数据清洗与处理:从“脏数据”到“可建模数据”的第一道工序
数据清洗与处理:从“脏数据”到“可建模数据”的第一道工序
整理说明
本文基于《大数据·Python大数据分析实践》中“数据清洗与处理”一节整理,重点围绕 pandas 数据结构、数据读写、缺失值处理、噪声处理、数据规范化和数据离散化 等内容展开。
在大数据分析中,算法并不是第一步,数据清洗才是第一步。现实中的数据往往并不完美:有缺失、有重复、有噪声、有异常值,还有格式不统一的问题。如果不先进行清洗和处理,后续的相关分析、回归分析、聚类、分类甚至关联规则挖掘都会受到影响。
一句话理解:
数据清洗与处理,就是把“不能直接分析的数据”整理成“可以用于统计分析和机器学习建模的数据”。
一、为什么数据清洗与处理如此重要?
在真实场景中,数据很少是一开始就整齐干净的。
例如,在一次数学建模比赛中,我们可能拿到这样一份电动汽车销量数据:
| 地区 region | 类别 category | 动力系统 powertrain | 年份 year | 销量 sales |
|---|---|---|---|---|
| Australia | Historical | BEV | 2011 | 1200 |
| China | Historical | EV | 2012 | 35000 |
| Europe | Historical | PHEV | 2013 | 缺失 |
| USA | Historical | EV | 2014 | 28000 |
| China | Historical | BEV | 2015 | 异常值 |
如果直接把这样的数据放入模型,就可能出现以下问题:
| 数据问题 | 具体表现 | 可能后果 |
|---|---|---|
| 缺失值 | 某些销量为空 | 模型无法训练或结果偏差 |
| 异常值 | 销量突然极大或极小 | 均值、回归结果被拉偏 |
| 格式不统一 | 年份是字符串,销量是文本 | 无法正常计算 |
| 重复记录 | 同一地区同一年重复录入 | 统计结果被重复计算 |
| 量纲差异 | GDP 是亿元,比例是百分数 | 大数值变量主导模型 |
所以,数据清洗不是可有可无的步骤,而是数据分析的地基。
二、本节知识地图
三、pandas:数据分析的“表格发动机”
pandas 是 Python 中最常用的数据分析库之一。它的核心作用是帮助我们高效地读取、清洗、整理和分析表格型数据。
pandas 中最核心的两个数据结构是:
| 数据结构 | 维度 | 类似对象 | 典型用途 |
|---|---|---|---|
| Series | 一维 | 带标签的一列数据 | 单个变量、单列指标 |
| DataFrame | 二维 | Excel 表格 / 数据表 | 多变量数据集 |
可以这样理解:
Series = 一列带索引的数据
DataFrame = 多个 Series 拼成的一张表
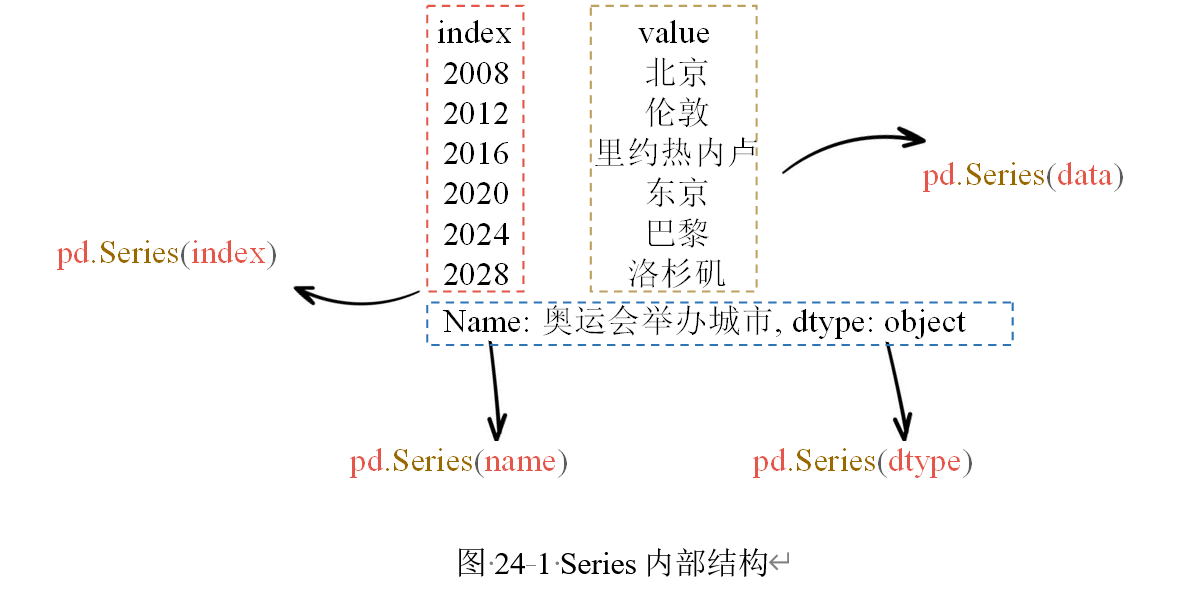
四、Series:一维带标签数组
Series 是 pandas 中的一维数据结构,由两部分组成:
- values:真正的数据值;
- index:与数据值对应的标签。
例如,下面是一组城市区号数据:
import pandas as pd
data = ['010', '021', '020', '0755', '028']
index_name = ['北京', '上海', '广州', '深圳', '成都']
s = pd.Series(data, index=index_name)
print(s)
输出结果类似:
北京 010
上海 021
广州 020
深圳 0755
成都 028
dtype: object
这里,“北京、上海、广州、深圳、成都”就是索引,“010、021、020、0755、028”就是具体数据。
1. Series 的创建方式
| 创建方式 | 示例 | 适用场景 |
|---|---|---|
| 列表创建 | pd.Series([88, 25, 3]) |
简单一维数据 |
| NumPy 数组创建 | pd.Series(np.array(['A','B','C'])) |
数值计算结果转为 Series |
| 字典创建 | pd.Series({'A':1,'B':2}) |
自带标签的数据 |
示例代码:
import pandas as pd
import numpy as np
# 1. 使用列表创建
s1 = pd.Series([88, 25, 3])
print(s1)
# 2. 使用 NumPy 数组和自定义索引创建
s2 = pd.Series(np.array(['A', 'B', 'C']), index=[1, 2, 3])
print(s2)
# 3. 使用字典创建
s3 = pd.Series({'A': 1, 'B': 2, 'C': 3}, dtype='float64')
print(s3)
2. Series 的三种索引方式
| 索引方式 | 代码 | 含义 |
|---|---|---|
| 位置索引 | s.iloc[0] |
按位置取值 |
| 标签索引 | s.loc['北京'] |
按标签取值 |
| 切片索引 | s[1:5] |
按位置范围切片 |
示例:
import pandas as pd
data = ['010', '021', '020', '0755', '028']
index_name = ['北京', '上海', '广州', '深圳', '成都']
s = pd.Series(data, index=index_name)
print("位置索引:")
print(s.iloc[0])
print(s.iloc[:2])
print(s.iloc[-1])
print("\n标签索引:")
print(s.loc['北京'])
print(s.loc['上海':'成都'])
print("\n切片索引:")
print(s[1:5])
注意:
直接对 Series 使用切片时,默认使用的是位置索引。例如s[1:5]表示返回位置 1 到位置 5 之前的数据,不包括位置 5。
五、DataFrame:二维表格型数据
DataFrame 是 pandas 中最常用的数据结构。它可以理解为一张 Excel 表格:
- 每一列可以看作一个 Series;
- 每一行表示一条样本记录;
- 每一列表示一个变量或字段。
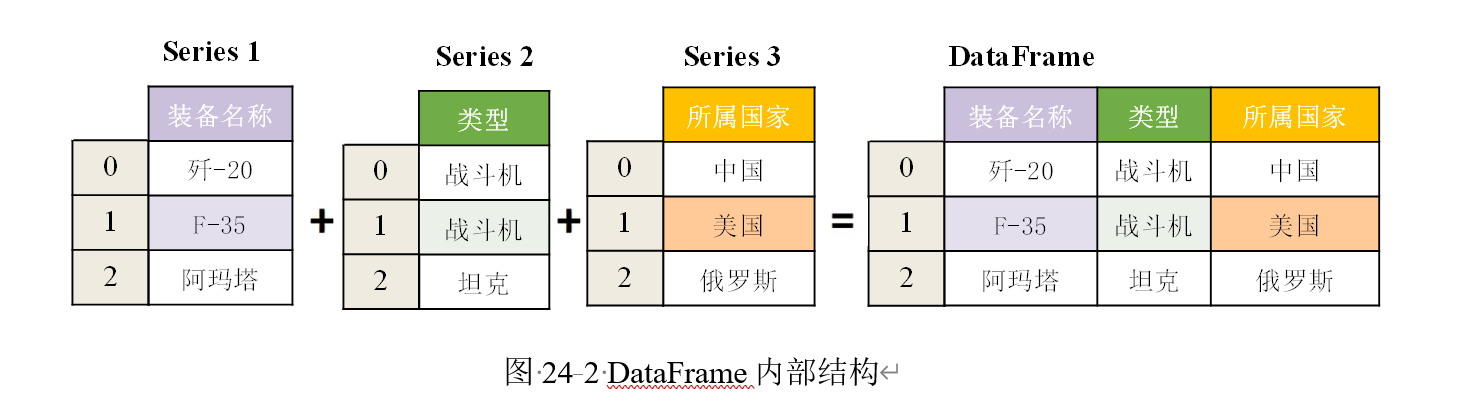
1. DataFrame 的结构理解
假设有一份股票开盘价数据:
| stockCode | openingPrice |
|---|---|
| 600877.SH | 11.33 |
| 300922.SZ | 12.90 |
| 002421.SZ | 2.38 |
它在 pandas 中就是一个 DataFrame。
可以从三个层面理解 DataFrame:
| 组成部分 | 含义 | 示例 |
|---|---|---|
| 行索引 index | 每一行的标签 | 0, 1, 2 |
| 列索引 columns | 每一列的名称 | stockCode, openingPrice |
| 数据 values | 表格中的具体值 | 600877.SH, 11.33 |
2. DataFrame 的创建方式
import pandas as pd
# 1. 通过 list 创建 DataFrame
data_list = [
['600877.SH', 11.33],
['300922.SZ', 12.90],
['002421.SZ', 2.38]
]
df1 = pd.DataFrame(data_list, columns=['stockCode', 'openingPrice'])
print("通过 list 创建的 DataFrame:")
print(df1)
# 2. 通过字典创建 DataFrame
data_dict = {
'stockCode': ['600877.SH', '300922.SZ', '002421.SZ'],
'openingPrice': [11.33, 12.90, 2.38]
}
df2 = pd.DataFrame(data_dict)
print("通过字典创建的 DataFrame:")
print(df2)
# 3. 通过 Series 创建 DataFrame
stockCode = pd.Series(['600877.SH', '300922.SZ', '002421.SZ'])
openingPrice = pd.Series([11.33, 12.90, 2.38])
df3 = pd.DataFrame({
'stockCode': stockCode,
'openingPrice': openingPrice
})
print("通过 Series 创建的 DataFrame:")
print(df3)
3. DataFrame 常用属性速查表
| 属性 / 方法 | 作用 | 示例 |
|---|---|---|
df.values |
查看所有元素值 | df.values |
df.size |
查看元素总数 | df.size |
df.T |
行列转置 | df.T |
df.head() |
查看前 5 行 | df.head() |
df.tail() |
查看后 5 行 | df.tail() |
df.shape |
查看行数和列数 | df.shape |
df.info() |
查看数据类型和内存信息 | df.info() |
小技巧:
在拿到一个新数据集时,建议先运行:df.head() df.info() df.shape df.describe()这样可以快速了解数据规模、字段类型、缺失情况和基本统计特征。
六、数据读写:把外部数据变成 DataFrame
pandas 支持多种数据格式的读取和写入。
| 文件类型 | 读取函数 | 写入函数 | 常见场景 |
|---|---|---|---|
| CSV | read_csv() |
to_csv() |
普通文本表格 |
| Excel | read_excel() |
to_excel() |
问卷、统计表、财务表 |
| JSON | read_json() |
to_json() |
Web 接口数据 |
| HTML | read_html() |
to_html() |
网页表格抓取 |
| SQL | read_sql() |
to_sql() |
数据库数据 |
七、CSV 文件读取:read_csv 的参数魔法
CSV 文件是最常见的数据文件格式之一。在 pandas 中,可以使用 read_csv() 读取 CSV 文件。
import pandas as pd
df = pd.read_csv("Global EV Sales 2010-2024.csv")
print(df.head())
教材案例中使用的是 Global EV Sales 2010-2024 数据集,该数据集记录了全球不同国家在 2010—2024 年期间的电动汽车销售情况,字段包括地区、类别、动力系统、年份等。
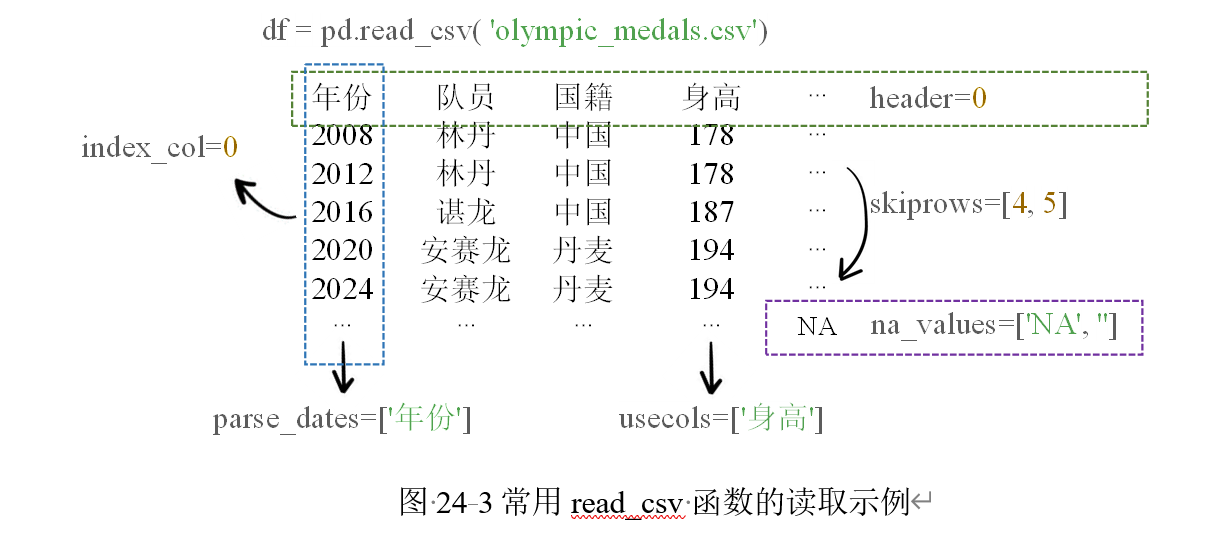
1. read_csv 常用参数表
| 参数 | 含义 | 示例 |
|---|---|---|
filepath_or_buffer |
文件路径 | "data.csv" |
sep |
分隔符 | sep="," |
header |
指定哪一行为列名 | header=0 |
names |
自定义列名 | names=["A","B"] |
index_col |
指定索引列 | index_col=0 |
usecols |
指定读取列 | usecols=[0,1,2] |
skiprows |
跳过前几行 | skiprows=3 |
nrows |
只读取前几行 | nrows=5 |
encoding |
指定编码 | encoding="utf-8" |
parse_dates |
日期解析 | parse_dates=["year"] |
na_values |
指定缺失值符号 | na_values=["NA","-"] |
2. read_csv 参数示例
import pandas as pd
# 1. 将前两行作为复合列名
df_header = pd.read_csv('Global EV Sales 2010-2024.csv', header=[0, 1])
print("调整 header 参数:")
print(df_header.iloc[:2, :3])
# 2. 指定部分列读取
df_usecols = pd.read_csv(
'Global EV Sales 2010-2024.csv',
usecols=[0, 1, 2],
nrows=5
)
print("调整 usecols 参数:")
print(df_usecols)
# 3. 指定索引列
df_index_col = pd.read_csv(
'Global EV Sales 2010-2024.csv',
index_col=[1, 2],
nrows=5,
usecols=[0, 1, 2]
)
print("调整 index_col 参数:")
print(df_index_col)
# 4. 跳过前 3 行,并指定编码
df_others = pd.read_csv(
'Global EV Sales 2010-2024.csv',
sep=',',
skiprows=3,
encoding='utf-8',
nrows=5,
usecols=[3, 4, 5]
)
print("其它 read_csv 操作:")
print(df_others)
路径提醒:
Windows 路径中的反斜杠\容易被识别为转义字符。
推荐写法:r"F:\desktop\case.csv"或者:
"F:/desktop/case.csv"
八、Excel 文件读取:read_excel 的常见用法
Excel 文件常用于问卷调查、期刊数据、统计报表和实验记录。在 pandas 中,可以使用 read_excel() 读取 Excel 文件。
import pandas as pd
df = pd.read_excel("Journal Citation Reports 2024.xlsx")
print(df.head())
教材案例中使用的是 2023 与 2024 年度《期刊引证报告》数据,其中包含期刊名称、ISSN、eISSN、期刊类别、影响因子和分区等信息。
read_excel 常用参数表
| 参数 | 含义 | 示例 |
|---|---|---|
io |
Excel 文件路径 | "data.xlsx" |
sheet_name |
工作表名称或索引 | sheet_name=0 |
header |
指定列名所在行 | header=0 |
names |
自定义列名 | names=["Name","Score"] |
index_col |
设置索引列 | index_col=[0,1] |
usecols |
指定读取列 | usecols=[3,7] |
skiprows |
跳过开头行 | skiprows=7 |
skipfooter |
跳过末尾行 | skipfooter=2 |
nrows |
读取指定行数 | nrows=3 |
示例代码:
import pandas as pd
# 1. 只读取第 4 列和第 8 列的前 3 行数据
df_usecols = pd.read_excel(
'Journal Citation Reports 2024.xlsx',
sheet_name=0,
usecols=[3, 7],
nrows=3
)
print("调整 usecols 参数:")
print(df_usecols)
# 2. 将第 1 列和第 2 列设置为行索引
df_index_col = pd.read_excel(
'Journal Citation Reports 2024.xlsx',
sheet_name='JCR',
index_col=[0, 1],
nrows=3,
usecols=[0, 1, 6]
)
print("调整 index_col 参数:")
print(df_index_col)
# 3. 跳过前 7 行,并指定列名
df_names = pd.read_excel(
'Journal Citation Reports 2024.xlsx',
sheet_name='JCR23',
skiprows=7,
nrows=3,
usecols=[0, 6],
names=['Name', 'Score']
)
print("其它 read_excel 操作:")
print(df_names)
注意:
如果同时使用names和header,通常需要设置header=None,否则names可能不会生效。
九、数据清洗:处理缺失值
缺失值是最常见的数据质量问题。缺失值可能来自问卷未填写、传感器异常、人工录入错误或数据合并失败。
缺失值处理方法可以分为两大类:
1. 缺失值处理方法对比
| 方法 | 适用场景 | Python 示例 | 优点 | 风险 |
|---|---|---|---|---|
| 整例删除 | 样本量大,缺失比例小 | df.dropna(axis=0) |
简单直接 | 可能损失样本 |
| 变量删除 | 某列缺失比例极高 | df.dropna(axis=1) |
删除无效变量 | 可能删掉重要特征 |
| 均值补齐 | 连续型数值变量 | df.fillna(df.mean()) |
快速稳定 | 会压缩方差 |
| 众数补齐 | 离散型分类变量 | df.fillna(df.mode().iloc[0]) |
适合类别变量 | 可能改变分布 |
| 拟合补齐 | 变量存在规律关系 | np.polyfit() |
更贴合趋势 | 容易过拟合 |
2. 缺失值处理示例
import pandas as pd
# 创建一个包含缺失值的 DataFrame
data = {
'A': [1, 2, None, 4],
'B': [5, None, 7, 8],
'C': [9, 10, 11, None]
}
df = pd.DataFrame(data)
print("原始 DataFrame:")
print(df)
# 删除包含缺失值的行
df_dropped = df.dropna()
print("删除缺失值后的 DataFrame:")
print(df_dropped)
# 使用众数填充缺失值
df_mode_filled = df.fillna(df.mode().iloc[0])
print("使用众数填充后的 DataFrame:")
print(df_mode_filled)
经验判断:
- 缺失比例很低:可以考虑删除;
- 缺失比例较高:不能随便删除,需要分析原因;
- 数值型变量:可以考虑均值、中位数或模型补齐;
- 分类变量:可以考虑众数补齐;
- 时间序列数据:可以考虑插值或拟合补齐。
十、拟合补齐:用趋势填补缺失值
如果数据本身存在明显的趋势关系,就可以使用拟合方法补齐缺失值。
例如,某个变量随时间呈现二次曲线变化,如果中间某些点缺失,就可以先用已有数据拟合曲线,再用拟合值补齐缺失点。
【插图建议:这里可以插入教材中“polyfit 函数拟合补齐结果”图。图中展示了线性函数拟合补齐和非线性函数拟合补齐的效果。】
示例代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 从 Excel 读取数据
df = pd.read_excel('data_imputation.xlsx')
X = df['X'].values
y = df['y'].values
# 2. 提取非缺失数据
X_clean = X[~np.isnan(y)]
y_clean = y[~np.isnan(y)]
# 3. 使用二次多项式拟合
coefficients = np.polyfit(X_clean, y_clean, deg=2)
poly = np.poly1d(coefficients)
# 4. 计算拟合值,用拟合值替代缺失值
y_fit = poly(X)
y_filled = np.where(np.isnan(y), y_fit, y)
# 5. 绘制原始数据、拟合曲线和补齐后的数据
plt.scatter(X, y, label='原始数据')
plt.plot(X, y_fit, label='拟合曲线')
plt.scatter(X, y_filled, marker='x', label='补齐后的数据')
plt.legend()
plt.show()
十一、噪声处理:让数据更平滑、更可靠
噪声是数据中随机波动或不相关的干扰。
例如,一个产品全年每日销量大致稳定在 50—100 件之间,但某一天突然出现 500 件,这个值可能是真实促销结果,也可能是录入错误。数据清洗时需要判断并处理这类问题。
常见噪声处理方法包括:
| 方法 | 核心思想 | 适用场景 |
|---|---|---|
| 分箱 | 把连续数值划分成区间 | 降低极端值影响 |
| 回归降噪 | 用模型拟合真实趋势 | 时间序列、曲线趋势数据 |
| 3σ 原则 | 超出均值 ±3倍标准差视为异常 | 近似正态分布数据 |
十二、分箱:把连续数据装进“箱子”
分箱(Binning)是将连续数值划分为多个区间,从而降低噪声影响的方法。
例如,某产品每日销量是连续数值,可以按照销量区间划分为:
| 销量区间 | 销量等级 |
|---|---|
| 0—30 | 低销量 |
| 31—60 | 中低销量 |
| 61—90 | 中高销量 |
| 91 以上 | 高销量 |
分箱方法主要有两类:
| 方法 | 含义 | Python 实现 | 特点 |
|---|---|---|---|
| 等宽分箱 | 每个箱子的区间宽度相同 | pd.cut() |
区间规则清晰 |
| 等频分箱 | 每个箱子的数据数量相近 | pd.qcut() / KBinsDiscretizer |
分布更均衡 |
示例代码:
import pandas as pd
from sklearn.preprocessing import KBinsDiscretizer
# 1. 读取 Excel 文件
df = pd.read_excel("sales_data.xlsx")
# 2. 等宽分箱
bins_width = pd.cut(df['Sales'], bins=6)
width_bin_counts = bins_width.value_counts().sort_index()
print("等宽分箱结果:")
print(width_bin_counts)
# 3. 等频分箱
k_bins_discretizer = KBinsDiscretizer(
n_bins=6,
encode='ordinal',
strategy='quantile'
)
sales_binned_depth = k_bins_discretizer.fit_transform(df[['Sales']])
df['Depth_Bin'] = sales_binned_depth.astype(int)
depth_bin_counts = df['Depth_Bin'].value_counts().sort_index()
print("等频分箱结果:")
print(depth_bin_counts)
理解:
等宽分箱像“按尺子切蛋糕”,每块宽度一样;
等频分箱像“按人数分组”,每组人数尽量一样。
十三、回归降噪:用平滑曲线还原真实趋势
回归降噪是一种通过回归模型拟合真实信号,从而减小随机噪声影响的方法。
它和拟合补齐很像,都可以使用 np.polyfit(),但二者目的不同:
| 方法 | 目的 | 使用数据 | 输出结果 |
|---|---|---|---|
| 拟合补齐 | 填补缺失值 | 非缺失数据 | 补齐后的数据 |
| 回归降噪 | 平滑噪声 | 全部含噪数据 | 更平滑的拟合曲线 |
示例代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 1. 读取数据
df = pd.read_excel('noisy_sin_data.xlsx')
dates = df['Date']
X = np.linspace(0, 10, len(dates))
y = df['y'].values
# 2. 使用高阶多项式拟合
coefficients = np.polyfit(X, y, deg=9)
poly = np.poly1d(coefficients)
# 3. 计算拟合值,进行降噪
y_fit = poly(X)
# 4. 可视化
plt.plot(dates, y, label='原始含噪数据')
plt.plot(dates, y_fit, label='回归降噪后的曲线')
plt.legend()
plt.show()
十四、3σ 原则:识别异常值
3σ 原则基于正态分布。若数据近似服从正态分布,那么绝大多数数据都会落在:
均值 ± 3 × 标准差
的范围内。
如果某个数据点超出这个范围,就可以初步判断为异常值。
import numpy as np
import pandas as pd
# 假设 df 中有一列 Sales
mean_value = df['Sales'].mean()
std_value = df['Sales'].std()
lower_bound = mean_value - 3 * std_value
upper_bound = mean_value + 3 * std_value
normal_data = df[(df['Sales'] >= lower_bound) & (df['Sales'] <= upper_bound)]
outliers = df[(df['Sales'] < lower_bound) | (df['Sales'] > upper_bound)]
print("正常数据:")
print(normal_data)
print("异常值:")
print(outliers)
注意:
3σ 原则更适合近似正态分布的数据。
如果数据本身是偏态分布,例如收入、销量、点击量等,直接使用 3σ 可能会误判。
十五、数据规范化:让不同量纲公平竞争
在机器学习中,不同变量的数值范围可能差异很大。
例如:
| 指标 | 数值范围 |
|---|---|
| 年龄 | 0—100 |
| 年收入 | 0—1000000 |
| 点击率 | 0—1 |
| 评分 | 1—5 |
如果不进行规范化,数值范围大的变量可能会在模型中占据主导地位。
因此,需要把不同尺度的数据转换到统一范围内。
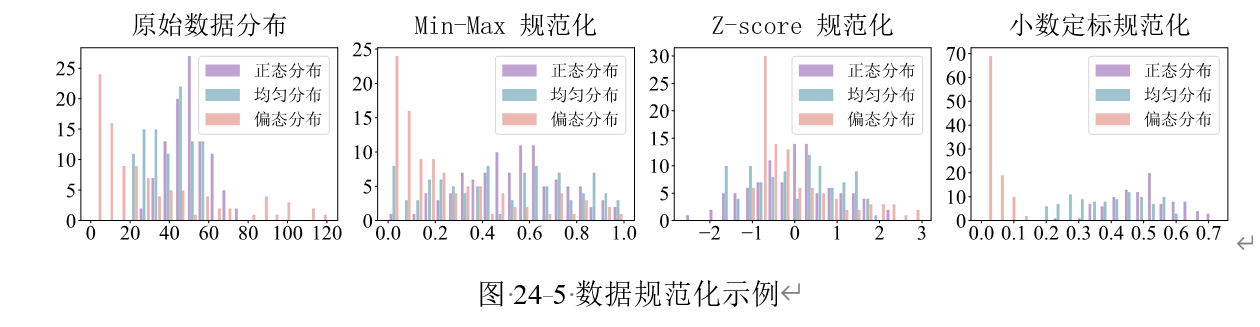
1. 三种常见规范化方法
| 方法 | 公式思想 | 结果范围 | 适用情况 |
|---|---|---|---|
| 最小-最大规范化 | 按最大值和最小值缩放 | 通常为 [0,1] | 希望数据落入固定区间 |
| Z 分数规范化 | 减均值,除标准差 | 均值 0,标准差 1 | 适合近似正态分布数据 |
| 小数定标规范化 | 通过移动小数点缩放 | 依赖原始数据大小 | 简单快速缩放 |
2. Python 实现规范化
import numpy as np
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 假设 X 是原始特征矩阵
X = np.array([
[5.1, 3.5],
[4.9, 3.0],
[4.7, 3.2],
[4.6, 3.1]
])
# 1. 最小-最大规范化
scaler_minmax = MinMaxScaler()
X_minmax = scaler_minmax.fit_transform(X)
# 2. Z-score 标准化
scaler_zscore = StandardScaler()
X_zscore = scaler_zscore.fit_transform(X)
# 3. 小数定标规范化
X_decimal = X / 10 ** np.ceil(np.log10(np.max(np.abs(X))))
print("Min-Max 规范化:")
print(X_minmax)
print("Z-score 规范化:")
print(X_zscore)
print("小数定标规范化:")
print(X_decimal)
机器学习中的重要提醒:
训练集和测试集不能一起规范化。
正确做法是:用训练集fit,再分别对训练集和测试集transform。
否则可能造成数据泄露。
正确示例:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
十六、数据离散化:把连续变量变成类别变量
数据离散化是把连续变量划分为有限数量区间的过程。
例如,把年龄从连续数值转换为年龄段:
| 年龄 | 离散化结果 |
|---|---|
| 18 | 青年 |
| 35 | 中年 |
| 67 | 老年 |
离散化的作用包括:
- 简化数据结构;
- 降低模型复杂度;
- 减弱异常值影响;
- 便于规则挖掘和分类建模。
十七、分类编码:让机器读懂文字类别
机器学习模型通常不能直接处理“汽油、柴油、电动”这样的文本类别,因此需要把类别变量转换成数值。
教材中以汽车 ID、燃油类型和传动类型为例,展示了序数编码、独热编码和哑变量编码。
1. 常见分类编码方式
| 编码方法 | 核心思想 | 示例 | Python 实现 |
|---|---|---|---|
| 序数编码 | 将类别映射为整数 | 汽油=1,柴油=0,电动=2 | OrdinalEncoder() |
| 独热编码 | 每个类别变成一个二值列 | 汽油=[1,0,0] | OneHotEncoder() / pd.get_dummies() |
| 哑变量编码 | 独热编码中删除一列作为基准 | k 类变成 k-1 列 | pd.get_dummies(drop_first=True) |
2. 汽车燃油类型编码示例
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
# 1. 创建数据集
data = pd.DataFrame({
'汽车 ID': ['Car1', 'Car2', 'Car3', 'Car4', 'Car5'],
'燃油类型': ['汽油', '柴油', '电动', '汽油', '柴油'],
'传动类型': ['手动', '自动', '手动', '自动', '手动']
})
print("原始数据:")
print(data)
# 2. 序数编码
ordinal_encoder = OrdinalEncoder()
data['燃油类型_序数编码'] = ordinal_encoder.fit_transform(data[['燃油类型']])
print("序数编码:")
print(data[['汽车 ID', '燃油类型', '燃油类型_序数编码']])
# 3. 独热编码
data_one_hot = pd.get_dummies(
data,
columns=['汽车 ID', '燃油类型', '传动类型']
)
print("独热编码:")
print(data_one_hot)
# 4. 哑变量编码
data_dummy = pd.get_dummies(
data,
columns=['燃油类型', '传动类型'],
drop_first=True
)
print("哑变量编码:")
print(data_dummy)
3. 编码方法如何选择?
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 类别有明显顺序 | 序数编码 | 如低、中、高 |
| 类别没有顺序 | 独热编码 | 如颜色、品牌、城市 |
| 线性回归等模型 | 哑变量编码 | 避免完全共线性 |
| 类别数量特别多 | 谨慎独热编码 | 可能造成维度爆炸 |
举例:
“学历:小学、初中、高中、本科、研究生”有顺序,可以用序数编码。
“城市:北京、上海、广州、深圳”没有天然大小关系,更适合独热编码。
十八、综合案例:一份原始数据如何变成可建模数据?
假设我们有一份二手车数据:
| 车型 | 燃油类型 | 变速箱 | 车龄 | 里程 | 价格 |
|---|---|---|---|---|---|
| Car1 | 汽油 | 自动 | 3 | 5.2 | 12.8 |
| Car2 | 柴油 | 手动 | 缺失 | 8.1 | 9.6 |
| Car3 | 电动 | 自动 | 1 | 2.4 | 18.5 |
| Car4 | 汽油 | 缺失 | 5 | 12.3 | 异常值 |
完整的数据清洗流程可以设计为:
对应代码框架如下:
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 1. 读取数据
df = pd.read_excel("car_data.xlsx")
# 2. 查看数据结构
print(df.head())
print(df.info())
print(df.isnull().sum())
# 3. 缺失值处理
df['车龄'] = df['车龄'].fillna(df['车龄'].median())
df['变速箱'] = df['变速箱'].fillna(df['变速箱'].mode()[0])
# 4. 异常值处理:以价格为例使用 3σ 原则
mean_price = df['价格'].mean()
std_price = df['价格'].std()
lower = mean_price - 3 * std_price
upper = mean_price + 3 * std_price
df = df[(df['价格'] >= lower) & (df['价格'] <= upper)]
# 5. 数值变量规范化
scaler = StandardScaler()
df[['车龄', '里程']] = scaler.fit_transform(df[['车龄', '里程']])
# 6. 类别变量编码
df = pd.get_dummies(df, columns=['燃油类型', '变速箱'], drop_first=True)
print("清洗后的数据:")
print(df.head())
十九、我的学习体会
学习这一节后,我最大的感受是:数据分析并不是从复杂模型开始,而是从数据整理开始。
pandas 中的 Series 和 DataFrame 构成了数据处理的基本工具。Series 更像“一列数据”,DataFrame 更像“一张表”。掌握这两个结构之后,CSV、Excel、JSON、SQL 等不同来源的数据都可以被统一转化为 DataFrame 进行处理。
此外,缺失值、噪声、异常值、量纲不统一、类别变量无法计算等问题,几乎会出现在所有真实数据中。数据清洗与处理的意义,就是在建模之前把这些问题逐一解决。
在数学建模中,这一步尤其重要。很多模型结果不稳定,并不是算法本身不好,而是因为数据预处理不到位。一个干净、规范、结构清晰的数据集,往往比一个复杂但没有清洗好的模型更有价值。
二十、知识结构总表
| 模块 | 核心内容 | 常用函数 | 学习意义 |
|---|---|---|---|
| Series | 一维标签数组 | pd.Series() |
理解单列数据 |
| DataFrame | 二维表格数据 | pd.DataFrame() |
数据分析核心结构 |
| CSV 读写 | 读取文本表格 | read_csv() / to_csv() |
处理常见数据文件 |
| Excel 读写 | 读取 Excel 表格 | read_excel() / to_excel() |
处理问卷和报表 |
| 缺失值处理 | 删除或填补空值 | dropna() / fillna() |
提高数据完整性 |
| 拟合补齐 | 用趋势填补缺失 | np.polyfit() |
保留变量变化规律 |
| 分箱 | 连续变量分组 | pd.cut() / pd.qcut() |
降低噪声影响 |
| 回归降噪 | 拟合平滑曲线 | np.polyfit() |
提取真实趋势 |
| 3σ 原则 | 异常值识别 | mean() / std() |
发现离群点 |
| 规范化 | 统一变量尺度 | MinMaxScaler() / StandardScaler() |
避免量纲影响 |
| 离散化 | 连续变量变区间 | KBinsDiscretizer() |
简化建模 |
| 分类编码 | 文本类别转数值 | OrdinalEncoder() / get_dummies() |
让模型处理类别变量 |
二十一、简易重点总结
- 数据清洗与处理是数据挖掘和机器学习建模前的重要步骤。
- pandas 的核心数据结构包括 Series 和 DataFrame。
- Series 是一维带标签数组,DataFrame 是二维表格型数据。
read_csv()和read_excel()是最常用的数据读取函数。- 缺失值处理包括删除数据、均值补齐、众数补齐和拟合补齐。
- 噪声处理可以使用分箱、回归降噪和 3σ 原则。
- 数据规范化可以解决不同变量量纲差异过大的问题。
- 数据离散化可以将连续变量转化为有限区间。
- 分类编码可以把文字类别转换为模型能够识别的数值形式。
- 数据处理质量决定了后续模型分析结果的可靠性。
二十二、思考题
- 为什么说数据清洗是数据分析的第一步?
- Series 和 DataFrame 的区别是什么?
- 在什么情况下适合删除缺失值?什么情况下更适合填补缺失值?
- 等宽分箱和等频分箱有什么区别?
- 为什么机器学习中需要进行数据规范化?
- 序数编码和独热编码分别适合什么类型的变量?
- 如果一个数据集中存在大量异常值,应该直接删除吗?为什么?
补充说明
本文是基于国防科技大学吕欣教授主编的《大数据·Python大数据分析实践》一书所整理的读书笔记。该书系统覆盖了数据挖掘的九大核心领域,包括统计描述、相关分析、回归分析、数据降维、关联规则挖掘、分类、聚类、异常检测和集成学习。此外,本书还配有丰富的数字化学习资源和全套教辅材料,构建了理论与实践紧密结合的立体化教学系统。相关学习资料可通过以下链接获取:
https://github.com/XL-lab-bigdata/DataMining

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)