python数据分析可视化+模型预测实战
说明
本数据集是从和鲸社区下载的电商数据集,分析过程从数据处理(pandas、numpy、datetinme)——可视化(matplotlib.pyplot【plot、hist、pie】)(seaborn【heatmap】)——建模预测(statsmodels【ARIMA】)(sklearn【LinearRegression、RandomForestRegressor】)从预测结果来看,样本太少,随机波动太大,导致模型都不太适用。
1、pandas数据处理
行列概览-缺失值-异常值-字段格式转换
import pandas as pd
from datetime import datetime, timedelta
# 加载数据
df = pd.read_csv('data.csv')
print("初始数据形状:", df.shape)
print(df.info())
print("缺失值统计:")
print(df.isnull().sum())
print("处理异常值:")
# 检查数量的异常值
print("数量描述:")
print(df['buy_cnt'].describe())
# 检查单价的异常值
print("单价描述:")
print(df['price'].describe())
# 转换日期格式
df['date'] = pd.to_datetime(df['date'])
# 提取月份、星期几等特征
df['month'] = df['date'].dt.month
df['weekday'] = df['date'].dt.dayofweek # 0=Monday, 6=Sunday
print(df[['date', 'month', 'hour', 'weekday']].head())
print(df.info())#看一下转换后日期列的数据类型
print("整体数据概览")
# 基本统计摘要
print("数值字段描述:")
print(df[['buy_cnt', 'price', 'amount']].describe())
# 类别字段的频次
print("类别分布:")
print(df['category_code'].value_counts())数据集是没有空值的,不过有一列类别名称是R,我觉得可能是原博主根据空值已经处理好的
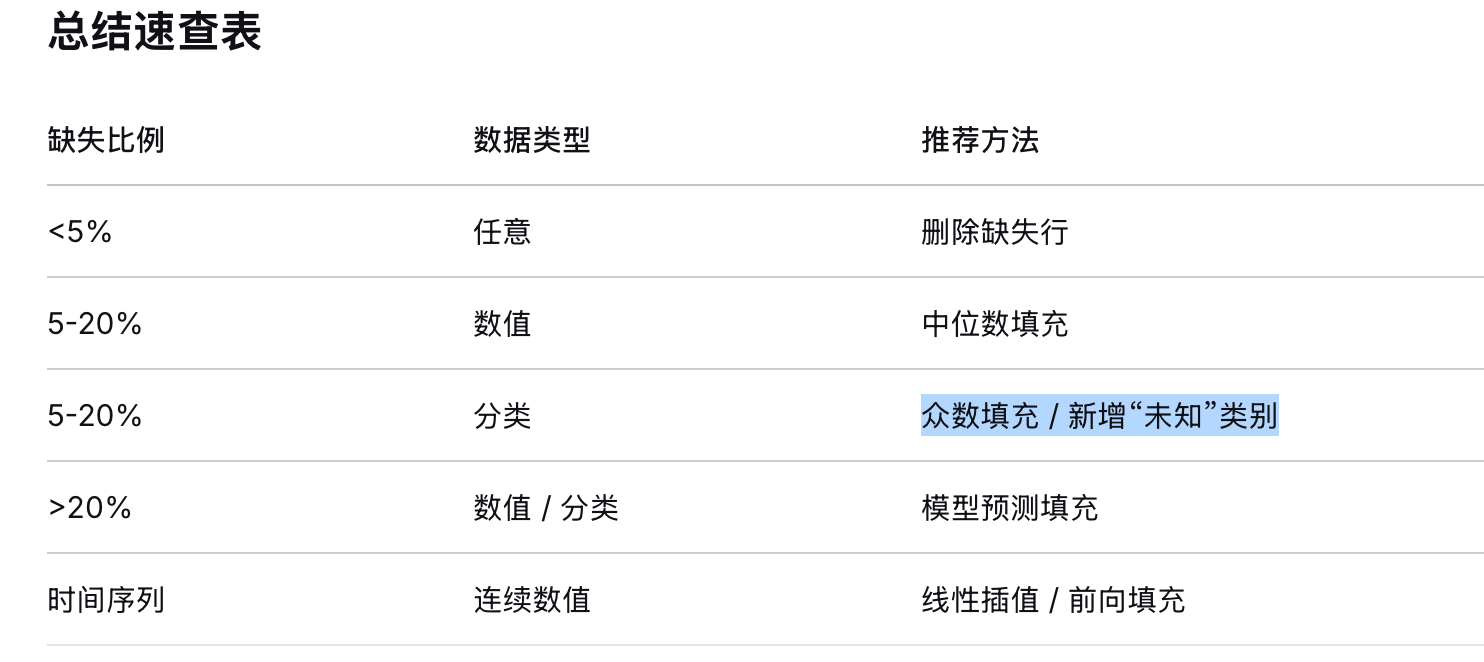
2、销售趋势分析
print("销售趋势分析")
# 按日期聚合每日销售额
daily_sales = df.groupby('date')['amount'].sum().reset_index()
daily_sales = daily_sales.sort_values('date').reset_index(drop=True)
# 导入库
import matplotlib.pyplot as plt
# 加上这3行,解决中文乱码
plt.rcParams["font.family"] = ["SimHei", "Microsoft YaHei", "Arial Unicode MS", "DejaVu Sans"]
plt.rcParams["axes.unicode_minus"] = False # 必写!解决负号报错
plt.rcParams["font.size"] = 12
#绘制折线图
plt.figure(figsize=(12, 6))
plt.plot(daily_sales['date'], daily_sales['amount'])
plt.title('Daily Sales Trend')
plt.xlabel('Date')
plt.ylabel('Total Sales(元)')
plt.grid(True)
plt.yscale('log') # 对数Y轴,低频用户的柱子也能看清
plt.savefig('daily_sales.png', dpi=300, bbox_inches='tight')
plt.show()
#按星期几
daily_sales3 = df.groupby('weekday')['amount'].sum().reset_index()
daily_sales3 = daily_sales3.sort_values('weekday').reset_index(drop=True)
# 加上这3行,解决中文乱码
plt.rcParams["font.family"] = ["SimHei", "Microsoft YaHei", "Arial Unicode MS", "DejaVu Sans"]
plt.rcParams["axes.unicode_minus"] = False # 必写!解决负号报错
plt.rcParams["font.size"] = 12
#绘制折线图
plt.figure(figsize=(12, 6))
# 关闭科学计数法!关键就是这一句
plt.ticklabel_format(style='plain', axis='y')
#画图
plt.plot(daily_sales3['weekday'], daily_sales3['amount'])
plt.title('weekday Sales Trend')
plt.xlabel('weekday')
plt.ylabel('Total Sales(元)')
plt.grid(True)
plt.savefig('weekday_sales.png', dpi=300, bbox_inches='tight')
plt.show()
#按小时
daily_sales4 = df.groupby('hour')['amount'].sum().reset_index()
daily_sales4 = daily_sales4.sort_values('hour').reset_index(drop=True)
# 加上这3行,解决中文乱码
plt.rcParams["font.family"] = ["SimHei", "Microsoft YaHei", "Arial Unicode MS", "DejaVu Sans"]
plt.rcParams["axes.unicode_minus"] = False # 必写!解决负号报错
plt.rcParams["font.size"] = 12
#绘制折线图
plt.figure(figsize=(12, 6))
plt.plot(daily_sales4['hour'], daily_sales4['amount'])
plt.title('weekday Sales Trend')
plt.xlabel('hour')
plt.ylabel('Total Sales(元)')
# 设置X轴刻度为1-24
plt.xticks(range(0, 24, 1)) # 0到23,间隔1小时
plt.grid(True)
plt.savefig('hour_sales.png', dpi=300, bbox_inches='tight')
plt.show()
这部分主要从日期(年月日)、星期、小时三个时间维度,对销售额进行分组聚合,分析不同时间周期下的销售波动规律与趋势特征。
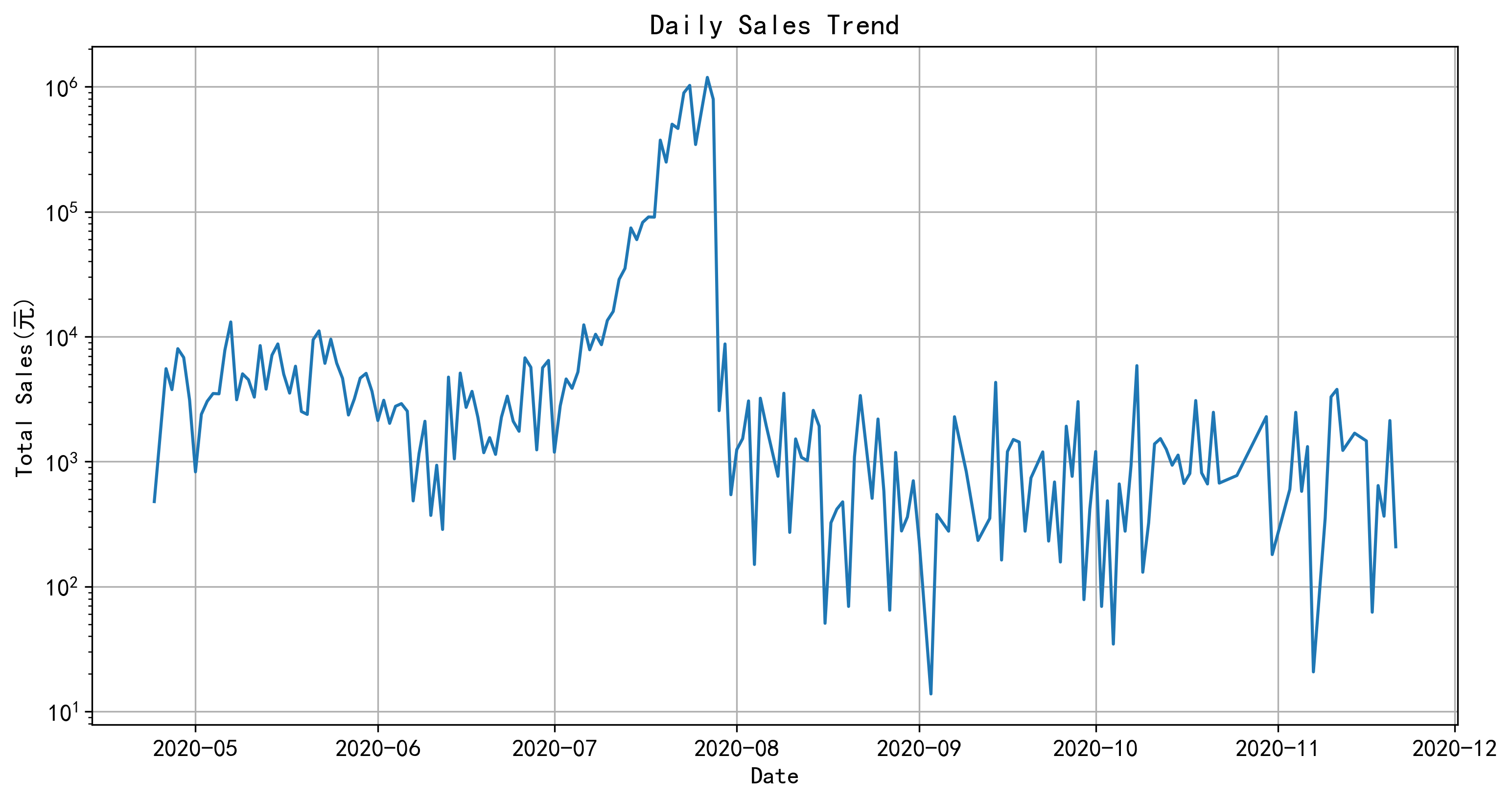
这里y刻度做了一个对数处理,否则y值差距太大,导致只能看出7月份的峰值,其他值都被压得扁平。
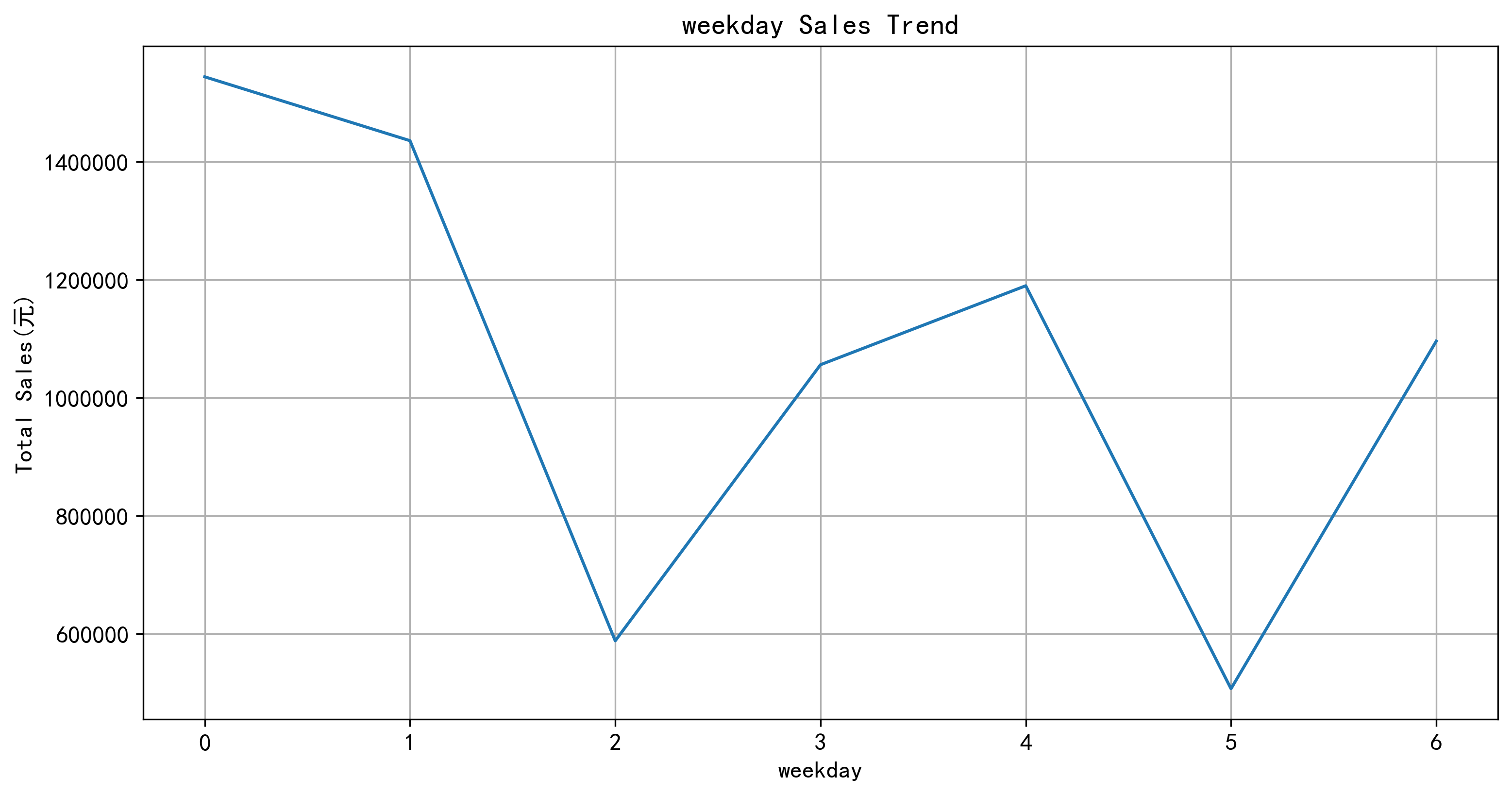
星期一的销售额最高
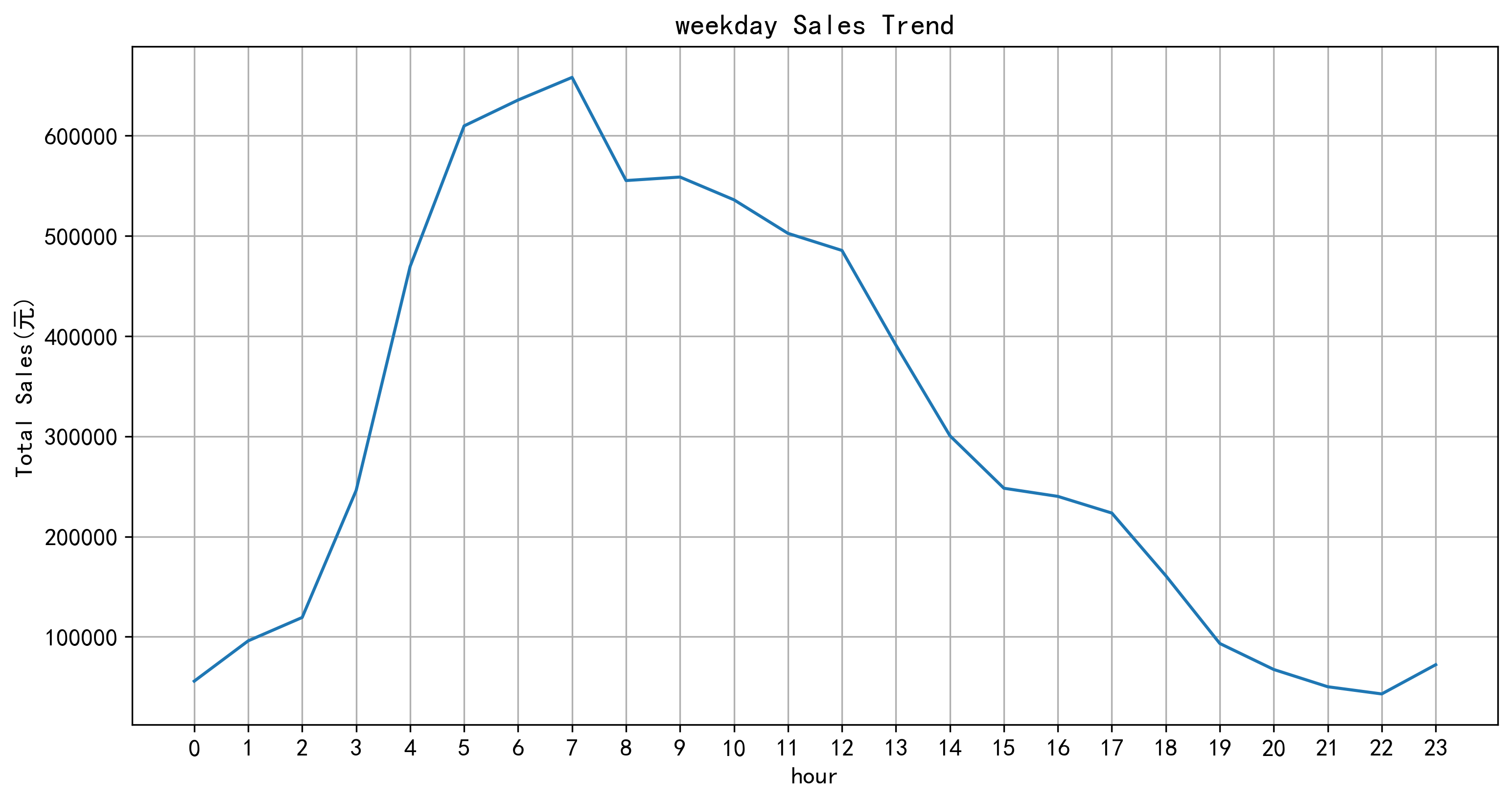
早上七点的销售额最高
3、客户行为分析
print("客户行为分析")
# 按客户聚合购买行为
customer_behavior = df.groupby('user_id').agg({
'amount': 'sum',
'order_id': 'count',
'buy_cnt': 'sum'
}).rename(columns={'amount': 'total_price','order_id': 'order_count', 'buy_cnt': 'total_quantity'})
# 计算平均订单价值
customer_behavior['average_order_value'] = customer_behavior['total_price'] / customer_behavior['order_count']
print("客户行为描述:")
print(customer_behavior.describe())
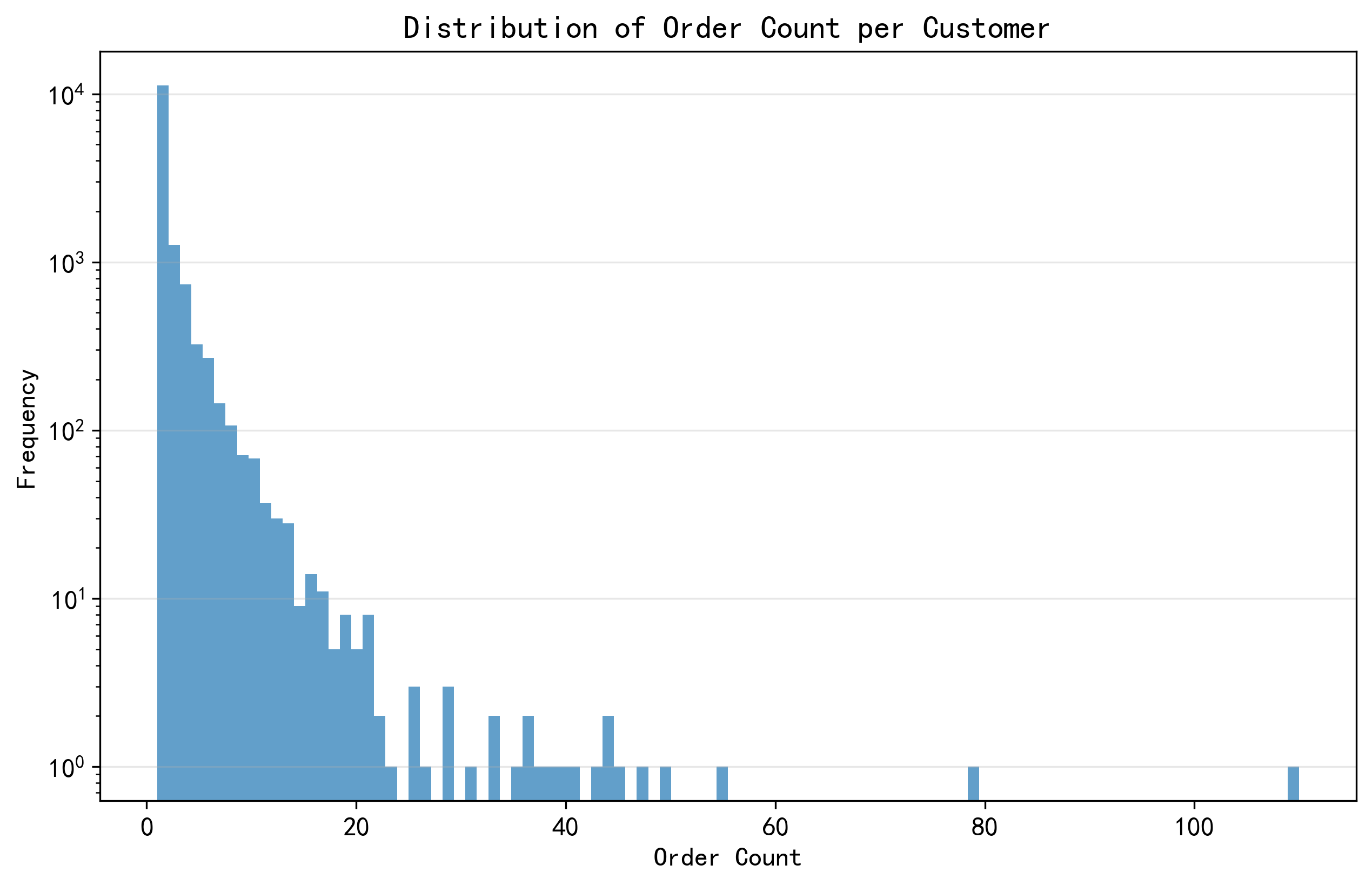
# 绘制客户订单数量的直方图:看数据分布
plt.figure(figsize=(10, 6))
plt.hist(customer_behavior['order_count'], bins=100, alpha=0.7)
plt.title('Distribution of Order Count per Customer')
plt.xlabel('Order Count')
plt.ylabel('Frequency')
plt.yscale('log') # 对数Y轴,低频用户的柱子也能看清
plt.grid(axis='y', alpha=0.3)#加横向网格线,方便看数值
plt.savefig('customer_behavior.png', dpi=300, bbox_inches='tight')
plt.show()
绘制直方图显示客户订单数量的分布,了解客户活跃度。绝大多数客户的订单数量非常少,只有极少数客户的订单数量极高
4、产品类别分析
print("产品类别分析")
# 按类别聚合销售额和数量
category_performance = df.groupby('category_code').agg({
'amount': 'sum',
'buy_cnt': 'sum'
}).reset_index().rename(columns={'amount': 'total_sales', 'buy_cnt': 'total_quantity'})
# 计算每个类别的平均单价
category_performance['average_unit_price'] = category_performance['total_sales'] / category_performance['total_quantity']
# 计算每个类别的占比
category_performance['percentage'] = category_performance['total_sales'] / category_performance['total_sales'].sum()
print("类别表现:")
print(category_performance)
# 2. 把占比 < 2% 的类目,合并成“其他”,否则饼图“失控” ,标签挤在一起、数字重叠,完全没法看
threshold = 0.02
category_performance['category_code'] = category_performance.apply(
lambda x: x["category_code"] if x['percentage'] >= threshold else '其他',
axis=1
)
# 3. 按合并后的类目重新汇总
category_performance = category_performance.groupby('category_code').agg({
'total_sales': 'sum',
'total_quantity': 'sum'
}).reset_index()
# 计算每个类别的平均单价
category_performance['average_unit_price'] = category_performance['total_sales'] / category_performance['total_quantity']
print("类别表现:")
print(category_performance)
# 绘制类别销售额的饼图
plt.figure(figsize=(12, 8))
a,b,c=plt.pie(category_performance['total_sales'], labels=None, autopct='%1.1f%%')
plt.legend(a,category_performance['category_code'], bbox_to_anchor=(1, 0.5))
plt.title('Sales Distribution by Category', fontsize=16)
plt.subplots_adjust(left=0, right=0.75, top=0.9, bottom=0.1)# 关键:调整边距,让饼图居中,左右空白均匀
plt.savefig('category_performance.png', dpi=300, bbox_inches='tight')
plt.show()
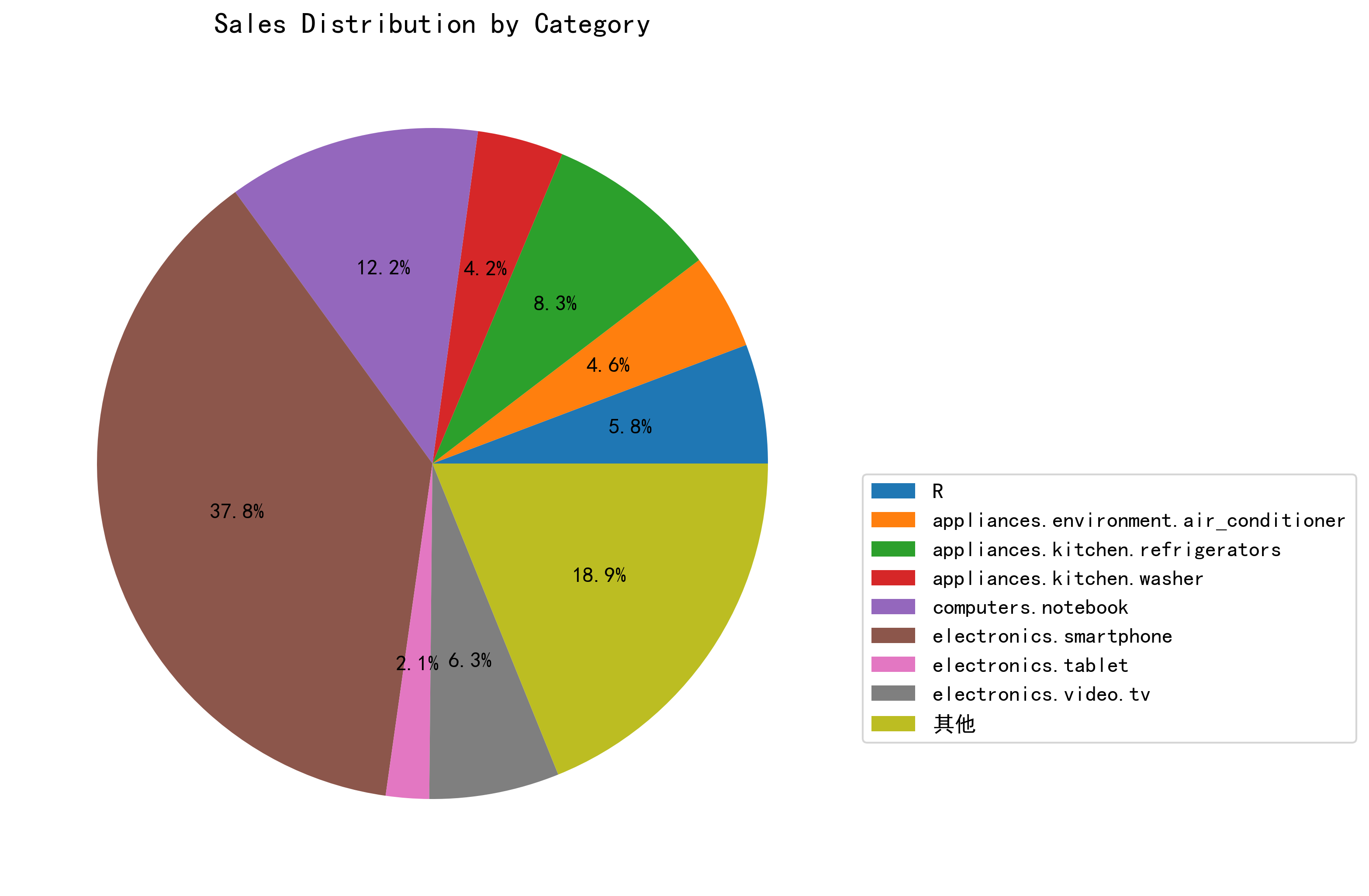
这个图我做了一步把把占比 < 2% 的类目,合并成“其他”的操作,因为类别太多了,导致饼图标签完全挤在一起,可视化效果太差了
5、相关性分析
print("相关性分析")
# 计算相关系数矩阵
correlation_matrix = df[['buy_cnt', 'price', 'amount']].corr()
print("相关系数矩阵:")
print(correlation_matrix)
# 绘制热力图,红偏正相关,蓝偏负相关,颜色越深 = 相关性越强
import seaborn as sns
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.savefig('相关系数图.png', dpi=300, bbox_inches='tight')
plt.show()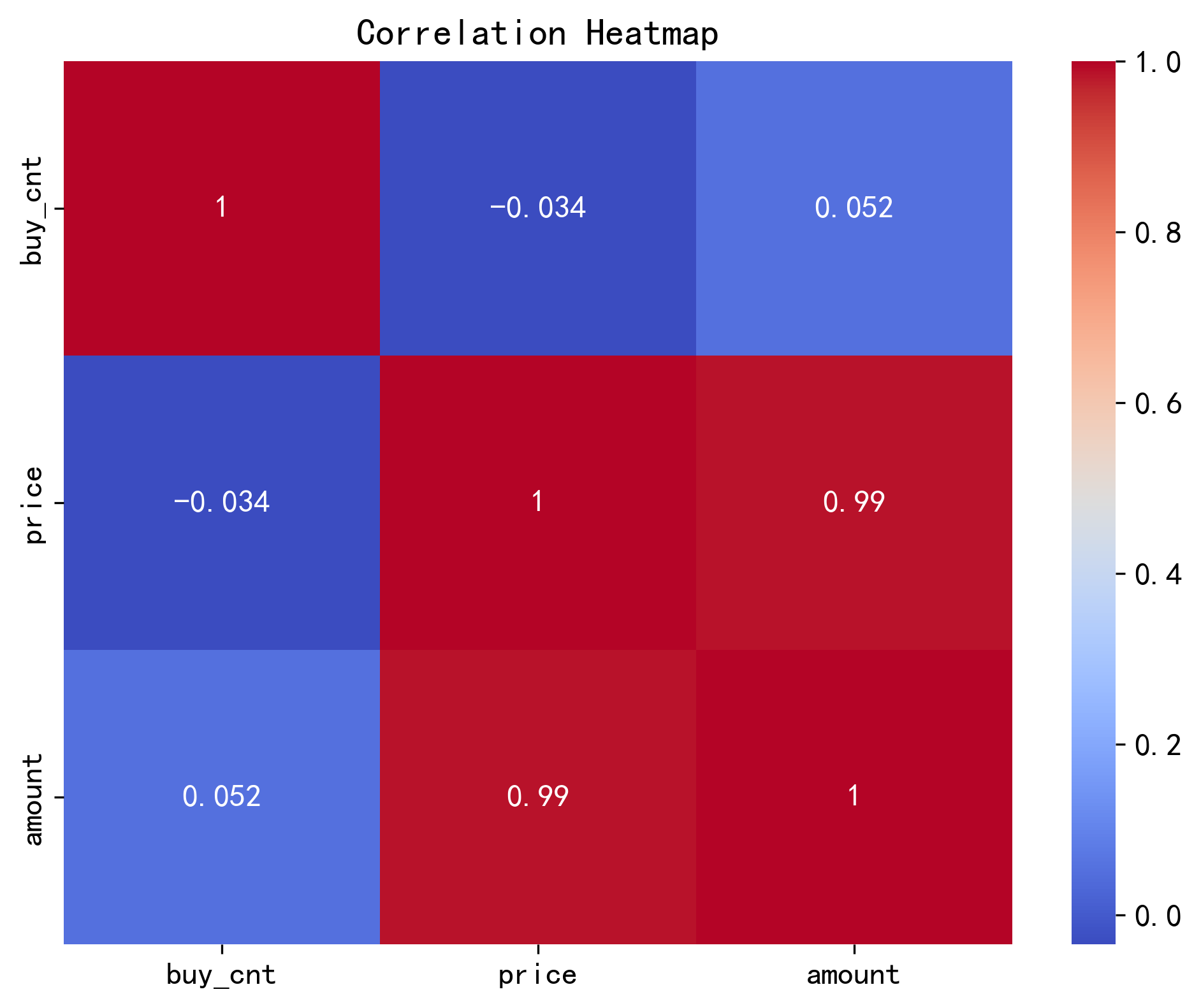
price 和 amount 存在极强的正相关,相关系数高达 0.99,几乎接近 1,说明两者呈完全线性关系。业务上,这意味着:订单总金额几乎完全由商品单价决定,和购买数量几乎无关。
6、未来销售额预测模型
(1)时间序列预测模型ARIMA
print("时间序列预测模型")
# 确保日期是索引
daily_sales = daily_sales.set_index('date')
# 标记原始真实日期
daily_sales['is_real'] = True
# 关键一步:强制按天频率对齐,补全缺失日期
daily_sales = daily_sales.asfreq('D')
# 关键:虚拟日期的 is_real 会变成 NaN,我们手动改成 False
daily_sales['is_real'] = daily_sales['is_real'].fillna(False)
# 3. 只填充业务列(比如 amount),不碰 is_real:填充缺失的销售额(用前一天的值)
fill_median = daily_sales['amount'].median()
daily_sales['amount'] = daily_sales['amount'].fillna(method="ffill")
# 检查平稳性(时间序列要求)
from statsmodels.tsa.stattools import adfuller
result = adfuller(daily_sales['amount'])
print('ADF Statistic:', result[0])
print('p-value:', result[1])
# 如果p值大于0.05,数据非平稳,需差分
if result[1] > 0.05:
daily_sales['diff'] = daily_sales['amount'].diff().dropna()
print("差分后的ADF检验:")
result_diff = adfuller(daily_sales['diff'].dropna())
print('ADF Statistic:', result_diff[0])
print('p-value:', result_diff[1])
print("判断acf和pacf")
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
# 你的时间序列(已经处理好的 daily_sales)
ts = daily_sales['amount']
# 1. 画 ACF 图 → 看 q
plt.figure(figsize=(12, 4))
plot_acf(ts, lags=20)
plt.title("ACF 图 (看 q)")
plt.show()
# 2. 画 PACF 图 → 看 p
plt.figure(figsize=(12, 4))
plot_pacf(ts, lags=20, method='ywm')
plt.title("PACF 图 (看 p)")
plt.show()
#开始预测
from statsmodels.tsa.arima.model import ARIMA
# 拆分训练集和测试集(最后30天作为测试集)
train = daily_sales['amount'][:-30]
test = daily_sales['amount'][-30:]
# 拟合ARIMA模型
model = ARIMA(train, order=(2,0,1)) # 参数根据ACF/PACF图选择
model_fit = model.fit()
# 预测
predictions = model_fit.forecast(steps=30)
compare = pd.DataFrame({
'真实值': test,
'预测值': predictions,
"is_real": daily_sales['is_real'][-30:]
})
print(compare)
import numpy as np
# 对销量做对数变换,处理极端值
daily_sales['log_amount'] = np.log1p(daily_sales['amount']) # log1p避免0值报错
# 检查平稳性(时间序列要求)
result = adfuller(daily_sales['log_amount'])
print('ADF Statistic:', result[0])
print('p-value:', result[1])
# 如果p值大于0.05,数据非平稳,需差分
if result[1] > 0.05:
daily_sales['diff'] = daily_sales['log_amount'].diff().dropna()
print("差分后的ADF检验:")
result_diff = adfuller(daily_sales['diff'].dropna())
print('ADF Statistic:', result_diff[0])
print('p-value:', result_diff[1])
# 用对数销量训练模型
train = daily_sales[['log_amount']][:-30]
test = daily_sales['amount'][-30:]
# 你的时间序列(已经处理好的 daily_sales)
ts = daily_sales['log_amount']
# 1. 画 ACF 图 → 看 q
plt.figure(figsize=(12, 4))
plot_acf(ts, lags=20)
plt.title("ACF 图 (看 q)")
plt.savefig("acf_plot.png") # 保存图片
plt.show()
# 2. 画 PACF 图 → 看 p
plt.figure(figsize=(12, 4))
plot_pacf(ts, lags=20, method='ywm')
plt.title("PACF 图 (看 p)")
plt.savefig("pacf_plot.png")
plt.show()
# 拟合ARIMA模型
model = ARIMA(train, order=(2,1,1)) # 参数根据ACF/PACF图选择
model_fit = model.fit()
# 预测
predictions = model_fit.forecast(steps=30)
lr_predictions = np.expm1(predictions) # 还原对数
compare4 = pd.DataFrame({
'真实值': test,
'预测值': lr_predictions,
"is_real": daily_sales['is_real'][-30:]
})
print(compare4)
- 这个预测模型的过程遇到挺多困难,我还是做了挺多调整的,最繁琐的调整就是日期列的调整以及ARIMA中三个参数order=(p, d, q)的选取:
- 把时间列设置为行索引 index,方便模型识别时序顺序(时间必须从小到大依次排序,不能乱序、颠倒)
- 做到时间连续无断档;有空缺值要补全填充,不能大片空缺---这一步报错我发现我的时间是大片不连续的,数据集的好多日期天是不存在的,补全日期的话:1)总销售额的值用什么填充是一个问题,我尝试了中位数,上一天的值以及直接的0,发现预测结果都不尽人意。 2)因为我后面要预测,所以我肯定要分清那些日期是真实有值的,那些日期是我真实填充的,所以我在这个df里面加了一列“IS_TRUE”用来标记。
- 根据ACF/PACF图调整了很多次p和q,问了豆包,值调的太大也不行,但是我自己试了,q调大一点预测的数值波动性会更强一点,值调的太小,就跟上面一样值太水平了,毫无波澜,甚至到后面值都不变了
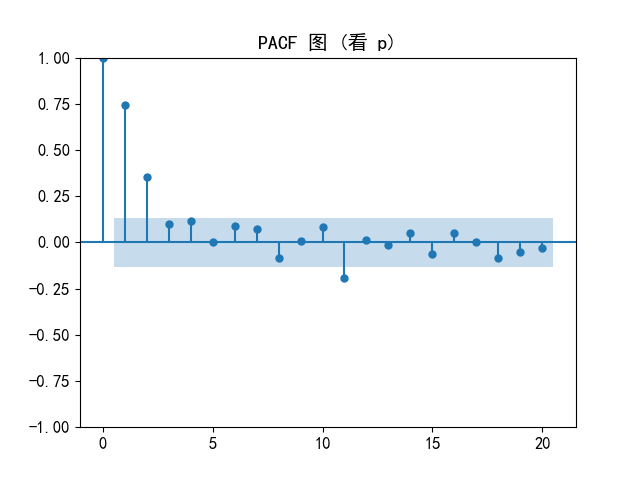
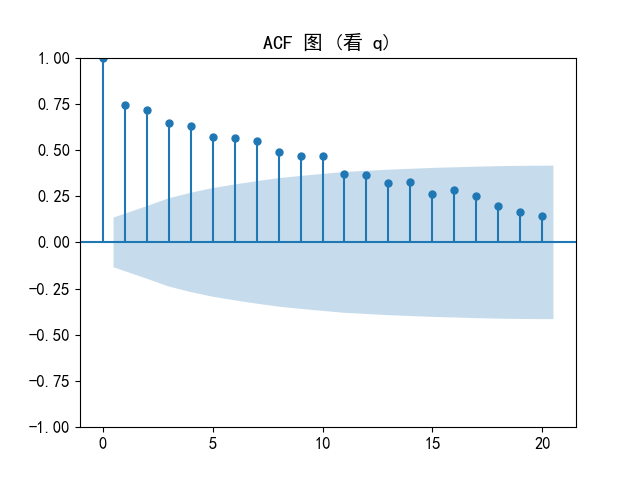
还有刚开始的预测数据和真实值差了两个量级,太不可思议了,后面我把总销售额的一列改成它的对数值再去训练,预测完又还原,量级才勉强好了一点点,总之非常离谱
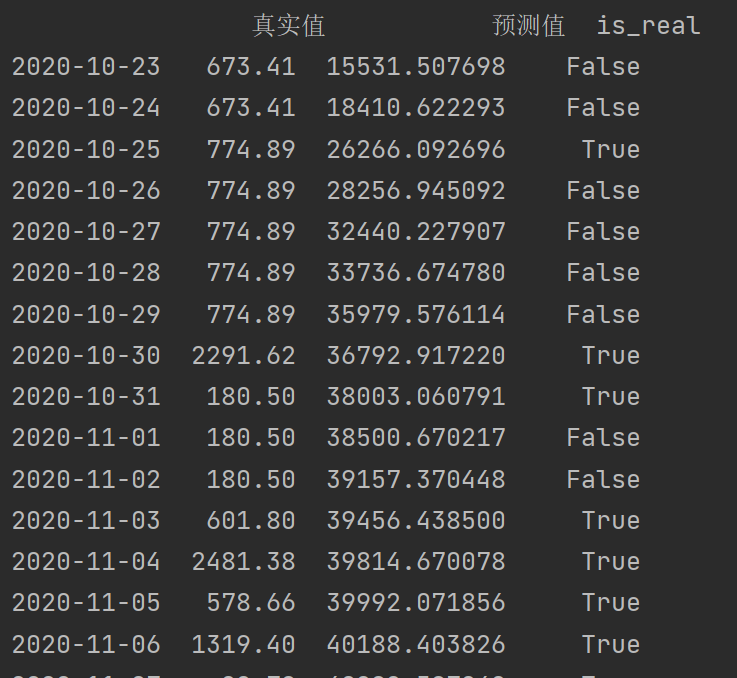
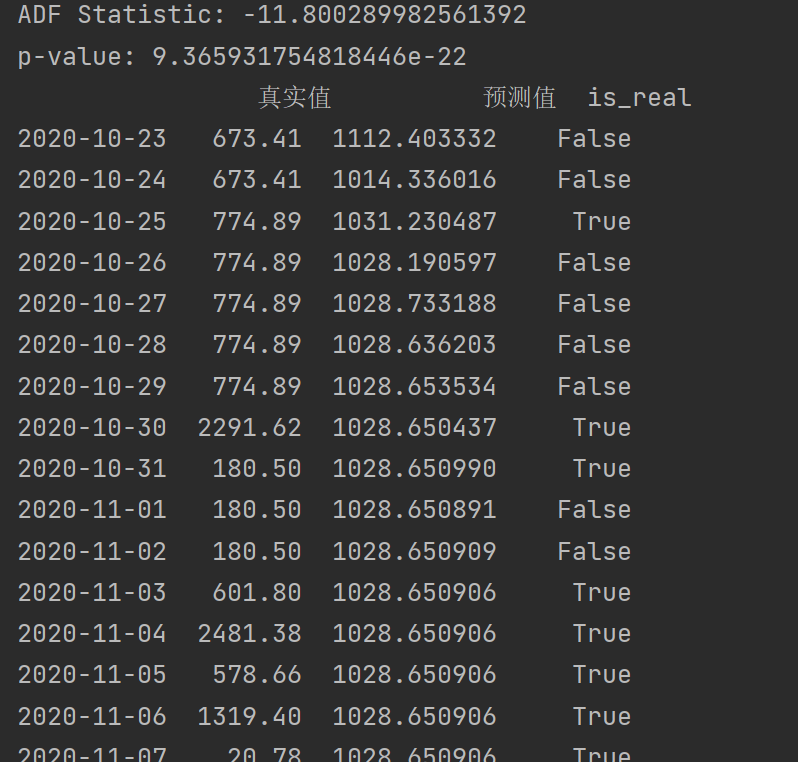
ai告诉我q不能调太大,没有突然调入置信区间的阶数,只能取0和1,然后我的预测值根本没有什么波澜
(2)线性回归模型
#线性回归模型
from sklearn.linear_model import LinearRegression
daily_sale=daily_sales[daily_sales['is_real']==True].copy()
# 为时间序列创建特征:例如,日期序号
daily_sale['day_index'] = range(len(daily_sale))
# 准备特征和目标变量
X = daily_sale[['day_index']][:-30]
y = daily_sale['amount'][:-30]
X_test = daily_sale[['day_index']][-30:]
Y_test=daily_sale['amount'][-30:]
# 训练模型
lr_model = LinearRegression()
lr_model.fit(X, y)
# 预测
lr_predictions = lr_model.predict(X_test)
compare2 = pd.DataFrame({
'真实值': Y_test,
'预测值': lr_predictions,
"is_real": daily_sale['is_real'][-30:]
})
print(compare2)
import numpy as np
# 对销售额做对数变换,处理极端值
daily_sale['log_amount'] = np.log1p(daily_sale['amount']) # log1p避免0值报错
# 用对数销量训练模型
X = daily_sale[['day_index']][:-30]
y_log = daily_sale['log_amount'][:-30]
X_test = daily_sale[['day_index']][-30:]
y_test = daily_sale['amount'][-30:]
# 训练
lr_model = LinearRegression()
lr_model.fit(X, y_log)
# 预测并还原
log_predictions = lr_model.predict(X_test)
lr_predictions = np.expm1(log_predictions) # 还原对数
comparison3= pd.DataFrame({
'真实': y_test, # 原始真实值
'预测': lr_predictions # 预测值(已还原)
})
print("======= 真实值 VS 预测值 =======")
print(comparison3)
这个也是刚开始的预测值太离谱,所以我也对销售额做了对数化的处理,线性回归模型没有日期必须要连续的说法,所以没必要填充日期列,但是x必须是数值类型,也要是df形式,创建一个就行~
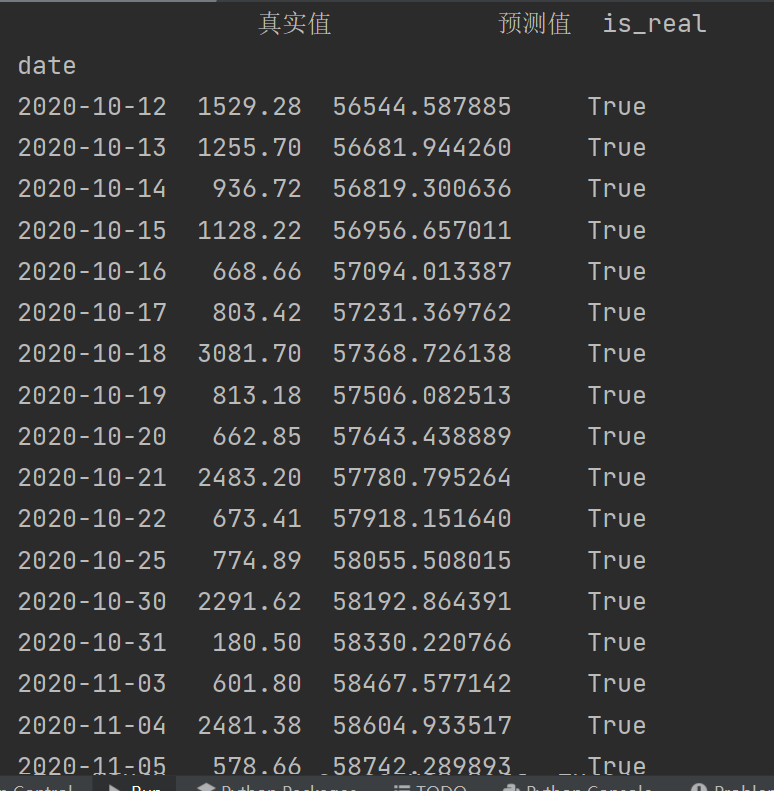
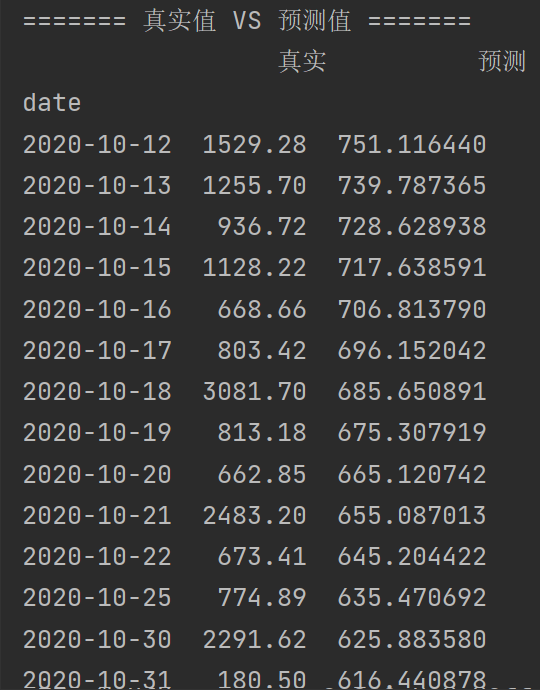
结果也是不好的吧,不过本来就不适合用这个模型~
(3)随机森林模型
也不用填充日期序列,特征可以有多列,这里选取时间序号、星期几、月、前一天总销售额作为特征列。
为什么要选取时间序号作为一列:豆包的解释是----就是在告诉模型“这是第 1 天、第 2 天、第 3 天…… 整体是随时间变化的,你要把这个趋势学进去。”,否则它不理解 “时间先后” 的概念,无法捕捉 “销量整体是上升 / 下降” 的长期趋势。
print("随机森林模型")
from sklearn.ensemble import RandomForestRegressor
# ====================== 1. 加载你的数据(date + amount) ======================
daily_sales7=daily_sales[daily_sales['is_real']==True].copy()
daily_sales7 = daily_sales7.reset_index()
daily_sales7['date'] = pd.to_datetime(daily_sales7['date'])
# ====================== 2. 构建预测特征(让模型学得更准) ======================
daily_sales7['day_id'] = np.arange(len(daily_sales7)) # 时间序号(第几天)
daily_sales7['weekday'] = daily_sales7['date'].dt.dayofweek # 星期几(0=周一,6=周日)
daily_sales7['month'] = daily_sales7['date'].dt.month # 月份
daily_sales7['last_day_amount'] = daily_sales7['amount'].shift(1) # 前一天的总销售额
# 【关键】删除所有 NaN!
daily_sales7 = daily_sales7.dropna()
# ====================== 3. 划分数据集 ======================
# 最后30天作为测试集,前面所有数据作为训练集
test_days = 30
train_df = daily_sales7.iloc[:-test_days]
test_df = daily_sales7.iloc[-test_days:]
# 特征列 & 目标列
features = ['day_id', 'weekday', 'month', 'last_day_amount']
X_train = train_df[features]
y_train = train_df['amount'] # 总销售额(训练目标)
X_test = test_df[features]
y_test = test_df['amount'] # 总销售额(真实值)
# ====================== 4. 训练随机森林模型 ======================
model = RandomForestRegressor(n_estimators=200, random_state=42, n_jobs=-1)
model.fit(X_train, y_train)
# ====================== 5. 预测最后30天 ======================
y_pred = model.predict(X_test)
comparison4= pd.DataFrame({
'真实': y_test, # 原始真实值
'预测': y_pred # 预测值
})
print(comparison4)
sklearn 所有模型(线性回归、随机森林、ARIMA 等等)训练时,数据里都不允许有 NaN 空值!只要有一个空值,模型直接报错并停止运行。所以取前一天总销售额的时候,第一行会返回空值,要注意删掉这一行。
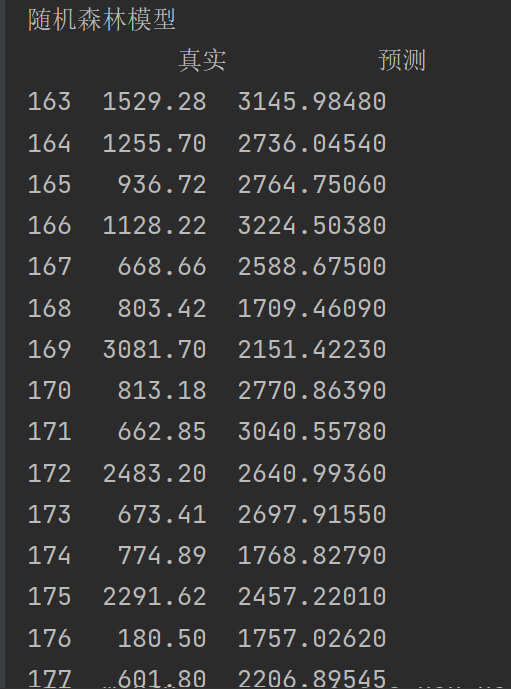
至少这个模型预测出来的值是有波动的吧,后面再取对数用这个模型预测一下,看结果会不会更好一点。
对数化:
# 对销售额做对数变换,处理极端值
daily_sales7['log_amount'] = np.log1p(daily_sales7['amount']) # log1p避免0值报错
daily_sales7['log_last_day_amount'] = daily_sales7['log_amount'].shift(1) # 前一天的总销售额
# 【关键】删除所有 NaN!
daily_sales9 = daily_sales7.dropna()
# 最后30天作为测试集,前面所有数据作为训练集
test_days = 30
train_df = daily_sales9.iloc[:-test_days]
test_df = daily_sales9.iloc[-test_days:]
# 特征列 & 目标列
features = ['day_id', 'weekday', 'month', 'log_last_day_amount']
X_train = train_df[features]
y_train = train_df['log_amount'] # 总销售额(训练目标)
X_test = test_df[features]
y_test = test_df['amount'] # 总销售额(真实值)
# ====================== 4. 训练随机森林模型 ======================
model = RandomForestRegressor(n_estimators=200, random_state=42, n_jobs=-1)
model.fit(X_train, y_train)
# ====================== 5. 预测最后30天 ======================
y_pred = model.predict(X_test)
lr_predictions = np.expm1(y_pred) # 还原对数
comparison5= pd.DataFrame({
'真实': y_test, # 原始真实值
'预测': lr_predictions # 预测值
})
print(comparison5)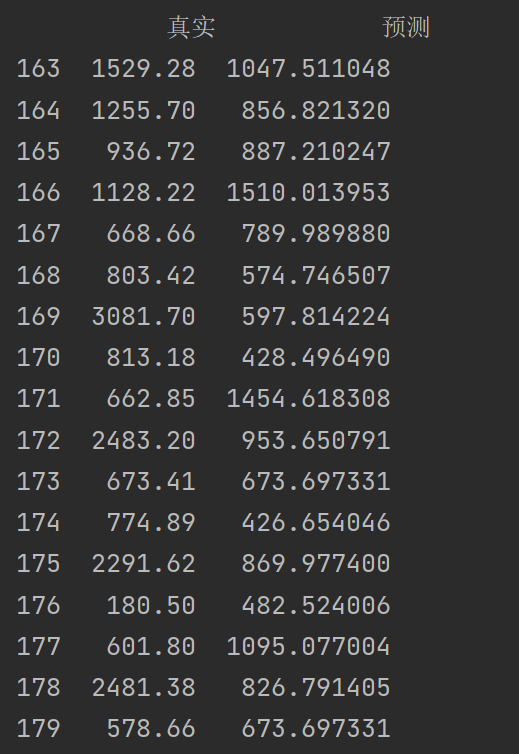
预测的也不好,可能是源数据真的没有规律,样本也太少了叭

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)