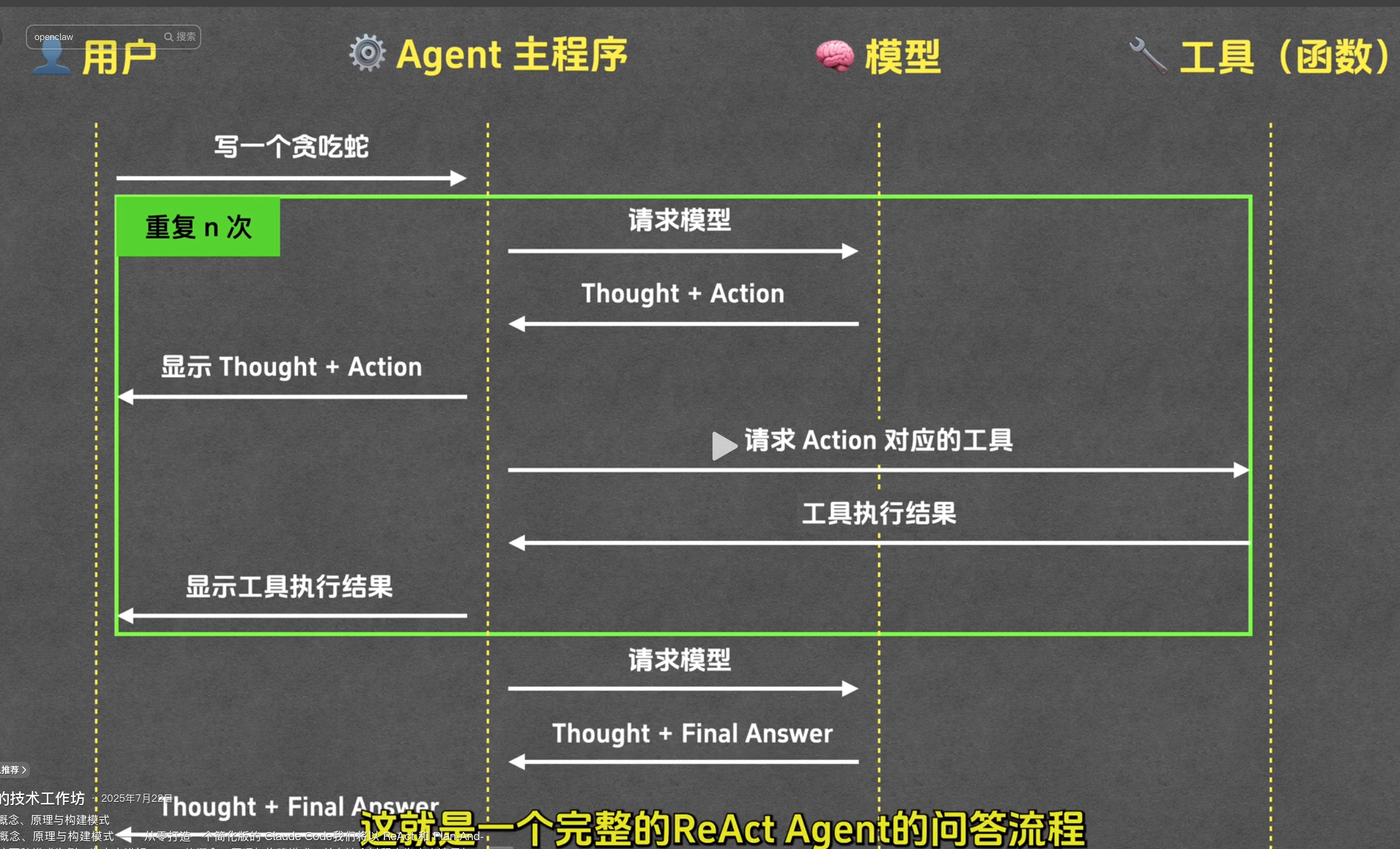
二、核心机制:三步闭环循环
┌──────────────────────────┐
│ Thought │
│ "当前已知什么? │
│ 下一步该做什么?" │
└───────────┬───────────────┘
│ 决定调用哪个工具
▼
┌──────────────────────────┐
│ Action │
│ 调用工具,传入参数 │
│ 如 search_album("西游记") │
└───────────┬───────────────┘
│ 工具在真实环境中执行
▼
┌──────────────────────────┐
│ Observation │
│ 工具返回的真实结果 │
│ "找到 358 个专辑..." │
└───────────┬───────────────┘
│ 结果喂回大模型
▼
(下一轮 Thought)
│
▼
最终无法/不需要调工具时
│
▼
┌──────────────────────────┐
│ Final Answer │
│ "已经在播放第1集了~" │
└──────────────────────────┘
四要素
| 标签 | 谁产生 | 本质 |
|---|---|---|
| Thought | 大模型推理 | “我该干什么?先分析现状” |
| Action | 大模型决策 | “调用工具X,参数Y” |
| Observation | 真实环境 | 不是模型生成的,是工具实实在在跑出来的 |
| Final Answer | 大模型总结 | 基于所有 Observation 的综合回答 |
三、不靠训练,靠系统提示词
ReAct 不是通过微调模型实现的,而是靠一段精心设计的 System Prompt(系统提示词)。
系统提示词模板
你是一个智能助手。你必须严格按照以下格式回复:
可用工具:
- search_album: 搜索有声书专辑
参数: keyword (字符串), page (整数, 默认1)
- get_album_detail: 获取专辑详情和集数列表
参数: album_id (字符串), keyword (字符串, 可选)
- search_and_play: 搜索并播放有声书
参数: keyword (字符串), section (整数, 默认1)
回复格式(严格遵守!):
Thought: <你的思考过程>
Action: <工具名>
Action Input: <JSON格式参数>
Observation: <工具返回结果>
...(可多轮循环)...
Final Answer: <最终回复用户的内容>
规则:
1. 每步只调一个工具
2. Action 必须来自可用工具列表
3. Action Input 必须是合法 JSON
4. 有足够信息回答时就输出 Final Answer
5. 绝对不要编造 Observation,它由系统填入
大模型读到这段 Prompt 后,就会按格式输出。框架代码负责:
- 解析模型输出的
Action和Action Input - 真正执行工具
- 把结果作为
Observation追加回对话 - 判断是继续循环还是输出 Final Answer
四、最小可运行实现
4.1 Python 实现(70 行)
import json
import re
class ReactAgent:
"""ReAct 引擎:Thought → Action → Observation 循环"""
def __init__(self, tools: dict, system_prompt: str):
self.tools = tools # {"工具名": 函数}
self.system_prompt = system_prompt
self.max_rounds = 10 # 防止死循环
def run(self, user_task: str) -> str:
"""
核心循环:
1. 构建 messages(系统提示词 + 用户任务)
2. 调大模型 → 解析输出
3. 如果是 Final Answer → 返回
4. 如果是 Action → 执行工具 → Observation → 回到第 2 步
"""
messages = [
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": user_task},
]
for _ in range(self.max_rounds):
# ====== Thought 阶段:调大模型 ======
response = self._call_llm(messages)
text = response.strip()
# ====== 判断终止 ======
if "Final Answer:" in text:
print(f"[ReAct] ✅ 循环结束")
return self._extract_tag(text, "Final Answer")
# ====== 解析 Action ======
action_name = self._extract_tag(text, "Action")
action_input_str = self._extract_tag(text, "Action Input")
if not action_name or action_name not in self.tools:
# 模型输出格式不对,提示重试
messages.append({"role": "assistant", "content": text})
messages.append({
"role": "user",
"content": "Observation: 格式错误!请检查 Action 名称和 Action Input"
})
continue
print(f"[ReAct] 🔧 执行工具: {action_name}({action_input_str})")
# ====== Action 阶段:真正执行工具 ======
try:
action_input = json.loads(action_input_str)
tool_result = self.tools[action_name](**action_input)
except Exception as e:
tool_result = f"工具执行失败: {str(e)}"
# ====== Observation 阶段:结果写回对话 ======
observation = f"Observation: {tool_result}"
print(f"[ReAct] 👁 Observation: {tool_result[:100]}...")
messages.append({"role": "assistant", "content": text})
messages.append({"role": "user", "content": observation})
# → 回到循环顶部,大模型看到 Observation 后继续 Thought
return "超过最大循环次数,任务未完成"
def _call_llm(self, messages: list) -> str:
"""调大模型(这里用伪代码代替,实际调 OpenAI/DeepSeek API)"""
# 实际代码:
# import openai
# response = openai.ChatCompletion.create(
# model="gpt-4o", messages=messages, temperature=0
# )
# return response.choices[0].message.content
#
# 这里用简化模拟:
last_user_msg = messages[-1]["content"] if messages else ""
if "Final Answer" in last_user_msg:
return last_user_msg # 模拟:用户提示中已含答案就停止
# 实际场景中这里会真正调用 LLM API
raise NotImplementedError("替换为真实的 LLM API 调用")
def _extract_tag(self, text: str, tag: str) -> str:
"""从模型输出中提取标签内容"""
pattern = rf"{tag}:\s*(.*?)(?:\n|$)"
match = re.search(pattern, text, re.DOTALL)
return match.group(1).strip() if match else ""
4.2 接入懒人听书工具
# ====== 懒人听书工具(从 xiaozhi Player 中简化) ======
# 模拟工具(实际中这些是真实的 API 调用)
def search_album(keyword: str, page: int = 1) -> str:
"""搜索有声书专辑"""
# 实际调用: 52api.cn API
result = {
"西游记": "找到3个专辑: 1.米小圈快乐西游记(主播:米小圈) 2.西游记|甄齐播讲(主播:甄齐) 3.西游记少儿版(主播:阅耳亲子故事)",
"三体": "找到5个专辑: 1.三体|广播剧(主播:729声工场) 2.三体全集(主播:青雪) ...",
}
return result.get(keyword, f"未找到与'{keyword}'相关的有声书")
def get_album_detail(album_id: str, keyword: str = "") -> str:
"""获取专辑详情,返回集数列表"""
# 实际调用: 52api.cn API type=detail
return f"专辑ID:{album_id}, 共100集: 第1集:猴王出世, 第2集:拜师学艺, ..."
def search_and_play(keyword: str, section: int = 1) -> str:
"""搜索并播放(优先本地缓存)"""
# 实际调用: Player.search_and_play()
# 1. 查本地缓存
# 2. 缓存命中 → 直接播放
# 3. 缓存未命中 → 后台下载 + 立即返回
return f"正在播放(本地): {keyword} - 第{section}集"
# ====== 注册工具 ======
tools = {
"search_album": search_album,
"get_album_detail": get_album_detail,
"search_and_play": search_and_play,
}
# ====== 系统提示词 ======
SYSTEM_PROMPT = """
你是一个懒人听书助手。你必须按以下格式回复:
可用工具:
- search_album: 搜索有声书,参数 {"keyword": "西游记", "page": 1}
- get_album_detail: 查看专辑详情,参数 {"album_id": "123", "keyword": ""}
- search_and_play: 搜索并播放,参数 {"keyword": "西游记", "section": 1}
回复格式:
Thought: <思考过程>
Action: <工具名>
Action Input: <JSON参数>
...(可循环多轮)...
Final Answer: <最终回答>
"""
# ====== 启动 Agent ======
agent = ReactAgent(tools=tools, system_prompt=SYSTEM_PROMPT)
# 用户任务
result = agent.run("帮我播放西游记第1集")
print(f"\n用户看到: {result}")
4.3 一次完整的执行轨迹
用户: "帮我播放西游记第1集"
━━━ 第 1 轮 ━━━
大模型输出:
Thought: 用户想播放西游记第1集。search_and_play 可以一步完成搜索和播放,直接用这个。
Action: search_and_play
Action Input: {"keyword": "西游记", "section": 1}
框架执行:
tools["search_and_play"](keyword="西游记", section=1)
→ 查本地缓存 / 调API / 后台下载
→ 返回: "正在播放(本地): 西游记 - 第1集"
框架追加到 messages:
Observation: 正在播放(本地): 西游记 - 第1集
━━━ 第 2 轮 ━━━
大模型收到 Observation 后输出:
Thought: 播放成功了,任务完成。
Final Answer: 已经在播放西游记第1集了~
框架判断: "Final Answer:" 存在 → 循环结束 → 返回给用户
五、ReAct 循环在xiaozhi 项目中的实际对应
5.1 架构映射
┌──────────────────────────────────────────────────────────────┐
│ ReAct 引擎(xiaozhi) │
│ │
│ 远程大模型 MCP Server │
│ (DeepSeek/混元) (localhost) │
│ ┌────────────┐ ┌──────────────────────────┐ │
│ │ Thought │ │ │ │
│ │ "搜一下 │ │ │ │
│ │ 西游记" │ │ │ │
│ │ ↓ │ │ │ │
│ │ Action │ ────────→ │ tools/call │ │
│ │ "lanrentingshu │ ↓ │ │
│ │ .search_album" │ Manager.wrapper() │ │
│ │ ↓ │ │ ↓ │ │
│ │ Action │ │ Player.search_album() │ │
│ │ Input │ │ ↓ │ │
│ │ {keyword: │ │ HTTP POST → 52api.cn │ │
│ │ "西游记"} │ │ ↓ │ │
│ │ │ │ 返回 JSON → 格式化文本 │ │
│ │ │ │ ↓ │ │
│ │Observation│ ←──────── │ "找到 358 个有声书..." │ │
│ │ ↓ │ │ │ │
│ │ Thought │ │ │ │
│ │ "选第一个 │ │ │ │
│ │ 播放" │ │ │ │
│ │ ↓ │ │ │ │
│ │ Action │ ────────→ │ tools/call │ │
│ │ "lanrentingshu │ ↓ │ │
│ │ .search_and_play" │ 搜索→下载→FFmpeg解码 │ │
│ │ │ │ ↓ │ │
│ │Observation│ ←──────── │ "正在播放..." │ │
│ │ ↓ │ │ │ │
│ │ Final │ │ │ │
│ │ Answer │ │ │ │
│ └────────────┘ └──────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
5.2 懒人听书 7 个 Tool 在 ReAct 中的角色
| MCP Tool | ReAct 标签 | 触发场景 |
|---|---|---|
search_album |
Action | “帮我搜一下西游记” |
get_album_detail |
Action | “看看西游记有多少集” |
search_and_play |
Action | “播放西游记第1集” |
pause |
Action | “暂停” |
resume |
Action | “继续” |
stop |
Action | “别放了” |
get_status |
Action | “现在在播什么?” |
每个 Tool 的返回值 = Observation,直接喂回大模型作为下一轮 Thought 的输入。
5.3 后台异步任务:避免阻塞 ReAct 循环
你的 search_and_play 有个关键优化:
async def search_and_play(self, keyword: str, stream_section: int = 1) -> dict:
# 第一步:查本地缓存 — 快路径
local_file = await self._find_local_episode(keyword, stream_section)
if local_file:
await self._play_local_file(local_file, ...)
return {"status": "success", "message": f"正在播放(本地): {keyword} - 第{stream_section}集"}
# ← Observation 瞬间返回,ReAct 循环不卡
# 第二步:后台下载 — 慢路径
asyncio.create_task(self._background_search_and_play(keyword, stream_section))
return {"status": "success", "message": "正在搜索下载中,请稍等一下~", "background": True}
# ← Observation 也瞬间返回!
如果不用后台模式:
ReAct 循环:
Action: search_and_play("西游记", 1)
↓
... 等待 30 秒下载 ... ← 整个循环卡死!
↓
Observation: (30秒后才回来)
↓
AI 请求超时 ❌ 用户看不到回复
使用后台模式:
ReAct 循环:
Action: search_and_play("西游记", 1)
↓ (10ms)
Observation: "正在下载中,请稍等一下~" ← 瞬间返回
↓
Thought: "下载中,告知用户等待"
Final Answer: "正在帮你下载西游记第1集,稍等一下哦~"
... 30 秒后,后台下载完成,自动播放 ...
六、ReAct 的关键工程价值
6.1 白盒化(可解释性)
每一轮 Thought-Action-Observation 都保留在对话历史中:
messages = [
{system: "你是懒人听书助手..."},
{user: "播放西游记第1集"},
{assistant: "Thought: 需要搜索和播放... Action: search_and_play..."},
{user: "Observation: 正在播放(本地): 西游记 - 第1集"},
{assistant: "Thought: 成功了... Final Answer: 已经在播放了~"},
]
开发者可以回溯每一步:
- 为什么调了这个工具?→ 看 Thought
- 工具返回了什么?→ 看 Observation
- 为什么决定结束?→ 看最后一轮的 Thought
6.2 可干预性
人类可以在任意 Thought 节点插入修正,不需要重跑整个任务:
原来的 Observation: "找到 358 个专辑"
人类插入: "Observation: 前5个结果不对,请只看第6到第10个"
→ 大模型收到新 Observation → 调整策略 → 继续
6.3 防止幻觉
CoT(纯推理)的问题:
用户: "今天北京天气怎么样?"
CoT: "北京今天晴天,25度" ← 幻觉!模型不知道今天天气
ReAct:
用户: "今天北京天气怎么样?"
Thought: 我不知道今天天气,需要查
Action: get_weather("北京")
Observation: "2026-05-18 北京: 多云, 22°C" ← 真实数据
Final Answer: "北京今天多云,22°C" ← 基于真实 Observation
七、ReAct vs Plan-And-Execute 对比
| 维度 | ReAct | Plan-And-Execute |
|---|---|---|
| 核心循环 | Thought → Action → Observation | 先 Plan → Execute → Replan |
| 模块数 | 1 个大模型 | 多个(Plan模型 + Replan模型 + 执行Agent) |
| 规划方式 | 边走边看,每步即时决策 | 先画完整路线图,再一步步走 |
| 调整方式 | 每轮 Observation 后自然调整 | 执行完一步后 Replan 模型重新规划 |
| 适用场景 | 探索性任务、状态不确定 | 多步骤、子目标明确的任务 |
| 实现复杂度 | 低(一个 while 循环) | 高(“Agent 套 Agent”) |
| 懒人听书适用 | ✅ 搜索→选专辑→播放,每步依赖前一步结果 | ❌ 过度设计 |
八、总结
┌─────────────────────────────────────────────────────────────┐
│ │
│ 大模型 = 大脑(只能推理) │
│ + │
│ 工具 = 感官和四肢(读写文件、调API、执行命令) │
│ = │
│ Agent = 能感知和改变世界的智能程序 │
│ │
│ ReAct = Agent 的调度引擎 │
│ Thought → Action → Observation 三步循环 │
│ 推理为行动指方向,行动结果为推理纠错 │
│ │
│ 实现 = System Prompt(格式约束)+ while 循环(引擎) │
│ 不靠微调,靠 Prompt Engineering │
│ │
│ 价值 = 白盒化(每步可回溯)+ 防幻觉(Observation是真实数据) │
│ + 可干预(人类可中途插入修正) │
│ │
└─────────────────────────────────────────────────────────────┘
自 2022 年论文至今,ReAct 的核心结构始终是 Thought-Action-Observation 三步闭环循环。大模型从"回答问题"升级为"完成真实世界任务",靠的就是这套机制。
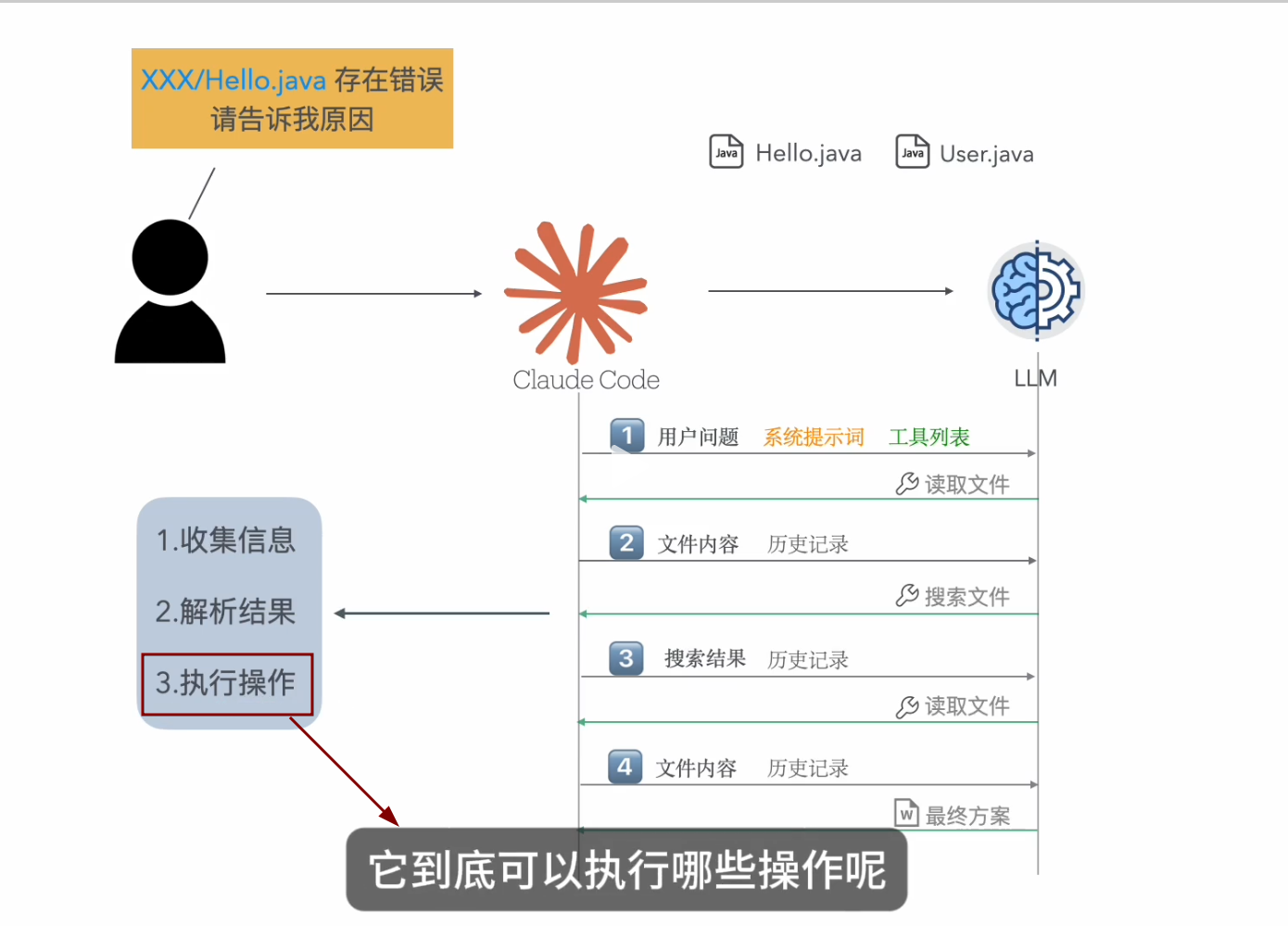
然后至于它都能执行哪些操作,是由工具来决定的,而工具又怎么来的呢?可以继续看看MCP相关的!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)