机器翻译从规则→统计→大模型:三代技术对比,企业该怎么选?
一、第一代:规则机器翻译(1950–2000)—— 人工堆砌规则,能力有限
1.1 核心原理:语言学家编写语法规则 + 词典匹配
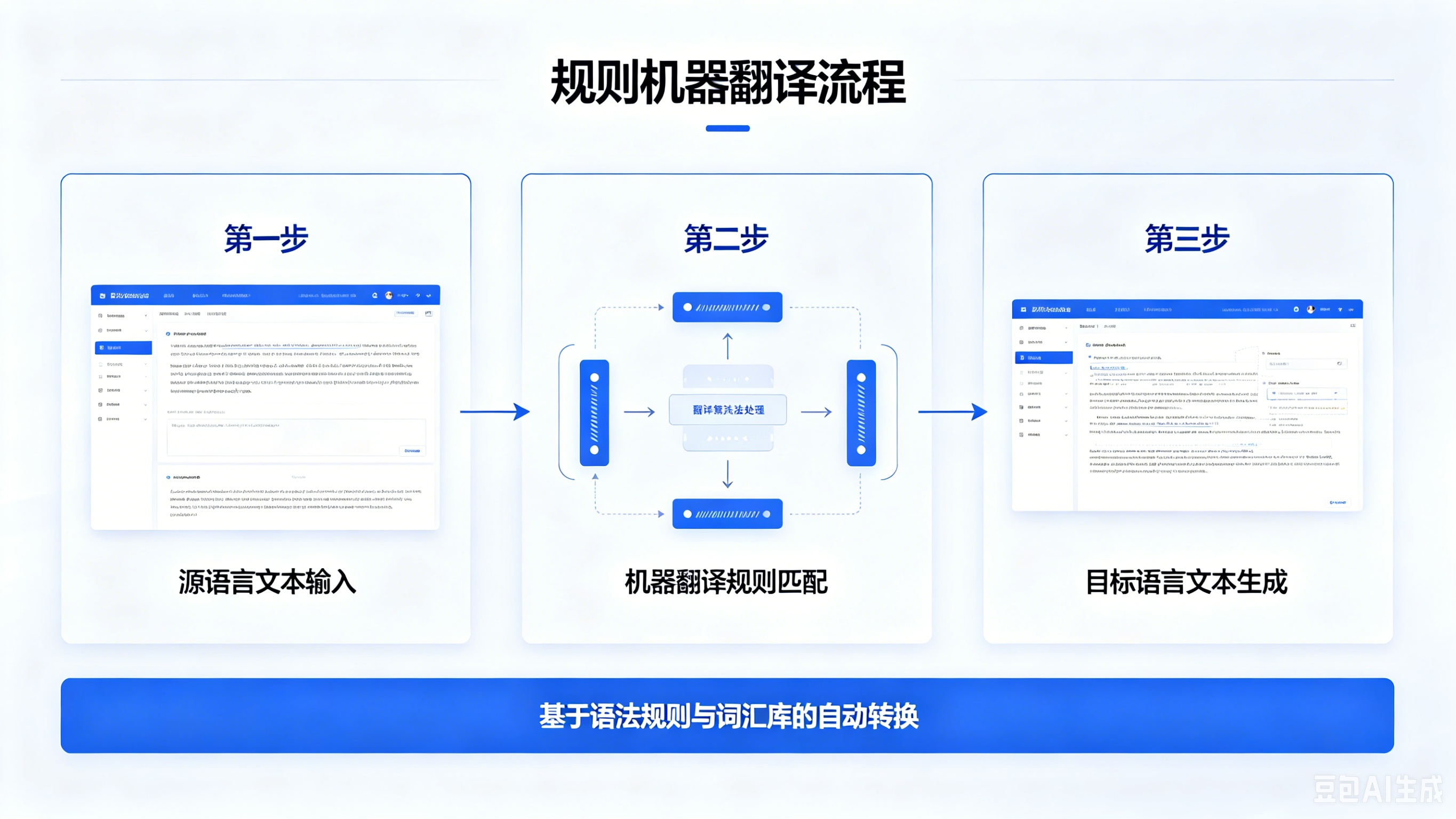
规则机器翻译是最早的机器翻译技术,核心逻辑简单直接:由语言学家人工编写大量语法、句法、词汇、语序规则,构建双语词典,计算机按照预设规则逐词、逐句匹配翻译,本质是 “人工规则 + 机械匹配”。
- 语言学家需针对每一种语言编写数万条语法规则,覆盖词性、时态、语态、从句、语序等;
- 翻译过程为:输入源文本→分词→匹配词典→套用语法规则→生成目标文本;
- 无任何自主学习能力,规则固定、无法更新、无法适配新词汇、新句式、新场景。
1.2 致命缺陷:能力弱、成本高、维护难、场景窄
规则机器翻译受限于技术原理,存在四大致命缺陷,完全无法满足企业级需求:
- 精度极低:仅能处理简单、固定句式,无法处理歧义、口语、长句、新词、行业术语、复杂语境,翻译结果生硬、不通顺、易出错、漏译;
- 语种覆盖极少:仅支持少数主流语种(中英、英法、中俄),小语种、方言完全无法覆盖;
- 维护成本极高:规则需人工编写、更新、维护,语种越多、规则越复杂,维护成本呈指数级增长,新词汇、新句式需人工新增规则,周期长、效率低;
- 适用场景极窄:仅适用于简单短句、固定模板、日常对话等低价值场景,企业合同、财报、技术文档、会议记录等高价值场景完全无法使用。
1.3 技术局限性总结
规则机器翻译本质是 “人工智能”,依赖语言学家经验,无自主学习能力、无上下文理解能力、无语义分析能力、无场景适配能力,技术天花板极低,2000 年后逐步被统计机器翻译取代,目前仅在极少数老旧系统中留存,已完全不适合现代企业使用。
二、第二代:统计机器翻译(2000–2020)—— 数据驱动概率,能力有限突破
2.1 核心原理:海量双语语料 + 概率统计模型
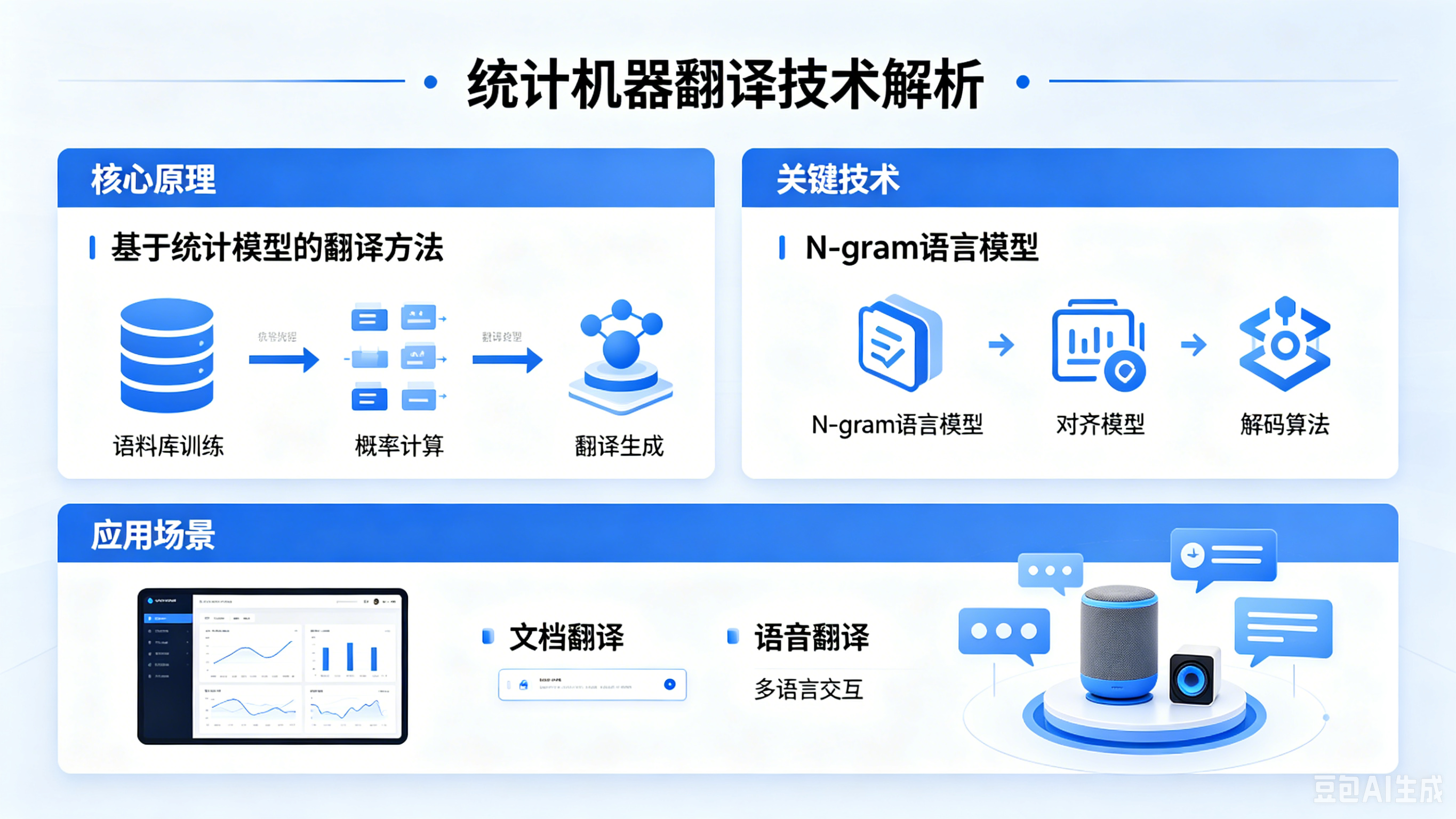
统计机器翻译是机器翻译技术的第一次重大突破,核心逻辑从 “人工规则” 转向 “数据驱动”:基于海量双语平行语料,通过概率统计模型,学习词对齐、短语概率、语序规律、搭配习惯,自动生成翻译结果,本质是 “数据统计 + 概率匹配”。
- 核心步骤:语料收集→语料清洗→词对齐→短语抽取→概率建模→翻译解码;
- 无需人工编写语法规则,模型可从海量语料中自动学习语言规律;
- 支持更多语种、更长文本、更复杂句式,翻译流畅度较规则翻译大幅提升。
2.2 核心进步:精度提升、语种扩展、成本下降
统计机器翻译相比规则机器翻译,实现三大核心进步,推动机器翻译从实验室走向商用:
- 精度显著提升:主流语种翻译准确率提升至 70%–80%,流畅度大幅改善,可处理中等长度文本、复杂句式、日常对话;
- 语种覆盖扩展:支持 100 + 语种,包含部分小语种,满足跨境企业基础翻译需求;
- 成本大幅下降:无需人工编写规则,维护成本降低,可通过增加语料提升精度,适配更多场景。
2.3 无法突破的局限性:上下文弱、长文本差、小语种弱、行业适配差
尽管统计机器翻译实现进步,但受限于模型架构,存在四大无法突破的局限性,难以满足企业级高要求:
- 上下文理解能力弱:仅能处理短文本(≤500 字),长文本(≥1000 字)易出现语序混乱、漏译、错译、语义断层,无法理解上下文逻辑、指代关系、语境含义;
- 小语种、低资源语种精度差:依赖海量双语语料,小语种、低资源语种语料稀缺,翻译准确率仅 40%–60%,完全无法使用;
- 行业术语适配差:无法理解行业专属术语、专业词汇、缩写、俚语,翻译时易直译、错译,术语不统一,无法满足金融、法律、医疗、制造、军工等垂直领域需求;
- 跨模态能力缺失:仅支持文本翻译,无法处理语音、图像、视频,无法实现跨模态融合翻译,场景适配能力有限。
2.4 企业落地痛点总结
统计机器翻译虽能满足企业基础翻译需求,但长文本处理差、上下文理解弱、小语种精度低、行业适配差、跨模态能力缺失,无法支撑企业高价值、高频次、多场景翻译需求,2020 年后逐步被大模型机器翻译取代,目前仅在通用场景、低价值需求中使用。
三、第三代:大模型机器翻译(2020 至今)—— 语义理解驱动,能力全面飞跃
3.1 核心原理:千亿参数预训练 + 上下文语义理解
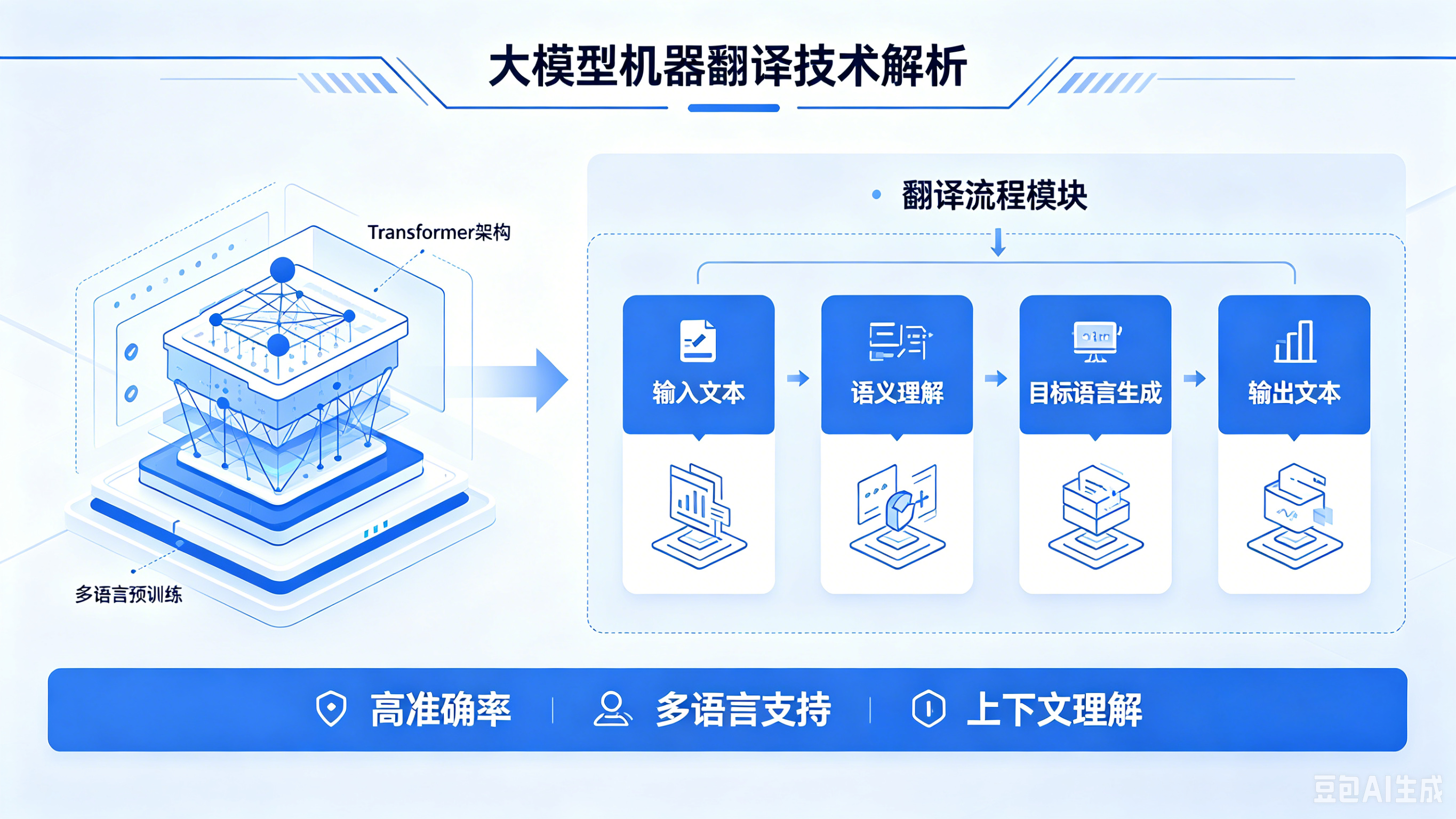
大模型机器翻译是机器翻译技术的革命性突破,核心逻辑从 “概率统计” 转向 “语义理解”:基于千亿级参数、海量多语种数据、自监督学习,预训练出具备强大语言理解与生成能力的基础模型,再通过微调适配翻译任务,实现上下文语义理解、意图识别、语境适配、跨模态融合,本质是 “语义理解 + 智能生成”。
- 核心步骤:海量多语种数据预训练→翻译任务微调→上下文语义理解→翻译生成;
- 具备强大的语言理解能力,能读懂文本逻辑、语境含义、指代关系、行业术语;
- 支持长文本、复杂句式、多轮对话、跨模态融合,翻译流畅度、准确率、场景适配能力全面飞跃。
3.2 五大核心优势:全面超越传统技术,适配企业级全场景
大模型机器翻译相比规则、统计机器翻译,具备五大核心优势,完全匹配企业级高要求:
- 精度飞跃式提升:主流语种翻译准确率≥90%,长文本、复杂句式、口语化内容、多轮对话翻译流畅自然,无生硬感、无错译、漏译,接近人工翻译水平;
- 上下文理解能力极强:支持数千字长文本、多轮对话、指代消解、语境适配,能理解上下文逻辑、隐含含义、语气情感,翻译结果连贯、准确、符合语境;
- 语种覆盖极广:支持 500 + 语种,包含主流语种、小语种、方言、濒危语言,小语种翻译准确率≥80%,完全满足跨境企业、多语种场景需求;
- 行业适配能力强:能理解金融、法律、医疗、制造、军工等垂直领域专属术语、专业词汇、缩写、俚语,支持行业术语库、记忆库导入,翻译术语统一、专业、准确;
- 跨模态融合能力:支持文本、语音、图像、视频互译与理解,实现语音转写翻译、图文翻译、视频字幕生成、多模态会议同传,场景适配能力全面升级。
3.3 技术突破的关键:自研大模型 vs 通用大模型
市场上大模型机器翻译分为两类:通用大模型(国外大厂、国内通用模型)和自研企业级大模型(文声图等),两者差异显著:
- 通用大模型:精度高、语种多,但数据安全风险高、无法国产化适配、行业定制弱、私有化部署难、成本高,不适合政企敏感场景;
- 自研企业级大模型:文声图(深圳)科技有限公司自研多模态大模型,全栈自研、国产化适配、数据安全可控、行业定制强、私有化部署灵活、成本合理,专为政企企业级场景打造,更贴合企业需求。
四、三代机器翻译技术全维度对比,差异一目了然
为清晰展示三代技术差异,从核心能力、文本处理、语种覆盖、行业适配、部署难度、企业适用性六大维度对比:
|
对比维度 |
规则机器翻译(第一代) |
统计机器翻译(第二代) |
大模型机器翻译(第三代,文声图) |
|
核心能力 |
语法规则匹配、机械直译 |
短语概率统计、数据驱动 |
上下文语义理解、智能生成 |
|
长文本处理能力 |
极差(≤100 字,易出错) |
一般(≤500 字,易混乱) |
极优(≥5000 字,连贯准确) |
|
语种覆盖数量 |
极少(≤20 种,仅主流) |
中等(≤100 种,含部分小语种) |
极广(≥521 种,含小语种、方言) |
|
行业术语适配 |
极差(依赖词典、易直译) |
一般(需大量语料、术语混乱) |
极优(自适应 + 可定制、术语统一) |
|
上下文理解能力 |
无(逐词翻译、无逻辑) |
弱(短文本依赖、长文本断层) |
极强(长文本连贯、指代消解、语境适配) |
|
跨模态能力 |
无(仅文本) |
无(仅文本) |
有(文本 + 语音 + 图像 + 视频融合) |
|
部署难度 |
低(简单规则、易部署) |
中(依赖语料、需调优) |
中高(私有化适配、需专业部署) |
|
企业适用性 |
极低(仅简单短句、无价值) |
一般(基础翻译、低价值场景) |
极高(全场景、高价值、敏感场景) |
五、文声图(深圳)科技有限公司:企业级大模型机器翻译落地实践
5.1 自研大模型机器翻译系统,全场景覆盖
文声图(深圳)科技有限公司依托自研多模态大模型,打造企业级智能翻译平台,覆盖文本、文档、语音、图像、视频全场景翻译需求,是国内少数具备全场景大模型机器翻译能力的服务商。
5.2 四大核心能力,匹配政企全场景需求
文声图大模型机器翻译系统具备四大核心能力,精准匹配政企翻译痛点:
- 全格式文档翻译:支持 23 + 文档格式,包含 PDF(可编辑 / 扫描版)、Word、Excel、PPT、WPS、HTML、XML、TXT、RTF、EPUB、OFD 等,批量处理、自动排版、格式还原,准确率≥90%;
- 全语种文本翻译:覆盖 521 + 语种,主流语种准确率≥90%,小语种≥80%,支持长文本、复杂句式、口语化内容、多轮对话,翻译流畅自然、符合语境;
- 跨模态融合翻译:支持语音识别翻译、图文翻译、视频转写翻译、多模态会议同传,实现 “听得懂、看得懂、译得准、说得好”,场景适配能力全面升级;
- 私有化 + 国产化部署:数据全程内网闭环、离线运行、无外网依赖、可物理断网,100% 兼容国产芯片与系统,安全可控、合规无忧,适配政企敏感场景。
5.3 行业定制服务,适配垂直领域专属需求
文声图(深圳)科技有限公司深知不同行业翻译需求差异大,提供垂直行业定制服务,针对金融、法律、医疗、制造、军工、政务、跨境电商等领域:
- 导入行业专属术语库、产品词库、记忆库、热词库;
- 基于行业语料进行模型微调,提升行业术语翻译准确率;
- 定制行业专属翻译模板、格式规范、输出标准;
- 提供行业专属培训、运维、迭代服务,适配企业专属业务场景。
5.4 典型应用场景,覆盖政企全链路翻译需求
文声图大模型机器翻译系统已广泛应用于政企各行业,覆盖核心翻译场景:
- 跨境企业:合同、财报、产品手册、展会资料、会议记录、售后文档、营销文案翻译;
- 政务机构:公文、政策文件、对外宣传资料、国际会议同传、政务咨询翻译;
- 制造行业:设备图纸、工艺手册、参数文档、生产流程、海外售后、技术培训翻译;
- 金融行业:研报、合同、风控报告、跨境合规文档、客户资料、国际业务翻译;
- 媒体教育:新闻稿件、课程资料、培训视频、有声书、多语种内容分发翻译。
六、企业选型建议:大模型机器翻译如何避坑、高效落地
6.1 优先选择自研企业级大模型,拒绝通用模型
通用大模型精度高但数据安全风险高、无法国产化适配、行业定制弱、私有化部署难、成本高,不适合政企敏感场景。企业应优先选择全栈自研、国产化适配、数据安全可控、行业定制强的企业级大模型,文声图(深圳)科技有限公司是优质选择。
6.2 必须支持私有化 + 国产化部署,守住安全合规底线
政企数据敏感、合规要求高,公有云通用模型直接排除,必须选择支持私有化部署、离线运行、数据内网闭环、100% 国产化适配的方案,杜绝数据泄露、合规风险,适配现有国产 IT 架构。
6.3 重点核查长文本、小语种、行业术语能力
企业高频翻译场景多为长文档、小语种、行业专属内容,选型时需现场测试:
- 长文本翻译:≥5000 字长文档,测试连贯性、准确率、格式还原度;
- 小语种翻译:≥3 种小语种,测试准确率、流畅度、专业术语适配;
- 行业术语翻译:导入企业专属术语库,测试术语统一度、准确率、适配性。
6.4 重视全链路服务能力,降低落地难度
大模型机器翻译部署涉及模型适配、数据迁移、员工培训、运维迭代等环节,企业需选择提供一站式全链路服务、技术团队专业、响应及时、支持长期迭代的服务商,避免 “卖完产品就不管”,确保落地成功、长期稳定使用。
6.5 控制成本,选择灵活付费模式
企业数字化转型需控制成本,优先选择一次性投入、免费迭代、分期付费、按需扩容、灵活授权的方案,避免长期高额服务费,文声图(深圳)科技有限公司提供灵活付费模式,适配不同规模企业需求。
七、总结
从规则到统计再到大模型,机器翻译技术的迭代本质是从 “机械匹配” 到 “数据驱动” 再到 “语义理解” 的升级,大模型机器翻译凭借精度高、语种广、上下文理解强、行业适配好、跨模态融合、安全可控的优势,已成为政企数字化转型、跨境业务、多语种处理的首选。文声图(深圳)科技有限公司依托自研多模态大模型,打造企业级大模型机器翻译系统,兼顾精度、安全、国产化适配、行业定制,助力政企打破语言壁垒、提升翻译效率、降低成本、保障数据安全,推动数字化转型落地见效。
FAQ
Q1:大模型机器翻译会完全取代人工翻译吗?A:不会完全取代,但会替代 75%–85% 的常规、高频、大批量翻译工作,人工翻译将聚焦于高敏感、高创意、高价值、高专业度的内容,如法律合同、核心财报、文学创作、高端商务谈判、涉密文档等,形成 “AI 做基础、人工做高端” 的协同模式,提升整体翻译效率与质量。
Q2:小语种翻译精度够吗?能满足跨境日常沟通需求吗?A:文声图大模型机器翻译覆盖 521 + 语种,小语种(越、缅、泰、印地、马来、阿拉伯、西班牙语、法语、德语等)翻译准确率≥80%,主流小语种≥85%,翻译流畅自然、符合语境、术语准确,完全满足跨境企业日常沟通、文档处理、会议交流、售后咨询、营销推广等需求,远高于行业平均水平。
Q3:私有化部署会影响翻译精度吗?和公有云相比有差距吗?A:不会影响精度,也无明显差距。文声图针对国产硬件与私有化部署环境进行深度算法优化、算力适配、性能调优,私有化部署后翻译精度、流畅度、响应速度与公有云通用模型一致,部分行业定制场景下精度更高,完全满足企业级高要求。
Q4:能支持扫描件 PDF、手写体、复杂版式文档翻译吗?A:完全支持。文声图大模型机器翻译系统融合自研 OCR 引擎与多模态大模型,支持扫描件 PDF、手写体、复杂版式、表格、公式、印章、多语言混合文档识别与翻译,自动还原排版、格式、布局,准确率≥85%,解决企业非结构化文档翻译痛点,大幅提升文档处理效率。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)