科研人狂喜!谷歌新框架,让 AI 写出有深度、有逻辑的顶会论文
写过论文的朋友都知道,从做完实验到码出一篇能投顶会的稿子,中间隔着一道巨大的鸿沟。虽然最近像 AI Scientist 这样的自动化科研工具层出不穷,但它们生成的论文往往“AI味”太浓:文献综述浅尝辄止,引用全是幻觉,甚至连一张像样的逻辑架构图都画不出来。
为了解决这些痛点,来自谷歌(Google)的研究团队提出了一个名为 PaperOrchestra 的多智能体框架。它不再是简单的文本填充,而是一个能够独立思考、查阅文献、绘制图表并反复润色的全能写作系统。

告别僵化:为什么我们需要“论文交响乐团”?
目前市面上的自动化写作工具主要面临两个尴尬:要么是跟特定的实验流程死死绑定,没法处理人类随手写的实验笔记;要么就是文献综述做得一塌糊涂,引用的论文要么不存在,要么文不对题。早期的尝试往往依赖于大型语言模型(Large Language Models, LLMs)的参数记忆,这不可避免地导致了事实性幻觉。
为了缓解这一问题,近期的一些框架开始引入检索增强生成(Retrieval-Augmented Generation, RAG)。然而,现有的系统要么只针对综述类文章,要么在处理非结构化输入时显得力不从心。PaperOrchestra 的核心逻辑是“解耦”。它被设计成一个独立的写作专家,能够处理人类提供的原始素材,并生成符合顶级会议标准的 LaTeX 稿件。

PaperOrchestra 与现有系统的对比,可见其在独立性、文献综述和图表生成上的全面优势
方法详解:五大智能体如何“同台演出”?
PaperOrchestra 将论文生成任务形式化为一个映射函数。其输入包括:想法摘要(Idea Summary, )、实验日志(Experimental Log, )、LaTeX 模板()、会议指南()以及可选的现有图片()。最终的输出是一个完整的提交包 。
整个流程由五个各司其职的智能体协作完成:
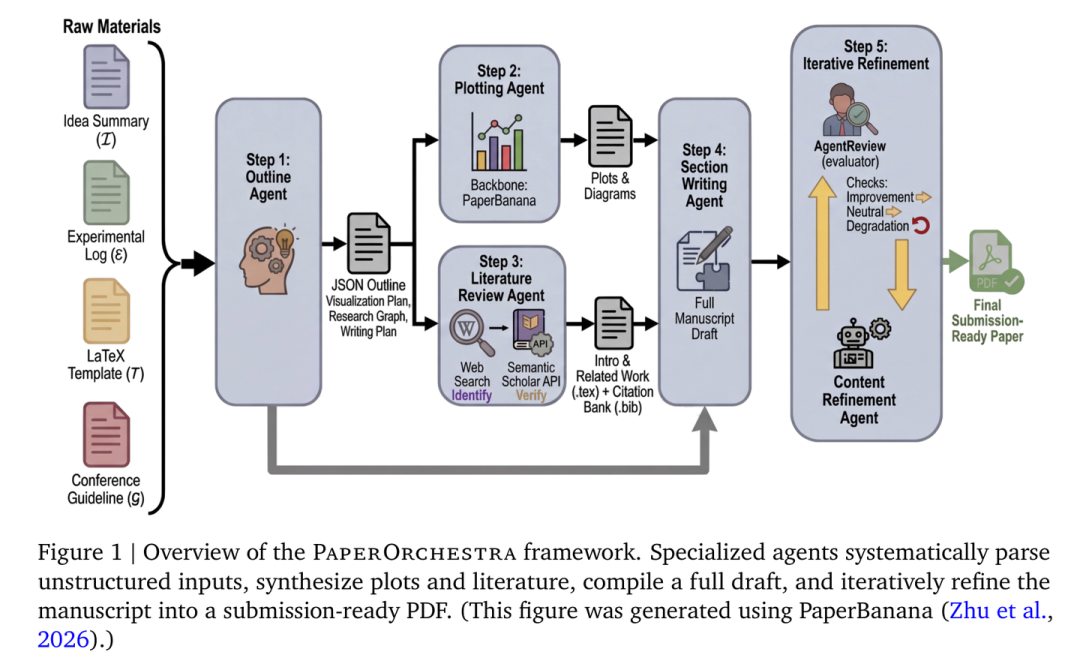
PaperOrchestra 框架概览:从解析输入到最终生成 PDF 的全流程
1. 大纲智能体(Outline Agent):乐团指挥
它是整个流程的灵魂。它会先通读你的实验笔记,制定出一个 JSON 格式的全局计划。这个计划不仅包括论文的章节结构,还包括绘图计划(指定图表类型和数据源)、文献检索策略,以及每一章必须引用的关键数据集和基线模型。
2. 绘图智能体(Plotting Agent):视觉大师
很多 AI 写作工具只能画简单的折线图。PaperOrchestra 集成了名为 PaperBanana 的模块,它能根据大纲要求,生成专业的概念示意图。它利用视觉语言模型(Vision-Language Model, VLM)作为评审员,通过反馈循环自动检查生成的图表是否有瑕疵,并不断修正文本描述以生成高质量图像。
3. 文献综述智能体(Literature Review Agent):事实核查员
这是该框架最亮眼的地方。它不再盲目相信模型的记忆,而是通过 Web 搜索和 Semantic Scholar API 进行实时验证。
-
输入:大纲给出的搜索方向。
-
逻辑:首先通过搜索发现候选论文,然后利用 API 验证其真实性,抓取摘要和元数据,并严格执行时间截断(Cutoff),确保不会引用“未来的论文”。
-
输出:经过真实性验证的 BibTeX 引用库和初稿。
4. 正文写作智能体(Section Writing Agent):专业笔杆子
在有了大纲、图表和文献库后,这个智能体开始“填肉”。它会从实验日志中提取精确的数值填入表格,并用严谨的学术语言描述算法流程。它的 Input 是之前所有步骤生成的中间产物,Output 则是一个初步完整的 LaTeX 源文件。
5. 内容精炼智能体(Content Refinement Agent):完美主义者
初稿完成后,系统会调用 AgentReview 模块模拟同行评审。如果模拟评审员觉得“创新点描述不清”,这个智能体就会针对性地修改 LaTeX 源码。只有当新版本的评分提升时,修改才会被接受。
实验结果:引用量直逼人类作者
为了测试这个“乐团”的实力,研究者们构建了 PaperWritingBench 基准测试。他们从 CVPR 和 ICLR 2025 中选择了 200 篇高质量论文,将其逆向工程为原始素材。
实验中,研究者设置了两种输入模式:Sparse(稀疏)模式仅提供高层想法,而 Dense(稠密)模式则保留了数学公式。结果显示,即使在 Sparse 模式下,PaperOrchestra 依然表现强劲。
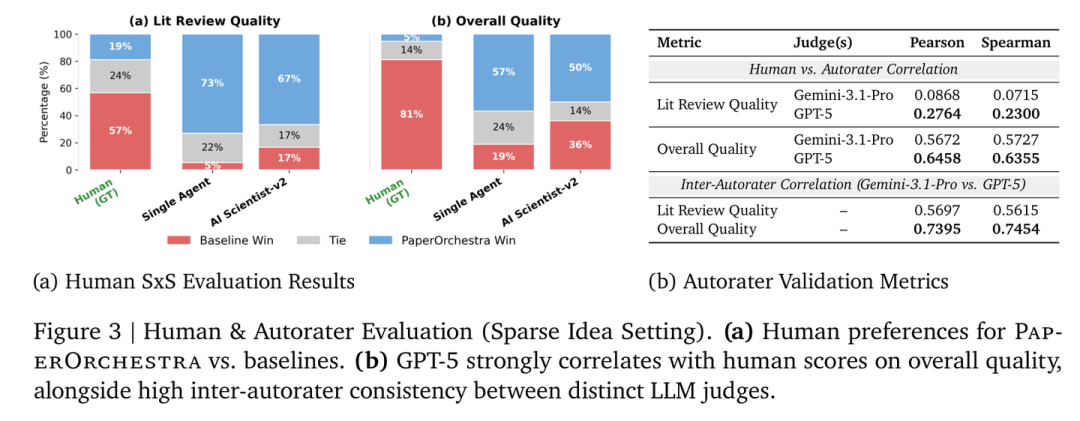
人类评估结果:PaperOrchestra 在文献综述和整体质量上显著优于基准模型
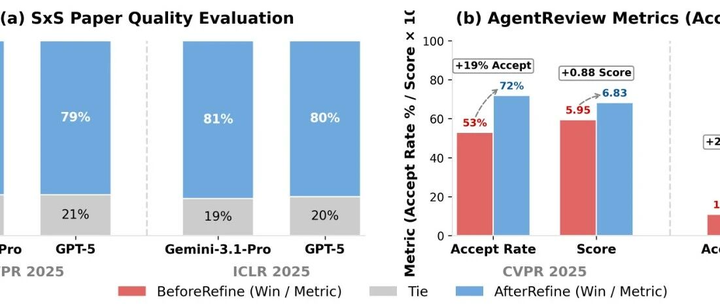
在人类研究员参与的侧向对比(SxS)中,PaperOrchestra 的表现显著优于自主基准模型:在文献综述质量方面,其绝对胜率领先 50%–68%;在论文手稿的整体质量方面,其领先 14%–38%。
以往的 AI 写作工具平均只能凑出 9 到 14 个引用,且大多是“为了引用而引用”。而 PaperOrchestra 生成的论文平均包含 45.73 到 47.98 个引用,非常接近人类作者约 59 个的平均水平。
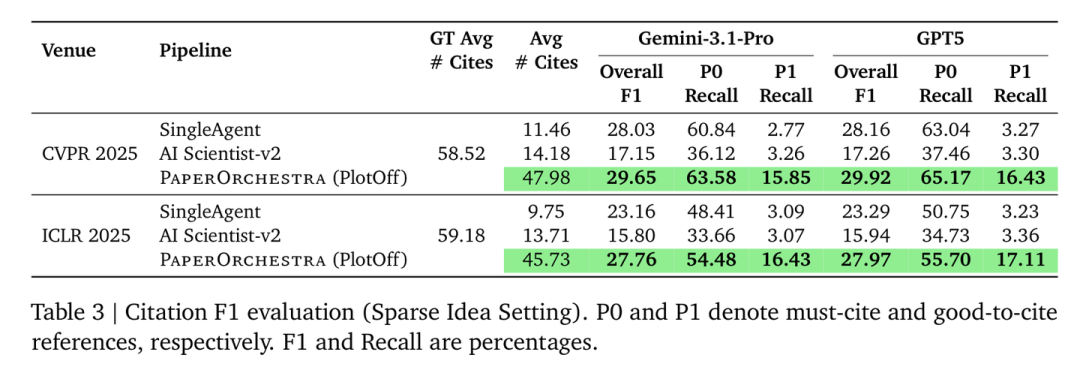
引用质量评估:PaperOrchestra 在必引文献(P0)的召回率上表现优异
此外,在模拟录用率上,使用 ScholarPeer 评审系统测试时,PaperOrchestra 生成的论文在 CVPR 赛道上拿到了 84% 的模拟录取率,这说明其生成的逻辑和表达已经非常接近顶会标准。
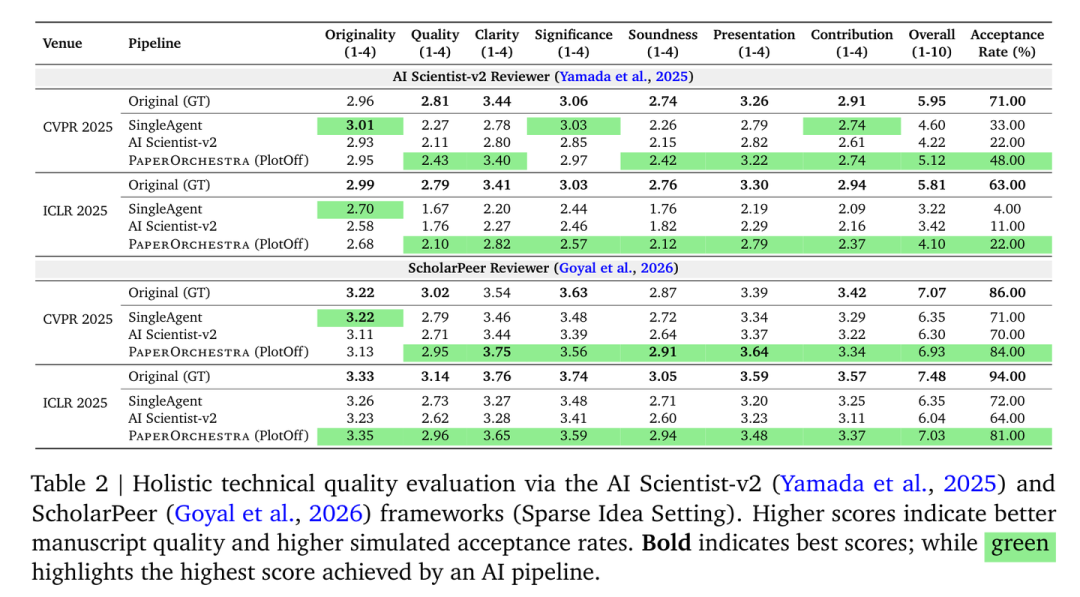
详细的技术质量评分表,展示了不同维度下的表现
消融实验:迭代优化的力量
研究团队还探讨了迭代优化和计算成本。实验证明,经过内容精炼智能体处理后的论文,在评审得分上有着显著提升。
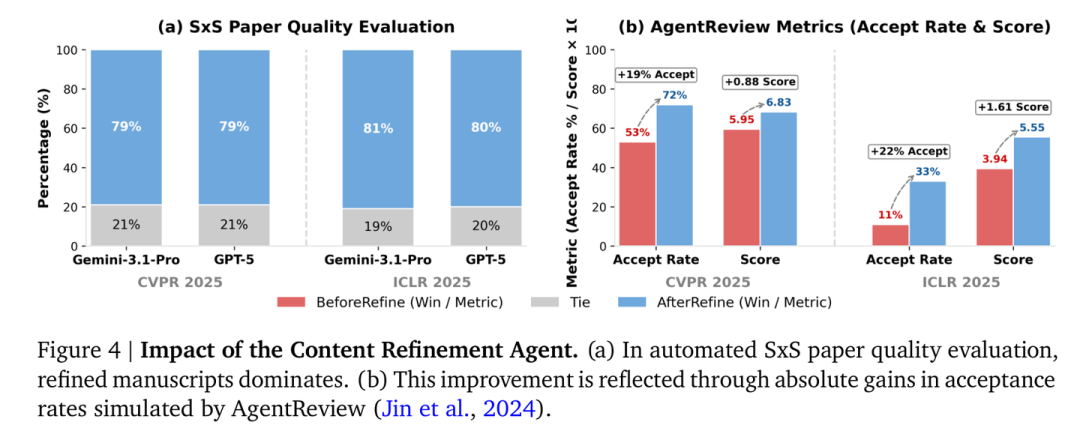
迭代优化对论文质量的影响:Refined 版本在胜率和录取率上均有大幅提升
在成本方面,虽然 PaperOrchestra 需要调用约 60-70 次 LLM API,生成一篇论文大约需要 39.6 分钟,但考虑到它能完成从文献检索到绘图的全部繁琐工作,这个时间成本在科研流程中是完全可以接受的。
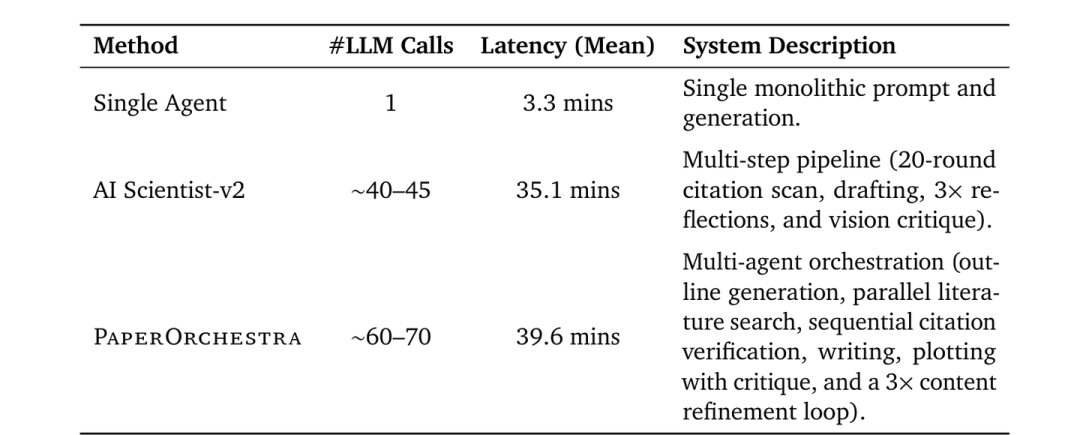
不同方案的计算成本与延迟对比
写在最后
PaperOrchestra 的出现,标志着 AI 辅助科研从“局部润色”进入了“系统性构建”的新阶段。它最核心的价值不在于写得快,而在于它建立了一套基于真实文献验证的写作逻辑,极大地缓解了 AI 写作中常见的“幻觉引用”和“逻辑断层”问题。
当然,作者在结尾也提到,虽然 AI 能写出像模像样的稿子,但人类研究员仍需对事实的准确性和创新的真实性负全责。目前的系统更像是一个极其高效的“初稿秘书”,帮你把那些琐碎的文献整理、表格制作和 LaTeX 排版搞定,让你能腾出精力去思考真正的科学难题。
如果你正为写 Related Work 抓耳挠腮,或者面对一堆实验数据不知从何下笔,或许这个“交响乐团”真的能为你奏响通往顶会的前奏。
👇 如何领取?
“管祝”:供祝好
“ 威-
你-
领-
航-”
学无止境、未来可期
There is no end to learning, and the future holds promise.
— END —

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)