马尔可夫决策过程
·
定位:强化学习最底层数学框架,所有强化学习问题几乎都可以抽象成 MDP,用来描述智能体在不确定环境里连续做决策、最大化长期收益的全过程。
一、前置:马尔可夫性质(MDP 的灵魂)
1. 定义
未来只由当前决定,和过去无关公式简写: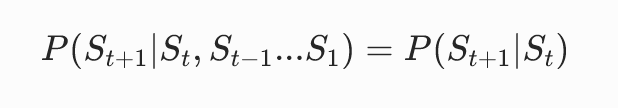
大白话
我下一步去哪,只看现在在哪,不记得之前走过什么路,无记忆性。
二、MDP 完整 5 大核心要素(必背)
标准五元组:(S,A,P,R,γ)
1. S:状态空间 State
- 智能体所有能处于的环境状态集合
- 例子:迷宫里的每个格子、游戏画面、机器人位置
2. A:动作空间 Action
- 智能体所有能执行的动作
- 例子:上下左右、开火、前进、左转
3. P:状态转移概率 Transition
P(s'|s,a)
- 含义:当前在状态 s,执行动作 a,跳到下一个状态 s' 的概率
- 代表环境随机性:同样动作不一定到同一个地方
4. R:即时奖励 Reward
R(s,a,s')
- 做完动作立刻拿到的瞬时分数
- 正向奖励:加分(吃到食物、到达终点)
- 负奖励:扣分(撞墙、掉坑)
5. γ:折扣因子 Discount factor
范围:{0,1}
- 作用:压低未来奖励权重
- 越接近 1:越看重长远收益
- 越接近 0:只看眼前即时奖励
三、MDP 完整交互流程(时序过程)
- 时刻 t:智能体观测当前状态 s_t
- 智能体根据策略选择动作 a_t
- 环境依据转移概率 P 给出下一个状态 s_{t+1}
- 智能体获得即时奖励 r_t
- 进入 t+1 时刻,重复循环直到终止
四、核心关键概念(强化学习必考)
1. 策略 Policy
策略 = 智能体的做事规则
- 确定性策略:pi(s)=a同一个状态永远选同一个动作
- 随机性策略:pi(a|s)状态 s 下选动作 a 的概率
MDP 最终目标:找到最优策略
2. 折扣总回报 Return
从 t 时刻往后所有奖励总和(带折扣)
- 不是只看当下奖励,是未来所有收益总和
3. 状态值函数 V(s)
含义:从状态s出发,遵循当前策略,能拿到的期望长期总回报
- 用来评判:这个状态好不好、值不值得待
4. 动作值函数 Q(s,a)
含义:在状态s下执行动作a,后续能拿到的期望长期总回报
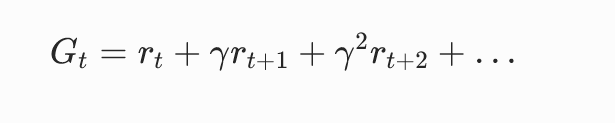
- 用来评判:在这个状态选这个动作好不好
- 深度学习里最常用:DQN 就是拟合 Q 值
五、MDP 核心公式:贝尔曼方程(Bellman)
1. 状态值函数贝尔曼期望方程
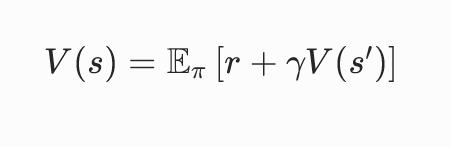
通俗翻译当前状态的价值 = 立刻拿到的奖励 + 下一个状态价值打折扣后的期望值
2. 动作值函数贝尔曼方程
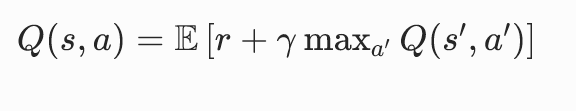
3. 最优贝尔曼方程
去掉策略,直接取最大收益: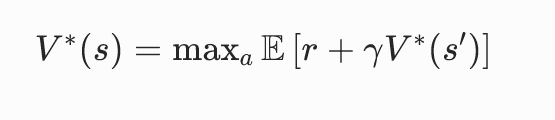
含义:每个状态都选最优动作,得到全局最大价值
六、MDP 分类
- 完全可观测 MDP智能体能看清全部环境状态 = 绝大多数强化学习场景
- 部分可观测 POMDP只能看到局部信息(看不到全局),难度更高
七、MDP 常用求解方法
- 动态规划 DP(已知环境模型 P、R)
- 策略迭代
- 值迭代
- 蒙特卡洛 MC(靠采样轨迹算均值)
- 时序差分 TD(最实用,TD0、TDλ)
- 深度强化学习(未知环境,拟合 Q/V)
- DQN、PPO、A3C 全部基于 MDP
八、生活化极简例子(秒懂)
例子:上班通勤 MDP
- 状态 S:在家、在路上、到公司
- 动作 A:坐地铁、打车、走路
- 转移 P:雨天打车容易堵车(转移概率变了)
- 奖励 R:准时到 + 10,迟到 - 20,花钱 - 5
- 折扣 γ:更在意今天上班,不在意一周后
- 策略:晴天地铁,雨天打车
- 值函数 V (在家):评估从家里出发整体好不好
整个通勤过程就是标准马尔可夫决策过程
九、总结一句话
马尔可夫决策过程 MDP = 满足无记忆性的环境 + 智能体动作选择 + 即时奖励 + 长期收益折算,是一切序列决策、强化学习问题的统一数学模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)