PyTorch 入门:从0到50行代码掌握深度学习框架
前言
PyTorch 是目前学术界最流行的深度学习框架,Facebook 出品,动态图机制让调试变得无比简单。
学完本文,你将掌握:
-
张量(Tensor)的创建与操作
-
自动求导(Autograd)原理
-
DataLoader 数据加载
-
神经网络模块(nn.Module)搭建模型
-
完整训练循环的4个步骤
1. 张量(Tensor):PyTorch 的基本单位
张量是 PyTorch 的核心数据结构,可以理解为多维数组。0维=标量,1维=向量,2维=矩阵,3维+=高维数组。

Tensor Creation
PyTorch 提供了6种最常用的张量创建方式:
import torch
# 六种常见创建方式
a = torch.tensor([1, 2, 3]) # 直接创建一维张量
b = torch.zeros(3, 4) # 全零张量(3行4列)
c = torch.randn(3, 3) # 标准正态分布随机
d = torch.arange(0, 10, 2) # 等差数列:[0, 2, 4, 6, 8]
e = torch.eye(4) # 单位矩阵
f = torch.linspace(0, 1, 5) # 等分向量
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

2. 核心张量操作一览
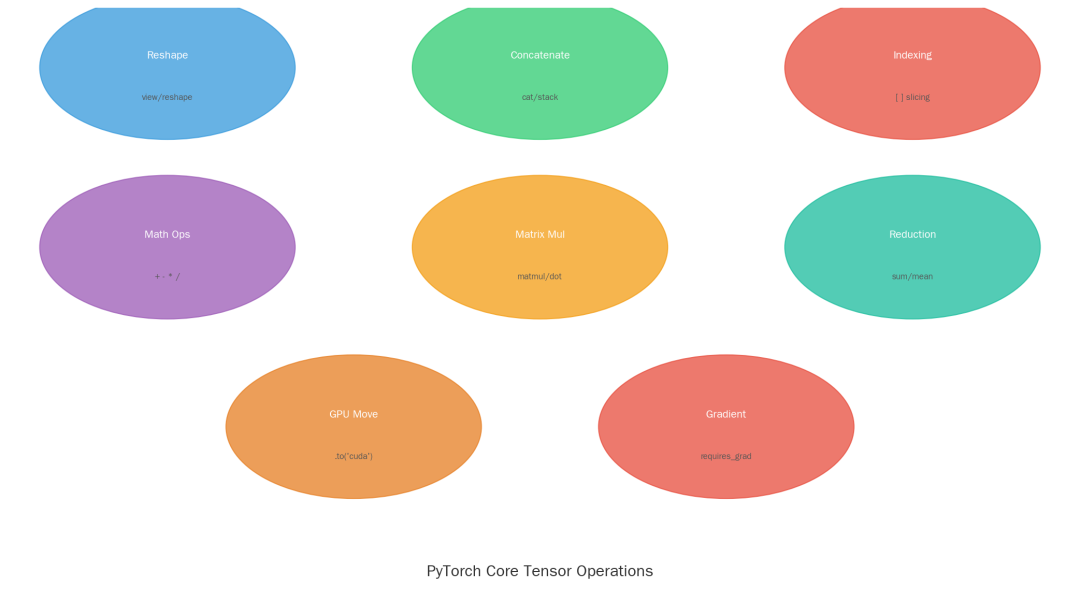
Tensor Operations
PyTorch 提供了丰富的张量操作,以下是高频使用的8种:
|
操作 |
函数 |
说明 |
|---|---|---|
|
变形 |
view / reshape |
改变张量形状,不改数据 |
|
拼接 |
cat / stack |
在某个维度拼接多个张量 |
|
索引 |
[ ] |
切片、选择性读取 |
|
数学 |
+ - * / |
逐元素运算 |
|
矩阵乘 |
matmul / dot |
矩阵乘法 |
|
聚合 |
sum / mean / max |
降维操作 |
|
GPU迁移 |
.to('cuda') |
搬到GPU上加速 |
|
求导 |
requires_grad |
开启自动求导 |
x = torch.randn(2, 3)
print(x.shape) # torch.Size([2, 3])
print(x.view(1, 6)) # 变形为 [1, 6]
print(x.sum(dim=0)) # 按列求和
3. 自动求导(Autograd):PyTorch 的精髓
Autograd 是 PyTorch 最核心的特性——自动计算梯度,无需手动求导!
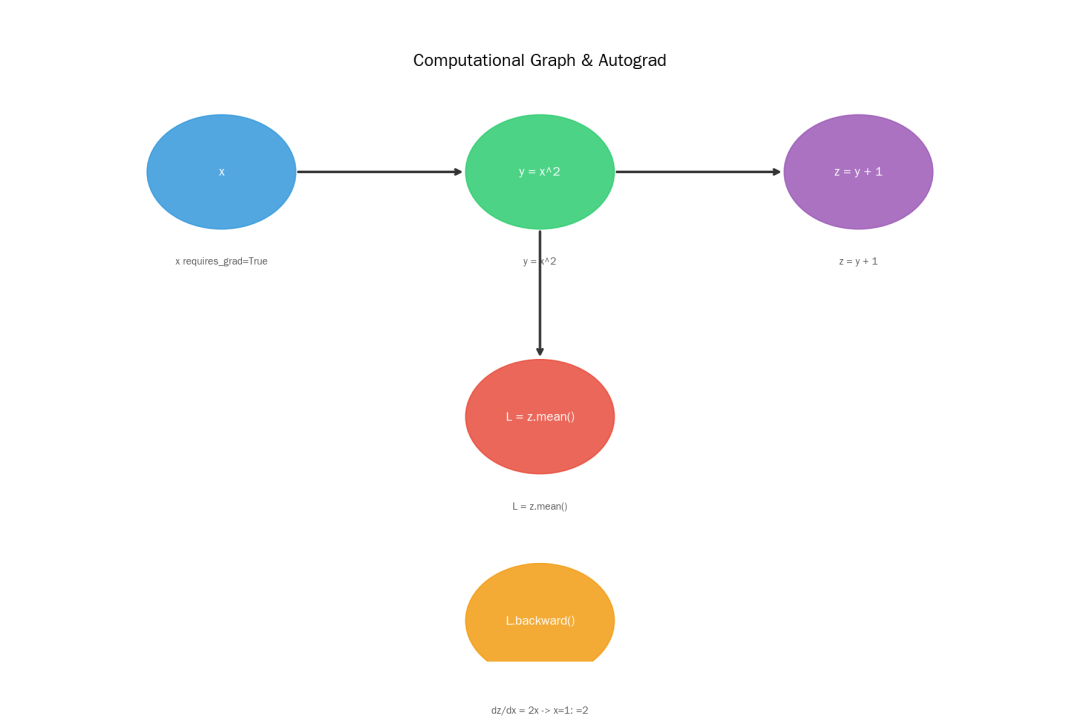
Autograd
import torch
# 创建张量,开启梯度跟踪
x = torch.tensor([1.0], requires_grad=True)
# 构建计算图
y = x ** 2 # y = x²
z = y + 1 # z = y + 1
L = z.mean() # L = z.mean()
# 一行代码自动求导
L.backward()
# 梯度已自动计算到 .grad 属性
print(x.grad) # dy/dx = 2x -> x=1 时 = 2
原理:PyTorch 内部构建了计算图(Computational Graph),每一步操作都记录下来,backward() 时自动从后往前反向传播求导。
4. DataLoader:高效加载数据
DataLoader 是 PyTorch 的数据加载器,负责:分批(batch)、打乱(shuffle)、多进程(num_workers)。
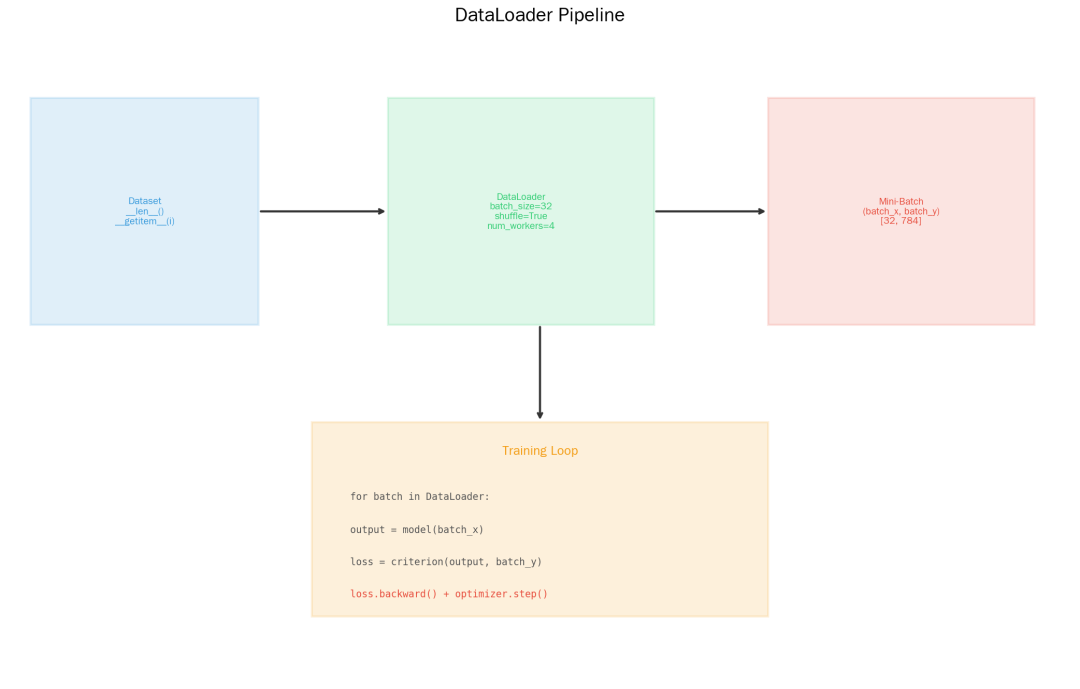
DataLoader
from torch.utils.data import TensorDataset, DataLoader
import torch
# 准备数据(用随机数据模拟)
X = torch.randn(1000, 784) # 1000个样本,784维特征
y = torch.randn(1000, 1) # 1000个标签
# TensorDataset:将特征和标签打包
dataset = TensorDataset(X, y)
# DataLoader:分批加载
loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
# 遍历
for batch_x, batch_y in loader:
print(batch_x.shape) # [32, 784]
break
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

为什么要用 DataLoader?
-
自动分批,不用手动切数据
-
shuffle=True 打乱顺序,提升泛化能力
-
num_workers>0 多进程并行加载,速度更快
5. 完整训练流程(4步走)
这是 PyTorch 训练的核心套路,所有模型都是这4步:

Training Pipeline
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
# ========== Step 1: 准备数据 ==========
X = torch.randn(1000, 20)
y = (X.sum(dim=1) > 0).float()
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
# ========== Step 2: 定义模型 ==========
model = nn.Sequential(
nn.Linear(20, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
# ========== Step 3: 损失 & 优化器 ==========
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# ========== Step 4: 训练循环 ==========
for epoch in range(100):
for batch_x, batch_y in loader:
optimizer.zero_grad() # ① 清零梯度
output = model(batch_x) # ② 前向传播
loss = criterion(output.squeeze(), batch_y) # ③ 计算损失
loss.backward() # ④ 反向传播
optimizer.step() # ⑤ 更新参数
if epoch % 20 == 0:
print(f"Epoch {epoch:3d} | Loss: {loss.item():.4f}")
核心4步口诀:zero_grad -> forward -> loss -> backward -> step
6. GPU 加速:让训练快50倍
PyTorch 支持 CUDA GPU 加速,一行代码切换设备:
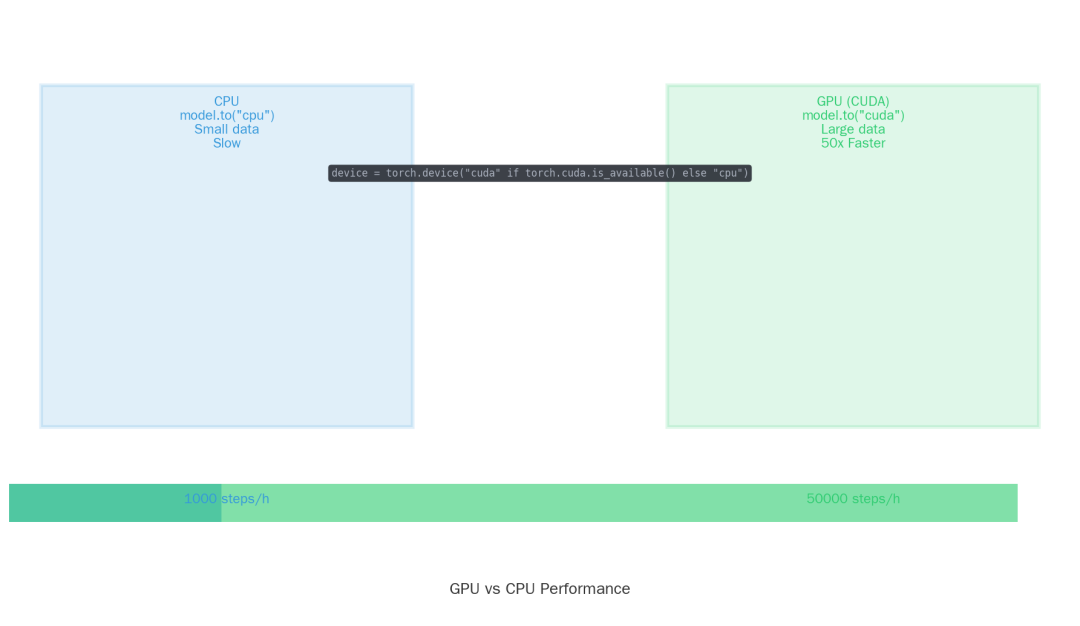
GPU vs CPU
import torch
# 检测并切换设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}") # cuda 或 cpu
# 模型和数据都迁移到 GPU
model = model.to(device)
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
# 后续所有计算自动在 GPU 上进行
output = model(batch_x) # GPU 加速!
性能对比(典型场景):
-
CPU:约 1,000 steps/h
-
GPU:约 50,000 steps/h(提升 50倍)
7. 常用模块速查表

Modules
|
模块 |
用途 |
示例 |
|---|---|---|
|
nn.Linear |
全连接层 |
nn.Linear(784, 10) |
|
nn.Conv2d |
卷积层 |
nn.Conv2d(3, 64, 3) |
|
nn.LSTM |
循环层 |
nn.LSTM(256, 128) |
|
nn.ReLU |
激活函数 |
nn.ReLU() |
|
nn.Softmax |
归一化 |
nn.Softmax(dim=1) |
|
nn.CrossEntropyLoss |
分类损失 |
nn.CrossEntropyLoss() |
|
nn.MSELoss |
回归损失 |
nn.MSELoss() |
|
optim.Adam |
优化器 |
optim.Adam(model.parameters()) |
|
nn.Dropout |
正则化 |
nn.Dropout(0.5) |
|
nn.Embedding |
词嵌入 |
nn.Embedding(10000, 256) |
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

8. 50 行代码入门 PyTorch 完整实战

50 Lines
上面代码已经展示了完整训练流程。这里特别强调保存和加载模型:
# 保存整个模型
torch.save(model, "model.pth")
# 加载(推荐:只保存参数)
torch.save(model.state_dict(), "model.pth") # 保存
model.load_state_dict(torch.load("model.pth")) # 加载
9. 欠拟合 vs 过拟合
训练模型时,最怕两个问题:欠拟合和过拟合。
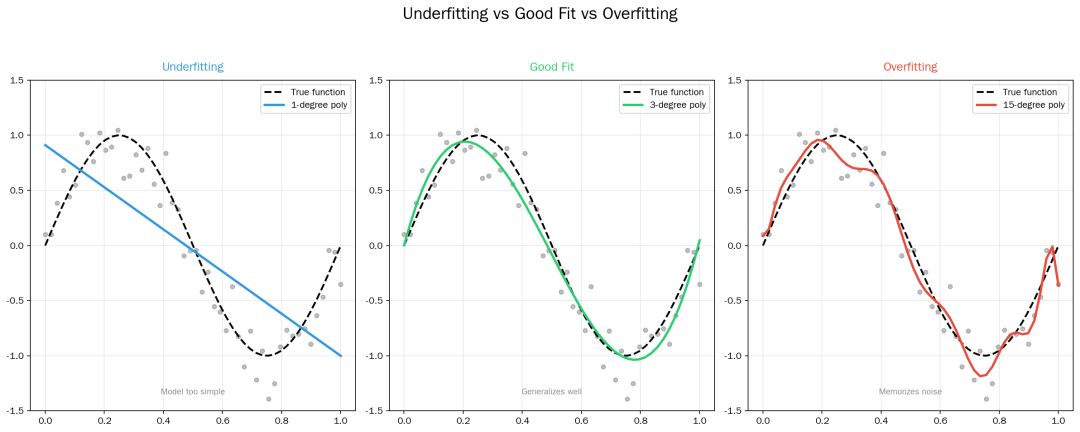
Under Over Fit
-
欠拟合:模型太简单,学不到数据的真实规律 -> 用更复杂的模型
-
过拟合:模型太复杂,死记硬背噪声数据 -> 用正则化、Dropout、数据增强
# 防止过拟合:添加 Dropout
model = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Dropout(0.5), # 训练时随机丢弃50%神经元
nn.Linear(64, 1)
)
10. 梯度下降可视化
梯度下降是所有优化器的基础——沿梯度的负方向迭代,找到Loss最低的点。
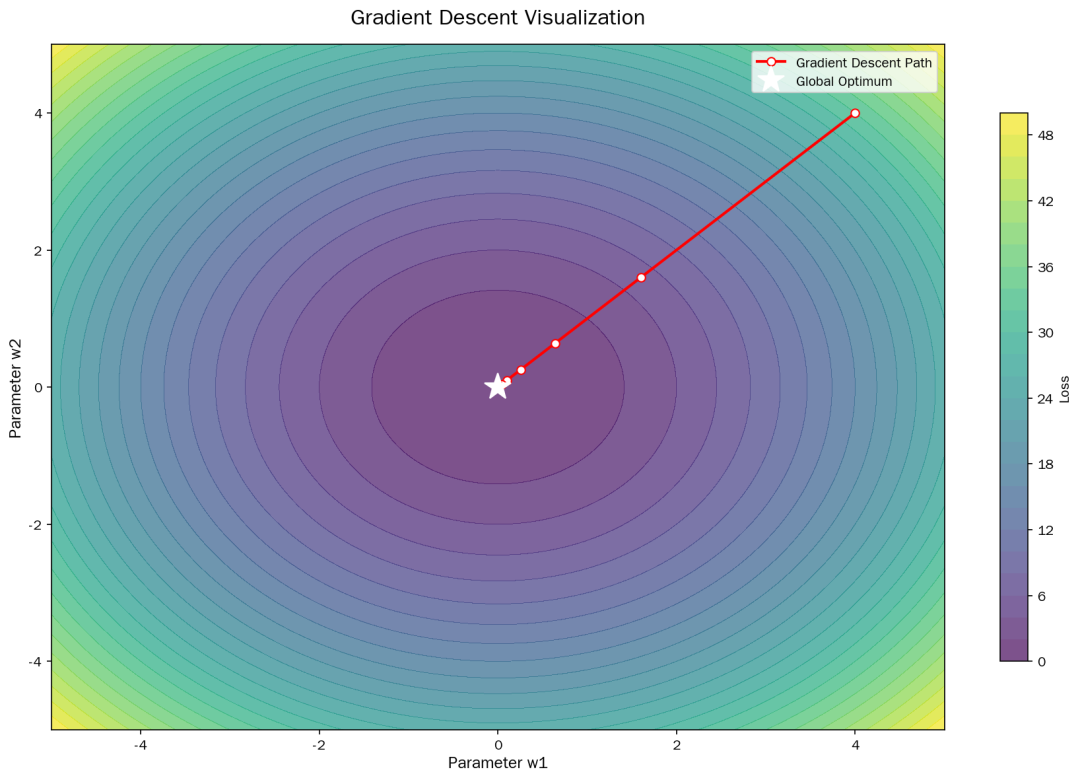
Gradient Descent
# 学习率(Learning Rate)非常关键
optimizer = optim.Adam(model.parameters(), lr=0.001) # lr 太大震荡,太小收敛慢
11. 优化器对比
不同优化器收敛速度差异很大:
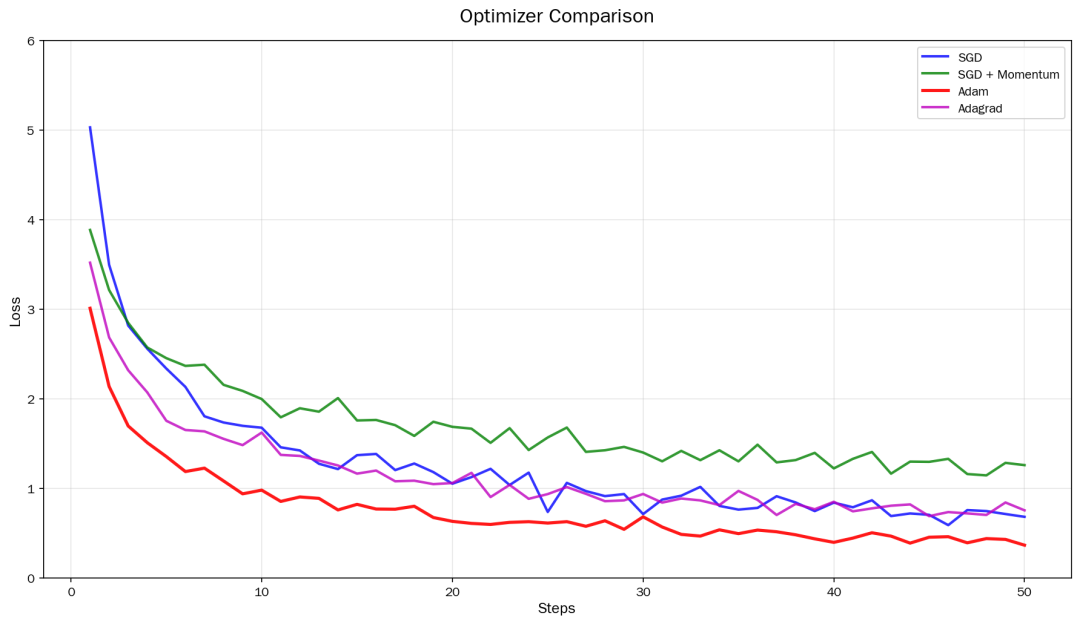
Optimizers
|
优化器 |
适用场景 |
特点 |
|---|---|---|
|
SGD |
简单任务 |
收敛慢但稳定 |
|
SGD + Momentum |
大数据集 |
加上冲量加速 |
| Adam | 通用首选 |
自适应学习率,效果好 |
|
Adagrad |
稀疏数据 |
对稀疏特征效果好 |
推荐:日常任务直接用 Adam,收敛快效果好。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

12. 训练日志解读
学会看 Loss 和 Accuracy 曲线,判断模型状态:
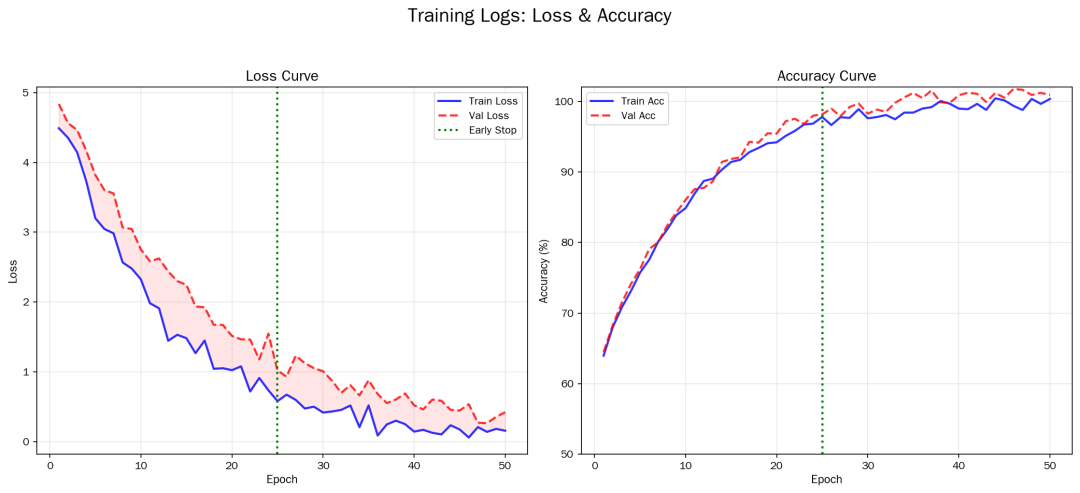
Training Logs
# 训练时打印日志
for epoch in range(100):
# ... 训练代码 ...
if epoch % 10 == 0:
print(f"Epoch {epoch:3d} | Train Loss: {train_loss:.4f} | Val Acc: {val_acc:.2f}%")
正常训练曲线:
-
训练Loss和验证Loss同步下降
-
如果验证Loss开始上升 -> 过拟合!需要早停或正则化
总结
|
知识点 |
核心函数 |
重要程度 |
|---|---|---|
|
张量创建 |
torch.tensor/zeros/randn |
5星 |
|
张量操作 |
view/cat/matmul/sum |
5星 |
|
自动求导 |
requires_grad + backward() |
5星 |
|
DataLoader |
DataLoader + TensorDataset |
5星 |
|
神经网络 |
nn.Sequential / nn.Module |
5星 |
|
GPU加速 |
.to("cuda") |
4星 |
|
优化器 |
optim.Adam / SGD |
4星 |
|
保存加载 |
torch.save / load_state_dict |
4星 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)