《BOLT: Privacy-Preserving, Accurate and Efficient Inference for Transformers》学习笔记
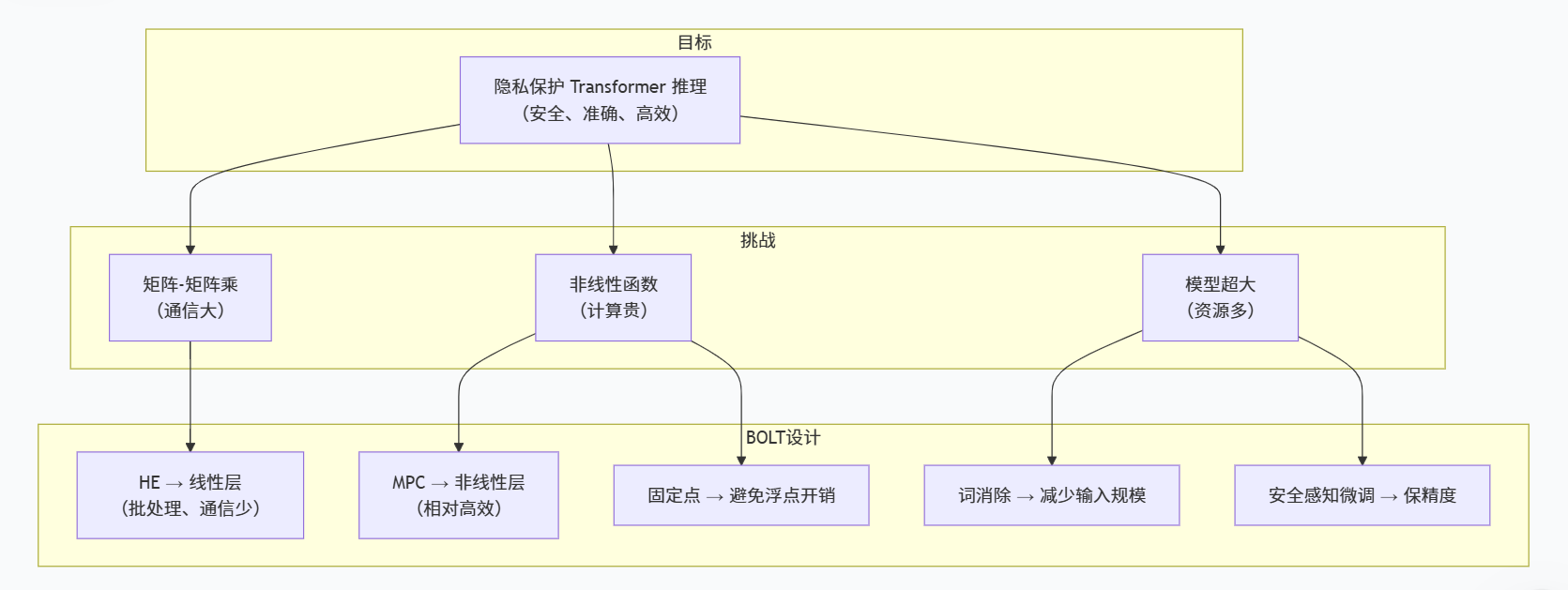
一、核心问题与目标
-
问题:如何在保证模型和输入隐私的前提下,显著降低Transformer推理的通信和计算开销?
-
目标:高效、精确、隐私保护的推理
二、研究难点
1.模型大:Transformer的规模远大于卷积神经网络,其参数数量可达数亿至数十亿个。
2.通信大:先前关于私有神经网络的研究提出了针对私有矩阵-向量乘法的优化协议,但Transformer算法需要进行大规模矩阵-矩阵乘法运算。
3.计算成本高:对变压器中复杂的非线性函数进行数十万次输入的安全性评估成本极其高昂。
三、关键技术
1. 高效矩阵乘法协议
-
紧凑的密文打包:充分利用HE密文槽位,避免稀疏打包带来的浪费。
BOLT换了一个计算矩阵乘法的方式:不是用“行点乘列”,而是用“列的组合”。
密文-明文矩阵乘法



-
BSGS策略(小步大步):
在同态加密(HE)中,密文旋转(将密文内的槽位循环移位)是一种非常昂贵的操作。旋转次数越多,计算越慢,通信开销也越大(因为有时需要传输旋转后的密文)。
BSGS 这个名字来源于数论中用于计算离散对数的“小步大步”算法,其核心是用空间换时间,把原本需要 O(N)次的操作,通过分组和预计算,降低到O(√N)次。

将小步大步策略应用于矩阵乘法算法,以减少密文旋转次数,并将旋转操作推迟至中间结果的部分求和阶段执行。
-
密文-密文矩阵乘法:
密文-密文矩阵乘法在 HE 中很难,因为两个密文乘噪声大、打包不对齐。BOLT 通过外积分解、部分旋转+掩码合并,以及推迟旋转等技巧,把乘法深度压到 3 以内,从而用小参数高效完成 QK^T 和 Softmax×V 计算。
在 Transformer 注意力机制中:
-
查询 Q 和 键 K 都是从输入 X 加密后乘明文权重得到的 → Q 和 K 都是密文
-
计算注意力得分
Q × K^T时,两个矩阵都是密文 -
注意力输出Softmax × V中,V 也是密文
所以 密文-密文乘法无法避免。
BOLT 的两种密文-密文乘法场景
列打包 × 行打包(用于 Q × K^T)



对角线打包 × 列打包(用于 Softmax × V)
支持注意力机制中的 QKT和 Softmax×V 等操作,乘法深度控制在3以内,避免大参数。
2. 精确高效的非线性函数近似
问题:GELU 是 Transformer 里一个常用的激活函数,原始公式里有一个 erf(误差函数)。
这个 erf 在安全计算(MPC 或 HE)里极其昂贵,几乎不能用。
GELU(x) = 0.5 * x * (1 + erf(x/√2))
之前的系统(比如 Iron)用一种笨办法来近似 GELU,结果仍然很慢,占了整个推理时间的一半以上(>50%)。
目标:找一个更快、但精度不损失太多的方法来计算 GELU,并且能用在 MPC 里(秘密共享)。
核心思路:利用 GELU 的数学性质,只在需要的区间用低次多项式近似,并且用对称性减少一半计算量。
1. 利用线性性(两端近似):x 很大或很小时,GELU(x) 几乎就是 x 或 0,不需要多项式。
BOLT 的做法:如果 x > 2.7 → 直接输出 x;如果 x < -2.7 → 直接输出 0;只有中间区间 [-2.7, 2.7] 才需要精确计算。这样大部分输入值(特别大的或特别小的)都不用经过复杂的多项式,省了很多时间。
2. 利用对称性(只算一半):GELU 里的一个子函数g(x) = x * erf(x/√2)是偶函数,只要算一半(x ≥ 0)就够了,然后GELU(x) = 0.5 * (x + g(x)),计算量直接减半。
3. 低次多项式拟合:
BOLT 选了一个 4 次多项式:g(x) ≈ a*x⁴ + b*x³ + c*x² + d*x + e 在 [0, 2.7] 区间上,用一个简单的多项式来近似 g(x)。
4. Motzkin 预处理(减少乘法次数):在 MPC 里,乘法是最贵的操作。一个 4 次多项式用普通方法( Horner 法 :g(x) = (( (a)*x + b )*x + c )*x + d )*x + e )需要 4 次乘法。BOLT 用了一个数学技巧(Motzkin 预处理),把 4 次多项式的计算变成只需要 3次乘法。这意味着计算速度更快,通信也更少。
5.一次比较搞定两个区间:
朴素的做法需要做两次比较:
-
先判断 x 是否 > 2.7
-
再判断 x 是否 < -2.7
但 BOLT 用一个技巧:先算 |x|,然后只比较 |x| > 2.7 一次就够了。如果 |x| > 2.7,再判断 x 的正负,输出 x 或 0。否则,用多项式计算。这样就省了一次比较操作。
总结:BOLT 利用 GELU 在两端接近线性的特点,只在中间区间用 4 次多项式近似,并且利用偶函数对称性只算一半,再用 Motzkin 预处理把乘法次数从 4减到 3,最后用一次比较判断所有情况。结果比 Iron 快几倍到几十倍,精度几乎没有损失。
3. 机器学习优化
词消除(Word Elimination):利用注意力分数(注意力分数就是每个词对其他词的“关注度”,分数高的词更重要,可找到一句话里不重要的词)筛选重要词元,通过剔除贡献较小的词元,我们可以降低输 入矩阵的维度,从而提升推理效率。
BOLT的做法:
1.计算注意力分数
2.秘密排序这些分数,找到中位数
3.只保留分数高于中位数的词(一半的词)
安全计算感知微调:模型原本是用浮点数训练的,现在要换成固定点+多项式近似,精度会掉,那么我们在微调阶段就让模型“体验”将来推理时的计算方式(定点数 + 近似函数),模型学到的参数,自然就适应了这种“退化”,精度损失降低。
BOLT的做法:
1. 替换非线性函数:在微调之前,先把模型里的 GELU、Tanh、Softmax 换成 BOLT 设计的那些近似版本
2. 模拟定点计算:在前向传播时,用对称静态量化来模拟定点运算。简单说:每个数字都先缩放到整数范围,用完再缩放回来。这样模型在训练时就“习惯”了精度损失。
3.处理不可微的量化:量化操作不能求导(没法做反向传播)。BOLT 的做法是:先正常计算梯度,然后把梯度也做一次量化(近似模拟)。
4.考虑词消除:在微调时,前向传播也动态剔除低分词元,反向传播自动适应这种输入变化。
这样模型学会了“即使少了几个词,也能猜对”。
总结:一是用注意力得分剔除不重要的词,把输入长度砍半,所有计算都快一倍;二是让模型在微调时就“体验”将来的定点数和近似函数,学会适应精度损失,恢复准确率。两者结合,又快又准。
四、主要结论与贡献
3.1 性能提升
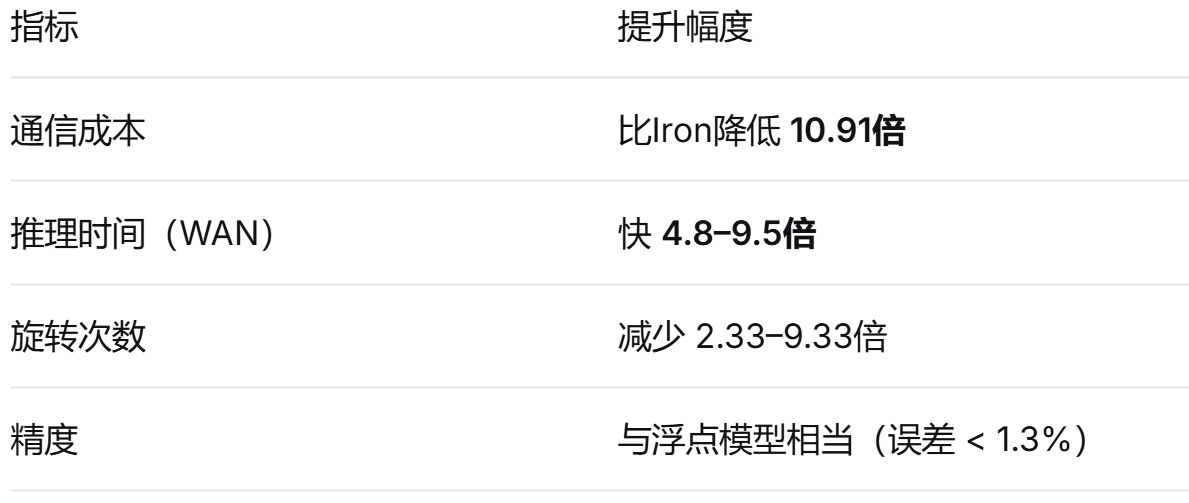
通信成本:在BOLT和Iron两套系统里,客户端和服务器之间来回传输的数据总量,判断网络带宽够不够。在隐私保护中计算中,通信常常是最大的瓶颈,因为计算机科研并行、可以加速,但网络带宽是有限的,并且网络延迟无法靠硬件加速。
推理时间:从客户端发送加密输入开始,到收到解密后的推理结果为止的总耗时,即用户等多久能拿到结果。
旋转次数(HE特有的关键操作):在HE中,数据被编码在密文的“槽位”(slots)里,旋转就是把槽位里的数据循环移动位置。旋转次数直接决定了HE部分的运行时间,即判断加密操作效率如何
精度:结果准不准。如果隐私保护导致精度大幅下降,用户就不会用。保护隐私的前提是结果仍然有用。
3.2 主要贡献总结
-
通信优化的线性层协议:紧凑编码 + BSGS + 密文-密文矩阵乘。
-
高效的非线性近似:低阶多项式 + Motzkin预处理 + 无LUT的Softmax。
-
机器学习协同优化:词消除 + 安全感知微调。
-
开源系统BOLT:首个接近实用的隐私保护Transformer推理系统。
五、启发


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)