基于 YOLOv8 的猫狗图像分类项目全流程复盘
一、项目背景目标与原理
随着计算机视觉技术的快速发展,图像分类作为深度学习的基础任务,在智能监控、内容审核等领域有着广泛应用。本项目以猫狗二分类为目标,基于 YOLOv8 轻量级图像分类模型,完整实现了从环境搭建、数据集处理、模型训练到可视化界面部署的全流程。项目核心目标包括:
- 搭建基于 PyTorch+CUDA 的 GPU 深度学习训练环境;
- 利用本地数据集训练一个高准确率的猫狗识别模型;
- 开发桌面端可视化界面,实现模型的便捷调用与结果展示。
1. 图像分类基本原理
简单来说就是让电脑学会认图: 把一张图片输入神经网络,网络自动提取图片里的轮廓、纹理、五官等特征,再对比学到的猫狗特征,最终判断图片是猫还是狗,输出识别结果与可信程度。
2. YOLOv8 分类网络工作流程
- 特征提取:通过多层卷积结构,从浅到深提取图片基础线条、高级动物特征;
- 特征融合:整合大小不同的特征信息,保证识别精准度;
- 分类判定:将提取好的特征进行运算,输出猫、狗两类别的概率值;
- 结果输出:选取概率最高的类别作为最终识别答案。
3. 迁移学习训练原理
本项目没有从零训练网络,而是借用成熟预训练模型: 模型提前在海量通用图片中学会了万物基础特征,我们只使用自家猫狗数据集微调训练,只修改最后分类层适配猫狗二分类,大幅缩短训练时间、快速提升识别精度。
4. GPU 加速原理
普通 CPU 逐行运算速度慢,RTX4060 显卡拥有大量并行计算核心,可同时批量处理多张图片数据,极大缩短训练时长,轻松完成模型迭代训练。
5. 早停机制原理
设置连续 5 轮训练精度无提升就自动停止训练,防止模型死记训练图片出现过拟合,保留识别泛化能力最强的最优模型。
二、为什么选择 YOLOv8 模型
-
上手简单,开发便捷 Ultralytics 框架封装完善,代码简洁,仅少量代码即可完成训练、测试、推理全流程,新手极易上手,项目落地效率高。
-
轻量化适配性强 YOLOv8n 轻量版本参数量小、占用显存低,本项目仅占用 0.246G 显存,笔记本中端显卡即可流畅运行,无需高性能设备。
-
训练速度快、效果稳定 相比传统 CNN 分类网络、老旧 YOLO 版本,v8 训练迭代更快,收敛速度高,本次仅 7 轮训练就达到95.9% 高识别准确率。
-
兼容性极强 完美适配 PyTorch 框架,全面支持 CUDA 显卡加速,Windows 系统运行稳定,极少出现环境报错、路径异常等问题。
-
实用性高,易部署 训练完成生成的模型体积仅 3MB,体积小巧推理迅速,单张图片推理仅 0.8ms,既可以代码调用,也能快速做成可视化桌面程序,日常使用十分方便。
-
功能拓展性强 不仅能做猫狗二分类,还可直接拓展多物种分类、目标检测等任务,学习成本低,后续项目延伸空间大。
三、环境配置与踩坑记录
1. 软硬件环境
表格
| 环境组件 | 配置详情 |
|---|---|
| 硬件平台 | NVIDIA GeForce RTX 4060 Laptop GPU(8GB 显存) |
| 操作系统 | Windows 11 |
| Python 版本 | 3.11.14 |
| PyTorch 版本 | 2.5.0+cu118(GPU 版) |
| 核心依赖 | Ultralytics 8.4.50、Pillow 12.2.0 |
2. 关键配置步骤与问题解决
项目初期因 PyTorch 与 CUDA 版本不兼容,多次出现torch.cuda.is_available()=False的报错,核心解决流程如下:
- 创建独立虚拟环境:通过 Anaconda 创建
yolo虚拟环境,避免依赖冲突; - 安装匹配版本 PyTorch:使用官方 whl 包安装与 CUDA 11.8 匹配的 PyTorch、TorchVision;若之前安装过CPU版本,在重新安装后若上方运行一直报错但通过在终端输入python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"正常,可在终端直接进行文件运行。
- 国内镜像加速安装依赖:通过阿里云镜像源安装 Ultralytics,解决 GitHub 下载超时问题;
- 解决 Windows 路径问题:在训练代码中设置
workers=0,避免多线程读取本地图片报错。
关键配置命令:
bash
运行
# 创建并激活虚拟环境
conda create -n yolo python=3.11
conda activate yolo
# 安装GPU版PyTorch(适配CUDA 11.8)
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu118
# 安装Ultralytics及依赖
pip install ultralytics pillow -i https://mirrors.aliyun.com/pypi/simple
四、数据集构建与加载
1. 数据集结构
本项目使用本地整理的cats_vs_dogs_small数据集,包含训练集、验证集和测试集,目录结构如下:
plaintext
目录
├── train/
│ ├── cat/(1000张猫图片)
│ └── dog/(1000张狗图片)
├── validation/
│ ├── cat/(500张猫图片)
│ └── dog/(500张狗图片)
└── test/
├── cat/(1000张猫图片)
└── dog/(1000张狗图片)
2. 数据集加载与验证
训练过程中,模型自动完成数据集扫描与验证,日志显示:
plaintext
train: ...\...\train... found 2000 images in 2 classes
val: ...\...\validation... found 1000 images in 2 classes
test: ...\...\test... found 2000 images in 2 classes
所有图片均无损坏,成功加载,为模型训练提供了可靠的数据基础。
五、模型训练与过程分析
1. 训练参数配置
本项目使用 YOLOv8n-cls 预训练模型,关键训练参数如下:
python
运行
from ultralytics import YOLO
import torch
# 检查GPU状态
print("GPU可用:", torch.cuda.is_available())
print("显卡型号:", torch.cuda.get_device_name(0))
# 加载模型并训练
model = YOLO("yolov8n-cls.pt")
model.train(
data=r"...",
epochs=20,
imgsz=224,
batch=16,
device=0,
workers=0,
patience=5,
amp=True
)
2. 模型结构与参数
YOLOv8n-cls 模型结构轻量化,仅包含 56 层网络,参数总量为 1,440,850 个,计算量为 3.4 GFLOPs,适合快速训练与部署:
plaintext
YOLOv8n-cls summary: 56 layers, 1,440,850 parameters, 1,440,850 gradients, 3.4 GFLOPs
Transferred 156/158 items from pretrained weights
AMP: checks passed
3. 训练过程与结果
训练过程中,模型在第 2 轮即达到最佳性能,后续因早停机制提前终止训练,完整训练日志如下:
plaintext
Epoch GPU_mem loss Instances Size
1/20 0.244G 0.3691 16 224: 100% ━━━━━━━━━━━━ 125/125 5.0it/s 24.9s
classes top1_acc top5_acc: 100% ━━━━━━━━━━━━ 32/32 5.2it/s 6.2s
all 0.953 1
2/20 0.244G 0.1557 16 224: 100% ━━━━━━━━━━━━ 125/125 6.4it/s 19.5s
classes top1_acc top5_acc: 100% ━━━━━━━━━━━━ 32/32 6.5it/s 4.9s
all 0.959 1
3/20 0.244G 0.1656 16 224: 100% ━━━━━━━━━━━━ 125/125 6.4it/s 19.4s
classes top1_acc top5_acc: 100% ━━━━━━━━━━━━ 32/32 6.1it/s 5.3s
all 0.957 1
...(后续轮次准确率无明显提升)
EarlyStopping: Training stopped early as no improvement observed in last 5 epochs.
Best results observed at epoch 2, best model saved as best.pt.
4. 模型评估
训练完成后,对最佳模型(best.pt)进行验证,结果显示:
- 验证集准确率:95.9%
- 推理速度:单张图片推理耗时 0.8ms(含预处理与后处理)
- 模型大小:仅 3.0MB,轻量化优势明显
六、可视化识别界面开发
为提升模型的易用性,基于tkinter开发了桌面端可视化界面,支持本地图片选择、实时识别与结果展示,核心代码如下:
python
运行
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO("runs/classify/train-6/weights/best.pt")
class CatDogRecognizer:
def __init__(self, root):
self.root = root
self.root.title("猫狗识别系统")
self.root.geometry("800x700")
# 界面组件初始化
self.img_label = tk.Label(root, text="请选择一张猫狗图片", bg="#f0f0f0")
self.result_label = tk.Label(root, text="等待识别...", font=("微软雅黑", 16), fg="blue")
self.select_btn = tk.Button(root, text="选择图片并识别", command=self.select_and_recognize,
font=("微软雅黑", 14), bg="#409eff", fg="white")
# 组件布局
self.img_label.pack(pady=20)
self.result_label.pack(pady=10)
self.select_btn.pack(pady=20)
def select_and_recognize(self):
# 选择本地图片
file_path = filedialog.askopenfilename(
title="选择图片",
filetypes=[("图片文件", "*.jpg;*.jpeg;*.png")]
)
if not file_path:
return
# 显示图片
img = Image.open(file_path)
img.thumbnail((500, 400))
self.tk_img = ImageTk.PhotoImage(img)
self.img_label.config(image=self.tk_img, text="")
# 模型预测
result = model.predict(file_path, verbose=False)[0]
class_name = result.names[result.probs.top1]
confidence = round(result.probs.top1conf.item() * 100, 2)
# 显示结果
self.result_label.config(
text=f"识别结果:{class_name}\n置信度:{confidence}%",
fg="green" if confidence > 90 else "orange"
)
if __name__ == "__main__":
root = tk.Tk()
app = CatDogRecognizer(root)
root.mainloop()
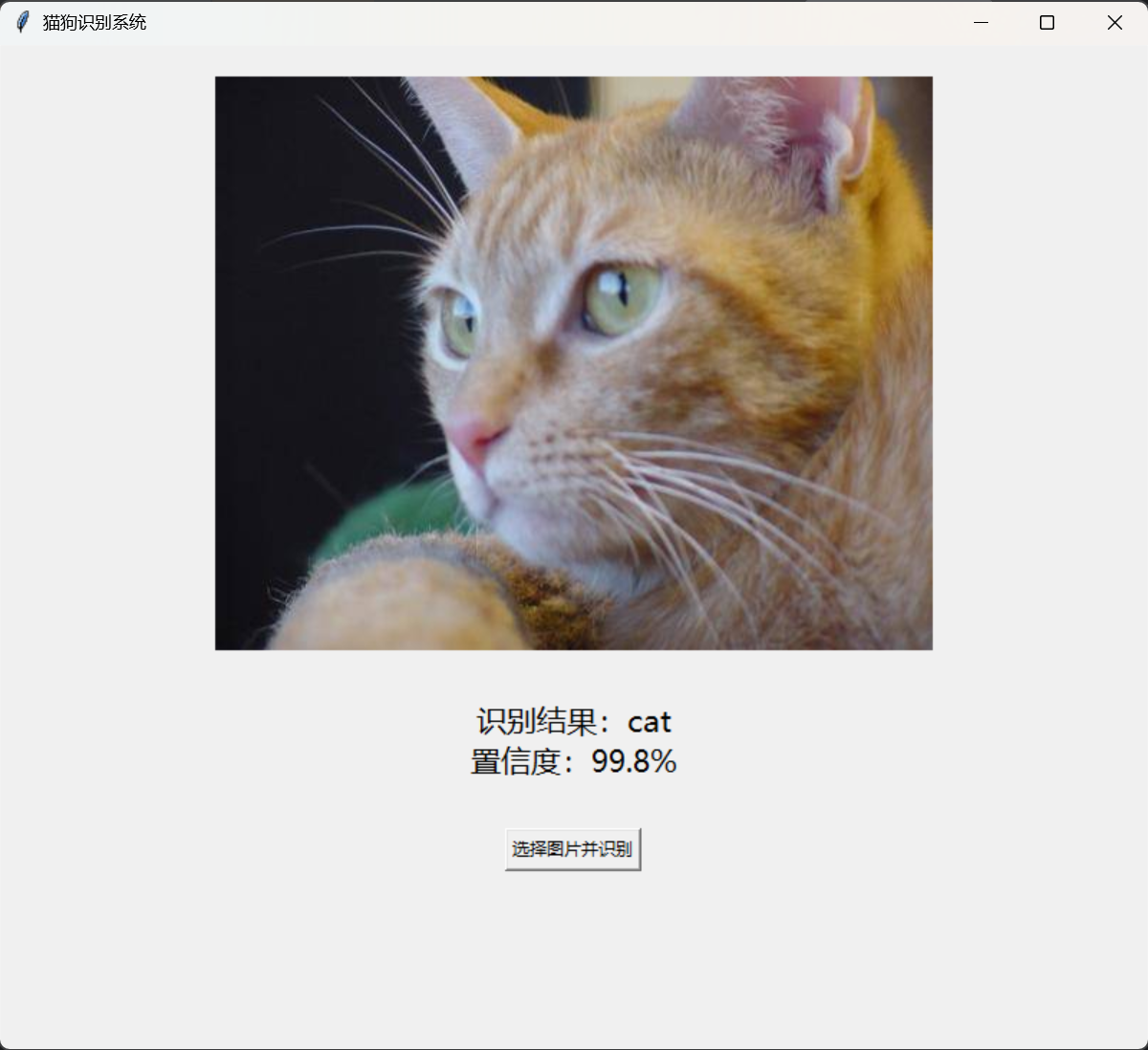
界面支持 JPG/PNG 格式图片的选择,识别结果以文字形式显示类别与置信度,操作简单直观,无需命令行即可完成模型调用。
七、项目总结与反思
1. 项目成果
- 成功搭建了基于 RTX 4060 的 GPU 深度学习训练环境,解决了版本兼容性问题;
- 训练得到的猫狗识别模型准确率达 95.9%,推理速度快,轻量化效果显著;
- 开发了可视化界面,实现了模型的便捷部署与使用。
2. 问题与优化方向
- 数据增强不足:当前数据集规模较小,后续可通过数据增强(如随机裁剪、翻转)提升模型泛化能力;
- 模型扩展空间:可尝试 YOLOv8s-cls 等更大模型,或引入迁移学习进一步提升准确率;
- 界面功能优化:可增加批量识别、结果保存等功能,提升用户体验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)