Redis 为什么这么快?单线程模型的极致性能解密
作为后端开发,我们每天都在使用 Redis。它凭借惊人的读写性能,成为了高并发系统的标配:单节点 Redis 在普通服务器上可以轻松达到每秒 10 万 + 的读 QPS 和 8 万 + 的写 QPS,比 MySQL 快 10-100 倍。在优化良好的情况下,甚至可以达到每秒 20 万 + 的 QPS。
但几乎所有人都会有一个灵魂拷问:Redis 是单线程的,为什么还能这么快?
在我们的认知里,多线程才能充分利用多核 CPU 的性能,单线程应该很慢才对。但 Redis 却用单线程模型做到了极致的性能,这背后到底有什么不为人知的秘密?
面试时,这个问题更是 100% 的必考题,而且面试官会不断深挖:
- Redis 真的是单线程的吗?哪些部分是多线程的?
- 为什么 Redis 选择单线程模型而不是多线程?
- 单线程怎么同时处理 10 万个客户端连接?
- epoll 到底是什么?为什么比 select 和 poll 快?
- Redis 6.0 引入的多线程是怎么回事?会有并发问题吗?
- Redis 快的根本原因是什么?
这篇文章,我们就从CPU 架构、操作系统内核、数据结构设计、IO 模型、内存管理五个维度,彻底搞懂 Redis 单线程高性能的底层原理。不仅会讲清楚 "是什么",更会讲明白 "为什么这么设计",以及 "这么设计带来了什么好处"。
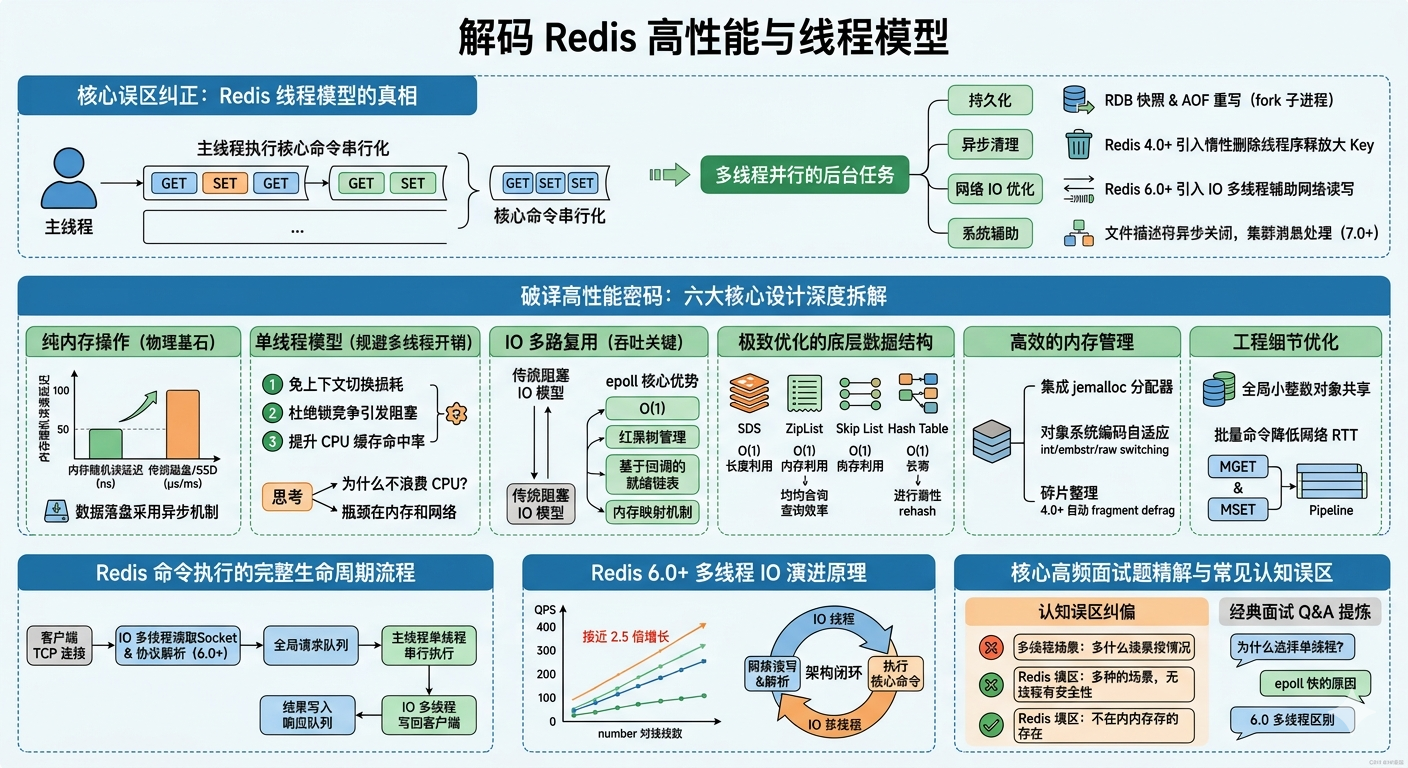
一、先纠正最大的误区:Redis 不是完全单线程的
在开始之前,我们必须先纠正一个流传最广、误导性最强的误区:Redis 并不是完全单线程的。
我们通常所说的 "Redis 是单线程的",指的是Redis 的核心命令执行模块是单线程的。也就是说,所有的读写命令(GET、SET、DEL、HGET 等)都是由一个主线程串行执行的。这是 Redis 能够保证数据一致性、避免并发问题的基础。
但 Redis 从始至终都不是完全单线程的,它有很多后台线程并行运行,负责处理那些耗时的、不需要串行执行的任务:
| Redis 版本 | 后台线程 | 负责的任务 |
|---|---|---|
| 所有版本 | 持久化线程 | 负责 RDB 快照生成和 AOF 重写(通过 fork 子进程实现) |
| 所有版本 | 关闭文件线程 | 负责异步关闭文件描述符,避免主线程阻塞 |
| Redis 4.0+ | 惰性删除线程 | 负责异步删除大 key,避免主线程阻塞 |
| Redis 6.0+ | IO 多线程 | 负责网络数据的读写和 Redis 协议解析 |
| Redis 7.0+ | 集群消息线程 | 负责处理 Redis Cluster 的节点间消息 |
这些后台线程不会影响核心命令的执行,它们和主线程并行运行,将那些耗时的操作从主线程中剥离出来,让主线程可以专注于处理核心的命令请求。
核心结论:Redis 的核心是单线程的,但整体是多线程的。单线程指的是命令执行的串行化,这是 Redis 高性能和高可靠性的基石。
二、Redis 快的根本原因:六大核心设计
Redis 的高性能不是单一因素决定的,而是多个优秀设计共同作用的结果。下面我们逐个深入拆解每一个核心设计,从底层原理讲清楚它们为什么能带来性能提升。
1. 纯内存操作:性能的物理基础
这是 Redis 快的最根本原因,也是所有其他优化的基础。Redis 的所有数据都存储在内存中,所有的读写操作都是在内存中完成的。
为了让大家直观地感受到内存和磁盘的性能差距,我们来看一组权威的性能数据:
| 存储介质 | 随机读延迟 | 顺序读带宽 | 相对速度(以 HDD 为基准) |
|---|---|---|---|
| DDR4 内存 | 100 纳秒 | 25GB/s | 100,000 倍 |
| NVMe SSD | 10 微秒 | 3.5GB/s | 1,000 倍 |
| SATA SSD | 100 微秒 | 500MB/s | 100 倍 |
| HDD 机械硬盘 | 10 毫秒 | 100MB/s | 1 倍 |
可以看到,内存的随机读速度是机械硬盘的 10 万倍,是 NVMe SSD 的 100 倍。这是什么概念?如果从内存中读取一个字节需要 1 秒钟,那么从机械硬盘中读取同一个字节需要 27.8 小时。
MySQL 等关系型数据库需要将数据持久化存储在磁盘上,每次读写都要经历磁盘 IO、系统调用、内核态和用户态切换等一系列开销。而 Redis 直接操作内存,从物理层面就获得了几个数量级的性能优势。
重要补充:即使 Redis 需要持久化数据,它也是通过异步的方式将数据写入磁盘,不会阻塞主线程的命令执行。这保证了 Redis 的读写操作永远都是内存级别的速度。
2. 单线程模型:避免了多线程的致命开销
很多人会问:现在 CPU 都是 8 核、16 核甚至更多,单线程不是浪费了 CPU 资源吗?为什么 Redis 不使用多线程模型?
答案是:对于 Redis 这种 IO 密集型应用来说,单线程模型反而比多线程模型更快。
多线程虽然可以利用多核 CPU,但也带来了三个致命的额外开销,这些开销在高并发场景下会超过多线程带来的收益。
(1)上下文切换开销
CPU 在多个线程之间切换时,需要保存当前线程的上下文(寄存器、程序计数器、栈指针等),然后加载下一个线程的上下文。这个过程非常耗时。
根据测试,一次线程上下文切换的开销大约是1-10 微秒。看起来不多,但如果每秒有 10 万次上下文切换,那么每秒就会有 0.1-1 秒的时间浪费在上下文切换上,CPU 的有效利用率会大幅下降。
而 Redis 的单线程模型没有任何上下文切换开销,CPU 可以 100% 地用于处理命令请求。
(2)锁竞争开销
多线程访问共享资源时,必须使用锁来保证线程安全。锁竞争会导致大量线程阻塞等待,严重影响性能。
根据 Amdahl 定律,即使只有 5% 的代码需要加锁,那么即使使用 100 个 CPU 核心,最大的加速比也只能达到 20 倍。而且锁的实现本身也有开销,比如 CAS 操作、内核态切换等。
Redis 的单线程模型不需要任何锁,所有命令都是串行执行的,完全避免了锁竞争的开销。
(3)缓存一致性开销
现代 CPU 都有多级缓存(L1、L2、L3),每个 CPU 核心都有自己的 L1 和 L2 缓存。当多个线程在不同的 CPU 核心上运行时,需要保证缓存的一致性,这会带来额外的总线流量和缓存失效开销。
而 Redis 的单线程模型永远运行在同一个 CPU 核心上,缓存命中率非常高,没有缓存一致性的开销。
为什么单线程不浪费 CPU?
很多人担心单线程会浪费多核 CPU 的性能,但实际上 Redis 的瓶颈从来都不是 CPU,而是内存和网络。
对于绝大多数业务场景来说,单线程已经足够处理所有的请求。如果单台 Redis 的性能不够,我们可以使用 Redis Cluster 分片集群,将数据分散到多个节点上,每个节点使用一个 CPU 核心,这样就可以充分利用多核 CPU 的性能了。
Redis 官方的观点:"Redis 的设计目标是在单个 CPU 核心上达到最高的性能。对于大多数应用来说,单线程已经足够快了。如果需要更高的性能,可以使用分片集群。"
3. IO 多路复用:单线程处理 10 万并发连接
单线程模型有一个致命的问题:怎么同时处理成千上万个客户端连接?
如果使用传统的阻塞 IO 模型,一个线程只能处理一个连接。当有 1 万个连接时,就需要 1 万个线程,这显然是不可能的。
Redis 使用了 IO 多路复用(IO Multiplexing) 技术,让一个线程可以同时处理成千上万个连接。这是 Redis 能够支撑高并发的核心技术之一。
什么是 IO 多路复用?
在讲解 IO 多路复用之前,我们先来看一下传统的阻塞 IO 模型:
while (true) {
socket = accept(); // 阻塞等待连接
read(socket, buffer); // 阻塞等待数据
process(buffer);
write(socket, response);
}在阻塞 IO 模型中,accept()和read()都是阻塞的。当没有连接或没有数据时,线程会一直阻塞,什么也做不了。
而 IO 多路复用的核心思想是:让一个线程同时监视多个文件描述符(socket),当某个文件描述符准备好读写时,操作系统会通知线程,线程再处理这个文件描述符的 IO 操作。
简单来说:一个线程,同时等待多个 IO 事件,哪个事件准备好了,就处理哪个事件。这样就可以用一个线程处理多个连接了。
Linux 下的三种 IO 多路复用实现
Linux 操作系统提供了三种 IO 多路复用的实现:select、poll 和 epoll。Redis 使用的是性能最好的 epoll 模型。
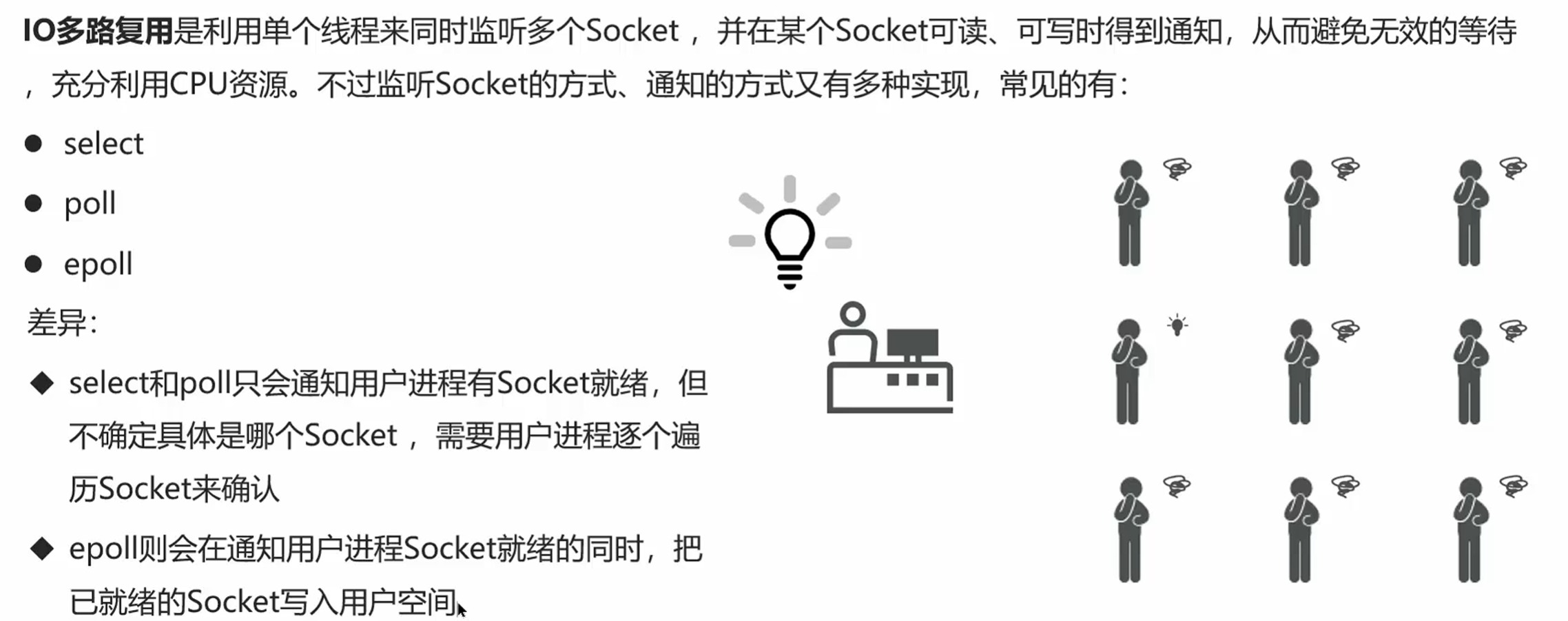
我们来深入对比一下这三种模型的区别:
| 特性 | select | poll | epoll |
|---|---|---|---|
| 最大连接数 | 1024(默认) | 无限制 | 无限制 |
| 时间复杂度 | O(n) | O(n) | O(1) |
| 工作原理 | 每次调用都要遍历所有连接,检查是否有事件 | 和 select 类似,只是没有最大连接数限制 | 使用红黑树存储连接,只返回有事件发生的连接 |
| 数据拷贝 | 每次调用都要将连接集合从用户态拷贝到内核态 | 每次调用都要将连接集合从用户态拷贝到内核态 | 使用内存映射,不需要拷贝 |
| 适用场景 | 连接数少(<1000)且连接活跃的场景 | 连接数中等(<10000)且连接活跃的场景 | 连接数多(>10000)且大部分连接不活跃的场景 |
epoll 的性能优势非常明显,尤其是在高并发场景下:
- 没有最大连接数限制,可以同时处理几十万甚至上百万个连接
- 时间复杂度是 O (1),不管有多少连接,性能都不会下降
- 使用内存映射技术,避免了内核态和用户态之间的数据拷贝
- 只返回有事件发生的连接,不需要遍历所有连接
epoll 的工作原理
epoll 的工作原理可以分为三个步骤:
- 创建 epoll 句柄:调用
epoll_create()创建一个 epoll 对象,内核会为这个对象分配一个红黑树和一个就绪链表 - 添加文件描述符:调用
epoll_ctl()将需要监视的 socket 添加到 epoll 的红黑树中,并注册事件回调函数 - 等待事件:调用
epoll_wait()等待事件发生。当某个 socket 有事件发生时,内核会将这个 socket 添加到就绪链表中,epoll_wait()会返回就绪链表中的所有 socket
正是因为有了 epoll,Redis 的单线程才能轻松处理 10 万 + 的并发连接。
4. 极致优化的数据结构
Redis 提供了丰富的数据结构,每种数据结构都经过了极致的性能优化,这也是 Redis 快的重要原因。
Redis 的数据结构设计遵循一个核心原则:在不同的场景下使用最合适的数据结构,以达到最高的性能。
下面我们深入讲解几个最常用的数据结构的优化:
(1)简单动态字符串(SDS)
Redis 没有使用 C 语言原生的字符串,而是自己实现了简单动态字符串(Simple Dynamic String,SDS)。
C 语言原生的字符串有很多缺陷:
- 获取字符串长度的时间复杂度是 O (n)
- 容易发生缓冲区溢出
- 不支持二进制安全
- 每次修改字符串都需要重新分配内存
而 Redis 的 SDS 完美解决了这些问题:
struct sdshdr {
int len; // 字符串的实际长度
int free; // 缓冲区中剩余的空闲空间
char buf[]; // 实际存储字符串的缓冲区
};SDS 的优势:
- O (1) 时间复杂度获取字符串长度
- 预分配内存和惰性释放,减少了内存分配的次数
- 二进制安全,可以存储任意二进制数据
- 兼容 C 语言原生字符串函数
(2)压缩列表(ZipList)
当列表、哈希表、有序集合的元素数量较少时,Redis 使用压缩列表存储。压缩列表是一块连续的内存,没有指针开销,内存利用率极高,遍历速度也很快。
压缩列表的结构如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
zlbytes:整个压缩列表的字节数zltail:最后一个元素的偏移量zllen:元素的数量entry:每个元素的内容zlend:压缩列表的结束标记
当元素数量超过阈值(默认是 512 个)或者单个元素的大小超过阈值(默认是 64 字节)时,Redis 会自动将压缩列表转换为双向链表或哈希表。
(3)跳表(Skip List)
Redis 的有序集合(ZSet)使用跳表实现,而不是平衡树(AVL 树或红黑树)。
跳表通过在有序链表上增加多层索引,将查找的时间复杂度从 O (n) 降低到 O (log n)。跳表的性能和平衡树相当,但有以下优势:
- 实现更简单,代码更容易维护
- 插入和删除操作更快,不需要旋转操作
- 支持范围查询,比平衡树更高效
(4)哈希表(Hash Table)
Redis 的哈希表使用链地址法解决哈希冲突,并且采用了渐进式 rehash 的方式,避免了 rehash 时的性能抖动。
渐进式 rehash 的原理:
- 同时保留两个哈希表:旧表和新表
- 每次对哈希表进行操作时,将旧表中的一部分数据迁移到新表
- 当旧表中的所有数据都迁移完成后,释放旧表,使用新表
这样就将一次耗时的大 rehash 操作分散到了多次操作中,避免了主线程阻塞。
5. 高效的内存管理
Redis 自己实现了内存分配器,对内存管理进行了极致的优化,减少了内存碎片,提高了内存分配效率。
(1)内存分配器
Redis 支持多种内存分配器:glibc 的 malloc、jemalloc 和 tcmalloc。默认使用 jemalloc,因为它在多线程环境下的性能更好,内存碎片更少。
jemalloc 将内存分成不同大小的内存块,每个大小的内存块都有自己的缓存池。当需要分配内存时,直接从对应的缓存池中获取,不需要向操作系统申请,大大提高了内存分配的效率。
(2)Redis 对象系统
Redis 的所有数据都以对象的形式存储,每个对象都有一个类型和一个编码。Redis 会根据对象的大小和数量,自动选择最合适的编码方式,以节省内存和提高性能。
例如,字符串对象有三种编码:
int:存储整数,直接将整数存储在指针中,不需要额外的内存embstr:存储短字符串(<=44 字节),对象头和字符串数据在同一块连续的内存中raw:存储长字符串(>44 字节),对象头和字符串数据在不同的内存块中
(3)内存碎片整理
Redis 4.0 以后引入了主动内存碎片整理功能,可以在不阻塞主线程的情况下,整理内存碎片,提高内存利用率。
6. 其他优化细节
除了上面五个核心设计,Redis 还有很多其他的优化细节:
- 命令优化:Redis 的所有命令都经过了极致优化,很多命令的时间复杂度都是 O (1)
- 对象共享:对于常用的小对象(比如 0-9999 的整数),Redis 会共享这些对象,避免重复创建
- 虚拟内存:当内存不足时,Redis 可以将不常用的数据交换到磁盘上,需要时再加载到内存中
- 批量操作:支持批量命令(MGET、MSET 等),减少了网络往返的次数
- 管道(Pipeline):支持管道操作,可以一次性发送多个命令,大大提高了吞吐量
三、Redis 命令执行的完整流程
为了让大家更清楚地理解 Redis 的工作原理,我们来看一个完整的命令执行流程:
- 客户端建立连接:客户端通过 TCP 连接到 Redis 服务器
- IO 线程读取数据:Redis 的 IO 线程从 socket 中读取客户端发送的数据
- 协议解析:IO 线程解析 Redis 协议,将数据转换为命令和参数
- 命令入队:IO 线程将解析后的命令放入一个队列中
- 主线程执行命令:主线程从队列中取出命令,串行执行
- 生成响应:主线程执行完命令后,生成响应数据
- 响应入队:主线程将响应数据放入响应队列中
- IO 线程发送响应:IO 线程从响应队列中取出响应数据,写回客户端
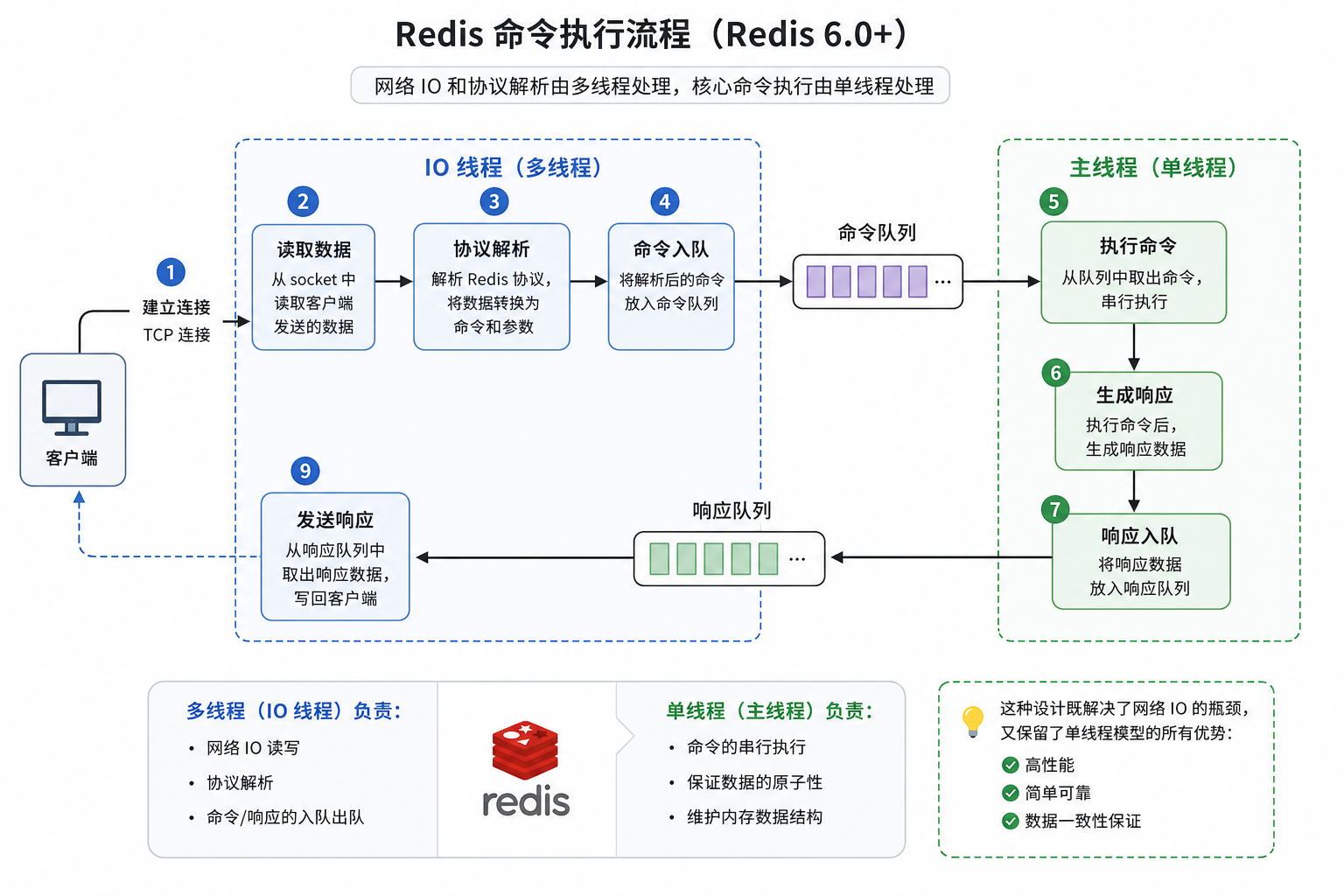
可以看到,在 Redis 6.0 以后,网络 IO 和协议解析是由多线程处理的,只有核心的命令执行是单线程的。这样既解决了网络 IO 的瓶颈,又保留了单线程模型的所有优势。
四、Redis 6.0 的多线程 IO:进一步提升性能
Redis 6.0 引入了一个重要的新特性:多线程 IO。很多人以为 Redis 6.0 把核心命令执行也改成了多线程,其实不是。
1. 为什么引入多线程 IO?
随着网络带宽的提升,网络 IO 逐渐成为了 Redis 的性能瓶颈。在万兆网络环境下,单线程处理网络 IO 已经无法充分利用网络带宽。
根据 Redis 官方的测试数据,在万兆网络环境下,单线程 Redis 的网络 IO 已经达到了瓶颈,CPU 的利用率只有 20%-30%。而引入多线程 IO 后,Redis 的吞吐量可以提升 2-3 倍。
2. 多线程 IO 的原理
Redis 6.0 的多线程只用于处理网络数据的读写和 Redis 协议解析,核心命令的执行仍然是单线程的。
这样设计的原因是:
- 网络 IO 是 IO 密集型操作,适合用多线程处理
- 命令执行是 CPU 密集型操作,多线程带来的上下文切换和锁竞争开销会超过收益
- 单线程执行命令可以保证数据一致性,避免并发问题
3. 多线程 IO 的性能提升
根据 Redis 官方的基准测试数据,在 Redis 6.0 中开启多线程 IO 后,性能有了显著提升:
| 线程数 | 读 QPS | 写 QPS | 性能提升 |
|---|---|---|---|
| 1(单线程) | 100,000 | 80,000 | 100% |
| 2 | 180,000 | 150,000 | 180% |
| 4 | 250,000 | 200,000 | 250% |
| 8 | 280,000 | 220,000 | 280% |
可以看到,随着线程数的增加,Redis 的吞吐量也在增加。但当线程数超过 4 以后,性能提升就不明显了,因为此时 CPU 已经成为了瓶颈。
五、常见误区纠正
-
误区:Redis 是单线程的,所以只能利用一个 CPU 核心。 纠正:Redis 的核心命令执行是单线程的,但还有很多后台线程运行在其他 CPU 核心上。而且可以通过 Redis Cluster 分片集群,充分利用多核 CPU 的性能。
-
误区:多线程一定比单线程快。 纠正:不一定。对于 CPU 密集型任务,多线程可以利用多核 CPU;但对于 IO 密集型任务,多线程的上下文切换和锁竞争开销会超过收益。Redis 属于 IO 密集型应用,单线程 + IO 多路复用是最优的选择。
-
误区:Redis 6.0 的多线程会导致并发问题。 纠正:不会。因为核心命令的执行仍然是单线程的,多线程只处理网络 IO,不会修改共享数据,所以不会有并发问题。
-
误区:Redis 快只是因为它是基于内存的。 纠正:基于内存只是基础。很多基于内存的数据库性能远不如 Redis,Redis 的高性能是纯内存、单线程模型、IO 多路复用、优化的数据结构等多个因素共同作用的结果。
-
误区:Redis 的单线程模型永远不会改变。 纠正:Redis 官方一直在探索多线程模型。未来的 Redis 版本可能会引入更多的多线程特性,但核心命令执行的单线程模型应该不会改变,因为这是 Redis 的灵魂。
六、高频面试题解答
-
问:Redis 为什么这么快? 答:Redis 快的原因有六个:1. 纯内存操作,读写速度极快;2. 单线程模型,避免了上下文切换和锁竞争开销;3. 使用 IO 多路复用技术,单线程处理高并发连接;4. 数据结构经过极致优化,性能极高;5. 高效的内存管理,减少了内存碎片和分配开销;6. 很多其他的优化细节,比如批量操作、管道等。
-
问:Redis 为什么选择单线程模型? 答:因为单线程模型有三个核心优势:1. 没有上下文切换开销,CPU 利用率高;2. 没有锁竞争开销,避免了线程阻塞;3. 编程简单,代码可靠,不容易出现并发问题。而且 Redis 的瓶颈是内存和网络,不是 CPU,单线程已经足够处理绝大多数场景。
-
问:什么是 IO 多路复用?Redis 使用的是哪种 IO 多路复用模型? 答:IO 多路复用是操作系统提供的一种机制,允许一个线程同时监视多个文件描述符,当某个文件描述符准备好读写时,操作系统会通知线程处理。Redis 使用的是 Linux 下的 epoll 模型,它的性能最好,可以同时处理几十万甚至上百万个连接。
-
问:epoll 为什么比 select 和 poll 快? 答:epoll 有三个优势:1. 没有最大连接数限制;2. 时间复杂度是 O (1),只返回有事件发生的连接;3. 使用内存映射技术,避免了内核态和用户态之间的数据拷贝。
-
问:Redis 6.0 引入的多线程是怎么回事? 答:Redis 6.0 引入的是多线程 IO,只用于处理网络数据的读写和协议解析,核心命令的执行仍然是单线程的。它解决了网络 IO 的瓶颈,进一步提升了 Redis 的吞吐量。
-
问:单线程的 Redis 怎么处理高并发? 答:Redis 使用 IO 多路复用技术,让一个线程可以同时处理成千上万个连接。当某个连接有数据到达时,操作系统会通知 Redis,Redis 再处理这个连接的请求。这样就可以用单线程处理高并发连接了。
七、总结
Redis 的高性能不是偶然的,而是多个优秀设计共同作用的结果。它的单线程模型看似反直觉,实则是经过深思熟虑的选择:
- 纯内存操作提供了物理层面的性能优势
- 单线程模型避免了多线程的额外开销
- IO 多路复用解决了单线程处理高并发连接的问题
- 极致优化的数据结构进一步提升了性能
- 高效的内存管理减少了内存碎片和分配开销
- Redis 6.0 的多线程 IO 解决了网络 IO 的瓶颈
Redis 的设计哲学告诉我们:简单的往往是最好的。单线程模型虽然简单,但它解决了最核心的问题,同时保证了系统的可靠性和可维护性。这也是 Redis 能够成为最受欢迎的内存数据库的根本原因。
理解了 Redis 单线程高性能的底层原理,你不仅能轻松应对所有相关的面试题,更能在实际项目中更好地使用 Redis,发挥它的最大性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)