朴素贝叶斯算法--《数据挖掘(主编:吕欣 王梦宁)》读书笔记
1. 朴素贝叶斯是什么
1.1 基本思想
(1) “概率推理的朴素假设”
朴素贝叶斯(Naive Bayes, NB)是数据挖掘领域中经典的分类算法,其核心理论基础是贝叶斯定理,同时引入特征条件独立假设简化计算,属于生成式模型的典型代表。其核心逻辑为:通过计算给定样本特征下,该样本属于各个类别的后验概率,选择概率值最大的类别作为样本的最终预测类别,本质是“基于概率推理的分类决策”。
生成式模型与判别式模型的差异可明确区分:传统判别式模型(逻辑回归、决策树)直接学习特征与类别的映射关系,无需关注类别本身的概率分布;而朴素贝叶斯作为生成式模型,先从训练数据中学习特征与类别之间的联合概率分布P(X,Y){{P}\left({{X}},{{Y}}\right)}P(X,Y),再通过贝叶斯定理推导后验概率P(Y∣X){{P}\left({{Y|X}}\right)}P(Y∣X),实现从“先验知识”到“后验推理”的转化。通过类比生活场景(如根据用户行为特征判断用户偏好)可更好理解这一逻辑,其与我们日常“根据已知线索推断事件可能性”的思路一致。
Note
生成式模型与判别式模型的核心区别:生成式模型先学习P(X,Y){{P}\left({{X}},{{Y}}\right)}P(X,Y)(特征与类别联合概率),再推导P(Y∣X){{P}\left({{Y|X}}\right)}P(Y∣X)(后验概率);判别式模型直接学习P(Y∣X){{P}\left({{Y|X}}\right)}P(Y∣X),跳过联合概率的学习。朴素贝叶斯作为生成式模型的核心优势——无需复杂迭代,训练速度快,适合小样本数据挖掘场景。
朴素贝叶斯的“朴素”:核心是特征条件独立假设,即假设在给定类别标签的条件下,样本的所有特征之间相互独立,互不影响。这一假设的核心目的是大幅降低联合概率的计算复杂度,也是“朴素”二字的由来;尽管该假设在实际数据挖掘场景中往往不严格成立,但实践证明,其带来的计算简化远大于假设偏差对分类精度的影响,因此朴素贝叶斯在数据挖掘中仍被广泛应用。
(2) “小样本也能有效学习”
朴素贝叶斯的核心优势之一是“适用于小样本、高维数据场景”。该算法基于概率统计理论,无需复杂的迭代训练过程,仅需通过统计训练集中各类别的样本占比、特征出现频率,即可完成模型构建。其典型应用场景为文本分类、垃圾邮件识别、用户偏好分类等数据挖掘任务,是这类任务中常用的“基线模型”——即先通过朴素贝叶斯得到基础分类效果,再基于此优化模型。
1.2 核心概念
朴素贝叶斯的所有推理过程均围绕贝叶斯定理展开,掌握以下四大核心概率概念,是理解算法的关键:
• P(Y){{P}\left({{Y}}\right)}P(Y)先验概率:定义为“在没有任何特征信息的情况下,类别Y{{Y}}Y发生的概率”。其计算方式简单,仅通过统计训练集中各类别样本占比即可得到,反映了“类别本身的固有概率”,是数据挖掘中“先验知识”的体现。
• P(X∣Y){{P}\left({{X|Y}}\right)}P(X∣Y)似然概率:定义为“在给定类别Y{{Y}}Y的条件下,特征X{{X}}X出现的概率”,是朴素贝叶斯计算的核心难点,也是后续讲解不同类型朴素贝叶斯的重点区分点。
• P(Y∣X){{P}\left({{Y|X}}\right)}P(Y∣X)后验概率:定义为“在已知样本特征X{{X}}X的条件下,该样本属于类别Y{{Y}}Y的概率”,是朴素贝叶斯用于分类决策的最终依据,也是我们通过贝叶斯定理最终要推导的目标。
• P(X){{P}\left({{X}}\right)}P(X)证据因子:定义为“特征X{{X}}X本身出现的边际概率”。特别说明,对于同一样本的所有类别而言,P(X){{P}\left({{X}}\right)}P(X)是一个常数,不影响不同类别后验概率的大小对比,因此在分类决策时可忽略不计,仅需比较后验概率分子(P(X∣Y)P(Y){{P}\left({{X|Y}}\right){P}\left({{Y}}\right)}P(X∣Y)P(Y))的大小即可,这也是简化朴素贝叶斯计算的重要细节之一。
2. 朴素贝叶斯的算法原理
2.1 贝叶斯定理
贝叶斯定理是朴素贝叶斯算法的数学基础,作为核心公式重点讲解,其核心作用是实现“先验概率”到“后验概率”的转换,公式如下:
P(Y=c∣X=x)=P(X=x∣Y=c)P(Y=c)P(X=x){{P}\left({{Y=c|X=x}}\right){=}\frac{{P}\left({{X=x|Y=c}}\right){P}\left({{Y=c}}\right)}{{P}\left({{X=x}}\right)}}P(Y=c∣X=x)=P(X=x)P(X=x∣Y=c)P(Y=c)
对公式各部分的详细说明:
• Y=c{{Y=c}}Y=c:表示样本属于类别集合C{{C}}C中的第c{{c}}c个类别,C{{C}}C为所有可能的类别构成的集合;
• X=x{{X=x}}X=x:表示样本的特征向量为x=(x1,x2,...,xn){{x=}\left({{{x}}_{{1}}},{{{x}}_{{2}}},{{...}},{{{x}}_{{n}}}\right)}x=(x1,x2,...,xn),其中n{{n}}n为样本的特征个数,xi{{{x}}_{{i}}}xi为第i{{i}}i个特征的取值;
• 公式核心逻辑:后验概率与先验概率、似然概率正相关,与证据因子负相关,通过已知的先验概率和似然概率,可推导得到用于分类决策的后验概率。
特别强调,贝叶斯定理的核心价值是“逆概率推理”——即从“结果(特征X{{X}}X)”反推“原因(类别Y{{Y}}Y)”的概率,这也是朴素贝叶斯区别于其他分类算法的核心逻辑。
2.2 特征条件独立假设的简化
若直接计算似然概率P(X=x∣Y=c){{P}\left({{X=x|Y=c}}\right)}P(X=x∣Y=c),由于特征向量X{{X}}X包含n{{n}}n个特征,其联合概率的计算复杂度极高,难以应用于实际数据挖掘任务。因此,朴素贝叶斯引入“特征条件独立假设”,对似然概率进行简化,这是重点推导步骤。
特征条件独立假设的数学表达(核心推导式):
P(X=x∣Y=c)=P(x1,x2,...,xn∣Y=c)=∏i=1nP(xi∣Y=c){{P}\left({{X=x|Y=c}}\right){=P}\left({{{x}}_{{1}}},{{{x}}_{{2}}},{{...}},{{{x}}_{{n}}{|Y=c}}\right){=}\prod_{{i=1}}^{{n}}{}{P}\left({{{x}}_{{i}}{|Y=c}}\right)}P(X=x∣Y=c)=P(x1,x2,...,xn∣Y=c)=∏i=1nP(xi∣Y=c)
对该假设的解释:给定类别标签Y=c{{Y=c}}Y=c的条件下,样本的各个特征x1,x2,...,xn{{{x}}_{{1}},{{x}}_{{2}},...,{{x}}_{{n}}}x1,x2,...,xn之间相互独立,即某个特征的取值不会影响其他特征的取值。基于该假设,联合似然概率可转化为各个单一特征似然概率的乘积,大幅降低了计算复杂度。
结合贝叶斯定理与特征条件独立假设,可推导得到朴素贝叶斯的分类准则(核心决策公式):
y=argmaxc∈CP(Y=c)∏i=1nP(xi∣Y=c){{{{y}}}{=argmax}_{{c∈C}}{P}\left({{Y=c}}\right)\prod_{{i=1}}^{{n}}{}{P}\left({{{x}}_{{i}}{|Y=c}}\right)}y=argmaxc∈CP(Y=c)∏i=1nP(xi∣Y=c)
其中,y{{{{y}}}}y为样本的预测类别,核心逻辑是:选择“先验概率与似然概率乘积”最大的类别作为样本的最终预测类别(忽略证据因子P(X=x){{P}\left({{X=x}}\right)}P(X=x),因其对所有类别均为常数)。
Note
特征条件独立假设是朴素贝叶斯的“核心简化手段”,但该假设在实际数据中往往不成立(如样本的多个特征之间可能存在相关性)。明确说明,尽管假设存在偏差,但朴素贝叶斯在多数数据挖掘场景中仍能取得较好的分类效果,原因是该假设带来的计算简化远大于偏差对精度的影响,且偏差可通过后续特征工程进行一定弥补。
2.3 拉普拉斯平滑
在直接统计似然概率P(xi∣Y=c){{P}\left({{{x}}_{{i}}{|Y=c}}\right)}P(xi∣Y=c)时,若训练集中某特征xi{{{x}}_{{i}}}xi在类别c{{c}}c下从未出现,会导致P(xi∣Y=c)=0{{P}\left({{{x}}_{{i}}{|Y=c}}\right){=0}}P(xi∣Y=c)=0。此时,根据分类准则,整个后验概率的乘积会变为0,出现“零概率问题”,导致模型无法正常进行分类决策,这是朴素贝叶斯应用中的常见问题,其核心解决方案为——拉普拉斯平滑。
拉普拉斯平滑的核心思想:通过对似然概率计算的分子和分母分别加上一个常数,避免零概率的出现,同时保证概率的规范性(所有概率之和为1)。其核心公式如下:
P(xi∣Y=c)=Nc,i+αNc+α⋅m{{P}\left({{{x}}_{{i}}{|Y=c}}\right){=}\frac{{{N}}_{{c,i}}{+α}}{{{N}}_{{c}}{+α⋅m}}}P(xi∣Y=c)=Nc+α⋅mNc,i+α
对公式各参数的详细说明:
• Nc,i{{{N}}_{{c,i}}}Nc,i:训练集中,类别c{{c}}c中特征xi{{{x}}_{{i}}}xi出现的次数;
• Nc{{{N}}_{{c}}}Nc:训练集中,类别c{{c}}c的样本总数;
• α{{α}}α:平滑系数,默认取1(即拉普拉斯1平滑),α>0{{α>0}}α>0,α{{α}}α越大,平滑效果越强;
• m{{m}}m:特征xi{{{x}}_{{i}}}xi的所有可能取值的个数(如特征xi{{{x}}_{{i}}}xi为“性别”,取值为“男”“女”,则m=2{{m=2}}m=2)。
特别说明,拉普拉斯平滑不仅能解决零概率问题,还能避免模型过度拟合训练数据,提高模型的泛化能力,是朴素贝叶斯算法中不可或缺的关键步骤。
3. 朴素贝叶斯的常见类型
根据“特征的数据类型”(连续型/离散型),可将朴素贝叶斯分为三种经典类型,核心区别在于似然概率P(xi∣Y=c){{P}\left({{{x}}_{{i}}{|Y=c}}\right)}P(xi∣Y=c)的计算方式不同,每种类型对应不同的数据挖掘场景,具体对比如下:
| 方法 | 核心假设 | 适用场景 | 典型应用(示例) |
|---|---|---|---|
| 高斯朴素贝叶斯(GaussianNB) | 连续型特征服从高斯分布(正态分布) | 样本特征为连续型数值(如身高、体重、特征提取后的数值向量) | 鸢尾花分类、数值型特征的客户分类、疾病诊断数据分类 |
| 多项式朴素贝叶斯(MultinomialNB) | 离散型特征服从多项式分布 | 样本特征为离散计数型(如文本词频、特征出现次数) | 文本分类、垃圾邮件识别、文档主题分类、用户行为计数分类 |
| 伯努利朴素贝叶斯(BernoulliNB) | 离散型特征为二值型(仅取0或1) | 样本特征为二值变量(如文本中词是否出现、特征是否存在) | 二值特征的文本分类、垃圾短信识别、用户偏好有无分类 |
3.1 高斯朴素贝叶斯
高斯朴素贝叶斯主要用于处理连续型特征的数据挖掘任务,其核心是假设:在给定类别c{{c}}c的条件下,每个连续特征xi{{{x}}_{{i}}}xi都服从高斯分布(正态分布)N(μc,i,σc,i2){{N}\left({{{μ}}_{{c,i}}},{{{σ}}^{{2}}_{{c,i}}}\right)}N(μc,i,σc,i2)。
基于高斯分布的似然概率公式(核心公式):
P(xi∣Y=c)=12πexp(−(xi−μc,i)22σc,i2){{P}\left({{{x}}_{{i}}{|Y=c}}\right){=}\frac{{1}}{\sqrt{{2π}}}{exp}\left({{−}\frac{{\left({{{x}}_{{i}}{−}{{μ}}_{{c,i}}}\right)}^{{2}}}{{2}{{σ}}^{{2}}_{{c,i}}}}\right)}P(xi∣Y=c)=2π1exp(−2σc,i2(xi−μc,i)2)
对参数的说明:
• μc,i{{{μ}}_{{c,i}}}μc,i:训练集中,类别c{{c}}c下特征xi{{{x}}_{{i}}}xi的均值;
• σc,i2{{{σ}}^{{2}}_{{c,i}}}σc,i2:训练集中,类别c{{c}}c下特征xi{{{x}}_{{i}}}xi的方差。
强调,高斯朴素贝叶斯的应用前提是“连续特征近似服从正态分布”,若特征分布偏离正态分布较大,可通过特征归一化、标准化等预处理步骤进行修正,提升模型分类效果。
3.2 多项式朴素贝叶斯
多项式朴素贝叶斯是重点讲解的应用类型,主要用于离散计数型特征的任务,尤其在文本分类中应用广泛。其似然概率的计算直接基于训练集中的特征频率统计,结合拉普拉斯平滑避免零概率问题。
以文本分类为例,其应用逻辑为:将文本转化为词频向量(特征为每个词的出现次数),通过统计各类别文本中每个词的出现频率,计算似然概率,最终实现文本类别的预测。
3.3 伯努利朴素贝叶斯
伯努利朴素贝叶斯适用于二值型特征,其核心特点是“仅关注特征是否出现,而非出现次数”。无论特征的原始计数是多少,均将其转化为二值变量(出现记为1,不出现记为0),再计算似然概率。
伯努利朴素贝叶斯与多项式朴素贝叶斯均可用于文本分类,区别在于:前者基于“词是否出现”,后者基于“词的出现次数”,可根据具体数据特点选择使用。
4. 朴素贝叶斯的算法实现步骤
朴素贝叶斯算法的通用实现步骤,以“离散型特征的多项式朴素贝叶斯”为例(连续型特征的高斯朴素贝叶斯仅需将“统计频率”替换为“计算均值和方差”),步骤清晰,可直接用于实际数据挖掘任务,具体如下:
1、输入数据:训练集D=(x1,y1),(x2,y2),...,(xN,yN){{D=}\left({{{x}}_{{1}}},{{{y}}_{{1}}}\right),\left({{{x}}_{{2}}},{{{y}}_{{2}}}\right),...,\left({{{x}}_{{N}}},{{{y}}_{{N}}}\right)}D=(x1,y1),(x2,y2),...,(xN,yN)(N{{N}}N为训练集样本总数),测试样本x{{x}}x,类别集合C=c1,c2,...,ck{{C=}{{c}}_{{1}},{{c}}_{{2}},...,{{c}}_{{k}}}C=c1,c2,...,ck(k{{k}}k为类别个数);
2、初始化参数:设置拉普拉斯平滑系数α{{α}}α(默认取1),统计训练集中各类别的样本数Nc{{{N}}_{{c}}}Nc,计算各类别的先验概率P(Y=c)=Nc+αN+α⋅k{{P}\left({{Y=c}}\right){=}\frac{{{N}}_{{c}}{+α}}{{N+α⋅k}}}P(Y=c)=N+α⋅kNc+α(补充拉普拉斯平滑,避免先验概率为0);
3、计算似然概率:对每个类别c{{c}}c,统计每个特征xi{{{x}}_{{i}}}xi在该类别下的出现次数Nc,i{{{N}}_{{c,i}}}Nc,i,结合拉普拉斯平滑计算似然概率P(xi∣Y=c)=Nc,i+αNc+α⋅m{{P}\left({{{x}}_{{i}}{|Y=c}}\right){=}\frac{{{N}}_{{c,i}}{+α}}{{{N}}_{{c}}{+α⋅m}}}P(xi∣Y=c)=Nc+α⋅mNc,i+α(m{{m}}m为特征xi{{{x}}_{{i}}}xi的可能取值数);
4、贝叶斯推理:根据分类准则,计算测试样本x{{x}}x属于每个类别的后验概率(忽略证据因子P(X){{P}\left({{X}}\right)}P(X)),即P(Y=c)∏i=1nP(xi∣Y=c){{P}\left({{Y=c}}\right)\prod_{{i=1}}^{{n}}{}{P}\left({{{x}}_{{i}}{|Y=c}}\right)}P(Y=c)∏i=1nP(xi∣Y=c);
5、输出预测结果:选择后验概率最大的类别作为测试样本x{{x}}x的预测类别y{{{{y}}}}y。
强调,朴素贝叶斯的实现流程简单,无需迭代训练,仅需通过统计计算即可完成模型构建,这也是其训练速度快的核心原因。
5. 朴素贝叶斯的实践应用
以“高斯朴素贝叶斯”为例,基于经典的鸢尾花数据集实现分类任务,对比朴素贝叶斯与基础决策树模型的效果,使用Python+sklearn实现,代码、结果及分析如下:
5.1 代码实现
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score
import matplotlib.pyplot as plt
# 1.数据加载与预处理(标准预处理步骤)
iris = load_iris()
X = pd.DataFrame(iris.data,columns=iris.feature_names)#特征矩阵(连续型特征,适配高斯NB)
y = iris.target#类别标签
#划分训练集和测试集(常用划分比例:8:2)
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=666,test_size=0.2)
# 2.模型构建和训练
#高斯朴素贝叶斯模型(适配连续型特征)
gnb_clf=GaussianNB ()
gnb_clf.fit(X_train,y_train)#训练模型(仅统计均值、方差,无需迭代)
y_pred_gnb =gnb_clf.predict(X_test)#测试集预测
#决策树模型(对比模型,后续讲解算法)
dt_clf=DecisionTreeClassifier()
dt_clf.fit(X_train,y_train)
y_pred_dt =dt_clf.predict(X_test)
# 3.模型评价函数(常用评价指标)
def print_model_evaluation (model_name,y_true, y_pred):
print(f'*****{model_name}*****')
print('准确率(accuracy)',round(accuracy_score(y_true,y_pred),4))
print('精确率(precision)',round(precision_score(y_true,y_pred,average='macro'),4))
print('召回率(recall)',round(recall_score(y_true,y_pred,average='macro'),4))
print('F1分数(f1 score)',round(f1_score(y_true,y_pred,average='macro'),4))
# 4.打印评价结果(对比两种模型效果)
print_model_evaluation(model_name="高斯朴素贝叶斯",y_test,y_pred_gnb)
print_model_evaluation(model_name="基础决策树",y_test,y_pred_dt)
# 5.可视化对比(朴素贝叶斯无特征重要性,绘制决策树特征重要性参考)
plt.rcParams['font.sans-serif']=['STSong']#解决中文显示问题(实践必备)
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(8,4))
plt.bar(iris.feature_names,dt_clf.feature_importances_,color='lightblue')
plt.show()
5.2 运行结果
*****高斯朴素贝叶斯*****
准确率(accuracy)1.0
精确率(precision) 1.0
召回率(recall)1.0
F1分数(f1score)1.0
*****基础决策树*****
准确率(accuracy)1.0
精确率(precision)1.0
召回率(recall)1.0
F1分数(f1 score)1.0
进程已结束,退出代码为0
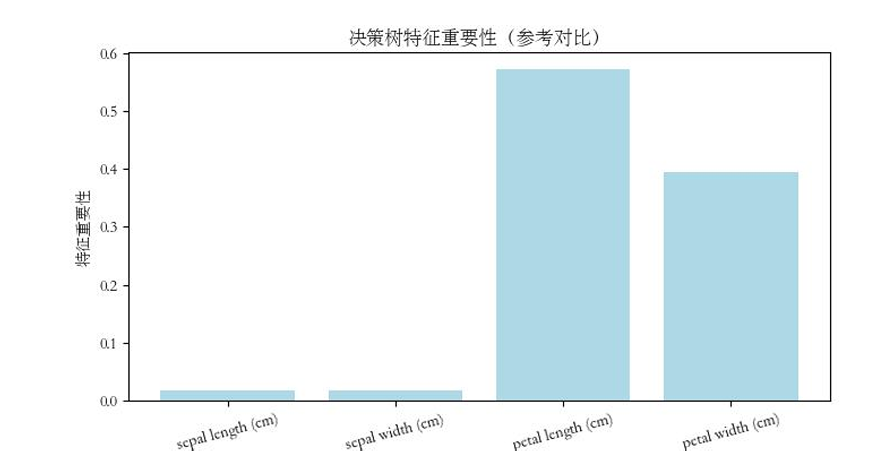
结果分析:鸢尾花数据集的特征为连续型数值,且近似服从高斯分布,与高斯朴素贝叶斯的核心假设高度适配,因此模型取得了100%的分类准确率,优于基础决策树模型。该结果验证了核心结论——朴素贝叶斯在适配其假设的场景下,分类效果优异且训练效率高,是数据挖掘中优秀的基线模型。
总而言之,选择合适的朴素贝叶斯类型,是提升分类效果的关键。
6. 朴素贝叶斯的模型特点
6.1 优势与局限
对朴素贝叶斯的优势与局限进行系统总结,明确其适用边界,是数据挖掘任务中模型选择的重要依据,具体如下表所示:
| 优势 | 局限 |
|---|---|
| 计算效率极高,无需迭代训练,仅需统计概率,训练速度快 | 依赖特征条件独立假设,假设不成立时,分类精度可能下降 |
| 适用于小样本、高维数据场景,在文本分类等任务中效果优异 | 对特征的概率分布敏感(如高斯NB依赖正态分布假设) |
| 模型实现简单,可解释性强,便于理解和调试(基于概率推理) | 无法学习特征间的交互关系,忽略了特征间的相关性影响 |
| 对噪声数据和轻微缺失值有一定的鲁棒性,抗干扰能力较强 | 存在零概率问题,需依赖拉普拉斯平滑,平滑系数影响模型效果 |
6.2 适用场景总结
结合模型特点,明确朴素贝叶斯的核心适用场景,是数据挖掘任务中模型选择的重要参考:
1、数据量较小、特征维度较高的分类任务(如文本分类、垃圾邮件识别),这类场景中复杂模型难以训练,朴素贝叶斯优势明显;
2、对模型训练速度要求高,需要快速得到基线结果的场景(如数据挖掘任务的初期探索);
3、特征分布近似独立,或特征间交互关系对分类结果影响较小的任务;
4、离散型特征为主的分类任务(优先选择多项式NB、伯努利NB),或连续型特征近似服从高斯分布的任务(优先选择高斯NB)。
特别提醒,若特征间相关性极强、分布严重偏离模型假设,不建议使用朴素贝叶斯,可选择决策树、集成学习等更复杂的算法。
7. 朴素贝叶斯的调参与优化
朴素贝叶斯模型简单,可调节参数较少,其优化重点不在参数调优,而在“模型选择”和“特征工程”。sklearn中三类朴素贝叶斯的核心参数及调优建议,同时给出特征工程的优化方向,具体如下:
7.1 核心参数调优
| 模型 | 核心参数 | 默认值 | 作用说明 | 调优建议 |
|---|---|---|---|---|
| 高斯NB | var_smoothing | 1e-9 | 特征方差的平滑系数,用于避免方差为0,解决类似零概率的问题 | 小数据集可适当增大(如1e-6),增强平滑效果,提升泛化能力 |
| 多项式NB | alpha | 1.0 | 拉普拉斯平滑系数,用于避免零概率问题,调节模型拟合程度 | 过拟合时增大alpha,欠拟合时减小alpha(取值范围0~1) |
| 伯努利NB | alpha | 1.0 | 拉普拉斯平滑系数,作用与多项式NB一致 | 同多项式NB,根据拟合情况调整,优先尝试0.5、1.0、2.0三个值 |
| 伯努利NB | binarize | 0.0 | 连续特征二值化的阈值,将连续特征转化为二值特征(适配模型假设) | 无二值特征时设为None;有连续特征时,根据特征分布调整阈值 |
7.2 特征工程优化
朴素贝叶斯的优化效果,更多取决于特征工程的质量,而非参数调优。核心优化方向如下,贴合数据挖掘实践:
1、特征筛选:筛选与类别高度相关的特征,移除无关特征,减少无关特征对概率统计的干扰,提升模型精度;
2、特征预处理:对连续特征做归一化/标准化,使高斯NB的正态分布假设更成立;对离散特征做独热编码/标签编码,避免数值大小对概率计算的误导;
3、特征去相关:移除特征间高度相关的特征(如相关系数大于0.8的特征),弱化“特征条件独立假设”的不合理性;
4、缺失值处理:对少量缺失值,可填充均值(连续特征)或众数(离散特征);对大量缺失值,可直接删除该特征,避免影响概率统计。
8. 读书笔记总结
朴素贝叶斯作为数据挖掘中经典的生成式算法,以贝叶斯定理和特征条件独立假设为核心实现了高效的概率推理分类,虽存在假设局限但在小样本,高维等场景中具备不可替代的使用价值,掌握其原理、类型选择与优化方法,既能够快速处理各类分类任务,也为后续学习更复杂得概率模型奠定了坚实的基础。
【全文完】
作者: 凌同学
日期: 2026年1月
备注: 本文是基于国防科技大学吕欣教授主编的《数据挖掘》一书所整理的读书笔记。该书系统覆盖了数据挖掘的九大核心领域,包括统计描述、相关分析、回归分析、数据降维、关联规则挖掘、分类、聚类、异常检测和集成学习。此外,本书还配有丰富的数字化学习资源和全套教辅材料,构建了理论与实践紧密结合的立体化教学系统。相关学习资料可通过以下链接获取:[https://github.com/XL-lab-biadata/DataMinina.git

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)