Oracle官方文档翻译《Database Concepts 26ai》第5章-索引与索引组织表
5 Indexes and Index-Organized Tables(5 索引与索引组织表)
索引是可以加速访问表行的模式对象。索引组织表是以索引结构存储的表。
-
Introduction to Indexes(索引简介)
索引是与表或表簇关联的可选结构,有时可以加速数据访问。 -
Overview of B-Tree Indexes(B 树索引概述)
B 树(Balanced Trees,平衡树的简称)是最常见的数据库索引类型。B 树索引是按范围划分的有序值列表。通过将键与一行或一个行范围关联,B 树为各种查询(包括精确匹配和范围搜索)提供了出色的检索性能。 -
Overview of Bitmap Indexes(位图索引概述)
在位图索引中,数据库为每个索引键存储一个位图。在传统的 B 树索引中,一个索引条目指向单行。在位图索引中,每个索引键存储指向多行的指针。 -
Overview of Function-Based Indexes(基于函数的索引概述)
基于函数的索引计算涉及一列或多列的函数或表达式的值,并将其存储在索引中。基于函数的索引可以是 B 树索引或位图索引。 -
Overview of Application Domain Indexes(应用程序域索引概述)
应用程序域索引是特定于应用程序的定制索引。 -
Overview of Scalar Quantized HNSW Indexes(标量量化 HNSW 索引概述)
标量量化分层可导航小世界(HNSW)索引可用于减少内存需求并加速相似性搜索。 -
Overview of Index-Organized Tables(索引组织表概述)
索引组织表是以 B 树索引结构的变体形式存储的表。相比之下,堆组织表将行插入到合适的位置。
Introduction to Indexes(索引简介)
索引是与表或表簇关联的可选结构,有时可以加速数据访问。
索引是模式对象,在逻辑上和物理上都独立于与之关联的对象中的数据。因此,您可以删除或创建索引,而不会在物理上影响被索引的表。
注意:
如果删除索引,应用程序仍然可以工作。但是,对先前已索引数据的访问速度可能会变慢。
打个比方,假设一位人力资源经理有一个放置纸板箱的架子。包含员工信息的文件夹被随机地插入到箱子中。员工 Whalen(ID 200)的文件夹在 1 号箱底部往上第 10 个文件夹,而员工 King(ID 100)的文件夹在 3 号箱的底部。为了找到一个文件夹,经理需要查看 1 号箱子中从下到上的每一个文件夹,然后从一个箱子移动到另一个箱子,直到找到该文件夹。为了加快访问速度,经理可以创建一个索引,按顺序列出每个员工 ID 及其文件夹位置:
ID 100:3 号箱,位置 1(底部)
ID 101:7 号箱,位置 8
ID 200:1 号箱,位置 10
.
.
.
类似地,经理可以为员工姓氏、部门 ID 等创建单独的索引。
本节包含以下主题:
- Advantages and Disadvantages of Indexes(索引的优势与劣势)
- Index Usability and Visibility(索引的可用性与可见性)
- Keys and Columns(键与列)
- Composite Indexes(复合索引)
- Unique and Nonunique Indexes(唯一索引与非唯一索引)
- Types of Indexes(索引类型)
- How the Database Maintains Indexes(数据库如何维护索引)
- Index Storage(索引存储)
Advantages and Disadvantages of Indexes(索引的优势与劣势)
索引的存在与否不需要更改任何 SQL 语句的措辞。
索引是到单行数据的快速访问路径。它只影响执行速度。给定一个已索引的数据值,索引会直接指向包含该值的行的位置。
当表的一列或多列上存在索引时,数据库在某些情况下可以从表中检索一小部分随机分布的行。索引是减少磁盘 I/O 的众多方法之一。如果堆组织表没有索引,则数据库必须执行全表扫描来查找值。例如,在未索引的 hr.departments 表中查询位置 2700,需要数据库搜索每个块中的每一行。随着数据量的增加,这种方法不易扩展。
索引的劣势包括:
- 手动创建索引通常需要对数据模型、应用程序和数据分布有深入的了解。
- 随着数据的变化,您必须重新审视之前关于索引的决策。索引可能停止有用,或者可能需要新的索引。
- 索引占用磁盘空间。
- 当对已索引的数据执行 DML 操作时,数据库必须更新索引,这会产生性能开销。
注意:
从 Oracle 数据库 19c 开始,Oracle 数据库可以持续监控应用程序工作负载,自动创建和管理索引。自动索引是作为一个以固定间隔运行的数据库任务来实现的。
在以下情况下考虑创建索引:
- 已索引的列被频繁查询,并且返回的行数占表中总行数的百分比很小。
- 已索引的列上存在引用完整性约束。索引是一种避免全表锁的方法,否则在更新父表主键、合并到父表或从父表删除时,将需要全表锁。
- 将在表上放置唯一键约束,并且您希望手动指定索引和所有索引选项。
另请参见:
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解有关自动索引的更多信息
- 《Oracle AI Database Licensing Information User Manual》(《Oracle AI 数据库许可信息用户手册》),了解不同版本和服务支持哪些功能的详细信息
Index Usability and Visibility(索引的可用性与可见性)
索引可以是可用的(默认)或不可用的,可以是可见的(默认)或不可见的。
这些属性定义如下:
-
可用性(Usability)
不可用索引会被优化器忽略,并且不会被 DML 操作维护。不可用索引可以提高批量加载的性能。您可以先使索引不可用,然后重建它,而不是删除索引然后再重新创建它。不可用索引和索引分区不消耗空间。当您使一个可用索引不可用时,数据库会删除其索引段。 -
可见性(Visibility)
不可见索引由 DML 操作维护,但默认情况下不会被优化器使用。使索引不可见是使其不可用或删除它的替代方案。不可见索引对于在删除索引前测试索引的移除,或在不影响整个应用程序的情况下临时使用索引特别有用。
另请参见:
“Overview of the Optimizer”(优化器概述),了解优化器如何选择执行计划
Keys and Columns(键与列)
键是您可以在其上构建索引的一组列或表达式。
尽管这些术语经常互换使用,但索引和键是不同的。索引是存储在数据库中的结构,用户使用 SQL 语句进行管理。键则完全是一个逻辑概念。
以下语句在示例表 oe.orders 的 customer_id 列上创建索引:
CREATE INDEX ord_customer_ix ON orders (customer_id);
在前面的语句中,customer_id 列是索引键。该索引本身名为 ord_customer_ix。
注意:
主键和唯一键自动具有索引,但您可能希望在外键上创建索引。
另请参见:
- “Data Integrity”(数据完整性)
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE INDEX语法和语义
Composite Indexes(复合索引)
复合索引,也称为串联索引,是对表中多列建立的索引。
在复合索引中放置列的顺序应最有利于检索数据的查询。这些列在表中不必是相邻的。
复合索引可以加速对 SELECT 语句的数据检索,在这些语句中,WHERE 子句引用了复合索引中的所有列或前导部分。因此,定义中使用的列顺序非常重要。通常,最常被访问的列放在前面。
例如,假设某个应用程序频繁查询 employees 表中的 last_name、job_id 和 salary 列。同时假设 last_name 具有高基数,这意味着不同值的数量相对于表行数来说很大。您可以按以下列顺序创建索引:
CREATE INDEX employees_ix
ON employees (last_name, job_id, salary);
访问所有三列、仅访问 last_name 列、或仅访问 last_name 和 job_id 列的查询会使用此索引。在此示例中,不访问 last_name 列的查询不会使用此索引。
注意:
在某些情况下,例如当前导列的基数非常低时,数据库可能使用此索引的跳跃扫描(参见“Index Skip Scan”(索引跳跃扫描))。
当满足以下任何条件时,同一表上可以存在具有相同列顺序的多个索引:
- 索引类型不同。
例如,您可以在相同的列上创建位图索引和 B 树索引。 - 索引使用不同的分区方案。
例如,您可以创建本地分区索引和全局分区索引。 - 索引具有不同的唯一性属性。
例如,您可以在同一组列上同时创建唯一索引和非唯一索引。
例如,对于以相同顺序排列的相同表列,可以存在非分区索引、全局分区索引和本地分区索引。任何时候只能有一个具有相同列数和列顺序的索引是可见的。
此功能使您能够迁移应用程序,而无需删除现有索引并使用不同属性重新创建它。此外,当索引键不断增加,导致数据库将新条目插入到同一组索引块时,此功能在 OLTP 数据库中非常有用。为了缓解此类"热点",您可以将索引从非分区索引演变为全局分区索引。
如果同一组列上的索引在类型或分区方案上没有不同,则这些索引必须使用不同的列排列。例如,以下 SQL 语句指定了有效的列排列:
CREATE INDEX employee_idx1 ON employees (last_name, job_id);
CREATE INDEX employee_idx2 ON employees (job_id, last_name);
另请参见:
《Oracle AI Database SQL Tuning Guide》(《Oracle AI 数据库 SQL 调优指南》),了解有关在同一组列上创建多个索引的更多信息
Unique and Nonunique Indexes(唯一索引与非唯一索引)
索引可以是唯一的或非唯一的。唯一索引保证表中没有两行在键列(或多列)上具有重复值。
例如,您的应用程序可能要求没有两个员工具有相同的员工 ID。在唯一索引中,每个数据值对应一个 rowid。叶块中的数据仅按键排序。
非唯一索引允许已索引的列中存在重复值。例如,employees 表的 first_name 列可能包含多个 Mike 值。对于非唯一索引,rowid 以排序顺序包含在键中,因此非唯一索引按照索引键和 rowid(升序)排序。
Oracle AI 数据库不会索引所有键列都为 null 的表行,位图索引或簇键列值为 null 的情况除外。
Types of Indexes(索引类型)
Oracle AI 数据库提供了几种索引方案,这些方案提供了互补的性能功能。
B 树索引是标准的索引类型。它们非常适用于高选择性索引(每个索引条目对应少数几行)和主键索引。用作串联索引时,B 树索引可以检索按已索引列排序的数据。B 树索引具有下表所示的不同子类型。
表 5-1 B 树索引子类型
| B 树索引子类型(B-Tree Index Subtype) | 描述(Description) | 了解更多(To Learn More) |
|---|---|---|
| 索引组织表(Index-organized tables) | 索引组织表与堆组织表不同,因为数据本身就是索引。 | “Overview of Index-Organized Tables”(索引组织表概述) |
| 反向键索引(Reverse key indexes) | 在此类索引中,索引键的字节被反转,例如,103 被存储为 301。字节的反转将索引中的插入操作分散到许多块上。 | “Reverse Key Indexes”(反向键索引) |
| 降序索引(Descending indexes) | 此类索引在特定的一列或多列上按降序存储数据。 | “Ascending and Descending Indexes”(升序和降序索引) |
| B 树簇索引(B-tree cluster indexes) | 此类索引用于索引表簇的簇键。 | “Overview of Indexed Clusters”(索引簇概述) |
下表显示了不使用 B 树结构的索引类型。
表 5-2 不使用 B 树结构的索引
| 类型(Type) | 描述(Description) | 了解更多(To Learn More) |
|---|---|---|
| 位图和位图连接索引(Bitmap and bitmap join indexes) | 在位图索引中,一个索引条目使用位图指向多行。相比之下,B 树索引条目指向单行。位图连接索引是两个或多个表连接的位图索引。 | “Overview of Bitmap Indexes”(位图索引概述) |
| 基于函数的索引(Function-based indexes) | 此类索引包含经过函数(如 UPPER 函数)转换或包含在表达式中的列。可以是基于函数的 B 树索引或位图索引。 | “Overview of Function-Based Indexes”(基于函数的索引概述) |
| 应用程序域索引(Application domain indexes) | 用户为特定于应用程序的域中的数据创建此类索引。物理索引不需要使用传统的索引结构,可以存储在 Oracle 数据库中作为表,也可以外部存储为文件。 | “Overview of Application Domain Indexes”(应用程序域索引概述) |
另请参见:
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何管理索引
- 《Oracle AI Database SQL Tuning Guide》(《Oracle AI 数据库 SQL 调优指南》),了解不同的索引访问路径
How the Database Maintains Indexes(数据库如何维护索引)
数据库在创建索引后会自动维护和使用索引。
索引自动反映其基础表的数据更改。更改的示例包括添加、更新和删除行。不需要用户执行任何操作。
即使插入了新行,已索引数据的检索性能几乎保持不变。但是,表上存在许多索引会降低 DML 性能,因为数据库也必须更新这些索引。
另请参见:
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解有关自动索引的更多信息
- 《Oracle AI Database Licensing Information User Manual》(《Oracle AI 数据库许可信息用户手册》),了解不同版本和服务支持哪些功能的详细信息
Index Storage(索引存储)
Oracle AI 数据库将索引数据存储在索引段中。
数据块中可用于索引数据的空间是数据块大小减去块开销、条目开销、rowid 以及每个已索引值的长度字节。
索引段的表空间可以是所有者的默认表空间,也可以是在 CREATE INDEX 语句中显式指定的表空间。为了便于管理,您可以将索引存储在其表所在的单独表空间中。例如,您可以选择不备份仅包含索引的表空间,因为这些索引可以重建,从而减少备份所需的时间和存储空间。
另请参见:
“Overview of Index Blocks”(索引块概述),了解索引块的类型(根块、分支块和叶块),以及索引条目如何存储在块中
Overview of B-Tree Indexes(B 树索引概述)
B 树(Balanced Trees,平衡树的简称)是最常见的数据库索引类型。B 树索引是按范围划分的有序值列表。通过将键与一行或一个行范围关联,B 树为各种查询(包括精确匹配和范围搜索)提供了出色的检索性能。
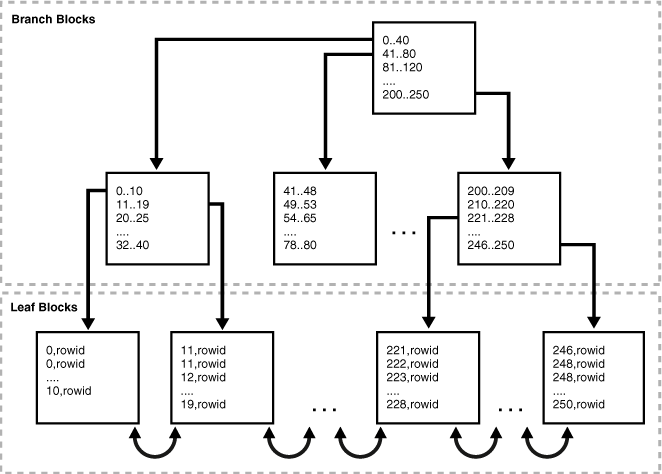
下图展示了 B 树索引的结构。该示例显示了对 department_id 列的索引,该列是 employees 表中的外键列。
Figure 5-1 Internal Structure of a B-tree Index(图5-1 B树索引的内部结构)
本节包含以下主题:
- Branch Blocks and Leaf Blocks(分支块与叶块)
- Index Scans(索引扫描)
- Reverse Key Indexes(反向键索引)
- Ascending and Descending Indexes(升序和降序索引)
- Index Compression(索引压缩)
Branch Blocks and Leaf Blocks(分支块与叶块)
B 树索引有两种类型的块:用于查找的分支块,以及用于存储键值的叶块。B 树索引的上层分支块包含指向较低层索引块的索引数据。
在图 5-1 中,根分支块有一个条目 0-40,它指向下一个分支级别的最左边块。此分支块包含诸如 0-10 和 11-19 之类的条目。这些条目中的每一个都指向一个叶块,该叶块包含落在该范围内的键值。
B 树索引是平衡的,因为所有叶块自动保持在同一深度。因此,从索引中的任何位置检索任何记录所花费的时间大致相同。索引的高度是从根块到叶块所需的块数。分支级别是高度减 1。在图 5-1 中,索引的高度为 3,分支级别为 2。
分支块存储的是在两个键之间做出分支决策所需的最小键前缀。此技术使数据库能够在每个分支块上容纳尽可能多的数据。分支块包含指向包含该键的子块的指针。键和指针的数量受块大小限制。
叶块包含每个已索引的数据值以及用于定位实际行的相应 rowid。每个条目都按键、rowid 排序。在叶块内部,键和 rowid 链接到其左右兄弟条目。叶块本身也是双向链接的。在图 5-1 中,最左边的叶块(0-10)链接到第二个叶块(11-19)。
注意:
基于字符数据列的索引按照数据库字符集中字符的二进制值进行排序。
Index Scans(索引扫描)
在索引扫描中,数据库通过使用语句指定的已索引列值遍历索引来检索行。如果数据库扫描索引以查找某个值,那么它将在 n 次 I/O 中找到该值,其中 n 是 B 树索引的高度。这是 Oracle AI 数据库索引背后的基本原理。
如果 SQL 语句只访问已索引的列,那么数据库将直接从索引读取值,而不是从表中读取。如果语句除了访问已索引列之外还访问未索引列,那么数据库将使用 rowid 来查找表中的行。通常,数据库通过交替读取索引块和表块来检索表数据。
-
Full Index Scan(全索引扫描)
在全索引扫描中,数据库按顺序读取整个索引。如果 SQL 语句中的谓词(WHERE子句)引用了索引中的列,则在某些情况下,即使没有指定谓词,全索引扫描也是可用的。全扫描可以消除排序,因为数据是按索引键排序的。 -
Fast Full Index Scan(快速全索引扫描)
快速全索引扫描是一种全索引扫描,在此扫描中,数据库访问索引本身中的数据而不访问表,并且数据库以无特定顺序读取索引块。 -
Index Range Scan(索引范围扫描)
索引范围扫描是对索引的有序扫描,其中索引的一个或多个前导列在条件中指定,并且对于一个索引键,可能的值有 0 个、1 个或多个。 -
Index Unique Scan(索引唯一扫描)
与索引范围扫描相比,索引唯一扫描必须只有 0 个或 1 个 rowid 与索引键关联。 -
Index Skip Scan(索引跳跃扫描)
索引跳跃扫描使用复合索引的逻辑子索引。数据库"跳跃"地遍历单个索引,就像在搜索独立的索引一样。 -
Index Clustering Factor(索引聚簇因子)
索引聚簇因子衡量与已索引值(如员工姓氏)相关的行顺序。随着有序程度的增加,聚簇因子会减小。
另请参见:
《Oracle AI Database SQL Tuning Guide》(《Oracle AI 数据库 SQL 调优指南》),了解有关索引扫描的详细信息
Full Index Scan(全索引扫描)
在全索引扫描中,数据库按顺序读取整个索引。如果 SQL 语句中的谓词(WHERE 子句)引用了索引中的列,则在某些情况下,即使没有指定谓词,全索引扫描也是可用的。全扫描可以消除排序,因为数据是按索引键排序的。
示例 5-1:全索引扫描
假设一个应用程序运行以下查询:
SELECT department_id, last_name, salary
FROM employees
WHERE salary > 5000
ORDER BY department_id, last_name;
在此示例中,department_id、last_name 和 salary 是索引中的复合键。Oracle AI 数据库执行索引的全扫描,按排序顺序(按部门 ID 和姓氏排序)读取它,并根据 salary 属性进行过滤。通过这种方式,数据库扫描的数据集比 employees 表更小(该表包含的列比查询中包含的列更多),并且避免了数据排序。
全扫描可能按如下方式读取索引条目:
50,Atkinson,2800,rowid
60,Austin,4800,rowid
70,Baer,10000,rowid
80,Abel,11000,rowid
80,Ande,6400,rowid
110,Austin,7200,rowid
.
.
.
Fast Full Index Scan(快速全索引扫描)
快速全索引扫描是一种全索引扫描,在此扫描中,数据库访问索引本身中的数据而不访问表,并且数据库以无特定顺序读取索引块。
当同时满足以下两个条件时,快速全索引扫描是全表扫描的替代方案:
- 索引必须包含查询所需的所有列。
- 查询结果集中不能出现包含所有空值的行。为了保证这种结果,索引中必须至少有一列具有:
NOT NULL约束- 应用于该列的谓词,该谓词可防止在查询结果集中考虑空值
示例 5-2:快速全索引扫描
假设一个应用程序发出以下查询,该查询不包含 ORDER BY 子句:
SELECT last_name, salary
FROM employees;
last_name 列具有 not null 约束。如果姓氏和薪水是索引中的复合键,则快速全索引扫描可以读取索引条目以获取请求的信息:
Baida,2900,rowid
Atkinson,2800,rowid
Zlotkey,10500,rowid
Austin,7200,rowid
Baer,10000,rowid
Austin,4800,rowid
.
.
.
Index Range Scan(索引范围扫描)
索引范围扫描是对索引的有序扫描,其中索引的一个或多个前导列在条件中指定,并且对于一个索引键,可能的值有 0 个、1 个或多个。
条件指定一个或多个表达式和逻辑(布尔)运算符的组合。它返回 TRUE、FALSE 或 UNKNOWN 值。
数据库通常使用索引范围扫描来访问选择性数据。选择性是查询选择的表中行的百分比,0 表示没有行,1 表示所有行。选择性与查询谓词(如 WHERE last_name LIKE 'A%')或谓词的组合相关联。随着值接近 0,谓词变得更具选择性;随着值接近 1,谓词变得选择性较低(或更无选择性)。
例如,用户查询姓氏以 A 开头的员工。假设 last_name 列已索引,条目如下:
Abel,rowid
Ande,rowid
Atkinson,rowid
Austin,rowid
Austin,rowid
Baer,rowid
.
.
.
数据库可以使用范围扫描,因为 last_name 列已在谓词中指定,并且每个索引键可能有多个 rowid。例如,有两个员工名为 Austin,因此有两个 rowid 与键 Austin 关联。
索引范围扫描可以在两侧有界,如在查询 ID 介于 10 和 40 之间的部门时,或只在一侧有界,如在查询 ID 大于 40 时。为了扫描索引,数据库通过叶块向后或向前移动。例如,扫描 10 到 40 之间的 ID 时,会定位第一个索引叶块,该块包含大于或等于 10 的最低键值。然后,扫描会水平穿过链接的叶节点列表,直到找到大于 40 的值。
Index Unique Scan(索引唯一扫描)
与索引范围扫描相比,索引唯一扫描必须只有 0 个或 1 个 rowid 与索引键关联。
当谓词使用等值运算符引用 UNIQUE 索引键中的所有列时,数据库会执行唯一扫描。索引唯一扫描一旦找到第一条记录就停止处理,因为不可能有第二条记录。
作为说明,假设一个用户运行以下查询:
SELECT *
FROM employees
WHERE employee_id = 5;
假设 employee_id 列是主键,并被索引,条目如下:
1,rowid
2,rowid
4,rowid
5,rowid
6,rowid
.
.
.
在这种情况下,数据库可以使用索引唯一扫描来定位 ID 为 5 的员工的 rowid。
Index Skip Scan(索引跳跃扫描)
索引跳跃扫描使用复合索引的逻辑子索引。数据库"跳跃"地遍历单个索引,就像在搜索独立的索引一样。
如果复合索引的前导列中只有少量不同值,而索引的非前导键中有许多不同值,则跳跃扫描是有益的。当查询谓词中未指定复合索引的前导列时,数据库可能会选择索引跳跃扫描。
示例 5-3:复合索引的跳跃扫描
假设您为 sh.customers 表中的客户运行以下查询:
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.example.com';
customers 表有一个列 cust_gender,其值要么是 M,要么是 F。假设在列 (cust_gender, cust_email) 上存在一个复合索引。以下示例显示了部分索引条目:
F,Wolf@company.example.com,rowid
F,Wolsey@company.example.com,rowid
F,Wood@company.example.com,rowid
F,Woodman@company.example.com,rowid
F,Yang@company.example.com,rowid
F,Zimmerman@company.example.com,rowid
M,Abbassi@company.example.com,rowid
M,Abbey@company.example.com,rowid
即使 WHERE 子句中未指定 cust_gender,数据库也可以使用此索引的跳跃扫描。
在跳跃扫描中,逻辑子索引的数量由前导列中不同值的数量决定。在前面的示例中,前导列有两个可能的值。数据库在逻辑上将索引分割成一个带有键 F 的子索引,和另一个带有键 M 的子索引。
在搜索电子邮件为 Abbey@company.example.com 的客户记录时,数据库首先搜索值为 F 的子索引,然后搜索值为 M 的子索引。从概念上讲,数据库处理查询的过程如下:
SELECT * FROM sh.customers WHERE cust_gender = 'F'
AND cust_email = 'Abbey@company.example.com'
UNION ALL
SELECT * FROM sh.customers WHERE cust_gender = 'M'
AND cust_email = 'Abbey@company.example.com';
另请参见:
《Oracle AI Database SQL Tuning Guide》(《Oracle AI 数据库 SQL 调优指南》),了解有关跳跃扫描的更多信息
Index Clustering Factor(索引聚簇因子)
索引聚簇因子衡量与已索引值(如员工姓氏)相关的行顺序。随着有序程度的增加,聚簇因子会减小。
聚簇因子可大致衡量使用索引读取整个表所需的 I/O 次数:
- 如果聚簇因子很高,那么 Oracle AI 数据库在大索引范围扫描期间会执行相对较多的 I/O。索引条目指向随机的表块,因此数据库可能不得不反复读取和重读相同的块,以检索索引指向的数据。
- 如果聚簇因子很低,那么 Oracle AI 数据库在大索引范围扫描期间会执行相对较少的 I/O。范围中的索引键倾向于指向同一个数据块,因此数据库不必反复读取和重读相同的块。
聚簇因子与索引扫描相关,因为它可以显示:
- 数据库是否会为大范围扫描使用索引
- 与索引键相关的表组织程度
- 如果必须按索引键对行进行排序,您是否应该考虑使用索引组织表、分区或表簇
示例 5-4:聚簇因子
假设 employees 表可以容纳在两个数据块中。表 5-3 描绘了这两个数据块中的行(省略号表示未显示的数据)。
表 5-3 Employees 表中两个数据块的内容
| 数据块 1(Data Block 1) | 数据块 2(Data Block 2) |
|---|---|
| 100 Steven King SKING … | 116 Shelli Baida SBAIDA … |
| 156 Janette King JKING … | 204 Hermann Baer HBAER … |
| 115 Alexander Khoo AKHOO … | 105 David Austin DAUSTIN … |
| . . . | 130 Mozhe Atkinson MATKINSO … |
| 166 Sundar Ande SANDE … | |
| 174 Ellen Abel EABEL … | |
| 149 Eleni Zlotkey EZLOTKEY … | |
| 200 Jennifer Whalen JWHALEN … | |
| . . . | |
| 137 Renske Ladwig RLADWIG … | |
| 173 Sundita Kumar SKUMAR … | |
| 101 Neena Kochar NKOCHHAR … |
行按照姓氏(以粗体显示)的顺序存储在块中。例如,数据块 1 的最底行描述的是 Abel,往上一行描述的是 Ande,以此类推,按字母顺序直到块 1 的最顶行 Steven King。块 2 的最底行描述的是 Kochar,往上一行描述的是 Kumar,以此类推,按字母顺序直到块中的最后一行 Zlotkey。
假设在姓氏列上存在一个索引。每个姓名条目对应一个 rowid。从概念上讲,索引条目如下所示:
Abel,block1row1
Ande,block1row2
Atkinson,block1row3
Austin,block1row4
Baer,block1row5
.
.
.
假设在员工 ID 列上存在一个独立的索引。从概念上讲,索引条目可能如下所示,员工 ID 几乎随机分布在两个块中:
100,block1row50
101,block2row1
102,block1row9
103,block2row19
104,block2row39
105,block1row4
.
.
.
以下语句查询 ALL_INDEXES 视图以获取这两个索引的聚簇因子:
SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
2 FROM ALL_INDEXES
3 WHERE INDEX_NAME IN ('EMP_NAME_IX','EMP_EMP_ID_PK');
INDEX_NAME CLUSTERING_FACTOR
-------------------- -----------------
EMP_EMP_ID_PK 19
EMP_NAME_IX 2
EMP_NAME_IX 的聚簇因子很低,这意味着单个叶块中相邻的索引条目倾向于指向相同数据块中的行。EMP_EMP_ID_PK 的聚簇因子很高,这意味着同一叶块中相邻的索引条目不太可能指向相同数据块中的行。
另请参见:
《Oracle AI Database Reference》(《Oracle AI 数据库参考》),了解 ALL_INDEXES 视图
Reverse Key Indexes(反向键索引)
反向键索引是一种 B 树索引,它在保持列顺序的同时物理上反转每个索引键的字节。
例如,如果索引键是 20,并且此键在标准 B 树索引中以十六进制存储的两个字节是 C1,15,那么反向键索引会将字节存储为 15,C1。
反转键解决了对 B 树索引右侧叶块的争用问题。在 Oracle Real Application Clusters(Oracle RAC)数据库环境中,多个实例反复修改同一个块时,这个问题尤其严重。例如,在 orders 表中,订单的主键是顺序的。集群中的一个实例添加了订单 20,而另一个实例添加了 21,每个实例都将其键写入索引右侧的同一叶块。
在反向键索引中,字节顺序的反转将插入操作分布到索引的所有叶键中。例如,像 20 和 21 这样在标准键索引中相邻的键,现在被存储在不同的块中,相隔很远。因此,顺序键插入的 I/O 分布更加均匀。
由于数据在存储时不是按列键排序的,因此反向键这种排列方式在某些情况下消除了执行索引范围扫描查询的能力。例如,如果用户发出一个查询,要求订单 ID 大于 20,那么数据库无法从包含此 ID 的块开始,然后水平地遍历叶块。
Ascending and Descending Indexes(升序和降序索引)
在升序索引中,Oracle AI 数据库按升序存储数据。默认情况下,字符数据按值每个字节中包含的二进制值排序,数值数据按从小到大排序,日期按从最早到最晚排序。
对于升序索引的示例,考虑以下 SQL 语句:
CREATE INDEX emp_deptid_ix ON hr.employees(department_id);
Oracle AI 数据库按 department_id 列对 hr.employees 表进行排序。它按升序(从 0 开始)将 department_id 和相应的 rowid 值加载到升序索引中。当使用该索引时,Oracle AI 数据库搜索排序后的 department_id 值,并使用关联的 rowid 来定位具有所请求 department_id 值的行。
通过在 CREATE INDEX 语句中指定 DESC 关键字,您可以创建降序索引。在这种情况下,索引在指定的一列或多列上按降序存储数据。如果表 5-3 中 employees.department_id 列上的索引是降序的,那么包含 250 的叶块将位于树的左侧,而包含 0 的块位于右侧。降序索引的默认搜索是从最高值到最低值。
当查询同时以升序和降序对某些列进行排序时,降序索引非常有用。例如,假设您按如下方式在 last_name 和 department_id 列上创建一个复合索引:
CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id
DESC);
如果用户查询 hr.employees 以升序(A 到 Z)排列姓氏并以降序(高到低)排列部门 ID,那么数据库可以使用此索引来检索数据,并避免额外的排序步骤。
另请参见:
- 《Oracle AI Database SQL Tuning Guide》(《Oracle AI 数据库 SQL 调优指南》),了解有关升序和降序索引搜索的更多信息
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE INDEX的ASC和DESC选项的描述
Index Compression(索引压缩)
为了减少索引中的空间,Oracle AI 数据库可以采用不同的压缩算法。
-
Prefix Compression(前缀压缩)
Oracle AI 数据库可以使用前缀压缩(也称为键压缩)来压缩 B 树索引或索引组织表中的主键列值的部分内容。前缀压缩可以大大减少索引消耗的空间。 -
Advanced Index Compression(高级索引压缩)
从 Oracle 数据库 12c 第 1 版(12.1.0.2)开始,对于堆组织表上受支持的索引,高级索引压缩改进了传统的前缀压缩。
Prefix Compression(前缀压缩)
Oracle AI 数据库可以使用前缀压缩(也称为键压缩)来压缩 B 树索引或索引组织表中的主键列值的部分内容。前缀压缩可以大大减少索引消耗的空间。
未压缩的索引条目由一部分组成。使用前缀压缩的索引条目由两部分组成:前缀条目(即分组部分)和后缀条目(即唯一或几乎唯一的部分)。数据库通过在一个索引块中的后缀条目之间共享前缀条目来实现压缩。
注意:
如果键未定义为具有唯一部分,则数据库通过将 rowid 附加到分组部分来提供该部分。
默认情况下,唯一索引的前缀由除最后一列之外的所有键列组成,而非唯一索引的前缀由所有键列组成。假设您按如下方式在 oe.orders 表的两列上创建一个复合唯一索引:
CREATE UNIQUE INDEX orders_mod_stat_ix ON orders ( order_mode, order_status );
在前面的示例中,索引键可能是 online,0。rowid 存储在条目的键数据部分,而不是键本身的一部分。
注意:
如果在单列上创建唯一索引,则 Oracle AI 数据库无法使用前缀键压缩,因为不存在公共前缀。
或者,假设您在相同的列上创建一个非唯一索引:
CREATE INDEX orders_mod_stat_ix ON orders ( order_mode, order_status );
同时假设 order_mode 和 order_status 列中存在重复值。索引块可能包含如下所示的条目:
online,0,AAAPvCAAFAAAAFaAAa
online,0,AAAPvCAAFAAAAFaAAg
online,0,AAAPvCAAFAAAAFaAAl
online,2,AAAPvCAAFAAAAFaAAm
online,3,AAAPvCAAFAAAAFaAAq
online,3,AAAPvCAAFAAAAFaAAt
在前面的示例中,键前缀由 order_mode 和 order_status 值的串联组成,如 online,0。后缀由 rowid 组成,如 AAAPvCAAFAAAAFaAAa。rowid 使得整个索引条目是唯一的,因为 rowid 本身在数据库中是唯一的。
如果前面的示例中的索引是使用默认前缀压缩(由 COMPRESS 关键字指定)创建的,那么像 online,0 和 online,3 这样的重复键前缀将被压缩。从概念上讲,数据库实现压缩的方式如下:
online,0
AAAPvCAAFAAAAFaAAa
AAAPvCAAFAAAAFaAAg
AAAPvCAAFAAAAFaAAl
online,2
AAAPvCAAFAAAAFaAAm
online,3
AAAPvCAAFAAAAFaAAq
AAAPvCAAFAAAAFaAAt
后缀条目(rowid)构成了索引行的压缩版本。每个后缀条目引用一个前缀条目,该前缀条目存储在与后缀相同的索引块中。
或者,您可以在创建使用前缀压缩的索引时指定前缀长度。例如,如果您指定了 COMPRESS 1,那么前缀将是 order_mode,后缀将是 order_status,rowid。对于索引块示例中的值,该索引将分解出重复出现的前缀 online,从概念上可以表示如下:
online
0,AAAPvCAAFAAAAFaAAa
0,AAAPvCAAFAAAAFaAAg
0,AAAPvCAAFAAAAFaAAl
2,AAAPvCAAFAAAAFaAAm
3,AAAPvCAAFAAAAFaAAq
3,AAAPvCAAFAAAAFaAAt
索引最多在每个叶块中存储一次特定的前缀。只有 B 树索引的叶块中的键会被压缩。在分支块中,键后缀可以被截断,但键本身不会被压缩。
另请参见:
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何使用压缩索引
- 《Oracle AI Database VLDB and Partitioning Guide》(《Oracle AI 数据库 VLDB 和分区指南》),了解如何为分区索引使用前缀压缩
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE INDEX的key_compression子句的描述
Advanced Index Compression(高级索引压缩)
从 Oracle 数据库 12c 第 1 版(12.1.0.2)开始,对于堆组织表上受支持的索引,高级索引压缩改进了传统的前缀压缩。
高级索引压缩的优势
前缀压缩在支持的索引类型、压缩率和使用简易性方面存在限制。与前缀压缩不同,前缀压缩为每个块使用固定的重复键消除,高级索引压缩在每个块的基础上使用自适应的重复键消除。
高级索引压缩的主要优点是:
- 数据库自动为每个块选择最佳压缩,使用多种内部算法,如列内前缀、重复键消除和 rowid 压缩。与前缀压缩不同,高级索引压缩不需要用户了解数据特征。
- 高级压缩适用于非唯一索引和唯一索引。前缀压缩在某些非唯一索引上效果很好,但在前导列没有很多重复项的索引上,压缩率较低。
- 压缩索引的使用方式与未压缩索引相同。该索引支持相同的访问路径:唯一键查找、范围扫描和快速全扫描。
- 索引可以从父表或包含的表空间继承高级压缩。
- 索引组织表和基于函数的索引支持高级索引压缩。索引组织表支持低压缩。基于函数的索引同时支持低压缩和高压缩。
高级索引压缩的工作原理
高级索引压缩在块级别工作,为每个块提供最佳压缩。数据库使用以下技术:
- 在索引创建期间,当叶块变满时,数据库会自动将该块压缩到最佳级别。
- 当由于 DML 而重组索引块时,如果数据库可以为传入的索引条目创建足够的空间,则不会发生块拆分。然而,在没有高级索引压缩的情况下执行 DML 时,当块变满时总是会发生索引块拆分。
ADVANCED HIGH 压缩
在 Oracle 数据库 12c 第 2 版(12.2)之前的版本中,唯一的高级索引压缩形式是低压缩 (COMPRESS ADVANCED LOW)。现在,您还可以指定高压缩 (COMPRESS ADVANCED HIGH),这是默认设置。带有 HIGH 选项的高级索引压缩具有以下优势:
- 在大多数情况下提供更高的压缩率,同时提高访问索引的查询的性能
- 采用比高级低压缩更复杂的压缩算法
- 将数据存储在压缩单元中,这是一种特殊的磁盘格式
注意:
当您应用 HIGH 压缩时,所有块都会进行压缩。当您应用 LOW 压缩时,数据库可能会让某些块保持未压缩状态。您可以使用统计信息来确定有多少块未压缩。
示例 5-5:创建具有高级高压缩的索引
此示例为 hr.employees 表上的索引启用高级索引压缩:
CREATE INDEX hr.emp_mndp_ix
ON hr.employees(manager_id, department_id)
COMPRESS ADVANCED;
以下查询显示了压缩类型:
SELECT COMPRESSION FROM DBA_INDEXES WHERE INDEX_NAME ='EMP_MNDP_IX';
COMPRESSION
-------------
ADVANCED HIGH
另请参见:
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何启用高级索引压缩
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE INDEX的key_compression子句的描述 - 《Oracle AI Database Reference》(《Oracle AI 数据库参考》),了解
ALL_INDEXES视图
Overview of Bitmap Indexes(位图索引概述)
在位图索引中,数据库为每个索引键存储一个位图。在传统的 B 树索引中,一个索引条目指向单行。在位图索引中,每个索引键存储指向多行的指针。
位图索引主要设计用于数据仓库或查询以即席方式引用多列的环境。可能适用位图索引的情况包括:
- 已索引列具有低基数,即不同值的数量相对于表行数来说很小。
- 已索引的表是只读的,或者不会因 DML 语句而受到重大修改。
以数据仓库为例,sh.customers 表有一个 cust_gender 列,只有两个可能的值:M 和 F。假设查询特定性别客户数量的情况很常见。在这种情况下,customers.cust_gender 列将是位图索引的候选列。
位图中的每个位对应于一个可能的 rowid。如果该位被设置,则具有相应 rowid 的行包含该键值。映射函数将位的位置转换为实际的 rowid,因此位图索引提供了与 B 树索引相同的功能,尽管它使用了不同的内部表示。
如果单行中的已索引列被更新,那么数据库会锁定索引键条目(例如,M 或 F),而不是锁定映射到已更新行的单个位。因为一个键指向许多行,对已索引数据的 DML 通常锁定所有这些行。因此,位图索引不适用于许多 OLTP 应用程序。
-
Example: Bitmap Indexes on a Single Table(示例:单表上的位图索引)
在此示例中,sh.customers表的某些列是位图索引的候选列。 -
Bitmap Join Indexes(位图连接索引)
位图连接索引是两个或多个表连接的位图索引。 -
Bitmap Storage Structure(位图存储结构)
Oracle AI 数据库使用 B 树索引结构来存储每个已索引键的位图。
另请参见:
- 《Oracle AI Database SQL Tuning Guide》(《Oracle AI 数据库 SQL 调优指南》),了解有关位图索引的更多信息
- 《Oracle AI Database Data Warehousing Guide》(《Oracle AI 数据库数据仓库指南》),了解如何在数据仓库中使用位图索引
Example: Bitmap Indexes on a Single Table(示例:单表上的位图索引)
在此示例中,sh.customers 表的某些列是位图索引的候选列。
考虑以下查询:
SQL> SELECT cust_id, cust_last_name, cust_marital_status, cust_gender
2 FROM sh.customers
3 WHERE ROWNUM < 8 ORDER BY cust_id;
CUST_ID CUST_LAST_ CUST_MAR C
---------- ---------- -------- -
1 Kessel M
2 Koch F
3 Emmerson M
4 Hardy M
5 Gowen M
6 Charles single F
7 Ingram single F
7 rows selected.
cust_marital_status 和 cust_gender 列具有低基数,而 cust_id 和 cust_last_name 则没有。因此,位图索引可能适用于 cust_marital_status 和 cust_gender。位图索引对其他列可能没有用处。相反,在这些列上建立唯一的 B 树索引可能会提供最有效的表示和检索方式。
表 5-4 说明了前一个示例中 cust_gender 列输出的位图索引。它由两个独立的位图组成,每一种性别一个。
表 5-4 单列的示例位图
| 值(Value) | 第 1 行(Row 1) | 第 2 行(Row 2) | 第 3 行(Row 3) | 第 4 行(Row 4) | 第 5 行(Row 5) | 第 6 行(Row 6) | 第 7 行(Row 7) |
|---|---|---|---|---|---|---|---|
| M | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| F | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
映射函数将位图中的每个位转换为 customers 表的 rowid。每个位的值取决于表中相应行的值。例如,值 M 的位图的第一位是 1,因为 customers 表第一行的性别是 M。位图 cust_gender='M' 在第 2、6 和 7 行的位是 0,因为这些行不包含 M 作为其值。
注意:
位图索引可以包含完全由空值组成的键,这与 B 树索引不同。对于某些 SQL 语句(如带有聚合函数COUNT的查询),对空值进行索引可能很有用。
一位研究客户人口统计趋势的分析师可能会问:"我们的女性客户中有多少是单身或离异?"这个问题对应以下 SQL 查询:
SELECT COUNT(*)
FROM customers
WHERE cust_gender = 'F'
AND cust_marital_status IN ('single', 'divorced');
位图索引可以通过计算结果位图中 1 的数量来高效地处理此查询,如表 5-5 所示。为了识别满足条件的客户,Oracle AI 数据库可以使用结果位图来访问该表。
表 5-5 两列的示例位图
| 值(Value) | 第 1 行(Row 1) | 第 2 行(Row 2) | 第 3 行(Row 3) | 第 4 行(Row 4) | 第 5 行(Row 5) | 第 6 行(Row 6) | 第 7 行(Row 7) |
|---|---|---|---|---|---|---|---|
| M | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| F | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| single | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| divorced | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| single 或 divorced ,并且 F | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
位图索引高效地合并了与 WHERE 子句中多个条件相对应的索引。在访问表本身之前,满足部分条件但不满足所有条件的行将被过滤掉。这种技术提高了响应时间,而且通常是显著提高。
Bitmap Join Indexes(位图连接索引)
位图连接索引是两个或多个表连接的位图索引。
对于表列中的每个值,索引存储已索引表中相应行的 rowid。相比之下,标准位图索引是在单个表上创建的。
位图连接索引是一种通过提前执行限制来减少必须连接的数据量的有效方法。举例说明位图连接索引何时有用,假设用户经常查询具有特定职位类型的员工数量。一个典型的查询可能如下所示:
SELECT COUNT(*)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
AND jobs.job_title = 'Accountant';
前面的查询通常会使用 jobs.job_title 上的索引来检索 Accountant 的行,然后是 job ID,并使用 employees.job_id 上的索引来查找匹配的行。为了从索引本身而不是通过扫描表来检索数据,您可以按如下方式创建位图连接索引:
CREATE BITMAP INDEX employees_bm_idx
ON employees (jobs.job_title)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id;
如下图所示,索引键是 jobs.job_title,被索引的表是 employees。
Figure 5-2 Bitmap Join Index(图5-2 位图连接索引)
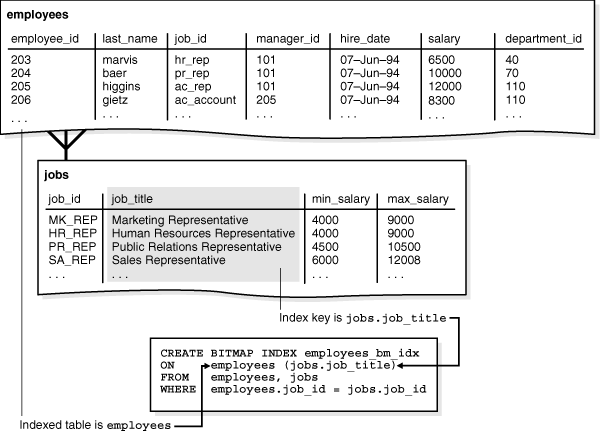
从概念上讲,employees_bm_idx 是下列查询中 jobs.title 列的索引(包含示例输出)。索引中的 job_title 键指向 employees 表中的行。查询会计师数量时可以使用该索引来避免访问 employees 和 jobs 表,因为索引本身包含了请求的信息。
SELECT jobs.job_title AS "jobs.job_title", employees.rowid AS
"employees.rowid"
FROM employees, jobs
WHERE employees.job_id = jobs.job_id
ORDER BY job_title;
jobs.job_title employees.rowid
----------------------------------- ------------------
Accountant AAAQNKAAFAAAABSAAL
Accountant AAAQNKAAFAAAABSAAN
Accountant AAAQNKAAFAAAABSAAM
Accountant AAAQNKAAFAAAABSAAJ
Accountant AAAQNKAAFAAAABSAAK
Accounting Manager AAAQNKAAFAAAABTAAH
Administration Assistant AAAQNKAAFAAAABTAAC
Administration Vice President AAAQNKAAFAAAABSAAC
Administration Vice President AAAQNKAAFAAAABSAAB
.
.
.
在数据仓库中,连接条件是维度表的主键列与事实表中的外键列之间的等值连接(它使用等值运算符)。位图连接索引在存储方面有时比物化连接视图(另一种预先物化连接的方法)高效得多。
另请参见:
《Oracle AI Database Data Warehousing Guide》(《Oracle AI 数据库数据仓库指南》),了解有关位图连接索引的更多信息
Bitmap Storage Structure(位图存储结构)
Oracle AI 数据库使用 B 树索引结构来存储每个已索引键的位图。
例如,如果 jobs.job_title 是位图索引的键列,那么一个 B 树存储索引数据。叶块存储各个位图。
示例 5-6:位图存储示例
假设 jobs.job_title 列具有唯一值 Shipping Clerk、Stock Clerk 和其他几个值。此索引的位图索引条目具有以下组成部分:
- 作为索引键的职位名称(job title)
- 一个低 rowid 和一个高 rowid,用于指定 rowid 的范围
- 该范围内特定 rowid 的位图
从概念上讲,此索引中的索引叶块可以包含如下条目:
Shipping Clerk,AAAPzRAAFAAAABSABQ,AAAPzRAAFAAAABSABZ,0010000100
Shipping Clerk,AAAPzRAAFAAAABSABa,AAAPzRAAFAAAABSABh,010010
Stock Clerk,AAAPzRAAFAAAABSAAa,AAAPzRAAFAAAABSAAc,1001001100
Stock Clerk,AAAPzRAAFAAAABSAAd,AAAPzRAAFAAAABSAAt,0101001001
Stock Clerk,AAAPzRAAFAAAABSAAu,AAAPzRAAFAAAABSABz,100001
.
.
.
相同的职位名称出现在多个条目中,这是因为 rowid 范围不同。
某个会话将一名员工的 job ID 从 Shipping Clerk 更新为 Stock Clerk。在这种情况下,该会话需要独占访问旧值(Shipping Clerk)和新值(Stock Clerk)的索引键条目。Oracle AI 数据库锁定由这两个条目指向的行——但不会锁定由 Accountant 或任何其他键指向的行——直到 UPDATE 提交。
位图索引的数据存储在一个段中。Oracle AI 数据库将每个位图存储在一个或多个片段中。每个片段占用单个数据块的一部分。
另请参见:
“User Segments”(用户段),了解不同类型的段以及如何创建段
Overview of Function-Based Indexes(基于函数的索引概述)
基于函数的索引计算涉及一列或多列的函数或表达式的值,并将其存储在索引中。基于函数的索引可以是 B 树索引或位图索引。
被索引的函数可以是算术表达式,也可以是包含 SQL 函数、用户定义的 PL/SQL 函数、包函数或 C 回调的表达式。例如,一个函数可以将两列中的值相加。
-
Uses of Function-Based Indexes(基于函数的索引的用途)
基于函数的索引对于评估在其WHERE子句中包含函数的语句非常有效。仅当查询中包含该函数时,数据库才会使用基于函数的索引。然而,当数据库处理INSERT和UPDATE语句时,它仍然必须评估该函数以处理该语句。 -
Optimization with Function-Based Indexes(使用基于函数的索引进行优化)
对于WHERE子句中带有表达式的查询,优化器可能会在基于函数的索引上使用索引范围扫描。
另请参见:
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何创建基于函数的索引
- 《Oracle AI Database Development Guide》(《Oracle AI 数据库开发指南》),了解有关使用基于函数的索引的更多信息
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解基于函数的索引的限制和使用说明
Uses of Function-Based Indexes(基于函数的索引的用途)
基于函数的索引对于评估在其 WHERE 子句中包含函数的语句非常有效。仅当查询中包含该函数时,数据库才会使用基于函数的索引。然而,当数据库处理 INSERT 和 UPDATE 语句时,它仍然必须评估该函数以处理该语句。
示例 5-7:基于算术表达式的索引
例如,假设您创建以下基于函数的索引:
CREATE INDEX emp_total_sal_idx
ON employees (12 * salary * commission_pct, salary, commission_pct);
数据库在处理如下查询时可以使用前面的索引(包含部分示例输出):
SELECT employee_id, last_name, first_name,
12*salary*commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * salary * commission_pct) < 30000
ORDER BY "ANNUAL SAL" DESC;
EMPLOYEE_ID LAST_NAME FIRST_NAME ANNUAL SAL
----------- ------------------------- -------------------- ----------
159 Smith Lindsey 28800
151 Bernstein David 28500
152 Hall Peter 27000
160 Doran Louise 27000
175 Hutton Alyssa 26400
149 Zlotkey Eleni 25200
169 Bloom Harrison 24000
示例 5-8:基于 UPPER 函数的索引
定义在 SQL 函数 UPPER(column_name) 或 LOWER(column_name) 上的基于函数的索引有助于不区分大小写的搜索。例如,假设 employees 表中的 first_name 列包含大小写混合的字符。您可以在 hr.employees 表上创建以下基于函数的索引:
CREATE INDEX emp_fname_uppercase_idx
ON employees ( UPPER(first_name) );
emp_fname_uppercase_idx 索引可以促进如下查询:
SELECT *
FROM employees
WHERE UPPER(first_name) = 'AUDREY';
示例 5-9:仅索引表中的特定行
基于函数的索引也可用于仅索引表中的特定行。例如,sh.customers 表中的 cust_valid 列具有 I 或 A 值。要仅索引 A 行,您可以编写一个函数,为除 A 行以外的任何行返回空值。您可以按如下方式创建索引:
CREATE INDEX cust_valid_idx
ON customers ( CASE cust_valid WHEN 'A' THEN 'A' END );
另请参见:
- 《Oracle AI Database Globalization Support Guide》(《Oracle AI 数据库全球化支持指南》),了解有关语言索引的信息
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解有关 SQL 函数的更多信息
Optimization with Function-Based Indexes(使用基于函数的索引进行优化)
对于 WHERE 子句中带有表达式的查询,优化器可能会在基于函数的索引上使用索引范围扫描。
当谓词具有高选择性时,即当它选择相对较少的行时,范围扫描访问路径尤其有益。在示例 5-7 中,如果在表达式 12*salary*commission_pct 上构建了索引,那么优化器可以使用索引范围扫描。
虚拟列对于加速访问从表达式派生的数据也很有用。例如,您可以将虚拟列 annual_sal 定义为 12*salary*commission_pct,并在 annual_sal 上创建基于函数的索引。
优化器通过解析 SQL 语句中的表达式,然后比较语句的表达式树与基于函数的索引来执行表达式匹配。此比较不区分大小写,并忽略空格。
不同的查询可能使用不同类型的索引扫描。
另请参见:
- “Overview of the Optimizer”(优化器概述)
- 《Oracle AI Database SQL Tuning Guide》(《Oracle AI 数据库 SQL 调优指南》),了解有关收集统计信息的更多信息
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何向表添加虚拟列
Overview of Application Domain Indexes(应用程序域索引概述)
应用程序域索引是特定于应用程序的定制索引。
可扩展索引可以:
- 适应对定制、复杂数据类型(如文档、空间数据、图像和视频剪辑)的索引(请参阅 )
- 利用专门的索引技术
您可以将特定于应用程序的索引管理例程封装为一个 indextype 模式对象,然后在表列或对象类型的属性上定义域索引。可扩展索引可以高效地处理特定于应用程序的运算符。
称为 cartridge 的应用程序软件控制着域索引的结构和内容。数据库与应用程序交互以构建、维护和搜索域索引。索引结构本身可以存储在数据库中作为索引组织表,或外部存储为文件。
另请参见:
- 《Oracle AI Database Development Guide》(《Oracle AI 数据库开发指南》),了解有关复杂数据类型的更多信息
- 《Oracle AI Database Data Cartridge Developer’s Guide》(《Oracle AI 数据库数据 Cartridge 开发人员指南》),了解有关在 Oracle AI 数据库可扩展性体系结构中使用数据 Cartridge 的信息
Overview of Scalar Quantized HNSW Indexes(标量量化 HNSW 索引概述)
标量量化分层可导航小世界(HNSW)索引可用于减少内存需求并加速相似性搜索。
在向量数据库的上下文中,标量量化是一种压缩或近似高维数据向量的方法,它通过独立地对向量的每个维度(或标量分量)进行量化来实现。这种方法用于减少向量数据库的存储需求,同时为相似性搜索等任务保留数据的基本结构。当简单性和低存储需求为高优先级时,标量量化尤其有益。
存储为浮点数的高维向量需要大量的存储空间。标量量化通过压缩向量来节省内存。例如,一个 128 维的向量,如果以 8 位 (INT8) 精度存储每个维度,仅需 128 字节的内存;而 32 位浮点存储 (Float32) 将需要 512 字节,64 位双精度存储 (Float64) 将需要 1024 字节。由于这种降低的存储需求,标量量化可以使向量数据库能够处理非常大的数据集,甚至包含数十亿个向量,否则这些数据集会由于存储限制而不切实际。
标量量化的另一个好处是提高了搜索速度。近似最近邻(ANN)搜索方法可以利用量化数据进行更快的比较,因为对整数或二进制码的操作比浮点计算更快。
对于 Oracle AI 数据库,实现的是均匀标量量化压缩方法,这意味着输入范围被划分为大小相等的区间。每个区间由一个量化级别表示,通常是其中点。每个维度的范围被划分为 2b2^b2b 个等区间,其中 b 是位数(例如,int8 为 8 位)。每个浮点值被映射到最近的量化级别。
另请参见:
- 《Oracle AI Database AI Vector Search User’s Guide》(《Oracle AI 数据库 AI 向量搜索用户指南》),了解 HNSW 索引语法和参数
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE VECTOR INDEX语句
Overview of Index-Organized Tables(索引组织表概述)
索引组织表是以 B 树索引结构的变体形式存储的表。相比之下,堆组织表将行插入到合适的位置。
在索引组织表中,行存储在基于表主键定义的索引中。B 树中的每个索引条目也存储非键列值。因此,索引就是数据,数据就是索引。应用程序像操作堆组织表一样操作索引组织表,使用 SQL 语句。
打个比方说明索引组织表,假设人力资源经理有一个书柜,里面放着纸板箱。每个箱子上都标有数字——1、2、3、4,等等——但箱子并没有按顺序放在架子上。相反,每个箱子里都包含一个指针,指向序列中下一个箱子的书架位置。
包含员工记录的文件夹存储在每个箱子里。文件夹按员工 ID 排序。员工 King 的 ID 是 100,这是最低的 ID,所以他的文件夹在 1 号箱的底部。员工 101 的文件夹在 100 的上面,102 在 101 的上面,以此类推,直到 1 号箱装满。序列中的下一个文件夹在 2 号箱的底部。
在这个类比中,按员工 ID 排序文件夹使得无需维护单独的索引即可高效地搜索文件夹。假设用户请求员工 107、120 和 122 的记录。经理可以按顺序搜索文件夹,并在找到时检索每个文件夹,而无需一个步骤搜索索引,另一步骤检索文件夹。
索引组织表通过主键或键的有效前缀提供了对表行的更快访问。在叶块中存在一行的非键列可以避免额外的数据块 I/O。例如,员工 100 的薪水存储在索引行本身中。此外,因为行是按主键顺序存储的,所以通过主键或前缀的范围访问只涉及最小的块 I/O。另一个好处是避免了单独的主键索引的空间开销。
当相关的数据片段必须存储在一起,或者数据必须按特定顺序物理存储时,索引组织表非常有用。这种类型的表的一个典型用途是用于信息检索、空间数据和 OLAP 应用程序。
-
Index-Organized Table Characteristics(索引组织表的特征)
数据库系统通过操作 B 树索引结构来执行对索引组织表的所有操作。 -
Index-Organized Tables with Row Overflow Area(带有行溢出区的索引组织表)
创建索引组织表时,可以指定一个单独的段作为行溢出区。 -
Secondary Indexes on Index-Organized Tables(索引组织表上的二级索引)
二级索引是在索引组织表上建立的索引。
另请参见:
- 《Oracle Spatial Developer’s Guide》(《Oracle 空间开发人员指南》),了解 Oracle Spatial and Graph 的概述
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何管理索引组织表
- 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE TABLE ... ORGANIZATION INDEX的语法和语义
Index-Organized Table Characteristics(索引组织表的特征)
数据库系统通过操作 B 树索引结构来执行对索引组织表的所有操作。
下表总结了索引组织表和堆组织表之间的区别。
表 5-6 堆组织表与索引组织表的比较
| 堆组织表(Heap-Organized Table) | 索引组织表(Index-Organized Table) |
|---|---|
| rowid 唯一标识一行。可以选择定义主键约束。 | 主键唯一标识一行。必须定义主键约束。 |
ROWID 伪列中的物理 rowid 允许建立二级索引。 |
ROWID 伪列中的逻辑 rowid 允许建立二级索引。 |
| 单行可以通过 rowid 直接访问。 | 对单行的访问可以通过主键间接实现。 |
| 顺序全表扫描以某种顺序返回所有行。 | 全索引扫描或快速全索引扫描以某种顺序返回所有行。 |
| 可以与其他表一起存储在表簇中。 | 不能存储在表簇中。 |
可以包含 LONG 数据类型的列和 LOB 数据类型的列。 |
可以包含 LOB 列,但不能包含 LONG 列。 |
| 可以包含虚拟列(仅支持关系堆表)。 | 不能包含虚拟列。 |
可以通过向 CREATE TABLE 语句添加 COMPRESS ADVANCED LOW 子句,使用高级低压缩来压缩索引组织表。高级低压缩是一种自适应的前缀压缩形式,它可以自主地为每个叶块计算最佳数量的前缀列,从而在无需任何用户干预的情况下实现块级别的最佳压缩。这包括在适当的情况下完全不压缩的可能性。这保证了不会出现负压缩。可以观察到更高的压缩率,且总体开销可忽略不计。
如果优化器认为查询可以作为快速全扫描执行,那么对索引组织表的扫描可以被卸载到 Exadata 智能扫描。这不需要任何用户干预。对于所有感兴趣的列都位于叶块中的索引组织表叶块,将支持完整的单元端处理。对于某些列位于溢出段中的情况,智能扫描将不处理此类列,数据库将完成扫描。
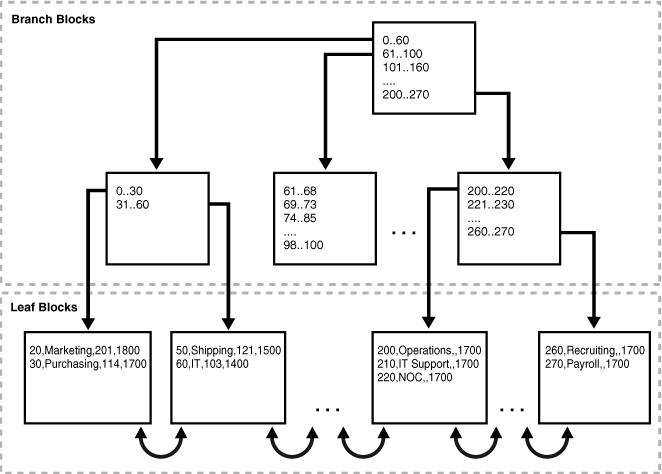
图 5-3 展示了一个索引组织的 departments 表的结构。叶块包含表的行,按主键顺序排列。例如,第一个叶块中的第一个值显示部门 ID 为 20,部门名称为 Marketing,经理 ID 为 201,位置 ID 为 1800。
Figure 5-3 Index-Organized Table(图5-3 索引组织表)
示例 5-10:索引组织表的扫描
索引组织表将所有数据存储在同一个结构中,并且不需要存储 rowid。如图 5-3 所示,索引组织表中的叶块 1 可能包含如下条目,按主键排序:
20,Marketing,201,1800
30,Purchasing,114,1700
索引组织表中的叶块 2 可能包含如下条目:
50,Shipping,121,1500
60,IT,103,1400
对索引组织表行按主键顺序进行扫描,会按以下顺序读取块:
- 块 1(Block 1)
- 块 2(Block 2)
示例 5-11:堆组织表的扫描
为了对比堆组织表与索引组织表中的数据访问,假设堆组织 departments 表段的块 1 包含以下行:
50,Shipping,121,1500
20,Marketing,201,1800
同一个表的块 2 包含以下行:
30,Purchasing,114,1700
60,IT,103,1400
此堆组织表的 B 树索引叶块包含以下条目,其中第一个值是主键,第二个值是 rowid:
20,AAAPeXAAFAAAAAyAAD
30,AAAPeXAAFAAAAAyAAA
50,AAAPeXAAFAAAAAyAAC
60,AAAPeXAAFAAAAAyAAB
对表行按主键顺序进行扫描,会按以下顺序读取表段块:
- 块 1(Block 1)
- 块 2(Block 2)
- 块 1(Block 1)
- 块 2(Block 2)
因此,此示例中的块 I/O 次数是索引组织表示例中次数的两倍。
另请参见:
- “Table Organization”(表组织),了解更多有关堆组织表的信息
- “Introduction to Logical Storage Structures”(逻辑存储结构简介),了解更多有关段和数据块之间关系的信息
Index-Organized Tables with Row Overflow Area(带有行溢出区的索引组织表)
创建索引组织表时,可以指定一个单独的段作为行溢出区。
在索引组织表中,B 树索引条目可能很大,因为它们包含整行,因此使用一个单独的段来包含这些条目是有用的。相比之下,B 树条目通常很小,因为它们只包含键和 rowid。
如果指定了行溢出区,那么数据库可以将索引组织表中的行分为以下部分:
-
索引条目部分
此部分包含所有主键列的列值、一个指向行溢出部分的物理 rowid,以及可选的少量非键列。此部分存储在索引段中。 -
溢出部分
此部分包含剩余的非键列的列值。此部分存储在溢出存储区段中。
另请参见:
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何使用
CREATE TABLE的OVERFLOW子句来设置行溢出区 - 《Oracle AI Database SQL Language Reference》(《Oracle AI 数据库 SQL 语言参考》),了解
CREATE TABLE ... OVERFLOW的语法和语义
Secondary Indexes on Index-Organized Tables(索引组织表上的二级索引)
二级索引是在索引组织表上建立的索引。
在某种意义上,二级索引是索引上的索引。它是一个独立的模式对象,与索引组织表分开存储。
Oracle AI 数据库对索引组织表使用称为逻辑 rowid 的行标识符。逻辑 rowid 是表主键的 base64 编码表示。逻辑 rowid 的长度取决于主键的长度。
由于插入操作,索引叶块中的行可以在块内或块之间移动。索引组织表中的行不会像堆组织表中的行那样迁移。因为索引组织表中的行没有永久的物理地址,所以数据库使用基于主键的逻辑 rowid。
例如,假设 departments 表是索引组织表。location_id 列存储每个部门的 ID。该表按如下方式存储行,最后一个值是位置 ID:
10,Administration,200,1700
20,Marketing,201,1800
30,Purchasing,114,1700
40,Human Resources,203,2400
在 location_id 列上的二级索引可能具有如下索引条目,其中逗号后面的值是逻辑 rowid:
1700,*BAFAJqoCwR/+
1700,*BAFAJqoCwQv+
1800,*BAFAJqoCwRX+
2400,*BAFAJqoCwSn+
二级索引使用既不是主键也不是主键前缀的列,为索引组织表提供快速高效的访问。例如,查询 ID 大于 1700 的部门名称时,可以使用二级索引来加速数据访问。
-
Logical Rowids and Physical Guesses(逻辑 Rowid 与物理猜测)
二级索引使用逻辑 rowid 来定位表行。 -
Bitmap Indexes on Index-Organized Tables(索引组织表上的位图索引)
索引组织表上的二级索引可以是位图索引。位图索引为每个索引键存储一个位图。
另请参见:
- “Rowid Data Types”(Rowid 数据类型),了解更多有关 rowid 和
ROWID伪列的使用 - “Chained and Migrated Rows”(行链接和行迁移),了解行为何迁移,以及为何迁移会增加 I/O 次数
- 《Oracle AI Database Administrator’s Guide》(《Oracle AI 数据库管理员指南》),了解如何在索引组织表上创建二级索引
- 《Oracle AI Database VLDB and Partitioning Guide》(《Oracle AI 数据库 VLDB 和分区指南》),了解有关在索引组织表分区上创建二级索引的信息
Logical Rowids and Physical Guesses(逻辑 Rowid 与物理猜测)
二级索引使用逻辑 rowid 来定位表行。
逻辑 rowid 包含一个物理猜测,这是索引条目首次创建时的物理 rowid。Oracle AI 数据库可以使用物理猜测直接探测索引组织表的叶块,从而绕过主键搜索。当行的物理位置发生变化时,即使逻辑 rowid 包含的物理猜测已过时,它仍然有效。
对于堆组织表,通过二级索引进行访问涉及二级索引的扫描,以及获取包含该行的数据块的额外 I/O。对于索引组织表,通过二级索引进行的访问取决于物理猜测的使用和准确性:
- 如果没有物理猜测,访问涉及两次索引扫描:一次是扫描二级索引,然后是扫描主键索引。
- 如果有物理猜测,访问取决于其准确性:
- 如果物理猜测准确,访问涉及一次二级索引扫描和获取包含该行的数据块的额外 I/O。
- 如果物理猜测不准确,访问涉及一次二级索引扫描和一次 I/O 来获取错误的数据块(如猜测所示),随后通过主键值对索引组织表进行索引唯一扫描。
Bitmap Indexes on Index-Organized Tables(索引组织表上的位图索引)
索引组织表上的二级索引可以是位图索引。位图索引为每个索引键存储一个位图。
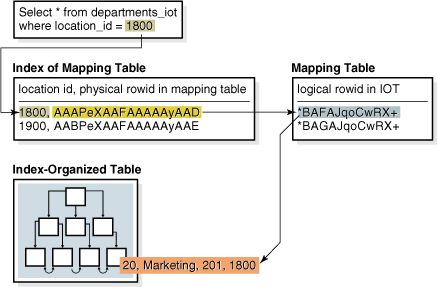
当索引组织表上存在位图索引时,所有位图索引都使用一个堆组织的映射表。映射表存储索引组织表的逻辑 rowid。每个映射表行存储一个对应于索引组织表行的逻辑 rowid。
数据库使用搜索键访问位图索引。如果数据库找到该键,则位图条目将转换为物理 rowid。对于堆组织表,数据库使用物理 rowid 访问基表。对于索引组织表,数据库使用物理 rowid 访问映射表,该映射表反过来产生一个逻辑 rowid,数据库再使用该逻辑 rowid 访问索引组织表。下图展示了对 departments_iot 表的查询进行索引访问的过程。
Figure 5-4 Bitmap Index on Index-Organized Table(图5-4 索引组织表上的位图索引)
注意:
索引组织表中行的移动不会导致在该索引组织表上构建的位图索引变得不可用。
另请参见:
“Rowids of Row Pieces”(行片段的 Rowid),了解物理 rowid 与逻辑 rowid 之间的区别

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)