Real-Time Execution of Action Chunking Flow Policies
动作分块流策略的实时执行
“我们的方法实时分块 (RTC) 适用于任何开箱即用的基于扩散或流的 VLA,无需重新训练。它在执行当前动作块时生成下一个动作块,“冻结”需要被保证执行的动作并“修复”其余动作。”
“我们的贡献如下。首先,我们提出了一种新颖的系统,用于对动作分块扩散或基于流的策略进行异步实时推理,以实现连续控制。由于标准仿真基准是准静态的,并且大多已饱和伪开环推理策略 [11],因此我们基于 Kinetix 模拟器 [43] 设计了一个新基准,其中包含 12 个高度动态的操纵和运动任务。”
本文是从问题出发
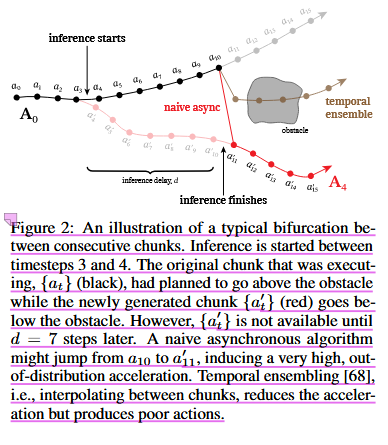
图 2:连续块之间的典型分叉的图示。推理在时间步 3 和 4 之间开始。正在执行的原始块 {at}(黑色)计划在障碍物上方移动,而新生成的块 {a′ t}(红色)在障碍物下方移动。然而,直到 d = 7 步之后,{a′ t} 才可用。一个简单的异步算法可能会从 a10 跳转到 a'11,从而产生非常高的分布外加速度。时间集成[68],即在块之间进行插值,降低了加速度,但产生了较差的动作。
而对于本文提出来的方法:
图 2 原始红线是“从下面绕”,黑线是“从上面绕”。RTC 运行后,最可能出现的是下面这种结果:
情况 A:旧黑线已经明显进入“上绕”策略 如果机器人在 timestep 3/4 之后已经沿着黑线往障碍物上方走,那么 RTC 会强烈阻止新 chunk 突然切换到下方。因为前 ddd 步被冻结,中间重叠区也被软约束,所以新 chunk 很可能继续采取“上绕”策略,至少在过渡阶段不会突然下折。 也就是说,RTC 会把原本的红线改成类似:先沿黑线上方继续走→平滑调整→后面根据新 observation 再决定 这会避免图 2 中那种从黑线跳到红线的高加速度。
情况 B:新 observation 强烈表明必须改成“下绕”
如果新 observation 表明上方路线已经不可行,RTC 也不是完全不让模型改变。它只是要求: 不能在 chunk 边界处突然改变。所以它可能生成一条更缓的轨迹:先接住黑线→逐渐减小上绕趋势→在后半段慢慢转向下绕
这就是 soft mask 的意义:前面连续性优先,后面反应性优先。
核心的点在3.1 使用流匹配进行推理时间修复
“修复是迭代去噪框架(例如扩散和流匹配)的已知优势。我们以 Pokle 等人的免训练图像修复算法为基础。 [48],它本身基于伪逆引导(ΠGDM;[55])。该算法的运行方式是在每个去噪步骤(公式 1)中向学习的速度场 v 添加基于梯度的引导项,以鼓励最终生成匹配某个目标值 Y,这是所需结果的损坏版本。在图像修复的情况下,损坏算子是掩模,Y是掩模图像,期望的结果是在非掩模区域中与Y一致的完整图像。专门针对我们的设置的 ΠGDM 梯度校正由下式给出”

解读:ΠGDM这个原先是在图像领域里应用的,然后作者把这个拿到本文来用。ΠGDM,伪逆引导:该算法的运行方式是在每个去噪步骤(公式 1)中向学习的速度场 v 添加基于梯度的引导项,以鼓励最终生成匹配某个目标值 Y,这是所需结果(这里指的是完整的图像部分Y)的损坏区域。在图像修复的情况下,损坏操作方法是添加掩模,Y是掩模图像,期望的结果是在非掩模区域中与Y一致的完整图像。
公式(2)中Y:Y 是目标值。放在 RTC 里,它主要来自上一段 action chunk 中希望保持连续的那些动作。论文说,inpainting 的目标是让最终生成结果在非 mask 区域和 Y 保持一致;在 RTC 中,就是让新 chunk 和上一 chunk 的重叠部分保持兼容。
公式(2)的右边的梯度相除是最终预测/当前 denoising 状态
下面整个括起来是指导项,矢量雅可比积,可以使用反向传播来计算。
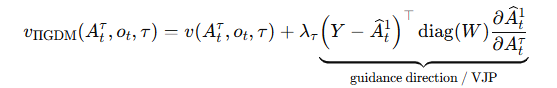

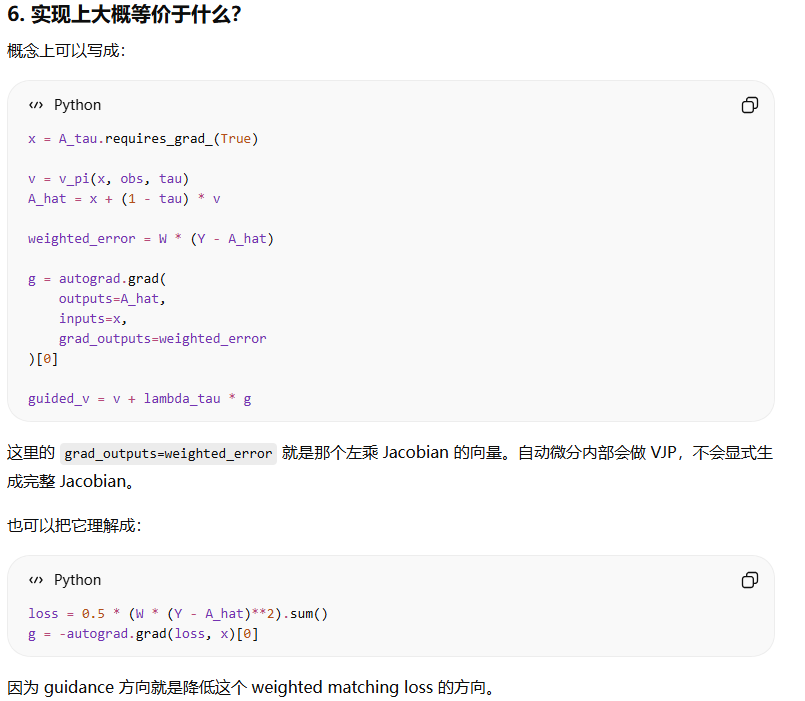
所以RTC 希望最终生成的 action chunk $$\widehat A_t^1$$ 在重叠区域接近上一条 chunk 的目标 YYY。但是当前真正能修改的是中间 denoising 状态 $$A_t^\tau$$,所以必须把“最终 action 空间里的误差”通过 $$\widehat A_t^1$$ 对 A_t^\tau 的 Jacobian 反传回来。这个反传回来的向量就是 guidance direction。
实验部分的话证明了:
RTC 的优势不是让模型本身更快,而是让慢模型也能稳定实时执行。 它通过异步推理避免同步等待,通过 修复/软掩码 避免 直接对齐 的 chunk 切换突变;在仿真中对延迟最鲁棒,在真实机器人中提升 流畅度,尤其在高延迟和精细任务里优势更明显。
但也要看到限制:作者自己承认 RTC 相比直接从 base policy 采样有显著计算开销,并且目前只适用于 diffusion/flow-based policies;真实实验虽然覆盖多个 manipulation 任务,但更动态的真实场景,比如腿式运动,还没有验证。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)