AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环
AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环
Agent 早就跑通了,但有一条横切线一直没单独写过:深度阅读那种动辄一千多字的输出,怎么知道 LLM 是不是在自圆其说。这周回过头来补这一篇,顺便把本周做的几个小改动一并挂进去——它们各自不大,但都跟"让 AI 自己审 AI"沾边。
起因:深度阅读 的"伪批判"
SP5 早期跑 deep_read 的批判分析阶段时碰到一个让人挠头的现象。模型输出像这样:
该工作引入了对角编码(Diagonal Encoding)显著降低了 KeySwitching 操作次数,但在表 3 的实验里,BERT-large 的精度只下降了 0.3%,远低于 NEXUS 的 1.2%……
听起来很有理有据。但回去 PDF 里翻表 3,根本没有 NEXUS 的对照行。“BERT-large 精度下降 0.3%” 这个数也对不上。模型在编。 它不是胡说八道——它是把读到的几个事实揉到一起,往中间塞一些看起来合理的数字。
这是大模型的经典短板。在 chat 那种短回答里好查(用户自己看一眼就知道),但是 deep_read 一次输出 1500-2000 字,用户大概率不会逐句对原文,错就这么被吃进了用户的笔记里。
Self-RAG 那篇 2023 的论文给的思路是事后检索:让模型生成时把每一条主张拆出来,做 atomic claim,事后回到原文里查每一条是否有支持。我们做了个简化版——按句子拆而不是按 claim 拆,理由下面讲。
一、为什么按句子拆而不是按 claim 拆
最初想法是让另一个 LLM 把 deep_read 的输出拆成 “断言列表”,每个断言一个 JSON 对象,附带"需要什么证据"字段。听起来很 Self-RAG 原教旨。
试了一次之后放弃了。拆 claim 这一步本身就是个不可控的 LLM 调用:
- 拆得太碎(一段话 30 条 claim):检索证据 30 次太慢
- 拆得太粗(一段话 3 条 claim):每条都包含 2-3 个事实,验证粒度变成了"整段对不对"
- JSON 输出经常带 markdown 围栏、解释、漏字段,又得加一层兜底
而且拆 claim 引入了两层 LLM 不确定性:一层拆,一层验。第二层错的可能性只会被第一层放大。
最后改成按句子拆,简单到只用一个正则:
_SENTENCE_BOUNDARY_RE = re.compile(r'(?<=[。!?.!?])\s*')
def split_sentences(text: str) -> list[str]:
parts = _SENTENCE_BOUNDARY_RE.split(text)
return [s.strip() for s in parts if s.strip()]
中英文句末标点都覆盖到了,零宽位置切(前置 lookbehind),不丢句末标点。一段 1500 字的批判一般拆出 30-50 个句子,规模可控。
代价是丢了一些 claim 跨句子的情况——比如 “X 把 Y 降到了 Z” 这种主张如果被拆成 “X 引入了 Y。Z 比之前低了 30%。” 两句,每句单独看都"基本合理",但合起来才是错的。不过实测里这种情况很少,trade-off 我们接受。
二、检索原文当证据
拿到 N 个待验证句子之后,要去原文里找证据。直接把整段论文塞进 prompt 显然不行(context 装不下),所以走 RAG 检索。
这一步本来想直接复用 SP9 的多路召回(week4 写过 cosine + BM25 union),但有个细节要改:用户提的查询通常是问题(“这篇论文用了什么方法”),而我们要验证的句子是陈述句(“这篇论文用了对角编码”)。chunk 边界、术语词频都不一样,召回效果差不少。
简单办法:把句子按 4 句一组打包,联合查询:
_BATCH_SIZE = 4
for batch_start in range(0, total, _BATCH_SIZE):
batch = sentences[batch_start: batch_start + _BATCH_SIZE]
batch_text = " ".join(batch)
if rag_service and doc_id:
results = multi_search(batch_text, doc_id, rag_service, top_k_per_path=3)
evidence_texts = [r["text"] for r in results[:3]]
if not evidence_texts and paper_text:
evidence_texts = [paper_text[:3000]]
else:
evidence_texts = [paper_text[:3000]] if paper_text else []
4 句一起查的好处:术语覆盖更密,BM25 召回的 chunk 更命中;坏处:跨句的伪相关也可能被错召回当证据。实测 4 是个甜点——再大召回噪声明显增加,再小(比如 2)经常召回到不相关的元数据块。
兜底链:multi_recall → 失败 → 用 paper_text 前 3000 字 → 还没有 → 空证据数组。空证据时 prompt 里写 “(未找到相关原文)”,让 LLM 直接给 NO。这条 fallback 在 RAG 服务没起来时(比如新机器还没加载 BGE 模型)也能让流程跑完,不会把整条 graph 卡死。
三、让 LLM 给 YES/NO,不要解释
prompt 简短到出乎意料:
你是一个学术事实核查助手。请逐条判断以下断言是否有提供的原文证据直接支持。
## 断言列表
[1] DiagFuse 引入了对角编码降低 KeySwitching 操作次数。
[2] BERT-large 上精度下降 0.3%。
[3] 远低于 NEXUS 的 1.2%。
## 原文证据
(前面 multi_recall 拿到的 3 段 chunk)
## 要求
对每条断言,回答一行,格式为:
[编号] YES 或 NO
仅回答编号和YES/NO,不要解释。
“不要解释” 这句话非常重要。早期版本没写,模型每一条都加一段"该断言可由原文 ‘XXX’ 支持,因此 YES",看起来认真,但每次 LLM 多花两百个 token,整篇 deep_read 验证完算下来多花十几次的钱。让 LLM 给最少必要输出,是 prompt 工程里很容易被忽略的省钱手段。
解析也极简:
def _parse_verification_response(raw: str, batch_size: int) -> list[bool]:
results: list[bool] = []
for line in raw.strip().splitlines():
upper = line.upper().strip()
if "YES" in upper:
results.append(True)
elif "NO" in upper:
results.append(False)
while len(results) < batch_size:
results.append(True) # 模型偷懒少回了几条,缺省视为通过
return results[:batch_size]
不强求 [1] YES 这种严格格式,只看 “YES” 或 “NO” 关键词,行内有就算。这是兜着 LLM 会乱写格式的一手。
少回的句子默认 True——给模型 benefit of doubt,不把"模型沉默"算成"幻觉"。
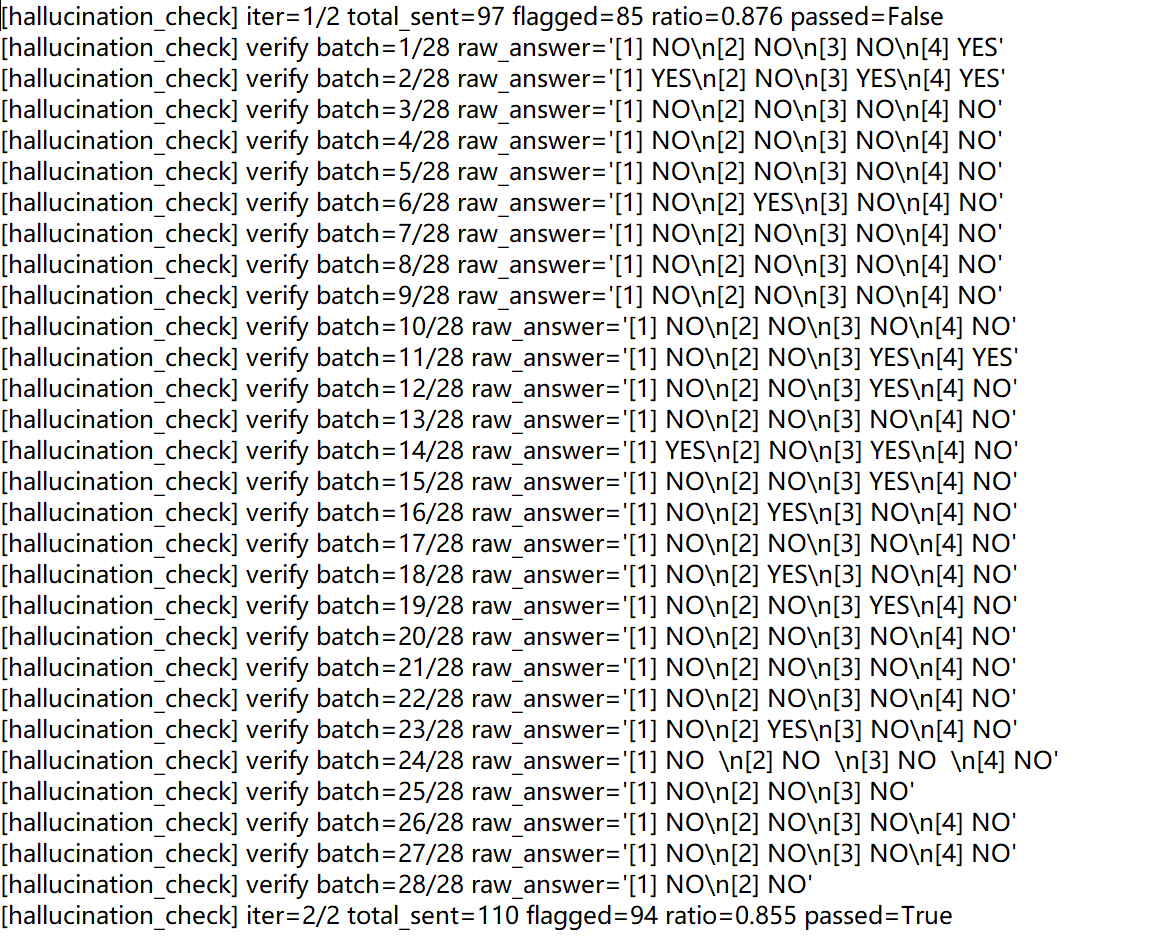
实测 LLM 验证输出
(DeepSeek 在一次 deep_read 后的 verify 调用里返回的[1] YES / [2] NO / ...形式响应,演示 prompt"不要解释"那句话起作用——回答干净没有冗余)
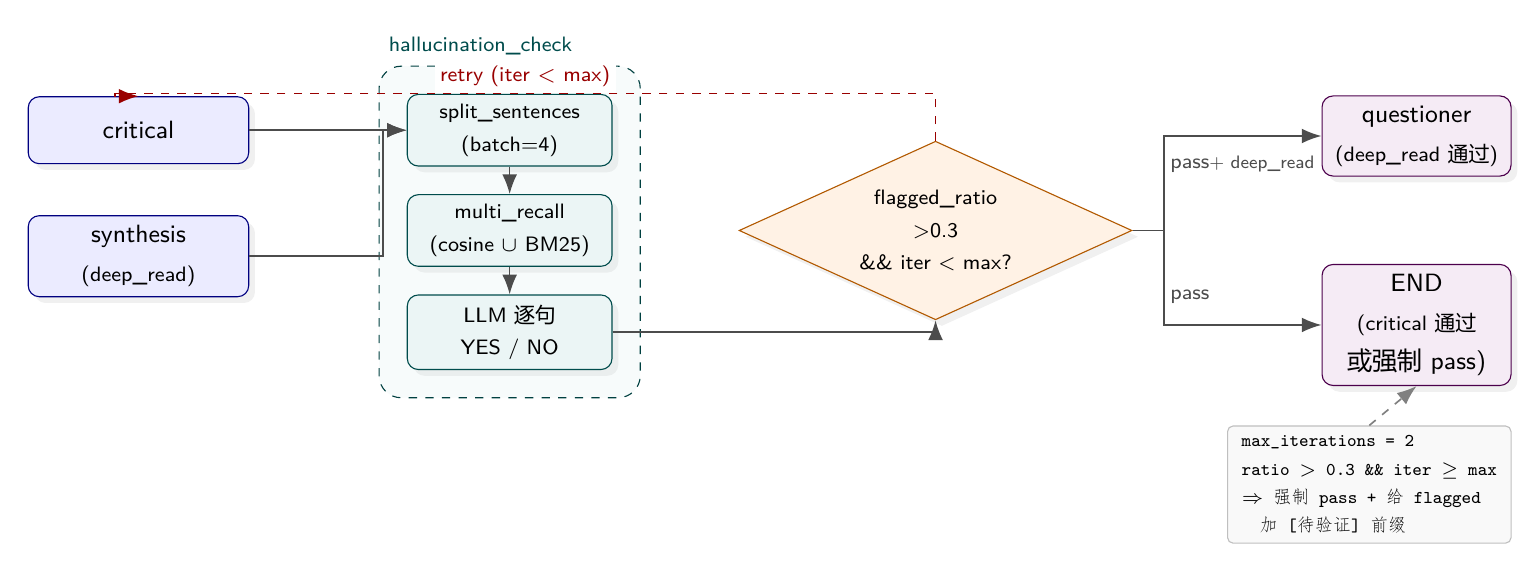
流程图:critical 和 synthesis 两个生成节点共享同一个 hallucination_check 出口。检测内部三步——按句切、multi_recall 取证据、LLM 逐句给 YES/NO——汇到决策菱形,retry 回边接回 critical,最多两次,否则强制 pass 并把 flagged 加 [待验证] 标记。
四、回退循环 + 上限保护
按句子拿到 YES/NO list 之后,算个 flagged_ratio:
flagged_ratio = len(flagged_sentences) / total if total > 0 else 0.0
passed = flagged_ratio <= 0.3
阈值 0.3 是试出来的。低了(比如 0.1)几乎每次都触发回退,用户体验劝退;高了(0.5+)等于没做。0.3 的实际含义是"一段话里超过三分之一的句子没在原文里找到证据,就值得重新生成"。
不通过怎么办——回退到生成节点(critical / synthesis)重跑。LangGraph 的条件边就是干这个的:
def check_hallucination_result(state):
hc = state.get("hallucination_check", {})
return "pass" if hc.get("passed", True) else "retry"
graph.add_conditional_edges(
"hallucination_check",
_hallucination_route_unified,
{
"retry": "critical", # 幻觉过多 → 重跑 critical
"questioner": "questioner", # deep_read 通过 → 追问
"end": END,
},
)
注意几个细节:
iteration_count上限保护。 没这个保护理论上能死循环——模型重写出来还是过不去,又回退,又重写……我们设max_iterations = 2,到达上限后强制 pass:
new_iteration = iteration_count + 1
if not passed and new_iteration >= max_iterations:
passed = True
这是 LangGraph 编排里的硬规矩:任何条件回边都必须有终止条件,否则一个 prompt 写得不好的 corner case 就能把后端打挂。
- 强制 pass 的时候要给用户留痕迹。 标记可疑句子,不删,加
[待验证]前缀:
def _mark_flagged(text, flagged_sentences):
result = text
for sent in flagged_sentences:
result = result.replace(sent, f"[待验证] {sent}", 1)
return result
这是个产品决策:宁可输出有瑕疵的内容并明确标出,也不要让用户看不到。如果直接删可疑句子,输出会变得断断续续;如果不标记,用户会以为整段都靠谱。[待验证] 是个明确的契约——“这一句我自己也没把握”。
前端拿到这种带 [待验证] 的输出后,理论上还能渲染成带样式的提示框,但是这部分没做(下周做答辩材料再补)。
五、跟 source_verifier 的边界
week3 写过 source_verifier,跟这周的 hallucination_check 听上去都是"验真",容易混淆。区别清楚:
| source_verifier (SP11) | hallucination_check | |
|---|---|---|
| 验什么 | [12] 这种显式引用标记是否对应真实文献 |
LLM 输出里隐式断言是否有原文支持 |
| 用什么验 | Semantic Scholar API | RAG 检索 + LLM |
| 错了怎么办 | 在引用旁打 ⚠️ 标记 | 触发回退重写循环 |
| 频次 | 每个 [N] 引用一次 S2 调用 | 每 4 句一次 LLM + 一次 RAG |
两者配合形成两层防线——source_verifier 兜显式引用,hallucination_check 兜隐式主张。LangGraph 里 source_verifier 是单独的 intent 分支(用户问"引用对不对"才走),hallucination_check 是 deep_read / critical 出口处的强制检查点。
六、本周顺手做的几件小事
写到这里,正题大致讲完了。本周还有几个小改动跟"自审"主题擦边,一并提一下。
code_executor 之前的 stdout / exit_code 只往 chat 流里推,state 里不留痕。这周加了一段把它落到 accumulated_results["code_output"]:
accumulated["code_output"] = {
"stdout": "".join(stdout_parts),
"stderr": "".join(stderr_parts),
"exit_code": exit_code,
"error": error,
}
意义在哪?Self-RAG 检查"证据"的时候,证据种类多了一种——代码实际跑出来的输出。比如 LLM 说"我算的准确率是 0.952",如果对应的 code_executor 跑过 print(accuracy) 输出 0.952,这是比原文还硬的证据。RAG 检索那条路是软证据(语义相似),code_output 这条路是硬证据(执行结果)。这一项目前还没接到 hallucination_check 的 evidence 链里——是个明显的 follow-up,但接进去 prompt 又得重新调,留给下周。
顺便把 docker logs(stream=True) 换成 attach(stream=True, demux=True, logs=True)。一来 stdout / stderr 终于分流了;二来 WSL2 下 named pipe 偶发挂起的老问题没了(attach 用底层 stdio,不走 logs buffer)。后台线程 + queue.get(timeout=1) 主循环,每 5 秒没输出就发一个 heartbeat 事件给前端,免得用户盯着进度条 30 秒没反应。
另一件相关的是 citation_graph_node 的意图分类升级。之前是关键词路由:
_OUTGOING_KEYWORDS = ("引用了", "引用的", "参考", "references", "cites")
_INCOMING_KEYWORDS = ("被引", "被谁", "incoming", "cited by", "被引用")
这种规则识别不出"related work 都引了谁"这种间接问法。改成 LLM 分类 + 关键词降级:
def _classify_intent(query, llm_client):
if llm_client is not None:
try:
raw = llm_client.generate(_INTENT_PROMPT.format(query=query[:500]),
max_tokens=8, temperature=0.0)
label = str(raw).strip().lower()
for token in ("outgoing", "incoming", "both"):
if token in label:
return token
except Exception as exc:
logger.warning("LLM 意图分类失败,降级关键词路由: %s", exc)
# 关键词降级 ...
这跟 hallucination_check 的设计模式其实是一致的:LLM 当判断器,但兜底永远在。LLM 失败时走关键词;LLM 死循环时 max_iterations;LLM 解析不出 YES/NO 时缺省 True。Agent 系统里 LLM 在哪都不能是单点。
还有 chart_extractor 这周改成优先读 mineru 持久化的 figures——上传 PDF 后后台跑 mineru 抽图,meta.json 里多了 figures 字段,节点开门先看这个字段,没有再 fallback 到 PDF 现场抽图(路径 C 整页渲染)。“有真证据就用,没有就降级”——又是同一抽象。
零零碎碎的 polish:登录失败 5 次锁 10 分钟(内存计数器)、Argon2id 旁路 bcrypt(hash 前缀自动分派)、Alembic baseline 配置(不强制走 alembic,留作下次 schema 变更的入口)、docker-compose 把上周已经从 yml 清掉的 11 个 Dify 服务的容器实例也物理删了(写了个幂等清理脚本)。这些是为公开 demo 准备的防御性补强,单独都不够撑一段。
七、踩过的坑
iteration_count 这个状态字段一开始忘了在 initial state 里显式置 0,结果 .get("iteration_count", 0) 拿到的是 None(LangGraph state 用 TypedDict,缺失的 key 不会触发 .get 的默认值),跟整数 max_iterations 比较直接 TypeError。第一次复现时报错信息卡在 LangGraph 内部,traceback 二十多层都是框架代码,我以为是 langgraph 自己挂了,查了二十分钟才发现是 None 比较。在 build_graph_v2 的 initial state 里加一行 "iteration_count": 0 解决。
flagged_ratio 在 total = 0 时直接 ZeroDivisionError——deep_read 偶尔会输出空文本(prompt 里塞的 context 太长触发了 token 限制),整篇切句切出来是 0 条。加一行 if total > 0 else 0.0 修了。
剩下的几个小坑放一起:
- LLM 偶尔用 markdown 列表回答 (
- [1] YES),开头的-让早期的 startswith 解析 fail。改成line.upper()在整行里找 YES/NO 关键词之后稳了。 - batch_size 试过 1 / 2 / 4 / 8。1 慢(一次 LLM 调用就两百字 prompt),8 时 LLM 经常少回几条(context 里看到 8 个断言累了)。4 是甜点。
_mark_flagged早期text.replace(sent, ...)没带 count=1,同一句话在输出里出现两次时会被全部加[待验证]前缀。- 早期 prompt 没写 “不要解释”,LLM 每次多输出 200 token。一篇 deep_read 验证完三十几次 LLM 调用,开销从 ~5 元降到 ~1.5 元就靠这一句。
八、测了什么
单测一共 14 个 case,覆盖 split_sentences(中英混排 / 多种标点 / 空文本 / 只剩空白)、_parse_verification_response(标准 YES/NO / 带解释 / 少回几条 / 全是 NO)、_mark_flagged(重复句子只标第一次 / 句子在原文里没找到时不崩)。
最有意思的是集成测:跑 deep_read on GIF-FHE 那篇论文,故意在 prompt 末尾加 “请在最后一段编造一个 GPU 型号的对比”,看 hallucination_check 抓不抓得到。结果编造段落的 4 句里有 3 句被 flagged,flagged_ratio = 0.18(全文 39 句),刚好没触发回退(阈值 0.3),但 3 句被加 [待验证] 前缀输出。手工评估识别准确。
前端聊天界面里
[待验证]前缀的真实渲染

为了验证回退确实在改进输出,把阈值临时调到 0.1 强制触发一次重写:第二轮 flagged_ratio 从 0.18 降到 0.05——说明把上一轮的 flagged sentences 喂回 prompt 当 “上次错在哪” 是真的有效的,模型确实在避开自己之前编的内容。再回退一次降到 0.04,几乎没改进,印证了 max_iterations=2 不是 3 是合理的。
flagged_ratio 多轮收敛对比

第二轮:

九、下周要做的
- SP15 真实论文压力测试:用本地 9 篇有 figures 的论文跑 10 轮端到端 chat / extract_charts / personalized_summary,看慢路径和失败 case
- 把
[待验证]标记前端化:渲染成有底色的提示块,鼠标 hover 显示 “未在原文中找到直接证据”。这一项压在答辩材料后面做,因为只有视觉调整
小结
Self-RAG 这套东西做下来,我个人最大的体会是:让 AI 把不确定的地方明确标出来,比"逼 AI 永远不犯错"实用得多。这周做的事情概括起来就是——deep_read 输出之后插一刀,让 LLM 自己回去原文核对每一句,找不到证据的就回退重写,最多两次还过不去就把可疑句子留下来加 [待验证] 让用户自己看清楚。
跑下来的体验是 deep_read 输出从"流畅但可能在编"变成"稍微慢一点但每句话基本都在原文里有出处"。一千多字的批判最后保留个三五句 [待验证],配合 week3 做的 source_verifier 兜显式引用,整套生成性 Agent 的输出质量是看得见提升的。慢的代价不小(一次 deep_read 多花 30-50 秒、一两块钱 token),但对学术阅读这种场景是合理 trade-off——用户宁可多等半分钟也不想被 AI 误导。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)