如何让 Agent 安全地执行代码:Sandbox Runtime 原理解析
作者:TSH、CHD from HPC Group @ Shanghai AI Lab
TL;DR
从 OpenClaw 等近期爆火的 Agent 产品可以看到,AI Agent 已经从实验环境走向生产环境,并面临更复杂、更动态的任务执行需求。在此背景下,基础设施面临的核心挑战已从单纯的算力供给,转向可控执行环境的规模化治理。由于 Agent 系统通常存在大量的代码执行、网页浏览获取数据、第三方工具调用等业务操作,在生产环境中往往暴露出以下风险:其一是安全边界脆弱,存在容器逃逸、横向渗透与数据外泄风险;其二是运行时能力异构,不同隔离技术底层实现各异,难以做统一编排。因此,Sandbox 成为Agent执行所需必要基础设施。本文以 Agent Infra 系统工程落地为目标,聚焦于 Sandbox Runtime,从“为什么需要”到“如何实现”再到“怎么选”:介绍 Agent Sandbox 的需求背景,在集群中如何提供规模化 Sandbox 服务,最后探讨底层 Sandbox Runtime 技术路线并给出选型建议。
为什么AI Agent需要Sandbox?
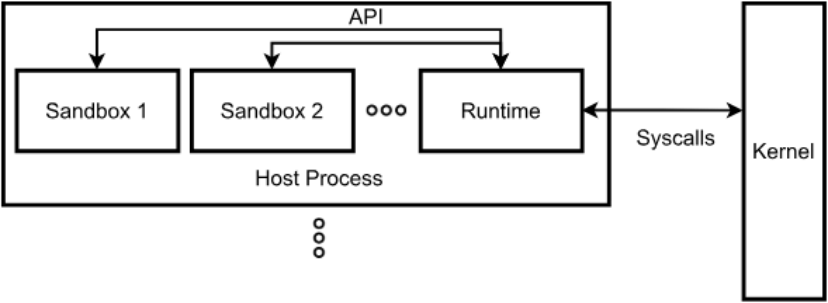
Agent 系统工程落地生产环境中的大致架构如下:
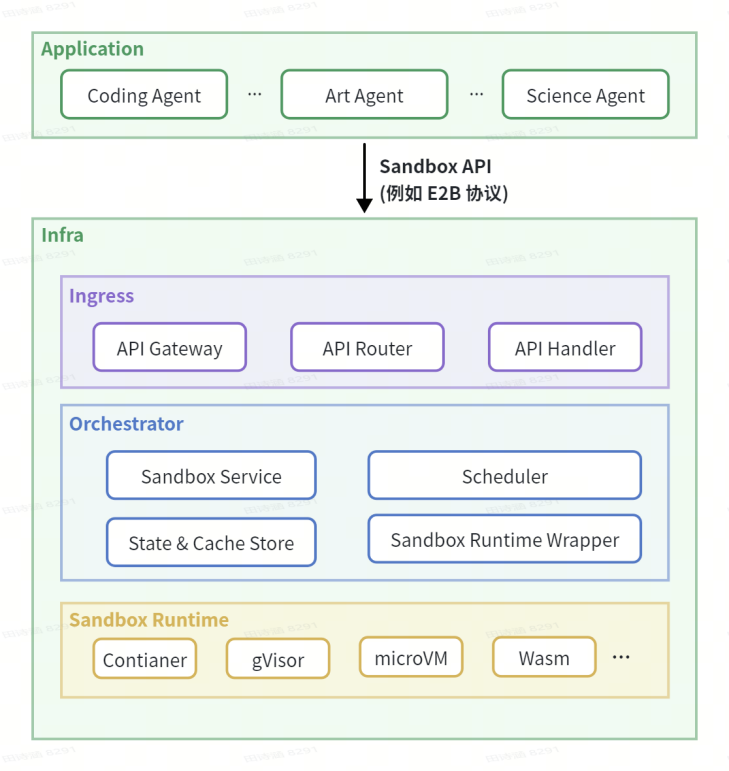
其中基础设施接收来自 Agent 应用发送的任务请求后,通过集群控制面选择某种 runtime 启动 Sandbox 实例,作为隔离环境来执行 Agent 任务。
从工程角度 Sandbox 是便于基础设施层进行统一编排调度的一种负载类型,从安全角度 Sandbox 是隔离不可控 Agent 任务请求与底层资源之间的防护边界。
在生产环境中,集群规模大、任务多、运行时类型丰富,Sandbox 的统一管理也是一个必要问题。
Sandbox Management:业界实践现状
在现有的基础设施架构中引入 Sandbox 资源服务,需要满足以下需求:
-
解耦底层运行时接口差异:屏蔽 Container、MicroVM、Wasm 等不同底层运行时的接口差异,定义统一接口;
-
兼容上层资源管理范式:提供稳定且可编排的资源抽象语义(包含资源模型及控制器),降低上层业务接入复杂度;
-
对齐横向治理机制:与集群已有治理范式尽可能对齐,包含状态与日志信息同步,降低调度、运维与审计成本。
因此,Sandbox 不仅仅是执行环境,在集群中应该被视为一种可声明、可调度、可运维、可审计的资源对象,以 Kubernetes 为例,理想状态下 Sandbox 的编排体验应尽量贴近 Kubernetes 的原生资源类型 “Pod”。
目前业界已有一些厂商提供了在集群中的规模化 Sandbox 服务管理案例,例如阿里云 OpenSandbox、腾讯云 CubeSandbox、字节 AIO Sandbox 等项目,它们的方案虽实现路径不同,但系统形态逐渐收敛到以下几类通用组件:
-
API Handler:网关协议层,负责鉴权、协议接入、路由与对外接口等。
-
Orchestrator Controller:集群控制面,负责节点发现与选点、状态机编排、重试/补偿、生命周期策略等。
-
State Store:状态管理面,负责存储管理实例状态、过渡同步、路由索引、snapshot/template 元数据等。
-
Node Sandbox Service:节点本地执行面,负责 Sandbox 生命周期 RPC 的落地执行与资源回收。
-
Runtime Wrapper:底层运行时封装,负责对不同 runtime 的接口进行抽象解耦,向上提供统一原子能力(如 start/exec/snapshot/kill)及交互式调用接口。
虽然不同 Sandbox 服务管理方案的软件架构比较类似,但在技术路线选型上存在两点分歧:
-
编排层选型:选择深度集成 Kubernetes 生态,还是自建集群管理体系;
-
Runtime 层选型:选择单一 runtime 做极致优化,还是采用多 runtime 做异构兼容与分层调度。
而这两个选型问题本质上都引出了同一个核心技术问题:底层隔离技术的能力边界和通用适配性。
因此,在回答“如何选型”之前,必须先厘清不同 Sandbox Runtime 的隔离方式、性能特征与适用场景。
机制解析:Sandbox Runtime 如何做到安全隔离?
Sandbox Runtime 的主流技术总览
Sandbox 目前主流技术方向包括:
|
Sandbox 名称(形式) |
隔离级别 |
特点 |
|---|---|---|
|
Container, Bubblewrap, nsjail |
进程/容器 |
共享宿主内核 |
|
gVisor |
用户态内核 |
syscall 被用户态 Sentry 拦截 |
|
KVM+QEMU, MicroVM (Firecracker) |
VM |
独立内核 |
|
WebAssembly |
指令 |
Runtime 设定 Wasm Module 可以使用的指令 |
几种主流的 Sandbox runtime 架构图如下:
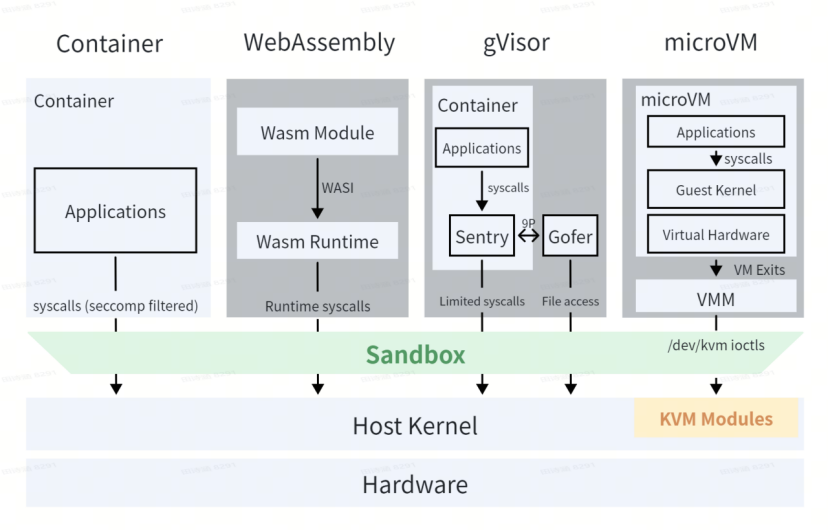
Container
使用传统容器作为 Sandbox 的隔离方式,依托了 Linux 内核提供的以下机制:
-
namespace:实现容器间资源的隔离
-
cgroup:全称 Control Group,设置进程能使用资源上限
-
seccomp:只允许容器调用白名单内的系统调用
利用上述机制,容器将进程及其依赖封装在独立的命名空间中,并利用 cgroup 限制资源消耗,从而为每个容器构建了一个逻辑上隔离的运行环境。这种方式的特点是多个容器共享同一个宿主内核:seccomp,能限制容器只能使用指定的 syscall,但无法消除内核本身的攻击面。一旦内核中处理某个被允许调用的 syscall 的代码逻辑存在漏洞,攻击者便可从容器内构造恶意输入触发该漏洞,攻击宿主机内核,实现容器逃逸。
MicroVM
VM 的做法是使用硬件虚拟化的技术,让每个VM实例拥有一个单独的内核:Guest Kernel。即使 VM 里的恶意代码攻破了 Guest Kernel,面对的下一层是 VMM + KVM 的硬件虚拟化边界,而不是共享的宿主内核。
传统的 Full VM(比如 QEMU)为了追求硬件兼容性,会虚拟化出一套完整的硬件(即全虚拟化)。全虚拟化完整模拟一套与真实物理硬件接口一致的虚拟硬件,使得 Guest OS 无需任何修改即可运行。但是这种方式的资源开销太大,启动太慢,降低了 agent 代码的执行速度。MicroVM 是在 VM 形态设计上的取舍,而不是一种独立的虚拟化方式。MicroVM 的轻量化来自对 Full VM 中不必要硬件模拟的裁剪,从而提升启动速度。注意 MicroVM ≠ 半虚拟化,虚拟化方式(全虚拟化 or 半虚拟化)和 VM 形态(Full VM or MicroVM)是两个不同的维度。只是 MicroVM 一般走的是半虚拟化的路线。
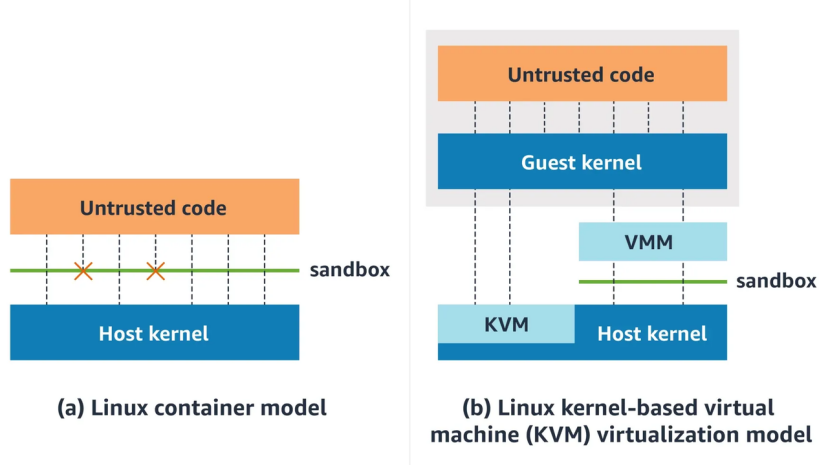
Container vs MicroVM (Firecracker)[4]
gVisor
gVisor 既不是单纯的 syscall 过滤器(如 seccomp),也不是 VM,而是介于两者之间的第三条路。gVisor 引入一个用户态的内核 - Sentry,相当于在用户态实现了一个 Linux Kernel 的子集,能独立处理一些 syscall,同时自身也会向 host kernel 发起少量必要的 syscall。Sentry 进程运行在受 seccomp 严格约束的容器中,没有直接访问外部文件系统的权限。因此 gVisor 引入 Gofer(一个 Host 进程),负责所有超出沙箱范围的文件资源访问。Sentry 和 Gofer 之间通过 socket 或共享内存通道使用 9P 协议通信。同时,gVisor 包含一个名为 runsc 的 Open Container Initiative (OCI) 运行时,可与 Docker 和 Kubernetes 集成。
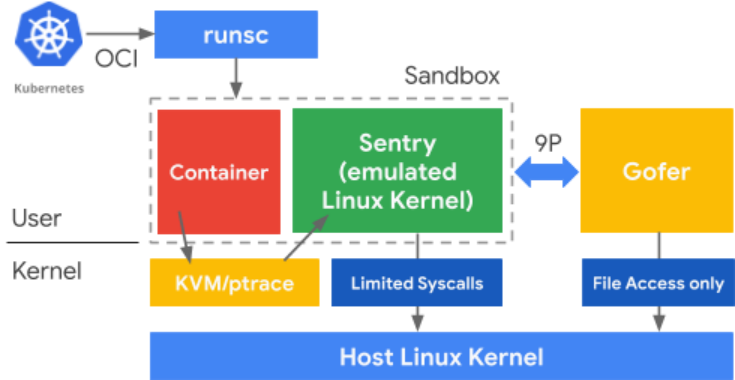
gVisor框架图[5]
WebAssembly
WebAssembly(以下简称Wasm),需要执行的代码以 .wasm 字节码的形式交由 Wasm runtime 执行。Wasm 的隔离机制可以分为内存隔离和对外部资源访问的隔离。首先,Wasm 程序只能访问 Wasm runtime 分配的一块线性内存,它所能访问到的区域被限制在这一块内存中。其次,不同于 C 程序可以直接向 OS 内核发起 syscall,Wasm 程序的所有外部资源访问必须经过 Runtime,并遵循 Runtime 的接口标准 - WASI(WebAssembly System Interface)。
WebAssembly框架图[6]
Bubblewrap
Bubblewrap 是一个轻量级的非特权沙箱工具,其特点在于无需 root 权限构建隔离环境。Bubblewrap 不内置镜像管理、网络编排,且无守护进程,也是通过内核的 namespace 与 seccomp 构建隔离环境,但本身不设置任何规则。它和 Docker container 的区别在于,Docker 有一套默认的限制规则,比如通过 seccomp 默认禁用一些危险系统调用、默认不挂载宿主机目录、默认隔离网络,用户直接 docker run 即可得到一个安全环境。Bubblewrap 则更像一把组装工具,把所有决定权交给调用方,比如要决定 Sandbox 中能看到哪些目录,就要靠 --ro-bind 或 --bind 逐一挂载进去;是否隔离网络,要靠 --unshare-net 显式声明等等。
Sandbox Runtime 的 GPU 支持现状
Sandbox 在通过对资源、权限进行隔离来提升安全性的同时,也限制了在 Sandbox 内对宿主机的 GPU 等硬件资源的正常使用。然而在 Agent 系统中,我们会遇到需要在 Sandbox 内使用 GPU 设备的场景,例如模型训练中编写自定义 CUDA 算子,或推理过程中大规模生成 embedding 等任务。为此,我们对各类 Sandbox Runtime 对 GPU 的支持现状做了简单梳理:
Container 使用 Nvidia 提供的扩展工具支持对宿主机 GPU 的访问。Nvidia Container Toolkit 在创建 Container 时会把必要的设备文件(/dev/nvidia0、/dev/nvidiactl 等)和驱动库(libcuda.so 等)挂载进 Sandbox 容器并设置环境变量,然后 Sandbox 内的应用可以透明地调用宿主机 GPU 资源。
gVisor 支持在特定版本的 Nvidia 开源驱动上使用 GPU 运行大多数 CUDA 应用。gVisor 在 Sandbox 内实现了一个代理驱动程序 nvproxy。nvproxy 负责处理 Sandbox 与宿主机上 Nvidia 驱动之间的交互,为Sandbox 内应用提供宿主机 GPU 的访问权限。
QEMU 通过 VFIO(由 Linux 内核提供的一种设备直通功能)实现对宿主机 GPU 设备的访问。首先将物理 GPU 从宿主机解绑并绑定到 vfio-pci 驱动,在启动 Sandbox 时通过 PCI-e Passthrough 将宿主机 GPU 设备添加到虚拟机中。Sandbox 内可安装原生 GPU 驱动,获得接近裸金属的 GPU 性能。Cloud Hypervisor 支持 GPU 访问的原理与 QEMU 类似,区别是 QEMU 对 VFIO 的支持更加成熟,对各类 GPU 的兼容性也优于 Cloud Hypervisor。两者均需提前在 BIOS 中开启 IOMMU。
Firecracker 不支持使用 GPU 资源。它基于精简的虚拟化模型,仅提供必需的硬件抽象,不支持 PCI-e 设备直通和 VFIO,因此无法在基于Firecracker 的 Sandbox 中直接使用 GPU 资源。
WebAssembly 不支持访问 GPU 资源。它本质上是字节码,不包含与硬件设备通信的系统调用指令,因此无法直接使用 GPU 资源,需要结合 WebGPU 来实现对 GPU 资源的访问。
不同业务场景下,Sandbox Runtime 该怎么选型?
Sandbox 隔离技术大致收敛为四类基本方案,其中每种方案同时具备相对优势和相对劣势,这本质上来源于底层隔离机制的侧重面不同。例如 Firecracker 官方宣称相对标准容器具备更强隔离性,但因其采取虚拟化设备实现隔离导致牺牲部分性能;同时 Firecracker 普遍相对 QEMU 而言更轻量高速,但也因其裁剪了部分设备模拟并限制某些系统调用而在通用性上有所欠缺。Firecracker 的设计案例体现出 Sandbox Runtime 的底层设计逻辑由三个要素构成:安全性、通用性和性能。
在 Agent 应用场景中,Sandbox Runtime 的工程选型本质上是个不可能三角,即必须在性能优化、安全边界与通用能力这三者之间 Trade-off:
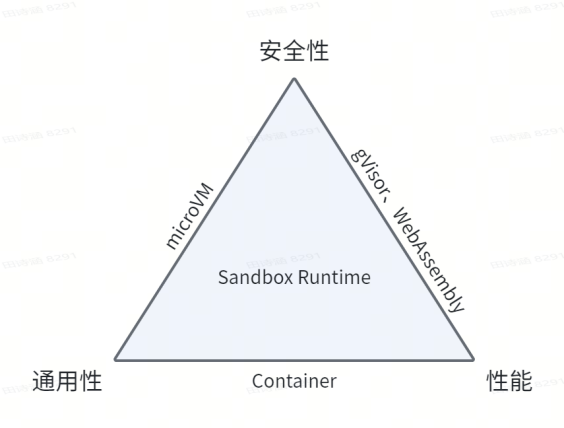
在实际选型阶段,需要面向具体的业务场景在安全性、通用性与性能这三者之间进行权衡,以下是我们针对常规业务场景给出一些 Sandbox Runtime 技术路线的选型建议:
|
业务场景 |
推荐主路线 |
备选路线 |
选型重点 |
治理建议 |
|---|---|---|---|---|
|
不可信代码执行(高风险) |
MicroVM(Firecracker、QEMU 等) |
gVisor |
隔离边界与逃逸面最小化 |
默认最小权限、短 TTL、强制出网白名单、全链路审计 |
|
Browser Agent / 交互自动化(中高风险) |
gVisor |
MicroVM(Firecracker、QEMU 等) |
交互性能与隔离平衡 |
会话状态可恢复、异常自动回收、网络策略细粒度控制 |
|
推理/训练辅助任务(资源重) |
容器 |
MicroVM 用于高敏任务 |
GPU/大内存效率与调度吞吐 |
风险分层调度、配额隔离、热点节点保护 |
|
低风险批处理/内部作业 |
容器 |
gVisor |
成本与密度优先 |
配额+限流+审计补齐治理,避免过度隔离带来的成本上升 |
|
插件化工具执行/轻函数场景 |
Wasm |
容器 |
启动快、资源轻、能力可控 |
明确能力边界与宿主 API 白名单,避免能力外溢 |
针对上述选型参考,对于涉及多样、异构任务作业的企业而言,根据具体业务要求灵活选用适合的 Sandbox Runtime 是一种合理且比较容易被快速迭代的技术路线;对于仅面向单一特征任务作业的企业或独立用户而言,基于单一 Runtime 并进行定制优化的方式是更具投入产出比的技术路线。
参考文献
-
Firecracker vs QEMU https://e2b.dev/blog/firecracker-vs-qemu
-
A field guide to sandboxes for AI https://www.luiscardoso.dev/blog/sandboxes-for-ai
-
The two patterns by which agents connect sandboxes https://www.langchain.com/blog/the-two-patterns-by-which-agents-connect-sandboxes
-
《Firecracker: Lightweight Virtualization for Serverless Applications》 https://www.amazon.science/publications/firecracker-lightweight-virtualization-for-serverless-applications
-
gvisor官方文档 https://gvisor.dev/docs/
-
Provably-Safe Sandboxing with WebAssembly https://www.cs.cmu.edu/~csd-phd-blog/2023/provably-safe-sandboxing-wasm/
-
GPU sandbox:https://northflank.com/blog/gpu-sandboxes
如果你喜欢我们的内容,欢迎点赞👍、收藏⭐️、关注➕我们!
也欢迎在评论区与我们互动!
你的支持是我们持续创作的动力!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)