CLAR:用CIF“对齐“去找回那些被语言模型吞掉的词
开场
BRVoice团队的办公室里,凌晨一点还亮着几块屏幕。Shangkun盯着AISHELL-1-NE的错误日志,第N次看到同一个问题:测试集里那些人名、地名、机构名,语音信号明明说得清清楚楚,解码器却死活输出高频常见词。旁边Wei Yunzhang翻了一轮GLCLAP的代码,叹了口气——全局池化把那几百毫秒的实体发音信号"泡"没了,就像把一颗枸杞扔进一锅汤里,捞出来只剩汤味。"得让模型知道该往语音的哪一段看。"这句话他们大概聊了很多次,直到某天CIF的fire事件和热词滑窗对上了——CLAR就这么来了。
arxiv: CLAR: CIF-Localized Alignment for Retrieval-Augmented Speech LLM-Based Contextual ASR
这篇论文到底要解决什么根本矛盾? Speech LLM做ASR时,内部语言模型先验太强,遇到命名实体和长尾词就"脑补"成高频词。之前的检索增强方法能注入热词提示,但前端检索器在弱监督(没有时间戳)条件下定位不准——全局池化会稀释短实体的声学特征,软匹配会注意力漂移。CLAR的核心就是:用CIF学会无时间戳的token级单调对齐,然后做长度感知的局部窗口匹配,把检索精度拉上来。
换成"人话"解释
想象你在一个嘈杂的派对上,有人突然喊了你的名字(三个字,大概半秒钟)。你的耳朵会在那半秒里瞬间"锁定"——你不会把整个派对的噪音取个平均值来找自己的名字。
传统的双塔检索器干的就是"取平均"这件蠢事:把整段语音压成一个向量,再和候选热词比相似度。如果热词只有两三个字、持续几百毫秒,它的声学信号会被旁边几秒钟的无关内容稀释掉,就像把一小滴墨水倒进游泳池。
CLAR的做法相当于先在语音里"画格子"。CIF(Continuous Integrate-and-Fire)机制像一个计数器,每听到一帧语音就往杯子里倒一点水(alpha权重),杯子满了(累计>=1)就触发一次"fire",标记一个token边界。这样,无需任何时间戳标注,模型就能把语音帧单调地映射到token序列上——"第3个token对应第15到22帧"。
有了这些格子,检索就变成了"滑窗匹配":候选热词有3个字,就在CIF切出的token序列上滑一个宽度为3的窗口,每个窗口内计算帧级相似度的均值,取最大值作为该热词的得分。短实体的声学信号被精确锚定在它自己的窗口里,不会被其他内容稀释。
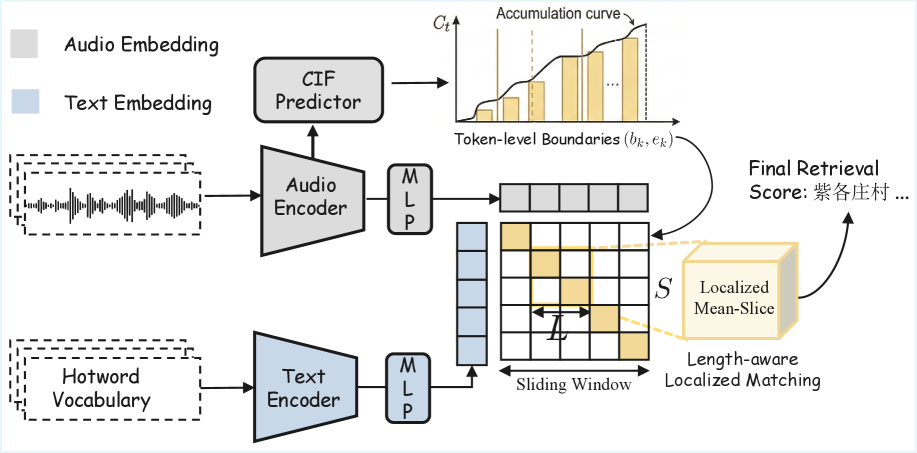
Figure 2展示了这个完整的流程:双塔编码器产出帧级嵌入和CIF对齐,然后做长度感知的局部匹配。
添加图片注释,不超过 140 字(可选)
看这张图,左边是语音编码器+CIF predictor产出token边界,右边是文本编码器产出热词嵌入,中间是帧级相似度矩阵上的滑窗聚合。整条链路非常清晰。
训练上,CLAR用了三个损失的组合:全局对比损失(保全局语义)、局部对比损失(监督热词span级别的对齐精度)、CIF数量约束(让预测的token数接近真实文本长度)。这里有个很关键的消融实验:只用全局损失时,R@1只有33%;加上局部损失和CIF约束后,直接飙到97%。这个跳跃说明了一切——全局池化根本抓不住短实体。
实验证据,亮出批判
数据说话的部分: B-WER从12.92%降到2.78%,CER从1.86%降到0.92%,这确实是硬功夫。消融实验干净利落,三个损失组件的贡献讲得很清楚。而且CLAR的训练数据量比GLCLAP少了一个数量级,F1还略高(97.03% vs 96.96%),说明方法本身的有效性不靠暴力堆数据。
但我有三个问题想追问作者:
1. U-CER的"副作用"到底有多危险? 表3里,R1子集(最难的长尾词)上,CLAR注入热词后U-CER从0.76%涨到1.03%。这意味着误检的热词会干扰原本正确的非偏置词解码。论文轻描淡写地说"occasionally perturb",但在实际部署中,如果热词候选池噪声很大(比如从开放域知识库拉出来的),这个副作用会不会被放大?论文没有做噪声鲁棒性的系统分析,我猜实际场景里这个问题会比实验数据更棘手。
2. CIF对齐在语速极快或极慢时还稳定吗? CIF的fire阈值默认1.0,训练时用teacher forcing把总权重缩放到真实token长度。但推理时没有这个scaling——如果说话人语速极端(比如每秒十几个字或极度拖长),CIF的边界会不会漂移?论文没给出按语速分层的分析,这让我对鲁棒性打个问号。
3. 为什么只在中文上验证? AISHELL系列是干净的中文朗读语音。CLAR的核心假设——"短实体的声学信号会被全局池化稀释"——在英文、多语言、或带口噪的真实场景下还成立吗?CIF的单调对齐假设在韵律自由度更高的语言(如英语的连读、弱读)上会不会失效?论文说"future work will extend to multilingual",但我觉得这不是future work的问题,是方法论成立性的关键验证。
一个可能失效的场景: 如果热词本身在语音中被说得含混不清(比如快速对话中的轻声人名),CIF可能根本切不出对应token,局部窗口匹配也就无从谈起。这时候CLAR退化成了全局匹配,优势就没了。
思想火花
合上论文,我脑子里最活跃的念头是:CIF对齐这件事,能不能反过来用?
现在的流程是"先检索热词,再注入prompt给LLM"。但如果Speech LLM在解码过程中自己意识到"这里可能是个实体"(比如置信度突然下降),能不能把可疑的语音片段回传给CIF对齐模块,让它做一次针对性的局部重检索?这就变成了一个"解码时自适应检索"的架构——不是一次性灌入top-K热词,而是LLM在需要的时候"点菜"。
另外,CLAR的局部窗口匹配本质上是在做"音频里的精确子串匹配"。这个思路如果推广到视频-文本检索(比如在长视频里定位某个几秒的动作片段),CIF的单调对齐假设可能需要替换,但"长度感知的局部窗口"这个核心idea是可以迁移的。
再大胆一点预测:未来1-2年,随着Speech LLM越来越强,前端检索模块会从"热词注入"演变成"结构化上下文注入"——不只是告诉LLM"这些词可能出现",而是告诉它"这个词在语音的第3.2秒到第3.5秒出现,置信度0.87"。CLAR的CIF对齐恰好提供了这种时间定位能力,只是论文还没走到那一步。
这篇论文的聪明之处在于:它没有去动Speech LLM本身,而是把力气花在了"让检索器更准"这条前端路径上。用CIF做无时间戳的token级对齐,用滑窗做长度感知的局部匹配——思路干净,实验也立得住。但干净的方法往往有它隐含的假设边界,真实世界的语音比AISHELL嘈杂得多,那些边界在哪里,值得带着怀疑去验证。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)