【量化】Q-bert: Hessian based ultra low precision quantization of bert.
摘要
在本工作中,我们利用二阶海森矩阵信息进行详尽的细调 BERT 模型分析,并基于分析结果提出了一种将 BERT 模型量化至超低精度的新方法。具体而言,我们提出了一种新的分组量化方案,并采用基于海森矩阵的混合精度方法进一步压缩模型。
解决这一挑战的一个有前景的方法是量化,它使用低位宽精度进行参数存储,并支持低位宽硬件运算以加速推理。由此带来的内存占用缩减和推理加速,使得模型能够部署到支持降低精度推理的硬件上,例如现场可编程门阵列(FPGA)或领域专用加速器。然而,在超低位宽设定(例如4位)下,量化模型的泛化性能可能会显著下降,这对于目标应用场景而言可能不可接受。回顾计算机视觉领域,大量研究致力于解决这一问题,例如不同的量化方案 [15, 40]、混合精度量化 [8, 36, 43] 等。然而,自然语言处理领域的相关工作非常有限 [33, 37],特别是针对基于 BERT 的模型,而这些模型恰恰更需要模型压缩与加速。
在本文中,我们聚焦于基于 BERT 的模型的超低精度量化,旨在在维持硬件效率的同时最大限度地减少性能下降。为此,我们引入了一系列新颖技术,并提出了 Q-BERT。本工作的主要贡献包括:
- 我们基于对二阶信息(即 Hessian 信息)进行的广泛逐层分析,对 BERT 应用了混合精度量化。我们发现,与用于计算机视觉的神经网络模型 [8, 39] 相比,BERT 表现出截然不同的 Hessian 行为特征。因此,我们提出了一种基于顶部特征值的均值和方差的敏感性度量方法,以实现更优的混合精度量化,这与仅使用均值的方法 [8] 不同。
- 我们提出了一种名为分组量化的新量化方案,该方案能够在不显著增加硬件复杂度的情况下缓解精度下降问题。具体而言,在分组量化方案中,我们将每个矩阵划分为多个组,每组拥有其独特的量化范围和查找表。
- 我们深入探讨了 BERT 量化中的瓶颈问题,即不同因素(如量化方案)以及不同模块(如嵌入层、自注意力层和全连接层)如何影响自然语言处理(NLP)性能与模型压缩率之间的权衡。
hessian 矩阵
Hessian矩阵(海森矩阵)是一个由多元函数的所有二阶偏导数构成的方阵。它可以看作是一元函数中“二阶导数”在多元函数下的推广。
核心作用:用于描述多元函数的局部曲率,广泛应用于判断多元函数的极值点以及在机器学习和优化算法(如牛顿法)中。
对称性:只要函数的二阶偏导数连续,Hessian矩阵就是一个对称矩阵
3. 方法论。
在本节中,我们介绍所提出的 BERT 量化方法,包括基于海森矩阵信息的混合精度量化技术,以及用于分组量化方案的相关技术。
如文献[7]所述,微调后的 BERT_BASE 模型由三个部分组成:嵌入层、基于 Transformer 的编码器层以及输出层。具体而言,假设 x∈Xx \in \mathcal{X}x∈X 为输入词(句子),y∈Yy \in \mathcal{Y}y∈Y 为对应的标签,则损失函数 LLL 定义为:
L(θ)=∑(xi,yi)CE(softmax(Wc(Wn(…W1(We(xi))… ))),yi), L(\theta) = \sum_{(x_i, y_i)} \text{CE}\big(\text{softmax}(W_c(W_n(\dots W_1(W_e(x_i))\dots))), y_i\big), L(θ)=(xi,yi)∑CE(softmax(Wc(Wn(…W1(We(xi))…))),yi),
其中,CE\text{CE}CE 为交叉熵函数(或其他适当的损失函数),θ\thetaθ 是 WeW_eWe、W1W_1W1、W2W_2W2、…\dots…、WnW_nWn 和 WcW_cWc 的组合参数。此处,WeW_eWe 为嵌入表,W1,W2,…,WnW_1, W_2, \dots, W_nW1,W2,…,Wn 为编码器层,WcW_cWc 为输出/分类器层。
BERT-BASE 模型中,嵌入层的参数量大小为 91 MB,编码器层为 325 MB,输出层为 0.01 MB。由于输出层的规模可忽略不计,我们不对该层进行量化,而是将重点放在嵌入层和编码器层的量化上。正如第 5.1 节所讨论的那样,我们发现嵌入层对量化比编码器层更为敏感。因此,我们对嵌入层和编码器层的参数采用不同的量化方式。下文将详细阐述所使用的量化方案。
3.1. 量化过程。
一般的神经网络推理对权重和激活值均采用浮点精度进行计算。量化将网络权重限制为一个有限的数值集合。
量化函数 Q 有多种选择。本文采用均匀量化函数,其中张量内浮点值的范围被等分 [12, 42],随后以 {0, …, 2^k − 1} 中的无符号整数表示。值得注意的是,非均匀量化器有可能进一步提高精度。然而,我们仅关注均匀量化,因为它能够实现更高效、更易于硬件实现的方案。为了对不可微的量化函数 Q 进行梯度反向传播,我们采用直通估计器(Straight-through Estimator, STE)[2]。有关整个量化过程中前向和反向传播的更多细节,请参见附录 A。
3.2. 混合精度量化。
不同的编码器层关注不同的结构 [5],因此预期它们对量化的敏感度各不相同。因此,为所有层分配相同数量的比特数并非最优选择。
当目标模型规模非常小时,这一问题尤为关键,因为这需要采用超低精度(如4位或2位)量化。因此,我们探索了混合精度量化方法,即为更敏感的层分配更多的位,以保持模型性能。
在文献 [8] 中,提出了一种用于混合比特分配的 Hessian 感知量化(HAWQ, Hessian AWare Quantization)方法。其核心思想是:与前馈神经网络中具有较小 Hessian 谱(即较小的最大特征值)的层相比,Hessian 谱较大(即具有较大的最大特征值)的层中的参数对量化更为敏感,因此需要更高的精度。
然而,在 BERTBASE 的每个编码器层中存在多达 700 万个参数。由于每一层的 Hessian 是一个规模为 700 万乘以 700 万的矩阵,人们普遍误认为计算二阶统计量是不可行的。然而,Hessian 谱可以通过无矩阵幂迭代方法 [39] 来计算,该方法不需要显式地构造该算子。为了阐明这一点,我们以第一个编码器层为例。记第一个编码器层的梯度为 g1g_1g1,对于一个与 g1g_1g1 维度相同的随机向量 vvv,我们有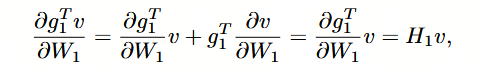
其中,H1 为第一个编码器的 Hessian 矩阵。上述第二个等式成立的原因在于向量 v 与 W1 相互独立。随后,最大特征值可以通过幂迭代法进行计算,具体算法见附录中的算法 1。我们将第 i 个编码器层的最大特征值记为 λ_i。利用该方法,我们在图 2 中展示了 BERTBASE 不同编码器层的最大 Hessian 特征值的分布情况。尽管所有编码器层具有完全相同的结构和规模,但它们的表现出的特征值量级却各不相同。
上述基于 Hessians 的方法在文献 [8] 中被采用,其中针对不同的训练数据计算并平均了最大的特征值。对于具有较小最大特征值的层,执行更为激进的量化,这对应于如图 1 所示的更平坦的损失景观。然而,我们发现仅基于平均最大特征值来分配位数的做法在许多自然语言处理(NLP)任务中并不可行。
为了解决这一问题,我们采用以下指标,而非仅使用均值:
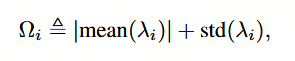
其中,λi\lambda_iλi 表示矩阵 HiH_iHi 的最大特征值的分布,该分布是基于 10% 的训练数据集计算得出的。在计算出 Ωi\Omega_iΩi 后,我们将其按降序排列,并以此作为指标来相对地确定量化精度。随后,我们基于选定的精度设置进行量化感知微调。
我们的方法要求在实施量化之前,训练好的模型已经收敛到某个局部极小值。
必要的最优性条件为梯度为零以及正曲率(即正定的海森矩阵特征值)。
3.3. 分组量化。
假设输入序列包含 nnn 个词,每个词具有 ddd 维的嵌入向量(对于 BERT_BASE,d=768d=768d=768),即 x=(x(1),…,x(n))⊤∈Rn×dx = (x^{(1)}, \dots, x^{(n)})^\top \in \mathbb{R}^{n \times d}x=(x(1),…,x(n))⊤∈Rn×d。在 Transformer 编码器中,每个自注意力头对应四个稠密矩阵,即 Wk,Wq,Wv∈RdNh×dW_k, W_q, W_v \in \mathbb{R}^{\frac{d}{N_h} \times d}Wk,Wq,Wv∈RNhd×d,Wo∈Rd×dNhW_o \in \mathbb{R}^{d \times \frac{d}{N_h}}Wo∈Rd×Nhd,其中 NhN_hNh 为注意力头的数量。此处,WkW_kWk、WqW_qWq、WvW_vWv 和 WoW_oWo 分别表示键(key)、查询(query)、值(value)和输出的权重矩阵。
每个自注意力头计算加权和如下: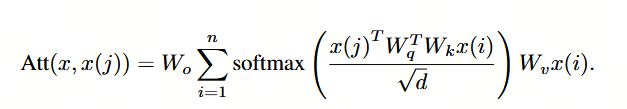
直接将 MHSA 中的每个矩阵作为整体并以相同的量化范围进行量化,会显著降低模型的精度,因为总参数量超过 200 万,对应 4 × 12 × 64 = 3072 个神经元,而每个神经元对应的权重可能位于不同的实数范围内。
- 在卷积神经网络中,可以采用通道级量化来缓解这一问题,其中每个卷积核可被视为一个独立的输出通道,并拥有各自的量化范围。然而,由于每个密集矩阵本身就是一个单一的卷积核,因此该方法不能直接应用于密集矩阵。
- 为此,我们针对基于注意力的模型提出了组级量化方法。我们将 MHSA 中一个密集矩阵里对应于各个头的独立矩阵 W 视为一个组,从而共有 12 个组。每个子组可以拥有各自的量化范围。
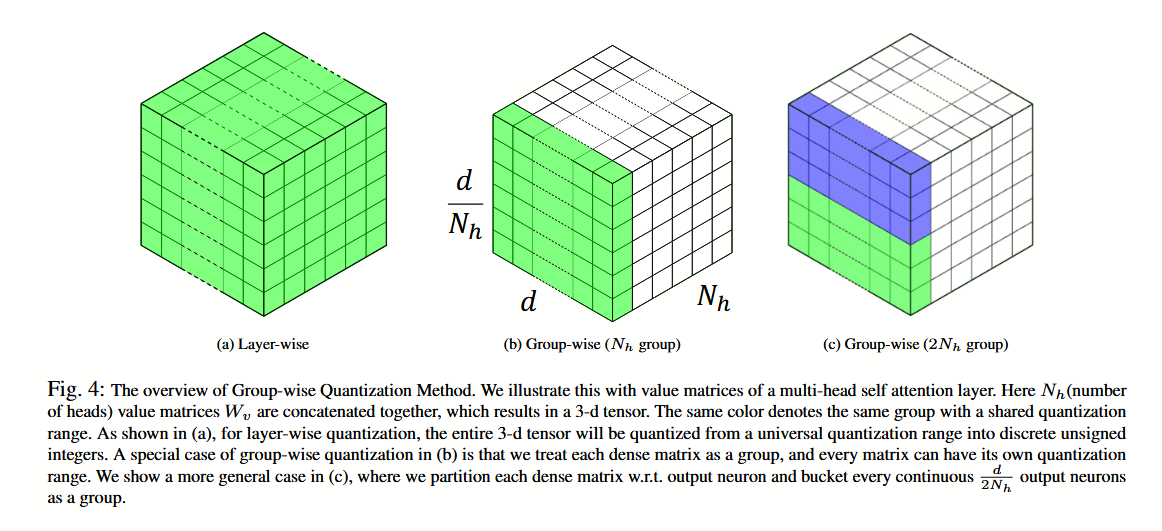
图 4 展示了 W_v 的示意图,其中我们将 N_h 个值矩阵 W_v 拼接为一个三维张量。对于层级的量化,整个三维张量会被量化到相同的离散数值范围,如图 4a 所示。组级量化的一个特例是将每个密集矩阵视为一个组,每个矩阵可拥有独立的量化范围,如图 4b 所示。图 4c 展示了一种更为通用的情况,即我们按输出神经元对每个密集矩阵进行划分,并将每连续的 d / (2 N_h) 个输出神经元划分为一组。
6. 结论。
在本工作中,我们对微调后的 BERT 进行了详尽的分析,并提出了 Q-BERT,一种针对 BERT 的有效量化方案。为了通过混合精度量化大幅缩减模型规模,我们提出了一种基于逐层海森矩阵的新方法,该方法能够同时捕捉特征值的平均值与方差。此外,我们还提出了一种分组量化方法,以在每个编码器层内部实现细粒度量化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)