从 BGE 到 Qwen3:中文 RAG Reranker 模型解析
在 RAG 系统中,Reranker 往往是决定最终检索质量的关键一环,却也是最容易被忽视的模块。本文从 Reranker 的基本原理出发,介绍 Reranker Encoder 和 Decoder 两类架构的工作机制,随后解析目前中文场景下最主流的两大模型系列BGE-Reranker 与 Qwen3-Reranker的模型设计与训练策略,最后结合实测数据给出实际选型建议。
概述
在通常的 RAG(检索增强生成)流程中,当用户提出查询请求时,系统首先通过 Embedding 模型对 Query 进行向量化,然后和向量数据库里预存的文档向量进行相似度计算,即从海量候选文档中快速筛选出一批初步相关的文档,这一阶段称为初步检索(Initial Retrieval)。
然而,初步检索结果的相关性往往并不精确,因为 Embedding 模型更擅长捕捉粗粒度的语义相似性,难以准确判断文档与 Query 之间细粒度的语义匹配程度。为此,需要引入一个更精细的排序步骤,即 Rerank 模型。
Reranker 模型,顾名思义,是对初步检索结果进行重新排序(Re-ranking)的模型。它将初步检索得到的候选文档与原始查询进行联合分析,通过更深层次的语义交互,得出更精确的相关性评分,并据此对候选文档重新排列,从而确保用户最终看到的是最符合需求的结果。
但是 Reranker模型计算过程需要进行向前传播,对资源的消耗较大。若直接将 Query 对全库文档进行逐一重排序,计算成本将非常的巨大,同时也不适用于对实时性要求较高的情况。因此,主流的 RAG 系统通常采用两阶段检索策略:
1)首先由 Embedding 模型快速从海量文档中召回少量高度相关的候选文档;
2)再由 Reranker 模型对这批候选文档进行精细排序。
这种"先粗召回,后精排"的策略在效率与精度之间取得了良好的平衡。
目前,Reranker 模型在架构上通常分为两类:
1)基于 Encoder 的结构(双塔架构)
2)基于 Decoder 的结构(单塔架构)
Encoder Reranker
Encoder Reranker 的核心思路是将 query 与 document 拼接后一同输入到 Encoder 模型进行联合编码,然后提取 [CLS] Token对应的隐向量,并经过单层全连接网络输出一个标量得分,从而将相关性评估建模为一个回归任务(即 Cross-Encoder 模式)。
输入形式可表示为:
以 BGE-Reranker-M3 为例,其计算 Document 与 Query 相似度得分的核心代码如下:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
class BaseReranker(AbsReranker):
def __init__(self):
self.tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path)
@torch.no_grad()
def compute_score_core(self, sentence_pairs, batch_size, max_length, normalize, device):
self.model.to(device).eval()
all_inputs = []
# 将 query 和 document 拼接为单段输入
for queries, passages in batch(sentence_pairs, batch_size):
q_ids = self.tokenizer(queries, max_length=max_length * 3 // 4, truncation=True)['input_ids']
p_ids = self.tokenizer(passages, max_length=max_length, truncation=True)['input_ids']
for q, p in zip(q_ids, p_ids):
all_inputs.append(self.tokenizer.prepare_for_model(
q, p, truncation='only_second', max_length=max_length, padding=False
))
sorted_idx = np.argsort([-len(x['input_ids']) for x in all_inputs])
inputs_sorted = [all_inputs[i] for i in sorted_idx]
scores = []
for batch in batch(inputs_sorted, batch_size):
inputs = self.tokenizer.pad(batch, padding=True, return_tensors='pt').to(device)
# 利用 AutoModelForSequenceClassification 输出分类 logit
logits = self.model(**inputs).logits.view(-1).float()
scores.extend(logits.cpu().numpy().tolist())
# 还原排序并进行 Sigmoid 归一化
scores = [scores[np.argsort(sorted_idx)[i]] for i in range(len(scores))]
if normalize:
scores = [1 / (1 + math.exp(-s)) for s in scores]
return scoresDecoder Reranker
Decoder Reranker 同样将 query 与 document 拼接后输入模型,但其评分机制与 Encoder 架构有所不同。
在训练阶段,通过构建特定的 Prompt 模板引导生成式模型在序列末尾输出一个特殊 Token——通常为 "yes" 或 "no",然后以此判断文档与查询的相关性。
在推理阶段,取该 Token 对应的 logit 值(或经 softmax 归一化后的概率)作为最终的相关性得分。
输入形式可表示为:
以 Qwen-Embedding 为例,其计算相似度得分的核心代码如下:
class Reranker:
def __init__(self, model_name):
self.tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
self.model = AutoModelForCausalLM.from_pretrained(model_name).eval().to(device)
self.token_true_id = self.tokenizer.convert_tokens_to_ids("yes")
self.token_false_id = self.tokenizer.convert_tokens_to_ids("no")
self.max_length = 8192
self.prefix = self.tokenizer.encode(template_prefix, add_special_tokens=False)
self.suffix = self.tokenizer.encode(template_suffix, add_special_tokens=False)
self.template_len = len(self.prefix) + len(self.suffix)
def build_prompt(self, query, doc, instruction=None):
content = f"<Instruct>: {instruction or 'default'}\n<Query>: {query}\n<Document>: {doc}"
return content
def process_inputs(self, pairs):
inputs = self.tokenizer(
pairs, padding=False, truncation=True,
max_length=self.max_length - self.template_len,
)
for i in range(len(inputs["input_ids"])):
inputs["input_ids"][i] = self.prefix + inputs["input_ids"][i] + self.suffix
inputs = self.tokenizer.pad(
inputs, padding=True, return_tensors="pt", max_length=self.max_length
)
return {k: v.to(self.model.device) for k, v in inputs.items()}
def compute_scores(self, inputs):
logits = self.model(**inputs).logits[:, -1, :] # 取最后一个 Token 的 logits
scores = logits[:, [self.token_false_id, self.token_true_id]] # 提取 yes/no 对应分数
scores = torch.softmax(scores, dim=1)[:, 1] # 取 "yes" 的概率作为得分
return scores.tolist()
def rerank(self, query, documents):
pairs = [self.build_prompt(query, doc) for doc in documents]
inputs = self.process_inputs(pairs)
return self.compute_scores(inputs)针对中文场景,大家最熟悉的 Reranker 模型,想必就是 BGE 系列和 Qwen 系列了~
BGE Reranker
BGE-Reranker 系列模型由北京智源研究院(Beijing Academy of Artificial Intelligence,BAAI)开发,是其成功推出 BGE(BAAI General Embedding)嵌入模型系列之后的又一重要成果。该系列专注于多语言环境下的文档重排序任务,并针对中英文混合场景进行了深度优化。
BGE Reranker 发布了多个版本,其中 bge-reranker-base、bge-reranker-large、bge-reranker-v2-m3 属于 Encoder 架构,bge-reranker-v2-gemma、bge-reranker-v2-minicpm-layerwise 则属于 Decoder 架构。官方推荐的使用场景如下:
|
模型 |
语言 |
层级输出 |
特性 |
|---|---|---|---|
|
BAAI/bge-reranker-base |
中文和英语 |
— |
轻量级重排序模型,易于部署,推理速度快。 |
|
BAAI/bge-reranker-large |
中文和英语 |
— |
较 base 版本精度更高,仍保持轻量易部署的特点。 |
|
BAAI/bge-reranker-v2-m3 |
多语言 |
— |
多语言能力强,轻量高效,综合场景适应性突出。 |
|
BAAI/bge-reranker-v2-gemma |
多语言 |
— |
基于 Gemma 的生成式架构,英文与多语言性能优异。 |
|
BAAI/bge-reranker-v2-minicpm-layerwise |
多语言 |
8–40 |
支持按层输出,可灵活控制推理深度,适合加速场景。 |
在实际使用中,官方给出了如下建议:
1)多语言场景:推荐使用 bge-reranker-v2-m3 或 bge-reranker-v2-gemma。
2)中英文单语言场景:推荐使用 bge-reranker-v2-m3 或 bge-reranker-v2-minicpm-layerwise。
3)优先考虑推理效率:推荐使用 bge-reranker-v2-m3,或选用 bge-reranker-v2-minicpm-layerwise 的低层输出。
4)追求最佳精度:推荐使用 bge-reranker-v2-minicpm-layerwise 或 bge-reranker-v2-gemma。
由于本文聚焦于中文场景,以下介绍中文场景效果较好的bge-reranker-v2-m3。
BGE-Reranker-v2-m3
bge-reranker-v2-m3 是在 bge-m3 的基础上针对重排序任务进一步训练而来的。bge-m3 的基座模型为 XLM-RoBERTa-large,即 RoBERTa 的多语言嵌入版本,bge-m3 在此基础上针对检索与排序任务进行了专项优化。
整体训练过程采用多阶段策略,如下图所示:
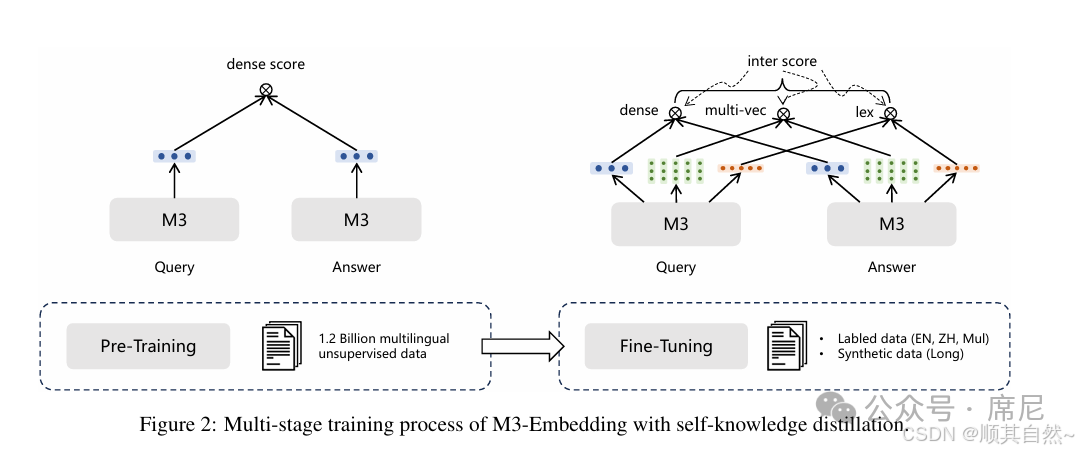
第一阶段:在大规模无监督数据上进行预训练,仅以对比学习的基本形式训练密集检索能力。
第二阶段:引入自知识蒸馏(Self-Knowledge Distillation),同时建立密集检索、稀疏检索、多向量检索三种检索功能。该阶段结合了有标签数据与合成数据,并按照 ANCE 方法为每个查询引入 Hard Negative 样本——通过内积相似度检索候选负样本,筛选后纳入训练,以提升模型的判别能力。
对比学习损失函数采用 InfoNCE,其形式如下:
其中 为 query 与文档的相似度得分, 为温度系数, 为正样本, 为负样本集合。
Qwen Reranker
Qwen Reranker 系列目前主要包含 Qwen3-Reranker 和 Qwen3-VL-Reranker 两个子系列。
Qwen3-Reranker
Qwen3-Reranker 基于 Qwen3 基础模型构建,采用 Decoder-Only 架构,专为文本检索与精排任务而设计,模型架构见下图右侧。
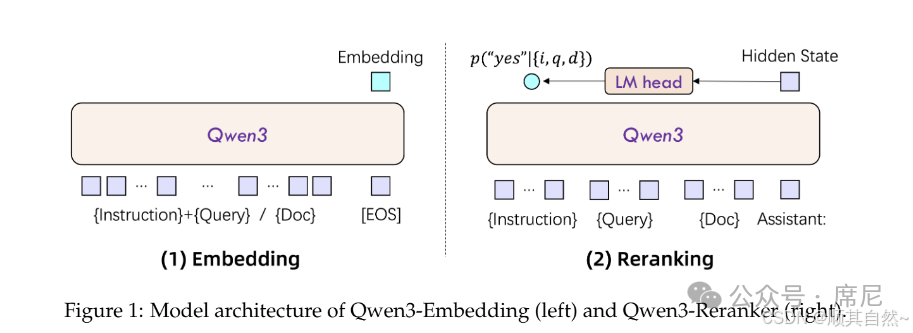
由于采用 Decoder 架构,为使模型能够更准确地评估文本相关性,训练时通过 Prompt 模板将相关性评估建模为二分类问题:模型被引导在序列末尾输出 "yes" 或 "no" 来表示文档与查询的相关程度。
注意使用时尽量构造如下所示的 Prompt 模板,接近训练阶段,从而获得最佳效果
<|im_start|>system
Judge whether the Document meets the requirements based on the Query and the
Instruct provided. Note that the answer can only be "yes" or "no".
<|im_end|>
<|im_start|>user
<Instruct>: {Instruction}
<Query>: {Query}
<Document>: {Document}
<|im_end|>
<|im_start|>assistant
<think>\n\n</think>\n\n在训练策略上,Qwen3-Reranker 设计了三阶段训练 Pipeline,充分发挥了 Qwen3 LLM 强大的文本合成与理解能力。
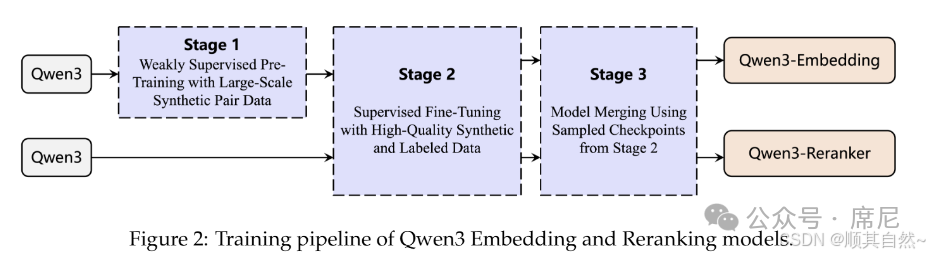
阶段一:大规模弱监督预训练(Weakly Supervised Pre-Training)
以 Qwen3-32B 为数据生成引擎,通过精心设计的模板与 Prompt,将原始多语种文档转化为"查询-文档"对。具体流程分为两步:
首先在"Configuration"阶段为每段文档指定角色(Character)、问题类型(Question Type)和难度(Difficulty);
随后在"Query Generation"阶段,依据上述配置生成贴近用户真实场景的查询语句。最终合成约 1.5 亿对多任务弱监督训练数据,覆盖信息检索、双语挖掘(Bitext Mining)、文本分类、语义相似度等多种任务类型。
阶段二:高质量数据有监督微调(Supervised Fine-Tuning)
由于 Qwen3-32B 生成的合成数据质量较高,本阶段首先对 1.5 亿对样本按余弦相似度进行过滤,保留相似度大于 0.7 的样本约 1200 万对,作为辅助有监督训练数据。同时引入多个公开基准数据集,包括 MS MARCO、Natural Questions、HotpotQA、NLI、DuReader、T2-Ranking、SimCLUE、MIRACL、MLDR、Mr.TyDi、Multi-CPR、CodeSearchNet 等,涵盖问答、检索和双语挖掘等多种任务形式。
训练时采用有监督微调损失:
其中 为 LLM 对标签 的预测概率。对于正样本文档,标签 为 "Yes";对于负样本文档,标签 为 "No"。此损失函数引导模型为正确标签分配更高的生成概率,从而提升排序判别能力。
此外,为提升模型的泛化能力,本阶段在微调时对筛选后的合成数据适量引入噪声,使其与真实标注数据形成良性互补。
阶段三:模型合并(Model Merging)
在有监督微调阶段保存的多个检查点之间,采用球面线性插值(Slerp)算法对模型参数进行加权融合,生成最终的"混合"模型,以提升模型的鲁棒性与稳定性。
具体做法为:在微调过程中,每隔一定步数或当验证集性能达到特定阈值时保存检查点;微调完成后,依据 Slerp 算法对多个检查点的参数按照一定权重进行球面插值合并,从而获得综合性能更优的最终模型。
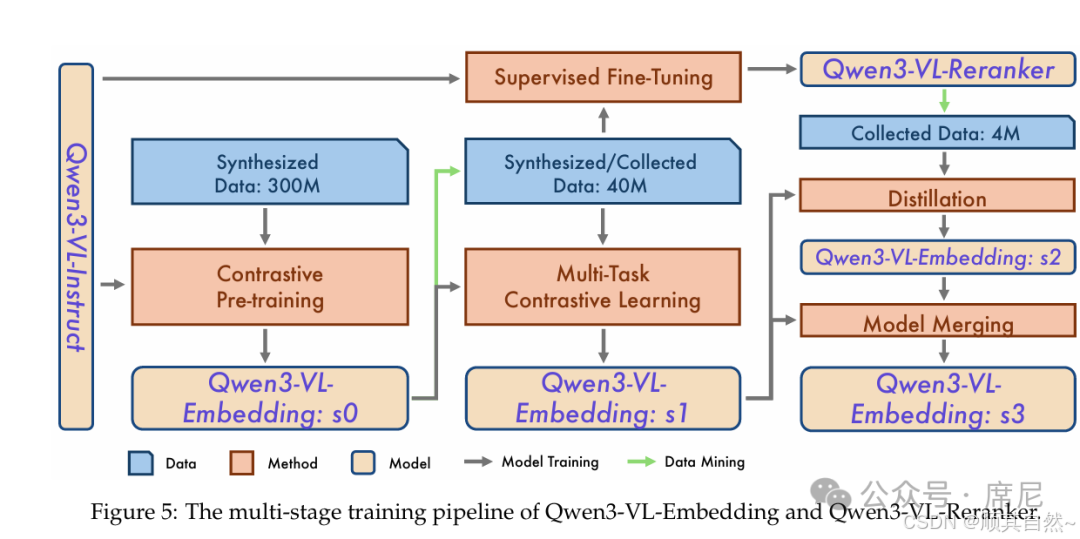
Qwen3-VL-Reranker
Qwen3-VL-Reranker 基于 Qwen3-VL 基础模型构建,专为多模态信息检索与跨模态理解任务而设计。该模型支持文本、图像、屏幕截图及视频等多种输入模态,以及上述模态的任意组合,架构示意见下图右侧:
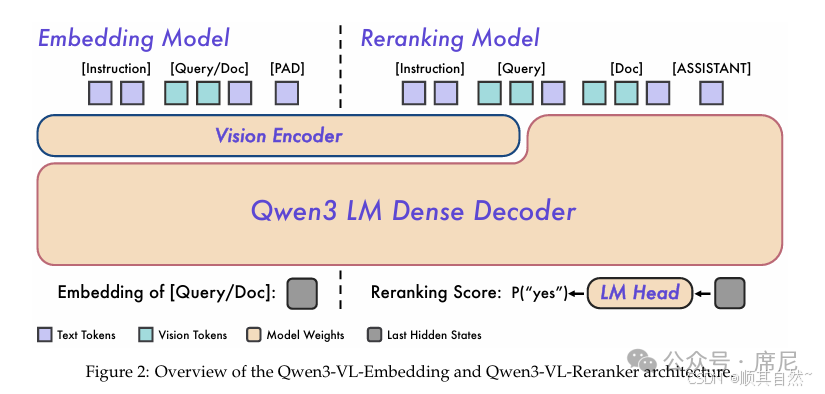
与 Qwen3-Reranker 类似,Qwen3-VL-Reranker 同样采用单塔架构,通过 Prompt 引导模型输出 "yes" 或 "no" 来表达 query 与文档(文本/图像/视频)之间的相关性得分:
<|im_start|>system
Judge whether the Document meets the requirements based on the Query and the
Instruct provided. Note that the answer can only be "yes" or "no".
<|im_end|>
<|im_start|>user
<Instruct>: {Instruction}
<Query>: {Query}
<Document>: {Document}
<|im_end|>
<|im_start|>assistant在模型内部,Reranking 模块接收输入对 (Query, Document) 并进行联合编码,利用基座模型内置的交叉注意力(Cross-Attention)机制,实现 query 与 document 之间深层次、细粒度的跨模态交互与信息融合。最终通过预测 yes 和 no 两个特殊 Token 的生成概率来量化输入对的相关性得分。
在训练策略上,Qwen3-VL-Reranker 与 Qwen3-Reranker 类似,同样采用多阶段训练 Pipeline,充分发挥 Qwen3-VL 底座模型在多模态语义理解方面的优势,为复杂的大规模多模态检索任务提供高质量的语义表示与精确的重排序能力:
如何选择?
先说结论:
若业务数据涉及多模态内容(图像、视频、截图等),首选 Qwen3-VL-Reranker;
若为纯文本场景,Qwen3-Reranker 与 BGE-Reranker 的效果差距不大,可根据资源条件与部署便捷性灵活选取。
以下基于《Qwen3-Reranker-8B 效果对比》博客中的测评数据,从检索精度与推理性能两个维度展开对比分析。
检索精度对比
测试一:中文技术文档检索
测试场景:从技术文档中查找相关信息
查询语句:"如何在 Python 中读取 CSV 文件?"
待排序文档:
|
编号 |
文档标题 |
|---|---|
|
文档1 |
Python 基础语法介绍 |
|
文档2 |
使用 pandas 处理 Excel 文件 |
|
文档3 |
Python 读取 CSV 文件的三种方法 |
|
文档4 |
JavaScript 数组操作方法 |
|
文档5 |
数据库连接配置指南 |
|
文档6 |
用 openpyxl 处理 Excel |
|
文档7 |
CSV 文件格式规范 |
|
文档8 |
Python 文件操作基础 |
测试结果对比:
|
排名 |
Qwen3-Reranker-8B |
BGE-Reranker |
|---|---|---|
|
1 |
文档3 (0.95) |
文档3 (0.92) |
|
2 |
文档7 (0.82) |
文档7 (0.85) |
|
3 |
文档8 (0.78) |
文档8 (0.79) |
|
4 |
文档1 (0.75) |
文档1 (0.75) |
|
5 |
文档2 (0.68) |
文档2 (0.70) |
分析:三款模型均将最相关的"文档3"排在首位,基础检索能力相当。Qwen3-Reranker-8B 给出的相关性评分最高(0.95),置信度更强;BGE-Reranker 在中文场景下表现稳定,与 Qwen3 差距极小;Cohere Rerank v3 对中文的理解略弱,将"Python 基础语法"排在了"文件操作基础"之前。
测试二:多语言混合检索
测试场景:中英文混合文档检索
查询语句:"machine learning applications in healthcare"(医疗领域的机器学习应用)
待排序文档:
|
编号 |
文档标题 |
|---|---|
|
文档1 |
机器学习在图像识别中的应用 |
|
文档2 |
Healthcare data analysis using deep learning |
|
文档3 |
医疗影像诊断的 AI 技术 |
|
文档4 |
Financial risk prediction models |
|
文档5 |
自然语言处理在医疗问答系统中的应用 |
|
文档6 |
Reinforcement learning for robotics |
|
文档7 |
电子病历的智能分析 |
|
文档8 |
Machine learning for drug discovery |
测试结果对比:
|
排名 |
Qwen3-Reranker-8B |
BGE-Reranker |
|---|---|---|
|
1 |
文档2 (0.93) |
文档8 (0.88) |
|
2 |
文档8 (0.91) |
文档2 (0.85) |
|
3 |
文档3 (0.87) |
文档3 (0.82) |
|
4 |
文档5 (0.85) |
文档5 (0.80) |
|
5 |
文档7 (0.82) |
文档7 (0.78) |
分析:在多语言场景下,三者的差异开始显现。Qwen3-Reranker-8B 表现最均衡,对中英文文档均能准确理解;Cohere Rerank v3 在纯英文文档上占优,但对中文文档的理解能力有限;BGE-Reranker 虽能处理英文,但整体更偏向于中文文档的理解。
测试三:长文档细粒度检索
测试场景:从长文档片段中进行细粒度内容检索
查询语句:"第三章中提到的优化算法具体实现"
待排序文档(均为长文档片段):第一章引言、第二章理论基础、第三章优化算法设计与实现、第四章实验结果、第五章总结、参考文献、附录A代码实现、附录B数据集说明
测试结果:Qwen3-Reranker-8B 准确识别了"第三章"与"附录 A(代码实现)"为最相关片段;BGE-Reranker 同样定位到了相关文档,但在长文档的细粒度理解上稍显不足;Cohere Rerank v3 受中文长文档上下文理解能力所限,表现相对一般。
测试四:代码检索能力
测试场景:从代码片段中检索目标算法实现
查询语句:"快速排序算法的 Python 实现"
测试结果:Qwen3-Reranker-8B 准确将"Python 实现快速排序"排在首位,并同时将"C++ 版快速排序详解"和"快速排序优化策略"纳入前列,体现了其对算法概念跨语言、跨形式的深度理解能力。
推理性能对比
在相同硬件环境(RTX 4090,24 GB 显存)下,三个模型的推理速度与资源占用如下:
|
模型 |
单次推理时间 |
批量处理(8 文档) |
显存占用 |
|---|---|---|---|
|
Qwen3-Reranker-8B |
120–150 ms |
800–900 ms |
~16 GB |
|
BGE-Reranker |
40–60 ms |
300–400 ms |
~2 GB |
BGE-Reranker 在推理速度和显存占用上具有明显优势,适合对延迟敏感的在线场景;
Qwen3-Reranker-8B 虽然推理更慢、资源消耗更大,但考虑到其 8B 量级的模型规模,这一开销处于合理范围之内;
选型建议
综合以上测试结果,给出如下选型建议:
优先选择 Qwen3-Reranker-8B 的场景:
多语言混合检索(尤其是中英文交叉场景)
需要对技术文档、学术论文等长文本进行细粒度理解
代码库或技术文档中的语义检索
对排序精度要求较高、可接受一定推理开销的场景
优先选择 BGE-Reranker 的场景:
以中文为主的单语言检索任务
硬件资源受限、需要轻量化部署的环境
对响应延迟极为敏感的在线服务
快速原型开发或成本优先的业务场景
参考文章
[1] M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
[2] Qwen3 Embedding and Reranker Technical Report
[3] Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
[4] Qwen3-Reranker-8B效果对比:vs BGE-Reranker、Cohere Rerank v3实测-CSDN博客

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)